AI夏令营第三期 - 基于论文摘要的文本分类与关键词抽取挑战赛笔记
赛题:基于论文摘要的文本分类与关键词抽取
背景:高效的从海量医学文献中提取疾病诊断和治疗关键信息
任务:通过论文摘要判断论文是否为医学文献 样例
数据集:csv文件,字段:标题、作者、摘要、关键词
评价指标:F1_score
解题思路:文本分类任务
思路一:特征提取+机器学习
数据预处理->特征提取->构建训练集和测试集->模型训练和评估->调参优化
数据预处理: 文本清洗(去除特殊字符、标点符号)
分词
NLP工具包(NLTK\spaCy)
特征提取: 文本转换为向量表示
TF-IDF(词频-逆文档频率):计算文本中词语的重要性
BOW(词袋模型):统计词语在文本中的出现次数
使用scikit-learn库的TfidfVectorizer或CountVectorizer来实现
构建训练集和测试集:分割预处理后的数据
模型训练和评估:训练集训练模型,测试集评估结果
调参优化:调整参数
机器学习baseline:
LogisticRegression模型
实则为一个线性分类器,通过 Logistic 函数(或
Sigmoid 函数),将数据特征映射到0~1区间的一个概率值(样本属于正例的可能性),通过与 0.5 的比对得出数据所属的分类(二分类)。逻辑回归的数学表达式为:
使用 sklearn.linear_model.LogisticRegression 来调用已实现的逻辑回归模型
Pandas:Python 语言的一个扩展程序库,用于数
据分析,基础是Numpy
scikit-learn:内部封装了多种机器学习算法与数据处理算法,提供了包括数据清洗、数据预处理、建模调参、数据验证、数据可视化的全流程功能
特征提取:
即从训练数据的特征集合中创建新的特征子集的过程。
提取出来的特征子集特征数一般少于等于原特征数,但能够更好地表征训练数据的情况,使用提取出的特征子集能够取得更好的预测效果。
训练数据的每一个维度称为一个特征
可以使用 sklearn 库中的 feature_extraction 包来实现文本与图片的特征提取。
在 NLP 任务中,特征提取一般需要将自然语言文本转化为数值向量表示,常见的方法包括基于 TF-IDF(词频-逆文档频率)提取或基于 BOW(词袋模型)提取
TF-IDF(term frequency–inverse document frequency):一种用于信息检索与数据挖掘的常用加权技术
TF 指 term frequence,即词频,指某个词在文章中出现次数与文章总词数的比值
IDF 指 inverse document frequence,即逆文档频率,指包含某个词的文档数占语料库总文档数的比例的倒数。
每个词最终的 IF-IDF 即为 TF 值乘以 IDF 值。计算出每个词的 TF-IDF 值后,使用 TF-IDF 计算得到的数值向量替代原文本即可实现基于 TF-IDF 的文本特征提取。
使用sklearn.feature_extraction.text 中的 TfidfVectorizer 类来简单实现文档基于 TF-IDF 的特征提取
BOW(Bag of Words)是一种常用的文本表示方法,其基本思想是假定对于一个文本,忽略其词序和语法、句法,仅仅将其看做是一些词汇的集合,而文本中的每个词汇都是独立的。
使用 sklearn.feature_extraction.text 中的 CountVectorizer 类来简单实现文档基于频数统计的 BOW 特征提取
停用词(Stop Words)是自然语言处理领域的一个重要工具,通常被用来提升文本特征的质量,或者降低文本特征的维度。
忽略一些不能提供有价值的信息作用的词语
划分数据集:训练集、验证集、预测集
同分布采样划分训练集和验证集
交叉验证,即对于一个样本总量为 T 的数据集,我们一般随机采样 10%~20%(也就是 0.1T~0.2T 的样本数)作为验证集,而取其他的数据为训练集。
使用 sklearn.model_selection 中的 train_test_split 函数便捷实现数据集的划分
选择机器学习模型:
- sklearn.linear_model:线性模型,如线性回归、逻辑回归、岭回归等
- sklearn.tree:树模型,一般为决策树
- sklearn.neighbors:最近邻模型,常见如 K 近邻算法
- sklearn.svm:支持向量机
- sklearn.ensemble:集成模型,如 AdaBoost、GBDT等
先实例化一个模型对象,再使用 fit 函数拟合训练数据,最后使用 predict 函数预测测试数据
数据探索:
使用pandas读取数据
利用pd.read_csv()方法对赛题数据进行读取,读取后返回一个DataFrame 数据
数据清洗:
数据和特征决定了机器学习的上限
数据清洗的作用是利用有关技术如数理统计、数据
挖掘或预定义的清理规则将脏数据转化为满足数据质量要求的数据。主要包括缺失值处理、异常值处理、数据分桶、特征归一化/标准化等流程。
由于表格中存在较多列,我们将这些列的重要内容组合在一起生成一个新的列方便训练
如果数据集中某行缺少title author abstract中的内容,我们需要利用fillna()来保证不会出现报错。
特征工程:
把原始数据转变为模型训练数据的过程,目的是获取更好的训练数据特征。比如BOW
模型训练与验证:
模型的选择决定结果的上限, 如何更好的去达到模型上限取决于模型的调参。
结果输出:
输出格式结果
改进1:使用TF-IDF,提高到0.76324
from sklearn.feature_extraction.text import TfidfVectorizervector = TfidfVectorizer().fit(train['text'])
改进2:添加停用词,下降到0.75911
stops =[i.strip() for i in open(r'stop.txt',encoding='utf-8').readlines()] 改进3:去掉author,更换模型RidgeClassifier()下降到0.73032
train['text'] = train['title'].fillna('') + ' ' + train['abstract'].fillna('')+ ' ' + train['Keywords'].fillna('')
test['text'] = test['title'].fillna('') + ' ' + test['abstract'].fillna('')
model = RidgeClassifier()
相关文章:
AI夏令营第三期 - 基于论文摘要的文本分类与关键词抽取挑战赛笔记
赛题:基于论文摘要的文本分类与关键词抽取 背景:高效的从海量医学文献中提取疾病诊断和治疗关键信息 任务:通过论文摘要判断论文是否为医学文献 样例 数据集:csv文件,字段:标题、作者、摘要、关键词 评价指…...

使用qsqlmysql操作mysql提示Driver not loaded
环境: win10 IDE: qt creator 编译器: mingw32 这里简单的记录下。我遇到的情况是在IDE使用debug和release程序都是运行正常,但是当我编译成发布版本之后。老是提示Driver not load。 这就很奇诡了。 回顾了下编译的时候是需要在使用qt先编译下libqsqlmysql.dll的…...

Java云原生框架Quarkus初探
Java云原生框架Quarkus初探 Quarkus 介绍 Quarkus 是一个云原生,容器优先的Java应用框架,它号称是超音速和亚原子的框架,主要特点是构建速度、启动速度快和占用资源少等特点。它为OpenJDK HotSpot和GraalVM量身定制, 根据Java库和…...

ElasticSearch相关概念
文章目录 前提倒排索引MySQL、ES的区别和关联IK分词器索引库mapping属性索引库的crud 文档的crudRestClientDSL查询DSL 查询种类DSL query 基本语法 搜索结构处理排序分页高亮RestClient 前提 开源的搜索引擎,从海量数据中快速找到需要的内容。(分词检索…...
微服务实战项目-学成在线-项目部署
微服务实战项目-学成在线-项目部署 1 什么是DevOps 一个软件的生命周期包括:需求分析阶、设计、开发、测试、上线、维护、升级、废弃。 通过示例说明如下: 1、产品人员进行需求分析 2、设计人员进行软件架构设计和模块设计。 3、每个模块的开发人员…...

封装form表单
目录 1. 源码 2. 其他页面引用 ps:请看完看明白再复用 1. 源码 <template><div style"width: 100%; height: 100%" class"form-condition"><!-- 普通表单 --><el-card shadow"hover" class"cardheigh…...

程序员如何利用公网远程访问查询本地硬盘【内网穿透】
🎬 鸽芷咕:个人主页 🔥 个人专栏: 《高效编程技巧》《cpolar》 ⛺️生活的理想,就是为了理想的生活! 公网远程访问本地硬盘文件【内网穿透】 文章目录 公网远程访问本地硬盘文件【内网穿透】前言1. 下载cpolar和Everything软件1.…...

算法|Day42 动态规划10
LeetCode 121.买卖股票的最佳时机 题目链接:https://leetcode.cn/problems/best-time-to-buy-and-sell-stock/description/ 题目描述:给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。 你只能选择 某一天…...
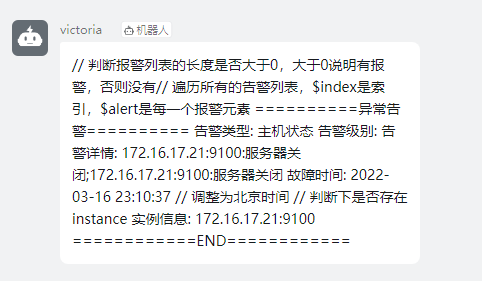
vmalert集成钉钉告警
vmalert通过在alert.rules中配置告警规则实现告警,告警规则语法与Prometheus兼容,依赖Alertmanager与prometheus-webhook-dingtalk实现钉钉告警,以下步骤: 1、构建vmalert 从源代码构建vmalert: git clone https://…...

深入解析 MyBatis 中的 <foreach> 标签:优雅处理批量操作与动态 SQL
在当今的Java应用程序开发中,数据库操作是一个不可或缺的部分。MyBatis作为一款颇受欢迎的持久层框架,为我们提供了一种优雅而高效的方式来管理数据库操作。在MyBatis的众多特性中,<foreach>标签无疑是一个强大的工具,它使得…...
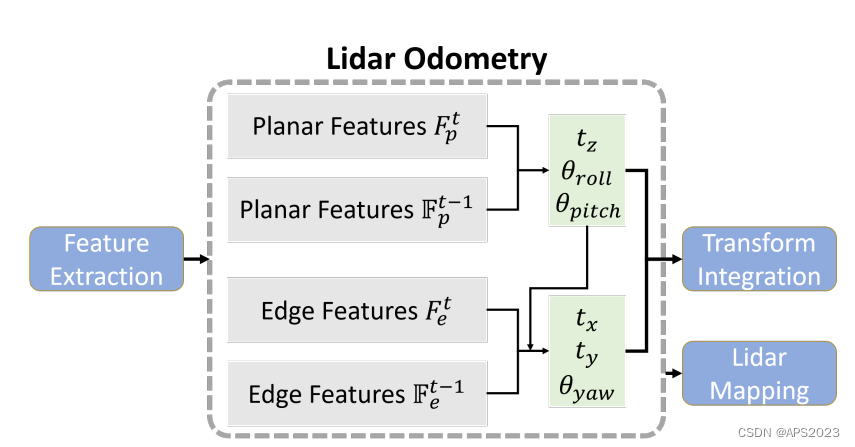
LeGO-Loam代码解析(二)--- Lego-LOAM的地面点分离、聚类、两步优化方法
1 地面点分离剔除方法 1.1 数学推导 LeGO-LOAM 中前端改进中很重要的一点就是充分利用了地面点,那首先自然是提取 对地面点的提取。 如上图,相邻的两个扫描线束的同一列打在地面上如 点所示,他们的垂直高度差 ,水平距离差 ,计算垂直高度差和水平高度差…...
程序员如何利用公网打造低成本轻量化的搜索和下载平台【内网穿透】
🎬 鸽芷咕:个人主页 🔥 个人专栏: 《高效编程技巧》《cpolar》 ⛺️生活的理想,就是为了理想的生活! 公网远程访问本地硬盘文件【内网穿透】 文章目录 公网远程访问本地硬盘文件【内网穿透】前言1. 下载cpolar和Everything软件1.…...
构建可远程访问的企业内部论坛
文章目录 前言1.cpolar、PHPStudy2.Discuz3.打开PHPStudy,安装网页论坛所需软件4.进行网页运行环境的构建5.运行Discuz网页程序6.使用cpolar建立穿透内网的数据隧道,发布到公网7.对云端保留的空白数据隧道进行配置8.Discuz论坛搭建完毕 前言 企业在发展…...
场:河南理工大学-C 旅游)
2023河南萌新联赛第(六)场:河南理工大学-C 旅游
2023河南萌新联赛第(六)场:河南理工大学 https://ac.nowcoder.com/acm/contest/63602/C 文章目录 2023河南萌新联赛第(六)场:河南理工大学题意解题思路代码 题意 小C喜欢旅游,现在他要去DSH旅…...
)
C语言 常用工具型API ----------strchr()
函数原型 char *strchr(const char *str, int c) 参数 str-- 要被检索的 C 字符串。 c-- 在 str 中要搜索的字符。 功能 在参数str所指向的字符串中搜索第一次出现字符c(一个无符号字符)的位置 头文件 #include <string.h> 返回值 返回一…...

建造者模式的理论与实现
本文实践代码仓库:https://github.com/goSilver/my_practice 文章目录 一、定义二、作用三、实现四、总结 一、定义 建造者模式是一种创建复杂对象的设计模式。它将一个复杂对象的构建过程分解为多个简单的步骤,并且允许按照特定的顺序来构建对象。通过…...

非计算机科班如何顺利转码进入计算机领域?
文章目录 如何规划才能实现转码?计算机岗位发展前景?现阶段转码 总结 🎉欢迎来到Java学习路线专栏~探索非计算机科班如何顺利转码进入计算机领域 ☆* o(≧▽≦)o *☆嗨~我是IT陈寒🍹✨博客主页:IT陈寒的博客dz…...
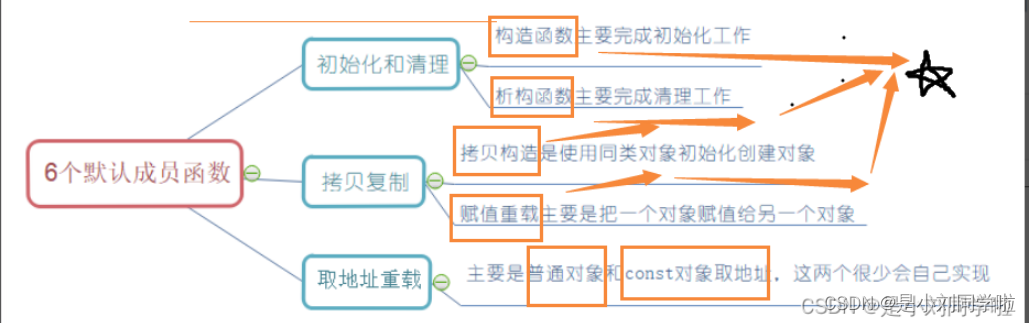
【C++类和对象】类有哪些默认成员函数呢?(下)
文章目录 一、类的6个默认成员函数二、日期类的实现2.1 运算符重载部分2.2 日期之间的运算2.3 整体代码1.Date.h部分2. Date.cpp部分 三. const成员函数四. 取地址及const取地址操作符重载扩展内容 总结 ヾ(๑╹◡╹)ノ" 人总要为过去的懒惰而付出代价ヾ(๑╹◡…...

springboot自定义banner的输出与源码解析
文章目录 一、介绍二、演示环境三、自定义banner1. 文本2. 图片3. placeholder占位符4. 关闭banner 四、源码分析1. 关闭banner2. banner模式3. banner打印器4. 打印banner① 获取banner② 打印banner 5. 版本号占位符的解析器6. 文本格式占位符的解析器7. 应用标题占位符的解析…...

LeetCode 141.环形链表
文章目录 💡题目分析💡解题思路🔔接口源码💡深度思考❓思考1❓思考2 题目链接👉 LeetCode 141.环形链表👈 💡题目分析 给你一个链表的头节点 head ,判断链表中是否有环。 如果链表中…...

Webots碰撞检测实战:如何用boundingObject快速给自制3D模型添加物理属性
Webots碰撞检测实战:如何用boundingObject快速给自制3D模型添加物理属性 当你把精心设计的机械臂模型导入Webots时,是否遇到过这样的尴尬:模型看起来完美无缺,却像幽灵一样穿透其他物体?这背后缺失的正是物理引擎最看重…...

从面试官视角看:2026年,什么样的前端项目经历能让你脱颖而出?
2026年前端面试突围指南:如何用项目经验打造技术叙事力 1. 从执行者到思考者:项目复盘的价值重构 在2026年的前端技术面试中,面试官最反感的莫过于候选人机械罗列技术栈而缺乏深度思考。我曾作为面试官遇到过一位候选人,当被问及&…...

3步实现百度网盘Mac版免费高速下载:告别龟速的终极指南
3步实现百度网盘Mac版免费高速下载:告别龟速的终极指南 【免费下载链接】BaiduNetdiskPlugin-macOS For macOS.百度网盘 破解SVIP、下载速度限制~ 项目地址: https://gitcode.com/gh_mirrors/ba/BaiduNetdiskPlugin-macOS 还在为百度网盘Mac版的下载速度发愁…...

手把手教你玩转RT-Thread SPI多设备管理:从总线抢占、片选控制到配置切换
RT-Thread SPI多设备管理实战:总线抢占、片选控制与动态配置切换 在嵌入式开发中,SPI总线因其高速、全双工的特性被广泛应用于传感器、存储芯片等外设连接。但当单个SPI总线上挂载多个从设备时,开发者常面临总线冲突、配置混乱等挑战。本文将…...

04-07-05 逻辑顺序的应用 - 学习笔记
04-07-05 逻辑顺序的应用 - 学习笔记 章节信息 核心主题:时间顺序、结构顺序、重要性顺序、如何选择合适的逻辑顺序 学习目标:掌握三种基本逻辑顺序,能够为任何内容选择最合适的排序方式 关键要点:三种顺序各有适用场景、排序影响理解、一致性原则核心概念 1. 为什么逻辑顺序很…...

智能合约开发革命:solmate 完整指南 - 现代、高效且节省 gas 的构建模块
智能合约开发革命:solmate 完整指南 - 现代、高效且节省 gas 的构建模块 【免费下载链接】solmate Modern, opinionated, and gas optimized building blocks for smart contract development. 项目地址: https://gitcode.com/gh_mirrors/so/solmate solmate…...

终极暗黑破坏神2存档编辑器:5步轻松定制你的游戏角色
终极暗黑破坏神2存档编辑器:5步轻松定制你的游戏角色 【免费下载链接】d2s-editor 项目地址: https://gitcode.com/gh_mirrors/d2/d2s-editor 你是否曾经在暗黑破坏神2中花费数小时刷装备却一无所获?是否想要尝试不同的角色build却不想重新练级&…...

Agent 记忆系统设计:短期、长期到知识图谱
一句话定义 Agent 记忆系统 让 AI 像人一样,把「刚刚发生的」「学过的」「长期积累的」分层管理。 类比:人类的记忆分三层——工作记忆(当前对话的上下文,几分钟内)、情节记忆(某件具体的事,…...
)
8卡海光Z100L服务器实战:手把手教你用vLLM部署32B大模型(附完整镜像与配置)
8卡海光Z100L服务器实战:从零部署Qwen2.5-32B大模型全流程指南 国产化算力平台正在成为AI基础设施的新选择。海光Z100L作为国产高性能计算卡的代表,其8卡服务器的配置足以承载32B参数规模的大模型推理。本文将完整呈现从硬件验收到模型服务的全链路操作&…...

前端工程化进阶:从开发到部署的全流程优化
前端工程化进阶:从开发到部署的全流程优化 一、引言:别再把前端工程化当配置活儿 "前端工程化不就是配置一下webpack吗?"——我相信这是很多前端开发者常说的话。 但事实是: 好的工程化可以提升开发效率50%以上规范的工…...