NLP文本匹配任务Text Matching [无监督训练]:SimCSE、ESimCSE、DiffCSE 项目实践
NLP文本匹配任务Text Matching [无监督训练]:SimCSE、ESimCSE、DiffCSE 项目实践
文本匹配多用于计算两个文本之间的相似度,该示例会基于 ESimCSE 实现一个无监督的文本匹配模型的训练流程。文本匹配多用于计算两段「自然文本」之间的「相似度」。
例如,在搜索引擎中,我们通常需要判断用户的搜索内容是否相似:
A:蛋黄吃多了有什么坏处 B:吃鸡蛋白过多有什么坏处 -> 不相似
A:蛋黄吃多了有什么坏处 B:蛋黄可以多吃吗 -> 相似
...那最直觉的思路就是让人工去标注文本对,再喂给模型去学习,这种方法称为基于「监督学习」训练出的模型:
但是,如果我们今天没有这么多的标注数据,只有一大堆的「未标注」数据,我们还能训练一个匹配模型吗?这种不依赖于「人工标注数据」的方式,就叫做「无监督」(或自监督)学习方式。我们今天要讲的 SimCSE, 就是一种「无监督」训练模型。
SimCSE: Simple Contrastive Learning of Sentence Embeddings
1.SimCSE 是如何做到无监督的?
SimCSE 将对比学习(Contrastive Learning)的思想引入到文本匹配中。对比学习的核心思想就是:将相似的样本拉近,将不相似的样本推远。
但现在问题是:我们没有标注数据,怎么知道哪些文本是相似的,哪些是不相似的呢?SimCSE 相出了一种很妙的办法,由于预训练模型在训练的时候通常都会使用 dropout 机制。这就意味着:即使是同一个样本过两次模型也会得到两个不同的 embedding。而因为同样的样本,那一定是相似的,模型输出的这两个 embedding 距离就应当尽可能的相近;反之,那些不同的输入样本过模型后得到的 embedding 就应当尽可能的被推远。
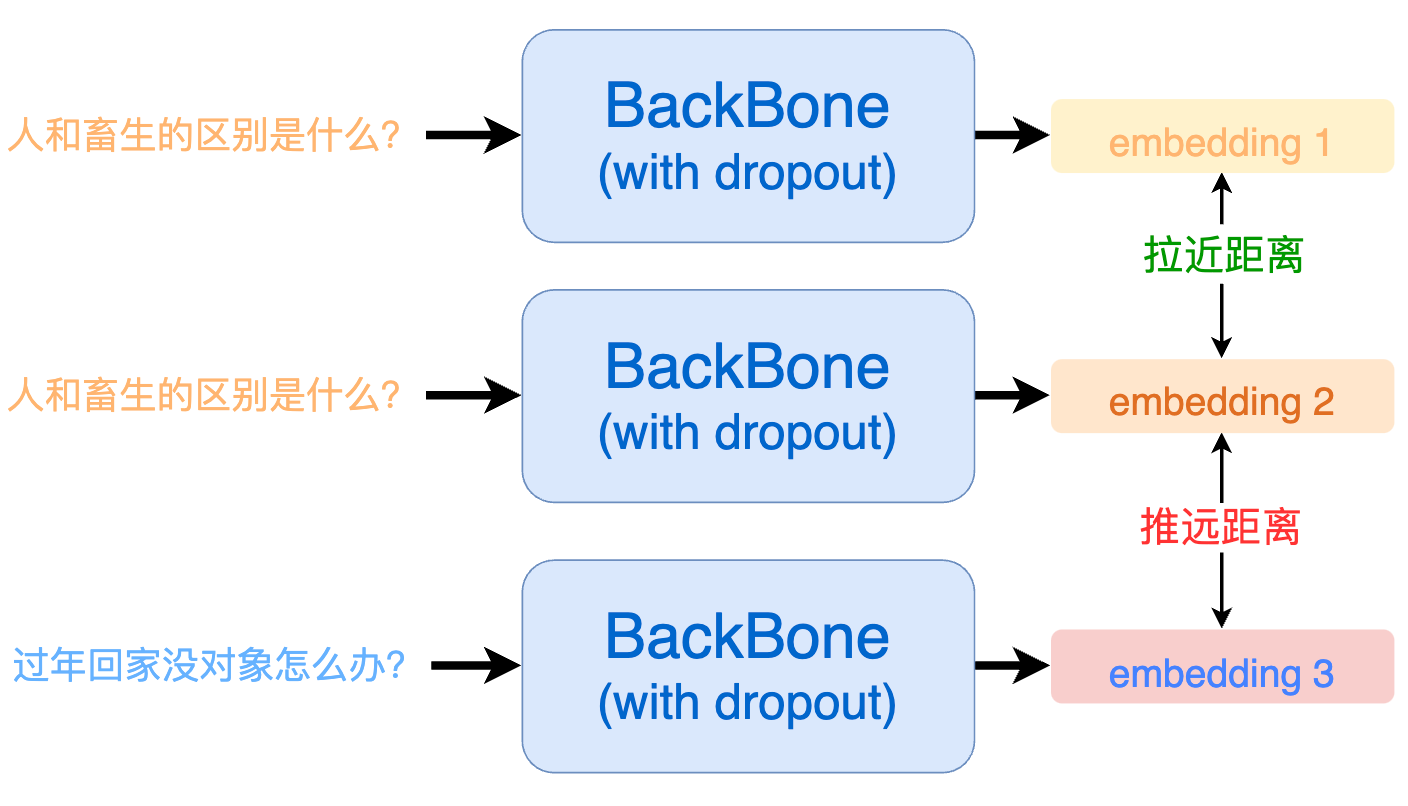
具体来讲,一个 batch 内每个句子会过 2 次模型,得到 2 * batch 个向量,将这些句子中通过同样句子得到的向量设置为正例,其他设置为负例。
假设 a1 和 a2 是由句子 a 过两次模型得到的结果,那么一个 batch 内的正负例构建如下所示:
| a1 | a2 | b1 | b2 | c1 | c2 | |
|---|---|---|---|---|---|---|
| a1 | -100 | 1 | 0 | 0 | 0 | 0 |
| a2 | 1 | -100 | 0 | 0 | 0 | 0 |
| b1 | 0 | 0 | -100 | 1 | 0 | 0 |
| b2 | 0 | 0 | 1 | -100 | 0 | 0 |
| c1 | 0 | 0 | 0 | 0 | -100 | 1 |
| c2 | 0 | 0 | 0 | 0 | 1 | -100 |
其中,对角线上的 - 100 表示自身和自身不做相似度比较。
2. SimCSE 的缺点?
从 SimCSE 的正例构建中我们可以看出来,所有的正例都是由「同一个句子」过了两次模型得到的。这就会造成一个问题:模型会更倾向于认为,长度相同的句子就代表一样的意思。由于数据样本是随机选取的,那么很有可能在一个 batch 内采样到的句子长度是不相同的。
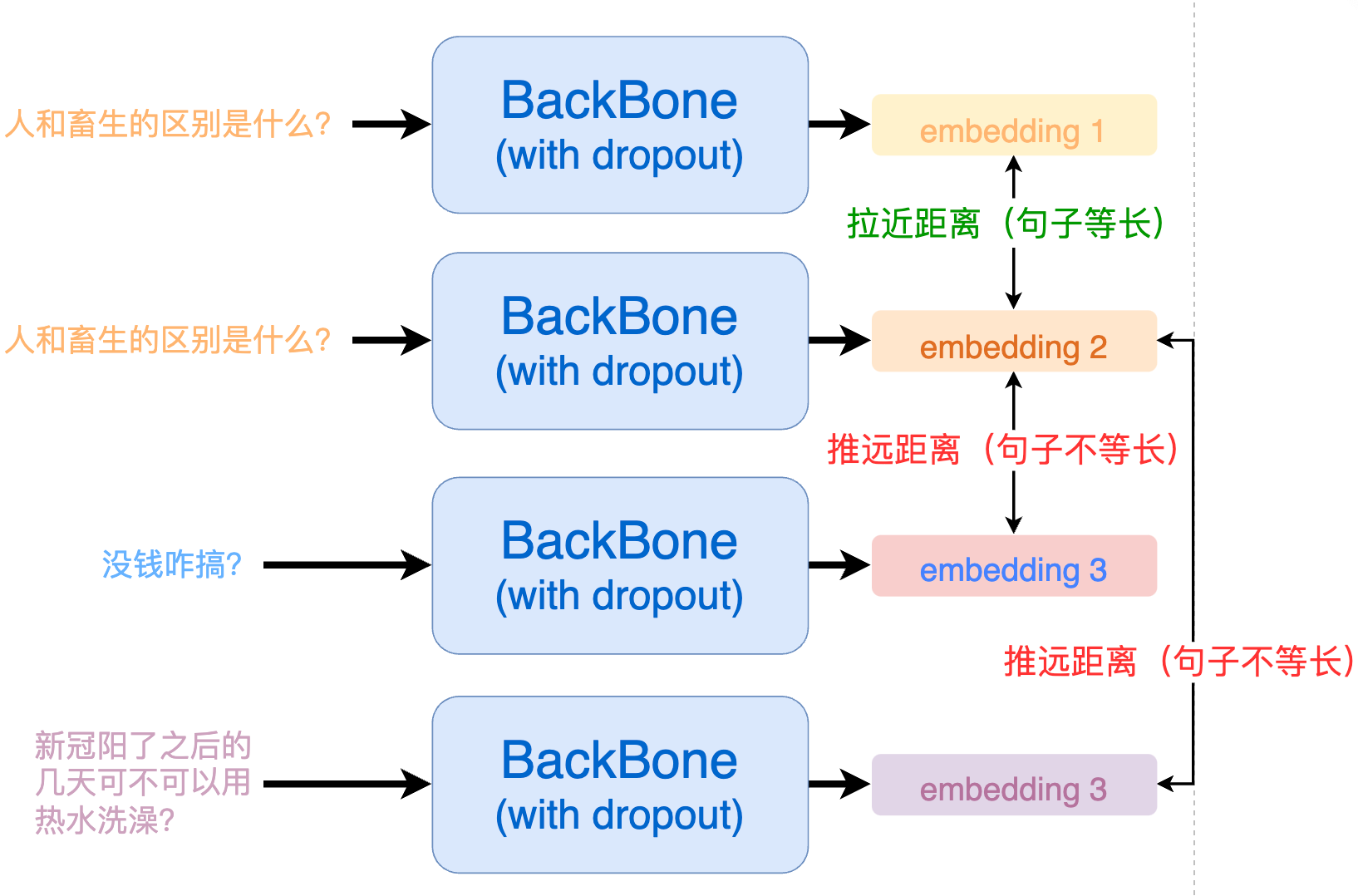
为了解决这个问题,我们最终采取的实现方式为 ESimCSE。
3. ESimCSE 解决模型对文本长度的敏感问题
ESimCSE 通过随机重复单词(Word Repetition)的方式来构建正例,巧妙的解决了句子长度敏感性的问题:
ESimCSE: Enhanced Sample Building Method for Contrastive Learning of Unsupervised Sentence Embedding
要想消除模型对句子长度的敏感,我们就需要在构建正例的时候让输入句子的长度发生改变,如下所示:
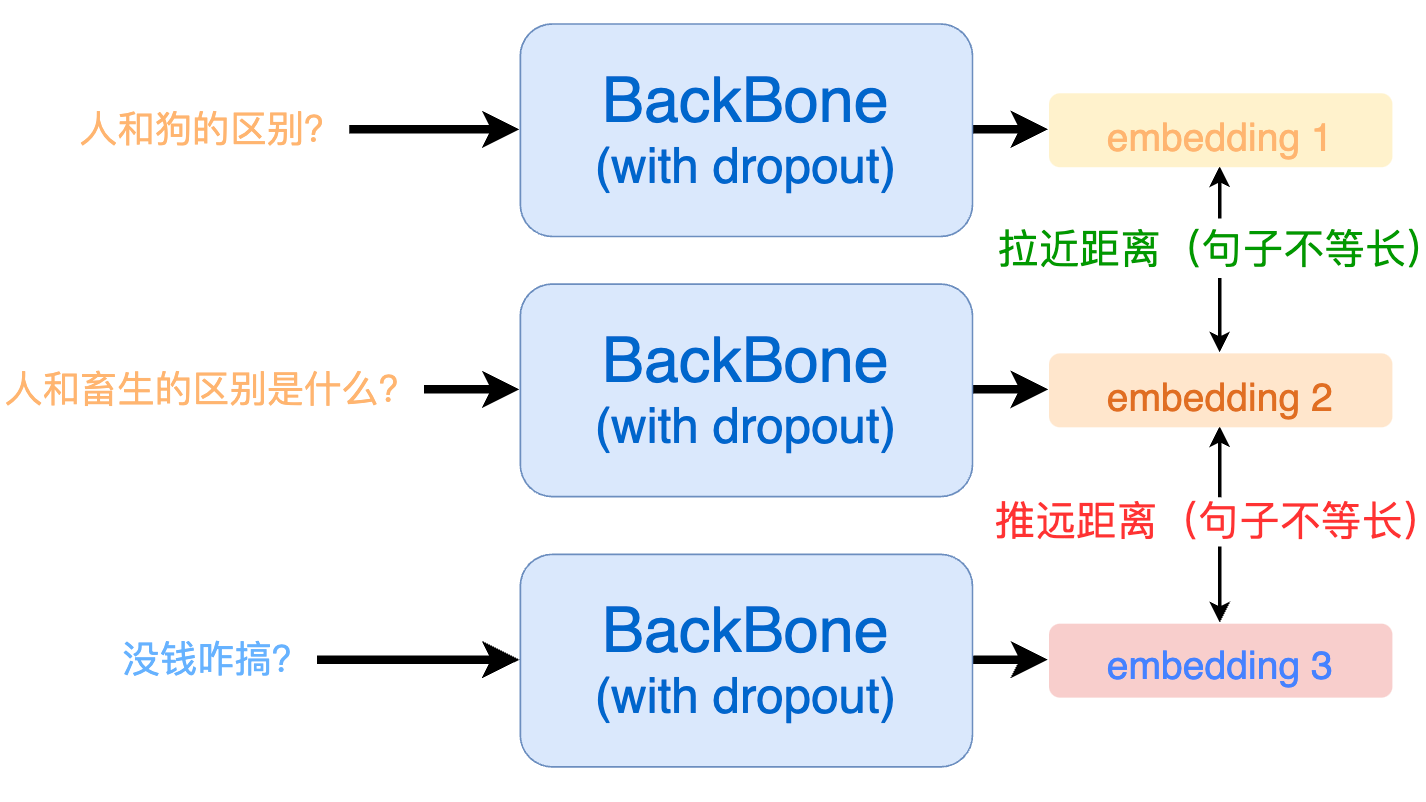
那么,改变句子长度通常有 3 种方法:随机删除、随机添加、同义词替换,但它们均存在句意变化的风险:
| 方法 | 原句子 | 变换后的句子 | 句意是否改变 |
|---|---|---|---|
| 随机删除 | 我 [不] 喜欢你 | 我喜欢你 | 是 |
| 随机添加 | 今天的饭好吃 | 今天的饭 [不] 好吃 | 是 |
| 同义词替换 | 小明长得像一只 [狼] | 小明长得像一只 [狗] | 是 |
用语义变换后的句子去构建正例,模型效果自然会受到影响。
那如果我们随机重复一些单词呢?
| 方法 | 原句子 | 变换后的句子 | 句意是否改变 |
|---|---|---|---|
| 随机重复单词 | 今天天气很好 | 今今天天气很好好 | 否 |
| 随机重复单词 | 我喜欢你 | 我我喜欢欢你 | 否 |
可以看到,通过随机重复单词,既能够改变句子长度,又不会轻易改变语义。
实现上,假设我们有一个 batch 的句子,我们先依次将每一个句子都进行随机单词重复(产生正例),如下:
origin -> ['人和畜生的区别', '今天天气很好', '三星手机屏幕是不是最好的?']
repetition -> ['人人和畜生的的区别', '今今天天气很好好', '三星星手机屏屏幕是不是最最好好的?']随后,我们将 origin 的 embedding(batch,768) 和 repetition 的 embedding(batch,768)做矩阵乘法,可以得到一个矩阵(batch,batch),矩阵对角线上就是正例,其余的均是负例:
| 句子 a | 句子 b | 句子 c | |
|---|---|---|---|
| 句子 a | 0.9248 | 0.2342 | 0.4242 |
| 句子 b | 0.3142 | 0.9123 | 0.1422 |
| 句子 c | 0.2903 | 0.1857 | 0.9983 |
矩阵中第(i,j)个元素代表 origin 列表中的第 i 个元素和 repetition 列表中第 j 个元素的相似度。
接下来就好构建训练标签了,因为 label 都在对角线上,所以第 n 行的 label 就是 n 。
labels = [i for i in range(len(origin))] # labels = [0, 1, 2]之后就用 CrossEntropyLoss 去计算并梯度回传就能开始训练啦。
def forward(self,query_input_ids: torch.tensor,query_token_type_ids: torch.tensor,doc_input_ids: torch.tensor,doc_token_type_ids: torch.tensor,device='cpu') -> torch.tensor:"""传入query/doc对,构建正/负例并计算contrastive loss。Args:query_input_ids (torch.LongTensor): (batch, seq_len)query_token_type_ids (torch.LongTensor): (batch, seq_len)doc_input_ids (torch.LongTensor): (batch, seq_len)doc_token_type_ids (torch.LongTensor): (batch, seq_len)device (str): 使用设备Returns:torch.tensor: (1)"""query_embedding = self.get_pooled_embedding(input_ids=query_input_ids,token_type_ids=query_token_type_ids) # (batch, self.output_embedding_dim)doc_embedding = self.get_pooled_embedding(input_ids=doc_input_ids,token_type_ids=doc_token_type_ids) # (batch, self.output_embedding_dim)cos_sim = torch.matmul(query_embedding, doc_embedding.T) # (batch, batch)margin_diag = torch.diag(torch.full( # (batch, batch), 只有对角线等于margin值的对角矩阵size=[query_embedding.size()[0]], fill_value=self.margin)).to(device)cos_sim = cos_sim - margin_diag # 主对角线(正例)的余弦相似度都减掉 margincos_sim *= self.scale # 缩放相似度,便于收敛labels = torch.arange( # 只有对角上为正例,其余全是负例,所以这个batch样本标签为 -> [0, 1, 2, ...]0, query_embedding.size()[0], dtype=torch.int64).to(device)loss = self.criterion(cos_sim, labels)return loss4.DiffCSE
结合句子间差异的无监督句子嵌入对比学习方法——DiffCSE主要还是在SimCSE上进行优化(可见SimCSE的重要性),通过ELECTRA模型的生成伪造样本和RTD(Replaced Token Detection)任务,来学习原始句子与伪造句子之间的差异,以提高句向量表征模型的效果。
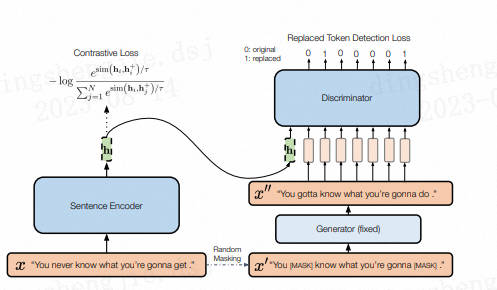
其思想同样来自于CV领域(采用不变对比学习和可变对比学习相结合的方法可以提高图像表征的效果)。作者提出使用基于dropout masks机制的增强作为不敏感转换学习对比学习损失和基于MLM语言模型进行词语替换的方法作为敏感转换学习「原始句子与编辑句子」之间的差异,共同优化句向量表征。
在SimCSE模型中,采用pooler层(一个带有tanh激活函数的全连接层)作为句子向量输出。该论文发现,采用带有BN的两层pooler效果更为突出,BN在SimCSE模型上依然有效。
①对于掩码概率,经实验发现,在掩码概率为30%时,模型效果最优。
②针对两个损失之间的权重值,经实验发现,对比学习损失为RTD损失200倍时,模型效果最优。
参考链接:https://blog.csdn.net/PX2012007/article/details/127696477
5. 数据集准备
项目中提供了一部分示例数据,我们使用未标注的用户搜索记录数据来训练一个文本匹配模型,数据在 data/LCQMC 。
若想使用自定义数据训练,只需要仿照示例数据构建数据集即可:
- 训练集:
喜欢打篮球的男生喜欢什么样的女生
我手机丢了,我想换个手机
大家觉得她好看吗
晚上睡觉带着耳机听音乐有什么害处吗?
学日语软件手机上的
...
- 测试集:
开初婚未育证明怎么弄? 初婚未育情况证明怎么开? 1
谁知道她是网络美女吗? 爱情这杯酒谁喝都会醉是什么歌 0
人和畜生的区别是什么? 人与畜生的区别是什么! 1
男孩喝女孩的尿的故事 怎样才知道是生男孩还是女孩 0
...
由于是无监督训练,因此训练集(train.txt)中不需要记录标签,只需要大量的文本即可。
测试集(dev.tsv)用于测试无监督模型的效果,因此需要包含真实标签。
每一行用 \t 分隔符分开,第一部分部分为句子A,中间部分为句子B,最后一部分为两个句子是否相似(label)。
6.模型训练
修改训练脚本 train.sh 里的对应参数, 开启模型训练:
python train.py \--model "nghuyong/ernie-3.0-base-zh" \--train_path "data/LCQMC/train.txt" \--dev_path "data/LCQMC/dev.tsv" \--save_dir "checkpoints/LCQMC" \--img_log_dir "logs/LCQMC" \--img_log_name "ERNIE-ESimCSE" \--learning_rate 1e-5 \--dropout 0.3 \--batch_size 64 \--max_seq_len 64 \--valid_steps 400 \--logging_steps 50 \--num_train_epochs 8 \--device "cuda:0"
正确开启训练后,终端会打印以下信息:
...
0%| | 0/2 [00:00<?, ?it/s]
100%|██████████| 2/2 [00:00<00:00, 226.41it/s]
DatasetDict({train: Dataset({features: ['text'],num_rows: 477532})dev: Dataset({features: ['text'],num_rows: 8802})
})
global step 50, epoch: 1, loss: 0.34367, speed: 2.01 step/s
global step 100, epoch: 1, loss: 0.19121, speed: 2.02 step/s
global step 150, epoch: 1, loss: 0.13498, speed: 2.00 step/s
global step 200, epoch: 1, loss: 0.10696, speed: 1.99 step/s
global step 250, epoch: 1, loss: 0.08858, speed: 2.02 step/s
global step 300, epoch: 1, loss: 0.07613, speed: 2.02 step/s
global step 350, epoch: 1, loss: 0.06673, speed: 2.01 step/s
global step 400, epoch: 1, loss: 0.05954, speed: 1.99 step/s
Evaluation precision: 0.58459, recall: 0.87210, F1: 0.69997, spearman_corr:
0.36698
best F1 performence has been updated: 0.00000 --> 0.69997
global step 450, epoch: 1, loss: 0.25825, speed: 2.01 step/s
global step 500, epoch: 1, loss: 0.27889, speed: 1.99 step/s
global step 550, epoch: 1, loss: 0.28029, speed: 1.98 step/s
global step 600, epoch: 1, loss: 0.27571, speed: 1.98 step/s
global step 650, epoch: 1, loss: 0.26931, speed: 2.00 step/s
...
在 logs/LCQMC 文件下将会保存训练曲线图:
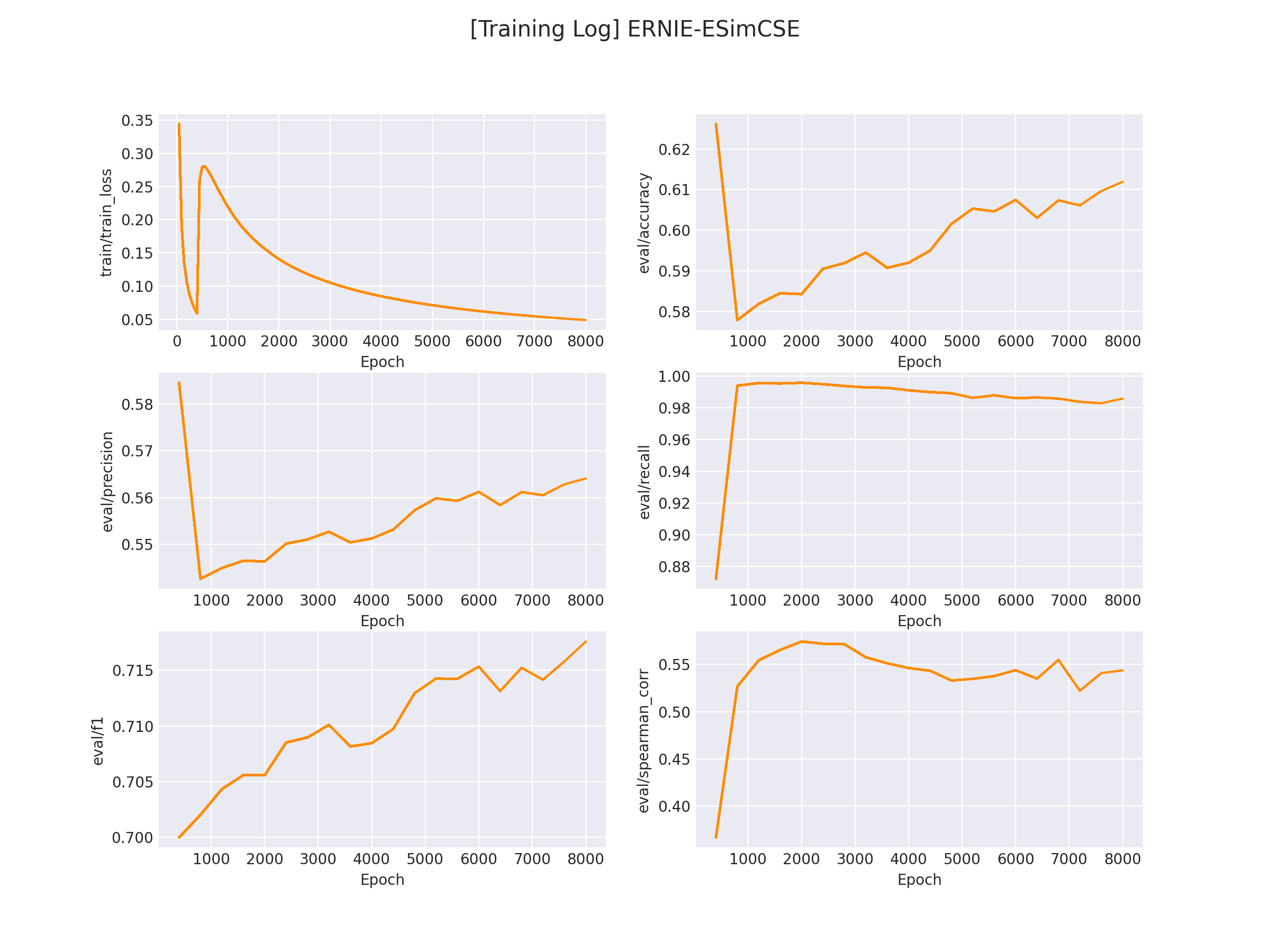
7.模型推理
完成模型训练后,运行 inference.py 以加载训练好的模型并应用:
...if __name__ == '__main__':...sentence_pair = [('男孩喝女孩的故事', '怎样才知道是生男孩还是女孩'),('这种图片是用什么软件制作的?', '这种图片制作是用什么软件呢?')]...res = inference(query_list, doc_list, model, tokenizer, device)print(res)
运行推理程序:
python inference.py
得到以下推理结果:
[0.1527191698551178, 0.9263839721679688] # 第一对文本相似分数较低,第二对文本相似分数较高
参考链接:https://github.com/HarderThenHarder/transformers_tasks/blob/main/text_matching/supervised
github无法连接的可以在:https://download.csdn.net/download/sinat_39620217/88214437 下载
更多优质内容请关注公号:汀丶人工智能;会提供一些相关的资源和优质文章,免费获取阅读。
相关文章:
NLP文本匹配任务Text Matching [无监督训练]:SimCSE、ESimCSE、DiffCSE 项目实践
NLP文本匹配任务Text Matching [无监督训练]:SimCSE、ESimCSE、DiffCSE 项目实践 文本匹配多用于计算两个文本之间的相似度,该示例会基于 ESimCSE 实现一个无监督的文本匹配模型的训练流程。文本匹配多用于计算两段「自然文本」之间的「相似度」。 例如…...

复习vue3,简简单单记录
这里的知识是结合视频以及其他文章一起学习,仅用于个人复习记录 ref 和reactive ref 用于基本类型 reactive 用于引用类型 如果使用ref 传递对象,修改值时候需要写为obj.value.attr 方式修改属性值 如果使用reactive 处理对象,直接obj.att…...
【自用】云服务器 docker 环境下 HomeAssistant 安装 HACS 教程
一、进入 docker 中的 HomeAssistant 1.查找 HomeAssistant 的 CONTAINER ID 连接上云服务器(宿主机)后,终端内进入 root ,输入: docker ps找到了 docker 的 container ID 2.config HomeAssistant 输入下面的命令&…...

使用dockerfile手动构建JDK11镜像运行容器并校验
Docker官方维护镜像的公共仓库网站 Docker Hub 国内无法访问了,大部分镜像无法下载,准备逐步构建自己的镜像库。【转载aliyun官方-容器镜像服务 ACR】Docker常见问题 阿里云容器镜像服务ACR(Alibaba Cloud Container Registry)是面…...

编程语言学习笔记-架构师和工程师的区别,PHP架构师之路
🏆作者简介,黑夜开发者,全栈领域新星创作者✌,CSDN博客专家,阿里云社区专家博主,2023年6月CSDN上海赛道top4。 🏆数年电商行业从业经验,历任核心研发工程师,项目技术负责…...

Streamlit 讲解专栏(十):数据可视化-图表绘制详解(上)
文章目录 1 前言2 st.line_chart:绘制线状图3 st.area_chart:绘制面积图4 st.bar_chart:绘制柱状图5 st.pyplot:绘制自定义图表6 结语 1 前言 在数据可视化的世界中,绘制清晰、易于理解的图表是非常关键的。Streamlit…...
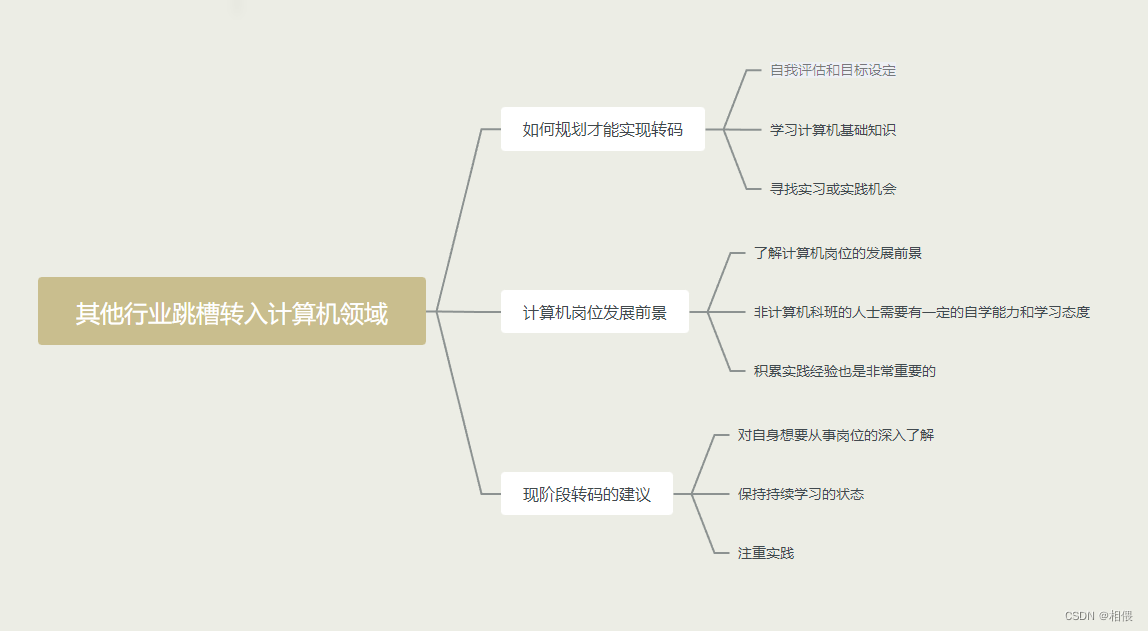
其他行业跳槽转入计算机领域简单看法
其他行业跳槽转入计算机领域简单看法 本人选择从以下几个方向谈谈自己的想法和观点。 先看一下总体图,下面会详细分析 如何规划才能实现转码 自我评估和目标设定:首先,你需要评估自己的技能和兴趣,确定你希望在计算机领域从事…...

Unity制作一个简单的登入注册页面
1.创建Canvas组件 首先我们创建一个Canvas画布,我们再在Canvas画布底下创建一个空物体,取名为Resgister。把空物体的锚点设置为全屏撑开。 2.我们在Resgister空物体底下创建一个Image组件,改名为bg。我们也把它 的锚点设置为全屏撑开状态。接…...

常用游戏运营指标DAU、LTV及参考范围
文章目录 前言运营指标指标范围参考值留存指标的意义总结 前言 作为游戏人免不了听到 DAU 、UP值、留存 等名词,并且有些名词听起来还很像,特别是一款上线的游戏,这些游戏运营指标是衡量游戏业务绩效和用户参与度的重要数据,想做…...

标准模板库STL——deque和list
deque概述 deque属于顺序容器,称为双端队列容器 底层数据结构是动态二维数组,从整体上看,deque的内存不连续 初始数组第一维数量为2,必要时进行2倍扩容 每次第一维扩容后,原来数组第二维元素从新数组下标为OldSize/2的…...
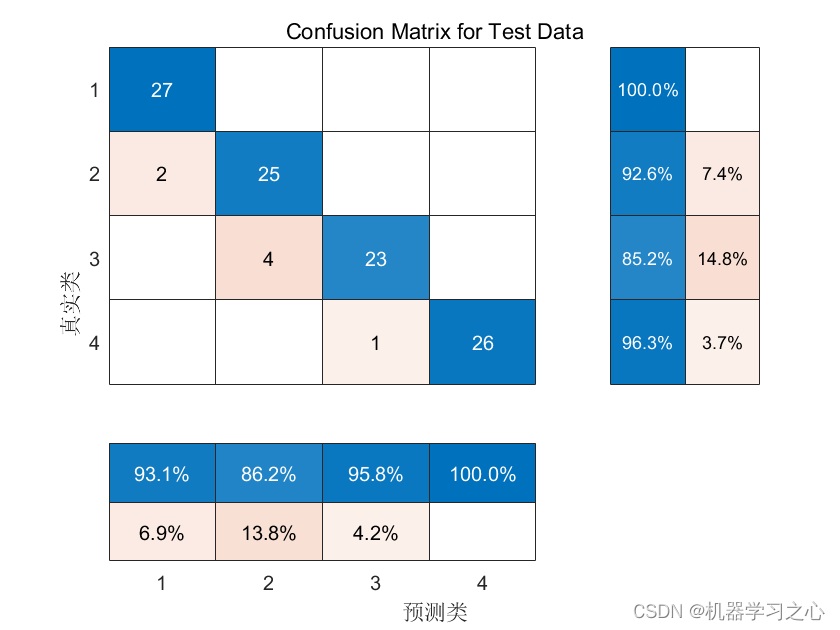
分类预测 | MATLAB实现WOA-CNN-BiGRU-Attention数据分类预测
分类预测 | MATLAB实现WOA-CNN-BiGRU-Attention数据分类预测 目录 分类预测 | MATLAB实现WOA-CNN-BiGRU-Attention数据分类预测分类效果基本描述模型描述程序设计参考资料 分类效果 基本描述 1.Matlab实现WOA-CNN-BiGRU-Attention多特征分类预测,多特征输入模型&…...
 第十章 类与对象)
C++ Primer Plus 第6版 读书笔记(10) 第十章 类与对象
第十章 类与对象 在面向对象编程中,类和对象是两个重要的概念。 类(Class)是一种用户自定义的数据类型,用于封装数据和操作。它是对象的模板或蓝图,描述了对象的属性(成员变量)和行为…...

基于C++ 的OpenCV绘制多边形,多边形多条边用不用的颜色绘制
使用基于C的OpenCV库来绘制多边形,并且为多边形的不同边使用不同的颜色,可以按照以下步骤进行操作: 首先,确保你已经安装了OpenCV库并配置好了你的开发环境。 导入必要的头文件: #include <opencv2/opencv.hpp&g…...

(六)、深度学习框架中的算子
1、深度学习框架算子的基本概念 深度学习框架中的算子(operator)是指用于执行各种数学运算和操作的函数或类。这些算子通常被用来构建神经网络的各个层和组件,实现数据的传递、转换和计算。 算子是深度学习模型的基本组成单元,它们…...

Redis实现共享Session
Redis实现共享Session 分布式系统中,sessiong共享有很多的解决方案,其中托管到缓存中应该是最常用的方案之一。 1、引入依赖 <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM…...

网络通信原理UDP协议(第五十课)
UDP协议:用户数据包协议,无连接、不可靠,效率高 字段长度描述Source Port2字节标识哪个应用程序发送(发送进程)。Destination Port2字节标识哪个应用程序接收(接收进程)。Length2字节UDP首部加上UDP数据的字节数,最小为8。Checksum2字节覆盖UDP首部和UDP数据,是可…...
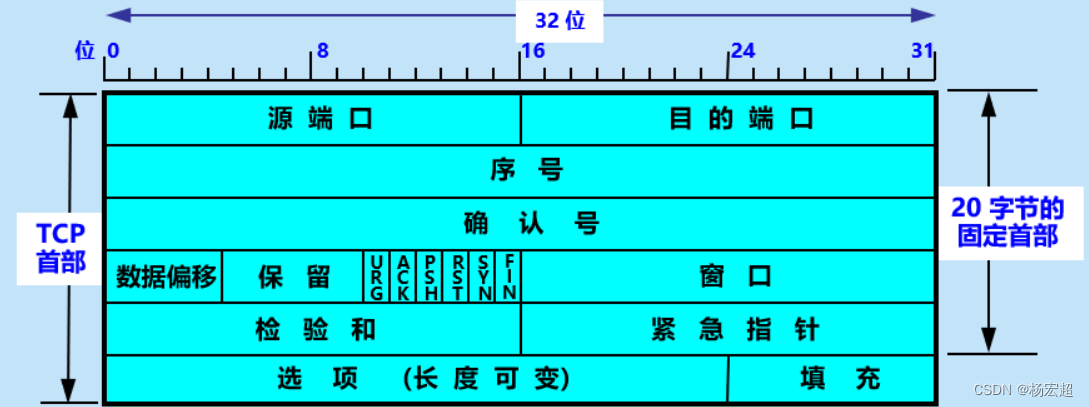
43、TCP报文(一)
本节内容开始,我们正式学习TCP协议中具体的一些原理。首先,最重要的内容仍然是这个协议的封装结构和首部格式,因为这里面牵扯到一些环环相扣的知识点,例如ACK、SYN等等,如果这些内容不能很好的理解,那么后续…...
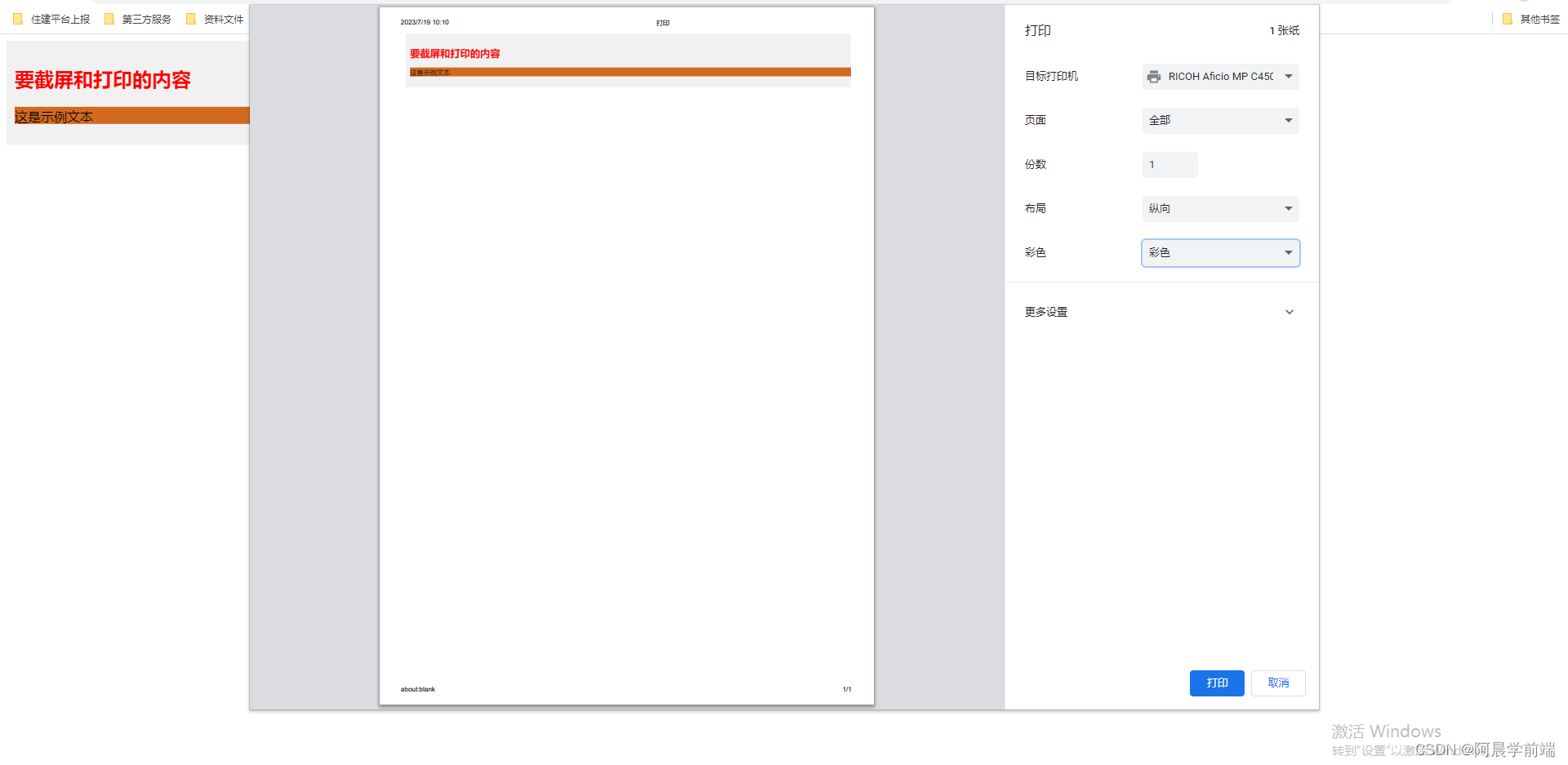
【JavaScript】使用js实现滑块验证码功能与浏览器打印
滑块验证码 效果图: 实现思路: 根据滑块的最左侧点跟最右侧点, 是否在规定的距离内【页面最左侧为原点】,来判断是否通过 html代码: <!DOCTYPE html> <html><head><title>滑动图片验证码&…...
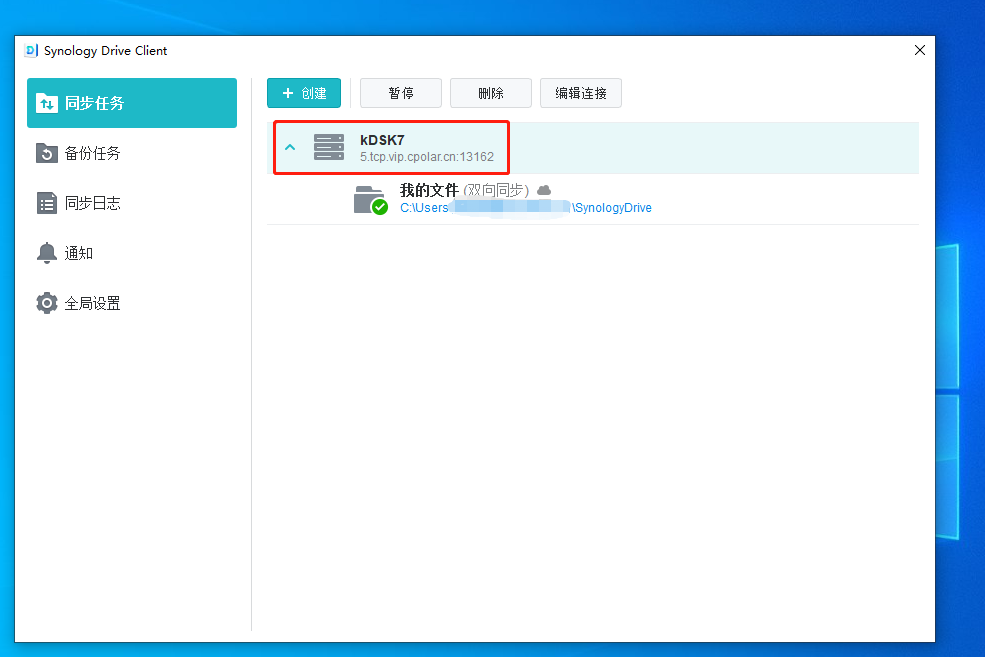
【使用群晖远程链接drive挂载电脑硬盘】
文章目录 前言1.群晖Synology Drive套件的安装1.1 安装Synology Drive套件1.2 设置Synology Drive套件1.3 局域网内电脑测试和使用 2.使用cpolar远程访问内网Synology Drive2.1 Cpolar云端设置2.2 Cpolar本地设置2.3 测试和使用 3. 结语 前言 群晖作为专业的数据存储中心&…...
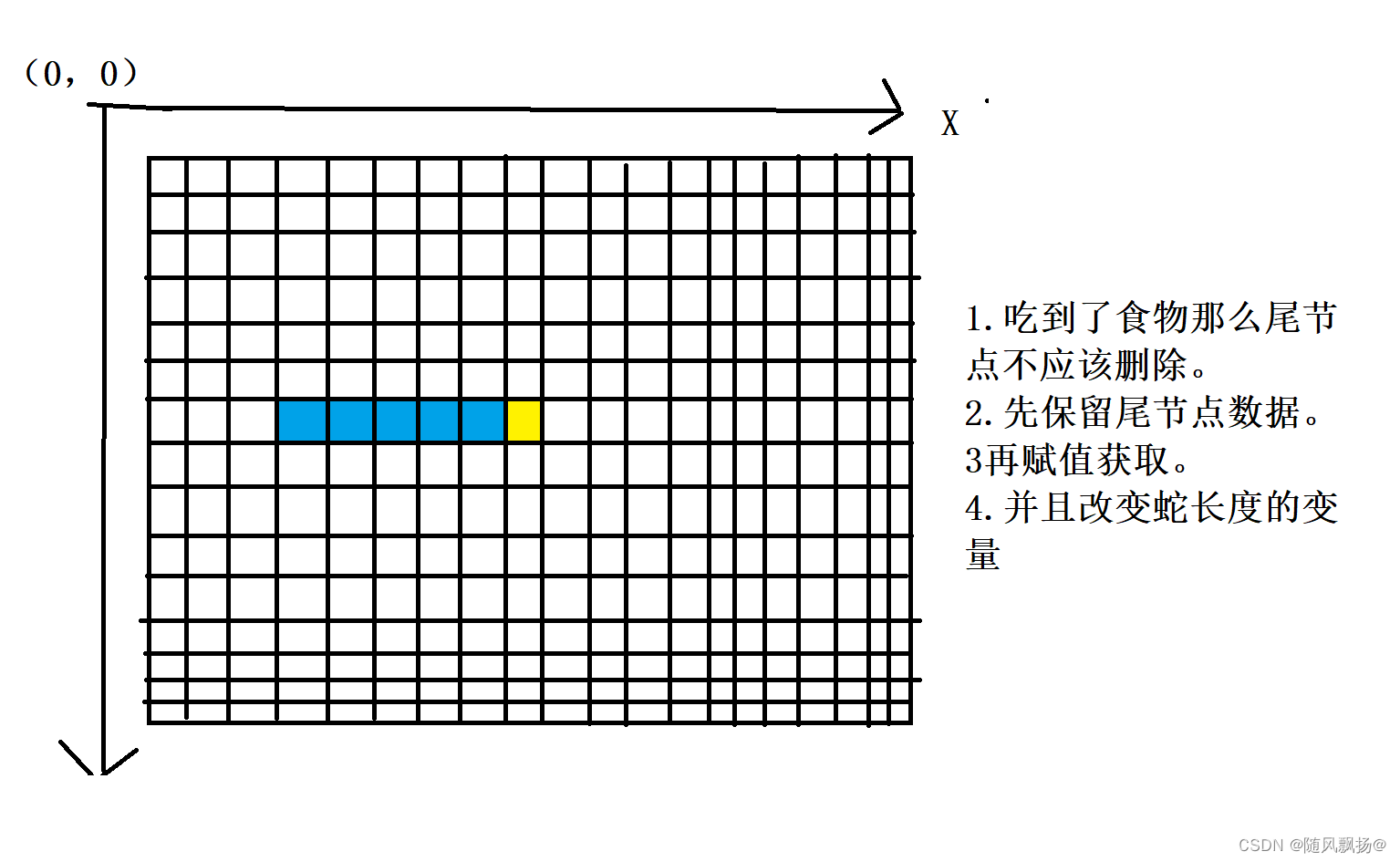
easyx图形库基础4:贪吃蛇
贪吃蛇 一实现贪吃蛇:1.绘制网格:1.绘制蛇:3.控制蛇的默认移动向右:4.控制蛇的移动方向:5.生成食物6.判断蛇吃到食物并且长大。7.判断游戏结束:8.重置函数: 二整体代码: 一实现贪吃蛇…...
)
别再乱用`define了!SV宏定义实战避坑指南(从`ifdef到字符串拼接)
别再乱用define了!SV宏定义实战避坑指南(从ifdef到字符串拼接) 在SystemVerilog开发中,宏定义(define)是提高代码复用性和灵活性的利器,但同时也是隐藏最深的"代码地雷"之一。许多开发…...

Windows构建工具终极指南:一键解决Node.js原生模块编译难题
Windows构建工具终极指南:一键解决Node.js原生模块编译难题 【免费下载链接】windows-build-tools :package: Install C Build Tools for Windows using npm 项目地址: https://gitcode.com/gh_mirrors/wi/windows-build-tools Windows-build-tools是一个专业…...

企业级应用如何利用多模型聚合能力优化AI功能
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业级应用如何利用多模型聚合能力优化AI功能 在开发复杂的企业应用,如客户关系管理(CRM)或企业…...

单元幕墙组装检验标准
单元幕墙组装检验标准 1 范围 本标准规定了沈阳远大企业集团单元幕墙组装的检验项目、检验方法、检验工具、质量评定方法。 本标准适用于单元幕墙板块的组装检验。 2 规范性引用文件 下列文件中的条款通过本标准的引用而成为本标准的条款,凡是注日期的引用文件,其随后所…...

从零到一:RK3588s平台imx415双目相机模组点亮与ISP调优实战
1. 环境准备:从零搭建开发环境 第一次接触RK3588s平台时,最头疼的就是环境搭建。我用的Firefly AIO-3588S-JD4开发板配套资料比较分散,光是找齐所有软件包就花了半天时间。这里分享下我的踩坑经验: 硬件清单必须严格核对&#x…...

Python自动化签到脚本dailycheckin:Docker部署与模块化设计详解
1. 项目概述与核心价值最近在折腾一些自动化工具,发现一个挺有意思的项目,叫Sitoi/dailycheckin。简单来说,这是一个用 Python 写的签到脚本集合,能帮你自动完成各种网站和应用的日常签到任务。你可能觉得签到不就是点一下吗&…...

为Hermes Agent配置自定义Provider指向Taotoken聚合服务的操作方法
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为Hermes Agent配置自定义Provider指向Taotoken聚合服务的操作方法 Hermes Agent 是一个功能强大的AI代理框架,它支持通…...

长期使用Taotoken的Token Plan套餐带来的月度成本变化观察
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Taotoken的Token Plan套餐带来的月度成本变化观察 对于需要持续调用大模型API的开发者或团队而言,成本的可预测…...

联想M920x黑苹果EFI配置终极指南:轻松实现macOS完美兼容
联想M920x黑苹果EFI配置终极指南:轻松实现macOS完美兼容 【免费下载链接】M920x-Hackintosh-EFI Hackintosh Opencore EFIs for M920x 项目地址: https://gitcode.com/gh_mirrors/m9/M920x-Hackintosh-EFI 想要在联想M920x迷你主机上体验macOS系统吗…...

终极免费B站视频下载方案:BilibiliDown完整使用指南
终极免费B站视频下载方案:BilibiliDown完整使用指南 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_mirrors/bi/…...