spark使用心得
spark入门
启停spark
sbin/start-all.shsbin/stop-all.sh
spark-shell
进入spark/bin目录,执行:
./spark-shell
输出中有这么一行:
Spark context Web UI available at http://xx.xx.xx.188:4040
意味着我们可以从web页面查看spark的运行情况,特别要注意的是,我们可从中看到节点的classpath,了解每个节点自带了哪些jar包。
如要查看集群各节点的信息,也可以查看http://xx.xx.xx.188:8080.
spark-shell默认运行于本地,要想运行于集群,需加上–master参数:
./spark-shell --master spark://xx.xx.xx.188:7077
helloworld
scala代码是:
object HelloWorld{def main(args: Array[String]): Unit = {//配置Spark应用名称val conf = new SparkConf().setAppName("CollectFemaleInfo")// 提交spark作业val sc = new SparkContext(conf)//读取数据。其是传入参数args(0)指定数据路径val text = sc.textFile(args(0))//筛选女性网民上网时间数据信息val data = text.filter(_.contains("female"))// 汇总每个女网民上网时间val femaleData:RDD[(String, Int)] = data.map { line =>val t = line.split(',')(t(0), t(2).toInt)}.reduceByKey(_+_)// 筛选出时间大于两小时的女网民val result = femaleData.filter(line => line._2 > 120)println("result count: " + result.count())result.collect().foreach(println)}
}
注意:
1、sparkContext的textFile默认加载hdfs的文件,要处理本地文件,需加上file://前缀。用本地数据文件的话,要求spark集群里的每个节点上都有这个本地文件,否则会报文件找不到的错误。所以,方便起见,最好是将数据放到hdfs上。
2、RDD的转换(transformation,例如map、flatMap、filter等)操作都是lazy的(亦即,只是创建一个新的RDD实例,而未做任何实际计算),只有count、collect这样的行动(action)操作才会真正去求值。这跟java stream的表现是一样的。
提交jar包
将代码用maven打包为jar,接着提交给spark运行,提交本地执行的命令如下:
./spark-submit --class com.lee.ConsistencyCheck /export/home/data/com.lee.distrulechecker.service-1.0-SNAPSHOT.jar ExtArea
提交spark集群运行的命令如下:
./spark-submit --class com.lee.ConsistencyCheck --master spark://xx.xx.xx.188:7077 /export/home/data/com.lee.distrulechecker.service-1.0-SNAPSHOT.jar ExtArea./spark-submit --class com.lee.ConsistencyCheck --master spark://xx.xx.xx.188:7077 --conf spark.cores.max=5 /export/home/data/com.lee.distrulechecker.service-1.0-SNAPSHOT.jar ExtArea./spark-submit --class com.lee.ConsistencyCheck --master local /export/home/data/com.lee.distrulechecker.service-1.0-SNAPSHOT.jar ExtArea注意:
1、–master 指定集群URL,支持的选项如下:
local 本地单线程local[K] 本地多线程(指定K个内核)local[*] 本地多线程(指定所有可用内核)spark://HOST:PORT 连接到指定的 Spark standalone cluster master,需要指定端口。mesos://HOST:PORT 连接到指定的 Mesos 集群,需要指定端口。yarn-client客户端模式 连接到 YARN 集群。需要配置 HADOOP_CONF_DIR。yarn-cluster集群模式 连接到 YARN 集群如果不指定–master选项默认就在local跑。
2、内存不够可用
--driver-memory 512M --executor-memory 512M
强制限制内存。
修改日志打印级别
spark-submit提交时会打印很多INFO信息,影响结果查看,可通过修改日志级别解决。
spark/conf目录下复制log4j.properties.template为log4j.properties,修改:
log4j.rootCategory=INFO, console
为
log4j.rootCategory=WARN, console
则在用spark-submit提交后不会出现大量的INFO信息。
提交集群执行时报错:Initial job has not accepted any resources
网上搜了以下,几个原因:
1、主机名和ip是否配置正确,查看/etc/hosts,同时在spark-shell里键入:
sc.getConf.getAll.foreach(println)
查看conf信息
2、内存不足,SPARK_EXECUTOR_MEMORY参数默认会使用1G内存,如果不够,可以在spark-submit里指定小于1G的数值,例如:
–executor-memory 512M
3、端口号被占用,之前的程序已运行。我的情况就是这样,spark-shell使用的集群模式,会把7077端口占用掉,导致随后的spark-submit必然失败。
提交jar时的库依赖
Java 和Scala 用户可以通过spark-submit 的–jars 标记提交独立的JAR 包依赖。当只有一两个库的简单依赖,并且这些库本身不依赖于其他库时,这种方法比较合适。但是一般Java 和Scala 的工程会依赖很多库。当你向Spark 提交应用时,你必须把应用的整个依赖传递图中的所有依赖都传给集群。为此,常规的做法是使用构建工具,生成单个大JAR 包,包含应用的所有的传递依赖。这通常被称为超级(uber)JAR 或者组合(assembly) JAR。
SparkSQL
我们可以在sparkSQL里写出比较复杂的sql,比如case when:
select case when (a.NAME <> b.EXTNAME) then 1 else 0 end from OBJ1 a join OBJ2 b on a.RID=b.RID
spark的python接口
spark通过py4j来做到python和java的互操作。我个人的猜测,由于spark计算的效率瓶颈应该在分布式计算上,使用python的效率未必比java或scala相差很多,就好比我们产品的程序,性能瓶颈都在sql上,用啥语言组织业务更多的出于使用方便的考量。
Spark进阶
driver/executor和master/worker的概念详解
《spark快速大数据分析》里对driver/executor和master/worker的介绍:
在分布式环境下,Spark 集群采用的是主/ 从结构。在一个Spark 集群中,有一个节点负责中央协调,调度各个分布式工作节点。这个中央协调节点被称为驱动器(Driver)节点。与之对应的工作节点被称为执行器(executor)节点。driver节点可以和大量的executor节点进行通信,它们也都作为独立的Java 进程运行。驱动器节点和所有的执行器节点一起被称为一个Spark 应用(application)。Spark 文档中始终使用驱动器节点和执行器节点的概念来描述执行Spark应用的进程。而主节点(master)和工作节点(worker)的概念则被用来分别表述集群管理器中的中心化的部分和分布式的部分。这些概念很容易混淆,所以要格外小心。
上述说法比较抽象,具化后是这样:
1、一个节点就是一个JVM进程,所以driver/executor和master/worker是四种进程;
2、master/worker进程是静态的、常驻的,spark集群起来后它们就存在了,我们在主机上执行ps命令可以看到master进程;在从机上ps,可以看到worker进程
3、driver/executor进程是动态的、随application存在的,application可以简单的认为就是用spark-submit提交的jar包。我们用 spark-submit提交jar包时,就会启动driver进程,driver进程好比监工,master进程好比总包工头,监工向总包工头提要求:“该干活了”,于是master通知它管理的小包工头(worker进程):“来来分点活给你们干”。worker进程就会去叫醒手下的工人(同一台从机上的executor进程):“你干这个、你干那个,手脚麻利点”。所以真正干活的是executor进程,driver还干点数据汇总的活,master/worker可都是“管理者”。application运行的时候,我们可以在从机上用ps命令看,会有好几个executor进程。这些进程由application触发启动,通过线程池运行实际的任务,等application结束,它们就会自然消亡。
因此,一个application的运行会有若干管理开销,比如数据的跨节点传输、启停executor进程、启停executor进程里的线程池等,若数据量较小,这些管理开销占的比重反而较大,得不偿失。举个例子,要处理1000条记录,3台机器,每台机器上4个executor进程,结果每个进程就处理80条记录,才开始就要结束,实在太浪费了。
spark调优参数
每个executor占用的核数
spark.executor.coresThe number of cores to use on each executor. In standalone and Mesos coarse-grained modes, setting this parameter allows an application to run multiple executors on the same worker, provided that there are enough cores on that worker. Otherwise, only one executor per application will run on each worker.
注意,这是每个executor可以使用的core数。所以,如果一台机器上仅有8个core且spark.executor.cores=4,那么每台机器上最多能起2个executor进程。
yarn集群下,该参数默认值为1,即每个executor进程使用一个core;standalone集群下则是该节点可用的所有core,考虑到standalone集群对application的调度默认是独占的,这个默认值就不难理解了,所以我们在各个worker上仅看到一个executor进程。
application占用的最大核数
spark.cores.maxWhen running on a standalone deploy cluster or a Mesos cluster in "coarse-grained" sharing mode, the maximum amount of CPU cores to request for the application from across the cluster (not from each machine). If not set, the default will be spark.deploy.defaultCores on Spark's standalone cluster manager, or infinite (all available cores) on Mesos.
每个executor占用的内存
spark.executor.memoryAmount of memory to use per executor process (e.g. 2g, 8g).
默认1g。
spark的优缺点
优点:
1、扩展性好,只需增加cpu和内存,就能在增加数据量的情况下保证性能不受较大影响。
实测中,数据量10倍增长,但耗时增长远低于10倍(当然,超过10w条记录后我们启用了多核,之前都是单核运行)。
2、资源独占(或采用静态资源分配策略)的情况下,效率始终比较稳定,不像数据库要受主键、背景数据量及统计信息的影响;
缺点:
1、比较重量级,小数据量计算的额外开销反而较大。这时设置spark.cores.max为很小的值(例如1),减少并行度,反而能提升效率。尽管如此,小数据量下相比于DB依然没有优势,两张千条记录的表连接在DB上耗时不超过1s,但在spark上仍需4s,这还不包括数据提取到hdfs的时间。
2、可能由于硬件资源有限(主要是core数),应用的并发度无法做到很高,最多不能超过总的核数。从测试情况来看,10w条记录以内的应用只需1核就能保证效率,但超过10w条,就要考虑多核了,像100w条,在10核时才能保证执行时间最短。
相关文章:

spark使用心得
spark入门 启停spark sbin/start-all.shsbin/stop-all.shspark-shell 进入spark/bin目录,执行: ./spark-shell 输出中有这么一行: Spark context Web UI available at http://xx.xx.xx.188:4040意味着我们可以从web页面查看spark的运行情…...

什么是边车
名词和概念定义 Sidecar:边车。微服务中数据平面的进程,负责转发应用、服务请求,并支持限流、熔断、负载均衡等特性。 Control-plane: 控制平面。微服务的配置中心,负责配置下发、数据搜集、服务发现等功能。 应用: 应用是指服务…...

vue项目打包成exe文件
1. 获取electron-quick-start demo git clone https://github.com/electron/electron-quick-start2. 安装依赖包 npm install 或 npm i // 安装依赖时可能会遇到node版本的问题,需要切换node版本的可以先看下nvm,简单易操作3. 打包项目(需要…...

基于MFCC特征提取和GMM训练的语音信号识别matlab仿真
目录 1.算法运行效果图预览 2.算法运行软件版本 3.部分核心程序 4.算法理论概述 4.1 MFCC特征提取 4.2 Gaussian Mixture Model(GMM) 4.3. 实现过程 4.4 应用领域 5.算法完整程序工程 1.算法运行效果图预览 2.算法运行软件版本 matlab2022a 3…...
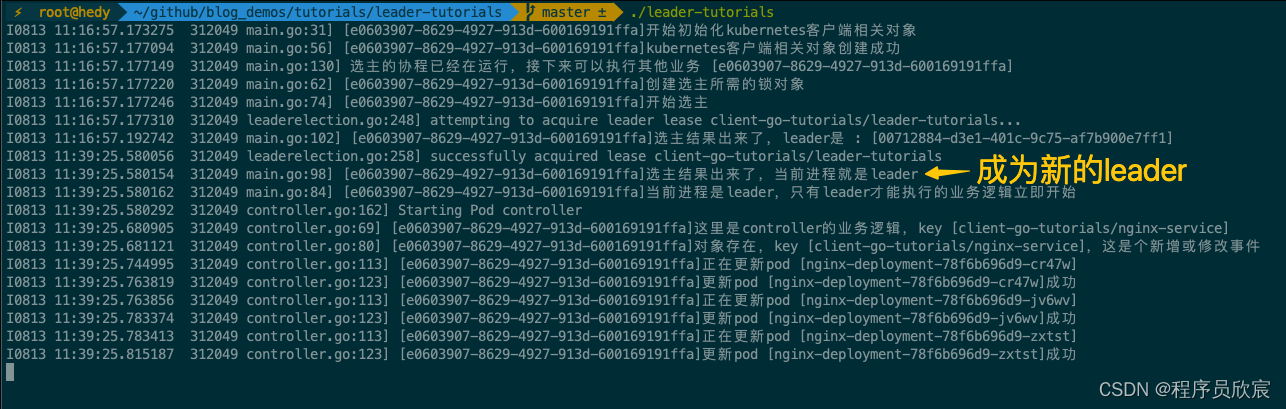
client-go实战之十二:选主(leader-election)
欢迎访问我的GitHub 这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos 本篇概览 本文是《client-go实战》系列的第十二篇,又有一个精彩的知识点在本章呈现:选主(leader-election)在解释什么是选主之前&…...
2023年即将推出的CSS特性对你影响大不大?
Google开发者大会每年都会提出有关于 Web UI 和 CSS 方面的新特性,今年又上新了许多新功能,今天就从中找出了影响最大的几个功能给大家介绍一下 :has :has() 可以通过检查父元素是否包含特定子元素或这些子元素是否处于特定状态来改变样式,也…...

opencv实战项目-停车位计数
手势识别系列文章目录 手势识别是一种人机交互技术,通过识别人的手势动作,从而实现对计算机、智能手机、智能电视等设备的操作和控制。 1. opencv实现手部追踪(定位手部关键点) 2.opencv实战项目 实现手势跟踪并返回位置信息&a…...
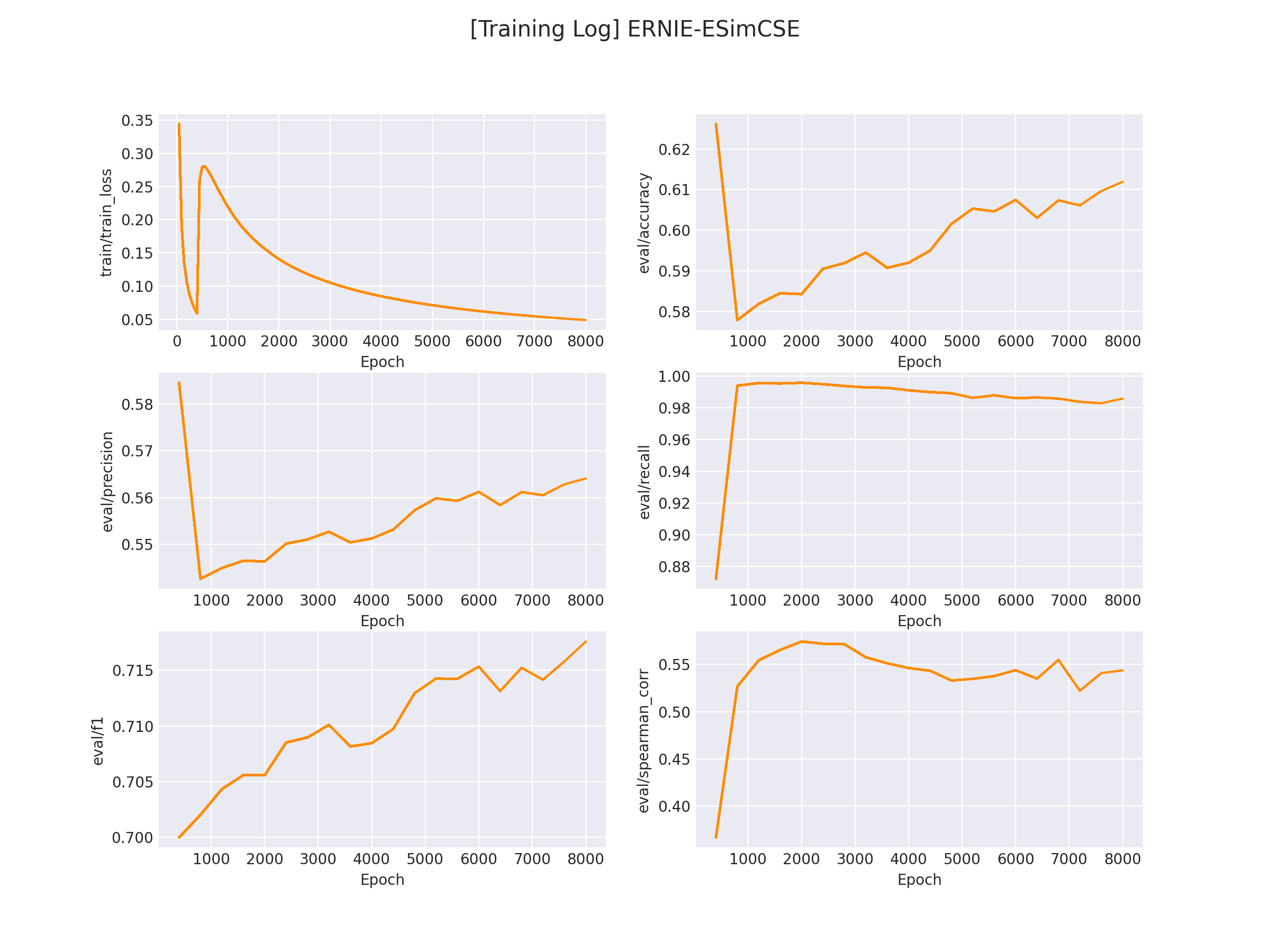
NLP文本匹配任务Text Matching [无监督训练]:SimCSE、ESimCSE、DiffCSE 项目实践
NLP文本匹配任务Text Matching [无监督训练]:SimCSE、ESimCSE、DiffCSE 项目实践 文本匹配多用于计算两个文本之间的相似度,该示例会基于 ESimCSE 实现一个无监督的文本匹配模型的训练流程。文本匹配多用于计算两段「自然文本」之间的「相似度」。 例如…...

复习vue3,简简单单记录
这里的知识是结合视频以及其他文章一起学习,仅用于个人复习记录 ref 和reactive ref 用于基本类型 reactive 用于引用类型 如果使用ref 传递对象,修改值时候需要写为obj.value.attr 方式修改属性值 如果使用reactive 处理对象,直接obj.att…...
【自用】云服务器 docker 环境下 HomeAssistant 安装 HACS 教程
一、进入 docker 中的 HomeAssistant 1.查找 HomeAssistant 的 CONTAINER ID 连接上云服务器(宿主机)后,终端内进入 root ,输入: docker ps找到了 docker 的 container ID 2.config HomeAssistant 输入下面的命令&…...

使用dockerfile手动构建JDK11镜像运行容器并校验
Docker官方维护镜像的公共仓库网站 Docker Hub 国内无法访问了,大部分镜像无法下载,准备逐步构建自己的镜像库。【转载aliyun官方-容器镜像服务 ACR】Docker常见问题 阿里云容器镜像服务ACR(Alibaba Cloud Container Registry)是面…...

编程语言学习笔记-架构师和工程师的区别,PHP架构师之路
🏆作者简介,黑夜开发者,全栈领域新星创作者✌,CSDN博客专家,阿里云社区专家博主,2023年6月CSDN上海赛道top4。 🏆数年电商行业从业经验,历任核心研发工程师,项目技术负责…...

Streamlit 讲解专栏(十):数据可视化-图表绘制详解(上)
文章目录 1 前言2 st.line_chart:绘制线状图3 st.area_chart:绘制面积图4 st.bar_chart:绘制柱状图5 st.pyplot:绘制自定义图表6 结语 1 前言 在数据可视化的世界中,绘制清晰、易于理解的图表是非常关键的。Streamlit…...
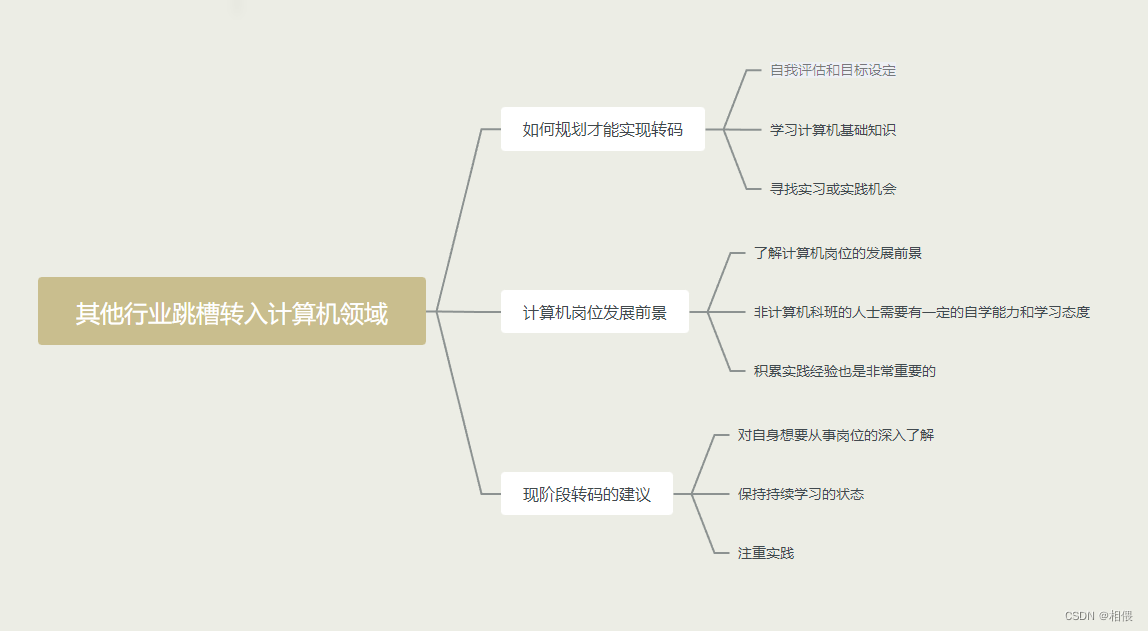
其他行业跳槽转入计算机领域简单看法
其他行业跳槽转入计算机领域简单看法 本人选择从以下几个方向谈谈自己的想法和观点。 先看一下总体图,下面会详细分析 如何规划才能实现转码 自我评估和目标设定:首先,你需要评估自己的技能和兴趣,确定你希望在计算机领域从事…...

Unity制作一个简单的登入注册页面
1.创建Canvas组件 首先我们创建一个Canvas画布,我们再在Canvas画布底下创建一个空物体,取名为Resgister。把空物体的锚点设置为全屏撑开。 2.我们在Resgister空物体底下创建一个Image组件,改名为bg。我们也把它 的锚点设置为全屏撑开状态。接…...

常用游戏运营指标DAU、LTV及参考范围
文章目录 前言运营指标指标范围参考值留存指标的意义总结 前言 作为游戏人免不了听到 DAU 、UP值、留存 等名词,并且有些名词听起来还很像,特别是一款上线的游戏,这些游戏运营指标是衡量游戏业务绩效和用户参与度的重要数据,想做…...

标准模板库STL——deque和list
deque概述 deque属于顺序容器,称为双端队列容器 底层数据结构是动态二维数组,从整体上看,deque的内存不连续 初始数组第一维数量为2,必要时进行2倍扩容 每次第一维扩容后,原来数组第二维元素从新数组下标为OldSize/2的…...
分类预测 | MATLAB实现WOA-CNN-BiGRU-Attention数据分类预测
分类预测 | MATLAB实现WOA-CNN-BiGRU-Attention数据分类预测 目录 分类预测 | MATLAB实现WOA-CNN-BiGRU-Attention数据分类预测分类效果基本描述模型描述程序设计参考资料 分类效果 基本描述 1.Matlab实现WOA-CNN-BiGRU-Attention多特征分类预测,多特征输入模型&…...
 第十章 类与对象)
C++ Primer Plus 第6版 读书笔记(10) 第十章 类与对象
第十章 类与对象 在面向对象编程中,类和对象是两个重要的概念。 类(Class)是一种用户自定义的数据类型,用于封装数据和操作。它是对象的模板或蓝图,描述了对象的属性(成员变量)和行为…...

基于C++ 的OpenCV绘制多边形,多边形多条边用不用的颜色绘制
使用基于C的OpenCV库来绘制多边形,并且为多边形的不同边使用不同的颜色,可以按照以下步骤进行操作: 首先,确保你已经安装了OpenCV库并配置好了你的开发环境。 导入必要的头文件: #include <opencv2/opencv.hpp&g…...

HyperMesh网格划分许可不够用?自动释放,仿真前处理加速
HyperMesh网格划分许可不够用?别慌,自动释放才是真本事前两天我被一个项目组找去救火,说他们的HyperMesh突然卡死,分分钟延迟两天交工。排查下来才发现,连累了整个分析流程的不是软件bug,是许可证池里没剩下…...

3大核心能力解析:Vin象棋如何用深度学习重塑中国象棋AI辅助体验
3大核心能力解析:Vin象棋如何用深度学习重塑中国象棋AI辅助体验 【免费下载链接】VinXiangQi Xiangqi syncing tool based on Yolov5 / 基于Yolov5的中国象棋连线工具 项目地址: https://gitcode.com/gh_mirrors/vi/VinXiangQi Vin象棋是一款基于YOLOv5深度学…...

CircuitPython开发实战:从环境搭建到内存优化与硬件选型
1. CircuitPython开发环境搭建与核心概念 如果你是从Arduino或者传统的嵌入式C开发转向微控制器编程,第一次接触CircuitPython的感觉,就像是突然有人给你递了一把万能钥匙。过去,点个灯、读个传感器,你得跟寄存器、数据手册、还有…...

工程定制丙级管道井门 物业机房通用款式
工程定制丙级管道井门,作为高层住宅、商业楼宇、物业机房强弱电井的专用消防配套设施,严格遵循国标消防规范生产,是建筑管井防火分隔、安全防护的核心产品。这款丙级管道井门采用钢制一体成型工艺,结构扎实不易变形,具…...

如何通过高效的能耗管理系统实现园区智能化与可持续发展?
高效能耗管理系统助力园区智能化发展 园区智能化的实现依赖于高效、利用该系统、园区能够实时收集分析能耗数据,形成精准的用能画像。这种数据驱动的管理方式使园区在资源配置上更加灵活。智能传感器和物联网技术的结合,帮助实时监控设备状态、自动识别能…...

终极指南:调度系统架构设计的核心原理与实践技巧
终极指南:调度系统架构设计的核心原理与实践技巧 【免费下载链接】system-design-101 Explain complex systems using visuals and simple terms. Help you prepare for system design interviews. 项目地址: https://gitcode.com/GitHub_Trending/sy/system-desi…...

HFSS扫频实战:三种扫频类型的选择策略与性能对比
1. HFSS扫频分析基础:为什么需要扫频? 刚接触HFSS仿真时,很多工程师都会疑惑:为什么不能直接计算目标频点的S参数?这个问题就像用相机拍照——单点频率仿真相当于只拍一张静态照片,而扫频分析则是录制一段视…...
)
CentOS 7/8 服务器根目录爆满?别慌,用LVM无损调整home空间给root(保姆级避坑指南)
CentOS服务器根目录空间告急?LVM动态扩容实战指南 凌晨三点,服务器监控突然狂闪警报——根目录剩余空间不足5%!这种场景对于运维人员来说无异于一场噩梦。当关键业务系统因日志无法写入而濒临崩溃时,传统的重装系统或数据迁移方案…...

CentOS 7服务器上,从零搞定NVIDIA驱动和CUDA 11.1的保姆级避坑指南
CentOS 7服务器NVIDIA驱动与CUDA 11.1实战避坑手册 接手一台老旧GPU服务器时,最令人头疼的莫过于搭建深度学习环境。那些看似简单的安装步骤背后,往往隐藏着无数个让新手崩溃的"坑"。本文将带你穿越雷区,用最稳妥的方式在CentOS 7上…...

IDEA Diagrams保姆级教程:5分钟看懂Java类图,定位源码、分析依赖超实用
IDEA Diagrams实战指南:用类图透视Java项目架构 刚接手一个遗留Java项目时,面对层层嵌套的类关系和错综复杂的接口实现,很多开发者都会感到无从下手。这时候,IDEA内置的Diagrams功能就像一盏明灯,能够将抽象的代码结构…...