java面试准备
1.自我介绍:
2.基础 :
1.集合 : java容器中分为collection 和map两大类
collection 分为list集合(有序且重复的),set集合(无序,不可重复)
list集合分为arrayList集合 : 查询快,增删慢,它是基于数组结构的,对数据的增删是在数组的尾部进行添加或删除的,其效率相对于LinkedList来说还是比较慢的,因为LinkedList是基于链表结构的查询慢增删快,它的增删只需要去改变指针的指向即可.并且arrayList做增删时还存在扩容问题,他的扩容是需要生成新的集合并且在原数组的基础上扩容1.5倍,他的 默认容量为10
set集合分为HashSet(无序且不可重复的,可以存储null值),TreeSet集合(他的底层是通过HashMap去实现的,对key去存储set元素,在里面会对元素进行排序,所以他不能存储null值)
map集合 :
HashMap集合: 他是基于key,value形式,基于数组和链表结构的,在对数据操作时继承了数组的线性查找和链表的寻址修改,并且HashMap集合是线程不安全的
原因 :
1.在jdk1.7中会造成环形链和数据丢失的情况
2.在jdk1.8中hashMap的put过程会造成数据覆盖的情况,其put过程为 : 1.对key求哈希值 2.判断是否发送哈希碰撞(求出的值相同),发生了碰撞就放入桶中,没有发生碰撞就以链表的形式链接到后面 3.链表的长度大于8会转为红黑树,链表的长度小于6会 从红黑素转为链表(这也是HashMap的存储机制)
线程安全的集合 :
1.copyOnWriteArraylist 2.copyOnWriteArraySet 3.HashMap
4.HashTable (执行的效率差,他是对整个HashTable进行加锁,同一时间只能有一个线程访问 )
5.ConcurrentHashMap 是一个无论在读或写操作上都支持很高性能的集合,在执行读操作的时候他几乎不需要加锁,在执行写操作时默认支持16个线程执行并发写操作(因为他里面的segment默认就是16个并发级别,支持扩张)
ConcurrentHashMap的存储机制 :
在jdk1.7中采用锁分段技术,将一个HashMap分为多个段,每段都加一把锁,这样就可以支持多线程的访问,以及不会影响系统对其他段的访问
在jdk1.8中采用CAS+Synchronized+Node+红黑树去实现的,更大程度上降低了锁的粒度
String和StringBuffer和StringBuilder的区别 :
string是一个不可变的类,在对字符串操作是会生成一个新的string对象,这样做的效率会很差并且还会消耗内存
StringBuffer是一个可变的线程安全的类,在对字符串操作时不会生成新的string对象,并且它里面有一个缓存区容量,当字符串的大小没有超过这个容量时,不会分配新的容量的
Stringbuilder也是一个可变的类,但是他是线程不安全的
1.如果我们对少量字符串操作时可以使用string类
2.如果在多线程下对大量字符串操作时,需要使用StringBuffer类,反之使用StringBuilder类
MySql :
在5.7版本以后默认值从的存储引擎是InnoDb,给,MySql的表提供了事物的处理,回滚以及崩溃修复的功能和多版本并发控制的事物安全,他支持外键,也就是当父表中的数据更新时字表中的数据也必须要有相应的改变,他总是支持自动增长且唯一不为空,在MySql中自动增长的列为主键,他的缺点是读写效率差执行速度慢
事物四大特性 :
原子性 : 一个或多个事物要么全部执行成功要么全部执行失败
一致性 : 一个事物可以从一种一致性的状态切换到另一种一致性的状态
隔离性 : 一个事物对数据的操作对其他事物是不可见的,多个事物之间是存在隔离的
持久性 : 一个事物对数据的修改在数据库中的改变是永久的,并且不支持回滚
事物的隔离级别 :
读未提交 : 会引发脏读,幻读,不可重复读
读已提交 : 会引发幻读,不可重复的
重复的 : 会引发不可重复读
串行化 : 从隔离级别来说,他是最高的隔离级别,从并发性上来说是最低的
脏读 : 一个事物读取到另一个事物未提交的数据,导致前后两次读取到的数据不一致
幻读 : 一个事物读取到另一个事物已提交的数据,导致前后两次读取到的数据不一致
不可重复读 : 一个事物前后两次读取到的数据不一致,由于其他事物插入数据导致事物并发的情况
索引优化 :
(高并发的处理方式,避免全表扫描,尽量使用索引)
导致全表扫描,索引时效的情况 :
1. 索引列使用函数计算
2. 模糊查询的左模糊(因为mysql是遵循最左匹配原则,所以使用左模糊时匹配的是一个占位符)
3. is not null 不走索引
4. or的使用不当(大于,小于,不等于等范围查询)
5.参数类型与字段类型不匹配,会导致类型发送隐式转换,索引失效
#{}和${}的区别 :
#{}可以防止sql注入,在进行编译时会解析为一个 占位符并且自动拼接单引号,不会改变参数的数据类型
${}不能防止sql注入,在编译时他是做一个string类型的转换,解析出什么就是什么=和Eq
==和equals的区别 :
== 比较的是参数值
equals在引用数据类型中没有重写euals时比较的是地址值;重写equals方法后比较的是地址值中的内容
mybatis : 支持定制化,存储过程和高级映射,几乎可以避免所有的jdbc代码和手动设置参数以及获取数据集
mybatisPlus : 是在mybatis上只做增强不做改变,主要是为了简化开发和提高效率
他的优点是损耗小,启动就会注入基本的crud,性能上基本无损耗,属于直接面向对象的操作,并且支持lambada表达式,内嵌服务器,拦截器分页插件等
他的缓存级别分为 :
一级缓存 : 默认开启的,他的增删需要清空一级缓存,是属于sqlSession中的缓存,他的生命周期和sqlSession一致的
二级缓存 : 他是sqlSessionFactory中的缓存,需要手动开启,如果我们每次查询都需要使用最新的数据时,需要禁用二级缓存的
相关文章:

java面试准备
1.自我介绍: 2.基础 : 1.集合 : java容器中分为collection 和map两大类 collection 分为list集合(有序且重复的),set集合(无序,不可重复) list集合分为arrayList集合 : 查询快,增删慢,它是基于数组结构的,对数据的增删是在数组的尾部进行添加或删除的,其效率相对于LinkedList…...
kafka-6-python单线程操作kafka
使用Python操作Kafka:KafkaProducer、KafkaConsumer Python kafka-python API的帮助文档 1 kafka tools连接 (1)/usr/local/kafka_2.13-3.4.0/config/server.properties listeners PLAINTEXT://myubuntu:9092 advertised.listenersPLAINTEXT://192.168.1.8:2909…...
【Spring教程】1.Spring概述
1、概述 1.1、Spring是什么? Spring 是一款主流的 Java EE 轻量级开源框架 ,Spring 由“Spring 之父”Rod Johnson 提出并创立,其目的是用于简化 Java 企业级应用的开发难度和开发周期。Spring的用途不仅限于服务器端的开发。从简单性、可测…...

设计模式-代理模式
控制和管理访问 玩过扮白脸,扮黑脸的游戏吗?你是一个白脸,提供很好且很友善的服务,但是你不希望每个人都叫你做事,所以找了黑脸控制对你的访问。这就是代理要做的:控制和管理对象。 监视器编码 需求&…...
)
DPDK — MALLOC(librte_malloc,Memory Manager,内存管理组件)
目录 文章目录 目录MALLOC(librte_malloc,Memory Manager,内存管理组件)rte_malloc() 接口malloc_heap 结构体malloc_elem 结构体内存初始化流程内存申请流程内存释放流程MALLOC(librte_malloc,Memory Manager,内存管理组件) MALLOC 库基于 hugetlbfs 内核文件系统来实…...

【Java开发】Spring 12 :Spring IOC控制反转和依赖注入(解决单接口多实现类调用)
IOC 是 Inversion of Control 的简写,译为“控制反转”,Spring 通过 IOC 容器来管理所有 Java 对象的实例化和初始化,控制对象与对象之间的依赖关系。我们将由 IOC 容器管理的 Java 对象称为 Spring Bean,它与使用关键字 new 创建…...

【C++学习】基础语法(三)
众所周知C语言是面向过程的编程语言,关注的是过程;解决问题前,需要分析求解的步骤,然后编辑函数逐步解决问题。C是基于面向对象的,关注的是对象,将一件事拆分成不同的对象,不同对象间交互解决问…...
k8s自动化安装脚本(kubeadm-1.23.7)
文章目录介绍软件架构版本介绍更新内容2023-02-192023-02-152023-02-142023-02-102022-10-202022-08-06准备部署包操作步骤环境准备结构备注解压部署包修改host文件脚本使用方式初始化环境验证ansible配置安装k8s集群登录master的节点添加node节点master节点状态检查组件安装安…...
面试题记录
Set与Map的区别 map是键值对,set是值的集合。键,值可以是任何类型map可以通过get获取,map不能。都能通过迭代器进行for…of遍历set的值是唯一的,可以做数组去重,map,没有格式限制,可以存储数据…...

链式前向星介绍以及原理
1 链式前向星 1.1 简介 链式前向星可用于存储图,本质上是一个静态链表。 一般来说,存储图常见的两种方式为: 邻接矩阵邻接表 邻接表的实现一般使用数组实现,而链式前向星就是使用链表实现的邻接表。 1.2 出处 出处可参考此…...

jenkins 安装 -适用于在线安装 后续写个离线安装的
jenkins安装1.下载jenkins2.安装启动3.附件卸载jdk的命令4.配置jenkins一、在jenkins配置文件中配置jdk环境变量二、修改jenkins默认的操作用户1.下载jenkins jenkins官网下载 https://www.jenkins.io/ 点击下载 我是centos系统所以选择centos,点击后按着官方提供…...
【C++】再谈vscode界面调试C++程序(linux) - 知识点目录
再谈vscode界面调试C程序(linux) 配套文档:vscode界面调试C程序(linux) 命令解释 g -g ../main.cpp 编译main.cpp文件; -g:生成调试信息。编译器会在可执行文件中嵌入符号表和源代码文件名&…...

蚂蚁感冒---第五届蓝桥杯真题
目录 题目链接 题目描述 分析: 代码: y总综合 666 题目链接 1211. 蚂蚁感冒 - AcWing题库 题目描述 分析: y总真牛逼,掉头等价于穿过,以第一个点为分界点,分别判断 代码: (自…...
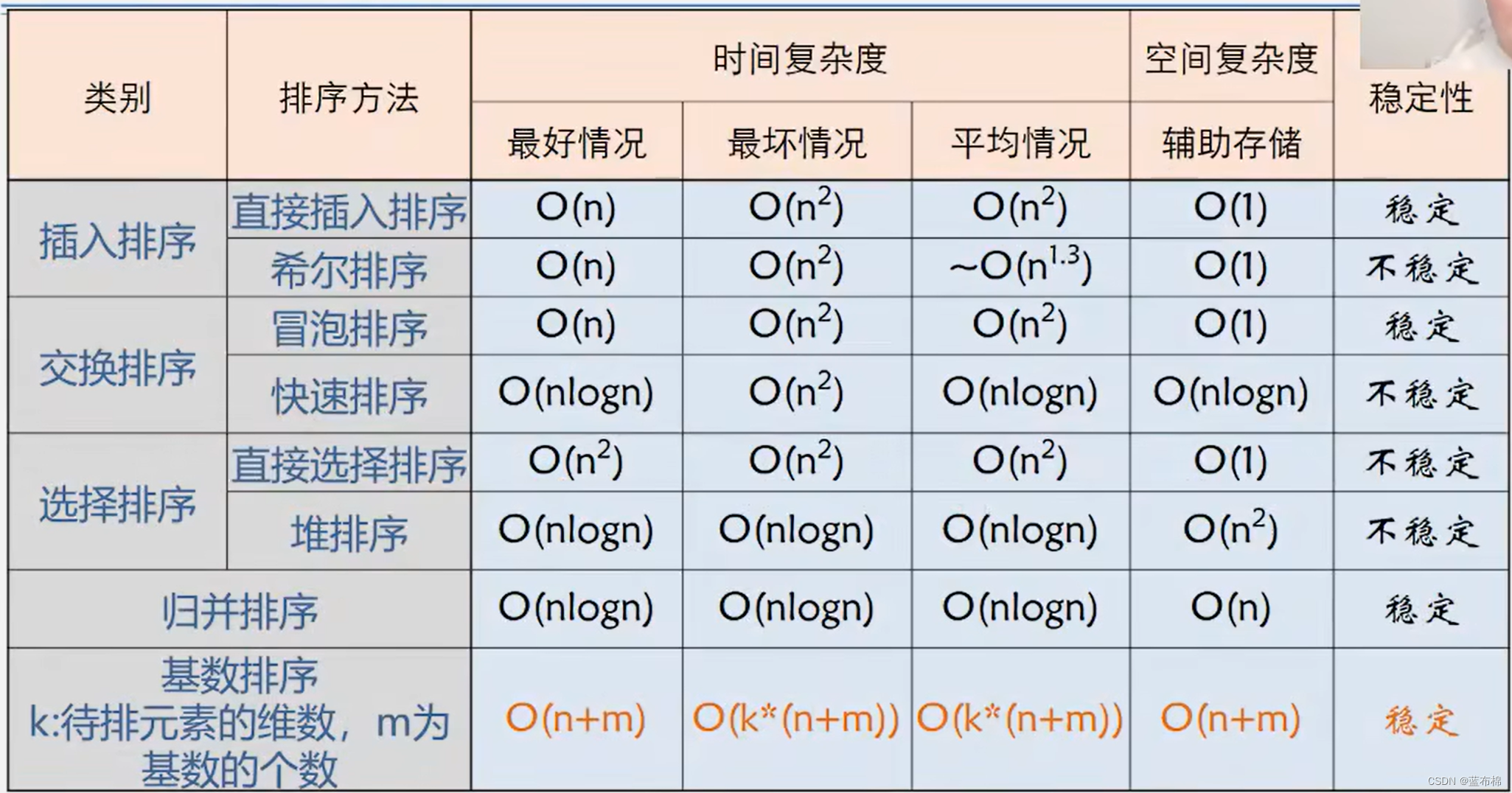
常见排序算法--Java实现
常见排序算法--Java实现插入排序直接插入排序折半插入排序希尔排序交换排序冒泡排序快速排序选择排序直接选择排序堆排序归并排序基数排序各种排序方法比较在网上找了些排序算法的资料。此篇笔记本人总结比较,简单注释,觉得比较好理解,且相对…...

算法笔记(九)—— 暴力递归
暴力递归(尝试) 1. 将问题转化为规模缩小了的同类问题子问题 2. 有明确的不需要的继续递归的条件 3. 有当得到子问题结果之后的决策过程 4. 不记录每一个子问题的解 Question:经典汉诺塔问题 1. 理解清楚,基础三个圆盘的移动…...

Flask框架学习记录
Flask项目简要 项目大致结构 flaskDemo1 ├─static ├─templates └─app.py app.py # 从flask这个包中导入Flask类 from flask import Flask# 使用Flask类创建一个app对象 # __name__:代表当前app.py这个模块 # 1.以后出现bug,可以帮助快速定位 # 2.对于寻找…...

【Opencv 系列】 第6章 人脸检测(Haar/dlib) 关键点检测
本章内容 1.人脸检测,分别用Haar 和 dlib 目标:确定图片中人脸的位置,并画出矩形框 Haar Cascade 哈尔级联 核心原理 (1)使用Haar-like特征做检测 (2)Integral Image : 积分图加速特征计算 …...

信源分类及数学模型
本专栏包含信息论与编码的核心知识,按知识点组织,可作为教学或学习的参考。markdown版本已归档至【Github仓库:information-theory】,需要的朋友们自取。或者公众号【AIShareLab】回复 信息论 也可获取。 文章目录信源分类按照信源…...
Games101-202作业1
一. 将模型从模型空间变换到世界空间下 在这个作业下,我们主要进行旋转的变换。 二.视图变换 ,将相机移动到坐标原点,同时保证物体和相机进行同样的变换(这样对形成的图像没有影响) 在这个作业下我们主要进行摄像机的平移变换&am…...
Linux系统之终端管理命令的基本使用
Linux系统之终端管理命令的基本使用一、检查本地系统环境1.检查系统版本2.检查系统内核版本二、终端介绍1.终端简介2.Linux终端简介3.终端的发展三、终端的相关术语1.终端模拟器2.tty终端3.pts终端4.pty终端5.控制台终端四、终端管理命令ps1.直接使用ps命令2.列出登录详细信息五…...

量子混合算法优化带容量约束的车辆路径问题
1. 量子混合算法求解带容量约束的车辆路径问题物流配送优化是供应链管理中的经典难题。想象一下,一家快递公司每天需要向城市各处投递包裹,每辆货车都有载重限制,如何规划路线才能使总运输距离最短?这就是带容量约束的车辆路径问题…...

观察Taotoken在高峰时段的模型路由与容灾表现
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察Taotoken在高峰时段的模型路由与容灾表现 在构建依赖大模型能力的应用时,服务的稳定性是开发者关心的核心问题之一…...

Rydberg原子阵列与量子导线技术在量子计算中的应用
1. Rydberg原子阵列中的量子导线技术解析 量子计算为解决组合优化问题提供了全新思路,特别是在处理NP难问题时展现出独特优势。Rydberg原子阵列作为近年来备受关注的可编程量子平台,其核心优势在于能够通过激光操控实现量子比特的精确排布和相互作用调控…...

基于DNS的TEE认证革新:原理、实现与性能优化
1. 项目概述:基于DNS的TEE认证革新在云计算安全领域,可信执行环境(TEE)技术正经历着从专用场景向通用基础设施的演进。传统TEE认证方案如RA-TLS存在两个根本性缺陷:一是依赖客户端主动验证硬件证明,导致非T…...

基于RAG的代码知识库构建:从原理到本地部署实战
1. 项目概述:当代码库成为知识库,我们如何精准“提问”?最近在跟几个做AI应用开发的朋友聊天,大家普遍有个痛点:项目代码越堆越多,文档要么不全要么过时,新来的同事想了解某个模块的逻辑&#x…...

自托管代码仓库聚合分析平台CodeStacker:架构设计与部署指南
1. 项目概述:一个为开发者打造的代码仓库聚合与智能分析工具如果你和我一样,每天需要面对GitHub、GitLab、Bitbucket等不同平台上的几十个甚至上百个代码仓库,那么“仓库管理”这件事本身,可能就已经消耗了你大量的精力。哪个项目…...

Topit:重构macOS多窗口工作流的开源利器
Topit:重构macOS多窗口工作流的开源利器 【免费下载链接】Topit Pin any window to the top of your screen / 在Mac上将你的任何窗口强制置顶 项目地址: https://gitcode.com/gh_mirrors/to/Topit 在日益复杂的数字工作环境中,macOS用户经常面临…...

隔着包装也能读、2m/s不串读:东集UF40如何应对管制药厂的RFID“极限大考”?
提到RFID固定式读写器,很多人的第一印象是仓库、货架与托盘。但在一些关乎生命安全的领域,RFID技术正面临着更严苛的考验。这一次,我们走进管制药厂——一个对精准追溯要求达到极致、不容任何差错的场景。核心痛点:一盒十瓶&#…...

如何用WinUtil在5分钟内完成Windows系统优化和软件安装?
如何用WinUtil在5分钟内完成Windows系统优化和软件安装? 【免费下载链接】winutil Chris Titus Techs Windows Utility - Install Programs, Tweaks, Fixes, and Updates 项目地址: https://gitcode.com/GitHub_Trending/wi/winutil 你是否厌倦了每次重装系统…...

S参数去嵌与DK/DF拟合:从实测数据反演PCB板材真实性能
1. 项目概述:从S参数中“挖”出板材的真实性能在高速PCB设计里,我们经常听到两个关键的板材参数:介电常数(DK, Dk)和损耗角正切(DF, Df)。供应商手册上会给出一个标称值&…...