画质提升+带宽优化,小红书音视频团队端云结合超分落地实践
随着视频业务和短视频播放规模不断增长,小红书一直致力于研究:如何在保证提升用户体验质量的同时降低视频带宽成本?
在近日结束的音视频技术大会「LiveVideoStackCon 2023」上海站中,小红书音视频架构视频图像处理算法负责人剑寒向大家分享了一项创新技术——基于人眼感知质量的端云结合超分框架。现场分享颇受关注,为此我们整理了分享内容,以飨读者。

以下全文根据剑寒演讲整理
大家好,我是剑寒,目前在小红书音视频架构负责视频图像算法研发和落地。今天我分享的主题是《基于人眼感知质量的端云结合画质及带宽优化实践》,核心是画质与带宽优化,有两个关键词分别是端云结合以及人眼感知质量。
我的分享分为以下几个部分:
1. 首先介绍小红书的视频处理架构,以及我们如何思考音视频系统中视频处理最重要的两个目标,即提升观看画质体验和降低视频带宽成本。
2. 接下来介绍小红书自研的一个基于 AI 的无参考视频质量评估算法 RedVQA,它提供与人眼视觉感知一致的质量评估。
3. 我们结合 RedVQA 设计了一个端云结合超分,在带宽节省以及多项播放技术指标上具有显著收益,契合当下降本增效的需求。端侧超分的部署在画质提升以及带宽节省上都有帮助。
4. 最后是总结和展望。


首先,大家对小红书的印象是什么呢?
小红书最初主要面向消费场景,比如美妆产品的分享和购买攻略。经过近几年的发展,小红书已经变成了一个综合的 UGC 分享社区,在“衣食住行玩”各方面都有大量的用户真实分享,提供很多有价值的信息。同时用户群体也发生了较大的变化,性别以及各年龄段的用户比例变得更加均衡。
另一个显著的变化是:小红书以前主要是图文笔记分享,随着视频成为用户分享生活的重要载体,小红书也响应趋势提出视频战略,目前用户刷小红书可以发现视频笔记占了很大的比例。当前每日新增视频达到了百万级别,直播消费侧业务也在稳步提升。
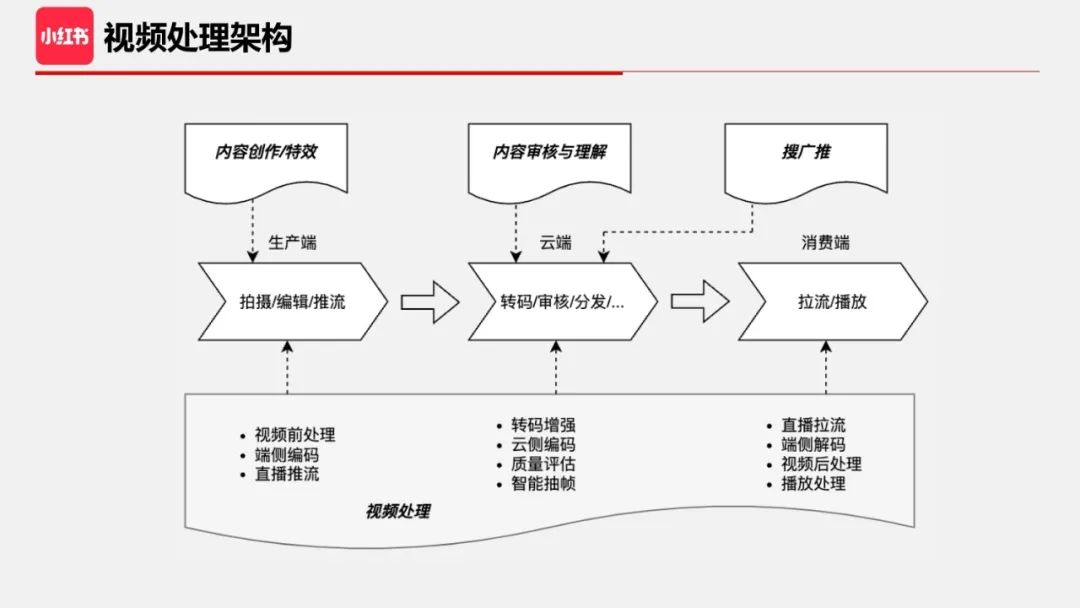
那么,PUGC 点播及直播业务背后涉及的关键技术有哪些?
这里展示一张架构图,整个链路主要包含生产端、云端和消费端,用户在生产端进行内容创作、编辑和推流;然后将内容发布到后台云端进行处理,主要包括多档位视频转码、内容审核与理解、以及视频搜索与推荐;消费端则是用户实际体验的场景,用户体验来自两方面,一方面是视频推荐内容的体验,另一方面是视频画质及播放流畅度的体验,后者也是我们在音视频处理中需要关注和优化的目标。从这张图可以看到,音视频处理横跨三端,也是整个上层视频业务及应用的基础设施,我们需要保障整条视频链路的稳定和通畅、关注用户体验以及降低成本(带宽、计算、存储等)。
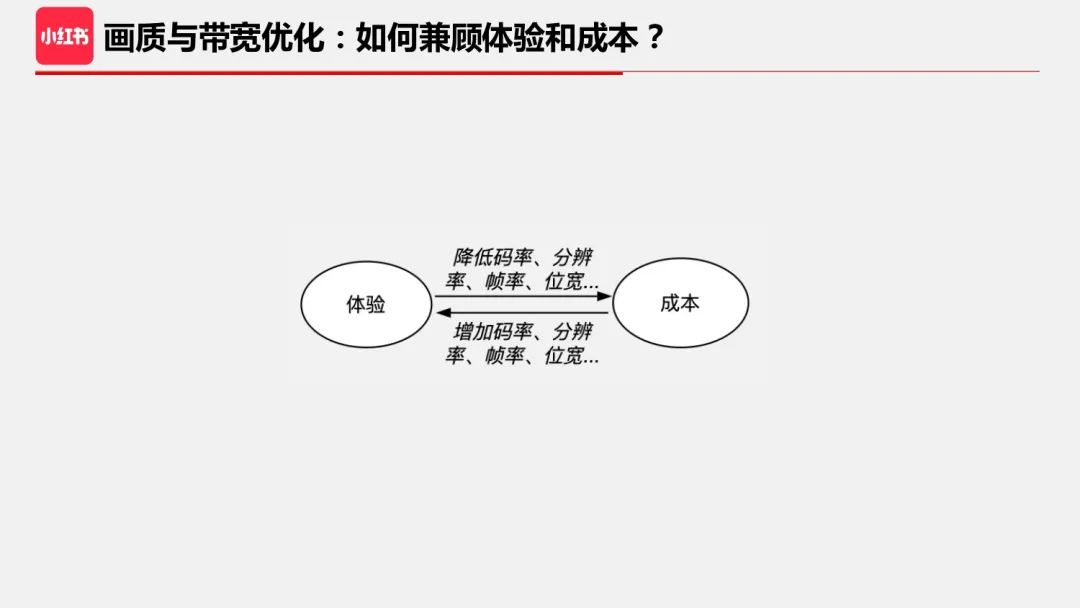
回归本次分享的主题:如何对画质与带宽进行优化?
在论述这个话题前,先简单介绍一下背景。
小红书成立专业的音视频团队还不到 2 年,如果是正常的研发路径,应该是先提升体验,容许增加一些成本。但是在疫情之后,全行业进入降本增效主题,降成本也成为我们重要目标之一。而提升体验是建立这个专业团队的初衷,在不牺牲用户体验的前提下来换取技术成本的节省,唯一的手段就是提升技术和优化策略。
因此,我们算是跑步进入了“深水区”,比较幸运的是,一方面我们是站在行业经验的肩膀上;另一方面,我们也有后发优势,并结合自己的思考可以进一步改进和优化。所以如何兼顾体验和成本?下面分三个层面说说我的理解。

1、模块级优化
首先,大家熟知的是编码标准的迭代和升级,每一代标准相比前一代标准在画质基本不变前提下可以节省 30%~50% 的码率。当前小红书大规模部署的是 H.265 标准,目前达到比较高的覆盖率。在研主要标准是 AV1,H.266 未来也可能会跟进。
新一代标准大规模落地还需要一些时间,当前主要挑战是计算复杂度比较高。对于点播来说,云端可以用计算成本来换,而在播放端,当前硬解 AV1 和 H.266 的设备非常少,因此需要配套部署经过极致优化的软解。
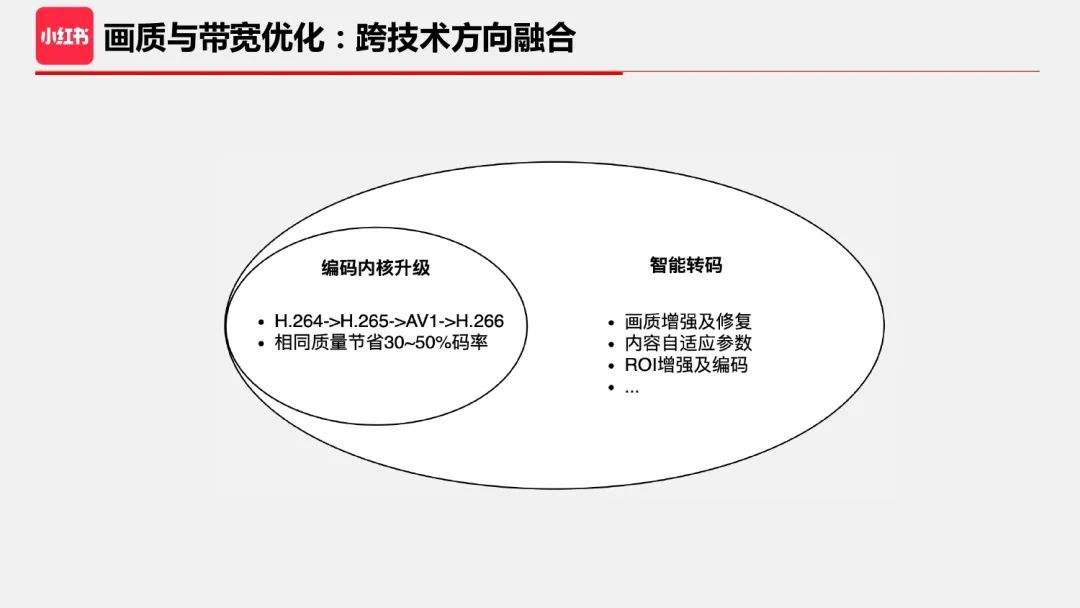
2、跨技术方向融合
编码考虑的是用最少的码率最大程度地代表原视频,因此视频质量的上限就是原视频。而 UGC 创作的视频质量非常多样,如果能用画质增强及修复算法提升原视频的质量,那么对应消费侧的转码视频质量也能随之提升。比如一个带噪视频经过去噪算法后再编码,不仅画质有提升,还能进一步节省码率。当然并不是所有画质算法都能带来这种 double 的收益。比如在云端做超分,画质提升的同时码率也会增加。
其次,当前的编码框架还是比较传统,缺乏对视频内容的理解,固定的编码参数以及码控算法并不是最优的。因此,通过对视频场景的分类以及增加对内容和语义的理解,可以进一步提升编码效果和效率。另外从主观感受来讲,对于感兴趣区域提升编码质量可以更有效地提升实际观看体验,而对于非感兴趣区域降低编码质量,不太影响观看体验但有助于节省码率。
视频分析、处理以及内容自适应编码技术整体形成了智能转码方案,涉及到 high level 图像分析、low level 图像处理、编码技术的融合。据我了解,各家厂商在这部分都有自己的一些方案,但是智能程度(包括效果和自动化程度两个方面)还有待提升,随着智能化程度的提升,收益及效率也会越来越高。
此外,学术界也有一些颠覆性的前沿探索,比如端到端的深度学习视频编码,不过总的来说更偏中长期才有机会大规模落地。
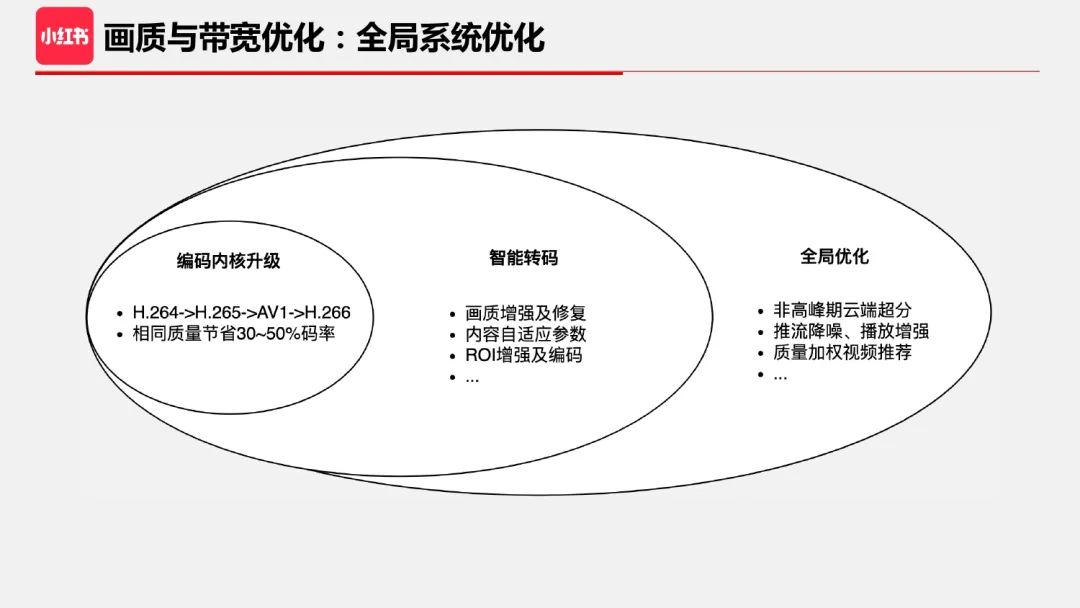
3、全局系统优化
转码是音视频处理最重要的一个任务,而它也只是云端处理的重要一环。全局来看,音视频处理是一个从生产端到消费端的视频处理链路。局部优化往往带来局部最优,站在全局视角,可以发现很多技术优化不再矛盾,比如前文提到云端超分,提升画质但是会增加码率,理论上会增加带宽成本,但如果全局分析,我们可以发现 CDN 通常是根据高峰期来收费,在非高峰期下发超分后的高码率视频并不会增加带宽成本。
另外,如果能够在播放端做好画质增强,就可以下发更低码率和更低分辨率的视频,从而实现显著的带宽节省,后面要讲的端云结合超分就是一个典型例子。
站在更大的视角,用户体验包含画质体验和内容体验,音视频处理的结果是提升大盘视频整体质量,而视频推荐能结合视频质量评估,就可以给用户推荐感兴趣且高质的视频。
从编码标准迭代到全局优化,我认为在兼顾体验和成本的优化上还有不少可以挖掘的点,且在单一技术点上其实也还有很大空间,给出这样的判断基于两个主要原因:一是音视频系统的智能化程度还比较低,更高的智能化意味着能够更好地兼顾体验和成本;此外,我们发现在音视频系统里落地的算法效果离学术界上限还有一定距离,客观原因是学术 idea 通常在很小的数据集上验证,而在亿级视频消费和展现上会有很多问题,但好的一面是,未来如果我们能利用好这些最新 idea 且解决泛化及性能问题,就会产生可观的收益。
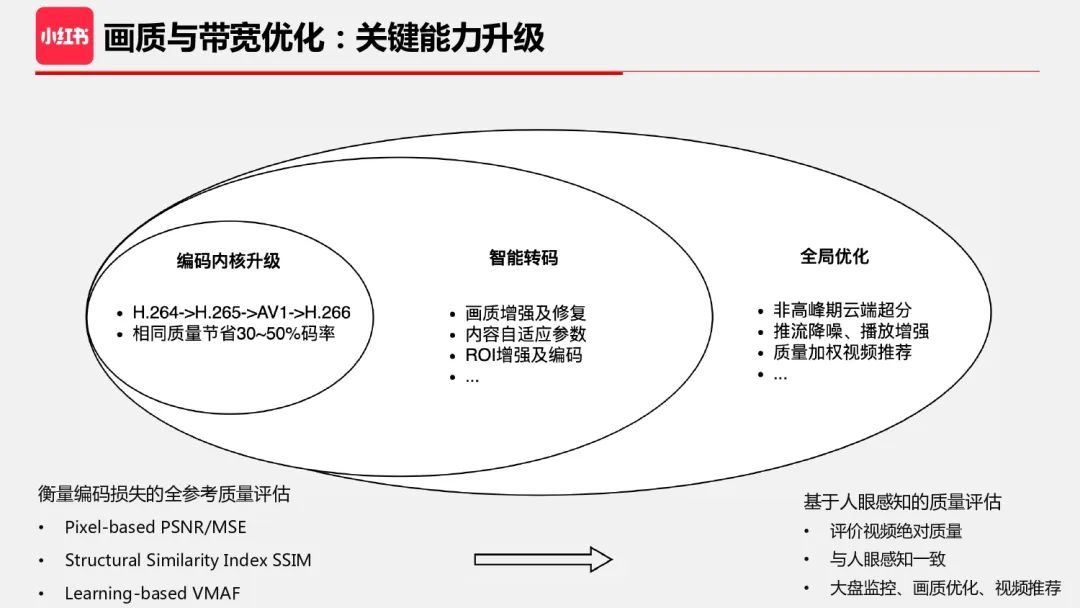
从模块优化到全局优化的演进过程中,我认为最重要且最基础的能力升级是质量评估。如果只是优化编码,可以用 PSNR/SSIM/VMAF 等有参考指标。而当构建智能转码时,这些有参考质量评估方法不再适用,比如经过画质增强的视频比原视频看着更好。此外,站在全局视角来看,很多处理节点也没有参考视频可用,相对质量评估方法也无法使用。因此质量评估需要升级为以人眼感知质量为基础,并且评估视频的绝对质量。

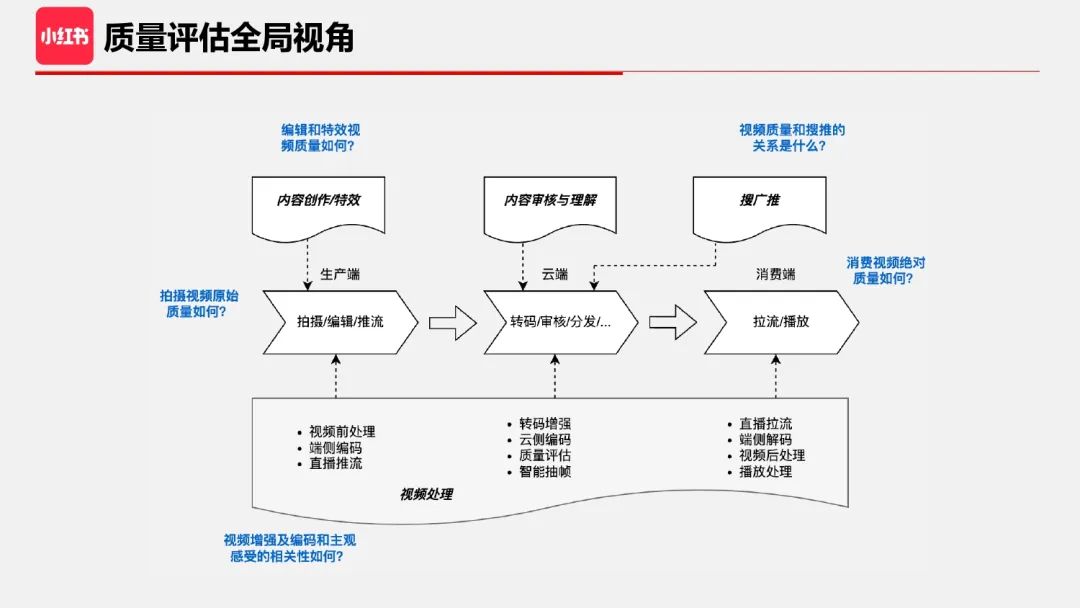
下面介绍小红书自研的质量评估指标 RedVQA,它是一个基于深度学习的无参考视频质量评估算法。
回到这张架构图,我们希望 RedVQA 能做什么?
首先,我们希望它能对整个视频链路任一节点的视频质量做评估,包括拍摄视频的原始质量、经过编辑和特效处理后的质量、经过转码下发到消费端的质量。
其次,我们希望它可以指导优化画质及编码算法。
最后,我们希望它能够辅助上层视频业务和应用。
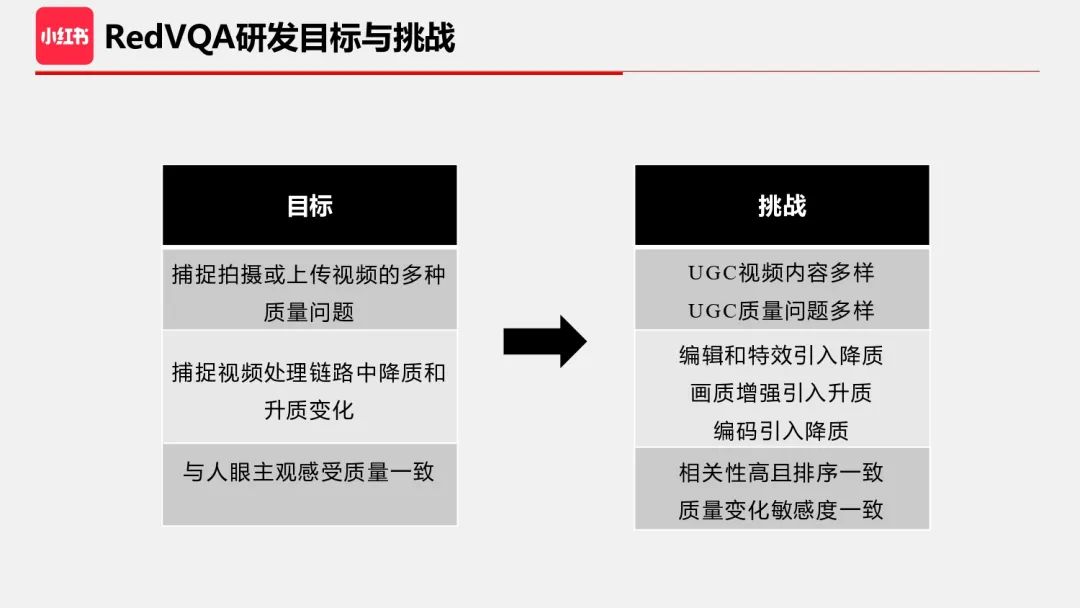
基于上面的分析,我总结下 RedVQA 的研发目标与挑战。
第一个目标是能够捕捉拍摄或上传视频的多种视频质量问题;挑战是如何尽量多地覆盖到各种 UGC 质量问题(比如模糊、过曝欠曝、噪声、颜色不自然、过锐等)。
第二个目标是能够捕捉视频处理链路中的降质和升质变化,要求我们能够识别和理解整个视频链路的升质和降质操作,并且把这些因素融入到算法和数据集设计中。举个例子,低码率编码会引入降质,画质问题表现为:细节丢失、清晰度下降、平坦区出现块效应、边缘和纹理区域出现振铃效应/蚊式噪声。另外值得注意的是,视频压缩相比图像压缩在码率分配上更加复杂,会使得视频质量在空域和时域上不是均匀分布,这也对算法的智能识别能力提出了更高的要求。画质增强算法通常可以提升画质,常见的超分、去模糊、去压缩损失、HDR 等算法有助于改善细节、清晰度、噪声、亮度/色彩等方面的画质体验。
第三个目标是与人眼主观感受质量一致,要求算法智能且泛化强。比如大光圈拍的照片会产生背景虚化效果,人眼觉得 ok、有美感,而算法有可能把虚化的背景误判为模糊问题。
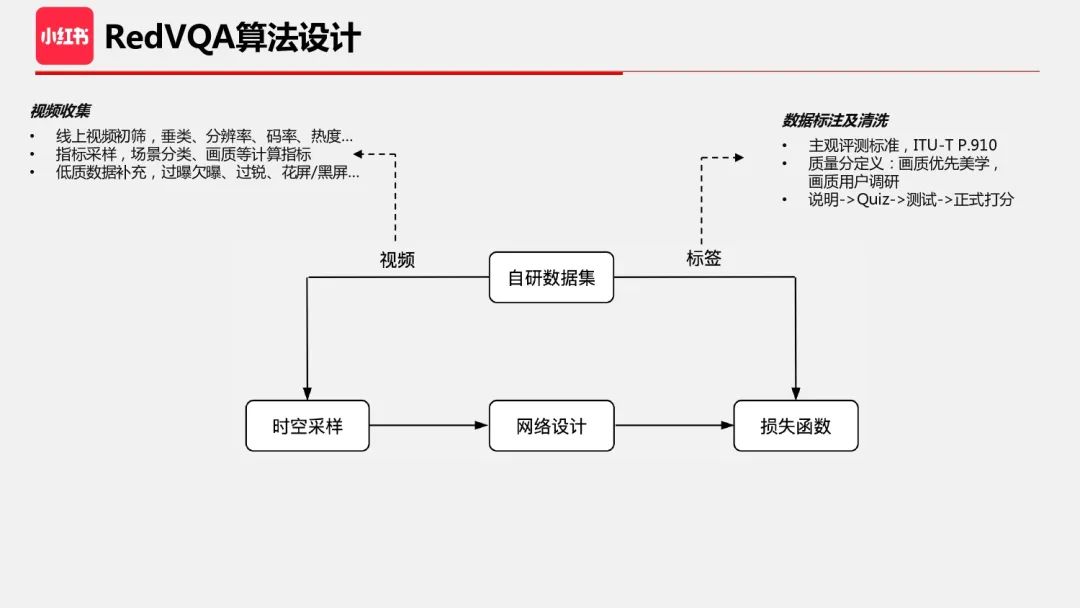
在自研数据集前,我们收集了质量评估领域的几个主要数据集,通过分析和总结得出一些结论:a. 相比 CV 任务,开源质量评估数据集规模很小;b. 数据来源可能和我们线上不太一致,包括用户设备和拍摄专业程度等;c. 开源数据集缺少经过业务视频链路处理的数据,如小红书特有的编码/画质处理、特效模板处理;d. 我们也测试了使用开源数据集训练的算法在业务测试集上的准确率,结果比开源数据集低很多。
因此,我们决定自研构建 RedVQA 数据集。数据集构建中非常关键的是视频收集,主要思考的问题是如何通过有限的数据集来代表相对无限的大数据,使得训练出来的算法具有很强的泛化能力。实践中,我们分为三个步骤:首先是视频初筛,这一步根据线上视频的标签、垂类和基础视频信息进行筛选,比如主要的分辨率要覆盖到,包含不同的码率、转码质量的视频。第二步,我们需要在候选数据集内采样一批尽可能场景丰富和质量多样的视频子集,我们利用了一些场景分类以及不同画质维度的检测指标作为判断标准。通过指标采样,希望采集到的数据集在各指标上更加均衡或者符合预期。经过前面两步,仍然会缺失一些低质视频,因为有些问题视频占比很少,很难从线上筛选出来。通过对整个视频链路的理解和分析,需要人工补充或构造一些低质视频。
在数据标注和清洗上主要参照 ITU-T P.910 标准,通过流程规范来保证数据标注质量。质量分的定义也比较重要,由于美学具有很强的个体主观性,我们主要考虑画质维度,而不同画质维度的优先级主要参考了小红书的用户调研。
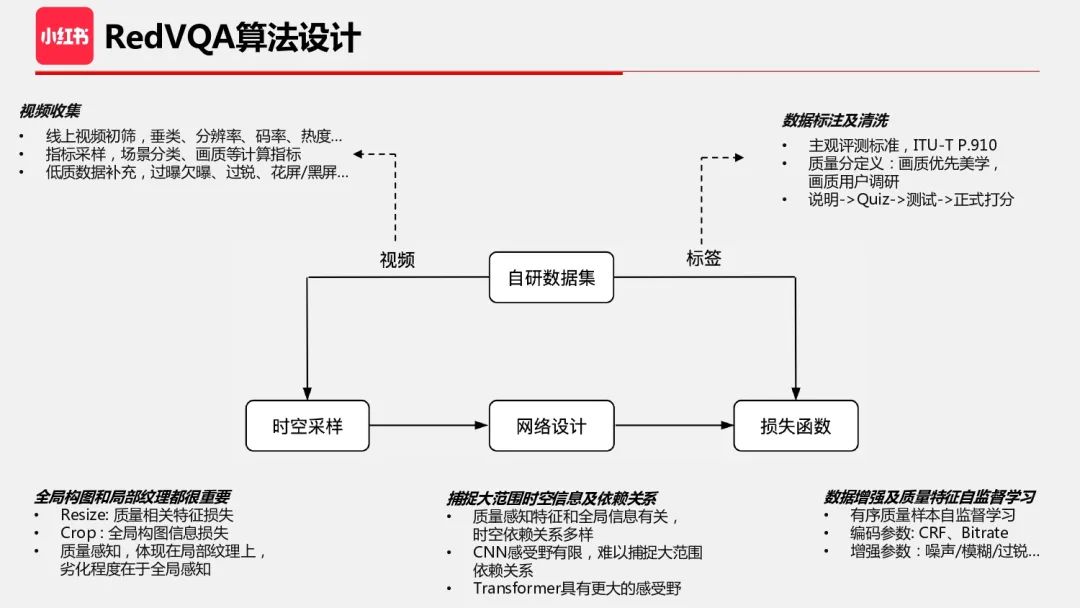
算法设计上,重点是如何有效提取质量特征,这里需要对质量问题的产生过程有充分的认知,比如视频链路中编辑和转码会如何影响质量,我总结了 3 个关键点:
1、在时空采样中,全局构图和局部纹理信息都很重要。质量感知特征体现在局部纹理上,而劣化程度在于全局感知;
2、网络设计要能够捕捉大范围时空信息及依赖关系,人眼对质量的感知涉及到整体语义理解、关注区域、创作意图理解等,很多视频处理操作会在较大的时空范围内影响质量,比如码率分配、ROI 编码;
3、质量评估数据集的量级和完备程度远低于分类识别等 CV 任务,而质量特征又非常复杂,因此需要某种显式地辅助质量特征提取的手段。一种方法是通过添加有序的质量样本或者利用质量评估的代理任务,进行数据增强及质量特征自监督学习。
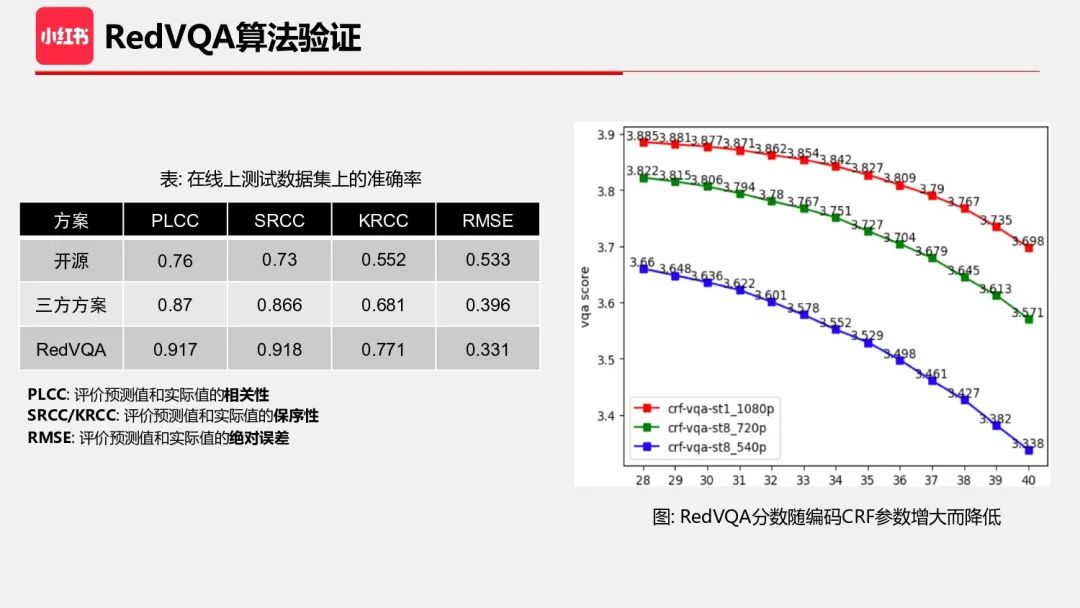
接下来是算法验证。首先介绍下质量评估领域的几个评价指标,PLCC 表示相关性,SRCC/KRCC 反映保序性,RMSE 反映绝对误差。RedVQA 的相关性在 0.9 左右,达到了可用的状态。此外,我们也验证了算法对质量劣化的敏感程度,首先需要构造一批质量保序的样本。我们通过编码参数的配置得到一系列不同分辨率和码率的样本,实际线上转码服务也是基于不同分辨率以及不同的编码参数来设计转码档位,这也贴合了线上的视频处理方式。上图可以看到,随着质量控制参数 CRF 的增大,质量分逐渐减小,符合预期,说明算法可以在一定程度上捕捉一些细微的质量损失。其次,我们也看到,同一个视频的不同分辨率版本,高分辨率质量整体优于低分辨率,这也符合预期。
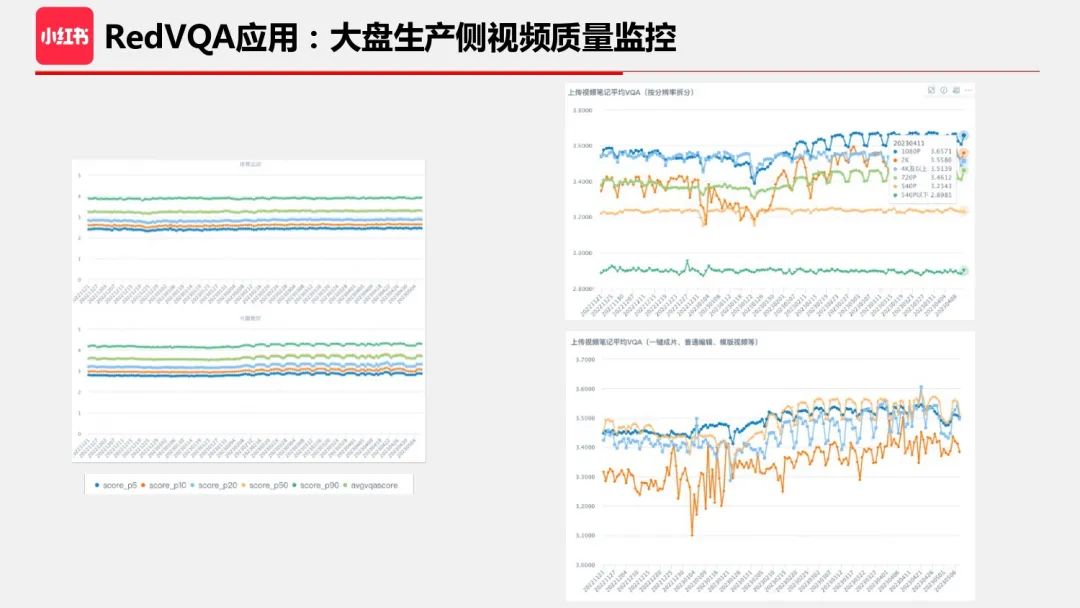
基于 RedVQA,我们实现了一个大盘质量监控看板,按照不同的维度统计视频的质量分。通过这些数据,有助于了解大盘整体的视频质量以及各拆分维度的质量。在有了数据后,后续的优化动作变得有据可依。图中展示了不同垂类的视频质量分,不同分位数的质量统计使得我们对生产侧视频的质量分布有了全局的掌握。右边上图是按照分辨率拆分的生产侧视频质量统计,右边下图是不同编辑方式的统计。
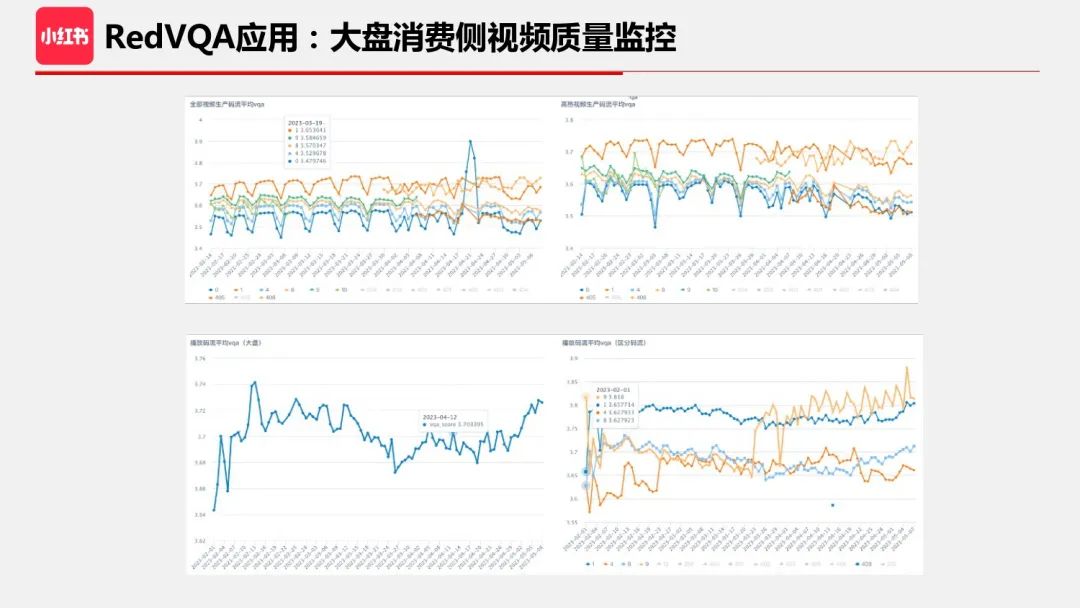
除了生产侧质量监控,消费侧视频质量监控更加重要,这决定了小红书对用户呈现的整体质量。消费侧比生产侧更复杂,一方面为了应对网速变化、成本控制以及端设备计算能力不同,每个上传视频都需要转码成不同的档位,通过播放控制来决策下发档位;另一方面,推荐系统会极大影响用户看到的视频内容,因此消费侧质量监控除了有助于了解实际用户看到的视频质量,也有助于我们对转码档位、播放以及推荐策略的优化。

下面介绍端云结合超分,也是今年我们降本增效的重点项目。
超分这个课题在学术界和工业界研究了很多年。但面向不同的业务场景和集成系统,端侧超分技术在业务目标和技术方向上存在很明显的区别。
比如面向一款新的硬件设备,只需要基于它的硬件加速器定制化地设计和优化算法即可。
对于视频业务和 APP,需要关注什么,如何获得显著收益,下面分享下我们的理解与实践。

对于视频 APP 来说,一个算法能不能落地,除了离线评测外,AB 实验数据是最终量化指标。我们希望获得 QoS 技术指标和 QoE 业务指标的正向收益,对于降本增效任务来说,带宽节省也是最重要的一个指标。而播放端视频算法落地,算法性能有极大的影响,算法耗时长可能引起卡顿、集成方式不对可能导致播放失败率和首帧时长增加。此外,用户设备机型及性能多种多样,通常在高端机上部署算法比较容易,如果想进一步覆盖到中低端机会非常困难。
最近两年业界在端侧超分大规模部署上有所突破,效果和覆盖率的进一步提升是大家都关注的问题。但我们也发现另一个问题待解决:通常算法效果验证是离线验证,而上线后很难再对画质算法效果进行量化,有没有 badcase 并不知道。而 QoE 指标是后验指标,而且从定义可以看到它不完全受到画质一个因素影响,因此 QoE 数据的好与坏,并不直接对应超分效果,也没法对算法后续迭代有指导作用。
还要说明的是,如果牺牲一部分收益,落地也会更简单,比如当我们针对一款高端机来设计端侧超分时,可以按照其计算性能打满算法复杂度从而提升效果,但在大盘上的收益就会非常有限。
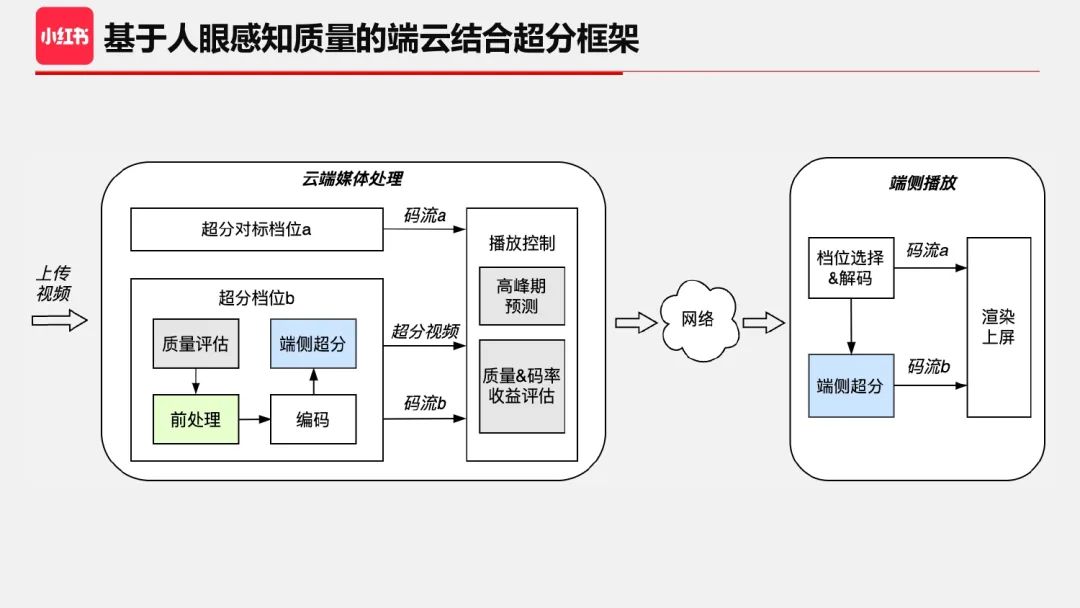
为了获取最大的收益,我们设计了一个基于人眼感知质量的端云结合超分方案来解决上述挑战,主要分为云端媒体处理和端侧播放两部分。用户在看视频时,对应的云端视频是有多个档位的,而不同的档位对应不同的决策。对超分来说,端侧超分算法部署在播放端解码之后,同时我们在云端为端侧超分定制化了的一个超分档位,定制化的目的是为了精细化控制超分开启策略且补偿最终端侧超分的效果。首先,我们通过带宽高峰期预测来控制超分档位下发的时间段;其次,我们通过质量&码率收益评估来更好地平衡用户体验与带宽收益,动态精细地量化出每个视频的质量问题及收益,避免超分效果不佳的视频产生超分档位,这里用到的质量评估即是前文提到的 RedVQA。

当我们设计超分算法时,首先要保证的是 QoS 数据无负向,要求开启超分后的各项技术指标不会显著劣化。而为了达到比较高的覆盖率,需要在中低端机上也能流畅的运行,这对于算法的性能提出了更高的要求。我们对算法的性能目标有个经验性的判断:计算复杂度应该在 GFLOPS 以内,耗时在 10ms 以内,功耗在 100mAh 以内,这样开启超分后的影响可能比较小。
在部署层面,因为 CPU 通常被多任务共享,如果算法过多占用 CPU 和内存也会引起 APP 崩溃,因此我们也要求算法尽量少占用 CPU 和内存。避免“碎片化”部署的意思是,我们不希望设计多个算法,以及针对多个处理器做优化,主要原因还是我们希望第一版算法能够快速验证和部署,尽快带来收益。当然我们后续也计划对部分机型设计更优的算法进行迭代。
下面的表格是一些算法调研总结,可以看到,公开文献中轻量深度学习超分算法 (SCSRN) 仍然有比较大的计算量,尽管网络模型看起来已经非常小了,而在VeriSilicon NPU 上的耗时是 19ms,如果在更通用的处理器上耗时会更大。给出一个计算量级的对比,5x5 高斯滤波的计算量大概在 100Mflops。
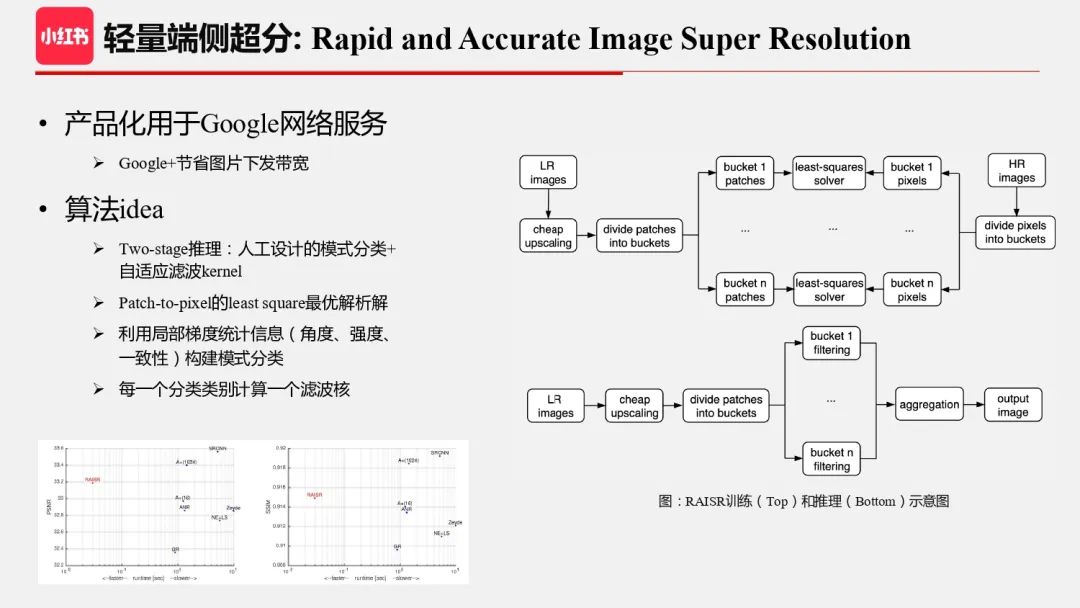
虽然可以进一步对上述算法进行模型压缩,不过我们总体判断在极轻量算法设计中,有图像理论指导的 low level 图像算法会比深度学习更高效,因此我们把目光投向超分领域更早的文献。这里列出一篇 Google 发表的很有启发意义的文献,被用于节省图片下发带宽。总体来说,这是一个 two-stage 算法,推理时先对图片 patch 进行模式分类,选出滤波 kernel,然后用这个 kernel 进行滤波,可以认为是一个内容自适应的滤波算法。在训练阶段,通过将相同分类的输入 patch 及对应的 ground truth pixel 集合在一起形成训练集,求解出 kernel。需要说明的是,这个算法的 kernel 求解不是通过梯度后向传播训练出来的,而是直接求的解析解。从左下图可以看到,这个算法在当时还是非常高效的,可以达到实时。
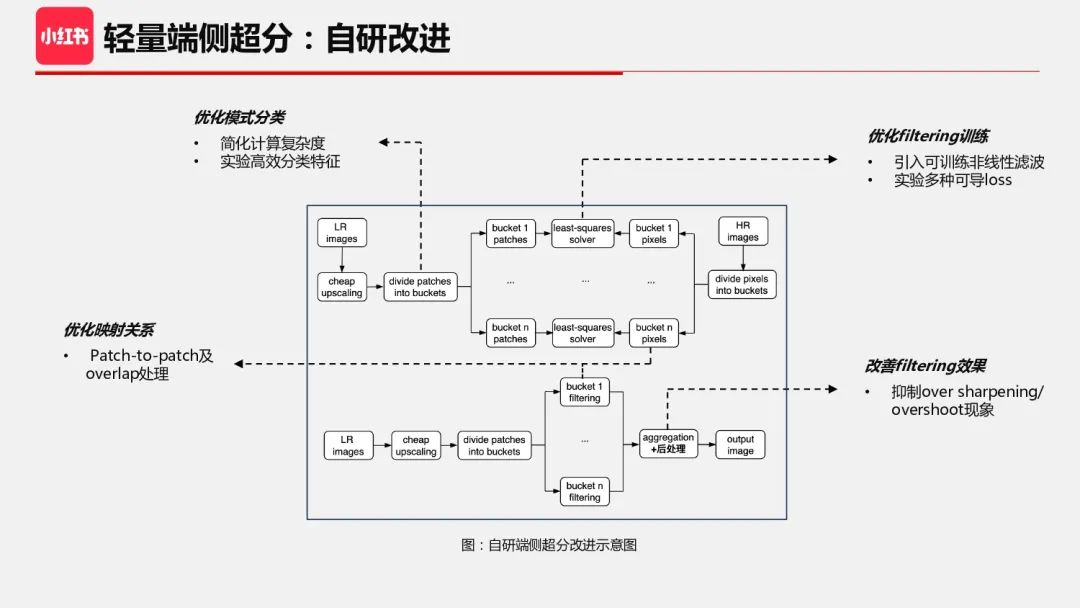
我们认识到这个算法的计算复杂度还是有点高,并且难以直接满足我们的性能目标,所以借鉴它的思路做了进一步的优化。下面几个点值得探究和改进:
1、模式分类还是有点复杂,为了降低复杂度,需要通过实验找到最有代表性的特征;
2、当前的 kernel 是解析解,效果上 与 L2 loss 相当,且是线性滤波,如果能引入可导梯度学习,就可以引入非线性滤波以及多种 loss;
3、当前算法是 Patch-to-pixel 映射,如果改成 Patch-to-patch 映射,可能计算会更高效;
4、最后推理结果可能出现一些画质问题,考虑加一些低计算复杂度后处理方法。
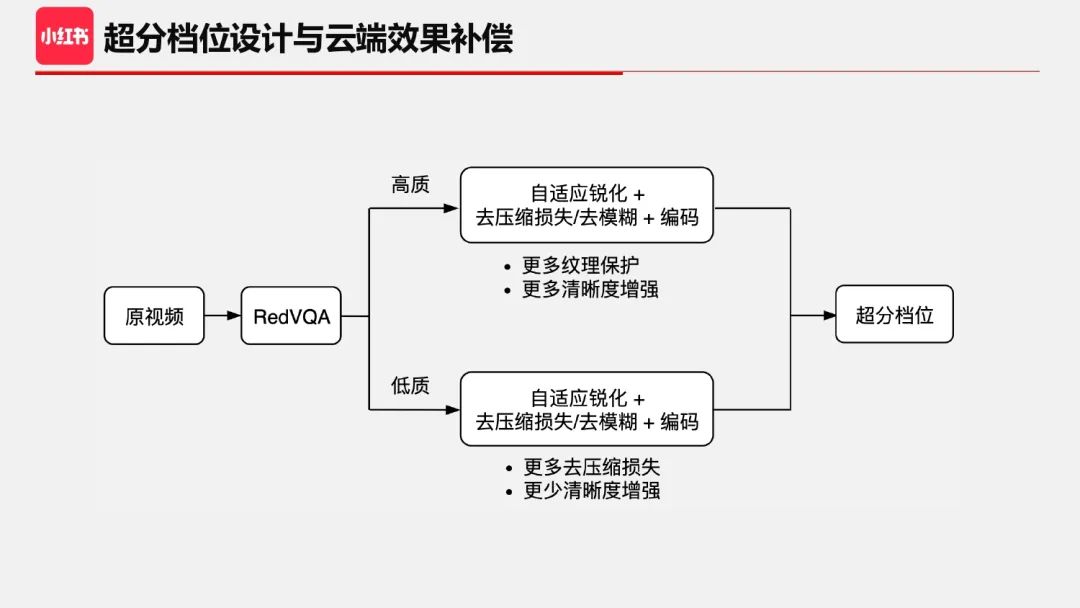
尽管在端侧超分算法上做了精心设计,但受限于其本身的计算量,能实现的效果还是有限。如果是一款终端产品研发,似乎也没有更好的办法。而在我们的视频处理架构中,端侧超分的输入视频或者下发的超分档位是由云端转码而来。通过定制化超分档位,可以有效提升和补偿端侧超分效果。实践中,我们基于 RedVQA 把原视频分成高质和低质。对于高质视频,可以通过云端增强算法有效提升超分后的纹理细节;对于低质视频,重点在于去除一些压缩损失,避免 artifact 放大。
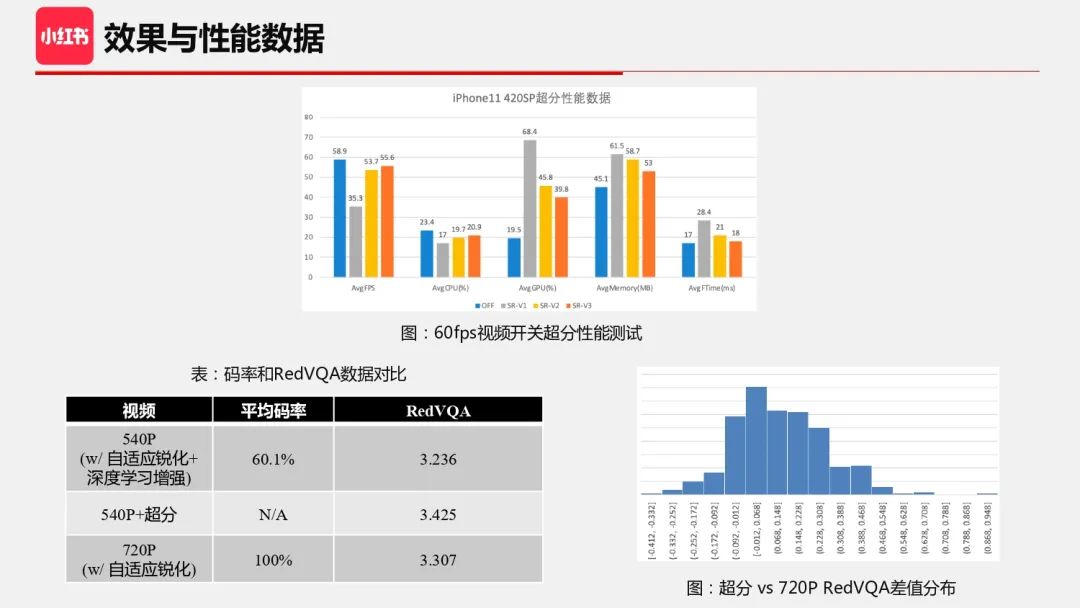
下面是整套方案的离线评测。上图是性能数据,对于一个 60fps 540P 的视频,开关超分帧率降得不多,GPU 占用增加 20%,内存增加 8M 左右(在撰写本文时,GPU 及内存占用经算法及性能优化后进一步降低),基本没有发热问题。下表是超分档位的码率和 RedVQA 质量分数据,其中超分档位是一个 540P 档位,我们用了自适应锐化以及深度学习增强来生成超分档位,对比的档位是一个 720P 档位,考虑计算时效以及计算成本,这个档位只带了自适应锐化。可以看到超分档位相比 720P 档位有 40% 的码率节省,平均质量分会小一点,而经过端侧超分后,平均质量分也超过了 720P 档位。进一步看下超分结果和 720P 视频的质量分差值分布,会发现并不是每个超分后视频质量分都高于 720P 视频。总的来说,RedVQA 提供了一种规模量化视频质量的方式,目前在画质优化方向上的准召率上还没有非常精细,不过实践中我们可以做一些权衡和策略来弥补。

以上是两个画质优化的例子。上图超分档位码率节省 45%,RedVQA 提升 0.529;下图码率节省 32%,RedVQA 提升 0.275。从这两个例子可以看到,超分视频同时兼具了画质收益和带宽收益。

再看两个劣化 case。上图超分档位码率节省 45%,RedVQA 降低 0.09;下图码率节省 46%,RedVQA 降低 0.13。我们也发现,并不是所有 RedVQA 降低都是画质劣化,但当码率节省过大时,比如这两个 case 都超过了 40% 的平均码率节省,判定为画质劣化的准确率就会提升。如前面所述,我们通过质量&码率收益评估可以更好的平衡用户体验与带宽成本,避免一些极端的劣化 case 影响用户体验。
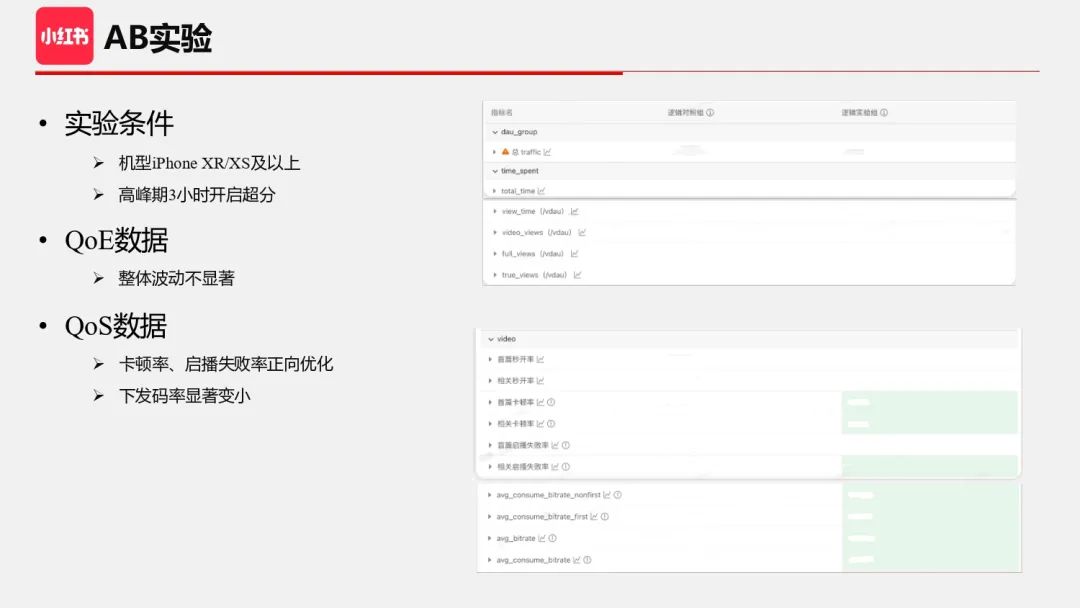
我们也做了 AB 实验佐证大盘上的表现。实验条件是基于 iPhone XR/XS 及以上开启超分,在带宽高峰 3 小时下发超分档位。实验结果还比较正向,QoE 数据整体波动,说明超分整体效果基本没大的问题,QoS 数据在卡顿率、启播失败率等技术指标上有显著优化,下发码率及带宽节省也比较显著。

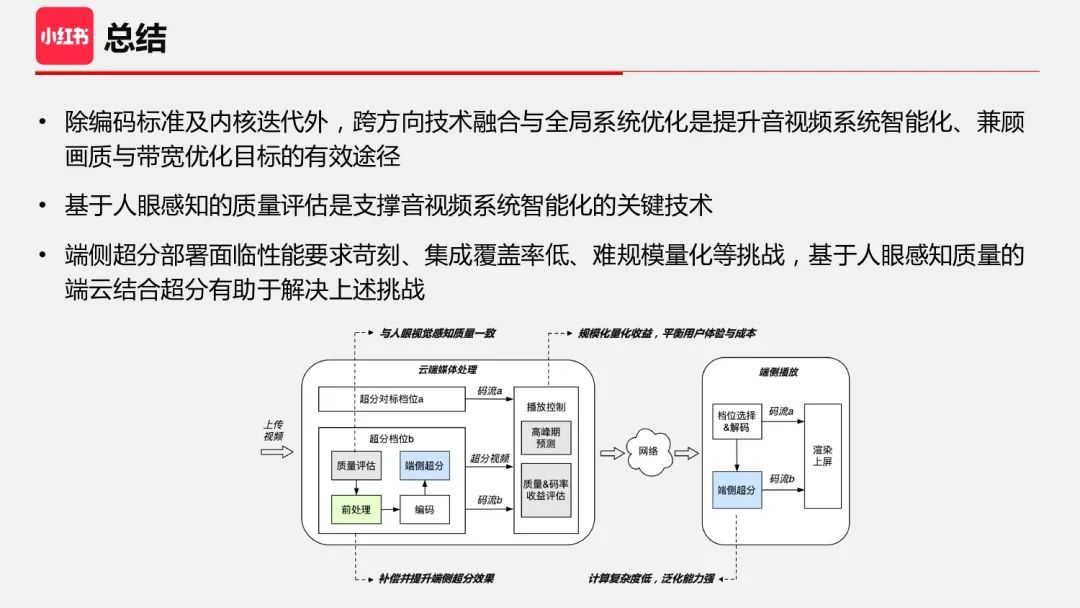
最后做下总结。在降本增效的大背景下,如何兼顾体验和成本是大家都很关注的问题。但对于音视频处理来说,体验和成本一直都是音视频处理的“一体两面”,而算法研发以及技术的迭代就是为了实现“既要又要”。从技术角度来说,我更关注如何提升音视频系统智能化这个话题,智能化的目标之一就是实现“既要又要”,另一个目标是实现更高的系统自动化程度及效率。另外,更好的跨方向技术融合以及全局系统优化能力可能是构建更智能音视频系统的有效途径,而基于人眼感知的质量评估是支撑音视频系统智能化的关键技术。最后,端侧超分部署面临性能要求苛刻、部署覆盖率低、难规模量化等挑战,我们设计了一个基于人眼感知质量的端云结合超分来解决这些挑战。

对于未来的展望,我们希望达到更智能的质量评估,在细粒度质量评估上有所提升,期待在画质优化方面发挥更好的作用。另外,未来我们会持续优化云端“窄带高清”视频转码,“窄带高清”的效果和收益会随着转码智能化程度的提升而持续扩大,但同时我们判断,整体收益提升的同时可能会伴随着画质分布方差也变大,融合了多种技术的“窄带高清”码流也对质量评估的准确性和泛化能力提出了更高的要求。
端云结合超分是一个非常有价值和可探索的方向,总的目标我们希望端云能够深度协同提升端侧超分后效果,从而无论在画质提升或带宽节省目标上带来更大的收益,这里说的“深度协同”包括整体方案端云划分合理、超分与编解码技术配合、端侧计算与播放策略适配等多个层面。具体来说,可以迭代更优的超分转码档位,设计更具表征能力和利用 Metadata 的超分模型,以及探索超分与编码的融合方案。
以上就是我的全部分享,谢谢!

剑寒
小红书音视频架构视频图像处理算法负责人。模式识别与智能系统专业博士,研究方向包括视频图像算法、异构计算优化等,擅长算法工程联合设计及优化。曾参与或主导“数字电视SoC设计与产业化”(国家科技重大专项)、4K 120 FPS HEVC芯片算法设计、拍照/短视频/直播画质算法研发和落地。
相关文章:
画质提升+带宽优化,小红书音视频团队端云结合超分落地实践
随着视频业务和短视频播放规模不断增长,小红书一直致力于研究:如何在保证提升用户体验质量的同时降低视频带宽成本? 在近日结束的音视频技术大会「LiveVideoStackCon 2023」上海站中,小红书音视频架构视频图像处理算法负责人剑寒向…...
【傅里叶级数与傅里叶变换】数学推导——3、[Part4:傅里叶级数的复数形式] + [Part5:从傅里叶级数推导傅里叶变换] + 总结
文章内容来自DR_CAN关于傅里叶变换的视频,本篇文章提供了一些基础知识点,比如三角函数常用的导数、三角函数换算公式等。 文章全部链接: 基础知识点 Part1:三角函数系的正交性 Part2:T2π的周期函数的傅里叶级数展开 P…...

第二章MyBatis入门程序
入门程序 创建maven程序 导入MyBatis依赖。pom.xml下导入如下依赖 <dependencies><dependency><groupId>org.mybatis</groupId><artifactId>mybatis</artifactId><version>3.5.6</version></dependency><dependen…...

AgentBench::AI智能体发展的潜在问题(二)
从历史上看,几乎每一种新技术的广泛应用都会在带来新机遇的同时引发很多新问题,AI智能体也不例外。从目前的发展看,AI智能体的发展可能带来的新问题可能包括如下方面: 第二是AI智能体的普及将有可能进一步加剧AI造成的技术性失业。…...
:逻辑运算符(上))
C++中的运算符总结(4):逻辑运算符(上)
C中的运算符总结(4):逻辑运算符(上) 8、逻辑运算 NOT、 AND、 OR 和 XOR 逻辑 NOT 运算用运算符!表示,用于单个操作数。表 1是逻辑 NOT 运算的真值表,这种运算将提供的布尔标记反转࿱…...
Flink安装与使用
1.安装准备工作 下载flink Apache Flink: 下载 解压 [dodahost166 bigdata]$ tar -zxvf flink-1.12.0-bin-scala_2.11.tgz 2.Flinnk的standalone模式安装 2.1修改配置文件并启动 修改,好像使用默认的就可以了 [dodahost166 conf]$ more flink-conf.yaml 启动 …...
CentOS系统环境搭建(七)——Centos7安装MySQL
centos系统环境搭建专栏🔗点击跳转 坦诚地说,本文中百分之九十的内容都来自于该文章🔗Linux:CentOS7安装MySQL8(详),十分佩服大佬文章结构合理,文笔清晰,我曾经在这篇文章…...

3.react useRef使用与常见问题
react useRef使用与常见问题 文章目录 react useRef使用与常见问题1. Dom操作: useRef()2. 函数组件的转发: React.forwardRef()3. 对普通值进行记忆, 类似于一个class的实例属性4. 结合useEffect,只在更新时触发FAQ 1. Dom操作: useRef() // 1. Dom操作: useRef()let app doc…...

Axios使用CancelToken取消重复请求
处理重复请求:没有响应完成的请求,再去请求一个相同的请求,会把之前的请求取消掉 新增一个cancelRequest.js文件 import axios from "axios" const cancelTokens {}export const addPending (config) > {const requestKey …...

九耶丨阁瑞钛伦特-Spring boot与Spring cloud 之间的关系
Spring Boot和Spring Cloud是两个相互关联的项目,它们可以一起使用来构建微服务架构。 Spring Boot是一个用于简化Spring应用程序开发的框架,它提供了自动配置、快速开发的特性,使得开发人员可以更加轻松地创建独立的、生产级别的Spring应用程…...
总结,由于顺丰的问题,产生了电脑近期一个月死机问题集锦
由于我搬家,我妈搞顺丰发回家,但是没有检查有没有坏,并且我自己由于不可抗力因素,超过了索赔时间,反馈给顺丰客服,说超过了造成了无法索赔的情况,现在总结发生了损坏配件有几件,显卡…...
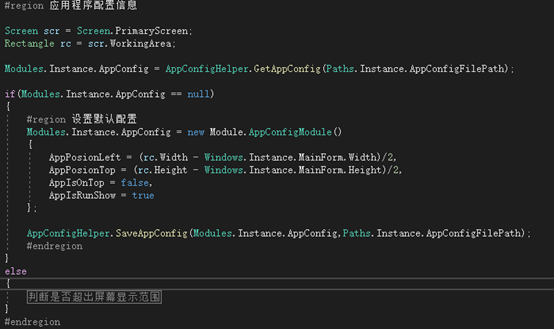
C#程序配置读写例子 - 开源研究系列文章
今天讲讲关于C#的配置文件读写的例子。 对于应用程序的配置文件,以前都是用的ini文件进行读写的,这个与现在的json类似,都是键值对应的,这次介绍的是基于XML的序列化和反序列化的读写例子。对于ini文件,操作系统已经提…...

Angular中的管道Pipes
Angular中的管道(Pipes)是一种强大的工具,它可以处理和转换数据,然后将其呈现在视图中。它们可以被用于排序、格式化和过滤数据等任务。在本文中,我们将介绍Angular中的管道以及如何使用它们来简化开发过程。 管道的基…...
React入门 jsx学习笔记
一、JSX介绍 概念:JSX是 JavaScript XML(HTML)的缩写,表示在 JS 代码中书写 HTML 结构 作用:在React中创建HTML结构(页面UI结构) 优势: 采用类似于HTML的语法,降低学…...

sqlserver数据库中把一张表中的数据复制到另一张表中
我们在使用ERP时经常会遇到,把老系统的单据直接拉过来使用,但是对应的数据却没有,为空,这时候就需要把老系统数据库里的数据复制一份到新系统里,(方法如下) 1、如果是整个表复制表达如下&#…...
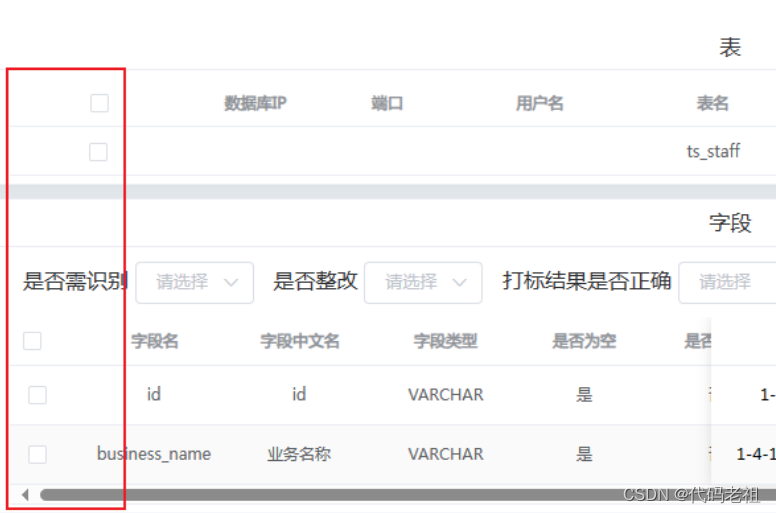
el-table 多个表格切换多选框显示bug
今天写了个功能,点击左侧的树做判断,一级树节点显示系统页面,二级树节点显示数据库页面,三级树节点显示表页面。 数据库页面和表页面分别有2个el-table ,上面的没有多选框,下面的有多选框 现在出现bug,在…...
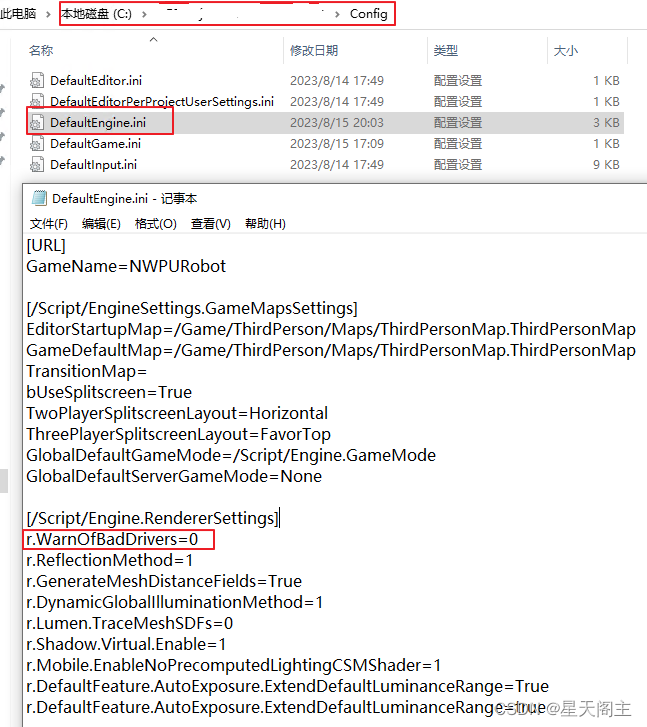
UE5.2程序发布及运行问题记录
发布后的程序默认是以全屏模式启动运行的,通过添加以下命令行参数,可实现程序的窗口模式运行: -ResX1280 -ResY720 -WINDOWED 发布后的程序,启动时,提示显卡驱动警告(如图1所示),但是…...

c语言strtol函数、strtod函数、strtoul函数浅悉
---------------- | strtol | ---------------- i.e. string to long long int strtol(const char *nptr, char **endptr, int base) strtol()会将nptr指向的字符串,根据参数base,按权转化为long int, 然后返回这个值。 参数base的范…...
Spark第三课
1.分区规则 1.分区规则 shuffle 1.打乱顺序 2.重新组合 1.分区的规则 默认与MapReduce的规则一致,都是按照哈希值取余进行分配. 一个分区可以多个组,一个组的数据必须一个分区 2. 分组的分区导致数据倾斜怎么解决? 扩容 让分区变多修改分区规则 3.HashMap扩容为什么必须…...

LangChain手记 Chains
整理并翻译自DeepLearning.AILangChain的官方课程:Chains(源代码可见) Chains 直译链,表达的意思更像是对话链,对话链的背后是思维链 LLM Chain(LLM链) 首先介绍了一个最简单的例子,…...
)
零基础转行网安:3个月学习路线+就业方向(2026最新)
零基础转行网安:3 个月学习路线 就业方向(2026 最新) 最近刷到很多小白在问: “2026 年零基础还能转行网安吗?”“没有学历、没有基础、不会代码,多久能找到工作?”“网上教程杂乱,…...

3个简单步骤让你的Windows桌面瞬间整洁:免费开源分区工具NoFences终极指南
3个简单步骤让你的Windows桌面瞬间整洁:免费开源分区工具NoFences终极指南 【免费下载链接】NoFences 🚧 Open Source Stardock Fences alternative 项目地址: https://gitcode.com/gh_mirrors/no/NoFences 你是否厌倦了桌面上杂乱无章的图标&…...
)
环境科学家都在偷偷用的NotebookLM技巧(2024中科院实测TOP5插件清单)
更多请点击: https://codechina.net 第一章:NotebookLM在环境科学研究中的范式变革 传统环境科学研究长期受限于多源异构数据整合困难、跨学科知识理解门槛高、因果推断缺乏可解释性支持等瓶颈。NotebookLM 作为基于用户自有文档构建的语义增强型AI协作…...

机械爪开发速查手册:从通信协议到PID控制的嵌入式实战指南
1. 项目概述:一份为开发者量身定制的“机械爪”速查手册最近在整理一个涉及硬件控制与嵌入式开发的项目时,我发现自己总是在几个关键的控制算法和通信协议上反复查阅资料,效率很低。后来在GitHub上偶然发现了kyrie-louy/openclaw-cheatsheet这…...

在Windows上安装APK的终极指南:5步掌握APK Installer工具
在Windows上安装APK的终极指南:5步掌握APK Installer工具 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾经想在Windows电脑上直接安装Android应用…...

3步搞定Windows安卓应用安装:告别模拟器的全新体验
3步搞定Windows安卓应用安装:告别模拟器的全新体验 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾经想在Windows电脑上运行手机应用,却…...

在多轮对话中感受Taotoken路由策略的稳定性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在多轮对话中感受Taotoken路由策略的稳定性 1. 引言:多轮对话的稳定性挑战 在构建依赖大语言模型的对话应用时&#x…...

猫抓浏览器扩展:三步实现网页视频自由下载的完整指南
猫抓浏览器扩展:三步实现网页视频自由下载的完整指南 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 你是否经常遇到这样的情况&#x…...

5分钟掌握猫抓扩展:浏览器视频下载终极指南
5分钟掌握猫抓扩展:浏览器视频下载终极指南 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 你是否经常遇到精彩的在线视频却无法下载保…...

Roborock 与 Ecovacs 机器人吸尘器多维度对比,谁更适合你?
选购机器人吸尘器:Roborock 与 Ecovacs 多维度对比,谁更适合你?当考虑购买机器人吸尘器时,面对众多品牌和型号,可能会让人无从下手。十年前,购买机器人吸尘器的选择范围还局限于少数几个竞争品牌࿰…...