机器学习:特征工程之特征预处理
目录
特征预处理
1、简述
2、内容
3、归一化
3.1、鲁棒性
3.2、存在的问题
4、标准化
⭐所属专栏:人工智能
文中提到的代码如有需要可以私信我发给你😊
特征预处理
1、简述

什么是特征预处理:scikit-learn的解释:
provides several common utility functions and transformer classes to change raw feature vectors into a representation that is more suitable for the downstream estimators.
翻译过来:通过一些转换函数将特征数据转换成更加适合算法模型的特征数据过程
详述:
特征预处理是机器学习和数据分析中的一个重要步骤,它旨在将原始数据转换为适合机器学习算法的形式,以提高模型的性能和稳定性。特征预处理涵盖了一系列数据转换和处理操作,用于清洗、归一化、缩放、编码等,以确保输入特征的质量和一致性。以下是特征预处理的一些常见操作和方法:
- 数据清洗和处理:处理缺失值、异常值和噪声,确保数据的完整性和准确性。常见的方法包括填充缺失值、平滑噪声、剔除异常值等。
- 特征缩放:将不同尺度的特征缩放到相似的范围,以避免某些特征对模型的影响过大。常见的特征缩放方法有标准化(Z-score标准化)和归一化(Min-Max缩放)。
- 特征选择:选择对目标变量有重要影响的特征,减少维度和噪声,提高模型的泛化能力。常见的特征选择方法有基于统计指标的方法(如方差选择、卡方检验)、基于模型的方法(如递归特征消除)、以及基于嵌入式方法(如L1正则化)。
- 特征转换:将原始特征转换为更适合模型的形式,如多项式特征、交叉特征、主成分分析(PCA)等。这可以帮助模型更好地捕捉数据的模式和结构。
- 特征编码:将非数值型的特征转换为数值型的形式,以便机器学习算法处理。常见的编码方法有独热编码(One-Hot Encoding)和标签编码(Label Encoding)。
- 文本特征提取:将文本数据转换为数值特征表示,如词袋模型、TF-IDF特征提取等,以便用于文本分析和机器学习。
- 特征组合和交叉:将多个特征进行组合或交叉,创建新的特征以捕捉更多的信息。这有助于挖掘特征之间的相互作用。
- 数据平衡处理:在处理不平衡数据集时,可以使用欠采样、过采样等方法来平衡正负样本的数量,以避免模型偏向于多数类。
特征预处理的目标是使数据更适合机器学习模型,提高模型的性能和稳定性,并且能够更好地捕捉数据的特征和模式。正确的特征预处理可以显著影响机器学习模型的结果和效果。不同的数据类型和问题可能需要不同的特征预处理方法,因此在进行特征预处理时需要根据具体情况进行选择和调整。
2、内容
包含内容:数值型数据的无量纲化:归一化、标准化 (二者放在后面详述)
什么是无量纲化:
无量纲化(Dimensionality Reduction)是特征工程的一部分,指的是将数据特征转换为合适的尺度或形式,以便更好地适应机器学习算法的要求。无量纲化的目的是减少特征的维度,同时保留数据中的重要信息,从而降低计算成本、避免维度灾难,并提高模型的性能和泛化能力。
无量纲化可以分为两种常见的方法:
①特征缩放(Feature Scaling):特征缩放是将特征的数值范围调整到相似的尺度,以便机器学习算法更好地工作。特征缩放的常见方法包括归一化和标准化。
归一化(Min-Max Scaling):将特征缩放到一个特定的范围,通常是[0, 1]。
标准化(Z-score Scaling):将特征缩放为均值为0,标准差为1的分布。
②降维(Dimensionality Reduction):降维是将高维特征空间映射到低维空间,以减少特征数量并去除冗余信息,从而提高计算效率和模型性能。常见的降维方法包括主成分分析(PCA)和线性判别分析(LDA)等。
主成分分析(PCA):通过线性变换将原始特征投影到新的坐标轴上,使得投影后的数据具有最大的方差。这些新坐标轴称为主成分,可以按照方差的大小选择保留的主成分数量,从而降低数据的维度。
线性判别分析(LDA):在降维的同时,尽可能地保留类别之间的区分性信息,适用于分类问题。
无量纲化可以帮助解决特征维度不一致、尺度不同等问题,使得机器学习算法能够更准确地学习数据的模式和结构。选择适当的无量纲化方法取决于数据的特点、问题的要求以及模型的性能。
特征预处理使用的API:sklearn.preprocessing
为什么我们要进行归一化/标准化?
特征的单位或者大小相差较大,或者某特征的方差相比其他的特征要大出几个数量级,容易影响(支配)目标结果,使得一些算法无法学习到其它的特征
3、归一化
定义:通过对原始数据进行变换把数据映射到(默认为[0,1])之间
公式:
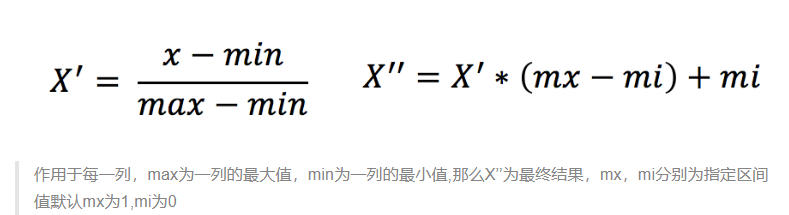
API:
sklearn.preprocessing.MinMaxScaler (feature_range=(0,1)… )
MinMaxScalar.fit_transform(X)
X:numpy array格式的数据[n_samples,n_features]
返回值:转换后的形状相同的array
下面分析会用到一组数据,名为dating.txt。展现如下:


实现:
关键代码解读:
transfer = MinMaxScaler(feature_range=(2, 3)):
实例化一个MinMaxScaler转换器对象,其中feature_range=(2, 3)表示将数据缩放到范围为[2, 3]之间。
data = transfer.fit_transform(data[['milage', 'Liters', 'Consumtime']]):
使用fit_transform方法将选定的特征('milage', 'Liters', 'Consumtime')进行最小-最大归一化处理。
fit_transform方法首先计算出特征的最小值和最大值,然后将数据进行线性缩放,使其在指定的范围内。
# -*- coding: utf-8 -*-
# @Author:︶ㄣ释然
# @Time: 2023/8/15 21:52
import pandas as pd
from sklearn.preprocessing import MinMaxScaler # 最大最小值归一化转换器'''
归一化处理。
关键代码解读:transfer = MinMaxScaler(feature_range=(2, 3)):实例化一个MinMaxScaler转换器对象,其中feature_range=(2, 3)表示将数据缩放到范围为[2, 3]之间。data = transfer.fit_transform(data[['milage', 'Liters', 'Consumtime']]):使用fit_transform方法将选定的特征('milage', 'Liters', 'Consumtime')进行最小-最大归一化处理。fit_transform方法首先计算出特征的最小值和最大值,然后将数据进行线性缩放,使其在指定的范围内。
'''
def min_max_demo():"""归一化演示"""data = pd.read_csv("data/dating.txt",delimiter="\t")print(data)# 1、实例化一个转换器类transfer = MinMaxScaler(feature_range=(2, 3))# 2、调用fit_transformdata = transfer.fit_transform(data[['milage', 'Liters', 'Consumtime']])print("最小值最大值归一化处理的结果:\n", data)if __name__ == '__main__':min_max_demo()打印结果:

手动计算(取前9行数据):

计算坐标为(0,0)的元素,总的计算流程为:[(40920-14488)/(75136-14488)] * (3-2)+2 = 2.435826408≈2.43582641
该结果与程序吻合!!
3.1、鲁棒性
鲁棒性(Robustness)是指在面对异常值、噪声和其他不完美情况时,系统能够继续正常工作并保持良好性能的能力。在数据分析、统计学和机器学习中,鲁棒性是一个重要的概念,指的是算法或方法对异常值和数据扰动的敏感程度。一个鲁棒性强的方法在存在异常值或数据变动时能够保持稳定的性能,而鲁棒性较差的方法可能会对异常值产生过度敏感的响应。
在数据处理和分析中,鲁棒性的重要性体现在以下几个方面:
- 异常值处理:鲁棒性的方法能够有效地识别和处理异常值,而不会因为异常值的存在导致结果的严重偏差。
- 模型训练:在机器学习中,使用鲁棒性的算法可以减少异常值对模型训练的影响,防止过拟合,并提高模型的泛化能力。
- 特征工程:在特征工程过程中,选择鲁棒性的特征提取方法可以确保提取的特征对异常值不敏感。
- 统计分析:鲁棒性的统计方法能够减少异常值对统计分析结果的影响,使得分析结果更可靠。
一些常见的鲁棒性方法包括:
- 中位数(Median):在数据中,中位数对异常值的影响较小,相对于平均值具有更强的鲁棒性。
- 百分位数(Percentiles):百分位数可以帮助识别数据分布的位置和离散程度,对异常值的影响较小。
- Z-score标准化:Z-score标准化将数据转化为均值为0、标准差为1的分布,能够对抗异常值的影响。
- IQR(四分位距)方法:使用四分位距来定义异常值的界限,对极端值具有一定的容忍度。
- 鲁棒性回归:使用鲁棒性回归方法可以减少异常值对回归模型的影响。
总之,鲁棒性是数据分析和机器学习中一个重要的考虑因素,能够保证在现实世界中面对多样性和不确定性时,方法和模型仍能保持有效性和稳定性。
3.2、存在的问题
使用归一化处理,如果数据中异常点较多,会有什么影响?
在数据中存在较多异常点的情况下,使用归一化处理可能会受到一些影响。归一化是将数据缩放到特定范围内的操作,但异常点的存在可能会导致以下影响:
- 异常点的放大:归一化可能会导致异常点在缩放后的范围内被放大。如果异常点的值较大,归一化后它们可能会被映射到特定范围的边缘,从而导致数据在正常值范围内分布不均匀。
- 降低数据的区分性:异常点可能导致归一化后的数据失去一部分原始数据的分布特征。数据特征的差异性可能被模糊化,从而降低模型的区分能力和准确性。
- 对模型的影响:在机器学习中,模型通常会受到输入数据的影响。异常点可能会干扰模型的训练,使其难以捕捉正常数据的模式,导致模型的性能下降。
- 过拟合的风险:如果异常点被放大或影响了数据的分布,模型可能会过拟合异常点,而忽略了正常数据的重要特征。
为了应对异常点对归一化处理的影响,可以考虑以下策略:
- 异常点检测和处理:在进行归一化之前,首先要进行异常点检测,并根据异常点的性质和数量采取适当的处理措施。可以选择删除异常点、使用异常点修正方法或将异常点映射到更合理的范围。
- 使用鲁棒性方法:某些归一化方法对异常点的影响较小,例如中心化和缩放(例如Z-score标准化),它们对异常值的影响较小,因为它们基于数据的分布特性。
- 尝试其他特征预处理方法:如果异常点较多且归一化效果不好,可以尝试其他特征预处理方法,如对数变换、截断、缩尾等。
总之,处理异常点是特征预处理的重要步骤,需要根据数据的特点和问题的需求来选择适当的策略。
这里使用标准化解决这个问题
4、标准化
定义:通过对原始数据进行变换把数据变换到均值为0,标准差为1范围内
公式:

标准差:

所以实际上标准化的公式为:


参数如下:
x为当前值
mean为平均值
N 表示数据的总个数
xi 表示第 i 个数据点
μ 表示数据的均值
归一化的异常点:

标准化的异常点:

对于归一化来说:如果出现异常点,影响了最大值和最小值,那么结果显然会发生改变
对于标准化来说:如果出现异常点,由于具有一定数据量,少量的异常点对于平均值的影响并不大,从而方差改变较小。
API:
sklearn.preprocessing.StandardScaler( )
处理之后每列来说所有数据都聚集在均值0附近标准差差为1
StandardScaler.fit_transform(X)
X:numpy array格式的数据[n_samples,n_features]
返回值:转换后的形状相同的array
import pandas as pd
from sklearn.preprocessing import StandardScaler # 标准化'''
sklearn.preprocessing.StandardScaler( ) 处理之后每列来说所有数据都聚集在均值0附近标准差差为1StandardScaler.fit_transform(X)X:numpy array格式的数据[n_samples,n_features]返回值:转换后的形状相同的array
'''
def stand_demo():"""标准化演示:return: None"""data = pd.read_csv("data/dating.txt", delimiter="\t")print(data)# 1、实例化一个转换器类transfer = StandardScaler()# 2、调用fit_transformdata = transfer.fit_transform(data[['milage', 'Liters', 'Consumtime']])print("标准化的结果:\n", data)print("每一列特征的平均值:\n", transfer.mean_)print("每一列特征的方差:\n", transfer.var_)if __name__ == '__main__':stand_demo()输出结果:

手动计算验证(取前8行数据),公式回顾如下:
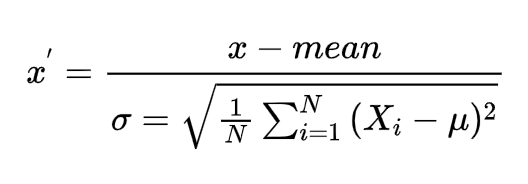
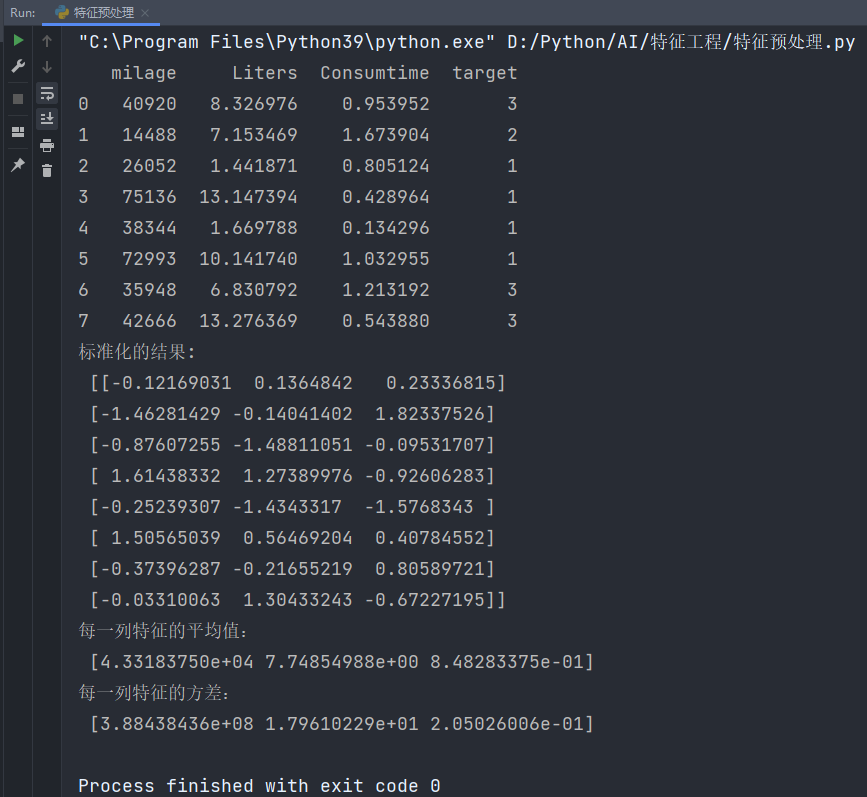
手动计算坐标为(0,0)的数据的标准化数据:
40920-43318.375=-2398.375
N=8,μ=43318.375 -> (40920-43318.375)^2+(14488-43318.375)^2+(26052-43318.375)^2+(75136-43318.375)^2+(38344-43318.375)^2+(72993-43318.375)^2+(35948-43318.375)^2+(42666-43318.375)^2=3107507487.875
3107507487.875 / 8 = 388438435.984375
根号下388438435.984375 = 19708.84156880802
最终:
x-mean=-2398.375
标准差=19708.84156880802
最后标准化后的数据结果为:-2398.375 / 19708.84156880802 = 0.121690307957813291 ≈ 0.12169031
与程序结果完全吻合!
标准化总结:在已有样本足够多的情况下比较稳定,适合现代嘈杂大数据场景。
相关文章:
机器学习:特征工程之特征预处理
目录 特征预处理 1、简述 2、内容 3、归一化 3.1、鲁棒性 3.2、存在的问题 4、标准化 ⭐所属专栏:人工智能 文中提到的代码如有需要可以私信我发给你😊 特征预处理 1、简述 什么是特征预处理:scikit-learn的解释: provide…...
高级艺术二维码制作教程
最近不少关于二维码制作的,而且都是付费。大概就是一个好看的二维码,扫描后跳转网址。本篇文章使用Python来实现,这么简单花啥钱呢?学会,拿去卖便宜点吧。 文章目录 高级二维码制作环境安装普通二维码艺术二维码动态 …...

每日一题leetcode--使循环数组所有元素相等的最少秒数
相当于扩散,每个数可以一次可以扩散到左右让其一样,问最少多少次可以让整个数组都变成一样的数 使用枚举,先将所有信息存到hash表中,然后逐一进行枚举,计算时间长短用看下图 考虑到环形数组,可以把首项n放…...
tauri-react:快速开发跨平台软件的架子,支持自定义头部UI拖拽移动和窗口阴影效果
tauri-react 一个使用 taurireacttsantd 开发跨平台软件的模板,支持窗口头部自定义和窗口阴影,不用再自己做适配了,拿来即用,非常 nice。而且已经封装好了 tauri 的 http 请求工具,省去很多弯路。 开原地址ÿ…...

k8s 自身原理之 Service
好不容易,终于来到 k8s 自身的原理之 关于 Service 的一部分了 前面我们用 2 个简图展示了 pod 之间和 pod 与 node 之间是如何通信息的,且通信的数据包是不会经过 NAT 网络地址转换的 那么 Service 又是如何实现呢? Service 我们知道是用…...

arduino Xiao ESP32C3 oled0.96 下雪花
Xiao ESP32C3使用oled 0.96实现下雪的功能 雪花下落的时候, 随机生成半径和位置 sandR和sandX,sandY 保存雪花下落位置的时候, 将其周边一圈设置为-1, 标记为有雪花 其他雪花下落的时候, 其他雪花的一圈如果遇到-1, 则停止下落, 并重复2 #include "oled.h" void …...

ElasticSearch索引库、文档、RestClient操作
文章目录 一、索引库1、mapping属性2、索引库的crud 二、文档的crud三、RestClient 一、索引库 es中的索引是指相同类型的文档集合,即mysql中表的概念 映射:索引中文档字段的约束,比如名称、类型 1、mapping属性 mapping映射是对索引库中文…...
)
Effective Java 案例分享(九)
46、使用无副作用的Stream 本章节主要举例了Stream的几种用法。 案例一: // Uses the streams API but not the paradigm--Dont do this! Map<String, Long> freq new HashMap<>(); try (Stream<String> words new Scanner(file).tokens()) …...
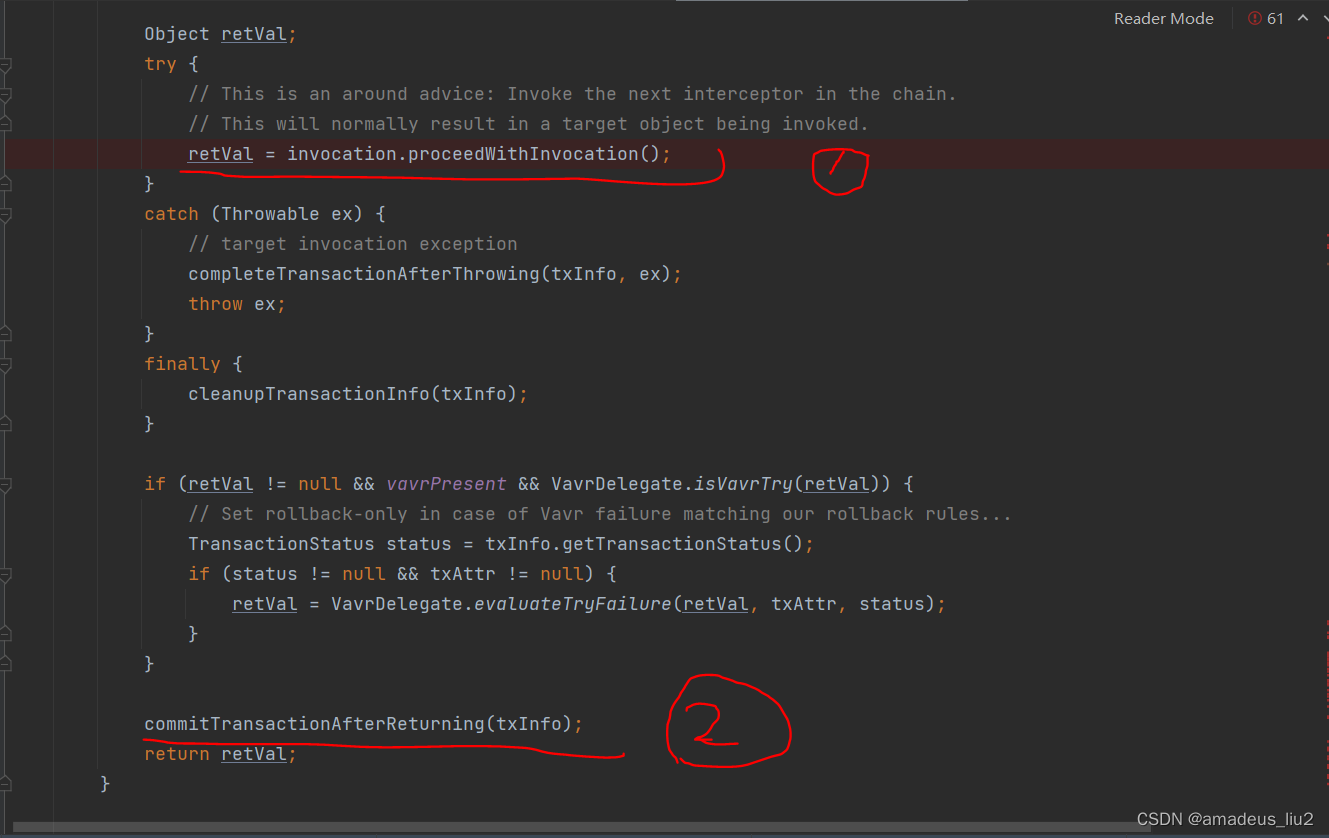
SpringBoot复习:(56)使用@Transactional注解标记的方法的执行流程
首先,如果在某个类或某个方法被标记为Transactional时,Spring boot底层会在创建这个bean时生成代理对象(默认使用cglib) 示例: 当调用studentService的addStudent方法时,会直接跳到CglibAopProxy类去执行intercept方…...
JVM——引言+JVM内存结构
引言 什么是JVM 定义: Java VirtualMachine -java 程序的运行环境 (ava 二进制字节码的运行环境) 好处: 一次编写,到处运行自动内存管理,垃圾回收功能数组下标越界检查,多态 比较: jvm jre jdk 学习jvm的作用 面试理解底层实现原理中…...
图形检测)
open cv学习 (十)图形检测
图形检测 demo1 # 绘制几何图像的轮廓 import cv2img cv2.imread("./shape1.png")gray cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 将图像二值化 t, binary cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY)# 检测图像中的所有轮廓 contours, hierarchy cv2.f…...

【C语言】字符函数和字符串函数
目录 1.求字符串长度strlen 2.长度不受限制的字符串函数 字符串拷贝strcpy 字符串追加strcat 字符串比较strcmp 3.长度受限制的字符串函数介绍strncpy strncat 编辑strncmp 4.字符串查找strstr 5.字符串分割strtok 6.错误信息报告 strerror perror 7.字符分类函…...
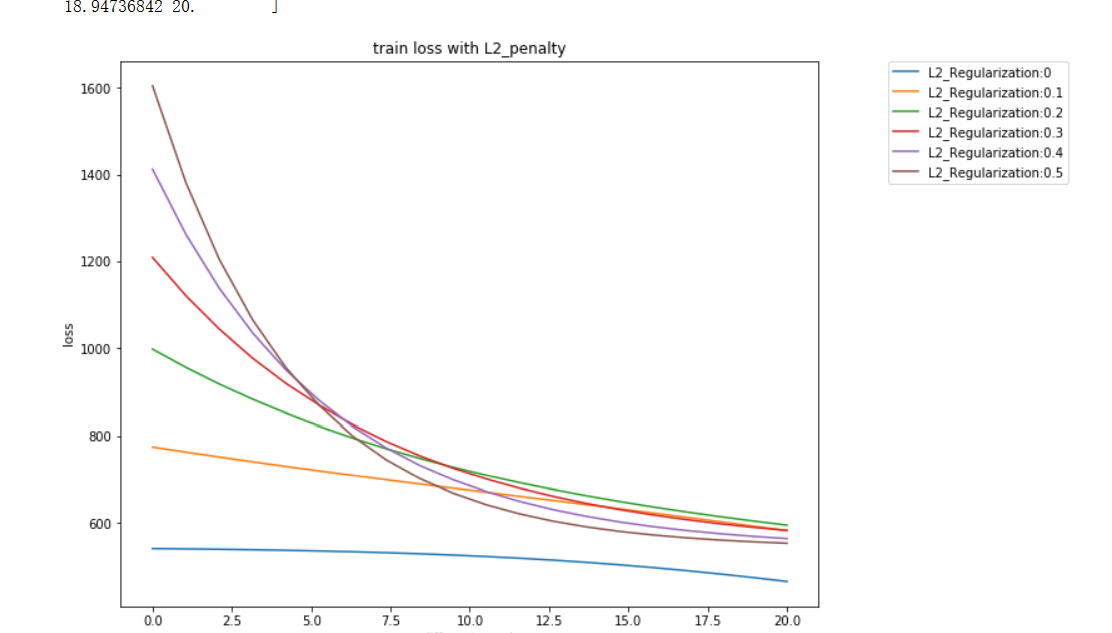
前馈神经网络正则化例子
直接看代码: import torch import numpy as np import random from IPython import display from matplotlib import pyplot as plt import torchvision import torchvision.transforms as transforms mnist_train torchvision.datasets.MNIST(root…...

spring的核心技术---bean的生命周期加案例分析详细易懂
目录 一.spring管理JavaBean的初始化过程(生命周期) Spring Bean的生命周期: 二.spring的JavaBean管理中单例模式及原型(多例)模式 2.1 . 默认为单例,但是可以配置多例 2.2.举例论证 2.2.1 默认单例 2.2…...

【Maven教程】(一)入门介绍篇:Maven基础概念与其他构建工具:理解构建过程与Maven的多重作用,以及与敏捷开发的关系 ~
Maven入门介绍篇 1️⃣ 基础概念1.1 构建1.2 maven对构建的支持1.3 Maven的其他作用 2️⃣ 其他构建工具2.1 IDE2.2 Make2.3 Ant2.4 Jenkins 3️⃣ Maven与敏捷开发🌾 总结 1️⃣ 基础概念 "Maven"可以翻译为 “知识的积累者” 或 “专家”。这个词源于波…...
今天,谷歌Chrome浏览器部署抗量子密码
谷歌已开始部署混合密钥封装机制(KEM),以保护在建立安全的 TLS 网络连接时共享对称加密机密。 8月10日,Chrome 浏览器安全技术项目经理Devon O’Brien解释说,从 8 月 15 日发布的 Chrome 浏览器 116 开始,谷…...
SUMO traci接口控制电动车前往充电站充电
首先需要创建带有停车位的充电站(停车场和充电站二合一),具体参考我的专栏中其他文章。如果在仿真的某个时刻,希望能够控制电动车前往指定的充电站充电,并且在完成充电后继续前往车辆原来的目的地,那么可以使用以下API:…...

现代CSS中的换行布局技术
在现代网页设计中,为了适应不同屏幕尺寸和设备类型,换行布局是一项重要的技术。通过合适的布局技术,我们可以实现内容的自适应和优雅的排版。本文将介绍CSS中几种常见的换行布局技术,探索它们的属性、代码示例和解析,帮…...

简单理解Python中的深拷贝与浅拷贝
I. 简介 深拷贝会递归的创建一个完全独立的对象副本,包括所有嵌套的对象,而浅拷贝只复制嵌套对象的引用,不复制嵌套对象本身。 简单来说就是两者都对原对象进行了复制,因此使用is运算符来比较新旧对象时,返回的都是F…...

C++之std::pair<uint64_t, size_t>应用实例(一百七十七)
简介: CSDN博客专家,专注Android/Linux系统,分享多mic语音方案、音视频、编解码等技术,与大家一起成长! 优质专栏:Audio工程师进阶系列【原创干货持续更新中……】🚀 人生格言: 人生…...

Windows上运行Swift代码的三种实战路径
1. 为什么Windows开发者需要Swift? Swift作为苹果生态的主力编程语言,近年来在服务端开发、机器学习等领域的应用越来越广泛。但很多刚接触Swift的Windows开发者会发现:官方文档里压根没提Windows支持!这其实是因为Swift最初就是…...

Kubernetes上Jenkins全栈部署:动态Agent与生产环境调优指南
1. 项目概述:一个面向Kubernetes的Jenkins全栈部署方案在容器化和云原生技术成为主流的今天,如何高效、稳定地部署和管理持续集成/持续交付(CI/CD)流水线,是每个开发团队和运维工程师必须面对的课题。传统的单体Jenkin…...

Noto Emoji:专业解决跨平台表情符号渲染难题的终极方案
Noto Emoji:专业解决跨平台表情符号渲染难题的终极方案 【免费下载链接】noto-emoji Noto Emoji fonts 项目地址: https://gitcode.com/gh_mirrors/no/noto-emoji 在现代数字通信中,表情符号已成为不可或缺的语言元素,然而跨平台表情符…...

OCT-X算法:早期胃癌AI检测的技术突破与应用
1. OCT-X算法:早期胃癌AI检测的技术突破在医疗影像分析领域,胃癌早期检测一直面临着巨大挑战。传统内窥镜检查依赖医生经验判断,存在主观性强、漏诊率高等问题。我们团队开发的OCT-X(One Class Twin Cross Learning)算…...

Arm CoreLink PCK-600电源管理套件解析与应用实践
1. Arm CoreLink PCK-600电源控制套件概述在现代SoC设计中,电源管理已经成为一个关键的技术挑战。随着移动设备和物联网应用的普及,如何在保证性能的同时最大限度地降低功耗,成为芯片设计者面临的核心问题。Arm CoreLink PCK-600电源控制套件…...

Agent Framework 中的 Workflow Composition
在前面的文章中,我们已经介绍了 Agent Framework 中如何定义流程节点,以及 Workflow 的流式执行事件。 如果你对这些概念还不太熟悉,可以先回顾上一篇文章: Agent Framework 定义流程节点以及节点的流式输出 这一节我们来介绍 Wor…...

Sophia优化器:二阶曲率感知如何加速大模型训练与调参
1. 项目概述:当优化器遇上“二阶”智慧最近在复现一些前沿的论文实验时,我又一次被优化器的选择给卡住了。AdamW虽然稳,但在某些超大规模模型或特定任务上,总觉得收敛速度不够快,调参又是个玄学。就在我对着损失曲线发…...

基于ESP32-S2与MAX17048的物联网电池监控系统设计与实现
1. 项目概述与核心价值 对于任何一个需要长期部署在户外的物联网设备,比如环境监测站、智能农业传感器或者远程摄像头,最让人头疼的问题往往不是代码bug,而是“它什么时候会没电?”。你不可能天天跑现场去检查,而设备…...

如何用FontForge从零设计专业字体?揭秘字体编辑器的核心玩法
如何用FontForge从零设计专业字体?揭秘字体编辑器的核心玩法 【免费下载链接】fontforge Free (libre) font editor for Windows, Mac OS X and GNULinux 项目地址: https://gitcode.com/gh_mirrors/fo/fontforge 想象一下,你手写的签名、设计的l…...

Arm Neoverse CMN-650架构解析与性能优化
1. Arm Neoverse CMN-650架构概览CMN-650是Arm Neoverse平台中的第三代一致性网格网络(Coherent Mesh Network)互连技术,专为高性能计算和数据中心场景设计。作为SoC内部的核心互连架构,它承担着连接处理器集群、内存控制器、I/O子系统以及加速器单元的关…...