fnn手动实现和nn实现(包括3种激活函数、隐藏层)
原文网址:https://blog.csdn.net/m0_52910424/article/details/127819278
fnn手动实现:
import time
import matplotlib.pyplot as plt
import numpy as np
import torch
import torch.nn as nn
import torchvision
from torch.nn.functional import cross_entropy, binary_cross_entropy
from torch.nn import CrossEntropyLoss
from torchvision import transforms
from sklearn import metrics
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 如果有gpu则在gpu上计算 加快计算速度
print(f'当前使用的device为{device}')
# 数据集定义
# 构建回归数据集合 - traindataloader1, testdataloader1
data_num, train_num, test_num = 10000, 7000, 3000 # 分别为样本总数量,训练集样本数量和测试集样本数量
true_w, true_b = 0.0056 * torch.ones(500,1), 0.028
features = torch.randn(data_num, 500)
labels = torch.matmul(features,true_w) + true_b # 按高斯分布
labels += torch.tensor(np.random.normal(0,0.01,size=labels.size()),dtype=torch.float32)
# 划分训练集和测试集
train_features, test_features = features[:train_num,:], features[train_num:,:]
train_labels, test_labels = labels[:train_num], labels[train_num:]
batch_size = 128
traindataset1 = torch.utils.data.TensorDataset(train_features,train_labels)
testdataset1 = torch.utils.data.TensorDataset(test_features, test_labels)
traindataloader1 = torch.utils.data.DataLoader(dataset=traindataset1,batch_size=batch_size,shuffle=True)
testdataloader1 = torch.utils.data.DataLoader(dataset=testdataset1,batch_size=batch_size,shuffle=True)# 构二分类数据集合
data_num, train_num, test_num = 10000, 7000, 3000 # 分别为样本总数量,训练集样本数量和测试集样本数量
# 第一个数据集 符合均值为 0.5 标准差为1 得分布
features1 = torch.normal(mean=0.2, std=2, size=(data_num, 200), dtype=torch.float32)
labels1 = torch.ones(data_num)
# 第二个数据集 符合均值为 -0.5 标准差为1的分布
features2 = torch.normal(mean=-0.2, std=2, size=(data_num, 200), dtype=torch.float32)
labels2 = torch.zeros(data_num)# 构建训练数据集
train_features2 = torch.cat((features1[:train_num], features2[:train_num]), dim=0) # size torch.Size([14000, 200])
train_labels2 = torch.cat((labels1[:train_num], labels2[:train_num]), dim=-1) # size torch.Size([6000, 200])
# 构建测试数据集
test_features2 = torch.cat((features1[train_num:], features2[train_num:]), dim=0) # torch.Size([14000])
test_labels2 = torch.cat((labels1[train_num:], labels2[train_num:]), dim=-1) # torch.Size([6000])
batch_size = 128
# Build the training and testing dataset
traindataset2 = torch.utils.data.TensorDataset(train_features2, train_labels2)
testdataset2 = torch.utils.data.TensorDataset(test_features2, test_labels2)
traindataloader2 = torch.utils.data.DataLoader(dataset=traindataset2,batch_size=batch_size,shuffle=True)
testdataloader2 = torch.utils.data.DataLoader(dataset=testdataset2,batch_size=batch_size,shuffle=True)# 定义多分类数据集 - train_dataloader - test_dataloader
batch_size = 128
# Build the training and testing dataset
traindataset3 = torchvision.datasets.FashionMNIST(root='.\\FashionMNIST\\Train',train=True,download=True,transform=transforms.ToTensor())
testdataset3 = torchvision.datasets.FashionMNIST(root='.\\FashionMNIST\\Test',train=False,download=True,transform=transforms.ToTensor())
traindataloader3 = torch.utils.data.DataLoader(traindataset3, batch_size=batch_size, shuffle=True)
testdataloader3 = torch.utils.data.DataLoader(testdataset3, batch_size=batch_size, shuffle=False)
# 绘制图像的代码
def picture(name, trainl, testl, type='Loss'):plt.rcParams["font.sans-serif"]=["SimHei"] #设置字体plt.rcParams["axes.unicode_minus"]=False #该语句解决图像中的“-”负号的乱码问题plt.title(name) # 命名plt.plot(trainl, c='g', label='Train '+ type)plt.plot(testl, c='r', label='Test '+type)plt.xlabel('Epoch')plt.ylabel('Loss')plt.legend()plt.grid(True)
print(f'回归数据集 样本总数量{len(traindataset1) + len(testdataset1)},训练样本数量{len(traindataset1)},测试样本数量{len(testdataset1)}')
print(f'二分类数据集 样本总数量{len(traindataset2) + len(testdataset2)},训练样本数量{len(traindataset2)},测试样本数量{len(testdataset2)}')
print(f'多分类数据集 样本总数量{len(traindataset3) + len(testdataset3)},训练样本数量{len(traindataset3)},测试样本数量{len(testdataset3)}')# 定义自己的前馈神经网络
class MyNet1():def __init__(self):# 设置隐藏层和输出层的节点数num_inputs, num_hiddens, num_outputs = 500, 256, 1w_1 = torch.tensor(np.random.normal(0,0.01,(num_hiddens,num_inputs)),dtype=torch.float32,requires_grad=True)b_1 = torch.zeros(num_hiddens, dtype=torch.float32,requires_grad=True)w_2 = torch.tensor(np.random.normal(0, 0.01,(num_outputs, num_hiddens)),dtype=torch.float32,requires_grad=True)b_2 = torch.zeros(num_outputs,dtype=torch.float32, requires_grad=True)self.params = [w_1, b_1, w_2, b_2]# 定义模型结构self.input_layer = lambda x: x.view(x.shape[0],-1)self.hidden_layer = lambda x: self.my_relu(torch.matmul(x,w_1.t())+b_1)self.output_layer = lambda x: torch.matmul(x,w_2.t()) + b_2def my_relu(self, x):return torch.max(input=x,other=torch.tensor(0.0))def forward(self,x):x = self.input_layer(x)x = self.my_relu(self.hidden_layer(x))x = self.output_layer(x)return x
def mySGD(params, lr, batchsize):for param in params:param.data -= lr*param.grad / batchsizedef mse(pred, true):ans = torch.sum((true-pred)**2) / len(pred)# print(ans)return ans# 训练
model1 = MyNet1() # logistics模型
criterion = CrossEntropyLoss() # 损失函数
lr = 0.05 # 学习率
batchsize = 128
epochs = 40 #训练轮数
train_all_loss1 = [] # 记录训练集上得loss变化
test_all_loss1 = [] #记录测试集上的loss变化
begintime1 = time.time()
for epoch in range(epochs):train_l = 0for data, labels in traindataloader1:pred = model1.forward(data)train_each_loss = mse(pred.view(-1,1), labels.view(-1,1)) #计算每次的损失值train_each_loss.backward() # 反向传播mySGD(model1.params, lr, batchsize) # 使用小批量随机梯度下降迭代模型参数# 梯度清零train_l += train_each_loss.item()for param in model1.params:param.grad.data.zero_()# print(train_each_loss)train_all_loss1.append(train_l) # 添加损失值到列表中with torch.no_grad():test_loss = 0for data, labels in traindataloader1:pred = model1.forward(data)test_each_loss = mse(pred, labels)test_loss += test_each_loss.item()test_all_loss1.append(test_loss)if epoch==0 or (epoch+1) % 4 == 0:print('epoch: %d | train loss:%.5f | test loss:%.5f'%(epoch+1,train_all_loss1[-1],test_all_loss1[-1]))
endtime1 = time.time()
print("手动实现前馈网络-回归实验 %d轮 总用时: %.3fs"%(epochs,endtime1-begintime1))# 定义自己的前馈神经网络
class MyNet2():def __init__(self):# 设置隐藏层和输出层的节点数num_inputs, num_hiddens, num_outputs = 200, 256, 1w_1 = torch.tensor(np.random.normal(0, 0.01, (num_hiddens, num_inputs)), dtype=torch.float32,requires_grad=True)b_1 = torch.zeros(num_hiddens, dtype=torch.float32, requires_grad=True)w_2 = torch.tensor(np.random.normal(0, 0.01, (num_outputs, num_hiddens)), dtype=torch.float32,requires_grad=True)b_2 = torch.zeros(num_outputs, dtype=torch.float32, requires_grad=True)self.params = [w_1, b_1, w_2, b_2]# 定义模型结构self.input_layer = lambda x: x.view(x.shape[0], -1)self.hidden_layer = lambda x: self.my_relu(torch.matmul(x, w_1.t()) + b_1)self.output_layer = lambda x: torch.matmul(x, w_2.t()) + b_2self.fn_logistic = self.logisticdef my_relu(self, x):return torch.max(input=x, other=torch.tensor(0.0))def logistic(self, x): # 定义logistic函数x = 1.0 / (1.0 + torch.exp(-x))return x# 定义前向传播def forward(self, x):x = self.input_layer(x)x = self.my_relu(self.hidden_layer(x))x = self.fn_logistic(self.output_layer(x))return xdef mySGD(params, lr):for param in params:param.data -= lr * param.grad# 训练
model2 = MyNet2()
lr = 0.01 # 学习率
epochs = 40 # 训练轮数
train_all_loss2 = [] # 记录训练集上得loss变化
test_all_loss2 = [] # 记录测试集上的loss变化
train_Acc12, test_Acc12 = [], []
begintime2 = time.time()
for epoch in range(epochs):train_l, train_epoch_count = 0, 0for data, labels in traindataloader2:pred = model2.forward(data)train_each_loss = binary_cross_entropy(pred.view(-1), labels.view(-1)) # 计算每次的损失值train_l += train_each_loss.item()train_each_loss.backward() # 反向传播mySGD(model2.params, lr) # 使用随机梯度下降迭代模型参数# 梯度清零for param in model2.params:param.grad.data.zero_()# print(train_each_loss)train_epoch_count += (torch.tensor(np.where(pred > 0.5, 1, 0)).view(-1) == labels).sum()train_Acc12.append((train_epoch_count/len(traindataset2)).item())train_all_loss2.append(train_l) # 添加损失值到列表中with torch.no_grad():test_l, test_epoch_count = 0, 0for data, labels in testdataloader2:pred = model2.forward(data)test_each_loss = binary_cross_entropy(pred.view(-1), labels.view(-1))test_l += test_each_loss.item()test_epoch_count += (torch.tensor(np.where(pred > 0.5, 1, 0)).view(-1) == labels.view(-1)).sum()test_Acc12.append((test_epoch_count/len(testdataset2)).item())test_all_loss2.append(test_l)if epoch == 0 or (epoch + 1) % 4 == 0:print('epoch: %d | train loss:%.5f | test loss:%.5f | train acc:%.5f | test acc:%.5f' % (epoch + 1, train_all_loss2[-1], test_all_loss2[-1], train_Acc12[-1], test_Acc12[-1]))
endtime2 = time.time()
print("手动实现前馈网络-二分类实验 %d轮 总用时: %.3f" % (epochs, endtime2 - begintime2))# 定义自己的前馈神经网络
class MyNet3():def __init__(self):# 设置隐藏层和输出层的节点数num_inputs, num_hiddens, num_outputs = 28 * 28, 256, 10 # 十分类问题w_1 = torch.tensor(np.random.normal(0, 0.01, (num_hiddens, num_inputs)), dtype=torch.float32,requires_grad=True)b_1 = torch.zeros(num_hiddens, dtype=torch.float32, requires_grad=True)w_2 = torch.tensor(np.random.normal(0, 0.01, (num_outputs, num_hiddens)), dtype=torch.float32,requires_grad=True)b_2 = torch.zeros(num_outputs, dtype=torch.float32, requires_grad=True)self.params = [w_1, b_1, w_2, b_2]# 定义模型结构self.input_layer = lambda x: x.view(x.shape[0], -1)self.hidden_layer = lambda x: self.my_relu(torch.matmul(x, w_1.t()) + b_1)self.output_layer = lambda x: torch.matmul(x, w_2.t()) + b_2def my_relu(self, x):return torch.max(input=x, other=torch.tensor(0.0))# 定义前向传播def forward(self, x):x = self.input_layer(x)x = self.hidden_layer(x)x = self.output_layer(x)return xdef mySGD(params, lr, batchsize):for param in params:param.data -= lr * param.grad / batchsize# 训练
model3 = MyNet3() # logistics模型
criterion = cross_entropy # 损失函数
lr = 0.15 # 学习率
epochs = 40 # 训练轮数
train_all_loss3 = [] # 记录训练集上得loss变化
test_all_loss3 = [] # 记录测试集上的loss变化
train_ACC13, test_ACC13 = [], [] # 记录正确的个数
begintime3 = time.time()
for epoch in range(epochs):train_l,train_acc_num = 0, 0for data, labels in traindataloader3:pred = model3.forward(data)train_each_loss = criterion(pred, labels) # 计算每次的损失值train_l += train_each_loss.item()train_each_loss.backward() # 反向传播mySGD(model3.params, lr, 128) # 使用小批量随机梯度下降迭代模型参数# 梯度清零train_acc_num += (pred.argmax(dim=1)==labels).sum().item()for param in model3.params:param.grad.data.zero_()# print(train_each_loss)train_all_loss3.append(train_l) # 添加损失值到列表中train_ACC13.append(train_acc_num / len(traindataset3)) # 添加准确率到列表中with torch.no_grad():test_l, test_acc_num = 0, 0for data, labels in testdataloader3:pred = model3.forward(data)test_each_loss = criterion(pred, labels)test_l += test_each_loss.item()test_acc_num += (pred.argmax(dim=1)==labels).sum().item()test_all_loss3.append(test_l)test_ACC13.append(test_acc_num / len(testdataset3)) # # 添加准确率到列表中if epoch == 0 or (epoch + 1) % 4 == 0:print('epoch: %d | train loss:%.5f | test loss:%.5f | train acc: %.2f | test acc: %.2f'% (epoch + 1, train_l, test_l, train_ACC13[-1],test_ACC13[-1]))
endtime3 = time.time()
print("手动实现前馈网络-多分类实验 %d轮 总用时: %.3f" % (epochs, endtime3 - begintime3))plt.figure(figsize=(12,3))
plt.title('Loss')
plt.subplot(131)
picture('前馈网络-回归-Loss',train_all_loss1,test_all_loss1)
plt.subplot(132)
picture('前馈网络-二分类-loss',train_all_loss2,test_all_loss2)
plt.subplot(133)
picture('前馈网络-多分类-loss',train_all_loss3,test_all_loss3)
plt.show()plt.figure(figsize=(8, 3))
plt.subplot(121)
picture('前馈网络-二分类-ACC',train_Acc12,test_Acc12,type='ACC')
plt.subplot(122)
picture('前馈网络-多分类—ACC', train_ACC13,test_ACC13, type='ACC')
plt.show()nn实现(包括3种激活函数、多层隐藏层):
import time
import matplotlib.pyplot as plt
import numpy as np
import torch
import torch.nn as nn
import torchvision
from torch.nn.functional import cross_entropy, binary_cross_entropy
from torch.nn import CrossEntropyLoss
from torchvision import transforms
from sklearn import metrics
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 如果有gpu则在gpu上计算 加快计算速度
print(f'当前使用的device为{device}')
# 数据集定义
# 构建回归数据集合 - traindataloader1, testdataloader1
data_num, train_num, test_num = 10000, 7000, 3000 # 分别为样本总数量,训练集样本数量和测试集样本数量
true_w, true_b = 0.0056 * torch.ones(500,1), 0.028
features = torch.randn(10000, 500)
labels = torch.matmul(features,true_w) + true_b # 按高斯分布
labels += torch.tensor(np.random.normal(0,0.01,size=labels.size()),dtype=torch.float32)
# 划分训练集和测试集
train_features, test_features = features[:train_num,:], features[train_num:,:]
train_labels, test_labels = labels[:train_num], labels[train_num:]
batch_size = 128
traindataset1 = torch.utils.data.TensorDataset(train_features,train_labels)
testdataset1 = torch.utils.data.TensorDataset(test_features, test_labels)
traindataloader1 = torch.utils.data.DataLoader(dataset=traindataset1,batch_size=batch_size,shuffle=True)
testdataloader1 = torch.utils.data.DataLoader(dataset=testdataset1,batch_size=batch_size,shuffle=True)# 构二分类数据集合
data_num, train_num, test_num = 10000, 7000, 3000 # 分别为样本总数量,训练集样本数量和测试集样本数量
# 第一个数据集 符合均值为 0.5 标准差为1 得分布
features1 = torch.normal(mean=0.2, std=2, size=(data_num, 200), dtype=torch.float32)
labels1 = torch.ones(data_num)
# 第二个数据集 符合均值为 -0.5 标准差为1的分布
features2 = torch.normal(mean=-0.2, std=2, size=(data_num, 200), dtype=torch.float32)
labels2 = torch.zeros(data_num)# 构建训练数据集
train_features2 = torch.cat((features1[:train_num], features2[:train_num]), dim=0) # size torch.Size([14000, 200])
train_labels2 = torch.cat((labels1[:train_num], labels2[:train_num]), dim=-1) # size torch.Size([6000, 200])
# 构建测试数据集
test_features2 = torch.cat((features1[train_num:], features2[train_num:]), dim=0) # torch.Size([14000])
test_labels2 = torch.cat((labels1[train_num:], labels2[train_num:]), dim=-1) # torch.Size([6000])
batch_size = 128
# Build the training and testing dataset
traindataset2 = torch.utils.data.TensorDataset(train_features2, train_labels2)
testdataset2 = torch.utils.data.TensorDataset(test_features2, test_labels2)
traindataloader2 = torch.utils.data.DataLoader(dataset=traindataset2,batch_size=batch_size,shuffle=True)
testdataloader2 = torch.utils.data.DataLoader(dataset=testdataset2,batch_size=batch_size,shuffle=True)# 定义多分类数据集 - train_dataloader - test_dataloader
batch_size = 128
# Build the training and testing dataset
traindataset3 = torchvision.datasets.FashionMNIST(root='.\\FashionMNIST\\Train',train=True,download=True,transform=transforms.ToTensor())
testdataset3 = torchvision.datasets.FashionMNIST(root='.\\FashionMNIST\\Test',train=False,download=True,transform=transforms.ToTensor())
traindataloader3 = torch.utils.data.DataLoader(traindataset3, batch_size=batch_size, shuffle=True)
testdataloader3 = torch.utils.data.DataLoader(testdataset3, batch_size=batch_size, shuffle=False)
# 绘制图像的代码
def picture(name, trainl, testl, type='Loss'):plt.rcParams["font.sans-serif"]=["SimHei"] #设置字体plt.rcParams["axes.unicode_minus"]=False #该语句解决图像中的“-”负号的乱码问题plt.title(name) # 命名plt.plot(trainl, c='g', label='Train '+ type)plt.plot(testl, c='r', label='Test '+type)plt.xlabel('Epoch')plt.ylabel('Loss')plt.legend()plt.grid(True)
print(f'回归数据集 样本总数量{len(traindataset1) + len(testdataset1)},训练样本数量{len(traindataset1)},测试样本数量{len(testdataset1)}')
print(f'二分类数据集 样本总数量{len(traindataset2) + len(testdataset2)},训练样本数量{len(traindataset2)},测试样本数量{len(testdataset2)}')
print(f'多分类数据集 样本总数量{len(traindataset3) + len(testdataset3)},训练样本数量{len(traindataset3)},测试样本数量{len(testdataset3)}')def ComPlot(datalist,title='1',ylabel='Loss',flag='act'):plt.rcParams["font.sans-serif"]=["SimHei"] #设置字体plt.rcParams["axes.unicode_minus"]=False #该语句解决图像中的“-”负号的乱码问题plt.title(title)plt.xlabel('Epoch')plt.ylabel(ylabel)plt.plot(datalist[0],label='Tanh' if flag=='act' else '[128]')plt.plot(datalist[1],label='Sigmoid' if flag=='act' else '[512 256]')plt.plot(datalist[2],label='ELu' if flag=='act' else '[512 256 128 64]')plt.plot(datalist[3],label='Relu' if flag=='act' else '[256]')plt.legend()plt.grid(True)from torch.optim import SGD
from torch.nn import MSELoss
# 利用torch.nn实现前馈神经网络-回归任务 代码
# 定义自己的前馈神经网络
class MyNet21(nn.Module):def __init__(self):super(MyNet21, self).__init__()# 设置隐藏层和输出层的节点数num_inputs, num_hiddens, num_outputs = 500, 256, 1# 定义模型结构self.input_layer = nn.Flatten()self.hidden_layer = nn.Linear(num_inputs, num_hiddens)self.output_layer = nn.Linear(num_hiddens, num_outputs)self.relu = nn.ReLU()# 定义前向传播def forward(self, x):x = self.input_layer(x)x = self.relu(self.hidden_layer(x))x = self.output_layer(x)return x# 训练
model21 = MyNet21() # logistics模型
model21 = model21.to(device)
print(model21)
criterion = MSELoss() # 损失函数
criterion = criterion.to(device)
optimizer = SGD(model21.parameters(), lr=0.1) # 优化函数
epochs = 40 # 训练轮数
train_all_loss21 = [] # 记录训练集上得loss变化
test_all_loss21 = [] # 记录测试集上的loss变化
begintime21 = time.time()
for epoch in range(epochs):train_l = 0for data, labels in traindataloader1:data, labels = data.to(device=device), labels.to(device)pred = model21(data)train_each_loss = criterion(pred.view(-1, 1), labels.view(-1, 1)) # 计算每次的损失值optimizer.zero_grad() # 梯度清零train_each_loss.backward() # 反向传播optimizer.step() # 梯度更新train_l += train_each_loss.item()train_all_loss21.append(train_l) # 添加损失值到列表中with torch.no_grad():test_loss = 0for data, labels in testdataloader1:data, labels = data.to(device), labels.to(device)pred = model21(data)test_each_loss = criterion(pred,labels)test_loss += test_each_loss.item()test_all_loss21.append(test_loss)if epoch == 0 or (epoch + 1) % 10 == 0:print('epoch: %d | train loss:%.5f | test loss:%.5f' % (epoch + 1, train_all_loss21[-1], test_all_loss21[-1]))
endtime21 = time.time()
print("torch.nn实现前馈网络-回归实验 %d轮 总用时: %.3fs" % (epochs, endtime21 - begintime21))# 利用torch.nn实现前馈神经网络-二分类任务
import time
from torch.optim import SGD
from torch.nn.functional import binary_cross_entropy
# 利用torch.nn实现前馈神经网络-回归任务 代码
# 定义自己的前馈神经网络
class MyNet22(nn.Module):def __init__(self):super(MyNet22, self).__init__()# 设置隐藏层和输出层的节点数num_inputs, num_hiddens, num_outputs = 200, 256, 1# 定义模型结构self.input_layer = nn.Flatten()self.hidden_layer = nn.Linear(num_inputs, num_hiddens)self.output_layer = nn.Linear(num_hiddens, num_outputs)self.relu = nn.ReLU()def logistic(self, x): # 定义logistic函数x = 1.0 / (1.0 + torch.exp(-x))return x# 定义前向传播def forward(self, x):x = self.input_layer(x)x = self.relu(self.hidden_layer(x))x = self.logistic(self.output_layer(x))return x# 训练
model22 = MyNet22() # logistics模型
model22 = model22.to(device)
print(model22)
optimizer = SGD(model22.parameters(), lr=0.001) # 优化函数
epochs = 40 # 训练轮数
train_all_loss22 = [] # 记录训练集上得loss变化
test_all_loss22 = [] # 记录测试集上的loss变化
train_ACC22, test_ACC22 = [], []
begintime22 = time.time()
for epoch in range(epochs):train_l, train_epoch_count, test_epoch_count = 0, 0, 0 # 每一轮的训练损失值 训练集正确个数 测试集正确个数for data, labels in traindataloader2:data, labels = data.to(device), labels.to(device)pred = model22(data)train_each_loss = binary_cross_entropy(pred.view(-1), labels.view(-1)) # 计算每次的损失值optimizer.zero_grad() # 梯度清零train_each_loss.backward() # 反向传播optimizer.step() # 梯度更新train_l += train_each_loss.item()pred = torch.tensor(np.where(pred.cpu()>0.5, 1, 0)) # 大于 0.5时候,预测标签为 1 否则为0each_count = (pred.view(-1) == labels.cpu()).sum() # 每一个batchsize的正确个数train_epoch_count += each_count # 计算每个epoch上的正确个数train_ACC22.append(train_epoch_count / len(traindataset2))train_all_loss22.append(train_l) # 添加损失值到列表中with torch.no_grad():test_loss, each_count = 0, 0for data, labels in testdataloader2:data, labels = data.to(device), labels.to(device)pred = model22(data)test_each_loss = binary_cross_entropy(pred.view(-1),labels)test_loss += test_each_loss.item()# .cpu 为转换到cpu上计算pred = torch.tensor(np.where(pred.cpu() > 0.5, 1, 0))each_count = (pred.view(-1)==labels.cpu().view(-1)).sum()test_epoch_count += each_counttest_all_loss22.append(test_loss)test_ACC22.append(test_epoch_count / len(testdataset2))if epoch == 0 or (epoch + 1) % 4 == 0:print('epoch: %d | train loss:%.5f test loss:%.5f | train acc:%.5f | test acc:%.5f' % (epoch + 1, train_all_loss22[-1], test_all_loss22[-1], train_ACC22[-1], test_ACC22[-1]))endtime22 = time.time()
print("torch.nn实现前馈网络-二分类实验 %d轮 总用时: %.3fs" % (epochs, endtime22 - begintime22))# 利用torch.nn实现前馈神经网络-多分类任务
from collections import OrderedDict
from torch.nn import CrossEntropyLoss
from torch.optim import SGD
# 定义自己的前馈神经网络
class MyNet23(nn.Module):"""参数: num_input:输入每层神经元个数,为一个列表数据num_hiddens:隐藏层神经元个数num_outs: 输出层神经元个数num_hiddenlayer : 隐藏层的个数"""def __init__(self,num_hiddenlayer=1, num_inputs=28*28,num_hiddens=[256],num_outs=10,act='relu'):super(MyNet23, self).__init__()# 设置隐藏层和输出层的节点数self.num_inputs, self.num_hiddens, self.num_outputs = num_inputs,num_hiddens,num_outs # 十分类问题# 定义模型结构self.input_layer = nn.Flatten()# 若只有一层隐藏层if num_hiddenlayer ==1:self.hidden_layers = nn.Linear(self.num_inputs,self.num_hiddens[-1])else: # 若有多个隐藏层self.hidden_layers = nn.Sequential()self.hidden_layers.add_module("hidden_layer1", nn.Linear(self.num_inputs,self.num_hiddens[0]))for i in range(0,num_hiddenlayer-1):name = str('hidden_layer'+str(i+2))self.hidden_layers.add_module(name, nn.Linear(self.num_hiddens[i],self.num_hiddens[i+1]))self.output_layer = nn.Linear(self.num_hiddens[-1], self.num_outputs)# 指代需要使用什么样子的激活函数if act == 'relu':self.act = nn.ReLU()elif act == 'sigmoid':self.act = nn.Sigmoid()elif act == 'tanh':self.act = nn.Tanh()elif act == 'elu':self.act = nn.ELU()print(f'你本次使用的激活函数为 {act}')def logistic(self, x): # 定义logistic函数x = 1.0 / (1.0 + torch.exp(-x))return x# 定义前向传播def forward(self, x):x = self.input_layer(x)x = self.act(self.hidden_layers(x))x = self.output_layer(x)return x# 训练
# 使用默认的参数即: num_inputs=28*28,num_hiddens=256,num_outs=10,act='relu'
model23 = MyNet23()
model23 = model23.to(device)# 将训练过程定义为一个函数,方便实验三和实验四调用
def train_and_test(model=model23):MyModel = modelprint(MyModel)optimizer = SGD(MyModel.parameters(), lr=0.01) # 优化函数epochs = 40 # 训练轮数criterion = CrossEntropyLoss() # 损失函数train_all_loss23 = [] # 记录训练集上得loss变化test_all_loss23 = [] # 记录测试集上的loss变化train_ACC23, test_ACC23 = [], []begintime23 = time.time()for epoch in range(epochs):train_l, train_epoch_count, test_epoch_count = 0, 0, 0for data, labels in traindataloader3:data, labels = data.to(device), labels.to(device)pred = MyModel(data)train_each_loss = criterion(pred, labels.view(-1)) # 计算每次的损失值optimizer.zero_grad() # 梯度清零train_each_loss.backward() # 反向传播optimizer.step() # 梯度更新train_l += train_each_loss.item()train_epoch_count += (pred.argmax(dim=1)==labels).sum()train_ACC23.append(train_epoch_count.cpu()/len(traindataset3))train_all_loss23.append(train_l) # 添加损失值到列表中with torch.no_grad():test_loss, test_epoch_count= 0, 0for data, labels in testdataloader3:data, labels = data.to(device), labels.to(device)pred = MyModel(data)test_each_loss = criterion(pred,labels)test_loss += test_each_loss.item()test_epoch_count += (pred.argmax(dim=1)==labels).sum()test_all_loss23.append(test_loss)test_ACC23.append(test_epoch_count.cpu()/len(testdataset3))if epoch == 0 or (epoch + 1) % 4 == 0:print('epoch: %d | train loss:%.5f | test loss:%.5f | train acc:%5f test acc:%.5f:' % (epoch + 1, train_all_loss23[-1], test_all_loss23[-1],train_ACC23[-1],test_ACC23[-1]))endtime23 = time.time()print("torch.nn实现前馈网络-多分类任务 %d轮 总用时: %.3fs" % (epochs, endtime23 - begintime23))# 返回训练集和测试集上的 损失值 与 准确率return train_all_loss23,test_all_loss23,train_ACC23,test_ACC23
train_all_loss23,test_all_loss23,train_ACC23,test_ACC23 = train_and_test(model=model23)plt.figure(figsize=(12,3))
plt.subplot(131)
picture('前馈网络-回归-loss',train_all_loss21,test_all_loss21)
plt.subplot(132)
picture('前馈网络-二分类-loss',train_all_loss22,test_all_loss22)
plt.subplot(133)
picture('前馈网络-多分类-loss',train_all_loss23,test_all_loss23)
plt.show()plt.figure(figsize=(8,3))
plt.subplot(121)
picture('前馈网络-二分类-ACC',train_ACC22,test_ACC22,type='ACC')
plt.subplot(122)
picture('前馈网络-多分类-ACC',train_ACC23,test_ACC23,type='ACC')
plt.show()plt.figure(figsize=(16,3))
plt.subplot(141)
ComPlot([train_all_loss31,train_all_loss32,train_all_loss33,train_all_loss23],title='Train_Loss')
plt.subplot(142)
ComPlot([test_all_loss31,test_all_loss32,test_all_loss33,test_all_loss23],title='Test_Loss')
plt.subplot(143)
ComPlot([train_ACC31,train_ACC32,train_ACC33,train_ACC23],title='Train_ACC')
plt.subplot(144)
ComPlot([test_ACC31,test_ACC32,test_ACC33,test_ACC23],title='Test_ACC')
plt.show()相关文章:
)
fnn手动实现和nn实现(包括3种激活函数、隐藏层)
原文网址:https://blog.csdn.net/m0_52910424/article/details/127819278 fnn手动实现: import time import matplotlib.pyplot as plt import numpy as np import torch import torch.nn as nn import torchvision from torch.nn.functional import cross_entrop…...

Lua + mysql 实战代码
--[[luarocks lua语言的包管理器luasql https://luarocks.org/brew install luarocksluarocks install luasql-mysql 注意此处,如果你是 mariadb,然后要求指定 MYSQL_DIR 参数的时候,千万不要指到 mariadb 的安装目录,而是要指…...
智慧工地监管云平台源码 建筑施工一体化信息管理系统源码
智慧工地管理云平台系统是一种利用人工智能和物联网技术来监测和管理建筑工地的系统。它可以通过感知设备、数据处理和分析、智能控制等技术手段,实现对工地施工、设备状态、人员安全等方面的实时监控和管理。 智慧工地平台系统工作原理: 1、感知设备的…...
三.net core 自动化发布到docker (创建一个dotnet工程发布)
创建Jenkins-create a job 输入名称(建议不要带“”这类的字符),选择自由风格的类型(红框标注的),点击确定 用于测试,下面选项基本没有选择-配置代码地址 选择执行shell #!/bin/bash # 获取短版本号 GITHA…...
【Spring Cloud 八】Spring Cloud Gateway网关
gateway网关 系列博客背景一、什么是Spring Cloud Gateway二、为什么要使用Spring Cloud Gateway三、 Spring Cloud Gateway 三大核心概念4.1 Route(路由)4.2 Predicate(断言)4.3 Filter(过滤) 五、Spring …...

Android JNI传递CallBack接口并接收回调
在JNI中,可以通过传递一个Java接口对象的引用给C代码,并在C代码中调用该接口对象的方法,实现JAVA层监听C数据变化,下面是一个简单的示例: 在Java代码中定义一个CallBack接口和JNI方法 class TestLib {companion objec…...
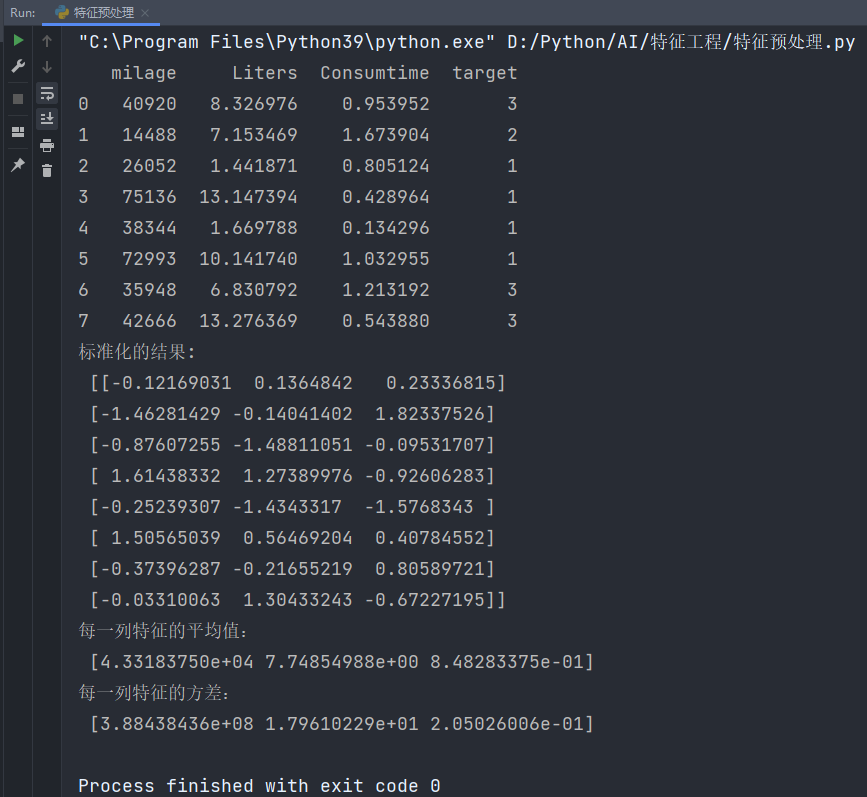
机器学习:特征工程之特征预处理
目录 特征预处理 1、简述 2、内容 3、归一化 3.1、鲁棒性 3.2、存在的问题 4、标准化 ⭐所属专栏:人工智能 文中提到的代码如有需要可以私信我发给你😊 特征预处理 1、简述 什么是特征预处理:scikit-learn的解释: provide…...
高级艺术二维码制作教程
最近不少关于二维码制作的,而且都是付费。大概就是一个好看的二维码,扫描后跳转网址。本篇文章使用Python来实现,这么简单花啥钱呢?学会,拿去卖便宜点吧。 文章目录 高级二维码制作环境安装普通二维码艺术二维码动态 …...

每日一题leetcode--使循环数组所有元素相等的最少秒数
相当于扩散,每个数可以一次可以扩散到左右让其一样,问最少多少次可以让整个数组都变成一样的数 使用枚举,先将所有信息存到hash表中,然后逐一进行枚举,计算时间长短用看下图 考虑到环形数组,可以把首项n放…...
tauri-react:快速开发跨平台软件的架子,支持自定义头部UI拖拽移动和窗口阴影效果
tauri-react 一个使用 taurireacttsantd 开发跨平台软件的模板,支持窗口头部自定义和窗口阴影,不用再自己做适配了,拿来即用,非常 nice。而且已经封装好了 tauri 的 http 请求工具,省去很多弯路。 开原地址ÿ…...

k8s 自身原理之 Service
好不容易,终于来到 k8s 自身的原理之 关于 Service 的一部分了 前面我们用 2 个简图展示了 pod 之间和 pod 与 node 之间是如何通信息的,且通信的数据包是不会经过 NAT 网络地址转换的 那么 Service 又是如何实现呢? Service 我们知道是用…...

arduino Xiao ESP32C3 oled0.96 下雪花
Xiao ESP32C3使用oled 0.96实现下雪的功能 雪花下落的时候, 随机生成半径和位置 sandR和sandX,sandY 保存雪花下落位置的时候, 将其周边一圈设置为-1, 标记为有雪花 其他雪花下落的时候, 其他雪花的一圈如果遇到-1, 则停止下落, 并重复2 #include "oled.h" void …...

ElasticSearch索引库、文档、RestClient操作
文章目录 一、索引库1、mapping属性2、索引库的crud 二、文档的crud三、RestClient 一、索引库 es中的索引是指相同类型的文档集合,即mysql中表的概念 映射:索引中文档字段的约束,比如名称、类型 1、mapping属性 mapping映射是对索引库中文…...
)
Effective Java 案例分享(九)
46、使用无副作用的Stream 本章节主要举例了Stream的几种用法。 案例一: // Uses the streams API but not the paradigm--Dont do this! Map<String, Long> freq new HashMap<>(); try (Stream<String> words new Scanner(file).tokens()) …...
SpringBoot复习:(56)使用@Transactional注解标记的方法的执行流程
首先,如果在某个类或某个方法被标记为Transactional时,Spring boot底层会在创建这个bean时生成代理对象(默认使用cglib) 示例: 当调用studentService的addStudent方法时,会直接跳到CglibAopProxy类去执行intercept方…...
JVM——引言+JVM内存结构
引言 什么是JVM 定义: Java VirtualMachine -java 程序的运行环境 (ava 二进制字节码的运行环境) 好处: 一次编写,到处运行自动内存管理,垃圾回收功能数组下标越界检查,多态 比较: jvm jre jdk 学习jvm的作用 面试理解底层实现原理中…...
图形检测)
open cv学习 (十)图形检测
图形检测 demo1 # 绘制几何图像的轮廓 import cv2img cv2.imread("./shape1.png")gray cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 将图像二值化 t, binary cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY)# 检测图像中的所有轮廓 contours, hierarchy cv2.f…...

【C语言】字符函数和字符串函数
目录 1.求字符串长度strlen 2.长度不受限制的字符串函数 字符串拷贝strcpy 字符串追加strcat 字符串比较strcmp 3.长度受限制的字符串函数介绍strncpy strncat 编辑strncmp 4.字符串查找strstr 5.字符串分割strtok 6.错误信息报告 strerror perror 7.字符分类函…...
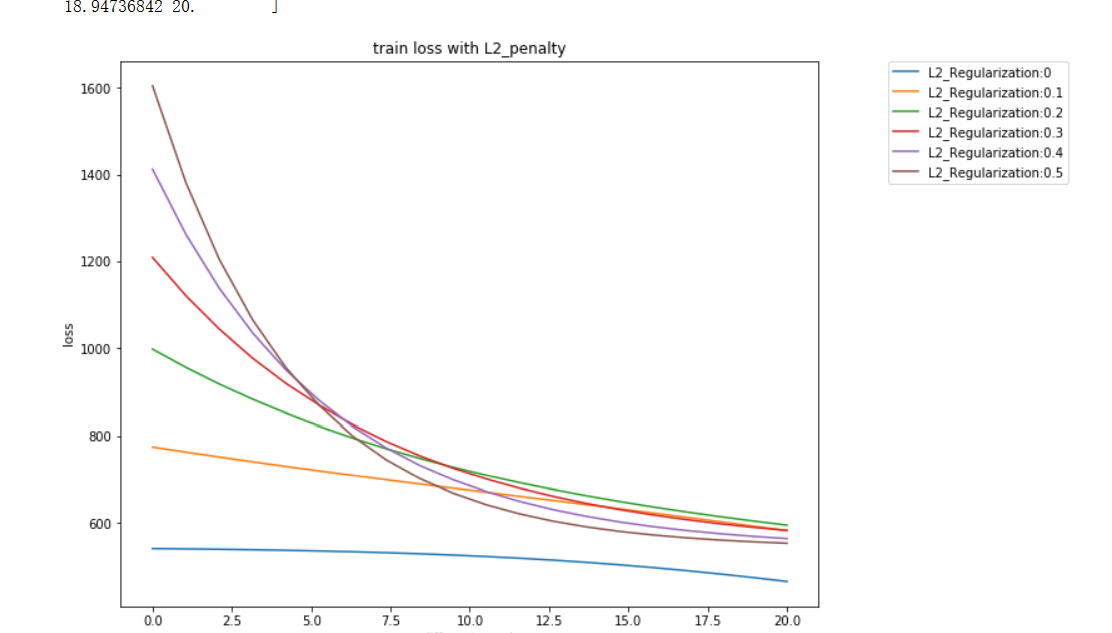
前馈神经网络正则化例子
直接看代码: import torch import numpy as np import random from IPython import display from matplotlib import pyplot as plt import torchvision import torchvision.transforms as transforms mnist_train torchvision.datasets.MNIST(root…...

spring的核心技术---bean的生命周期加案例分析详细易懂
目录 一.spring管理JavaBean的初始化过程(生命周期) Spring Bean的生命周期: 二.spring的JavaBean管理中单例模式及原型(多例)模式 2.1 . 默认为单例,但是可以配置多例 2.2.举例论证 2.2.1 默认单例 2.2…...
)
多语种出海必备,ElevenLabs菲律宾文语音质量实测对比:Wavenet vs. Instant Voice vs. Custom Model(附MOS评分表)
更多请点击: https://intelliparadigm.com 第一章:多语种出海语音技术演进与菲律宾语本地化挑战 随着全球数字服务加速出海,语音交互系统正从单语种向多语种、低资源语言深度拓展。菲律宾语(Filipino/Tagalog)作为东…...
)
旁遮普语内容出海迫在眉睫!ElevenLabs+AWS Polly双引擎容灾方案(含Failover切换SLA 99.99%保障协议模板)
更多请点击: https://intelliparadigm.com 第一章:旁遮普语内容出海的战略紧迫性与本地化语音缺口 旁遮普语是全球使用人数超1.2亿的语言,主要分布在印度旁遮普邦、巴基斯坦旁遮普省及庞大的海外侨民社群(如加拿大、英国、美国&…...

6000万美元拿下世界杯:FIFA终于清醒了?
5月15号下午,央视和国际足联官宣了新周期的版权合作。朋友圈里炸开了锅,大家都在讨论那个数字:6000万美元。这是2026年美加墨世界杯的中国区转播权价格。说实话,看到这个价格我有点意外。上一届卡塔尔世界杯,传闻中的版…...

Harness 中的请求标识染色:端到端追踪
1. 标题选项(核心关键词:Harness、请求标识染色、端到端追踪、可观测性、CI/CD) 「Harness 可观测性实战:请求标识染色实现全链路端到端追踪」 「从0到1搞定Harness请求染色:让微服务调用链路+变更链路无所遁形」 「告别排查黑洞:Harness请求标识染色的端到端追踪落地指南…...

3分钟掌握FanControl:Windows风扇控制终极指南
3分钟掌握FanControl:Windows风扇控制终极指南 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/fa/FanCon…...

腾讯 Marvis 操作系统层 AI 助手内测:多场景显身手,“AI 打工人”雏形初现但仍待打磨
多场景显身手近日,腾讯开始内测一款名为 Marvis(马维斯)的操作系统层个人 AI 助手。这一 AI 助手通过多个 Agent 的协作完成 App 操作、EXE 操作、电脑操作、文件管理、文档生成以及各种复杂任务,24 小时持续在线,并支…...

GNN与MLIP:材料科学计算的高效新方法
1. GNN与MLIP:材料科学计算的新范式在材料科学领域,传统的第一性原理计算(如密度泛函理论DFT)虽然精度高,但计算成本极其昂贵,难以处理大体系或长时间尺度的模拟。图神经网络(GNN)与…...

基于节点电价的电网对电动汽车接纳能力评估模型研究附Matlab代码
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、程序设计科研仿真。 🍎完整代码获取 定制创新 论文复现点击:Matlab科研工作室 👇 关注我领取海量matlab电子书和数学建模资料 &…...

面试官问‘0.1+0.2≠0.3’,你能从CPU层面讲清楚吗?浮点数运算避坑指南
为什么0.10.2不等于0.3?从晶体管到代码的浮点数运算解密 当你在Python或JavaScript中输入0.1 0.2时,得到的不是预期的0.3,而是一个近似值0.30000000000000004。这个看似简单的数学问题背后,隐藏着计算机处理数字的复杂机制。理解…...

14502黄大年茶思屋145期难题 第二题 QLC盘多namespace并发备电量优化问题 标准化解题框架
总标题:黄大年茶思屋145期难题第二题 AI无偏差版脱敏题目标准化解题详细写作框架 子标题:QLC盘多namespace并发备电量优化问题 标准化解题框架 摘要 本文严格遵循AI无偏差脱敏标准化写作范式,完整复刻本期第二道脱敏原题全文,逐项…...