人工智能任务1-【NLP系列】句子嵌入的应用与多模型实现方式
大家好,我是微学AI,今天给大家介绍一下人工智能任务1-【NLP系列】句子嵌入的应用与多模型实现方式。句子嵌入是将句子映射到一个固定维度的向量表示形式,它在自然语言处理(NLP)中有着广泛的应用。通过将句子转化为向量表示,可以使得计算机能够更好地理解和处理文本数据。
本文采用多模型实现方式词嵌入,包括:Word2Vec 、Doc2Vec、BERT模型,将其应用于句子嵌入任务。这些预训练模型通过大规模的无监督学习从海量文本数据中学习到了丰富的语义信息,并能够产生高质量的句子嵌入。
目录
- 引言
- 项目背景与意义
- 句子嵌入基础
- 实现方式
- Word2Vec
- Doc2Vec
- BERT
- 项目实践与代码
- 数据预处理
- 句子嵌入实现
- 总结
- 参考资料
引言
随着人工智能和大数据的发展,自然语言处理(NLP)在许多领域得到了广泛应用,如搜索引擎,推荐系统,自动翻译等。其中,句子嵌入是NLP的关键技术之一,它可以将自然语言的句子转化为计算机可以理解的向量,从而使机器可以处理和理解自然语言。本文将详细介绍句子嵌入在NLP中的应用项目,以及几种常见的中文文本句子嵌入的实现方式。
项目背景与意义
在自然语言处理中,将句子转化为向量的过程称为句子嵌入。这是因为计算机不能直接理解自然语言,而是通过处理数值数据(例如向量)来实现。句子嵌入可以捕捉句子的语义信息,帮助机器理解和处理自然语言。
句子嵌入的应用项目广泛,如情感分析,文本分类,语义搜索,机器翻译等。例如,在情感分析中,句子嵌入可以将文本转化为向量,然后通过机器学习模型来预测文本的情感。在机器翻译中,句子嵌入可以帮助机器理解源语言的句子,并将其转化为目标语言的句子。
句子嵌入的应用主要包括以下几个方面:
文本分类/情感分析:句子嵌入可以用于文本分类任务,如将电影评论分为正面和负面情感。基于句子嵌入的模型能够学习到句子的语义信息,并将其应用于情感分类。
语义相似度:通过计算句子嵌入之间的相似度,可以衡量句子之间的语义相似性。这在问答系统、推荐系统等任务中非常有用,可以帮助找到与输入句子最相关的其他句子。
机器翻译:句子嵌入可以用于机器翻译任务中的句子对齐和翻译建模。通过将源语言句子和目标语言句子编码成嵌入向量,可以捕捉句子之间的对应关系和语义信息,从而提高翻译质量。
句子生成:利用预训练的语言模型和句子嵌入,可以生成连贯、语义正确的句子。句子嵌入可以作为生成任务的输入,保证生成的句子与输入的上下文相关。
信息检索/相似句子查找:通过将句子转换为嵌入向量,可以建立索引并进行快速的相似句子查找。这在搜索引擎、知识图谱等领域具有重要应用价值。
句子嵌入基础
句子嵌入是一种将自然语言句子转化为固定长度的实数向量的技术。这个向量能够捕获句子的语义信息,例如句子的主题,情感,语气等。句子嵌入通常是通过神经网络模型学习得到的。这些模型可以是无监督的,如Word2Vec,Doc2Vec,或者是有监督的,如BERT。
实现方式
接下来,我们将介绍三种常见的中文文本句子嵌入的实现方式。
方法一:Word2Vec
Word2Vec是一种常见的词嵌入方法,它可以将词语转化为向量。这种方法的思想是,将一个句子中的所有词向量取平均,得到句子的向量。
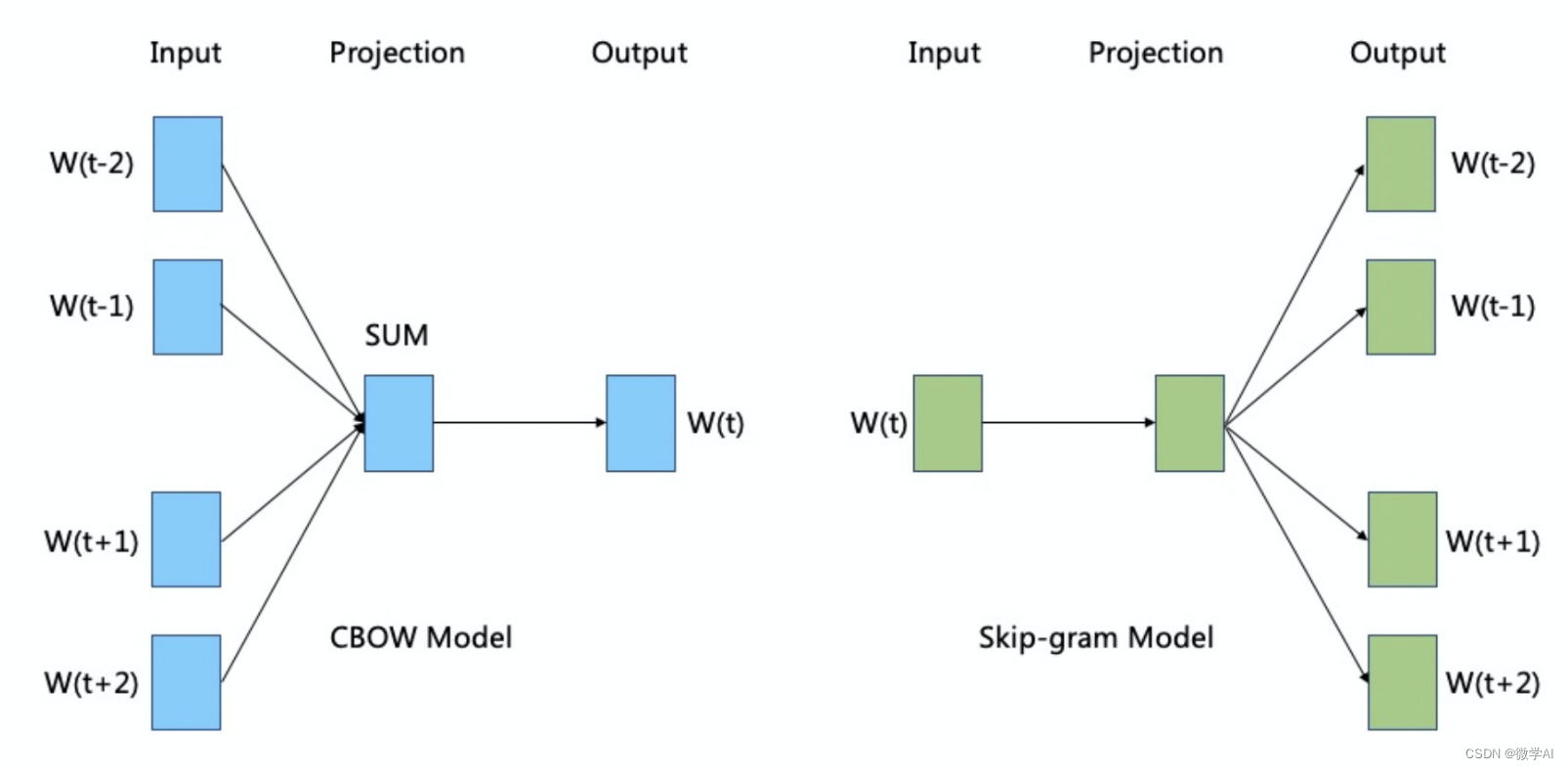
Word2Vec 有两种实现方式:CBOW(Continuous Bag-of-Words)和Skip-gram。
CBOW 模型旨在根据上下文预测中心词,而 Skip-gram 模型则是根据中心词预测上下文。以下是这两种模型的基本数学原理:
CBOW 模型:
假设我们有一个中心词 w t w_t wt,并且上下文窗口大小为 m m m,则上下文词可以表示为 w t − m , w t − m + 1 , . . . , w t − 1 , w t + 1 , . . . , w t + m w_{t-m}, w_{t-m+1}, ..., w_{t-1}, w_{t+1}, ..., w_{t+m} wt−m,wt−m+1,...,wt−1,wt+1,...,wt+m。
CBOW 模型试图根据上下文词来预测中心词,其目标是最大化给定上下文条件下中心词的条件概率。
具体而言,CBOW 模型通过将上下文词的词向量进行平均或求和,得到上下文表示 v = 1 2 m ∑ i = 1 2 m v w t i \mathbf{v} = \frac{1}{2m} \sum_{i=1}^{2m} \mathbf{v}_{w_{t_i}} v=2m1∑i=12mvwti。然后,将上下文表示 v \mathbf{v} v 输入到一个隐藏层中,并通过一个非线性函数(通常是 sigmoid 函数)得到隐藏层的输出 h = σ ( W v + b ) \mathbf{h} = \sigma(\mathbf{W}\mathbf{v} + \mathbf{b}) h=σ(Wv+b)。最后,将隐藏层的输出与中心词 w t w_t wt 相关的 one-hot 编码表示进行比较,并使用 softmax 函数得到每个词的概率分布 y ^ \hat{\mathbf{y}} y^。模型的目标是最大化实际中心词的对数概率: max log P ( w t ∣ w t − m , . . . , w t − 1 , w t + 1 , . . . , w t + m ) \max \log P(w_t | w_{t-m}, ..., w_{t-1}, w_{t+1}, ..., w_{t+m}) maxlogP(wt∣wt−m,...,wt−1,wt+1,...,wt+m)。
Skip-gram 模型:
Skip-gram 模型与 CBOW 模型相反,它试图根据中心词预测上下文词。
具体而言,Skip-gram 模型将中心词 w t w_t wt 的词向量 v w t \mathbf{v}_{w_t} vwt 输入到隐藏层,并通过一个非线性函数得到隐藏层的输出 h = σ ( W v w t + b ) \mathbf{h} = \sigma(\mathbf{W}\mathbf{v}_{w_t} + \mathbf{b}) h=σ(Wvwt+b)。然后,将隐藏层的输出与上下文词 w t − m , w t − m + 1 , . . . , w t − 1 , w t + 1 , . . . , w t + m w_{t-m}, w_{t-m+1}, ..., w_{t-1}, w_{t+1}, ..., w_{t+m} wt−m,wt−m+1,...,wt−1,wt+1,...,wt+m 相关的 one-hot 编码表示依次比较,并使用 softmax 函数得到每个词的概率分布 y ^ \hat{\mathbf{y}} y^。模型的目标是最大化实际上下文词的对数概率: max ∑ i = 1 2 m log P ( w t i ∣ w t ) \max \sum_{i=1}^{2m} \log P(w_{t_i} | w_{t}) max∑i=12mlogP(wti∣wt)。
在实际训练过程中,Word2Vec 使用负采样(negative sampling)来近似 softmax 函数的计算,加快模型的训练速度,并取得更好的性能。
希望上述使用 LaTeX 输出的数学表示对您有所帮助!
方法二:Doc2Vec
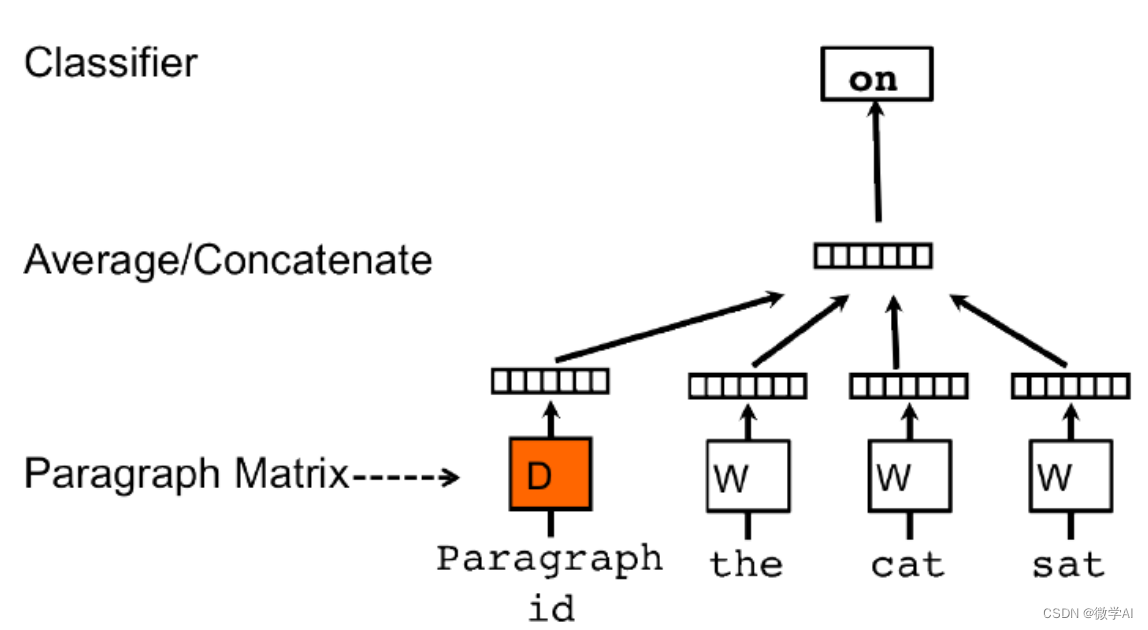
Doc2Vec是一种直接获取句子向量的方法,它是Word2Vec的扩展。Doc2Vec不仅考虑词语的上下文关系,还考虑了文档的全局信息。
假设我们有一个包含N个文档的语料库,每个文档由一系列单词组成。Doc2Vec的目标是为每个文档生成一个固定长度的向量表示。
Doc2Vec使用了两种不同的模型来实现这一目标:分别是PV-DM和PV-DBOW。
对于PV-DM模型,在训练过程中,每个文档被映射到一个唯一的向量(paragraph vector),同时也将每个单词映射到一个向量。在预测阶段,模型输入一部分文本(可能是一个或多个单词)并尝试预测缺失部分文本(通常是一个单词)。模型的损失函数基于预测和真实值之间的差异进行计算,然后通过反向传播来更新文档和单词的向量表示。
对于PV-DBOW模型,它忽略了文档内单词的顺序,只关注文档的整体表示。在该模型中,一个文档被映射到一个向量,并且模型的目标是通过上下文单词的信息预测该文档。同样地,模型使用损失函数和反向传播来更新文档和单词的向量表示。
总体而言,Doc2Vec通过将每个文档表示为固定长度的向量来捕捉文档的语义信息。这些向量可以用于度量文档之间的相似性、聚类文档或作为其他任务的输入。
使用数学符号描述Doc2Vec的具体细节,可以参考以下公式:
PV-DM模型:
- 输入:一个文档d,由单词序列 ( w 1 , w 2 , . . . , w n ) (w_1, w_2, ..., w_n) (w1,w2,...,wn)组成,其中 n n n是文档中的单词数。
- 文档向量: p v dm ( d ) pv_{\text{dm}}(d) pvdm(d),表示文档d的向量表示。
- 单词向量:每个单词 w i w_i wi都有一个对应的向量表示 w i w_i wi。
- 预测:给定输入部分文本 ( w 1 , w 2 , . . . , w k ) (w_1, w_2, ..., w_k) (w1,w2,...,wk),模型尝试预测缺失文本 w k + 1 w_{k+1} wk+1。
- 损失函数:使用交叉熵或其他适当的损失函数计算预测值与真实值之间的差异。
- 训练:通过反向传播和梯度下降算法更新文档向量和单词向量。
PV-DBOW模型:
- 输入:一个文档d,由单词序列 ( w 1 , w 2 , . . . , w n ) (w_1, w_2, ..., w_n) (w1,w2,...,wn)组成,其中 n n n是文档中的单词数。
- 文档向量: p v dbow ( d ) pv_{\text{dbow}}(d) pvdbow(d),表示文档d的向量表示。
- 单词向量:每个单词 w i w_i wi都有一个对应的向量表示 w i w_i wi。
- 预测:给定一个文档d,模型尝试预测与该文档相关的上下文单词。
- 损失函数:使用交叉熵或其他适当的损失函数计算预测值与真实值之间的差异。
- 训练:通过反向传播和梯度下降算法更新文档向量和单词向量。
方法三:BERT
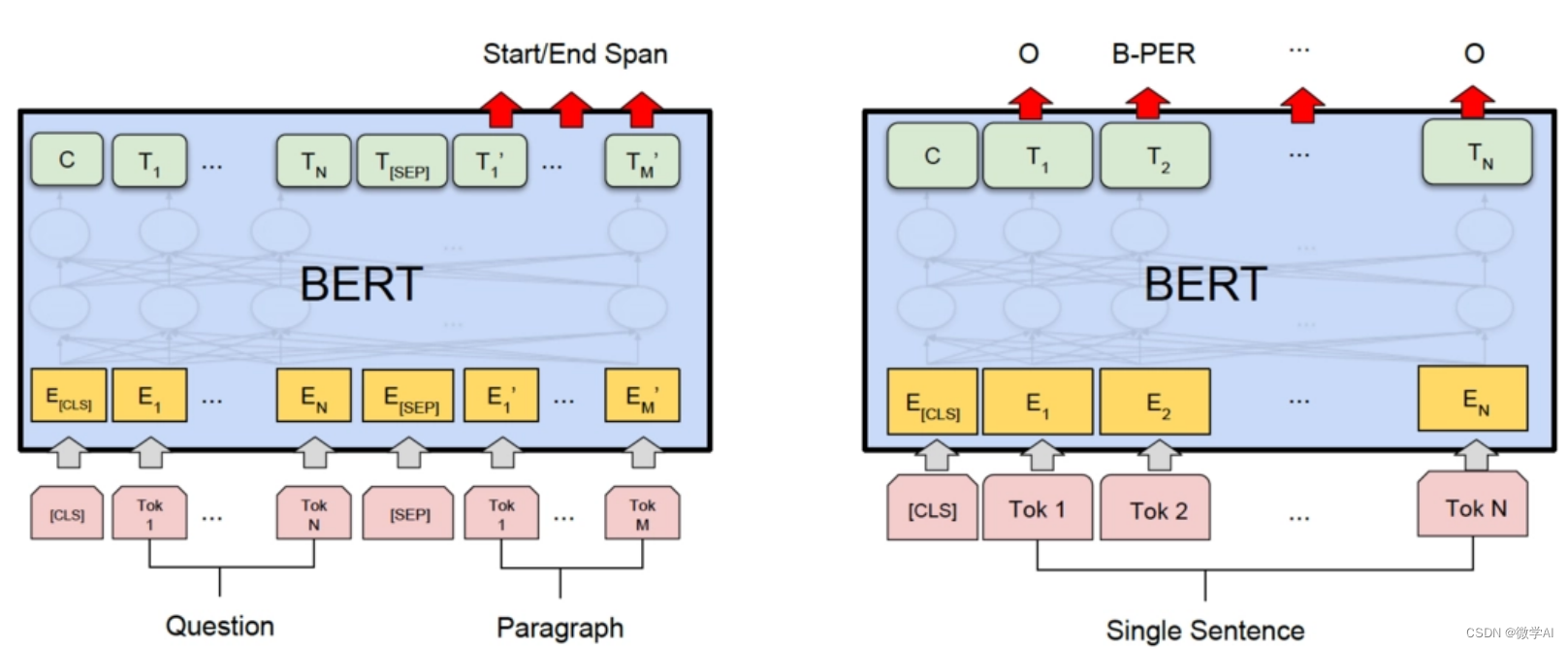
BERT是一种基于Transformer的深度学习模型,它可以获取到句子的深层次语义信息。
BERT模型的数学原理基于两个关键概念:MLM和NSP。
首先,我们将输入文本序列表示为一系列的词向量,并且为每个词向量添加相对位置编码。然后,通过多次堆叠的Transformer层来进行特征抽取。
在MLM阶段,BERT会对输入序列中的一部分词进行随机掩码操作,即将这些词的嵌入向量替换为一个特殊的标记 “[MASK]”。然后,模型通过上下文上下文预测这些被掩码的词。
在NSP阶段,BERT会将两个句子作为输入,并判断它们是否是原始文本中的连续句子。这个任务旨在帮助模型学习到句子级别的语义信息。
具体而言,BERT模型的数学原理包括以下几个步骤:
- 输入嵌入层:输入是一系列的词语索引,将其映射为词向量表示。
- 位置编码:为每个输入添加相对位置编码,以便模型能够理解词语之间的顺序关系。
- Transformer层:通过多次堆叠的Transformer层进行特征抽取,每层由多头自注意力机制和前馈神经网络组成。
- Masked Language Model(MLM):对输入序列中的一部分词进行掩码,并通过上下文预测这些被掩码的词。
- Next Sentence Prediction(NSP):将两个句子作为输入,判断它们是否是原始文本中的连续句子。
项目实践与代码
接下来,我们将通过一个例子来展示如何实现中文文本的句子嵌入。我们将使用Python语言和相关的NLP库(如gensim,torch,transformers等)来完成。
数据预处理
首先,我们需要对数据进行预处理,包括分词,去除停用词等。以下是一个简单的数据预处理代码示例:
import jiebadef preprocess_text(text):# 使用jieba进行分词words = jieba.cut(text)# 去除停用词stop_words = set(line.strip() for line in open('stop_words.txt', 'r', encoding='utf-8'))words = [word for word in words if word not in stop_words]return words
句子嵌入实现
接下来,我们将展示如何使用上述的三种方法来实现句子嵌入。
方法一:Word2Vec + 文本向量平均
from gensim.models import Word2Vecdef sentence_embedding_word2vec(sentences, size=100, window=5, min_count=5):# 训练Word2Vec模型model = Word2Vec(sentences, size=size, window=window, min_count=min_count)# 对每个句子的词向量进行平均sentence_vectors = []for sentence in sentences:vectors = [model.wv[word] for word in sentence if word in model.wv]sentence_vectors.append(np.mean(vectors, axis=0))return sentence_vectors
方法二:Doc2Vec
from gensim.models import Doc2Vec
from gensim.models.doc2vec import TaggedDocumentdef sentence_embedding_doc2vec(sentences, vector_size=100, window=5, min_count=5):# 将句子转化为TaggedDocument对象documents = [TaggedDocument(doc, [i]) for i, doc in enumerate(sentences)]# 训练Doc2Vec模型model = Doc2Vec(documents, vector_size=vector_size, window=window, min_count=min_count)# 获取句子向量sentence_vectors = [model.docvecs[i] for i in range(len(sentences))]return sentence_vectors
方法三:BERT
import torch
from transformers import BertTokenizer, BertModel# 加载预训练的BERT模型和分词器
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
model = BertModel.from_pretrained('bert-base-chinese')# 输入待转换的句子
sentence = "这是一个示例句子。"# 使用分词器将句子分成tokens
tokens = tokenizer.tokenize(sentence)# 添加特殊标记 [CLS] 和 [SEP]
tokens = ['[CLS]'] + tokens + ['[SEP]']# 将tokens转换为对应的id
input_ids = tokenizer.convert_tokens_to_ids(tokens)# 创建输入tensor
input_tensor = torch.tensor([input_ids])# 使用BERT模型获取句子的嵌入向量
with torch.no_grad():outputs = model(input_tensor)sentence_embedding = outputs[0][0][0] # 取第一个句子的第一个token的输出作为句子的嵌入向量# 输出句子的嵌入向量
print(sentence_embedding)
print(sentence_embedding.shape)
总结
本文详细介绍了句子嵌入在NLP中的应用项目,以及几种常见的中文文本句子嵌入的实现方式。我们通过实践和代码示例展示了如何使用Word2Vec + 文本向量平均,Doc2Vec,和BERT来实现句子嵌入。希望本文能够帮助读者更好地理解句子嵌入,并在实际项目中应用句子嵌入技术。
相关文章:
人工智能任务1-【NLP系列】句子嵌入的应用与多模型实现方式
大家好,我是微学AI,今天给大家介绍一下人工智能任务1-【NLP系列】句子嵌入的应用与多模型实现方式。句子嵌入是将句子映射到一个固定维度的向量表示形式,它在自然语言处理(NLP)中有着广泛的应用。通过将句子转化为向量…...
【Java并发编程面试题(60道)】
toc Java并发编程面试题(60道) 基础 1.并行跟并发有什么区别? 从操作系统的角度来看,线程是CPU分配的最小单位。 并行就是同一时刻,两个线程都在执行。这就要求有两个CPU去分别执行两个线程。并发就是同一时刻,只有一个执行&…...

Python:逢七拍腿游戏
场景模拟: 通过在 for 循环中使用 continue 语句实现计算拍腿次数,即计算从1到100(不包括100),一共有多少个尾数为7或7的倍数这样的游戏,代码如下: total 99 # 记…...

esp32C3 micropython oled 恐龙快跑游戏
目录 简介 效果展示 源代码 main.py ssd1306.py 实现思路 血量值 分数 恐龙 障碍物 得分与血量值的计算 简介 使用合宙esp32c3模块,基于micropython平台开发的一款oled小游戏,恐龙快跑,所有代码已经给出,将两个py文件…...
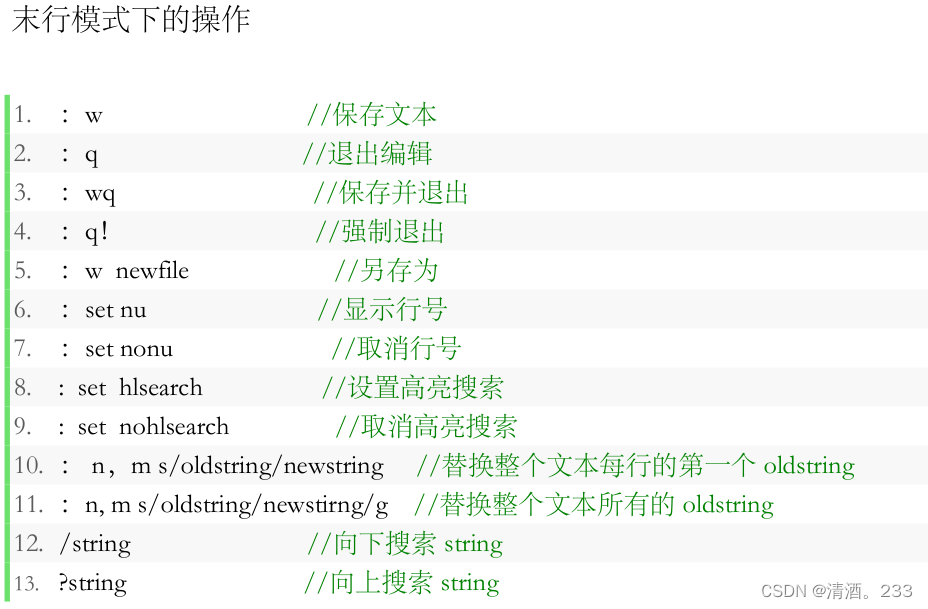
53.Linux day03 文件查看命令,vi/vim常用命令
今天进行了新的学习。 目录 1.cat a.查看单个文件的内容: b.查看多个文件的内容: c.将多个文件的内容连接并输出到一个新文件: d.显示带有行号的文件内容: 2.more 3.less 4.head 5.tail 6.命令模式 7.插入模式 8.图…...
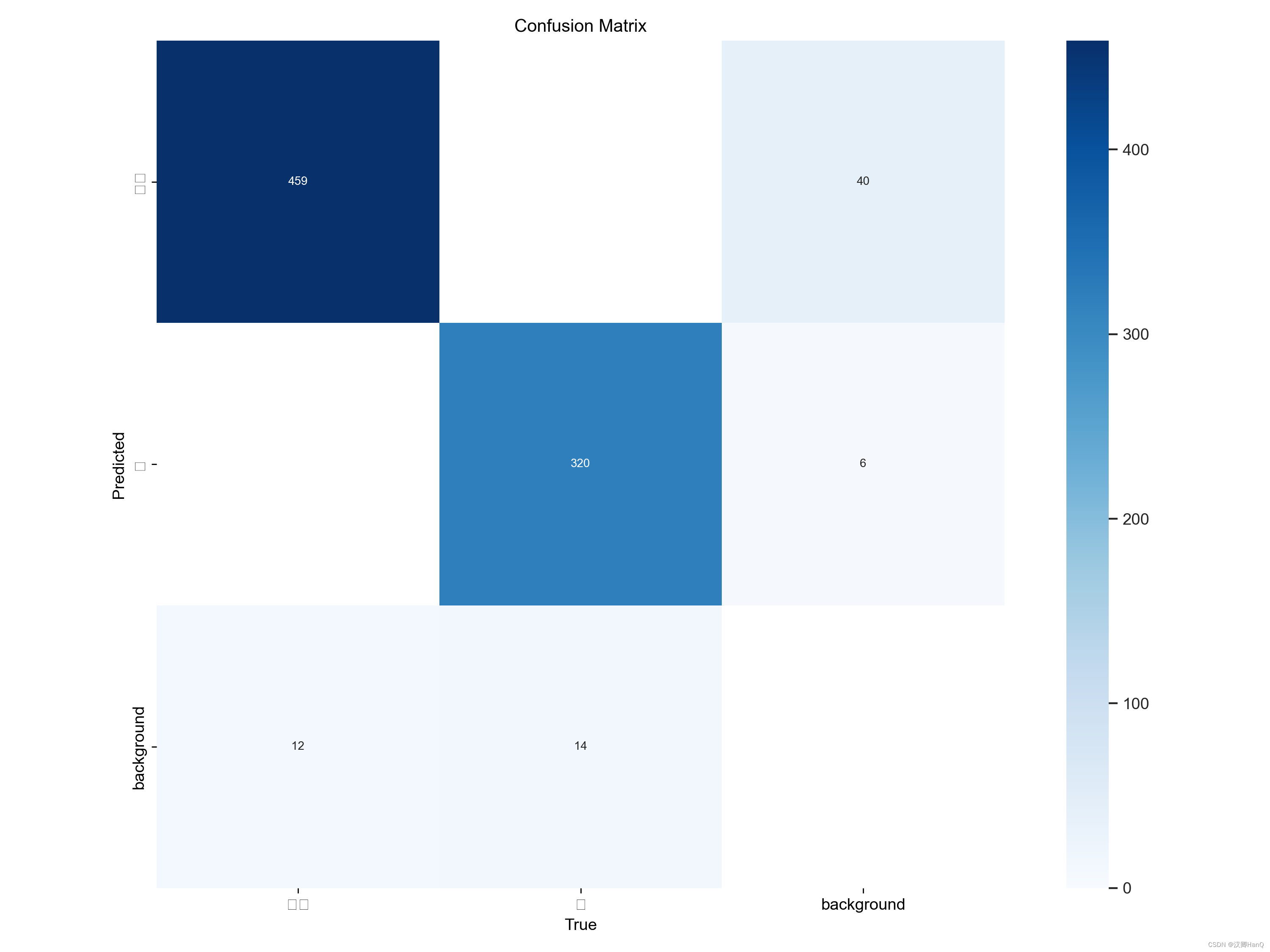
YOLOv8改进后效果
数据集 自建铁路障碍数据集-包含路障,人等少数标签。其中百分之八十作为训练集,百分之二十作为测试集 第一次部署 版本:YOLOv5 训练50epoch后精度可达0.94 mAP可达0.95.此时未包含任何改进操作 第二次部署 版本:YOLOv8改进版本 首…...
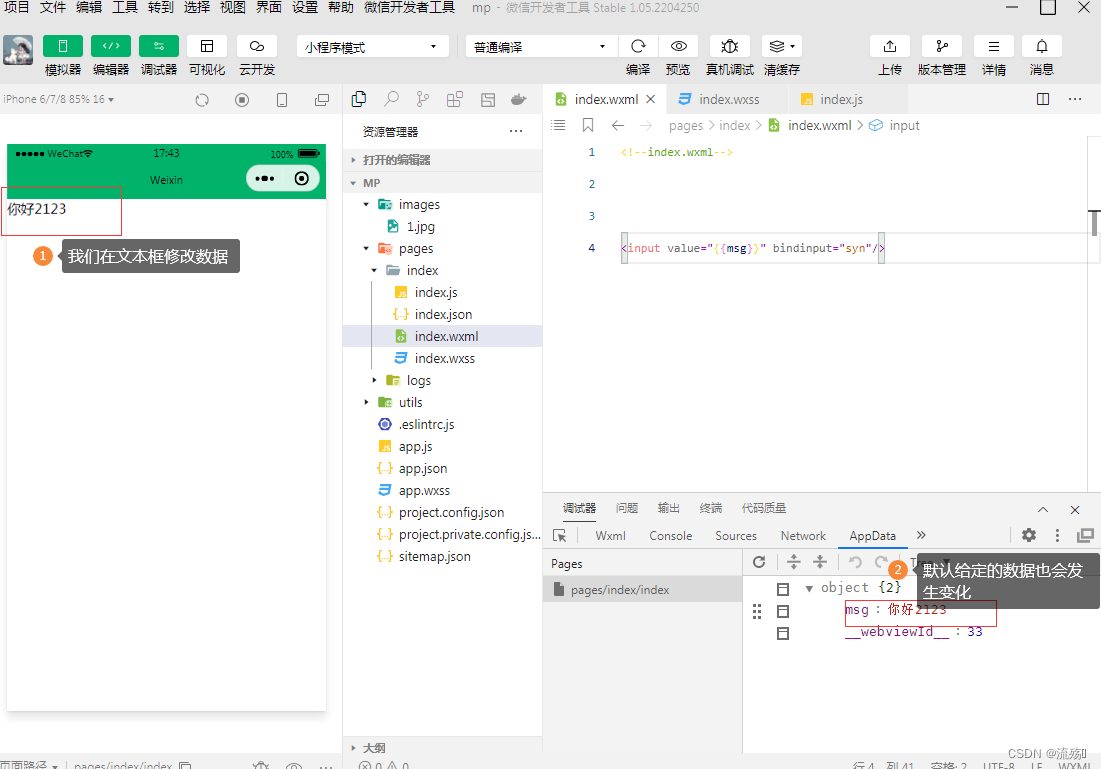
小程序的数据绑定和事件绑定
小程序的数据绑定 1.需要渲染的数据放在index.js中的data里 Page({data: {info:HELLO WORLD,imgSrc:/images/1.jpg,randomNum:Math.random()*10,randomNum1:Math.random().toFixed(2)}, }) 2.在WXML中通过{{}}获取数据 <view>{{info}}</view><image src"{{…...

第四章MyBatis核心配置文件
environments与environment标签 environments主要用来配置环境,属性default表示默认环境,值为environment的idenvironment为具体环境,属性id表示环境唯一标识environments可以有多个environment 加载默认环境 sqlSessionFactory sqlSessi…...
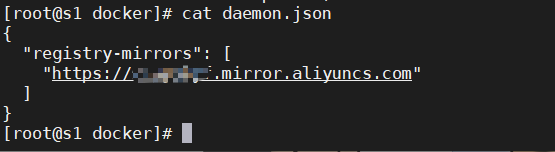
⛳ Docker - Centos 安装配置
目录 ⛳ Docker - Centos 安装配置🏭 Docker 安装:📢 一、安装依赖包💬 二、添加 Docker 下载源地址🐾 三、更新yum缓存👣 四、安装Docker💻 五、启动Docker🎁 六、查看Docker状态和…...
Python web实战之Django 的跨站点请求伪造(CSRF)保护详解
关键词:Python、Web、Django、跨站请求伪造、CSRF 大家好,今天我将分享web关于安全的话题:Django 的跨站点请求伪造(CSRF)保护,介绍 CSRF 的概念、原理和保护方法. 1. CSRF 是什么? CSRF&#…...
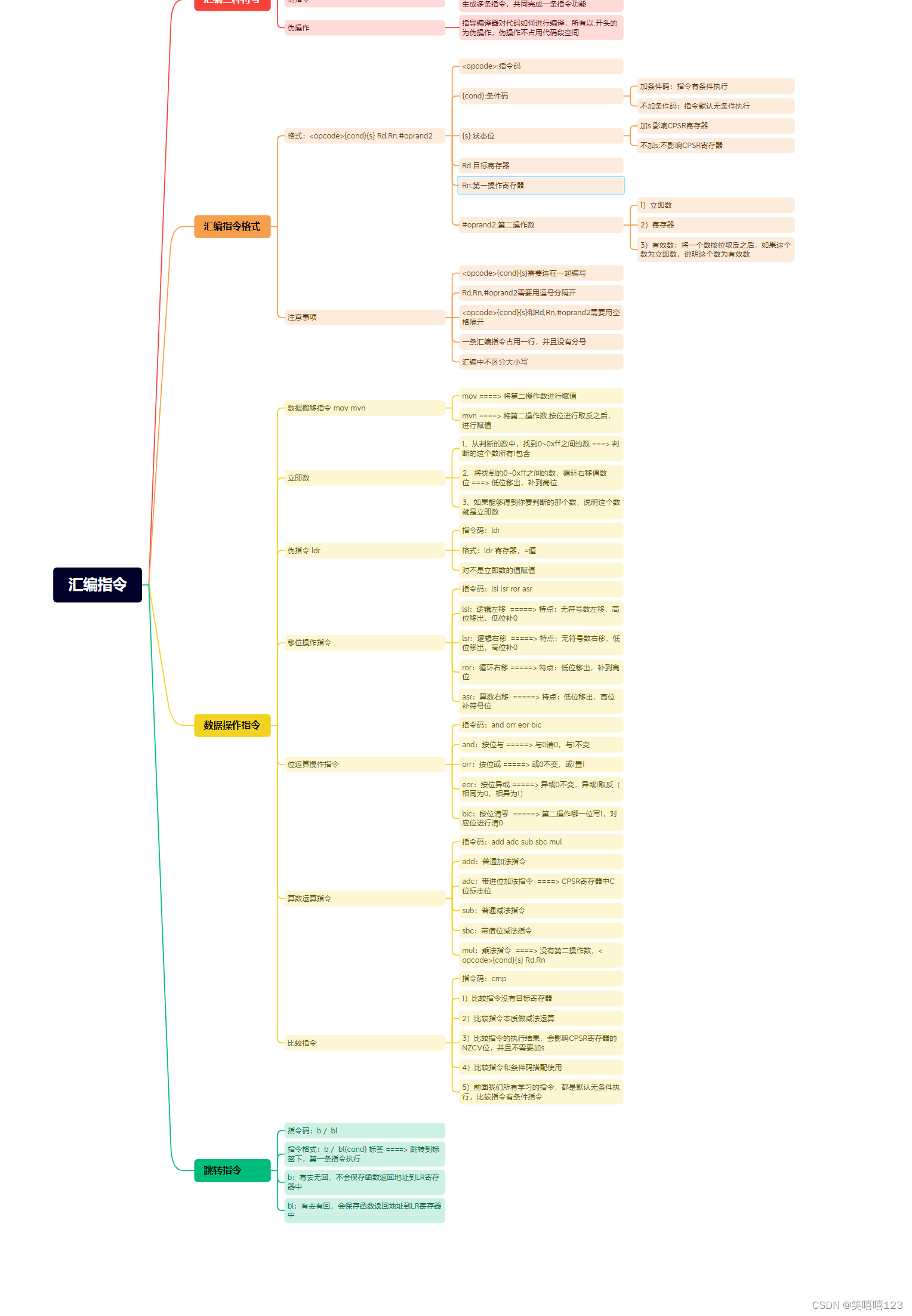
ARM(汇编指令)
.global _start _start:/*mov r0,#0x5mov r1,#0x6 bl LoopLoop:cmp r0,r1beq stopsubhi r0,r0,r1subcc r1,r1,r0mov pc,lr*/ mov r0,#0x1mov r1,#0x0mov r2,#0x64bl Loop Loop:cmp r0,r2bhi stopadd r1,r1,r0add r0,r0,#0x01mov pc,lr stop:B stop.end...

神经网络基础-神经网络补充概念-01-二分分类
概念 二分分类是一种常见的机器学习任务,其目标是将一组数据点分成两个不同的类别。在二分分类中,每个数据点都有一个与之关联的标签,通常是“正类”或“负类”。算法的任务是根据数据点的特征来学习一个模型,以便能够准确地将新…...
 线程同步)
Linux16(1) 线程同步
目录 1、概念 2、线程的实现: 3、线程同步: 4、使用信号量: 5、使用信号量实现进程同步: 6、使用互斥锁 7、使用互斥锁实现线程同步 8、读写锁 9、使用读写锁 10、使用读写锁实现进程同步 1、概念 线程:进程…...

深入探讨lowess算法:纯C++实现与局部加权多项式回归的数据平滑技术
引言 在统计学和数据科学中,有时我们面对的数据是嘈杂的、充满噪声的。为了更好地揭示数据的潜在趋势和结构,数据平滑技术成为了一个重要工具。lowess或称为局部加权多项式回归是其中的一种流行方法,它对每一个点给予一个权重,根…...
 Groth16的可塑性)
Sui安全篇|详解零知识证明 (ZKP) Groth16的可塑性
Sui Move允许用户使用Groth16进行高效验证任何非确定性多项式时间(Non-deterministic Polynomial time ,NP)状态。Groth16是一种高效且广泛使用的零知识简洁非交互知识证明(Zero-Knowledge Succinct Non-interactive Argument of …...

记录--webpack和vite原理
这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助 前言 每次用vite创建项目秒建好,前几天用vue-cli创建了一个项目,足足等了我一分钟,那为什么用 vite 比 webpack 要快呢,这篇文章带你梳理清楚它们的原理…...

Windows系统中使用bat脚本启动git bash 并运行指定命令 - 懒人一键git更新
目标 双击"autoGitPull.bat",自动打开git bash,并cd到项目,逐个git pull,保留git bash窗口展示进度。 脚本 start "" "D:\Program Files\Git\git-bash.exe" -c "echo autoGitPull &&…...

elementui form组件出现英文提示
今天让解决一个bug,是表单组件提示词会出现英文。 问题情景如下: 有时会出现中文,有时会出现英文。 解决方法: 经查看,代码采用的是elementui的form组件,在el-form-item中使用了required属性,同…...

使用windows Api简单验证ISO9660文件格式,以及装载和卸载镜像文件
使用IIsoImageManager接口简单验证ISO镜像文件正确性,使用AttachVirtualDisk装载ISO镜像文件,和使用DetachVirtualDisk卸载,(只支持windows 8及以上系统) 导读 IIsoImageManager 验证ISO文件正确性AttachVirtualDisk 装载镜像文件DetachVirtualDisk 卸载镜像文件其他相关函…...

iPhone 15受益:骁龙8 Gen 3可能缺席部分安卓旗舰机
明年一批领先的安卓手机的性能可能与今年的机型非常相似。硅成本的上涨可能是原因。 你可以想象,2024年许多最好的手机都会在Snapdragon 8 Gen 3上运行,这是高通公司针对移动设备的顶级芯片系统的更新,尚未宣布。然而,来自中国的…...

ComfyUI-Manager 3步深度优化:构建稳定高效的AI工作流管理平台
ComfyUI-Manager 3步深度优化:构建稳定高效的AI工作流管理平台 【免费下载链接】ComfyUI-Manager ComfyUI-Manager is an extension designed to enhance the usability of ComfyUI. It offers management functions to install, remove, disable, and enable vario…...
)
Midjourney Mud印相实战手册(含12组高保真历史文物级Mud Prompt库+对应seed校验表)
更多请点击: https://intelliparadigm.com 第一章:Midjourney Mud印相的技术起源与美学范式 Mud印相(Mud Printing)并非传统暗房工艺的直系衍生物,而是Midjourney V6 模型在高语义控制模式下催生的一种跨模态视觉隐喻…...

Linux系统信息查询全攻略:从内核到发行版的深度解析与脚本实践
1. 项目概述:一个看似简单却暗藏玄机的基础操作“查看Linux系统版本”,这几乎是每个运维工程师、开发人员乃至普通用户在接触Linux系统时,第一个需要掌握的命令。它简单到常常被新手教程一笔带过,却又复杂到足以让老手在排查问题时…...

MEMS传感器机械臂姿态检测【附代码】
✨ 长期致力于MEMS传感器、机械臂、惯性测量单元、数据融合、姿态检测系统研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)设计基于ICM20948的惯性测量…...

【BK3633】从规格书到实战:解锁蓝牙5.2双模芯片的十大核心应用场景
1. BK3633芯片核心特性解析 第一次拿到BK3633规格书时,我被它的参数惊艳到了——这简直是为物联网设备量身定制的瑞士军刀。作为博通集成推出的蓝牙5.2双模芯片,它完美兼顾了高性能与低功耗这对"冤家"。实测下来,全速运行电流仅5mA…...

Mac运行CORE Keygen受阻?巧用UPX与brew轻松解包
1. 当Mac遇到CORE Keygen无法运行时该怎么办? 最近有不少朋友在Mac上运行CORE Keygen时遇到了问题,双击应用图标后要么毫无反应,要么直接弹出"无法打开"的提示。这种情况其实很常见,特别是对于一些特殊用途的应用程序。…...

英雄联盟终极自动化工具:LeagueAkari 免费完整指南,告别繁琐操作
英雄联盟终极自动化工具:LeagueAkari 免费完整指南,告别繁琐操作 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 你是否…...

AI提示词工程化:Git仓库管理、版本控制与团队协作实战
1. 项目概述:一个提示词仓库的诞生与价值最近在折腾AI应用开发时,我遇到了一个几乎所有开发者都会头疼的问题:如何高效地管理和复用那些精心调校过的提示词(Prompt)。无论是用于代码生成的、内容创作的,还是…...

2026届学术党必备的五大降AI率工具解析与推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 每位学者以及学生,在学术研究的这条道路之上,都必然要跨越论文写作这…...
)
STM32单片机如何用IRIG-B解码模块实现10ns级高精度授时(附完整驱动代码)
STM32单片机如何用IRIG-B解码模块实现10ns级高精度授时(附完整驱动代码) 在工业自动化、电力系统同步、通信基站等对时间精度要求苛刻的领域,微秒级甚至毫秒级的时钟同步已经无法满足需求。IRIG-B作为一种标准时间码格式,通过解码…...