大模型技术实践(一)|ChatGLM2-6B基于UCloud UK8S的创新应用
近半年来,通过对多款主流大语言模型进行了调研,我们针对其训练方法和模型特点进行逐一分析,方便大家更加深入了解和使用大模型。本文将重点分享ChatGLM2-6B基于UCloud云平台的UK8S实践应用。
01各模型结构及特点
自从2017年6月谷歌推出Transformer以来,它已经成为自然语言处理领域的重要里程碑和核心模型之一。从2018年至今推出的主流模型GPT、BERT、T5、ChatGLM、LLaMA系列模型,都是以Transformer为基本架构实现的。
BERT
使用了Transformer中Encoder编码器。
特点:
1. 双向注意力,也就是说每个时刻的Attention计算都能够得到全部时刻的输入,可同时感知上下文。
2. 适合文本理解,但不适合生成任务。
GPT
使用Transformer中Decoder解码器。
特点:
1. 单向注意力,无法利用下文信息。
2. 适合文本生成领域。
T5
采用Transformer的Encoder-Decoder结构。
改动:
1. 移除了层归一化的偏置项。
2. 将层归一化放置在残差路径之外。
3. 使用了相对位置编码,且是加在Encoder中第一个自注意力的Query和Key乘积之后。
特点:
1. 编码器的注意力是双向的,解码器的注意力是单向的,所以可以同时胜任理解和生成任务。
2. 参数量大。
LLaMA
使用Transformer中Decoder解码器。
改动:
1. 预归一化。对每个Transformer子层的输入进行规范化,而不是对输出进行规范化。
2. SwiGLU激活函数。采用SwiGLU激活函数替换了ReLU。
3. 旋转嵌入。删除了绝对位置嵌入,而在网络的每一层增加了旋转位置嵌入。
特点:
1. LLaMA-13B比GPT-3(参数量为175B)小10倍,但在大多数基准测试中都超过了GPT-3。
2. 没有将中文语料加入预训练,LLaMA在中文上的效果很弱。
ChatGLM
ChatGLM是基于GLM-130B训练得到的对话机器人。GLM使用了一个单独的Transformer。
改动:
1. 自定义Mask矩阵。
2. 重新排列了层归一化和残差连接的顺序。
3. 对于输出的预测标记,使用了一个单独的线性层。
4. 将ReLU激活函数替换为GeLU函数。
5. 二维位置编码。
特点:
通过Mask矩阵,GLM把BERT、GPT、T5这3个模型优点结合起来:
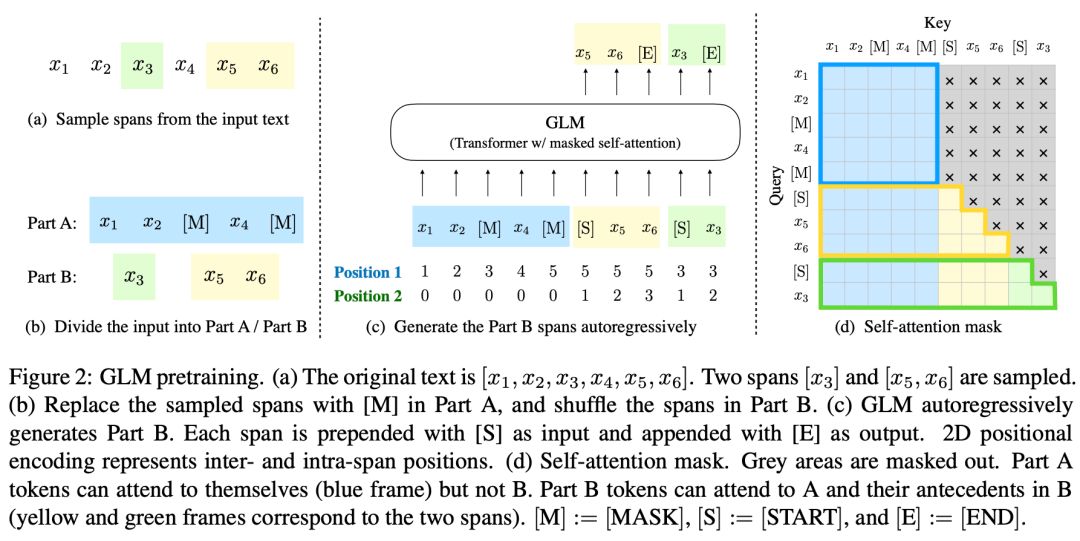
1. 当整个的文本被Mask时,空白填充任务等价于无条件语言生成任务。
2. 当被掩码的片段长度为1时,空白填充任务等价于掩码语言建模任务。
3. 当文本1和文本2拼接在一起时,再将文本2掩码掉,空白填充任务等价于有条件语言生成任务。
随机从一个参数为3的泊松分布中采样片段的长度,直到至少遮盖了原始Token的15%。然后在文本中随机排布填空片段的位置,如Part B所示。另外,Position 1表示的是Mask后的文本中的位置,Position 2表示的是在Mask内部的相对位置。
02训练方法及训练目标
各大语言模型的训练基本都是基于大规模无标签语料来训练初始的语言模型,再利用下游任务的有标签训练语料,进行微调训练。
BERT
BERT使用了Transformer的Encoder作为Block,既参考了ELMo模型的双向编码思想,参考了GPT用Transformer作为特征提取器的方法,又参考了 Word2Vec所使用的CBOW方法。
BERT的训练方法
分为两个阶段,分别是多任务训练目标的预训练阶段和基于有标签语料的微调阶段。
BERT的预训练目标
• 掩码语言模型:Masked Language Model(MLM),目的是提高模型的语义理解能力,即对文本进行随机掩码,然后预测被掩码的词。
• 下句预测:Next Sentence Prediction(NSP),目的是训练句子之间的理解能力,即预测输入语句对(A,B)中,句子B是否为句子A的下一句。
T5
T5模型采用Transformer的Encoder和Decoder,把各种NLP任务都视为Text-to-Text任务。
T5的训练方法
同样采用了预训练和微调的训练策略。
T5模型采用了两个阶段的训练:Encoder-Decoder Pretraining(编码器-解码器预训练)和 Denoising Autoencoder Pretraining(去噪自编码器预训练)。
在Encoder-Decoder Pretraining阶段,T5模型通过将输入序列部分遮盖(用特殊的占位符替换)然后让模型预测被遮盖掉的词或片段。这可以帮助模型学习到上下文理解和生成的能力。
在Denoising Autoencoder Pretraining阶段,T5模型通过将输入序列部分加入噪声或随机置换,然后将模型训练为还原原始输入序列。这可以增强模型对输入的鲁棒性和理解能力。
T5的预训练目标
类似BERT的MLM。T5中可Mask连续多个Token,让模型预测出被Mask掉的Token到底有几个,并且是什么。

GPT
GPT采用两阶段式训练方法
第一阶段:在没有标注的数据集中进行预训练,得到预训练语言模型。
第二阶段:在有标注的下游任务上进行微调。(有监督任务上进行了实验,包括自然语言推理、问答、语义相似度和文本分类等。)
除了常规的有监督微调,引入RLHF(人类反馈强化学习)之后,还需要:
收集数据并训练奖励模型。
使用强化学习对语言模型进行微调。
GPT的训练目标
是从左到右的文本生成,无条件生成。
GPT2
在无Finetune的Zero-Shot场景下进行,也就是“无监督,多任务”。
在原始Input上加入任务相关Prompt,无需微调也可做任务。
GPT3
2020年5月模型参数规模增加到1750亿,大力出奇迹,预训练后不需要微调。
提出了In-Context Learning。
2020年9月,GPT3引入RLHF。
2022年3月的OpenAI发布InstructGPT,也就是GPT3+Instruction Tuning+RLHF+PPO。
GPT4
2023年3月,GPT4支持图片形式输入。
LLaMA
训练一系列语言模型,使用的更多的Token进行训练,在不同的推理预算下达到最佳的性能。
模型参数包括从7B到65B等多个版本:
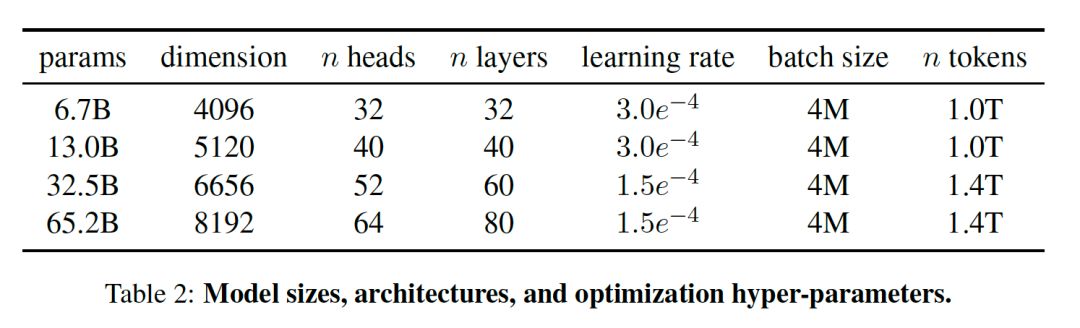
LLaMA的训练方法
无监督预训练。
有监督微调,训练奖励模型,根据人类反馈进行强化学习。
LLaMA的任务
零样本和少样本任务,并在总共20个基准测试上报告了结果:
零样本。提供任务的文本描述和一个测试示例。模型要么通过开放式生成提供答案,要么对提出的答案进行排名。
少样本。提供任务的几个示例(1到64个)和一个测试示例。模型将这个文本作为输入,并生成答案或对不同选项进行排名。
LlaMA2相比于LLaMA
1. 支持更长的上下文,是LLaMA的2倍。
2. 提出Grouped-Query Attention,加速推理。
3. 提出Ghost Attention让多回合对话前后一致。
ChatGLM
对话机器人ChatGLM是基于GLM-130B模型训练得到的。结合模型量化技术,得到可在普通显卡部署的ChatGLM-6B。
GLM的预训练目标
文档级别的目标:从原始本文长度的50%到100%之间均匀分布的范围中进行抽样,得到片段。该目标旨在生成较长的文本。
句子级别的目标:限制被Mask的片段必须是完整的句子。抽样多个片段(句子)来覆盖原始Tokens的15%。该目标旨在用于Seq2seq任务,其中预测通常是完整的句子或段落。
ChatGLM的训练方法
无标签预训练,有监督微调、反馈自助、人类反馈强化学习等技术。
大语言模型小结
大语言模型的训练方式基本是海量无标签数据预训练,下游再用有标签数据微调。从GPT3开始,ChatGLM、LLaMA系列模型也都引入了基于人类反馈的强化学习,让模型与人类偏好对齐,这是一个很酷的想法。
03ChatGLM2-6B在K8S上的实践
获取项目代码和模型文件,相关链接如下
(https://github.com/THUDM/ChatGLM2-6B/tree/main)。
基于UCloud云平台的K8S实践
可参照UCloud文档中心(https://docs.ucloud.cn),登录UCloud控制台(https://console.ucloud.cn/uhost/uhost/create),创建UFS、创建UK8S。
创建文件存储UFS
先创建文件系统,将模型文件存储到UFS中,之后记得添加挂载点。

这是可选项,UFS优点是可多节点挂载。如果不使用UFS,模型文件可放在其他位置,需要在后续的ufspod.yml文件中做相应修改。
创建容器云UK8S
首选创建集群:
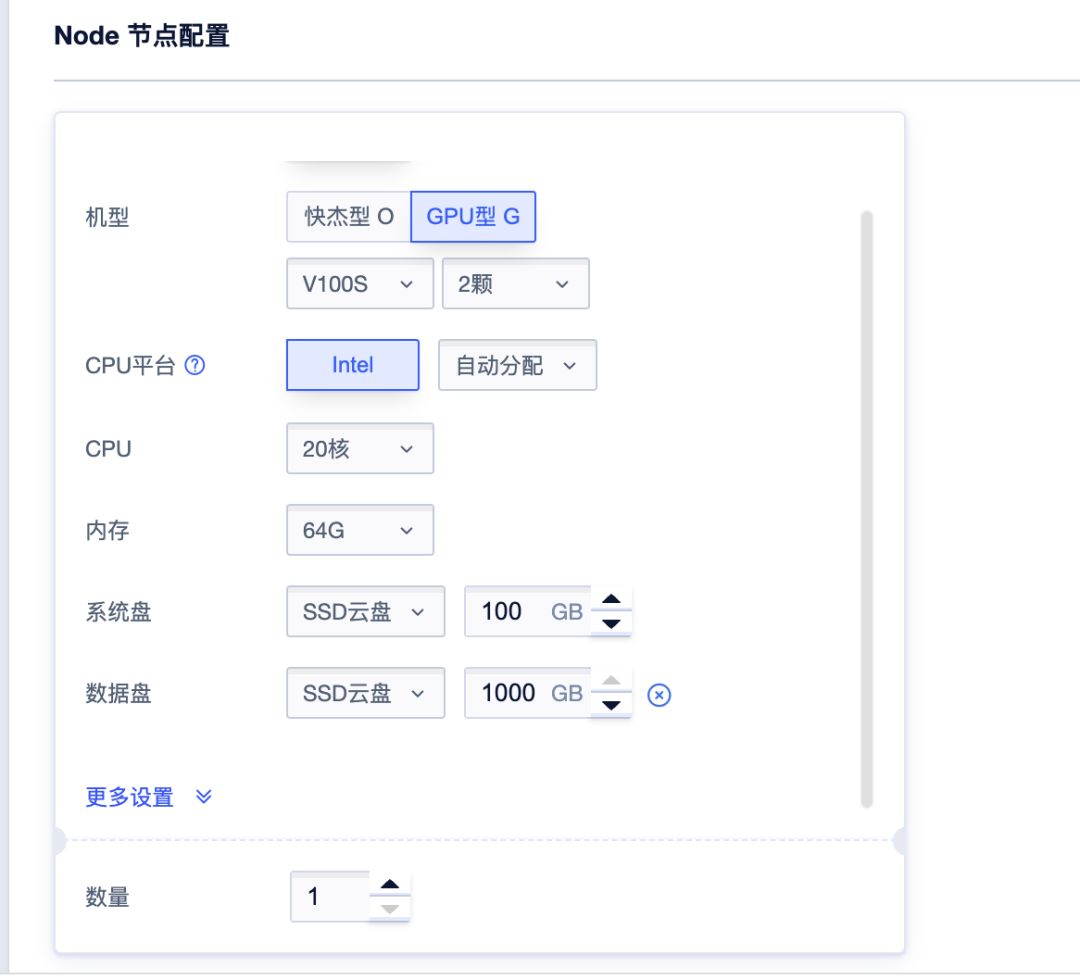
可自由选择Node节点到配置:
创建好了之后,界面如下:
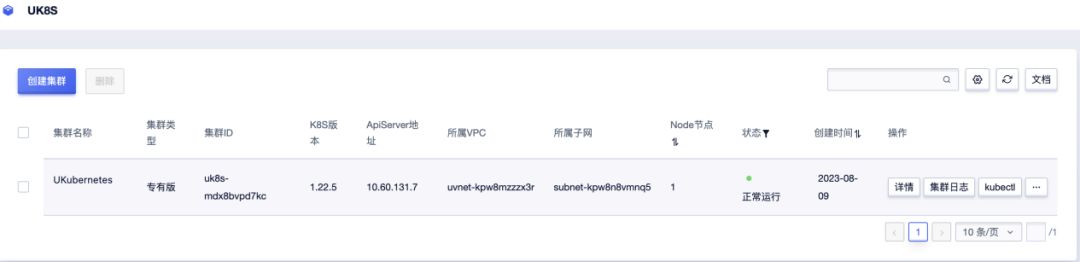
接下来可点击右侧的“详情”按钮,在跳转到的新页面左侧,点击“外网凭证”对应行的“查看”,可以看到如下图所示:
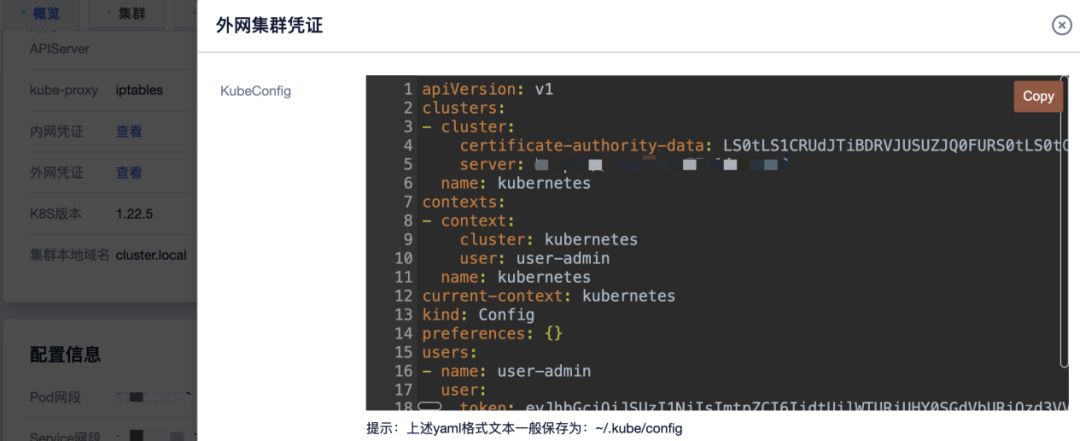
根据提示,保存文本内容到~/.kube/config文件中。
在UK8S中的Node节点:
安装Docker
安装英伟达GPU驱动
安装NVIDIA Container Toolkit
在UK8S中使用UFS
根据在UK8S中使用UFS(https://docs.ucloud.cn/uk8s/volume/ufs?id=在uk8s中使用ufs)的文档说明,创建PV和PVC。
登录UK8S的Node节点
首先参照文档安装及配置Kubectl(https://docs.ucloud.cn/uk8s/manageviakubectl/connectviakubectl?id=安装及配置kubectl)。
1. 先放上配置文件Ufspod.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: myfrontend
spec:
selector:
matchLabels:
app: myfrontend
replicas: 1
template:
metadata:
labels:
app: myfrontend
spec:
containers:
- name: myfrontend
image: uhub.service.ucloud.cn/yaoxl/chatglm2-6b:y1
volumeMounts:
- mountPath: "/app/models"
name: mypd
ports:
- containerPort: 7861
volumes:
- name: mypd
persistentVolumeClaim:
claimName: ufsclaim
---
apiVersion: v1
kind: Service
metadata:
name: myufsservice
spec:
selector:
app: myfrontend
type: NodePort
ports:
- name: http
protocol: TCP
port: 7861
targetPort: 7861
nodePort: 30619
2. 执行配置文件Ufspod.yml
kubectl apply -f ufspod.yml
3. 进入Pod
首先通过命令得到Pod Name:
kubectl get po
#NAME READY STATUS RESTARTS AGE
#myfrontend-5488576cb-b2wqw 1/1 Running 0 83m
在Pod内部启动一个Bash Shell:
kubectl exec -it <pod_name> -- /bin/bash
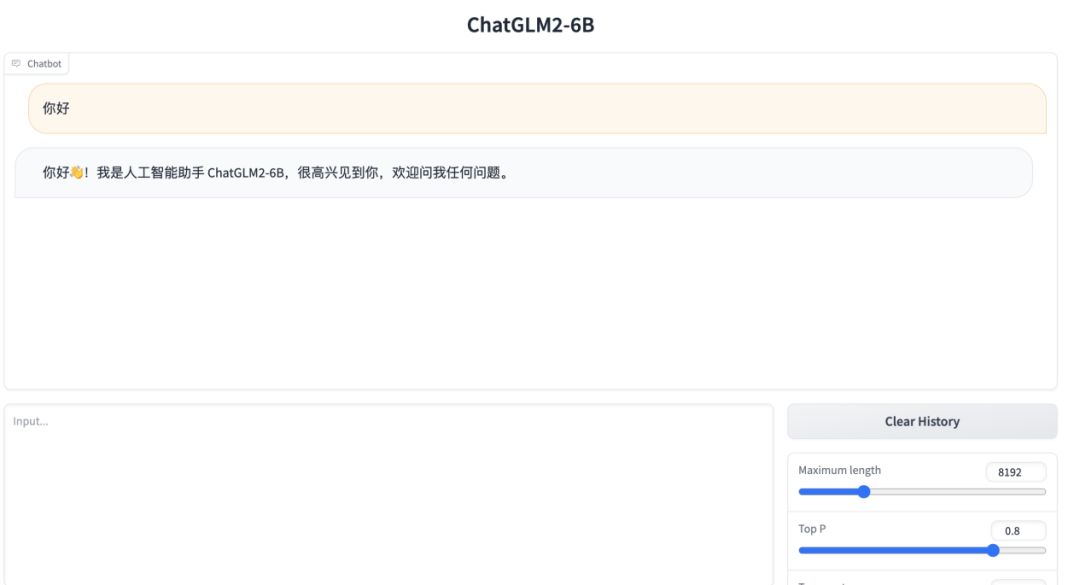
4. 打开网页版的Demo
执行:
python3 web_demo.py
得到:
UCloud将持续关注大语言模型的发展,并在后续发布有关LlaMA2实践、LangChain构建云上推理环境等方面的文章。欢迎大家保持关注并与我们进行更多交流探讨!
相关文章:
大模型技术实践(一)|ChatGLM2-6B基于UCloud UK8S的创新应用
近半年来,通过对多款主流大语言模型进行了调研,我们针对其训练方法和模型特点进行逐一分析,方便大家更加深入了解和使用大模型。本文将重点分享ChatGLM2-6B基于UCloud云平台的UK8S实践应用。 01各模型结构及特点 自从2017年6月谷歌推出Transf…...
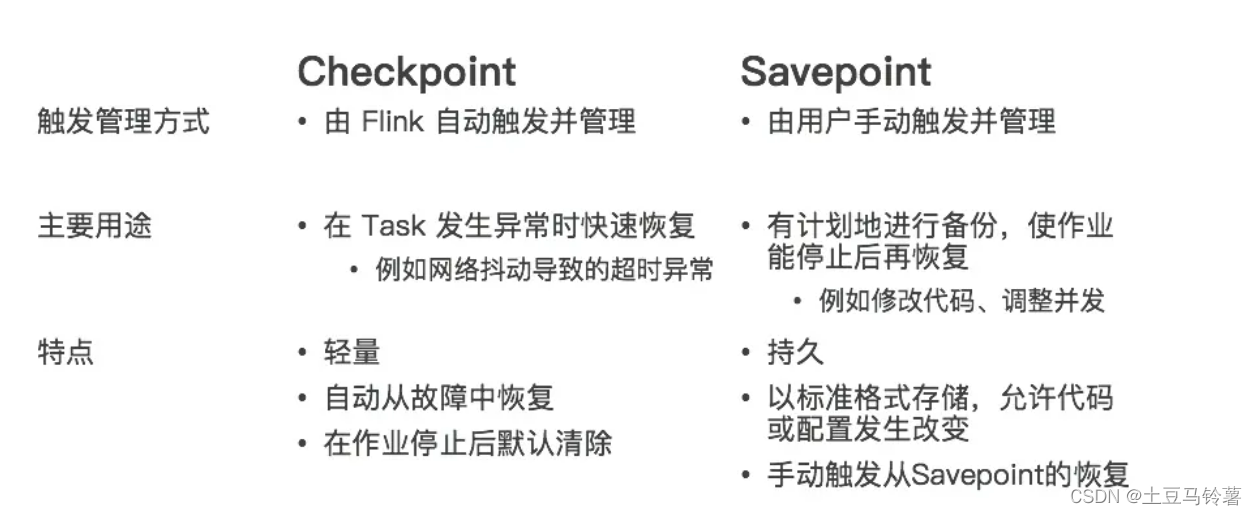
Flink状态和状态管理
1.什么是状态 官方定义:当前计算流程需要依赖到之前计算的结果,那么之前计算的结果就是状态。 这句话还是挺好理解的,状态不只存在于Flink,也存在生活的方方面面,比如看到一个认识的人,如何识别认识呢&am…...

【3Ds Max】布料命令的简单使用
简介 在3ds Max中,"布料"(Cloth)是一种模拟技术,用于模拟物体的布料、织物或软体的行为,例如衣物、帆布等。通过应用布料模拟,您可以模拟出物体在重力、碰撞和其他外力作用下的变形和动态效果。…...
用 VB.net,VBA 两种方式 读取单元格内的 换行数据,并出力到 CSV文件
用 VB.net,VBA 两种方式 读取单元格内的 换行数据,并出力到 CSV文件 需求 如下图所示,为了生成csv文件导入数据库,需要将下图 的 1 和 2 拼接成 如下 3 所示的一行数据, 开头为 1 ,往后为 2 的换行数据 将换…...
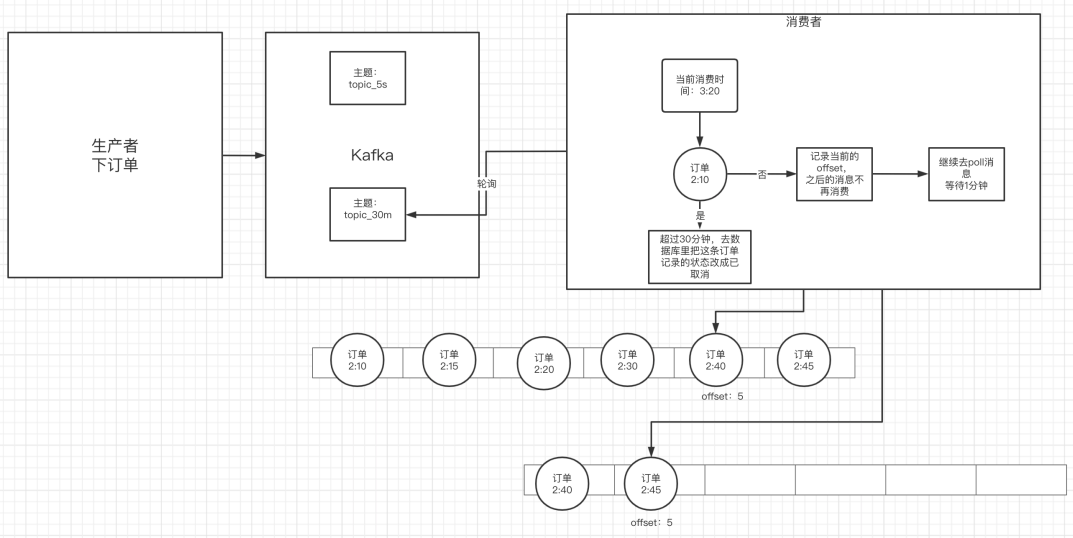
kafka线上问题优化
如何防止消息丢失 生产者: 使用同步发送把ack设成1或者all(非0,0可能会出现消息丢失的情况),并且设置同步的分区数>2 消费者:把自动提交改成手动提交 如何防止重复消费 在防止消息丢失的方案中&#…...

FifthOne:用于矢量搜索的计算机视觉接口
一、说明 数据太多了。数据湖和数据仓库;广阔的像素牧场和充满文字的海洋。找到正确的数据就像大海捞针一样!如果你喜欢开源机器学习库 FiftyOne,矢量搜索引擎通过将复杂数据(图像的原始像素值、文本文档中的字符)转换为称为嵌入矢…...

认识Axios
axios中文网 一. 为什么会诞生Axios 最初浏览器页面向服务器请求数据时,返回的是整个页面,整个页面都会刷新ajax的出现,它可以在页面无刷新的情况下请求数据原生的XMLHttpRequest,jQuery封装的ajax,以及axios都可以实…...
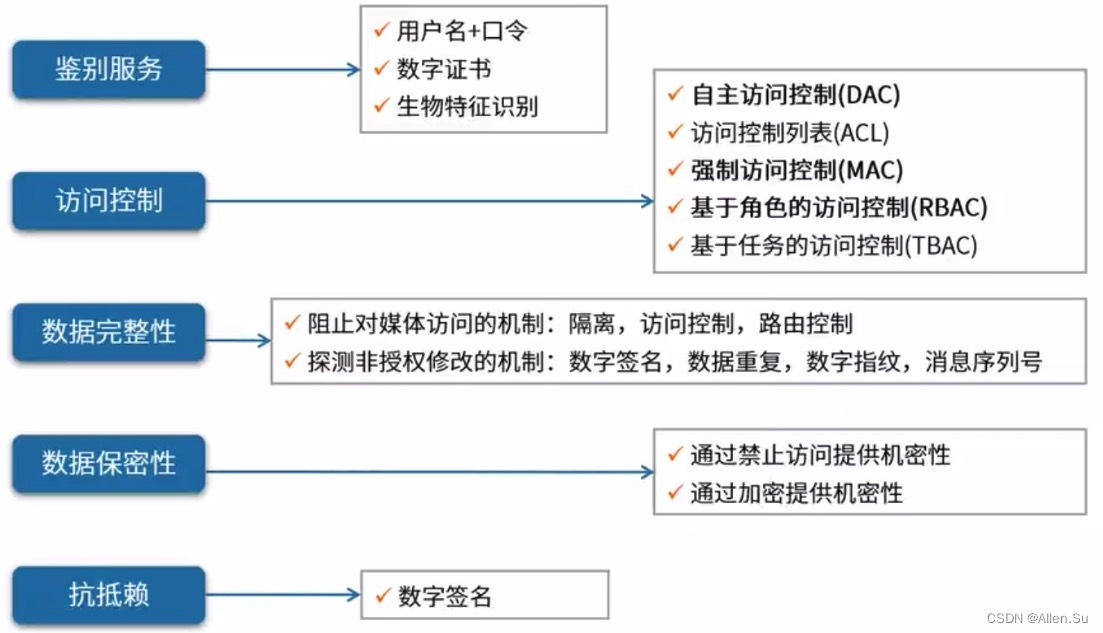
系统架构设计专业技能 · 信息安全技术
系列文章目录 系统架构设计专业技能 网络技术(三) 系统架构设计专业技能 系统安全分析与设计(四)【系统架构设计师】 系统架构设计高级技能 软件架构设计(一)【系统架构设计师】 系统架构设计高级技能 …...
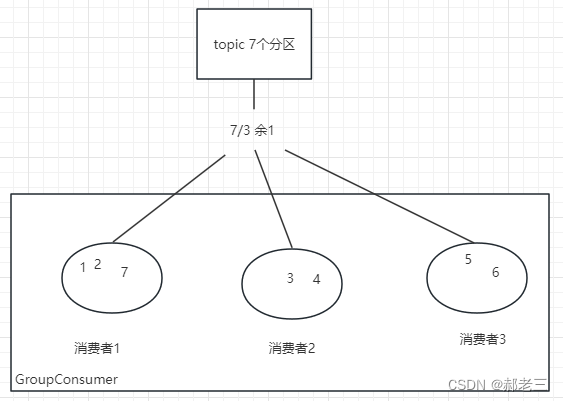
kafka晋升之路-理论+场景
kafka晋升之路 一:故事背景二:核心概念2.1 系统架构2.2 生产者(Producer)2.2.1 生产者分区2.2.2 生产者分区策略 2.3 经纪人(Broker)2.3.1 主题(Topic)2.3.2 分区(Partit…...

(牛客网)链表相加(二)
嗯哼~ 题目 描述 假设链表中每一个节点的值都在 0 - 9 之间,那么链表整体就可以代表一个整数。 给定两个这种链表,请生成代表两个整数相加值的结果链表。 数据范围:0 ≤ n,m ≤ 1000000,链表任意值 0 ≤ val ≤ 9 要求&#x…...

Vs code 使用中的小问题
1.Java在Vs code 中使用单元测试失败或者如何使用单元测试 创建Java项目,或者将要测试的文件夹添加进工作区 要出现lib包,并有两个测试用的jar包 编写测试文件 public class TestUnit{ public static void main(String[] args) {String str "…...

vue2和vue3
1. 双向数据绑定原理发生了改变 vue2的双向数据绑定是利用了es5 的一个API Object.definepropert() 对数据进行劫持 结合发布订阅模式来实现的。vue3中使用了es6的proxyAPI对数据进行处理。 相比与vue2,使用proxy API 优势有:defineProperty只能监听某个…...
火山引擎ByteHouse:一套方案,让OLAP引擎在精准投放场景更高效
由于流量红利逐渐消退,越来越多的广告企业和从业者开始探索精细化营销的新路径,取代以往的全流量、粗放式的广告轰炸。精细化营销意味着要在数以亿计的人群中优选出那些最具潜力的目标受众,这无疑对提供基础引擎支持的数据仓库能力࿰…...

【论文阅读】SHADEWATCHER:使用系统审计记录的推荐引导网络威胁分析(SP-2022)
SHADEWATCHER: Recommendation-guided CyberThreat Analysis using System Audit Records S&P-2022 新加坡国立大学、中国科学技术大学 Zengy J, Wang X, Liu J, et al. Shadewatcher: Recommendation-guided cyber threat analysis using system audit records[C]//2022 I…...
Mac 使用 rar 命令行工具解压和压缩文件
在 Mac 中常遇到的压缩文件有 zip 和 rar 格式的,如果是 zip 格式的 Mac 系统默认双击一下文件就能直接解压了,但 rar 文件就不行。 需要额外下载 rar 工具了实现。 第一步:下载 rar 工具 工具网址:https://www.rarlab.com/dow…...

7.maven
1 初始Maven 1.1 什么是Maven Maven是Apache旗下的一个开源项目,是一款用于管理和构建java项目的工具。 官网:https://maven.apache.org/ Apache 软件基金会,成立于1999年7月,是目前世界上最大的最受欢迎的开源软件基金会&…...
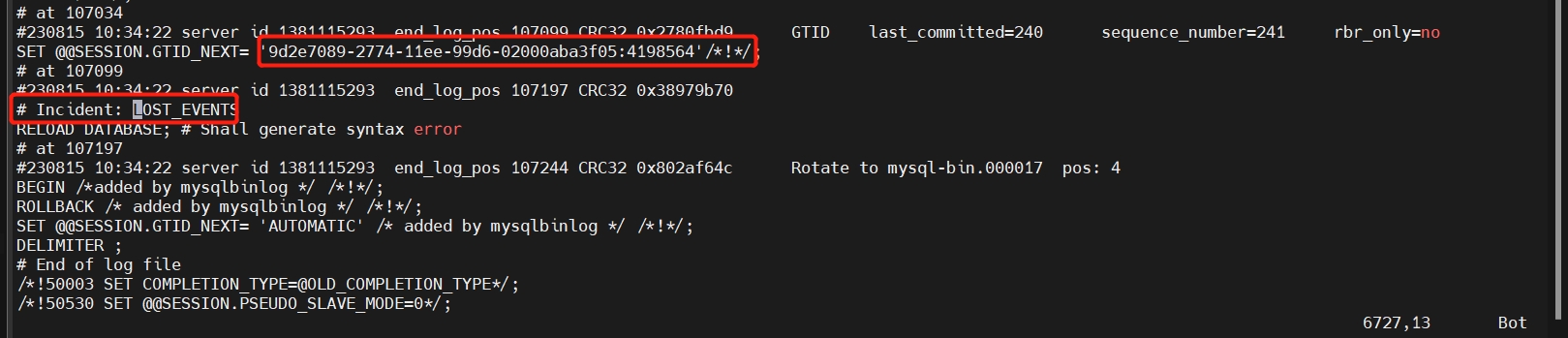
MySQL 主从复制遇到 1590 报错
作者通过一个主从复制过程中 1590 的错误,说明了 MySQL 8.0 在创建用户授权过程中的注意事项。 作者:王祥 爱可生 DBA 团队成员,主要负责 MySQL 故障处理和性能优化。对技术执着,为客户负责。 本文来源:原创投稿 爱可生…...

games101-windows环境配置(CMake+vcpkg+VS2019)
下载工具 安装CMake 安装vcpkg 安装vs2019 安装 eigen3 opencv 在vcpkg安装目录下,使用Windows Power Shell运行下面脚本 .\vcpkg.exe install eigen3:x64-windows .\vcpkg.exe install opencv:x64-windows安装过程中可能会用红色字体提示:Failed to…...
2023年Java核心技术面试第五篇(篇篇万字精讲)
目录 十 . HashMap,ConcurrentHashMap源码解析 10.1 HashMap 的源码解析: 10.1.1数据结构: 10.1.2哈希算法: 10.1.3解决哈希冲突: 10.1.4扩容机制: 10.1.5如何使用 HashMap: 10.2 HashMap 关注…...
第十课:Qt 字符编码和中文乱码相关问题
功能描述:最全的 Qt 字符编码相关知识以及中文乱码的原因与解决办法 一、字符编码种类 ASCII 码 美国人对信息交流的编码,包括 26 个字母(大小写)、数字和标点符号等,用一个字节(8 位)表示这些…...

WarcraftHelper:让经典魔兽争霸III在现代电脑上焕发新生的全能助手
WarcraftHelper:让经典魔兽争霸III在现代电脑上焕发新生的全能助手 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为魔兽争霸III在宽…...

HsMod:炉石传说功能增强插件的全方位优化方案
HsMod:炉石传说功能增强插件的全方位优化方案 【免费下载链接】HsMod Hearthstone Modify Based on BepInEx 项目地址: https://gitcode.com/GitHub_Trending/hs/HsMod HsMod是一款基于BepInEx框架开发的炉石传说功能增强插件,通过55项实用功能为…...

突破平台限制:WorkshopDL重构Steam创意工坊资源获取体验
突破平台限制:WorkshopDL重构Steam创意工坊资源获取体验 【免费下载链接】WorkshopDL WorkshopDL - The Best Steam Workshop Downloader 项目地址: https://gitcode.com/gh_mirrors/wo/WorkshopDL WorkshopDL作为一款仅10MB大小的开源工具,通过智…...

HumanoidVerse深度解析:如何通过多模拟器框架实现人形机器人sim2real高效训练
1. HumanoidVerse框架概览:多模拟器支持与模块化设计 HumanoidVerse是卡耐基梅隆大学(CMU)推出的开源框架,专门针对人形机器人的sim2real训练需求。这个框架最大的特点在于其多模拟器支持架构,能够无缝对接IsaacGym、IsaacSim和Genesis三种主…...

Linux 中的硬链接和软连接是什么,二者有什么区别?
在 Linux 文件系统中,**硬链接(Hard Link)和软链接(Soft Link,又称符号链接 Symbolic Link)**是两种不同的文件引用方式。它们都允许用户通过不同的路径访问同一个文件内容,但它们的实现机制、限…...

Stable Diffusion 2.0超分实战:4倍放大图片还能保持清晰度的秘密
Stable Diffusion 2.0超分实战:4倍放大图片还能保持清晰度的秘密 在数字图像处理领域,超分辨率技术一直是设计师和开发者关注的焦点。传统放大方法往往导致图像模糊、细节丢失,而基于深度学习的超分方案正在改变这一局面。Stable Diffusion 2…...
)
告别台式机没麦克风的尴尬:用SonoBus+VB-Cable把手机秒变无线麦(保姆级配置)
台式机零成本无线麦克风方案:SonoBus与VB-Cable实战指南 你是否遇到过这样的尴尬时刻——台式电脑突然需要语音沟通,却发现没有麦克风?无论是紧急会议、游戏开黑还是直播互动,这种硬件缺失带来的困扰可能让你措手不及。本文将介绍…...

**发散创新:基于微应用架构的轻量级权限控制实战设计**在现代前端开
发散创新:基于微应用架构的轻量级权限控制实战设计 在现代前端开发中,**微应用(Micro Frontend)*8 已成为构建复杂单页应用(SPA)的标准方案之一。它允许团队独立开发、部署和维护各自的功能模块,…...

Graphormer开源模型部署教程:3.7GB小模型+RTX4090一键启动分子建模服务
Graphormer开源模型部署教程:3.7GB小模型RTX4090一键启动分子建模服务 1. 项目介绍 Graphormer是一种基于纯Transformer架构的图神经网络模型,专门为分子图(原子-键结构)的全局结构建模与属性预测而设计。这个3.7GB的小模型在OG…...

BVH构建优化:四种分割算法在光线追踪中的性能对比
1. BVH分割算法基础概念 当你在玩3D游戏时,有没有想过为什么场景中的物体能够如此快速地渲染出来?这背后就离不开BVH(边界体积层次结构)技术的支持。简单来说,BVH就像是一个高效的"物体分类系统",…...