【C++修炼之路】18.map和set
每一个不曾起舞的日子都是对生命的辜负

map和set
- map和set
- 一.关联式容器
- 二.set
- 2.1 set的介绍
- 2.2 set的使用
- 1.set的模板参数列表
- 2.set的构造
- 3.set的迭代器
- 4.set修改操作
- 5.bound函数
- 三.multiset
- 四.map
- 3.1 map的介绍
- 3.2 map的使用
- 1.map的模板参数说明
- 2.pair的介绍
- 3.map的[]重载
- 五.multimap
map和set
本节目标:
-
- 关联式容器
-
- 键值对
-
- 树形结构的关联式容器
一.关联式容器
在初阶阶段,我们已经接触过STL中的部分容器,比如:vector、list、deque、forward_list(C++11)等,这些容器统称为序列式容器,因为其底层为线性序列的数据结构,里面存储的是元素本身。那什么是关联式容器?它与序列式容器有什么区别?
关联式容器也是用来存储数据的,与序列式容器不同的是,其里面存储的是<key, value>结构的键值对,在数据检索时比序列式容器效率更高。
键值对:
用来表示具有一一对应关系的一种结构,该结构中一般只包含两个成员变量key和value,key代表键值,value表示与key对应的信息。比如:现在要建立一个英汉互译的字典,那该字典中必然有英文单词与其对应的中文含义,而且,英文单词与其中文含义是一一对应的关系,即通过该应该单词,在词典中就可以找到与其对应的中文含义。
树形结构的关联式容器:
根据应用场景的不桶,STL总共实现了两种不同结构的管理式容器:树型结构与哈希结构。**树型结构的关联式容器主要有四种:map、set、multimap、multiset。**这四种容器的共同点是:使用平衡搜索树(即红黑树)作为其底层结果,容器中的元素是一个有序的序列。下面一依次介绍每一个容器。
二.set
2.1 set的介绍
set的底层为二叉搜索树,也就是上一节中所实现的,不过在此之上,set作为容器来说,封装了和以前的vector、list、deque相关的迭代器、运算符重载等,方便我们去进行一系列的操作。
仍然是需要看文档:
set - C++ Reference (cplusplus.com)
可以发现,这与之前我们所学的容器的方法几乎差不多。只不过有了些许特征:
- set是按照一定次序存储元素的容器
- 在set中,元素的value也标识它(value就是key,类型为T),并且每个value必须是唯一的。set中的元素不能在容器中修改(元素总是const),但是可以从容器中插入或删除它们。
- 在内部,set中的元素总是按照其内部比较对象(类型比较)所指示的特定严格弱排序准则进行排序。
- set容器通过key访问单个元素的速度通常比unordered_set容器慢,但它们允许根据顺序对子集进行直接迭代。
- set在底层是用二叉搜索树(红黑树)实现的。
- set没有[]重载。
注意:
- 与map/multimap不同,map/multimap中存储的是真正的键值对<key, value>,set中只放value,但在底层实际存放的是由<value, value>构成的键值对。
- set中插入元素时,只需要插入value即可,不需要构造键值对。
- et中的元素不可以重复(二叉搜索树中重复则不会插入,并且返回false因此可以使用set进行去重)。
- 使用set的迭代器遍历set中的元素,可以得到有序序列
- set中的元素默认按照小于来比较
- set中查找某个元素,时间复杂度为:log2nlog_2 nlog2n (实际上是二叉搜索树的高度次)
- set中的元素不允许修改(为什么?)
- set中的底层使用二叉搜索树(红黑树)来实现。
2.2 set的使用
头文件当然是:#include<set>
1.set的模板参数列表

T: set中存放元素的类型,实际在底层存储<value, value>的键值对。
**Compare:**set中元素默认按照小于来比较
**Alloc:**set中元素空间的管理方式,使用STL提供的空间配置器管理
对于Compare来说,利用仿函数默认小于,就是默认按照升序去处理的,即上一讲中的二叉搜索树中序从小到大。
2.set的构造
| 函数声明 | 功能介绍 |
|---|---|
| set (const Compare& comp = Compare(), const Allocator&= Allocator() ); | 构造空的set |
| set (InputIterator first, InputIterator last, const Compare& comp = Compare(), const Allocator& =Allocator() ); | 用[first, last)区间中的元素构造set |
| set ( const set<Key,Compare,Allocator>& x); | set的拷贝构造 |
3.set的迭代器
对于set的迭代器,和之前的vector、list相同,有正向迭代器、反向迭代器、const迭代器。名称都是一样的。
容量的函数也是如此,就不一一展示了,看上面文档就行,如果知道vector、list的容量函数,也可以不看。
4.set修改操作
| pair<iterator,bool> insert (const value_type& x ) | 在set中插入元素x,实际插入的是<x, x>构成的键值对,如果插入成功,返回<该元素在set中的位置,true>,如果插入失败,说明x在set中已经存在,返回<x在set中的位置,false> |
|---|---|
| void erase ( iterator position ) | 删除set中position位置上的元素 |
| size_type erase ( constkey_type& x ) | 删除set中值为x的元素,返回删除的元素的个数 |
| void erase ( iterator first,iterator last ) | 删除set中[first, last)区间中的元素 |
| void swap (set<Key,Compare,Allocator>&st ); | 交换set中的元素,实际上只需交换搜索树根节点的指针 |
| iterator find ( constkey_type& x ) const | 返回set中值为x的元素的位置 |
| size_type count ( constkey_type& x ) const | 返回set中值为x的元素的个数 |
对于第一个pair,实际上就是KV模型,下面会展示。erase的重载也没什么,交换函数值得一提的是由于底层是二叉搜索树,因此swap只需交换根节点的指针。对于find,count, 由于set是去重的元素,因此上面提到的返回位置以及元素个数并不需要在意,因为每一个元素都是唯一的。而也有不唯一的容器:multiset,multiset只排序不去重,下面讲这个的时候会知道返回位置是中序遍历的第一个。
演示1:
#include<iostream>
#include<set>//底层是二叉搜索树:自动进行排序去重
using namespace std;void test_set1()
{set<int> s;//排序+去重s.insert(3);s.insert(1);s.insert(4);s.insert(7);s.insert(2);s.insert(1);set<int>::iterator it = s.begin();//auto it = s.begin();while (it != s.end()){cout << *it << " ";++it;}cout << endl;for (auto e : s)//范围for底层就是迭代器{cout << e << " ";}cout << endl;auto pos = s.find(3); //这个更快,因为借用搜索树的特性//auto pos = find(s.begin(), s.end(), 3);//底层实现不一样,这个是暴力查找if (pos != s.end()){s.erase(pos);}cout << s.erase(1) << endl;cout << s.erase(3) << endl;s.erase(1);s.erase(1);for (auto e : s)//范围for底层就是迭代器{cout << e << " ";}cout << endl;
}
int main()
{test_set1();return 0;
}

演示2:
5.bound函数
在文档中发现,有两个函数:lower_bound,upper_bound,这两个实际上也是迭代器类型,传入的只有一个参数,同样是左闭右开,传值之后可以标记对应的位置:
int main()
{set<int> myset;set<int>::iterator itlow, itup;for (int i = 1; i < 10; i++){myset.insert(i * 10);//10 20 30 40 50 60 70 80 90 }itlow = myset.lower_bound(35);itup = myset.upper_bound(70);myset.erase(itlow, itup);for (set<int>::iterator it = myset.begin(); it != myset.end(); it++){cout << " " << *it;}cout << endl;return 0;
}

可见,对于erase也有迭代器为参数的重载函数,此外,通过bound类型的迭代器可以保存位置。即便没有该元素,同样可以标记,因为元素是有序。
如果把70变成75,itup同样会得到80的位置,所以upper_bound返回的是大于该位置的边界,可以对标end(),而lower_bound对标begin,返回的是大于等于的边界。这就非常方便获得一个左闭右开的范围。但这个东西实际上用的不多。
三.multiset
与set不同的是,multiset虽然会排序,但并不会进行去重,因此是由重复值的存在的。底层仍然是二叉搜索树。
#include<iostream>
#include<set>
#include<string>
using namespace std;
void test_set2()
{multiset<int> s;//单纯排序,没有去重s.insert(3);s.insert(1);s.insert(4);s.insert(7);s.insert(2);s.insert(1);s.insert(1);s.insert(1);s.insert(3);cout << s.count(1) << endl;//1的数量for (auto e : s)//范围for底层就是迭代器{cout << e << " ";}cout << endl;
}
int main()
{test_set2();return 0;
}
需要注意的是查找的返回值是中序遍历的第一个。
四.map
3.1 map的介绍
map的底层当然也是二叉搜索树,但就好比set是K模型一样,map就是上篇二叉搜索树提到的KV模型,即一一对应的方式。
文档说明:
www.cplusplus.com
- . map是关联容器,它按照特定的次序(按照key来比较)存储由键值key和值value组合而成的元素。
- 在map中,键值key通常用于排序和惟一地标识元素,而值value中存储与此键值key关联的内容。键值key和值value的类型可能不同,并且在map的内部,key与value通过成员类型value_type绑定在一起,为其取别名称为pair:
typedef pair<const key, T value_type>; - 在内部,map中的元素总是按照键值key进行比较排序的
- map中通过键值访问单个元素的速度通常比unordered_map容器慢,但map允许根据顺序对元素进行直接迭代(即对map中的元素进行迭代时,可以得到一个有序的序列)。
- map支持下标访问符,即在[]中放入key,就可以找到与key对应的value。
- map通常被实现为二叉搜索树(更准确的说:平衡二叉搜索树(红黑树))。
3.2 map的使用
头文件当然是:#include<map>
1.map的模板参数说明
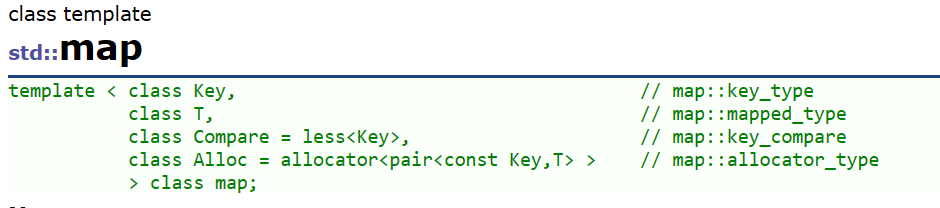
key: 键值对中key的类型
T: 键值对中value的类型
Compare: 比较器的类型,map中的元素是按照key来比较的,缺省情况下按照小于来比较,一般情况下(内置类型元素)该参数不需要传递,如果无法比较时(自定义类型),需要用户自己显式传递比较规则(一般情况下按照函数指针或者仿函数来传递)
**Alloc:**通过空间配置器来申请底层空间,不需要用户传递,除非用户不想使用标准库提供的空间配置器
而对于map的构造,迭代器的一些,与之前的容器使用方式相同,就不展示了,需要可以自行查看文档。
2.pair的介绍
我们需要知道pair:

first就是Key,second是Value。就是KV模型的结构。在搜索树定义的时候,我们是直接定义了两个变量类型:K,V。那为什么需要pair这个东西将两个值放在一起呢?实际上是为了map能够更方便的操作,举个例子,对于map,如果是迭代器访问,返回的时候不可能返回两个参数,这时候以pair为参数的函数就派上用场了,直接返回pair类型就好了。
、
但pair类型也不支持流插入,所以就需要一个一个的访问
int main()
{map<string, string> dict;dict.insert(pair<string, string>("排序", "sort"));//匿名对象dict.insert(pair<string, string>("左边", "left"));dict.insert(pair<string, string>("右边", "right"));dict.insert(make_pair("字符串", "string"));//make_pair是一个函数模板//map<string, string>::iterator it = dict.begin();auto it = dict.begin();//这样方便while (it != dict.end()){//cout << *it << endl;//pair不支持流插入,因此这样不行//cout << (*it).first << ":" << (*it).second << endl; //这样可以cout << it->first << ":" << it->second << endl;//返回的是数据的地址/指针++it;}cout << endl;for (const auto& kv : dict)//注意加引用,不加就是拷贝构造,代价大{cout << kv.first << ":" << kv.second << endl;}return 0;
}

3.map的[]重载
如果想通过map统计水果出现的次数,可以这样:
int main()
{//map统计水果操作的次数string arr[] = { "苹果", "西瓜", "香蕉", "草莓", "西瓜","苹果", "苹果","西瓜","苹果", "香蕉", "苹果", "香蕉" };map<string, int> countMap;for (auto& e : arr){auto it = countMap.find(e);if (it == countMap.end())//没有就插入{countMap.insert(make_pair(e, 1));}else{it->second++;}}for (const auto& kv : countMap)//注意加引用,不给就是拷贝构造,代价大{cout << kv.first << ":" << kv.second << endl;}return 0;
}

但这样看起来麻烦很多,实际上可以通过这种方式:
int main()
{//map统计水果操作的次数string arr[] = { "苹果", "西瓜", "香蕉", "草莓", "西瓜","苹果", "苹果","西瓜","苹果", "香蕉", "苹果", "香蕉" };map<string, int> countMap;for (auto& e : arr){countMap[e]++;}for (const auto& kv : countMap)//注意加引用,不加就是拷贝构造,代价大{cout << kv.first << ":" << kv.second << endl;}return 0;
}

方括号支持的是随机访问,而对于这个括号来说,括号里的实际上是key,countMap[e]就是value。
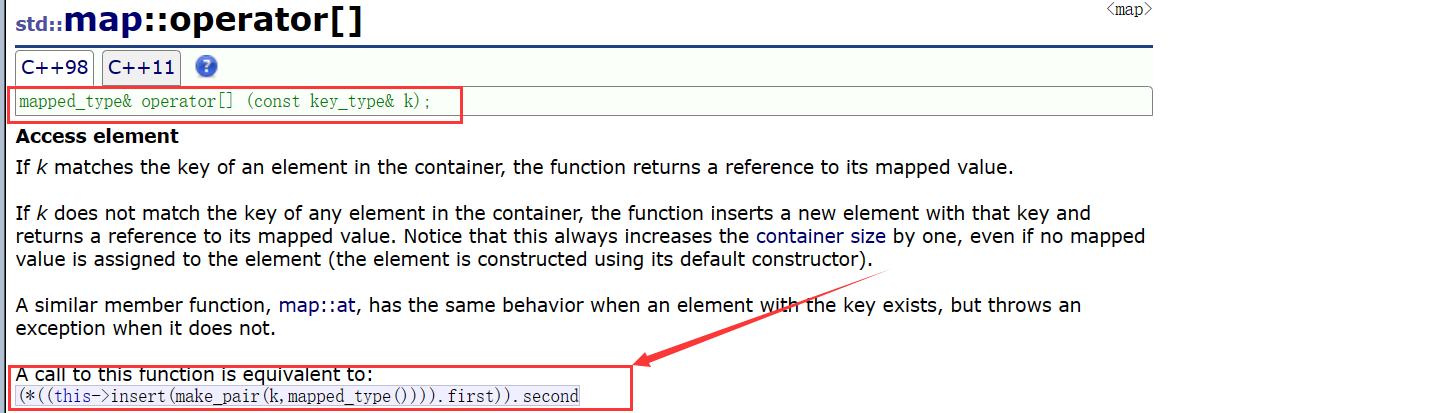
上面所标注的就是map[]重载的返回值,发现还有insert的操作,所以我们应该先知道insert的返回值:
发现insert返回类型为pair<iterator, bool>类型,看看文档是如何说明的:
因此,我们可以将最上面的map重载的返回值进行解释了,可以转化成这样了:
V& operator[](const K& k)
{pair<iterator, bool> ret = insert(make_pair(k, V()));return ret.first->second;
}
这样,我们就知道,operator返回的就是map<string, int>的第二个参数,并且是引用返回,所以map的映射关系就是这样的。
可以看出,C++map的[]有很多功能:
- 插入
- 修改
- 查找
因此,了解底层之后我们也可以直接这样写:
int main()
{map<string, string> dict;dict.insert(pair<string, string>("排序", "sort"));//匿名对象dict.insert(pair<string, string>("左边", "left"));dict.insert(pair<string, string>("右边", "right"));dict.insert(make_pair("字符串", "string"));//make_pair是一个函数模板dict["迭代器"] = "iterator"; // 插入+修改dict["insert"];//单纯的插入,默认构造的va为""//dict.insert(pair<string, string>("左边", "XXX"));//这样会插入失败,因为已经有了"左边"dict["insert"] = "插入";//修改cout << dict["左边"] << endl;// 查找//key在就是查找,不在就是插入return 0;
}


因此,用[]代替insert很方便,而且对于已有的key,如果想再插入相同的key,无论对应的value是否相同,都不能成功,因为pair<iterator, bool>对应的bool会返回false。如果想修改指定key的value,就用[]。
对于词典来说,由于一词多义,key和value也可能不是一一映射的关系,有可能是一个key对应多个value,这个时候,可以这样map<string, vector<string>>,除此之外,也可以利用multimap,下面将会提到。
再次说明:map中用pair保存值。
五.multimap
和multset一样,multimap与map相比也是不会进行去重,只是有序。
那继续看一下,用multimap完成上面说的”一词多义“:
#include<iostream>
#include<map>
#include<string>
using namespace std;
int main()
{multimap<string, string> dict;dict.insert(pair<string, string>("left", "左边"));dict.insert(pair<string, string>("left", "剩余"));dict.insert(pair<string, string>("string", "字符串"));dict.insert(pair<string, string>("left", "xxx"));for (const auto& kv : dict){cout << kv.first << ":" << kv.second << endl;}return 0;
}

multimap是不支持[]重载的,文档里面也没有:
multimap - C++ Reference (cplusplus.com)
但multimap同样可以统计次数,因为下面的方式是先find,再加入或者值++。
#include<iostream>
#include<map>
#include<string>
using namespace std;
int main()
{string arr[] = { "苹果", "西瓜", "香蕉", "草莓", "西瓜","苹果", "苹果","西瓜","苹果", "香蕉", "苹果", "香蕉" };multimap<string, int> countMap;for (auto& e : arr){auto it = countMap.find(e);if (it == countMap.end())//没有就插入{countMap.insert(make_pair(e, 1));}else{it->second++;}}for (const auto& kv : countMap)//注意加引用,不给就是拷贝构造,代价大{cout << kv.first << ":" << kv.second << endl;}return 0;
}

这样也可以统计次数。
相关文章:
【C++修炼之路】18.map和set
每一个不曾起舞的日子都是对生命的辜负 map和setmap和set一.关联式容器二.set2.1 set的介绍2.2 set的使用1.set的模板参数列表2.set的构造3.set的迭代器4.set修改操作5.bound函数三.multiset四.map3.1 map的介绍3.2 map的使用1.map的模板参数说明2.pair的介绍3.map的[]重载五.m…...

ChatGPT原理与技术演进剖析
—— 要抓住一个风口,你得先了解这个风口的内核究竟是什么。本文作者:黄佳 (著有《零基础学机器学习》《数据分析咖哥十话》) ChatGPT相关文章已经铺天盖地,剖析(现阶段或者只能说揣测)其底层原…...
Retrofit+Hilt后端请求小项目1--项目介绍
简介 本项目根据 youtube 对应教程实现而来 将会对对应代码以及依赖(如 Hilt、retrofit、coil)进行详细的分析与解读,同时缕清项目结构安排 如文章有叙述不清晰的,请直接查看原教程:https://www.youtube.com/watch?…...
实际项目角度优化App性能
前言:前年替公司实现了一个在线检疫App,接下来一年时不时收到该App的需求功能迭代,部分线下问题跟进。随着新冠疫情防控政策放开,该项目也是下线了。 从技术角度来看,有自己的独特技术处理特点。下面我想记录一下该App…...
Structure|Alphafold2在肽结构预测任务上的基准实验
题目:Benchmarking AlphaFold2 on peptide structureprediction 文献来源:2023, Structure 31, 1–9 代码:基准实验,比较了比较多的模型 1.背景介绍 由2-50个氨基酸构成的聚合物可以称为肽。但是关于肽和蛋白质之间的差异还是…...

Simple XML
简介 官网:https://simple.sourceforge.net/home.php Github:https://github.com/ngallagher/simplexml Simple 是用于 Java 的高性能 XML 序列化和配置框架。它的目标是提供一个 XML 框架,使 XML 配置和通信系统的快速开发成为可能。该框架…...

在代码质量和工作效率的矛盾间如何取舍?
这个问题的答案是,在很短的一段时期,编写高质量代码似乎会拖慢我们的进度。与按照头脑中首先闪现的念头编写代码相比,高质量的代码需要更多的思考和努力。但如果我们编写的不仅仅是运行一次就抛之脑后的小程序,而是更有实质性的软…...

rabbitMq安装(小短文)--未完成
rabbitMq是在activeMq的基础上创造的,有前者的功能,比前者强,属于后来居上。系统环境:windows10首先下载相关软件Erlang,因为他是这个语言写的。https://www.erlang.org/downloads然后安装,并且弄到环境变量里验证是否…...

Python调用MMDetection实现AI抠图去背景
这篇文章的内容是以 《使用MMDetection进行目标检测、实例和全景分割》 为基础,需要安装好 MMDetection 的运行环境,同时完成目标检测、实例分割和全景分割的功能实践,之后再看下面的内容。 想要实现AI抠图去背景的需求,我们需要…...
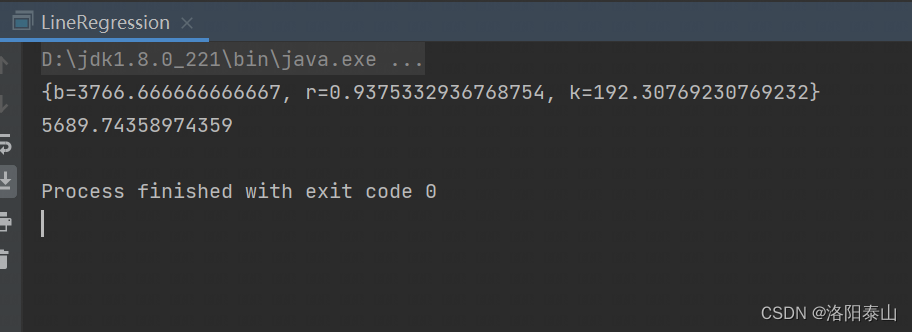
Java代码使用最小二乘法实现线性回归预测
最小二乘法简介最小二乘法是一种在误差估计、不确定度、系统辨识及预测、预报等数据处理诸多学科领域得到广泛应用的数学工具。它通过最小化误差(真实目标对象与拟合目标对象的差)的平方和寻找数据的最佳函数匹配。利用最小二乘法可以简便地求得未知的数…...

linux-rockchip-音频相关
一、查看当前配置声卡状态 cat /proc/asound/cards二、查看当前声卡工作状态 声卡分两种通道,一种是Capture、一种是Playback。Capture是输入通道,Playback是输出通道。例如pcm0p属于声卡输出通道,pcm0c属于声卡输入通道。 ls /proc/asoun…...
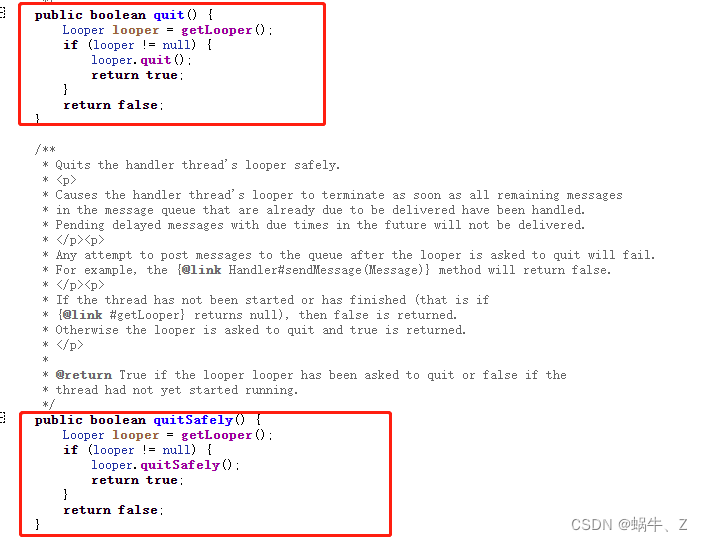
Android Handler的内存抖动以及子线程创建Handler
一、介绍 Handler,作为一个在主线程存活的消息分发工具,在App开发过程使用频率很高,也是面试问的比较多的。 面试常见的比如:子线程如何创建?Handler的机制是什么?内存抖动等,接下来我们会针对H…...

机器学习算法原理之k近邻 / KNN
文章目录k近邻 / KNN主要思想模型要素距离度量分类决策规则kd树主要思想kd树的构建kd树的搜索总结归纳k近邻 / KNN 主要思想 假定给定一个训练数据集,其中实例标签已定,当输入新的实例时,可以根据其最近的 kkk 个训练实例的标签,…...
【期末复习】例题说明Prim算法与Kruskal算法
点睛Prim与Kruskal算法是用来求图的最小生成树的算法。最小生成树有n个顶点,n-1条边,不能有回路。Prim算法Prim算法的特点是从个体到整体,随机选定一个顶点为起始点出发,然后找它的权值最小的边对应的另一个顶点,这两个…...
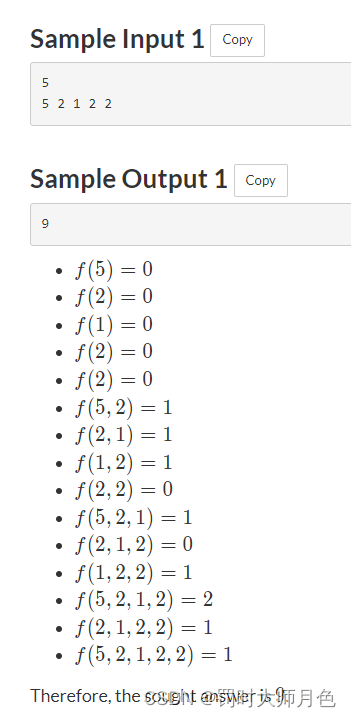
AtCoder Beginner Contest 290 A-E F只会n^2
ABC比较简单就不再复述 D - Marking 简要题意 :给你一个长度为nnn的数组,下标为0到n−10 到 n-10到n−1,最初指针位于0,重复执行n-1次操作,每次操作的定义为将当前指针加上ddd,如果该位置为空(未填数),否则我们向右找到第一个为空…...
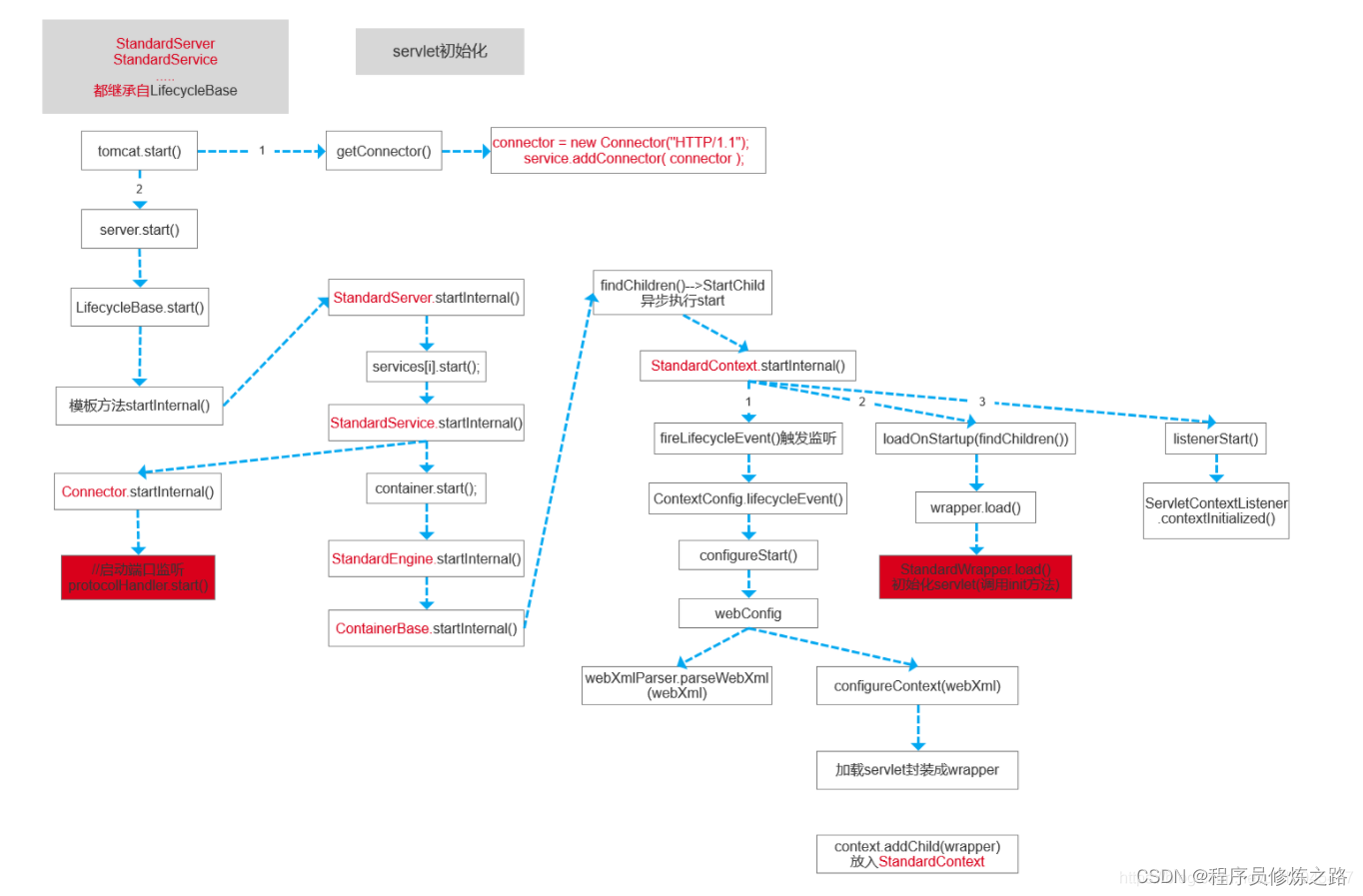
springMvc源码解析
入口:找到springboot的自动配置,将DispatcherServlet和DispatcherServletRegistrationBean注入spring容器(DispatcherServletRegistrationBean间接实现了ServletContextInitializer接口,最终ServletContextInitializer的onStartup…...
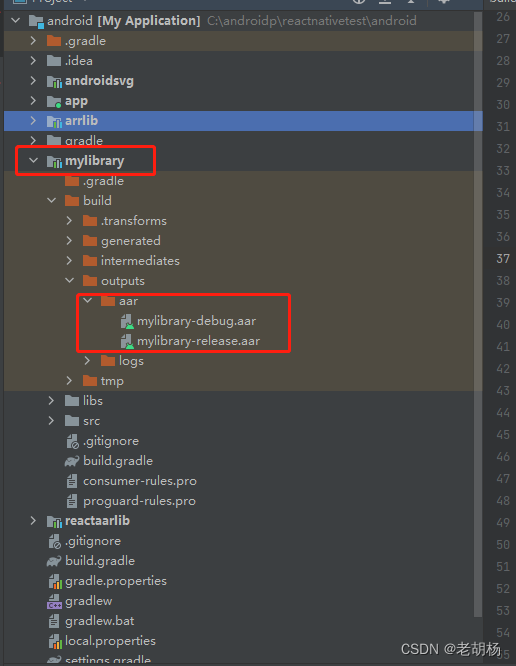
采用aar方式将react-native集成到已有安卓APP
关于react-native和android的开发环境搭建、环境变量配置等可以查看官方文档。 官方文档地址 文章中涉及的node、react等版本: node:v16.18.1 react:^18.1.0 react-native:^0.70.6 gradle:gradle-7.2开发工具:VSCode和android studio 关于react-native和…...
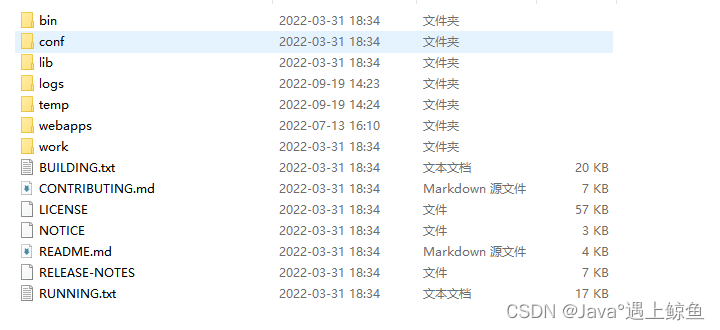
Tomcat目录介绍,结构目录有哪些?哪些常用?
bin 启动,关闭和其他脚本。这些 .sh文件(对于Unix系统)是这些.bat文件的功能副本(对于Windows系统)。由于Win32命令行缺少某些功能,因此此处包含一些其他文件。 比如说:windows下启动tomcat用的…...
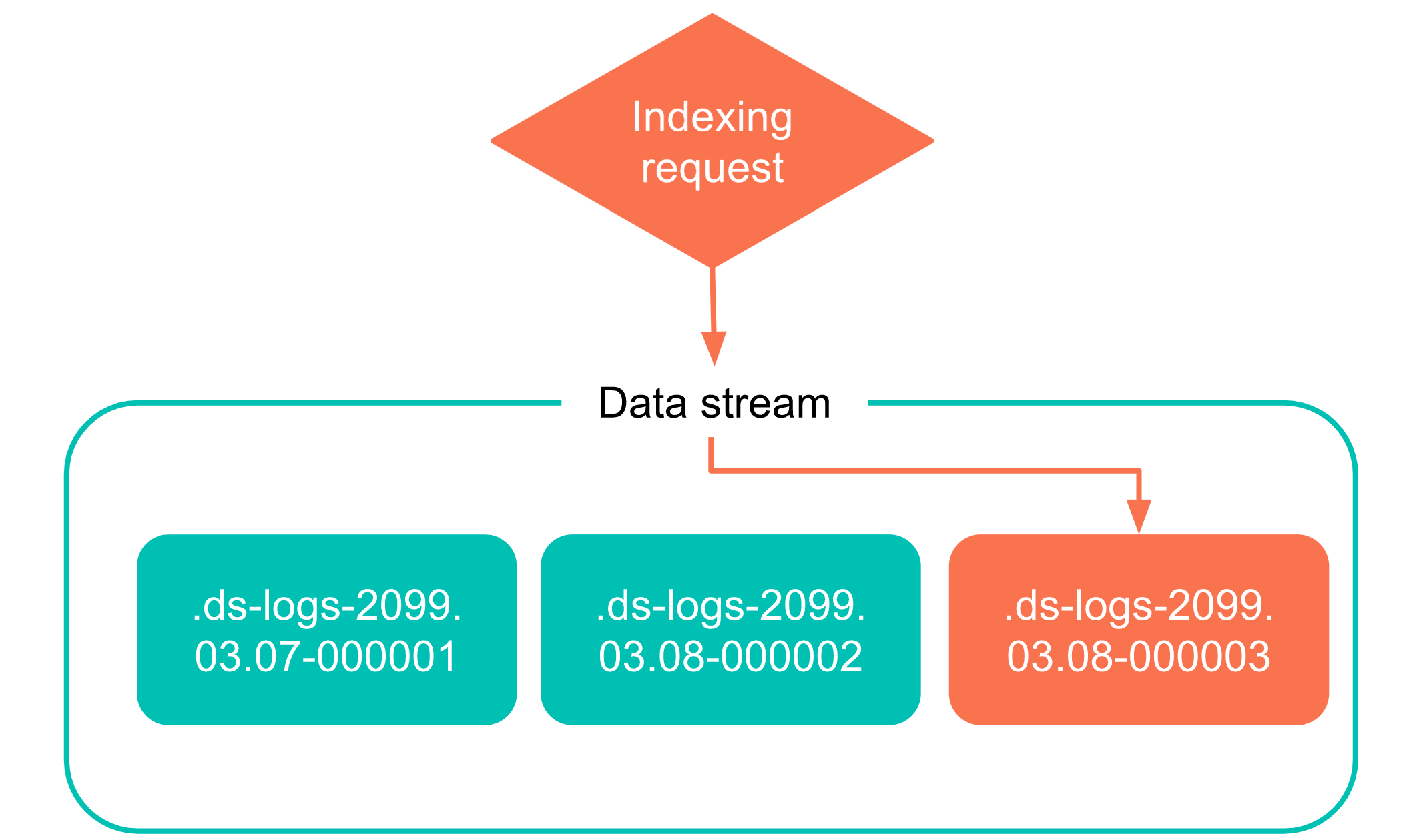
Elasticsearch也能“分库分表“,rollover实现自动分索引
一、自动创建新索引的方法 MySQL的分库分表大家是非常熟悉的,在Elasticserach中有存在类似的场景需求。为了不让单个索引太过于庞大,从而引发性能变差等问题,我们常常有根据索引大小、时间等创建新索引的需求,解决方案一般有两个…...

6 大经典机器学习数据集,3w+ 用户票选得出,建议收藏
内容一览:本期汇总了超神经下载排名众多的 6 个数据集,涵盖图像识别、机器翻译、遥感影像等领域。这些数据集质量高、数据量大,经历人气认证值得收藏码住。 关键词:数据集 机器翻译 机器视觉 数据集是机器学习模型训练的基础&…...

小白友好型OCR文字识别镜像:无需深度学习基础,开箱即用体验
小白友好型OCR文字识别镜像:无需深度学习基础,开箱即用体验 1. 为什么选择这款OCR镜像? 在日常工作和生活中,我们经常需要从图片中提取文字信息 - 可能是扫描的文档、拍摄的发票、或是路牌照片。传统OCR软件要么功能有限&#x…...

HunyuanVideo-Foley在智能家居场景的落地:让智能设备拥有更自然的语音反馈
HunyuanVideo-Foley在智能家居场景的落地:让智能设备拥有更自然的语音反馈 1. 智能家居音效的现状与痛点 清晨6点半,刺耳的"滴滴滴"闹铃声把你从睡梦中惊醒;晚上关灯时,突然的"咔哒"断电声让人心头一紧——…...

海康H5player错误码解析与实战排错指南
1. 海康H5player错误码全景解析 第一次接触海康H5player的开发同学,看到那一串0x开头的错误码时,往往会一头雾水。这些看似随机的十六进制数字背后,其实隐藏着完整的错误分类体系。根据我多年对接海康设备的经验,这些错误码可以归…...

【NOIP】1999真题解析 luogu-P1014 Cantor 表 | GESP三、四级以上可练习
NOIP 1999 普及组真题,主要考察简单的二维矩阵模拟与通过寻找数学规律进行时间复杂度优化。可以用模拟法暴力求解,也能通过总结对角线的排列规律实现高效求解。GESP三、四级以上可练习。题目难度⭐⭐☆☆☆,洛谷难度等级普及−。 luogu-P101…...

VibeVoice语音合成系统效果展示:专业配音级语音频谱图分析
VibeVoice语音合成系统效果展示:专业配音级语音频谱图分析 1. 语音合成技术的新突破 你有没有想过,现在的AI语音合成已经能做到多逼真?不再是那种机械的、冰冷的机器人声音,而是真正像专业配音演员录制的高质量语音。VibeVoice语…...

嵌入式Linux网络状态检测方案与优化实践
1. 嵌入式设备网络状态检测实战指南 在嵌入式Linux开发中,网络连接状态的实时监测是个常见但容易被忽视的需求。想象一下,你正在开发一个智能家居网关,突然Wi-Fi断了,但设备还在傻乎乎地发送数据;或者工业现场的设备&a…...

PostgreSQL 选择数据库
PostgreSQL 选择数据库 引言 在当今数据驱动的世界中,选择合适的数据库系统对于企业来说至关重要。PostgreSQL,作为一款功能强大、开源的关系型数据库管理系统(RDBMS),因其卓越的性能、灵活性和可扩展性而备受青睐。本文将深入探讨PostgreSQL的特点,分析为何它是众多数…...

告别命令行恐惧:用LLaMA-Factory的Gradio WebUI,像玩积木一样微调你的大模型
告别命令行恐惧:用LLaMA-Factory的Gradio WebUI,像玩积木一样微调你的大模型 当大模型技术从实验室走向产业应用时,一个残酷的现实摆在眼前:90%的潜在使用者被命令行界面挡在门外。那些闪烁着光标的神秘终端窗口,就像一…...

解放加密音乐:ncmdump的格式转换革新
解放加密音乐:ncmdump的格式转换革新 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 一、价值定位:破解NCM格式限制的技术方案 ncmdump作为一款开源工具,专为破解网易云音乐NCM加密格式而设计&am…...

【数字信号检测】基于迫零算法大规模MIMO低复杂度信号检测附Matlab代码
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、建模仿真、程序设计、完整代码获取、论文复现及科研仿真。👇 关注我领取海量matlab电子书和数学建模资料🍊个人信条:格物致知,完整Matl…...