jdk 04 stream的collect方法
01.收集(collect)
collect,收集,可以说是内容最繁多、功能最丰富的部分了。
从字面上去理解,就是把一个流收集起来,最终可以是收集成一个值也可以收集成一个新的集合。
collect主要依赖java.util.stream.Collectors类内置的静态方法。
这个是stream中的collect方法:
<R, A> R collect(Collector<? super T, A, R> collector);

02.归集(toList/toSet/toMap)
因为流不存储数据,那么在流中的数据完成处理后,需要将流中的数据重新归集到新的集合里。 toList、toSet和toMap比较常用,另外还有toCollection、toConcurrentMap等复杂一些的用法。
List<Integer> list = Arrays.asList(1, 6, 3, 4, 6, 7, 9, 6, 20);List<Integer> listNew = list.stream().filter(x -> x % 2 == 0).collect(Collectors.toList());System.out.println("产生的新集合是:" + listNew);Set<Integer> set = list.stream().filter(x -> x % 2 == 0).collect(Collectors.toSet());System.out.println("产生的不重复的新集合是:" + set);List<Person> personList = new ArrayList<>();personList.add(new Person("Tom", 8900, 22, "male", "New Yark"));personList.add(new Person("Jack", 7000, 29, "male", "Washington"));personList.add(new Person("Lily", 7800, 24, "female", "Washington"));personList.add(new Person("Anni", 8200, 28, "female", "New Yark"));personList.add(new Person("Owen", 9500, 26, "male", "New Yark"));personList.add(new Person("Alisa", 7900, 27, "female", "New Yark"));Map<?, Person> personMap =personList.stream().filter(p -> p.getSalary() > 8000).collect(Collectors.toMap(Person::getName,p -> p));System.out.println("产生的新的map集合是:" + personMap);3.统计(count/averaging)
Collectors提供了一系列用于数据统计的静态方法:
计数:count
平均值:averagingInt、averagingLong、averagingDouble
最值:maxBy、minBy
求和:summingInt、summingLong、summingDouble
统计以上所有:summarizingInt、summarizingLong、summarizingDouble /*** 案例:统计员工人数、平均工资、工资总额、最高工资。*/// 求总数Long count = personList.stream().collect(Collectors.counting());System.out.println("员工总数:" + count);// 求平均工资Double avgSalary = personList.stream().collect(Collectors.averagingDouble(Person::getSalary));System.out.println("员工平均工资:" + avgSalary);// 求工资之和Integer sumSalary = personList.stream().collect(Collectors.summingInt(Person::getSalary));System.out.println("员工工资总和:" + sumSalary);// 一次性统计所有信息DoubleSummaryStatistics collect = personList.stream().collect(Collectors.summarizingDouble(Person::getSalary));System.out.println("员工工资所有统计:" + collect);分组(partitioningBy/groupingBy)
分区:将stream按条件分为两个Map,比如员工按薪资是否高于8000分为两部分。
分组:将集合分为多个Map,比如员工按性别分组。有单级分组和多级分组。 /*** 案例:将员工按薪资是否高于8000分为两部分;将员工按性别和地区分组*/// 将员工按薪资是否高于8000分组Map<Boolean, List<Person>> part =personList.stream().collect(Collectors.partitioningBy(x -> x.getSalary() > 8000));// 将员工按性别分组Map<String, List<Person>> group = personList.stream().collect(Collectors.groupingBy(Person::getSex));// 将员工先按性别分组,再按地区分组Map<String, Map<String, List<Person>>> group2 =personList.stream().collect(Collectors.groupingBy(Person::getSex,Collectors.groupingBy(Person::getArea)));System.out.println("员工按薪资是否大于8000分组情况:" + part);System.out.println("员工按性别分组情况:" + group);System.out.println("员工按性别、地区:" + group2);接合(joining)
joining可以将stream中的元素用特定的连接符(没有的话,则直接连接)连接成一个字符串。
String names = personList.stream().map(p -> p.getName()).collect(Collectors.joining(","));System.out.println("所有员工的姓名:" + names);List<String> strs = Arrays.asList("A", "B", "C");String str = strs.stream().collect(Collectors.joining("-"));System.out.println("拼接后的字符串:" + str);
归约(reducing)
Collectors类提供的reducing方法,相比于stream本身的reduce方法,增加了对自定义归约的支持。
// 每个员工减去起征点后的薪资之和Integer sumsal = personList.stream().collect(Collectors.reducing(0, Person::getSalary, (x, y) -> x + y - 5000));System.out.println("员工扣税薪资总和:" + sumsal);// stream的reduceInteger sum = personList.stream().map(Person::getSalary).reduce(0, (x, y) -> x + y - 5000);System.out.println("----员工扣税薪资总和:" + sum);
排序(sorted)
sorted,中间操作。有两种排序:
sorted():自然排序,流中元素需实现Comparable接口sorted(Comparator com):Comparator排序器自定义排序
/*** 案例:将员工按工资由高到低(工资一样则按年龄由大到小)排序*/
// 按工资升序排序(自然排序)
List<String> nameList =personList.stream().sorted(Comparator.comparing(Person::getSalary)).map(Person::getName).collect(Collectors.toList());
System.out.println("按工资升序排序(自然排序):" + nameList);
// 按工资降序排序
List<String> nameList1 =personList.stream().sorted(Comparator.comparing(Person::getSalary).reversed()).map(Person::getName).collect(Collectors.toList());
System.out.println("按工资降序排序:" + nameList1);// 先按工资再按年龄升序排序
List<String> nameList2 =personList.stream().sorted(Comparator.comparing(Person::getSalary).thenComparing(Person::getSalary)).map(Person::getName).collect(Collectors.toList());
System.out.println("先按工资再按年龄升序排序:" + nameList2);// 先按工资再按年龄自定义排序(降序)
List<String> nameList3 = personList.stream().sorted((p1, p2) -> {if (p1.getSalary() == p2.getSalary()) {return p2.getAge() - p1.getAge();} else {return p2.getSalary() - p1.getSalary();}
}).map(Person::getName).collect(Collectors.toList());
System.out.println("先按工资再按年龄自定义排序(降序):" + nameList3);
提取/组合
流也可以进行合并(concat)、去重(distinct)、限制(limit)、跳过(skip)等操作。
String[] arr1 = {"a", "b", "c", "d"};
String[] arr2 = {"d", "e", "f", "g"};Stream<String> stream1 = Stream.of(arr1);
Stream<String> stream2 = Stream.of(arr2);// concat:合并两个流 distinct:去重
List<String> stringList = Stream.concat(stream1, stream2).distinct().collect(Collectors.toList());
System.out.println("流合并:" + stringList);
// limit:限制从流中获得前n个数据
List<Integer> integerList = Stream.iterate(1, x -> x + 2).limit(10).collect(Collectors.toList());
System.out.println("limit:" + integerList);
// skip:跳过前n个数据
List<Integer> integerList1 = Stream.iterate(1, x -> x + 2).skip(1).limit(5).collect(Collectors.toList());
System.out.println("skip:" + integerList1);
相关文章:
jdk 04 stream的collect方法
01.收集(collect) collect,收集,可以说是内容最繁多、功能最丰富的部分了。 从字面上去理解,就是把一个流收集起来,最终可以是收集成一个值也可以收集成一个新的集合。 collect主要依赖java.util.stream.Collectors类内置的静态方…...

介绍REST API
REST (Representational State Transfer) 是一种基于 web 架构的 API 设计风格, 允许客户端应用程序通过 HTTP 请求与服务器进行交互。RESTful API就是按照REST风格设计的API。 RESTful API 的设计原则包括:使用统一资源标识符 (URI) 标识资源ÿ…...
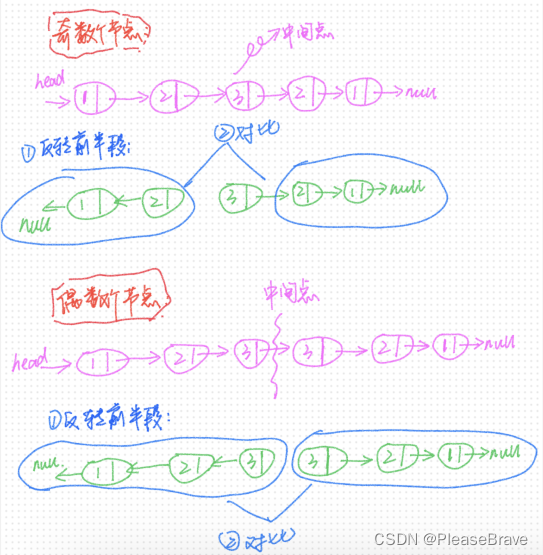
【leetcode 力扣刷题】反转链表+递归求解
反转链表递归求解 206. 反转链表解法①:取下一个节点在当前头节点前插入解法②:反转每个节点next的指向解法③:递归 92.反转链表Ⅱ反转left到right间节点的next指向 234.回文链表解法①:将链表元素存在数组中,在数组上…...

一文读懂Redis配置,史上真香配置
文章目录 基本配置项AOF持久化配置项RDB持久化配置项淘汰策略配置项主从复制配置项鸣谢 让那些总为redis连接异常的小白指引明灯,少走弯路。为那些不知道如何进行高级配置的大佬整一杯小酒。 基本配置项 bind:用于设置Redis绑定的IP地址。默认情况下&…...

maven打出jar中动态替换占位符
使用场景: maven打出的jar中pom.xml动态替换占位符 有些时候某些公共工具jar包被项目引用后发现公共jar的pom.xml中的version依然还是占位符,例如下面 <dependency><groupId>org.projectlombok</groupId><artifactId>lombok<…...

【Git游戏】通过游戏重新学习Git
在提交树上移动 HEAD HEAD:一个标志符号(通常情况下指向当前分支,间接指向当前最新的提交记录) 可以通过git checkout commitID从而指向提交记录 commitID 本身是一串哈希值(基于 SHA-1,共 40 位) 我们在…...

如何通过以太坊JSON-RPC方式获取ERC-20代币的信息?
目录 一、ERC-20介绍 二、ERC-20代币标准功能 1、可选功能 2、标准功能 三、获取代币信息...

线性代数的学习和整理4: 求逆矩阵的多种方法汇总
目录 原始问题:如何求逆矩阵? 1 EXCEL里,直接可以用黑盒表内公式 minverse() 数组公式求A- 2 非线性代数方法:解方程组的方法 3 增广矩阵的方法 4 用行列式的方法计算(未验证) 5 A-1/|A|*A* &…...

【C#学习笔记】匿名函数和lambda表达式
文章目录 匿名函数匿名函数的定义匿名函数作为参数传递匿名函数的缺点 lambda表达式什么是lambda表达式闭包 匿名函数 为什么我们要使用匿名函数?匿名函数存在的意义是为了简化一些函数的定义,特别是那些定义了之后只会被调用一次的函数,与其…...

百度Apollo:引领自动驾驶技术创新的先锋
文章目录 前言一、内容总结 前言 大家好,我是萝卜头不吃萝卜头,今天和大家分享一下我学习百度Apollo自动驾驶的心得。 在七月份的时候,我收到了Apollo开发者社区的邀请,进行学习Apollo自动驾驶汽车的2023星火培训训练,…...
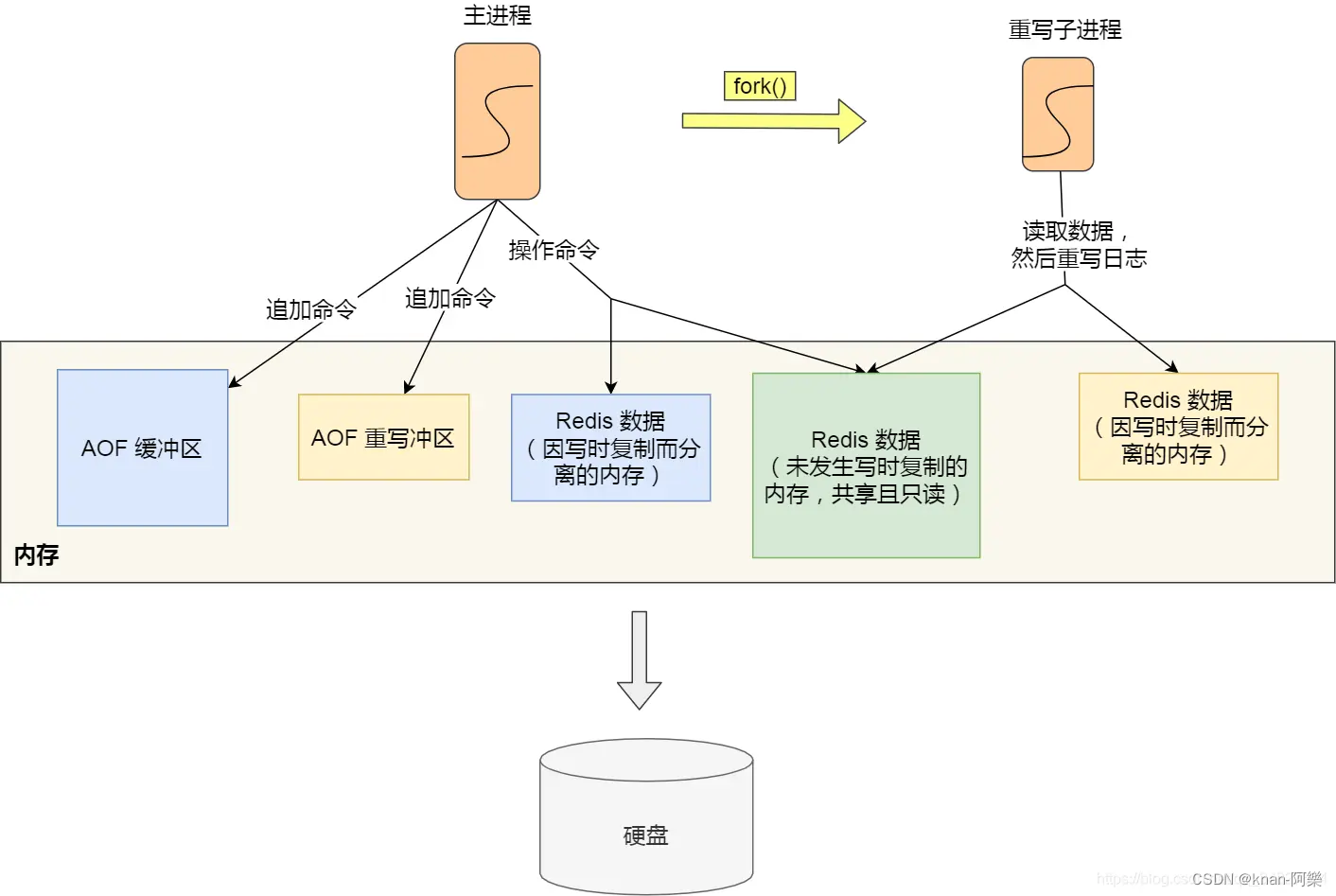
Redis 重写 AOF 日志期间,主进程可以正常处理命令吗?
重写 AOF 日志的过程是怎样的? Redis 的重写 AOF 过程是由后台子进程 bgrewriteaof 来完成的,这么做有以下两个好处。 子进程进行 AOF 重写期间,主进程可以继续处理命令请求,从而避免阻塞主进程子进程带有主进程的数据副本。这里…...
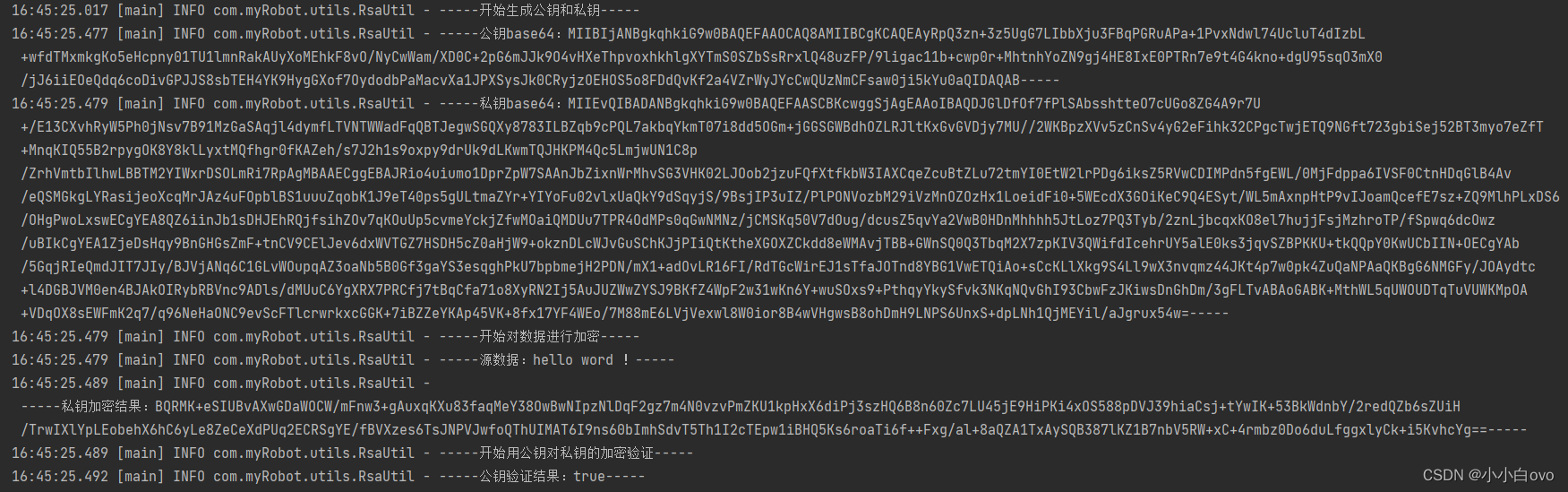
java实现生成RSA公私钥、SHA256withRSA加密以及验证工具类
前言: RSA属于非对称加密。所谓非对称加密,需要两个密钥:公钥 (publickey) 和私钥 (privatekey)。公钥和私钥是一对,如果用公钥对数据加密,那么只能用对应的私钥解密。如果用私钥对数据加密,只能用对应的公…...
lab7 thread
文章目录 Uthread: switching between threadstaskhints思路上下文的恢复和保存thread_createthread_schedule Using threads思路 Barrier Uthread: switching between threads 在这个练习中,你将为一个用户级别线程系统设计上下文切换机制,并实现它。 …...

接口自动化测试:mock server之Moco工具
什么是mock server mock:英文可以翻译为模仿的,mock server是我们用来解除依赖(耦合),假装实现的技术,比如说,前端需要使用某些api进行调试,但是服务端并没有开发完成这些api&#…...
用python从零开始做一个最简单的小说爬虫带GUI界面(2/3)
目录 前一章博客 前言 主函数的代码实现 逐行代码解析 获取链接 获取标题 获取网页源代码 获取各个文章的链接 函数的代码 导入库文件 获取文章的标题 获取文章的源代码 提取文章目录的各个文章的链接 总代码 下一章内容 前一章博客 用python从零开始做一个最简单…...

CEF 缓存处理:清理缓存、禁用缓存、忽略缓存
目录 一、CEF缓存处理 1、指定缓存路径 2、清理缓存 3、禁用缓存 1)、原理分析...
Android 系统桌面 App —— Launcher 开发(1)
Android 系统桌面 App —— Launcher 开发(1) Launcher简介 Launcher就是Android系统的桌面,俗称“HomeScreen”也就是我们开机后看到的第一个App。launcher其实就是一个app,它的作用是显示和管理手机上其他App。目前市场上有很…...
一个程序员的工作日记--每天就干两件事,一年后让别人刮目相看
文章目录 成功源于专注一、早上布局二、晚上复盘三、技术细节四、专注与成功五、专注的重要性六、忙碌和赚钱七、结论以嵌入式开发为例:一、早上布局二、晚上复盘三、技术细节四、专注与成功五、忙碌和赚钱六、结论在嵌入式软件开发中,我们需要按照以下步…...

Linux虚拟机安装(Ubuntu 20)
最近这段时间使用VMWare安装了一下Ubuntu版本的Linux虚拟机,在这里记录一下安装时参考的文章以及需要注意的细节 参考链接: VMware虚拟机下安装Ubuntu20.04(保姆级教程) 一、安装VMWare 下载链接:VMware Workstatio…...

1.6 服务器处理客户端请求
客户端进程向服务器进程发送一段文本(MySQL语句),服务器进程处理后再向客户端进程发送一段文本(处理结果)。 从图中我们可以看出,服务器程序处理来自客户端的查询请求大致需要经过三个部分,分别…...

Office RibbonX Editor:让Office界面定制变得像搭积木一样简单
Office RibbonX Editor:让Office界面定制变得像搭积木一样简单 【免费下载链接】office-ribbonx-editor An overhauled fork of the original Custom UI Editor for Microsoft Office, built with WPF 项目地址: https://gitcode.com/gh_mirrors/of/office-ribbon…...

Lindy自动化效率翻倍的秘密:从零搭建高可靠多步骤任务流的7步黄金流程
更多请点击: https://intelliparadigm.com 第一章:Lindy自动化效率翻倍的秘密:从零搭建高可靠多步骤任务流的7步黄金流程 Lindy自动化平台以“越久越可靠”为设计哲学,将经典软件工程原则与现代可观测性实践深度融合。其核心优势…...

使用TaotokenCLI工具一键配置开发环境中的API密钥
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Taotoken CLI工具一键配置开发环境中的API密钥 在团队协作或个人开发中,为每个项目或成员手动配置大模型API密钥和…...

阿波罗登月,不可能:读心术与影子叙事 ——不是向全世界展示登月,而是向全世界注射登月
阿波罗登月,不可能:读心术与影子叙事 ——不是向全世界展示登月,而是向全世界注射登月 Jianbing Zhu 1^{1}1 1^{1}1 ECT-OS-JiuHuaShan 文明实验室 ORCID: 0009-0006-8591-1891 DOI: 10.5281/zenodo.20373157 Email: ect-os-jiuhuashanzoho…...

3大技术突破:重新定义Switch游戏安装性能极限
3大技术突破:重新定义Switch游戏安装性能极限 【免费下载链接】Awoo-Installer A No-Bullshit NSP, NSZ, XCI, and XCZ Installer for Nintendo Switch 项目地址: https://gitcode.com/gh_mirrors/aw/Awoo-Installer Awoo Installer是一款专为破解版Nintendo…...

基于ISDN信令的来电语音播报系统:从原理到树莓派实现
1. 项目概述:一个基于ISDN的来电语音播报系统如果你家里或办公室里还有一台老式的ISDN路由器,别急着把它当电子垃圾处理掉。我最近就利用手头一台闲置的ISDN路由器,折腾出了一个挺有意思的小玩意儿:一个能自动识别来电号码&#x…...

基于窗口比较器与晶体管逻辑的可编程非线性电压指示器设计
1. 项目概述:打造一个可编程的“移动光点”电压指示器在电子制作和仪器仪表领域,我们经常需要一个直观的电压指示器。经典的LM3914点/条图显示驱动芯片大家都很熟悉,它能把一个模拟电压信号转换成10个LED的点亮状态,形成移动的光点…...

终极鸣潮优化指南:WaveTools工具箱让你的游戏体验飞起来
终极鸣潮优化指南:WaveTools工具箱让你的游戏体验飞起来 【免费下载链接】WaveTools 🧰鸣潮工具箱 项目地址: https://gitcode.com/gh_mirrors/wa/WaveTools 对于《鸣潮》玩家来说,流畅的游戏体验和个性化的配置管理是提升游戏乐趣的关…...

线程池面试
线程池面试|一页极简口述满分版(高级开发必背) 一、核心概念解析(口述满分) 线程池核心作用:实现线程复用,规避线程频繁创建、销毁的性能开销,同时实现并发限流、服务熔断防护、异步…...
)
BGP选路原则--本地优先级(LocPrf)
如果BGP收到相同的路由,首选值PrefVal如果也相同的话,那么就会继续比较下一条原则:本地优先级Local_Pref 一、拓扑图 二、配置BGP路由协议: R1 bgp 100 peer 12.1.1.2 as-number 200 peer 13.1.1.3 as-number 200 R2 bgp 200 peer 4.4.4.4 as-number 200 peer 4.4.4…...