校园供水系统智能管理
import pandas as pd
data1=pd.read_excel("C://Users//JJH//Desktop//E//附件_一季度.xlsx")
data2=pd.read_excel("C://Users//JJH//Desktop//E//附件_二季度.xlsx")
data3=pd.read_excel("C://Users//JJH//Desktop//E//附件_三季度.xlsx")
data4=pd.read_excel("C://Users//JJH//Desktop//E//附件_四季度.xlsx")
data1| 水表名 | 水表号 | 采集时间 | 上次读数 | 当前读数 | 用量 | |
|---|---|---|---|---|---|---|
| 0 | 司法鉴定中心 | 0 | 2019/1/1 00:15:00 | 2157.1 | 2157.1 | 0.0 |
| 1 | 司法鉴定中心 | 0 | 2019/1/1 00:30:00 | 2157.1 | 2157.1 | 0.0 |
| 2 | 司法鉴定中心 | 0 | 2019/1/1 00:45:00 | 2157.1 | 2157.1 | 0.0 |
| 3 | 司法鉴定中心 | 0 | 2019/1/1 01:00:00 | 2157.1 | 2157.1 | 0.0 |
| 4 | 司法鉴定中心 | 0 | 2019/1/1 01:15:00 | 2157.1 | 2157.1 | 0.0 |
| ... | ... | ... | ... | ... | ... | ... |
| 729278 | 物业 | 3030100102 | 2019/3/31 22:45:00 | 50.9 | 50.9 | 0.0 |
| 729279 | 物业 | 3030100102 | 2019/3/31 23:00:00 | 50.9 | 50.9 | 0.0 |
| 729280 | 物业 | 3030100102 | 2019/3/31 23:15:00 | 50.9 | 50.9 | 0.0 |
| 729281 | 物业 | 3030100102 | 2019/3/31 23:30:00 | 50.9 | 50.9 | 0.0 |
| 729282 | 物业 | 3030100102 | 2019/3/31 23:45:00 | 50.9 | 50.9 | 0.0 |
729283 rows × 6 columns
data1.isnull().sum()
水表名 0
水表号 0
采集时间 0
上次读数 0
当前读数 0
用量 0
dtype: int64
data2.isnull().sum()
水表名 0
水表号 0
采集时间 0
上次读数 0
当前读数 0
用量 0
dtype: int64
data3.isnull().sum()
水表名 0
水表号 0
采集时间 0
上次读数 0
当前读数 0
用量 0
dtype: int64
data4.isnull().sum()
水表名 0
水表号 0
采集时间 0
上次读数 0
当前读数 0
用量 0
dtype: int64
import numpy as np
# 合并数据
data1['季度'] = pd.Series(["一季度" for i in range(len(data1.index))])
data2['季度'] = pd.Series(["二季度" for i in range(len(data2.index))])
data3['季度'] = pd.Series(["三季度" for i in range(len(data3.index))])
data4['季度'] = pd.Series(["四季度" for i in range(len(data4.index))])
data1| 水表名 | 水表号 | 采集时间 | 上次读数 | 当前读数 | 用量 | 季度 | |
|---|---|---|---|---|---|---|---|
| 0 | 司法鉴定中心 | 0 | 2019/1/1 00:15:00 | 2157.1 | 2157.1 | 0.0 | 一季度 |
| 1 | 司法鉴定中心 | 0 | 2019/1/1 00:30:00 | 2157.1 | 2157.1 | 0.0 | 一季度 |
| 2 | 司法鉴定中心 | 0 | 2019/1/1 00:45:00 | 2157.1 | 2157.1 | 0.0 | 一季度 |
| 3 | 司法鉴定中心 | 0 | 2019/1/1 01:00:00 | 2157.1 | 2157.1 | 0.0 | 一季度 |
| 4 | 司法鉴定中心 | 0 | 2019/1/1 01:15:00 | 2157.1 | 2157.1 | 0.0 | 一季度 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 729278 | 物业 | 3030100102 | 2019/3/31 22:45:00 | 50.9 | 50.9 | 0.0 | 一季度 |
| 729279 | 物业 | 3030100102 | 2019/3/31 23:00:00 | 50.9 | 50.9 | 0.0 | 一季度 |
| 729280 | 物业 | 3030100102 | 2019/3/31 23:15:00 | 50.9 | 50.9 | 0.0 | 一季度 |
| 729281 | 物业 | 3030100102 | 2019/3/31 23:30:00 | 50.9 | 50.9 | 0.0 | 一季度 |
| 729282 | 物业 | 3030100102 | 2019/3/31 23:45:00 | 50.9 | 50.9 | 0.0 | 一季度 |
729283 rows × 7 columns
data = data1.append([data2,data3,data4],ignore_index=True) # 添加合并
dataC:\Users\JJH\AppData\Local\Temp\ipykernel_31264\4019438690.py:1: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.data = data1.append([data2,data3,data4],ignore_index=True) # 添加合并
| 水表名 | 水表号 | 采集时间 | 上次读数 | 当前读数 | 用量 | 季度 | |
|---|---|---|---|---|---|---|---|
| 0 | 司法鉴定中心 | 0 | 2019/1/1 00:15:00 | 2157.1 | 2157.1 | 0.0 | 一季度 |
| 1 | 司法鉴定中心 | 0 | 2019/1/1 00:30:00 | 2157.1 | 2157.1 | 0.0 | 一季度 |
| 2 | 司法鉴定中心 | 0 | 2019/1/1 00:45:00 | 2157.1 | 2157.1 | 0.0 | 一季度 |
| 3 | 司法鉴定中心 | 0 | 2019/1/1 01:00:00 | 2157.1 | 2157.1 | 0.0 | 一季度 |
| 4 | 司法鉴定中心 | 0 | 2019/1/1 01:15:00 | 2157.1 | 2157.1 | 0.0 | 一季度 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 3086783 | 消防 | 3620303200 | 2019/12/31 22:45:00 | 22.0 | 22.0 | 0.0 | 四季度 |
| 3086784 | 消防 | 3620303200 | 2019/12/31 23:00:00 | 22.0 | 22.0 | 0.0 | 四季度 |
| 3086785 | 消防 | 3620303200 | 2019/12/31 23:15:00 | 22.0 | 22.0 | 0.0 | 四季度 |
| 3086786 | 消防 | 3620303200 | 2019/12/31 23:30:00 | 22.0 | 22.0 | 0.0 | 四季度 |
| 3086787 | 消防 | 3620303200 | 2019/12/31 23:45:00 | 22.0 | 22.0 | 0.0 | 四季度 |
3086788 rows × 7 columns
x=data[['水表名','用量','采集时间']]
x
| 水表名 | 用量 | 采集时间 | |
|---|---|---|---|
| 0 | 司法鉴定中心 | 0.0 | 2019/1/1 00:15:00 |
| 1 | 司法鉴定中心 | 0.0 | 2019/1/1 00:30:00 |
| 2 | 司法鉴定中心 | 0.0 | 2019/1/1 00:45:00 |
| 3 | 司法鉴定中心 | 0.0 | 2019/1/1 01:00:00 |
| 4 | 司法鉴定中心 | 0.0 | 2019/1/1 01:15:00 |
| ... | ... | ... | ... |
| 3086783 | 消防 | 0.0 | 2019/12/31 22:45:00 |
| 3086784 | 消防 | 0.0 | 2019/12/31 23:00:00 |
| 3086785 | 消防 | 0.0 | 2019/12/31 23:15:00 |
| 3086786 | 消防 | 0.0 | 2019/12/31 23:30:00 |
| 3086787 | 消防 | 0.0 | 2019/12/31 23:45:00 |
3086788 rows × 3 columns
x1=x[x['水表名']=='消防']
x1
| 水表名 | 用量 | 采集时间 | |
|---|---|---|---|
| 1500912 | 消防 | 0.0 | 2019/4/22 12:15:00 |
| 1500913 | 消防 | 0.0 | 2019/4/22 12:30:00 |
| 1500914 | 消防 | 0.0 | 2019/4/22 12:45:00 |
| 1500915 | 消防 | 0.0 | 2019/4/22 13:00:00 |
| 1500916 | 消防 | 0.0 | 2019/4/22 13:15:00 |
| ... | ... | ... | ... |
| 3086783 | 消防 | 0.0 | 2019/12/31 22:45:00 |
| 3086784 | 消防 | 0.0 | 2019/12/31 23:00:00 |
| 3086785 | 消防 | 0.0 | 2019/12/31 23:15:00 |
| 3086786 | 消防 | 0.0 | 2019/12/31 23:30:00 |
| 3086787 | 消防 | 0.0 | 2019/12/31 23:45:00 |
23984 rows × 3 columns
import matplotlib.pyplot as plt
print(len(x1))
23984
# 自定义x轴刻度
xticks = ['Jan', 'Mar', 'May', 'Jul', 'Sep','Nov'] # 自定义刻度标签
x = range(23984)# 自定义x轴刻度
num_ticks = 6 # 指定刻度数量
step = len(x) // num_ticks # 计算刻度步长
xtick_positions = [i * step for i in range(num_ticks)] # 生成刻度位置
plt.xticks(xtick_positions, xticks)
plt.plot(x1['采集时间'],x1['用量'],color='black',linewidth=0.5)
plt.show()

x=data[['水表名','用量','采集时间']]
x
| 水表名 | 用量 | 采集时间 | |
|---|---|---|---|
| 0 | 司法鉴定中心 | 0.0 | 2019/1/1 00:15:00 |
| 1 | 司法鉴定中心 | 0.0 | 2019/1/1 00:30:00 |
| 2 | 司法鉴定中心 | 0.0 | 2019/1/1 00:45:00 |
| 3 | 司法鉴定中心 | 0.0 | 2019/1/1 01:00:00 |
| 4 | 司法鉴定中心 | 0.0 | 2019/1/1 01:15:00 |
| ... | ... | ... | ... |
| 3086783 | 消防 | 0.0 | 2019/12/31 22:45:00 |
| 3086784 | 消防 | 0.0 | 2019/12/31 23:00:00 |
| 3086785 | 消防 | 0.0 | 2019/12/31 23:15:00 |
| 3086786 | 消防 | 0.0 | 2019/12/31 23:30:00 |
| 3086787 | 消防 | 0.0 | 2019/12/31 23:45:00 |
3086788 rows × 3 columns
x2=x[x['水表名']=='XXX第一学生宿舍']
x2
| 水表名 | 用量 | 采集时间 | |
|---|---|---|---|
| 220372 | XXX第一学生宿舍 | 0.12 | 2019/1/1 00:15:00 |
| 220373 | XXX第一学生宿舍 | 0.12 | 2019/1/1 00:30:00 |
| 220374 | XXX第一学生宿舍 | 0.12 | 2019/1/1 00:45:00 |
| 220375 | XXX第一学生宿舍 | 0.12 | 2019/1/1 01:00:00 |
| 220376 | XXX第一学生宿舍 | 0.12 | 2019/1/1 01:15:00 |
| ... | ... | ... | ... |
| 2533541 | XXX第一学生宿舍 | 0.40 | 2019/12/31 22:45:00 |
| 2533542 | XXX第一学生宿舍 | 0.40 | 2019/12/31 23:00:00 |
| 2533543 | XXX第一学生宿舍 | 0.50 | 2019/12/31 23:15:00 |
| 2533544 | XXX第一学生宿舍 | 0.50 | 2019/12/31 23:30:00 |
| 2533545 | XXX第一学生宿舍 | 0.50 | 2019/12/31 23:45:00 |
35039 rows × 3 columns
# 自定义x轴刻度
xticks = ['Jan', 'Mar', 'May', 'Jul', 'Sep','Nov'] # 自定义刻度标签# 自定义x轴刻度
num_ticks = 6 # 指定刻度数量
step = len(x2) // num_ticks # 计算刻度步长
xtick_positions = [i * step for i in range(num_ticks)] # 生成刻度位置
plt.xticks(xtick_positions, xticks)
plt.plot(x2['采集时间'],x2['用量'],color='black',linewidth=0.5)
plt.show()

x=data[['水表名','用量','采集时间']]
x3=x[x['水表名']=='留学生楼(新)']
# 自定义x轴刻度
xticks = ['Jan', 'Mar', 'May', 'Jul', 'Sep','Nov'] # 自定义刻度标签# 自定义x轴刻度
num_ticks = 6 # 指定刻度数量
step = len(x3) // num_ticks # 计算刻度步长
xtick_positions = [i * step for i in range(num_ticks)] # 生成刻度位置
plt.xticks(xtick_positions, xticks)
plt.plot(x3['采集时间'],x3['用量'],color='black',linewidth=0.3)
plt.show()

x=data[['水表名','用量','采集时间']]
x4=x[x['水表名']=='XXX教学大楼总表']
# 自定义x轴刻度
xticks = ['Jan', 'Mar', 'May', 'Jul', 'Sep','Nov'] # 自定义刻度标签# 自定义x轴刻度
num_ticks = 6 # 指定刻度数量
step = len(x4) // num_ticks # 计算刻度步长
xtick_positions = [i * step for i in range(num_ticks)] # 生成刻度位置
plt.xticks(xtick_positions, xticks)
plt.plot(x4['采集时间'],x4['用量'],color='black',linewidth=0.3)
plt.show()

import matplotlib.pyplot as pltplt.rcParams['font.sans-serif'] = ['SimHei'] # 指定字体为SimHei
labels = ['消防', '留学生楼(新)', 'XXX教学大楼总表']plt.boxplot([x1['用量'],x3['用量'],x4['用量']])plt.xticks(range(1, 4), labels)
# 显示图形
plt.show()

相关文章:
校园供水系统智能管理
import pandas as pd data1pd.read_excel("C://Users//JJH//Desktop//E//附件_一季度.xlsx") data2pd.read_excel("C://Users//JJH//Desktop//E//附件_二季度.xlsx") data3pd.read_excel("C://Users//JJH//Desktop//E//附件_三季度.xlsx") data4…...

Flask-SocketIO和Flask-Login联合开发socketio权限系统
设置 Flask, Flask-SocketIO, Flask-Login: 首先,确保安装了必要的库: pip install Flask Flask-SocketIO Flask-Login基础设置: from flask import Flask, render_template, redirect, url_for, request from flask_socketio import SocketIO, emit from flask_…...

航空电子设备中的TSN通讯架构—直升机
前言 以太网正在迅速取代传统网络,成为航空电子设备和任务系统的核心高速网络。本文提出了以太网时间敏感网络(TSN)在航空电子设备上应用的技术优势问题。在实际应用中,TSN已成为一个具有丰富的机制和协议的工具箱,可满足与时间和可靠性相关…...

elment-ui中使用el-steps案例
el-steps案例 样式 代码 <div class"active-box"><div class"active-title">请完善</div><el-steps :active"active" finish-status"success" align-center><el-step title"第一步" /><…...

FPGA解析串口指令控制spi flash完成连续写、读、擦除数据
前言 最近在收拾抽屉时找到一个某宝的spi flash模块,如下图所示,我就想用能不能串口来读写flash,大致过程就是,串口向fpga发送一条指令,fpga解析出指令控制flah,这个指令协议目前就是: 55 AA …...

msvcp120.dll丢失的解决方法,分享三种快速修复的方法
今天,我将和大家分享一个关于电脑问题的解决方法——msvcp120.dll丢失的解决方法。希望对大家有所帮助。 首先,让我们来了解一下msvcp120.dll文件。msvcp120.dll是Microsoft Visual C 2010 Redistributable Package的一个组件,它包含了一些运…...
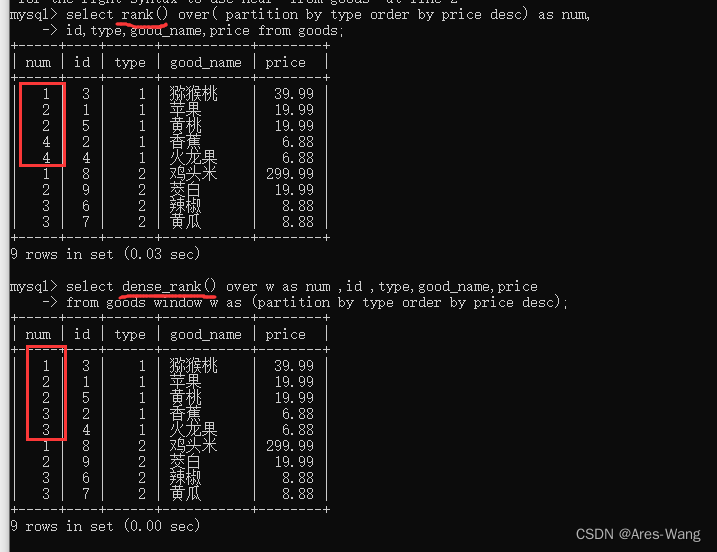
mysql 8.0 窗口函数 之 序号函数 与 sql server 序号函数 一样
sql server 序号函数 序号函数 ROW_NUMBER() 顺序排序RANK() 并列排序,会跳过重复的序号,比如序号为1,1,3DENSE_RANK() 并列排序,不会跳过重复的序号,比如 序号为 1,1,2 语法结构…...
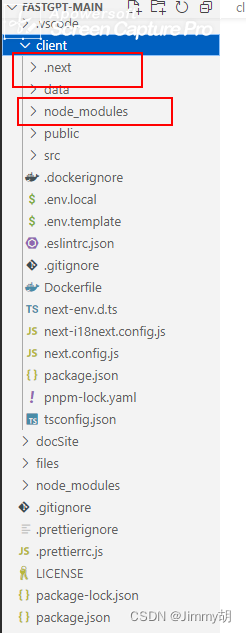
fastgpt构建镜像
1.把client目录复制到服务器 .next和node_modules文件夹不用上传到服务器 在服务器目录运行 docker build -t fastgpt:1.0.3 . 构建服务 再运行 docker ps 就可以看到容器了...

Git笔记--分支常用命令
目录 1--git branch -v 2--git branch 3--git checkout 4--git merge 1--git branch -v git branch -v git branch -v 用于查看分支版本; 2--git branch git branch xxxxx # xxxxx表示分支名 git branch 用于创建分支; 3--git checkout git check…...

常见设计模式学习+面试总结
一 设计模式简介 二 面试总结 1 什么是单例模式?都有哪些地方用到单例? 内存中只会创建且仅创建一次对象的设计模式,保证一个类只有一个实例,并且提供一个访问该全局访问点。 应用场景: 网站的计数器,一般…...

sql解决取多个截至每个月的数据
问题:需要查询1月、1-2月、1-3月… 1-12月,分区间的累计数据,在同一个sql语句里面实现。 多个分开查询效率不高,并且数据手动合并麻烦。 with t1 as ( SELECT *,CASE WHEN insutype 390 THEN 居民 ELSE 职工 END 人员类别,SUBST…...
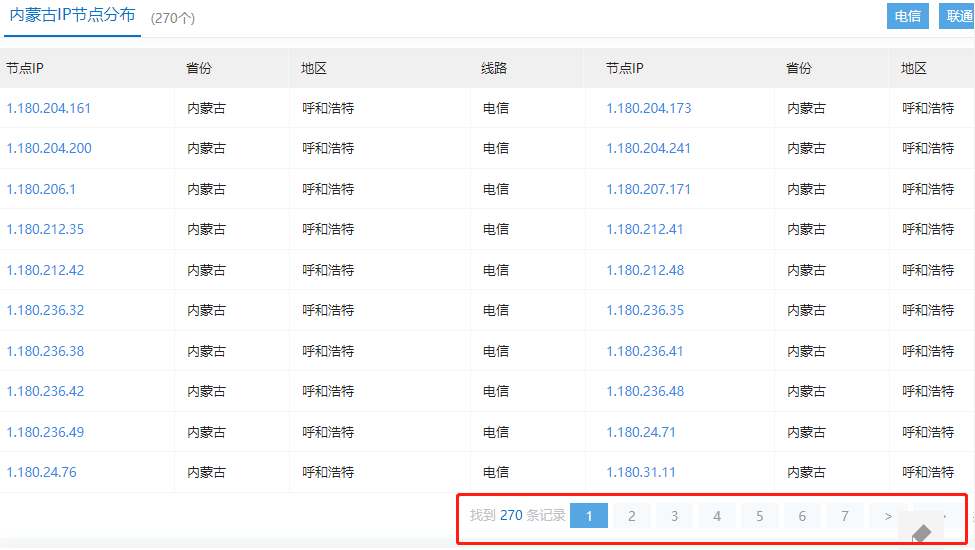
数据采集:selenium 获取 CDN 厂家各省市节点 IP
写在前面 工作需要遇到,简单整理理解不足小伙伴帮忙指正 对每个人而言,真正的职责只有一个:找到自我。然后在心中坚守其一生,全心全意,永不停息。所有其它的路都是不完整的,是人的逃避方式,是对…...
【el-tree】树形组件图标的自定义
饿了么树形组件的图标自定义 默认样式: 可以看到el-tree组件左侧自带展开与收起图标,咱们可以把它隐藏:: .groupList {::v-deep .el-tree-node { .el-icon-caret-right {display: none;} } } 我的全部代码 <div class"groupList"><el…...
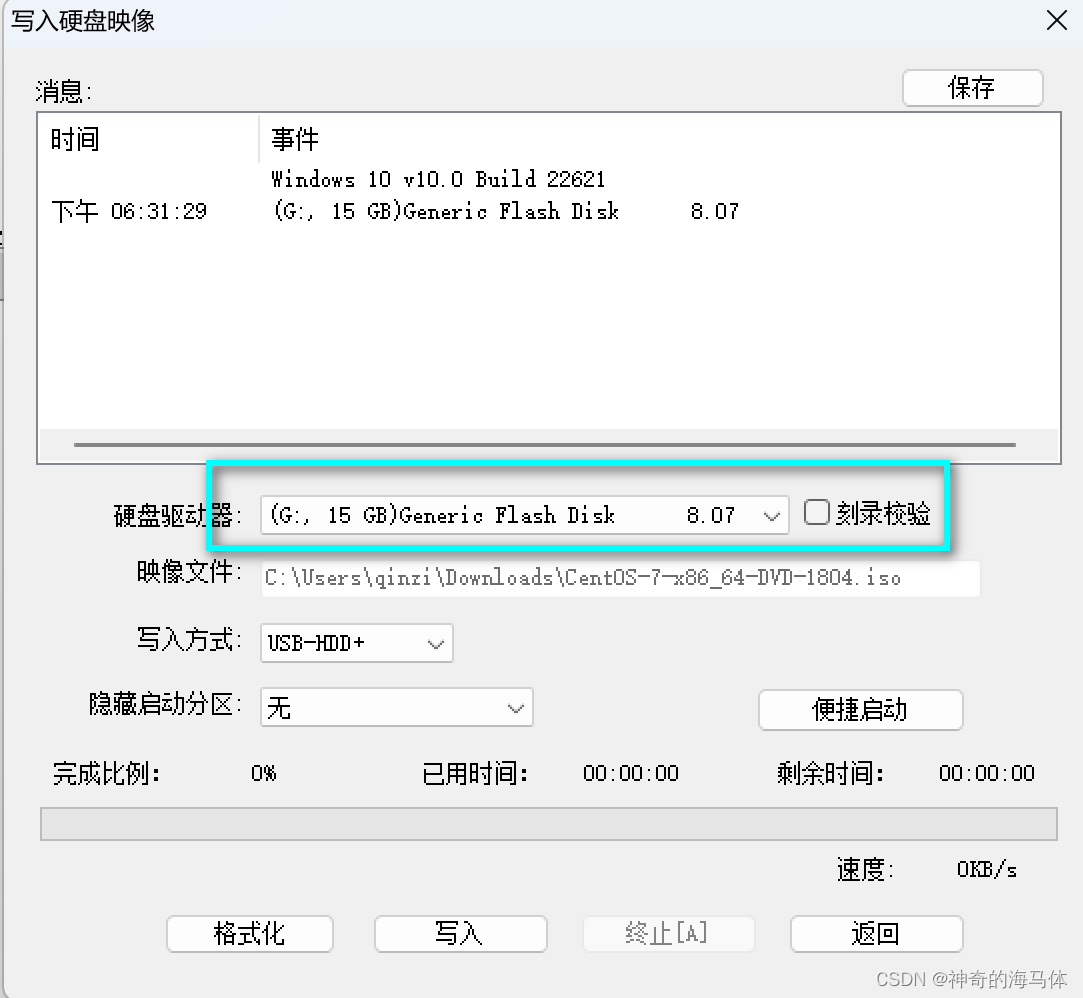
UltralSO软碟通制作Linux系统盘
第一步: 下载镜像 阿里云下载地址:https://mirrors.aliyun.com/centos-vault/ 按照需求选择系统版本,我这要求安装CentOS7.5的系统,我以CentOS7.5为例 第二步: 下载UltralSO软件 官网下载地址:https://cn.…...

yolov8训练心得 持续更新
目录 优化器 lion优化器,学习率0.0001,训练效果: 学习率衰减 600个batch衰减0.7,发现效果较好...
超越界限:大模型应用领域扩展,探索文本分类、文本匹配、信息抽取和性格测试等多领域应用
超越界限:大模型应用领域扩展,探索文本分类、文本匹配、信息抽取和性格测试等多领域应用 随着 ChatGPT 和 GPT-4 等强大生成模型出现,自然语言处理任务方式正在逐步发生改变。鉴于大模型强大的任务处理能力,未来我们或将不再为每…...

Compose - 基本使用
一、概念 1.1 Compose优势 由一个个可以组合的Composable函数拼成界面,方便维护和复用。布局模型不允许多次测量,提升了性能。Compose可以和View互操作(相互包含对方)。 1.2 声明式UI APP展示的数据绝大多数不是静态数据而是会…...
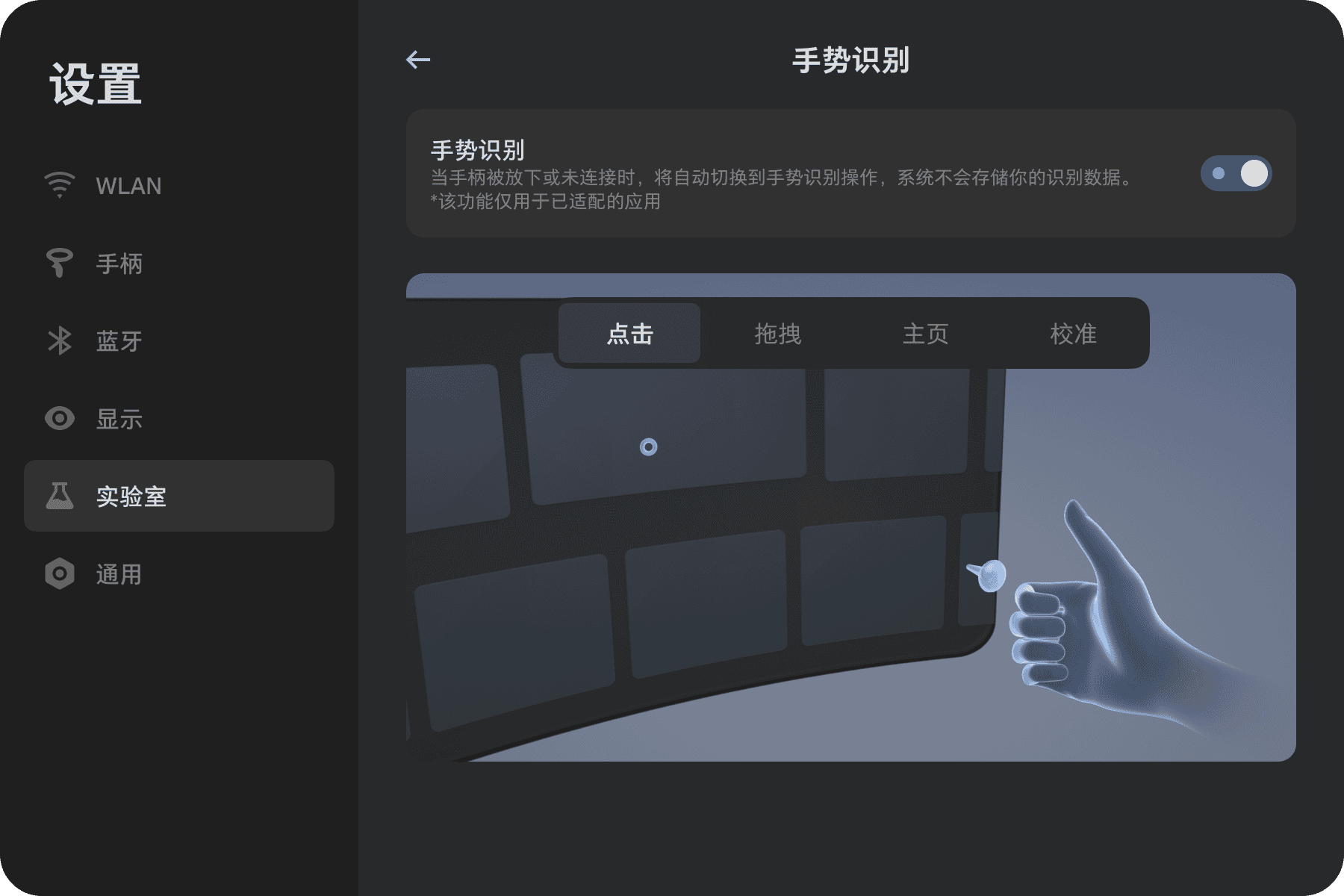
Unity3D Pico VR 手势识别
本文章使用的 Unity3D版本: 2021.3.6 , Pico SDK 230 ,Pico OS v.5.7.1 硬件Pico 4 Pico SDK可以去Pico官网下载SDK 导入SDK 第一步:创建Unity3D项目 第二步:导入 PICO Unity Integration SDK 选择 Windows > Package Manager。 在 Packag…...

【docker】运行registry
registry简介 Docker registry是docker镜像仓库的服务,用于存储和分发docker镜像。 Docker registry主要特点和功能: 存储docker镜像:提供持久化存储docker镜像的功能,存储镜像的各个layer。 分发镜像:拉取和推送镜像的去中心化存储和分发服务。 支持版本管理:给镜像打标签…...
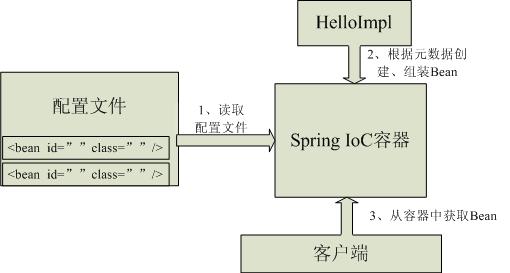
java八股文面试[Spring]——如何实现一个IOC容器
什么是IOC容器 IOC不是一种技术,只是一种思想,一个重要的面向对象编程的法则,它能指导我们如何设计出松耦合,更优良的程序。传统应用程序都是由我们在类内部主动创建依赖对象,从而导致类与类之间高耦合,难于…...
)
斐讯K3从梅林‘变砖’到官复原职:一个手残党的硬核救砖全记录(附TTL/编程器操作避坑点)
斐讯K3救砖实战:从梅林固件崩溃到完美恢复的完整指南 1. 当路由器变成"砖头":一个普通用户的崩溃瞬间 那是一个普通的周末下午,我正兴冲冲地准备给我的斐讯K3刷上梅林固件,幻想着能获得更强大的功能和更稳定的性能。按照…...

VLC源码深度定制:3大核心模块解析与编译实践
VLC源码深度定制:3大核心模块解析与编译实践 【免费下载链接】vlc VLC media player - All pull requests are ignored, please use MRs on https://code.videolan.org/videolan/vlc 项目地址: https://gitcode.com/gh_mirrors/vl/vlc 你是否曾想过ÿ…...

CodeBuddy ai对话框上面的git docs terminal Rulds 干嘛用的,以thinkphp fastadmin 为例,插件市场
CodeBuddy(或同类 AI 编程助手)里的**「上下文注入(Context Injection)」功能模块**,作用是把项目/环境信息喂给 AI,让它“看得懂你的项目”,而不是凭空瞎编代码。 插件市场###ai对对话框 逐个拆…...

基于LLM与RAG的法律AI工具:从架构解析到工程实践
1. 项目概述:一个法律文本智能生成与分析的AI工具最近在和一些做法律科技的朋友聊天时,他们反复提到一个痛点:处理海量的、格式固定的法律文书,比如起诉状、合同、律师函,既耗时又容易在细节上出错。人工起草一份严谨的…...
:Kubernetes部署图像去噪服务,实现容器编排和弹性扩展)
Pytorch图像去噪实战(七十四):Kubernetes部署图像去噪服务,实现容器编排和弹性扩展
Pytorch图像去噪实战(七十四):Kubernetes部署图像去噪服务,实现容器编排和弹性扩展 一、问题场景:Docker Compose够用,但多服务扩展开始吃力 前面我们用 Docker Compose 部署了图像去噪服务。 Compose 对单机部署非常好用,但当项目变复杂后,会遇到: 多台机器部署困难…...

深入T100系统腹地:拆解标准区、测试区与客制开发的协作逻辑
深入T100系统腹地:拆解标准区、测试区与客制开发的协作逻辑 在企业管理系统的复杂生态中,T100以其独特的四区架构和多环境协作机制,为企业的数字化转型提供了稳健的技术支撑。这套架构不仅关乎代码的流转,更是企业业务流程标准化与…...

实战复盘:我是如何用Elastic Security+Zeek构建一个小型企业安全监控平台的
实战复盘:Elastic SecurityZeek构建小型企业安全监控平台 当企业规模扩张到50人以上时,网络资产和终端设备数量会呈现指数级增长。去年为某电商团队部署安全系统时,他们的CTO向我展示了一份令人不安的数据:平均每天遭遇23次暴力破…...

实测推荐!2026年毕业论文5000字范文免费下载AI写作工具排行,查重降AI率全攻略
本文由知学术AIPaperGPT内容团队实测撰写 2026-05-11实测推荐!2026年毕业论文5000字范文免费下载AI写作工具排行,查重降AI率全攻略又是一年毕业季,无数本科、硕士生正为毕业…...

如何在Chrome浏览器中快速生成与扫描二维码:终极免费插件指南
如何在Chrome浏览器中快速生成与扫描二维码:终极免费插件指南 【免费下载链接】chrome-qrcode :zap: A Chrome plugin to Genrate QRCode of URL / Text, or Decode the QRcode in website. 一个Chrome浏览器插件,用于生成当前URL或者选中内容的二维码&a…...

2026购物机器人操作指南:工作原理与使用教程
在电商自动化和AI技术不断发展的背景下,购物机器人(Shopping Bot)正在成为越来越多人关注的工具。无论是用于限量商品抢购、价格监控,还是电商数据采集,它都在改变传统的线上购物方式。本文将从基础概念出发࿰…...