Huggingface训练Transformer
在之前的博客中,我采用SFT(监督优化训练)的方法训练一个GPT2的模型,使得这个模型可以根据提示语进行回答。具体可见博客召唤神龙打造自己的ChatGPT_gzroy的博客-CSDN博客
Huggingface提供了一个TRL的扩展库,可以对transformer模型进行强化学习,SFT是其中的一个训练步骤,为此我也测试一下如何用Huggingface来进行SFT训练,和Pytorch的训练方式做一个比较。
训练数据
首先是获取训练数据,这里同样是采用Huggingface的chatbot_instruction_prompts的数据集,这个数据集涵盖了不同类型的问答,可以用作我们的模型优化之用。
from datasets import load_datasetds = load_dataset("alespalla/chatbot_instruction_prompts")
train_ds = ds['train']
eval_dataset = ds['test']
eval_dataset = eval_dataset.select(range(1024))训练集总共包括了258042条问答数据,对于验证集我只选取了头1024条记录,因为总的数据集太长,如果在训练过程中全部验证的话耗时太长。
加载GPT2模型
Huggingface提供了很多大模型的训练好的参数,这里我们可以直接加载一个已经训练好的GPT2模型来做优化
from transformers import AutoModelForCausalLM, AutoTokenizermodel = AutoModelForCausalLM.from_pretrained("gpt2")
tokenizer = AutoTokenizer.from_pretrained("gpt2")
tokenizer.pad_token = tokenizer.eos_token然后我们可以定义TRL提供的SFTTrainer来进行训练,首先需要对训练数据处理一下,因为训练数据包括了两列,分别是prompt和response,我们需要把两列的文本合为一起,通过格式化字符来区分,如以下格式化函数:
def formatting_func(example):text = f"### Prompt: {example['prompt']}\n ### Response: {example['response']}"return text定义SFTTrainer的训练参数,具体每个参数的含义可见官网的文档:
args = TrainingArguments(output_dir='checkpoints_hf_sft',overwrite_output_dir=True, per_device_train_batch_size=4,per_device_eval_batch_size=4,fp16=True,torch_compile=True,evaluation_strategy='steps',prediction_loss_only=True,eval_accumulation_steps=1,learning_rate=0.00006,weight_decay=0.01,adam_beta1=0.9,adam_beta2=0.95,warmup_steps=1000,eval_steps=4000,save_steps=4000,save_total_limit=4,dataloader_num_workers=4,max_steps=12000,optim='adamw_torch_fused')最后就可以定义一个trainer来训练了
trainer = SFTTrainer(model,args = args,train_dataset=dataset,eval_dataset=eval_dataset,tokenizer=tokenizer,packing=True,formatting_func=formatting_func,max_seq_length=1024
)trainer.train(resume_from_checkpoint=False)因为是第一次训练,我设置了resume_from_checkpoint=False,如果是继续训练,把这个参数设为True即可从上次checkpoint目录自动加载最新的checkpoint来训练。
训练结果如下:
[12000/12000 45:05, Epoch 0/1]
| Step | Training Loss | Validation Loss |
|---|---|---|
| 4000 | 2.137900 | 2.262321 |
| 8000 | 2.187800 | 2.232235 |
| 12000 | 2.218500 | 2.210413 |
总共耗时45分钟,比我在pytorch上的训练要快一些(快了10分钟多一些),但是这个训练集的Loss随着Step的增加反而增加了,Validation Loss就减少了,有些奇怪。在Pytorch上我同样训练12000个迭代,最后training loss是去到1.8556的。可能还要再调整一下trainer的参数看看。
测试
最后我们把SFT训练完成的模型,通过huggingface的pipeline就可加载进行测试了。
from transformers import pipelinemodel = AutoModelForCausalLM.from_pretrained('checkpoints_hf_sft/checkpoint-12000/')
pipe = pipeline(task='text-generation', model=model, tokenizer=tokenizer, device=0)pipe('### Prompt: Who is the current president of USA?')[{'generated_text': '### Prompt: Who is the current president of USA?\n ### Response: Harry K. Busby is currently President of the United States.'}]回答的语法没问题,不过内容是错的。
再测试另一个问题
### Prompt: How to make a cup of coffee?
[{'generated_text': '### Prompt: How to make a cup of coffee?\n ### Response: 1. Preheat the oven to 350°F (175°C).\n\n2. Boil the coffee beans according to package instructions.\n\n3. In a'}]
这个回答就正确了。
总结
通过用Huggingface可以很方便的对大模型进行强化学习的训练,不过也正因为太方便了,很多训练的细节被包装了,所以训练的结果不太容易优化,不像在Pytorch里面控制的自由度更高一些。当然可能我对huggingface的trainer参数的细节还不太了解,这个有待后续继续了解。
另外我还发现huggingface的一个小的bug,就是模型从头训练的时候没有问题,但是当我从之前的checkpoint继续训练时,会报CUDA OOM的错误,从nvidia-smi命令看到的显存占用率来看,好像trainer定义模型和装载Checkpoint会重复占用了显存,因此同样的batch_size,在继续训练时就报内存不够了,这个也有待后溪继续了解。
相关文章:
Huggingface训练Transformer
在之前的博客中,我采用SFT(监督优化训练)的方法训练一个GPT2的模型,使得这个模型可以根据提示语进行回答。具体可见博客召唤神龙打造自己的ChatGPT_gzroy的博客-CSDN博客 Huggingface提供了一个TRL的扩展库,可以对tra…...

IA-YOLO项目中DIP模块的初级解读
IA-YOLO项目源自论文Image-Adaptive YOLO for Object Detection in Adverse Weather Conditions,其提出端到端方式联合学习CNN-PP和YOLOv3,这确保了CNN-PP可以学习适当的DIP,以弱监督的方式增强图像检测。IA-YOLO方法可以自适应地处理正常和不…...
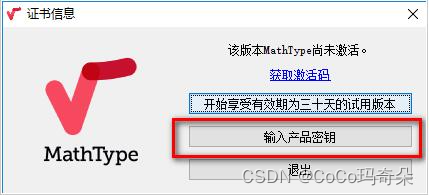
MathType7.4mac最新版本数学公式编辑器安装教程
MathType7.4中文版是一款功能强大且易于使用的公式编辑器。该软件可与word软件配合使用,有效提高了教学人员的工作效率,避免了一些数学符号和公式无法在word中输入的麻烦。新版MathType7.4启用了全新的LOGO,带来了更多对数学符号和公式的支持…...
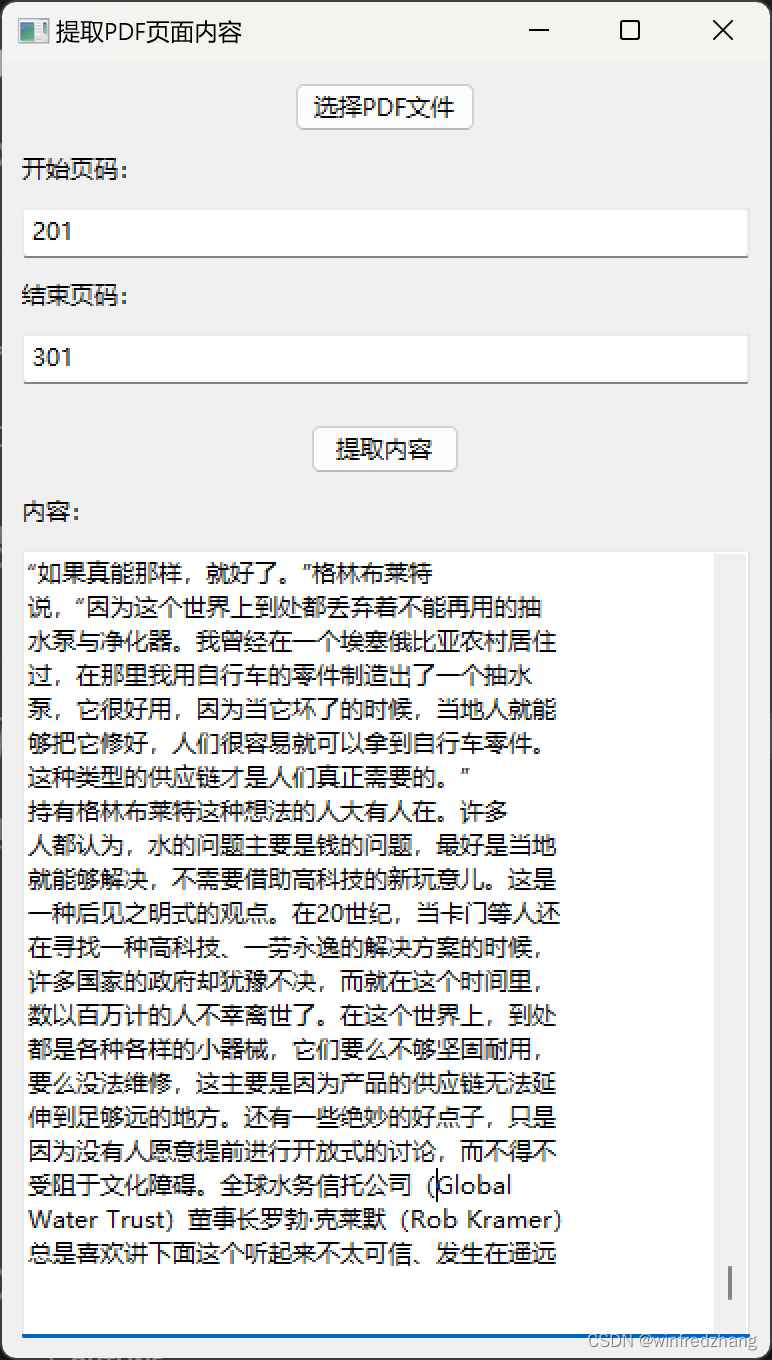
为Claude的分析内容做准备:提取PDF页面内容的简易应用程序
由于Claude虽然可以分析整个文件,但是对文件的大小以及字数是有限制的,为了将pdf文件分批传入Claude人工智能分析和总结文章内容,才有了这篇博客: 在本篇博客中,我们将介绍一个基于 wxPython 和 PyMuPDF 库编写的简易的…...
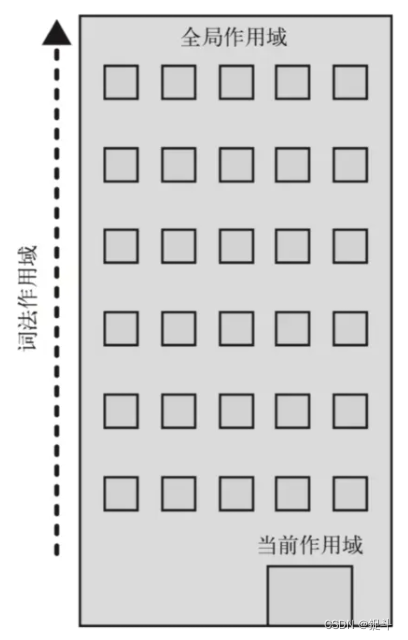
js中作用域的理解?
1.作用域 作用域,即变量(变量作用域又称上下文)和函数生效(能被访问)的区域或集合 换句话说,作用域决定了代码区块中变量和其他资源的可见性 举个例子 function myFunction() {let inVariable "函数内部变量"; } myFunction();//要先执行这…...
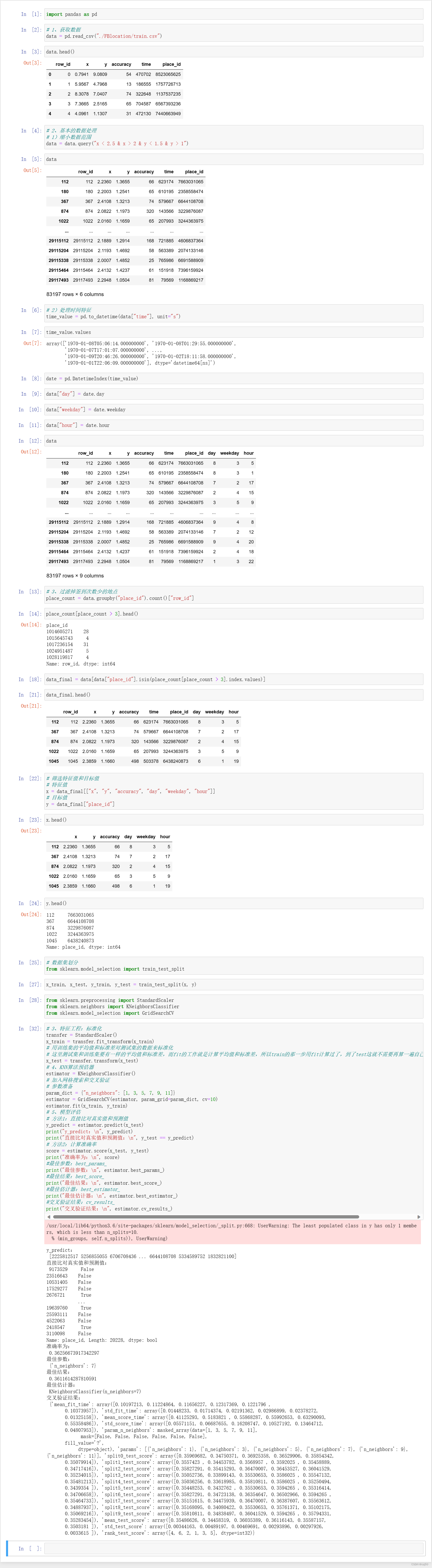
机器学习基础之《分类算法(4)—案例:预测facebook签到位置》
一、背景 1、说明 2、数据集 row_id:签到行为的编码 x y:坐标系,人所在的位置 accuracy:定位的准确率 time:时间戳 place_id:预测用户将要签到的位置 3、数据集下载 https://www.kaggle.com/navoshta/gr…...

【Java】反射 之 调用方法
调用方法 我们已经能通过Class实例获取所有Field对象,同样的,可以通过Class实例获取所有Method信息。Class类提供了以下几个方法来获取Method: Method getMethod(name, Class...):获取某个public的Method(包括父类&a…...

Java——单例设计模式
什么是设计模式? 设计模式是在大量的实践中总结和理论化之后优选的代码结构、编程风格、以及解决问题的思考方式。设计模式免去我们自己再思考和摸索。就像是经典的棋谱,不同的棋局,我们用不同的棋谱、“套路”。 经典的设计模式共有23种。…...

Java实现excel表数据的批量存储(结合easyexcel插件)
场景:加哥最近在做项目时,苦于系统自身并未提供数据批量导入的功能还不能自行添加上该功能,且自身不想手动一条一条将数据录入系统。随后,自己使用JDBC连接数据库、使用EasyExcel插件读取表格并将数据按照业务逻辑批量插入数据库完…...
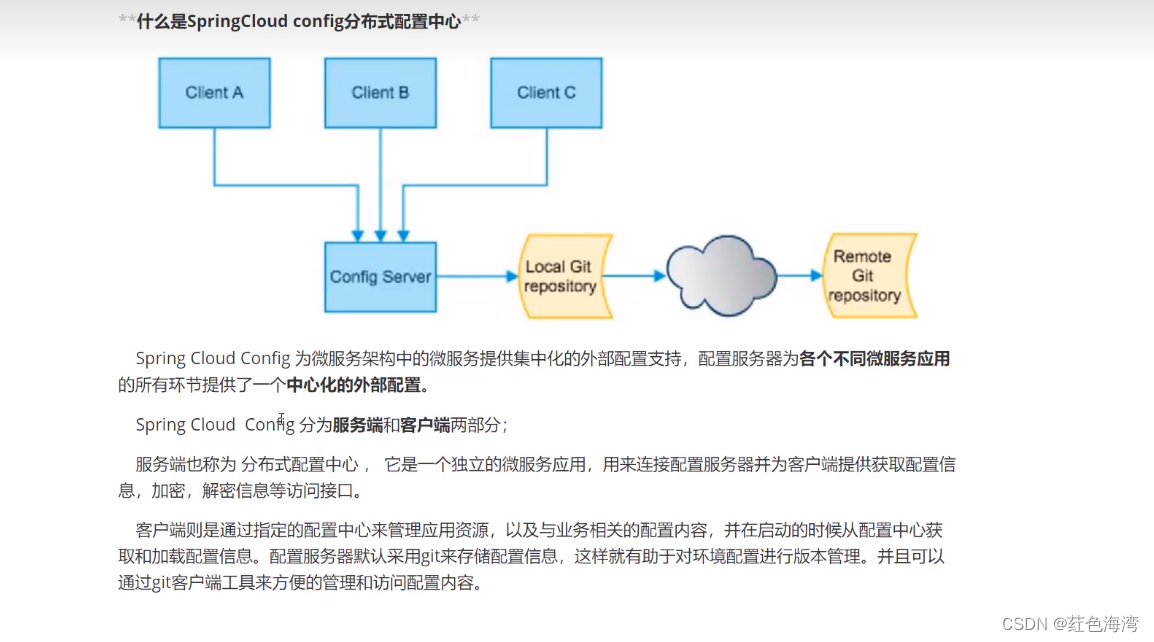
Config:客户端连接服务器访问远程
springcloud-config: springcloud-config push pom <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0"xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocatio…...

【KMP算法-代码随想录】
目录 1.什么是KMP2.什么是next数组3.什么是前缀表(1)前后缀含义(2)最长公共前后缀(3)前缀表的必要性 4.计算前缀表5.前缀表与next数组(1)使用next数组来匹配 6.构造next数组…...
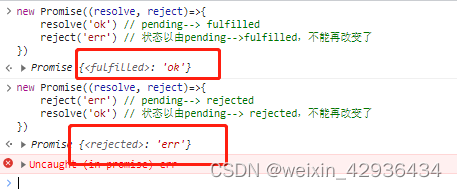
【手写promise——基本功能、链式调用、promise.all、promise.race】
文章目录 前言一、前置知识二、实现基本功能二、实现链式调用三、实现Promise.all四、实现Promise.race总结 前言 关于动机,无论是在工作还是面试中,都会遇到Promise的相关使用和原理,手写Promise也有助于学习设计模式以及代码设计。 本文主…...
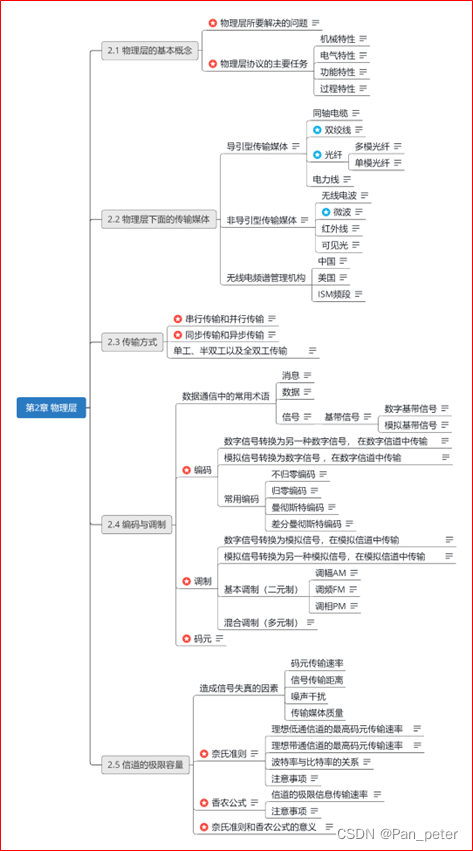
计算机网络-笔记-第二章-物理层
目录 二、第二章——物理层 1、物理层的基本概念 2、物理层下面的传输媒体 (1)光纤、同轴电缆、双绞线、电力线【导引型】 (2)无线电波、微波、红外线、可见光【非导引型】 (3)无线电【频谱的使用】 …...

前端开发中的单伪标签清除和双伪标签清除
引言 在前端开发中,我们经常会遇到一些样式上的问题,其中之一就是伪元素造成的布局问题。为了解决这个问题,我们可以使用伪标签清除技术。本篇博客将介绍单伪标签清除和双伪标签清除的概念、用法和示例代码,并详细解释它们的原理…...

云计算中的数据安全与隐私保护策略
文章目录 1. 云计算中的数据安全挑战1.1 数据泄露和数据风险1.2 多租户环境下的隔离问题 2. 隐私保护策略2.1 数据加密2.2 访问控制和身份验证 3. 应对方法与技术3.1 零知识证明(Zero-Knowledge Proofs)3.2 同态加密(Homomorphic Encryption&…...
MacOS软件安装包分享(附安装教程)
目录 一、软件简介 二、软件下载 一、软件简介 MacOS是一种由苹果公司开发的操作系统,专门用于苹果公司的计算机硬件。它被广泛用于创意和专业应用程序,如图像设计、音频和视频编辑等。以下是关于MacOS的详细介绍。 1、MacOS的历史和演变 MacOS最初于…...

【linux进程概念】
目录: 冯诺依曼体系结构操作系统进程 基本概念描述进程-PCBtask_struct-PCB的一种task_ struct内容分类组织进程查看进程 fork()函数 冯诺依曼体系结构 我们常见的计算机,如笔记本。我们不常见的计算机,如服务器,大部分都遵守冯诺…...

直击成都国际车展:远航汽车多款车型登陆车展,打造完美驾乘体验
随着市场渗透率日益高涨,新能源汽车成为今年成都国际车展的关注焦点。在本届车展上,新能源品牌占比再创新高,覆盖两个展馆,印证了当下新能源汽车市场的火爆。作为大运集团重磅打造的高端品牌,远航汽车深度洞察高端智能…...

android nv21 转 yuv420sp
上面两个函数的目标都是将NV21格式的数据转换为YUV420P格式,但是它们在处理U和V分量的方式上有所不同。 在第一个函数NV21toYUV420P_1中,U和V分量的处理方式是这样的:对于U分量,它从NV21数据的Y分量之后的每个奇数位置取数据&…...

使用Nacos与Spring Boot实现配置管理
🌷🍁 博主猫头虎 带您 Go to New World.✨🍁 🦄 博客首页——猫头虎的博客🎐 🐳《面试题大全专栏》 文章图文并茂🦕生动形象🦖简单易学!欢迎大家来踩踩~🌺 &a…...

UE5中用TypeScript替代蓝图:Puerts热重载实战指南
1. 为什么非得在UE5里塞进TypeScript——一个被蓝图卡住脖子的开发者的自白 我第一次在UE5项目里写完第10个“Get All Actors of Class”节点,拖出第7条执行引线,再连上第4个“Branch”判断分支,最后把结果塞进一个“Set Array Element”时&a…...

HALAR® ECTFE光滑内壁:脱硫塔里,石膏垢为什么不贴它
苏福(深圳)科技有限公司 世索科HALAR ECTFE官方代理商一、脱硫塔结垢这事,运行维护的人最头疼湿法烟气脱硫(WFGD)系统里,脱硫塔内壁、除雾器、浆液循环管道,天天泡在含硫酸钙、亚硫酸钙的浆液里…...

免费中医AI终极指南:仲景大模型如何让普通人也能享受专业中医咨询
免费中医AI终极指南:仲景大模型如何让普通人也能享受专业中医咨询 【免费下载链接】CMLM-ZhongJing 首个中医大语言模型——“仲景”。受古代中医学巨匠张仲景深邃智慧启迪,专为传统中医领域打造的预训练大语言模型。 The first-ever Traditional Chines…...

商业空间吸音地毯怎么选?16 年品牌雅尔居靠谱
商业空间装修,噪音控制是刚需。办公室人声嘈杂、酒店走廊脚步声扰客、工装大堂回音重,都会直接影响空间体验与使用效率。选对吸音地毯,既能高效降噪,又能提升空间质感,是商业空间地面材料的优选。今天就来聊聊吸音地毯…...

COOT模型详解:视频时序理解与跨模态对齐技术
1. 项目概述:让视频自己“开口说话”的底层逻辑 你有没有遇到过这样的场景:手头有一段3分钟的产品演示视频,需要快速生成一段精准的图文摘要发给客户;或者正在做无障碍内容建设,得为一段教学视频配上符合语义节奏的字幕…...

3个步骤让你的Switch Joy-Con在Windows上焕发新生:JoyCon-Driver完全指南
3个步骤让你的Switch Joy-Con在Windows上焕发新生:JoyCon-Driver完全指南 【免费下载链接】JoyCon-Driver A vJoy feeder for the Nintendo Switch JoyCons and Pro Controller 项目地址: https://gitcode.com/gh_mirrors/jo/JoyCon-Driver 你是否曾想过让闲…...

python旅游分享点评网系统
目录同行可拿货,招校园代理 ,本人源头供货商项目概述核心功能技术栈扩展功能建议项目亮点项目技术支持源码获取详细视频演示 :同行可合作点击我获取源码->获取博主联系方式->进我个人主页-->同行可拿货,招校园代理 ,本人源头供货商 项目概述 Python旅游分…...

Source Sans 3:让数字界面阅读体验焕然一新的开源字体解决方案
Source Sans 3:让数字界面阅读体验焕然一新的开源字体解决方案 【免费下载链接】source-sans Sans serif font family for user interface environments 项目地址: https://gitcode.com/gh_mirrors/so/source-sans 你是否曾经在设计网页或应用时,…...

Appium环境搭建:Java/Node.js/ADB/Xcode可信三角验证指南
1. 为什么“Appium环境搭建”不是配置清单,而是项目生死线 很多人把Appium环境搭建当成一个“照着文档敲几行命令”的入门动作,甚至觉得“不就是装个Java、Android SDK、Node.js,再下个Appium Desktop点开就行?”——我去年带三个…...

TI MSPM0G3105-Q1汽车MCU实战解析:从核心特性到硬件设计
1. 项目概述:为什么是MSPM0G3105-Q1?在汽车电子和工业控制领域摸爬滚打十几年,我经手过的MCU型号少说也有几十款。每次启动一个新项目,选型都是头等大事,它直接决定了后续开发的难易度、系统的稳定性和最终产品的成本。…...