《机器学习在车险定价中的应用》实验报告
目录
一、实验题目
机器学习在车险定价中的应用
二、实验设置
1. 操作系统:
2. IDE:
3. python:
4. 库:
三、实验内容
实验前的猜想:
四、实验结果
1. 数据预处理及数据划分
独热编码处理结果(以地区为例)
2. 模型训练
3. 绘制初始决策树
4. 模型评价
5. 模型优化
绘制优化后的决策树
6. 修改样本、网格搜索参数进一步优化模型
五、实验分析
一、实验题目
机器学习在车险定价中的应用
二、实验设置
1. 操作系统:
Windows 11 Home
2. IDE:
PyCharm 2022.3.1 (Professional Edition)
3. python:
3.8.0
4. 库:
| numpy | 1.20.0 | |
| matplotlib | 3.7.1 |
|
| pandas | 1.1.5 | |
| scikit-learn | 0.24.2 |
conda create -n ML python==3.8 pandas scikit-learn numpy matplotlib三、实验内容
本次实验使用决策树模型进行建模,实现对车险 数据的分析,车险数据为如下MTPLdata.csv数据集:
该车险数据集包含了50万个样本,每个样本有8个特征和1个标签。其中,标签是一个二元变量,值为0或1,表示车主是否报告过车险索赔(clm,int64);特征包括车主的年龄(age,int64),车辆的年限(ac,int64)、功率(power,int64)、燃料类型(gas,object)、品牌(brand,object),车主所在地区(area,object)、居住地车辆密度(dens,int64)、以及汽车牌照类型(ct,object)。
实验前的猜想:
详见实验报告
四、实验结果
1. 数据预处理及数据划分
将数据读入并进行数据预处理,包括哑变量处理和划分训练集和测试集
MTPLdata = pd.read_csv('MTPLdata.csv')
# 哑变量处理-独热编码
# 将clm列的数据类型转换为字符串
MTPLdata['clm'] = MTPLdata['clm'].map(str)
# 选择包括第1、2、3、4、5、6、7、8列的数据作为特征输入
# ac、brand、age、gas、power
X_raw = MTPLdata.iloc[:, [0, 1, 2, 3, 4]]
# X_raw = MTPLdata.iloc[:, [0, 1, 2, 3, 4, 5, 6, 7]]
# 对X进行独热编码
X = pd.get_dummies(X_raw)
# 选择第9列作为标签y
y = MTPLdata.iloc[:, 8]# 将数据划分为训练集和测试集,测试集占总数据的20%
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, test_size=0.2, random_state=1)
独热编码处理结果(以地区为例)
2. 模型训练
我们使用决策树分类器模型进行训练(设定树的最大深度为2,使用平衡的类权重,并默认使用基尼系数检验准确度)。
model = DecisionTreeClassifier(max_depth=2, class_weight='balanced', random_state=123)
model.fit(X_train, y_train) # 数据拟合
model.score(X_test, y_test) # 在测试集上评估模型3. 绘制初始决策树
为了更好地解读决策树模型,调用plot_tree函数绘制决策树。
plt.figure(figsize=(11, 11))
plot_tree(model, feature_names=X.columns, node_ids=True, rounded=True, precision=2)
plt.show()
4. 模型评价
pred = model.predict(X_test)
table = pd.crosstab(y_test, pred, rownames=['Actual'], colnames=['Predicted'])
# table# 计算模型的准确率、错误率、召回率、特异度和查准率
table = np.array(table) # 将pandas DataFrame转换为numpy array
Accuracy = (table[0, 0] + table[1, 1]) / np.sum(table) # 准确率
Error_rate = 1 - Accuracy # 错误率
Sensitivity = table[1, 1] / (table[1, 0] + table[1, 1]) # 召回率
Specificity = table[0, 0] / (table[0, 0] + table[0, 1]) # 特异度
Recall = table[1, 1] / (table[0, 1] + table[1, 1]) # 查准率
5. 模型优化
为了寻找更优的模型,我们使用cost_complexity_pruning_path函数计算不同的ccp_alpha对应的决策树的叶子节点总不纯度,并绘制ccp_alpha与总不纯度之间的关系图。
model = DecisionTreeClassifier(class_weight='balanced', random_state=123)
path = model.cost_complexity_pruning_path(X_train, y_train)
plt.plot(path.ccp_alphas, path.impurities, marker='o', drawstyle='steps-post')
plt.xlabel('alpha (cost-complexity parameter)')
plt.ylabel('Total Leaf Impurities')
plt.title('Total Leaf Impurities vs alpha for Training Set')
plt.show()1w样本 50w样本
接着,我们通过交叉验证选择最优的ccp_alpha,并使用最优的ccp_alpha重新训练模型。
绘制优化后的决策树
rangeccpalpha = np.linspace(0.000001, 0.0001, 10, endpoint=True)
param_grid = {'max_depth': np.arange(3, 7, 1),# 'ccp_alpha': rangeccpalpha,'min_samples_leaf': np.arange(1, 5, 1)
}
kfold = StratifiedKFold(n_splits=10, shuffle=True, random_state=1)
model = GridSearchCV(DecisionTreeClassifier(class_weight='balanced', random_state=123),param_grid, cv=kfold)
model.fit(X_train, y_train)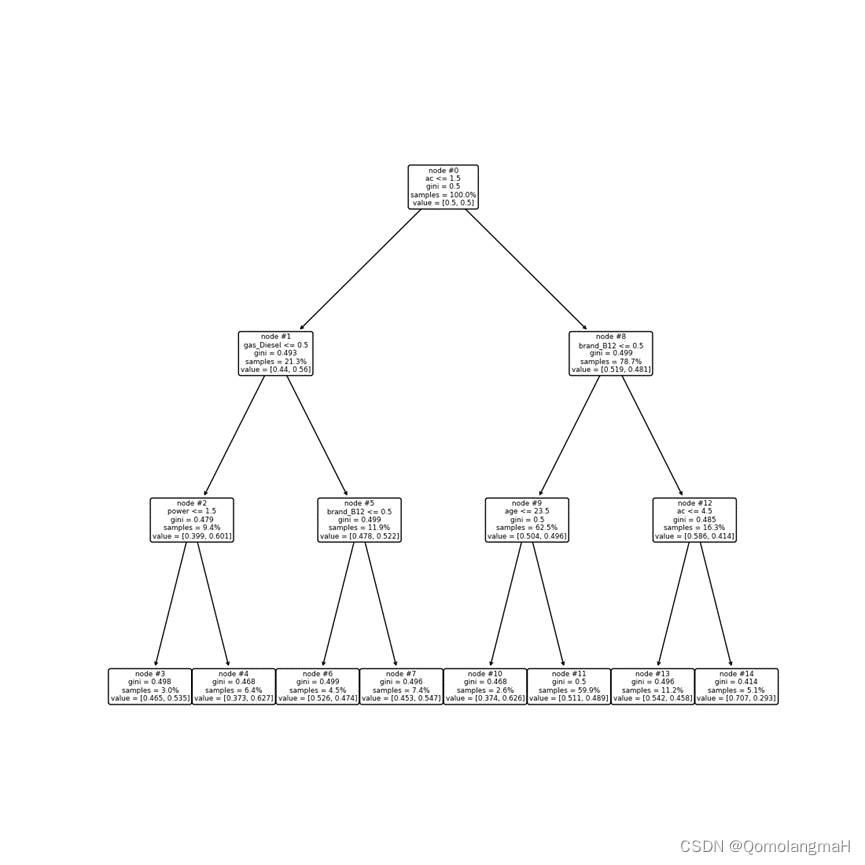
此外,还计算了各个特征的重要性,并绘制了特征重要性图。
plt.figure(figsize=(20, 20))
sorted_index = model.feature_importances_.argsort()
plt.barh(range(X_train.shape[1]), model.feature_importances_[sorted_index])
plt.yticks(np.arange(X_train.shape[1]), X_train.columns[sorted_index])
plt.xlabel('Feature Importance')
plt.ylabel('Feature')
plt.title('Decision Tree')
plt.tight_layout()
plt.show()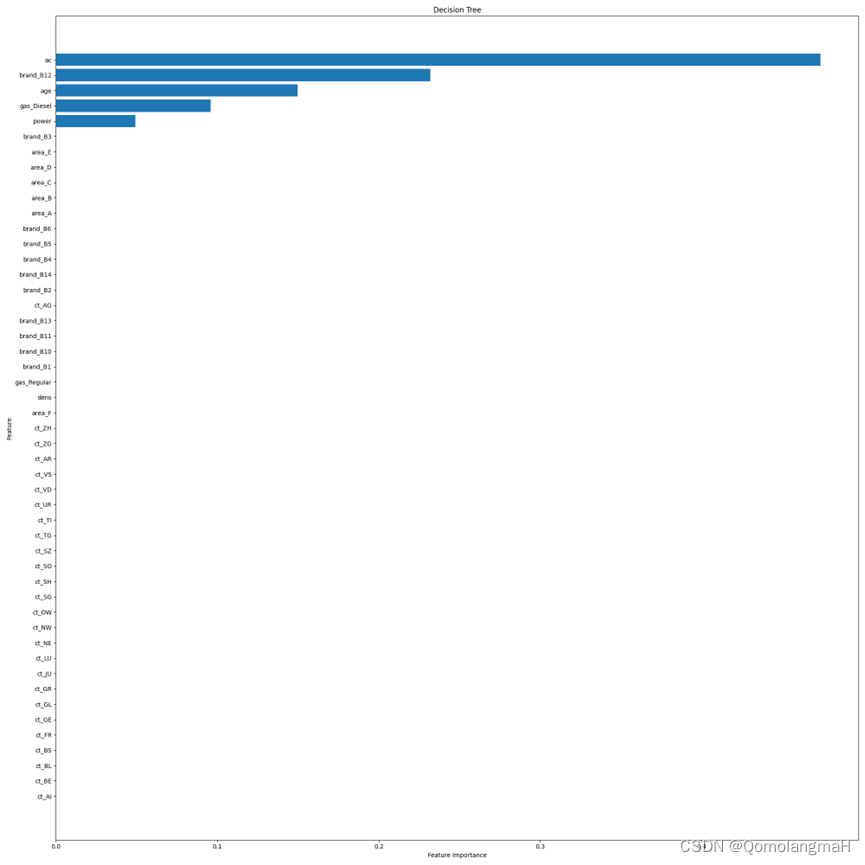
6. 修改样本、网格搜索参数进一步优化模型
详见实验报告
五、实验分析
请下载本实验对应的代码及实验报告资源(其中实验分析部分共2页、1162字)
相关文章:
《机器学习在车险定价中的应用》实验报告
目录 一、实验题目 机器学习在车险定价中的应用 二、实验设置 1. 操作系统: 2. IDE: 3. python: 4. 库: 三、实验内容 实验前的猜想: 四、实验结果 1. 数据预处理及数据划分 独热编码处理结果(以…...
14. Docker中实现CI和CD
目录 1、前言 2、什么是CI/CD 3、部署Jenkins 3.1、下载Jenkins 3.2、启动Jenkins 3.3、访问Jenkins页面 4、Jenkins部署一个应用 5、Jenkins实现Docker应用的持续集成和部署 5.1、创建Dockerfile 5.2、集成Jenkins和Docker 6、小结 1、前言 持续集成(CI/CD)是一种…...

【多思路解决喝汽水问题】1瓶汽水1元,2个空瓶可以换一瓶汽水,给20元,可以喝多少汽水
题目内容 喝汽水问题 喝汽水,1瓶汽水1元,2个空瓶可以换一瓶汽水,给20元,可以喝多少汽水(编程实现)。 题目分析 数学思路分析 根据给出的问题和引用内容,我们可以得出答案。 首先ÿ…...
)
P1591 阶乘数码(Java高精度)
题目描述 求 n ! n! n! 中某个数码出现的次数。 输入格式 第一行为 t ( t ≤ 10 ) t(t \leq 10) t(t≤10),表示数据组数。接下来 t t t 行,每行一个正整数 n ( n ≤ 1000 ) n(n \leq 1000) n(n≤1000) 和数码 a a a。 输出格式 对于每组数据&a…...

Mybatis的动态SQL及关键属性和标识的区别(对SQL更灵活的使用)
( 虽然文章中有大多文本内容,想了解更深需要耐心看完,必定大有受益 ) 目录 一、动态SQL ( 1 ) 是什么 ( 2 ) 作用 ( 3 ) 优点 ( 4 ) 特殊标签 ( 5 ) 演示 二、#和$的区别 2.1 #使用 ( 1 ) #占位符语法 ( 2 ) #优点 2.…...
mysql下载
网址 MySQL :: Download MySQL Community Serverhttps://dev.mysql.com/downloads/mysql/ 2、选择MSI进行安装 3、这里我选择离线安装 4、这里我选择直接下载 5、等待下载安装即可...

聚合函数与窗口函数
聚合函数 回答一 聚合函数(Aggregate Functions)是SQL中的函数,用于对一组数据进行计算,并返回单个结果。聚合函数通常用于统计和汇总数据,包括计算总和、平均值、计数、最大值和最小值等。 以下是一些常见的聚合函…...
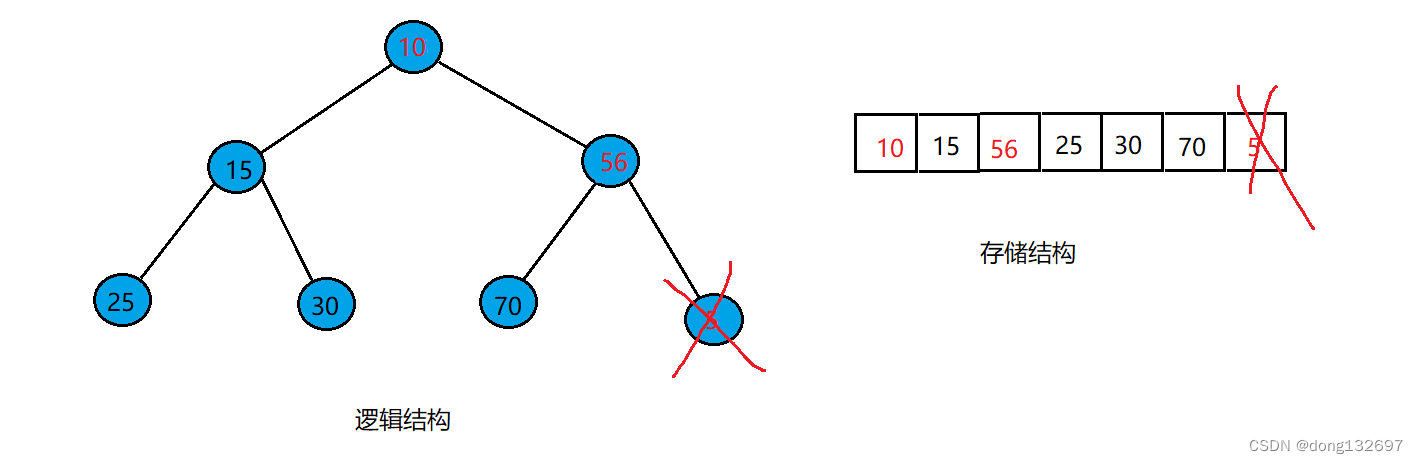
c语言实现堆
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、树1、树的概念2、树的相关概念3、树的表示 二、二叉树1、二叉树概念2、特殊的二叉树3、二叉树的性质4、二叉树的顺序结构5、二叉树的链式结构 三、堆(二叉树…...

ubuntu 如何将文件打包成tar.gz
要将文件打包成.tar.gz文件,可以使用以下命令: tar -czvf 文件名.tar.gz 文件路径 其中,-c表示创建新的归档文件,-z表示使用gzip进行压缩,-v表示显示详细的打包过程,-f表示指定归档文件的名称。 例如&am…...
)
前端优化页面加载速度的方法(持续更新)
提速方法方向 延迟脚本加载 使用 async 属性: 在这种方法中,脚本将在下载完成后立即执行,而不会阻塞其他页面资源的加载和渲染。这适用于那些不依赖于其他脚本和页面内容的脚本,例如分析脚本等。示例如下: html …...

利用SSL证书的SNI特性建立自己的爬虫ip服务器
今天我要和大家分享一个关于自建多域名HTTPS爬虫ip服务器的知识,让你的爬虫ip服务器更加强大!无论是用于数据抓取、反爬虫还是网络调试,自建一个支持多个域名的HTTPS爬虫ip服务器都是非常有价值的。本文将详细介绍如何利用SSL证书的SNI&#…...

HTML和CSS
HTML HTML(Hyper Text Markup Language):超文本语言 超文本:超越了文本的限制,比普通文本更强大。除了文字信息,还可以定义图片、音频、视频等内容。 标记语言:由标签构成的语言 HTML标签都是预定义好的。例如:使用&l…...

C#的IndexOf
在 C# 中,IndexOf 是一个字符串、数组或列表的方法,用于查找指定元素的第一个匹配项的索引。它返回一个整数值,表示匹配项在集合中的位置,如果未找到匹配项,则返回 -1。 IndexOf 方法有多个重载形式,可以根…...

深度学习2.神经网络、机器学习、人工智能
目录 深度学习、神经网络、机器学习、人工智能的关系 大白话解释深度学习 传统机器学习 VS 深度学习 深度学习的优缺点 4种典型的深度学习算法 卷积神经网络 – CNN 循环神经网络 – RNN 生成对抗网络 – GANs 深度强化学习 – RL 总结 深度学习 深度学习、神经网络…...

利用LLM模型微调的短课程;钉钉宣布开放智能化底座能力
🦉 AI新闻 🚀 钉钉宣布开放智能化底座能力AI PaaS,推动企业数智化转型发展 摘要:钉钉在生态大会上宣布开放智能化底座能力AI PaaS,与生态伙伴探寻企业服务的新发展道路。AI PaaS结合5G、云计算和人工智能技术的普及和…...
 UML之用例图详解)
软件工程(七) UML之用例图详解
1、UML-4+1视图 UML-4+1视图将会与后面的架构4+1视图会一一对应上 视图往往出现在什么场景:我们看待一个事物,我们觉得它很复杂,难以搞清楚,为了化繁为简,我们会从一个侧面去看,这就是视图。而4+1视图就是分不同角度去看事物。 逻辑视图(logical view) 一般使用类与对…...
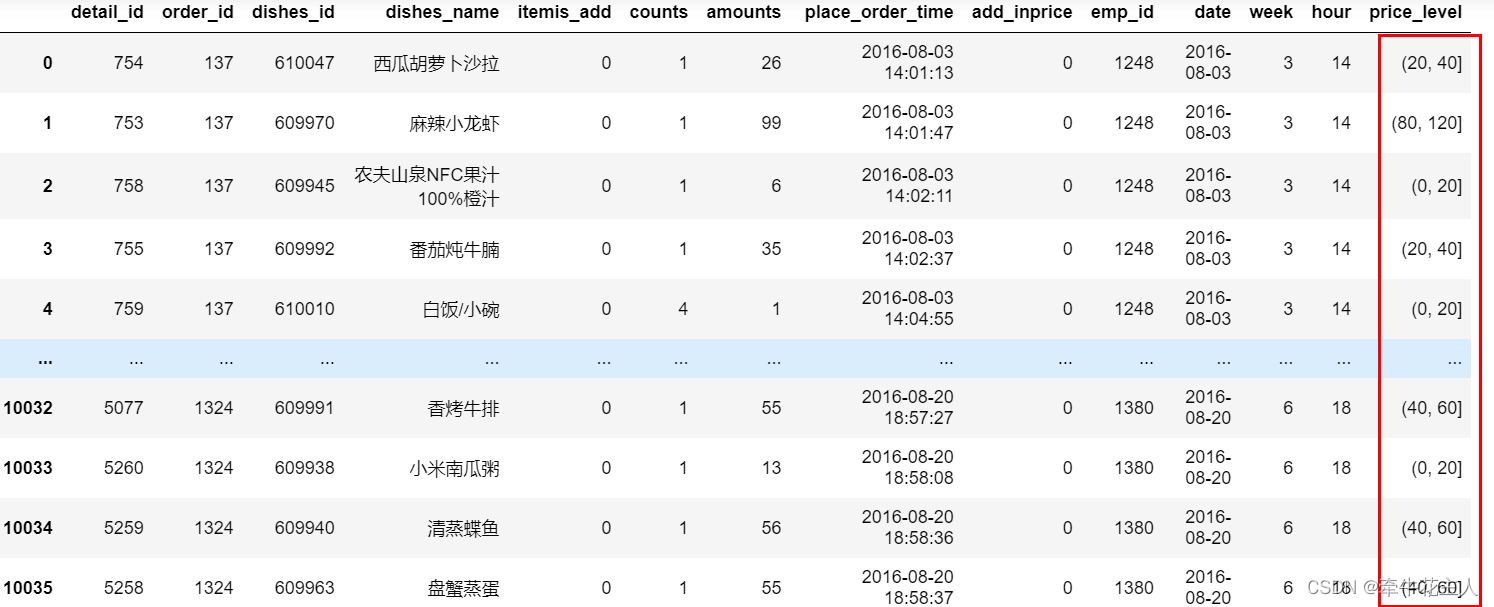
pd.cut()函数--Pandas
1. 函数功能 将连续性数值进行离散化处理:如对年龄、消费金额等进行分组 2. 函数语法 pandas.cut(x, bins, rightTrue, labelsNone, retbinsFalse, precision3, include_lowestFalse, duplicatesraise, orderedTrue)3. 函数参数 参数含义x要离散分箱操作的数组&…...

DataBinding的基本使用
目录 一、MVC、MVP和MVVM框架的使用场景二、Java使用 一、MVC、MVP和MVVM框架的使用场景 MVC: 适用于小型项目,够灵活, 缺点:Activity不仅要做View的事情还要做控制和模型的处理,导致Activity太过臃肿,管理…...
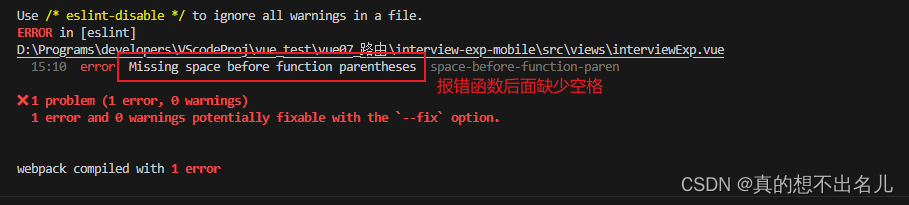
eslint和prettier格式化冲突
下载插件 ESLint 和 Prettier ESLint 进入setting.json中 setting.json中配置 {"editor.tabSize": 2,"editor.linkedEditing": true,"security.workspace.trust.untrustedFiles": "open","git.autofetch": true,"…...
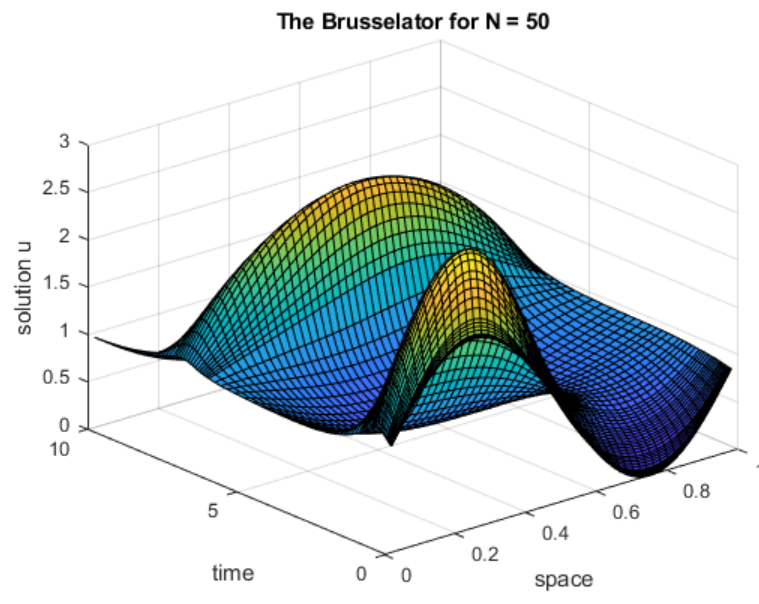
matlab使用教程(26)—常微分方程的求解
1.求解非刚性 ODE 本页包含两个使用 ode45 来求解非刚性常微分方程的示例。MATLAB 提供几个非刚性 ODE 求解器。 • ode45 • ode23 • ode78 • ode89 • ode113 对于大多数非刚性问题,ode45 的性能最佳。但对于允许较宽松的误差容限或刚度适中的问题&…...

嵌入式GUI设计:硬件选型与OpenGL优化实战
1. 嵌入式GUI设计的核心价值与市场驱动力在智能设备爆发的时代,嵌入式图形用户界面(GUI)已经从"锦上添花"变成了"不可或缺"的核心竞争力。我亲历过多个项目,那些仅关注硬件性能而忽视交互体验的产品ÿ…...

【ROS进阶-1】从零构建自定义消息:实战配置与编译全解析
1. 为什么需要自定义ROS消息 在ROS开发中,消息是节点间通信的基础载体。虽然ROS已经提供了丰富的标准消息类型,比如std_msgs、geometry_msgs等,但在实际项目中,我们经常会遇到标准消息无法满足需求的情况。就像在C编程中ÿ…...

AI编程工具全景指南:从CLI到智能体,构建高效开发工作流
1. 项目概述:一份为“氛围编码”时代量身定制的开发者地图如果你是一名开发者,最近几个月一定被“氛围编码”这个词刷屏了。从Cursor、Claude Code到各种AI原生IDE和代理工具,我们仿佛一夜之间进入了一个新的编程范式。但问题也随之而来&…...

【Oracle数据库指南】第03篇:Oracle SQL分组统计与排序——GROUP BY、HAVING与ORDER BY深度解析
上一篇【第02篇】Oracle SQL查询高级技巧——条件与函数 下一篇【第04篇】Oracle多表查询与连接操作——JOIN的全面解析 摘要 本文详细讲解Oracle SQL中的分组统计功能,包括分组函数(COUNT、SUM、AVG、MAX、MIN等)的用法、GROUP BY子句的多列…...

CANN/GE获取模型输出名称
aclmdlGetOutputNameByIndex 【免费下载链接】ge GE(Graph Engine)是面向昇腾的图编译器和执行器,提供了计算图优化、多流并行、内存复用和模型下沉等技术手段,加速模型执行效率,减少模型内存占用。 GE 提供对 PyTorch…...

AI API智能调度中继服务:多账号管理与高可用架构实践
1. 项目概述:一个高性能的AI API智能调度中转站如果你手头有多个Claude、Gemini或者OpenAI的账号,并且经常在不同的开发工具(比如Claude Code CLI、各种SDK)之间切换使用,那你肯定体会过那种管理上的繁琐。每次调用都得…...

TeamHero:基于规则引擎的智能任务自动化分配系统设计与实战
1. 项目概述与核心价值 最近在GitHub上看到一个挺有意思的项目,叫“TeamHero”,作者是sagiyaacoby。乍一看这个名字,你可能会联想到团队协作或者英雄联盟,但实际上,它是一个专注于自动化团队管理与任务分发的工具。简…...

奇点大会周边酒店技术适配白皮书:支持会议直播推流、多设备协同充电、边缘计算终端供电的5家硬核之选
更多请点击: https://intelliparadigm.com 第一章:奇点智能技术大会周边酒店推荐 核心推荐区域 奇点智能技术大会主会场位于上海张江科学城AI创新集聚区,建议优先选择地铁2号线(广兰路站)及13号线(中科路…...

5月中国AI独角兽融资热潮:DeepSeek领涨,月之暗面、阶跃星辰等估值重估!
5月中国AI产业一级市场热闹非凡这个5月,中国AI产业的一级市场热闹非凡。先是国产超级AI独角兽DeepSeek,正在推进成立以来的首次外部融资。最新消息显示,国家AI产业投资基金、腾讯等资方都已进入洽谈名单。一个月前,就有消息传出De…...

在自动化视频剪辑脚本中调用AI进行智能片段筛选与拼接
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在自动化视频剪辑脚本中调用AI进行智能片段筛选与拼接 自动化视频生产正成为内容创作者和运营团队提升效率的关键路径。面对海量的…...