从C语言到C++_34(C++11_下)可变参数+ lambda+function+bind+笔试题
目录
1. 可变参数模板
1.1 展开参数包
1.1.1 递归函数方式展开
1.1.2 逗号表达式展开
1.2 emplace相关接口
2. lambda表达式(匿名函数)
2.1 C++11之前函数的缺陷
2.2 lambda表达式语法
2.3 函数对象与lambda表达式
3. 包装器
3.1 function包装器
3.1.1 function包装器使用
3.1.2 function的场景(力扣150:逆波兰表达式求值)
3.2 bind绑定
4. 笔试选择题
答案及解析
本篇完。
1. 可变参数模板
C++11的新特性可变参数模板能够让您创建可以接受可变参数的函数模板和类模板,相比 C++98/03,类模版和函数模版中只能含固定数量的模版参数,可变模版参数无疑是一个巨大的改进。然而由于可变模版参数比较抽象,使用起来需要一定的技巧,所以这块还是比较晦涩的。现阶段我们掌握一些基础的可变参数模板特性就够我们用了,所以这里我们点到为止,以后如果有需要,再可以深入学习。
下面就是一个基本可变参数的函数模板
template <class ...Args>
void ShowList(Args... args)
{//.......
}
- 声明一个参数包Args...args,这个参数包中可以包含0到N(N>=0)个模板参数。
- Args:是一个模板参数包
- args:是一个函数形参参数包
上面的参数args前面有省略号,所以它就是一个可变模版参数,我们把带省略号的参数称为“参数包”,它里面包含了0到N(N>=0)个模版参数。我们无法直接获取参数包args中的每个参数的, 只能通过展开参数包的方式来获取参数包中的每个参数,这是使用可变模版参数的一个主要特点,也是最大的难点,即如何展开可变模版参数。由于语法不支持使用args[i]这样方式获取可变参数,所以我们的用一些奇招来一一获取参数包的值。
在使用可变参数模板的时候,可以传入任意个类型的数据,编译器会将所有类型打包。
可变参数模板的难点就是如果展开参数包,从而使用里面的每个模板参数。
1.1 展开参数包
1.1.1 递归函数方式展开
template <class T>// 递归终止函数
void ShowList(const T& t)
{cout << t << endl;
}template <class T, class ...Args>// 展开函数
void ShowList(T value, Args... args)
{cout << value << " ";ShowList(args...);
}int main()
{ShowList(1);ShowList(1, 'R');ShowList(1, 'R', std::string("left"));return 0;
}
调用同一个函数模板,传入不同个数的参数,函数模板都能将这些变化的参数打印出来。

如上图灵魂画手,这种方式很像递归,在函数模板中调用函数模板,通过模板参数中的第一个模板参数一个个从参数包中拿参数。不需要的形参的函数就相当于一个结束条件。
1.1.2 逗号表达式展开
template <class T>
void PrintArg(T t)
{cout << t << " ";
}template <class ...Args>//展开函数
void ShowList(Args... args)
{int arr[] = { (PrintArg(args), 0)... };cout << endl;
}int main()
{ShowList(1);ShowList(1, 'R');ShowList(1, 'R', std::string("left"));return 0;
}
同样将参数包挨个展开了。
- 逗号表达式的结果是最右边的值。
这种展开参数包的方式,不需要通过递归终止函数,是直接在ShowList函数体中展开的, PrintArg不是一个递归终止函数,只是一个处理参数包中每一个参数的函数。这种就地展开参数包的方式实现的关键是逗号表达式。我们知道逗号表达式会按顺序执行逗号前面的表达式。 ShowList函数中的逗号表达式:(PrintArg(args), 0),也是按照这个执行顺序,先执行 PrintArg(args),再得到逗号表达式的结果0。同时还用到了C++11的另外一个特性——初始化列表,通过初始化列表来初始化一个变长数组, {(PrintArg(args), 0)...}将会展开成((PrintArg(arg1),0), (PrintArg(arg2),0), (PrintArg(arg3),0), etc... ),最终会创建一个元素值都为0的数组int arr[sizeof(Args)]。由于是逗号表达式,在创建数组的过程中会先执行逗号表达式前面的部分PrintArg(args) 打印出参数,也就是说在构造int数组的过程中就将参数包展开了,这个数组的目的纯粹是为了在数组构造的过程展开参数包
逗号表达式简化的代码:
template <class T>
int PrintArg(T t)
{cout << t << " ";return 0;
}template <class ...Args>//展开函数
void ShowList(Args... args)
{int arr[] = { PrintArg(args)... };cout << endl;
}int main()
{ShowList(1);ShowList(1, 'R');ShowList(1, 'R', std::string("left"));return 0;
}
采用上图所示方式也可以展开参数包。
- 在ShowList中的数组中多次调用PrintArg函数,每次调用后返回值是0。
- 多个0形参的列表初始化数组。
这种方式中,看起来比逗号表达式好理解,数组同样仅起辅助作用。
1.2 emplace相关接口
C++11基于可变参数模板在STL中提供了emplace相关的接口:
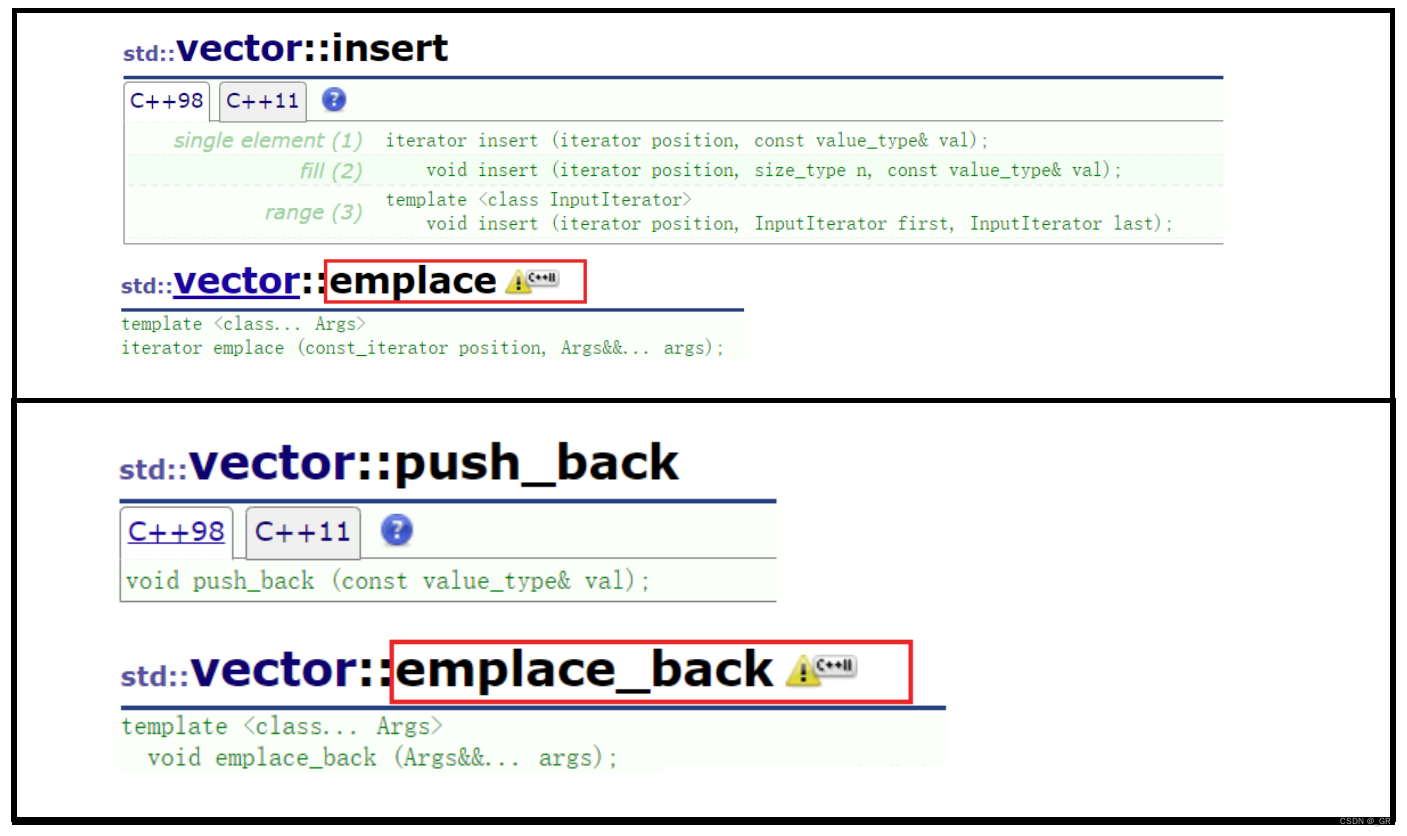
emplace的作用和insert类似,emplace_back的作用和push_back相似。
上图是以vector为例,其他STL容器也有emplace系列的相关接口。
emplace接口也是模板函数,它既是一个万能引用模板也是一个可变参数模板,可以称为万能引用可变参数模板。无论插入的数据是左值还是右值,无论是多少个,都可插入。
int main()
{list<int> mylist;mylist.push_back(10);mylist.push_back(20);mylist.emplace_back(30);mylist.emplace_back(40);//mylist.emplace_back(50, 60); //不能这样用for (const auto& e : mylist){cout << e << endl;}return 0;
}
- 对于内置类型,push_back和emplace_back没有任何区别。
- 而且也不可以一次性插入多个内置类型的值。
只有对容器实例化后,并且存放多个值时,才能使用empalce_back一次性插入:
int main()
{list<pair<int, char>> mylist;mylist.push_back({ 10, 'a' });mylist.emplace_back(20, 'b');mylist.push_back(make_pair(30, 'c'));mylist.emplace_back(make_pair(40, 'd'));mylist.emplace_back(50, 'e');for (const auto& e : mylist){cout << e.first << ":" << e.second << endl;}return 0;
}
emplace相关接口的优势:
将上篇文章C++11——新特性 | 右值引用 | 完美转发中的string复制过来,在用字符串的构造的构造函数中打印提示信息,使用push_back插入不同类型的值:
namespace rtx
{class string{public:string(const char* str = ""):_size(strlen(str)), _capacity(_size){_str = new char[_capacity + 1];strcpy(_str, str);cout << "string(const char* str = "") -- 构造函数" << endl;}void swap(string& s){::swap(_str, s._str);::swap(_size, s._size);::swap(_capacity, s._capacity);}string(const string& s) // 拷贝构造:_str(nullptr), _size(0), _capacity(0){cout << "string(const string& s) -- 拷贝构造(深拷贝)" << endl;string tmp(s._str);swap(tmp);}string(string&& s) // 移动构造:_str(nullptr), _size(0), _capacity(0){cout << "string(string&& s) -- 移动构造(资源转移)" << endl;swap(s);}string& operator=(const string& s) // 拷贝赋值{cout << "string& operator=(string s) -- 拷贝赋值(深拷贝)" << endl;string tmp(s);swap(tmp);return *this;}string& operator=(string&& s) // 移动赋值{cout << "string& operator=(string s) -- 移动赋值(资源移动)" << endl;swap(s);return *this;}~string(){delete[] _str;_str = nullptr;}void reserve(size_t n){if (n > _capacity){char* tmp = new char[n + 1];strcpy(tmp, _str);delete[] _str;_str = tmp;_capacity = n;}}void push_back(char ch){if (_size >= _capacity){size_t newcapacity = _capacity == 0 ? 4 : _capacity * 2;reserve(newcapacity);}_str[_size] = ch;++_size;_str[_size] = '\0';}protected:char* _str;size_t _size;size_t _capacity;};
}int main()
{std::list< std::pair<int, rtx::string> > mylist;mylist.emplace_back(10, "sort");mylist.emplace_back(make_pair(20, "sort"));cout << "#########################################" << endl;mylist.push_back(make_pair(30, "sort"));mylist.push_back({ 40, "sort" });return 0;
}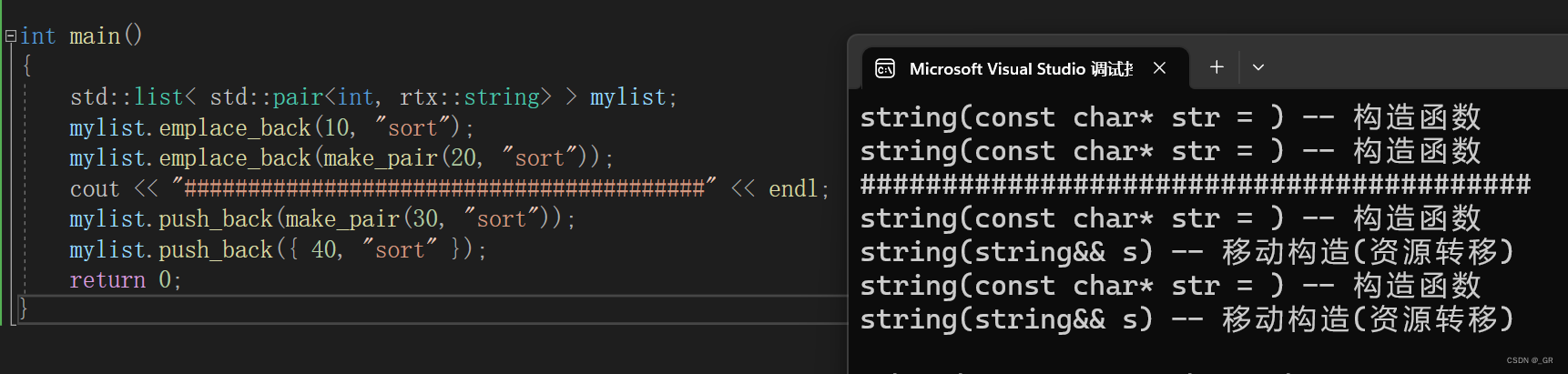
据此对比发现:
插入左值时,emplace_back和push_back没有区别。
因为左值无论是编译器还是emplace_back都是不敢进行优化的,只能老老实实进行深拷贝,以防影响到原本的左值。插入右值(匿名键值对)时,emplace_back仅调用了构造函数。
在插入的过程中,匿名对象一直存在,没有被转移资源,知道链表在new一个新节点的时候,才用右值对象中的数据来初始化节点,其中string调用的是普通构造函数,是用右值中的字符串来初始化的。插入多个值(可变参数)时,emplace_back仅调用了构造函数。
和插入右值一样,只有在new一个新节点的时候,多个插入的值才被用来初始化,所以也是只调用了普通构造函数。
- 只有在插入自定义类型的右值时,emplace_back的效率才比push_back高。
- emplace_back比push_back少调用了一个移动构造函数
我们知道,移动构造是将右值的资源进行转移,也是非常高效的,代价非常小。
emplace系列接口在存在移动构造的情况下,并不能比push_back高效很多,但还是高一点的。
如果没有移动构造:
使用emplace_back插入左值和右值。
- 对于左值,仍然需要深拷贝。
- 对于右值,则仅调用了构造函数,不用进行拷贝构造而发生深拷贝。
emplace_back相比于push_back少调用了拷贝构造,没有进行深拷贝,大大提高了效率,降低了系统开销。
对于不存在移动构造的情况下,emplace相关接口比push_back高效很多。
所以以后用push_back系列的时候都可以用emplace_back系列替代。(想到就行)
2. lambda表达式(匿名函数)
2.1 C++11之前函数的缺陷
在C++98中,如果想要对一个数据集合中的元素进行排序,可以使用std::sort方法。
#include <algorithm>
#include <functional>
int main()
{int arr[] = { 4,1,8,5,3,7,0,9,2,6 };// 默认按照小于比较,排出来结果是升序std::sort(arr, arr + sizeof(arr) / sizeof(arr[0]));// 如果需要降序,需要改变元素的比较规则std::sort(arr, arr + sizeof(arr) / sizeof(arr[0]), greater<int>());return 0;
}如果待排序元素为自定义类型,需要用户定义排序时的比较规则:
struct Goods
{string _name; // 名字double _price; // 价格int _evaluate; // 评价Goods(const char* str, double price, int evaluate):_name(str), _price(price), _evaluate(evaluate){}
};
struct ComparePriceLess
{bool operator()(const Goods& gl, const Goods& gr){return gl._price < gr._price;}
};
struct ComparePriceGreater
{bool operator()(const Goods& gl, const Goods& gr){return gl._price > gr._price;}
};
int main()
{vector<Goods> v = { { "苹果", 2.1, 5 }, { "香蕉", 3, 7 }, { "西瓜", 5.5,3 }, { "橘子", 7.7, 4 } };sort(v.begin(), v.end(), ComparePriceLess());sort(v.begin(), v.end(), ComparePriceGreater());
}随着C++语法的发展,人们开始觉得上面的写法太复杂了,每次为了实现一个algorithm算法, 都要重新去写一个类,如果每次比较的逻辑不一样,还要去实现多个类,特别是相同类的命名,可能导致命名不规范, 这些都给编程者带来了极大的不便。因此,在C++11语法中出现了Lambda表达式。
2.2 lambda表达式语法
lambda表达式书写格式:
[capture-list] (parameters) mutable -> return-type { statement }
即:
[捕捉列表](参数列表)mutable->(返回值类型){函数体}
[捕捉列表]
捕捉列表是编译器判断lambda表达式的依据,所以必须写[],[]内可以有参数,后面详细讲解。
(参数列表)
参数列表和普通函数的参数列表一样,如果不需要参数传递,可以连同()一起省略。
mutable
默认情况下,lambda表达式的形参都是const类型,形参不可以被修改,使用mutable可以取消形参的常量属性。使用mutable时,参数列表不可以省略(即使参数为空)。一般情况下mutable都是省略的。
->返回值类型
->和返回值类型是一体的,如->int表示lambda的返回值是int类型。一般情况下省略->返回值类型,因为编译器可以根据函数体中的return推导出返回值类型。为了提高程序的可读性可以写上。
{函数体}
和普通函数一样,{ }里的是lambda的具体实现逻辑。
注意:
- 在lambda函数定义中,参数列表和返回值类型都是可选部分,可写可不写。
- 而捕捉列表和函数体必须写,但是内容可以为空。
- 因此C++11中最简单的lambda函数为:[ ]{ }; 该lambda函数不能做任何事情。
写两个简单的lambda:
int main()
{// 两个数相加的lambdaauto add1 = [](int a, int b)->int {return a + b;};auto add2 = [](int a, int b) {return a + b;};cout << add1(1, 6) << endl;cout << add2(1, 6) << endl;return 0;
}
C++11之前函数的缺陷例子用lambda表达式解决:
struct Goods
{string _name; // 名字double _price; // 价格int _evaluate; // 评价Goods(const char* str, double price, int evaluate):_name(str), _price(price), _evaluate(evaluate){}
};
int main()
{vector<Goods> v = { { "苹果", 2.1, 5 }, { "香蕉", 3, 7 }, { "西瓜", 5.5,3 }, { "橘子", 7.7, 4 } };sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2) {return g1._price < g2._price; });sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2) {return g1._price > g2._price; });sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2) {return g1._evaluate < g2._evaluate; });sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2) {return g1._evaluate > g2._evaluate; });return 0;
}交换变量的lambda:
int main()
{// 交换变量的lambdaint x = 0, y = 7;auto swap1 = [](int& x1, int& x2)->void{int tmp = x1; x1 = x2; x2 = tmp; };swap1(x, y);cout << x << "-------" << y << endl;auto swap2 = [](int& x1, int& x2){int tmp = x1;x1 = x2;x2 = tmp;};swap2(x, y);cout << x << "-------" << y << endl;return 0;
}
能不能不传参数交换x和y呢?用上捕捉列表就行:
int main()
{// 交换变量的lambdaint x = 0, y = 7;auto swap1 = [](int& x1, int& x2)->void{int tmp = x1; x1 = x2; x2 = tmp; };swap1(x, y);cout << x << "-------" << y << endl;auto swap2 = [](int& x1, int& x2){int tmp = x1;x1 = x2;x2 = tmp;};swap2(x, y);cout << x << "-------" << y << endl;auto swap3 = [x, y](int& x1, int& x2){int tmp = x1;x1 = x2;x2 = tmp;};swap3(x, y);cout << x << "-------" << y << endl;swap3(x, y);cout << x << "-------" << y << endl;return 0;
}
捕获列表说明:
捕捉列表描述了上下文中那些数据可以被lambda使用,以及使用的方式传值还是传引用。
- [var]:表示值传递方式捕捉变量var
- [=]:表示值传递方式捕获所有父作用域中的变量(包括this)
- [&var]:表示引用传递捕捉变量var,捕捉,不是传参,捕捉中就不存在取地址这一语法。
- [&]:表示引用传递捕捉所有父作用域中的变量(包括this)
注意:
① 父作用域指包含lambda函数的语句块。
② 语法上捕捉列表可由多个捕捉项组成,并以逗号分割。比如:[=, &a, &b]:以引用传递的方式捕捉变量a和b,值传递方式捕捉其他所有变量 [&,a, this]:值传递方式捕捉变量a和this,引用方式捕捉其他变量。
③ 捕捉列表不允许变量重复传递,否则就会导致编译错误。 比如:[=, a]:=已经以值传递方式捕捉了所有变量,捕捉a重复。
④ 在块作用域以外的lambda函数捕捉列表必须为空。
⑤ 在块作用域中的lambda函数仅能捕捉父作用域中局部变量,捕捉任何非此作用域或者非局部变量都会导致编译报错。
⑥ lambda表达式之间不能相互赋值,即使看起来类型相同。

简单使用:
int main()
{int a, b, c, d, e;a = b = c = d = e = 1;auto f1 = [=]() // 全部传值捕捉{cout << a << b << c << d << e << endl;};f1();auto f2 = [=, &a]() // 混合捕捉{a++;cout << a << b << c << d << e << endl;};f2();return 0;
}
2.3 函数对象与lambda表达式
函数对象,又称为仿函数,即可以像函数一样使用的对象,就是在类中重载了operator()运算符的类对象。
class Rate
{
public:Rate(double rate) : _rate(rate){}double operator()(double money, int year){return money * year * _rate;}
private:double _rate;
};int main()
{// 函数对象double rate = 0.5;Rate r1(rate);cout << r1(518, 3) << endl;// lamberauto r2 = [=](double money, int year)->double {return money * year * rate;};cout << r2(518, 3) << endl;return 0;
}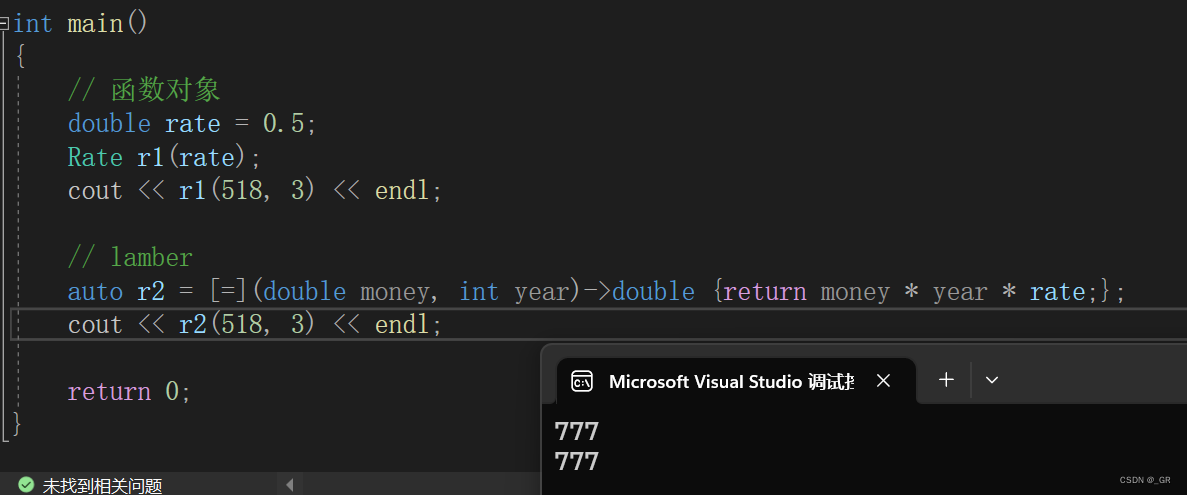
使用函数对象和lambda两种方式进行利率计算,执行的函数体内容相同。
- 从使用方式上来看,函数对象和lambda表达式完全一样,如中r1和r2所示。
- rate是函数对象的成员变量,通过构造函数初始化,lambda通过捕获列表来捕获该变量。

调试起来后,查看汇编代码,如上图所示是调用函数对象部分的汇编代码。
- 创建函数对象时,调用了Rate类域中的构造函数。
- 调用函数对象时,调用了Rate类域中的operator()成员函数。

上图所示是lambda表达式部分的汇编代码。
创建lambda表达式时,也是调用了某个类中的构造函数。
该类不像函数对象那样明确,而是有很长一串,如上图所示的lambda_0d841c589991fabbf3e571d463f613ab。
调用lambda表达式时,调用的是该类中的operator()成员函数。
函数对象和lambda在汇编代码上是一样的,只是类不同而已。函数对象的类名是我们自己定义的。
- lambda的类名是编译器自己生成的。
编译器在遇到lambda表达式的时候,会执行一个算法,生成长串数字,而且几乎每次生成的数字都不同,也就意味着每次创建的类名都不同。
lambda表达式的类型只有编译器自己知道,用户是无法知道的。
所以要通过auto来推演它的类型,才能接收这个匿名的函数对象。
lambda表达式和函数对象其实是一回事,只是lambda表达式的类是由编译器自动生成的。
此时应该就理解了为什么说lambda其实就是一个匿名的函数对象了吧。
所以:lambda表达式相互不可以赋值,因为编译器生成的类不一样,也就意味着不是一个类型。
3. 包装器
3.1 function包装器
function包装器:也叫作适配器。
C++中的function本质是一个类模板,也是一个包装器。
我们为什么需要function呢?:
ret = func(x);
上面func可能是什么呢?那么func可能是函数名?函数指针?函数对象(仿函数对象)?也有可能
是lamber表达式对象?所以这些都是可调用的类型,如此丰富的类型,可能会导致模板的效率低下。为什么呢?往下看:
template<class F, class T>
T useF(F f, T x)
{static int count = 0;cout << "count:" << ++count << endl;cout << "count:" << &count << endl;return f(x);
}
double f(double i)
{return i / 2;
}
struct Functor
{double operator()(double d){return d / 3;}
};
int main()
{// 函数名cout << useF(f, 11.11) << endl;// 函数对象cout << useF(Functor(), 11.11) << endl;// lamber表达式对象cout << useF([](double d)->double { return d / 4; }, 11.11) << endl;return 0;
}
通过上面的程序验证,我们会发现useF函数模板实例化了三份。
3.1.1 function包装器使用
包装器可以很好的解决上面的问题:
std::function在头文件<functional>
类模板原型如下
template <class T> function; // undefinedtemplate <class Ret, class... Args>
class function<Ret(Args...)>;
模板参数说明:
Ret: 被调用函数的返回类型
Args…:被调用函数的形参
function包装器使用:
int f(int a, int b)
{return a + b;
}
struct Functor
{
public:int operator() (int a, int b){return a + b;}
};
class Plus
{
public:static int plusi(int a, int b){return a + b;}double plusd(double a, double b){return a + b;}
};
int main()
{std::function<int(int, int)> func1 = f; // 函数名(函数指针)cout << func1(1, 2) << endl;std::function<int(int, int)> func2 = Functor(); // 函数对象cout << func2(1, 2) << endl;std::function<int(int, int)> func3 = [](const int a, const int b){return a + b; }; // lamber表达式cout << func3(1, 2) << endl;std::function<int(int, int)> func4 = &Plus::plusi; // 类的静态成员函数cout << func4(1, 2) << endl;std::function<double(Plus, double, double)> func5 = &Plus::plusd;cout << func5(Plus(), 1.1, 2.2) << endl; // 类的成员函数需要用对象调用return 0;
}
function包装器解决模板的效率低下问题:
template<class F, class T>
T useF(F f, T x)
{static int count = 0;cout << "count:" << ++count << endl;cout << "count:" << &count << endl;return f(x);
}
double f(double i)
{return i / 2;
}
struct Functor
{double operator()(double d){return d / 3;}
};
int main()
{// 函数名function<double(double)> f1 = f;cout << useF(f1, 11.11) << endl;// 函数对象function<double(double)> f2 = Functor();cout << useF(f2, 11.11) << endl;// lamber表达式对象function<double(double)> f3 = [](double d)->double { return d / 4; };cout << useF(f3, 11.11) << endl;return 0;
}
useF函数模板只实例化了一份。
3.1.2 function的场景(力扣150:逆波兰表达式求值)
包装器的其他一些场景,以前写过的题目:
150. 逆波兰表达式求值 - 力扣(LeetCode)
给你一个字符串数组 tokens ,表示一个根据 逆波兰表示法 表示的算术表达式。
请你计算该表达式。返回一个表示表达式值的整数。
注意:
- 有效的算符为
'+'、'-'、'*'和'/'。 - 每个操作数(运算对象)都可以是一个整数或者另一个表达式。
- 两个整数之间的除法总是 向零截断 。
- 表达式中不含除零运算。
- 输入是一个根据逆波兰表示法表示的算术表达式。
- 答案及所有中间计算结果可以用 32 位 整数表示。
以前的思路和代码:逆波兰表达式严格遵循「从左到右」的运算。计算逆波兰表达式的值时,使用一个栈存储操作数,从左到右遍历逆波兰表达式,进行如下操作:
如果遇到操作数,则将操作数入栈;
如果遇到运算符,则将两个操作数出栈,其中先出栈的是右操作数,
后出栈的是左操作数,使用运算符对两个操作数进行运算,将运算得到的新操作数入栈。
整个逆波兰表达式遍历完毕之后,栈内只有一个元素,该元素即为逆波兰表达式的值。
简单来说就是:① 操作数入栈 ② 遇到操作符就取栈顶两个操作数运算
//1 操作数入栈
//2 遇到操作符就取栈顶两个操作数运算
class Solution {
public:int evalRPN(vector<string>& tokens) {stack<int> st;for(auto& e: tokens){if(e == "+" || e == "-" || e == "*" || e == "/"){int right = st.top();//右操作数先出栈st.pop();int left = st.top();st.pop();switch(e[0]){case '+':st.push(left + right);break;case '-':st.push(left - right);break;case '*':st.push(left * right);break;case '/':st.push(left / right);break;}}else{st.push(stoi(e));}}return st.top();}
};用了lambda表达式和function包装器的代码:(测试改了,用long long)
class Solution {
public:int evalRPN(vector<string>& tokens) {stack<long long> st;map<string, function<long long(long long, long long)>> opFuncMap ={{"+", [](long long a, long long b) {return a + b;}},{"-", [](long long a, long long b) {return a - b;}},{"*", [](long long a, long long b) {return a * b;}},{"/", [](long long a, long long b) {return a / b;}},};for (auto& str : tokens){if (opFuncMap.count(str)) // 操作符{int right = st.top();//右操作数先出栈st.pop();int left = st.top();st.pop();st.push(opFuncMap[str](left, right));}else // 操作数{st.push(stoll(str));}}return st.top();}
};3.2 bind绑定
学了包装器,如果出现以下这种场景怎么办?
int Plus(int a, int b)
{return a + b;
}
class Sub
{
public:int sub(int a, int b){return a - b;}
};
int main()
{//function<int(int, int)> funcPlus = Plus;//function<int(Sub, int, int)> funcSub = &Sub::sub; // 类内函数要传类,多一个参数map<string, function<int(int, int)>> opFuncMap ={{ "+", Plus},{ "-", &Sub::sub}};return 0;
}这时包装器“包不了了”,类内函数要传类,多一个参数,此时bind就来了:

- bind:也叫做绑定,是一个函数模板,返回一个function,它就像一个函数包装器(适配器),接受一个可调用对象,生成一个新的可调用对象来“适应”原对象的参数列表。
这是一个万能引用模板,除了可调用对象模板参数外,其他参数是可变参数,也就是一个参数包。
int Plus(int a, int b)
{return a + b;
}
class Sub
{
public:int sub(int a, int b){return a - b;}
};
using namespace placeholders; // _1, _2 要加命名空间
int main()
{//function<int(int, int)> funcPlus = Plus;//function<int(Sub, int, int)> funcSub = &Sub::sub; // 类内函数要传类,多一个参数//map<string, function<int(int, int)>> opFuncMap =//{// { "+", Plus},// { "-", &Sub::sub}//};//function<int(int, int)> funcPlus = Plus;//function<int(int, int)> funcSub = bind(&Sub::sub, Sub(), _1, _2);map<string, function<int(int, int)>> opFuncMap ={{ "+", Plus},{ "-", bind(&Sub::sub, Sub(), _1, _2)}};return 0;
}这里用bind绑定了第一个参数(固定住了),成功运行。
还有调整顺序的功能:
int Sub(int a, int b)
{return a - b;
}
using namespace placeholders; // _1, _2 要加命名空间
int main()
{int x = 2, y = 9;cout << Sub(x, y) << endl;//_1 _2.... 定义在placeholders命名空间中,代表绑定函数对象的形参,//_1,_2...分别代表第一个形参、第二个形参...//function<int(int, int)> bindFunc1 = bind(Sub, _1, _2); // 没换顺序//function<int(int, int)> bindFunc2 = bind(Sub, _2, _1); // 换顺序了auto bindFunc1 = bind(Sub, _1, _2); // 没换顺序auto bindFunc2 = bind(Sub, _2, _1); // 换顺序了cout << bindFunc1(x, y) << endl;cout << bindFunc2(x, y) << endl;return 0;
}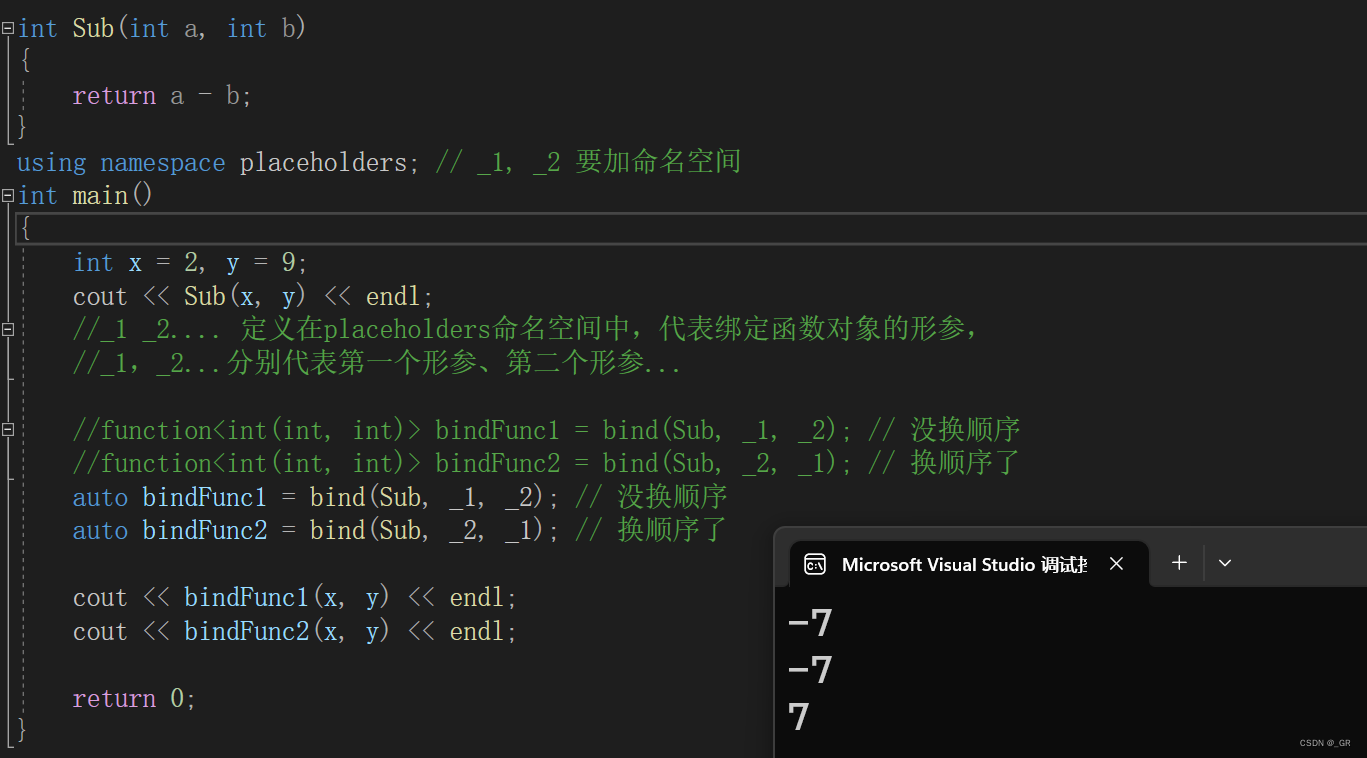
调整顺序的功能比较鸡肋,很少用,除非特殊场景,bind用来占位比较常用。
4. 笔试选择题
1. 下面关于范围for说法错误的是
A.范围for可以直接应用在数组上
B.对于STL提供的所有容器,均可以使用for依次访问器元素
C.使用范围for操作stack,可以简化代码
D.对于自定义类型,想要支持范围for,必须提供begin和end迭代器
E.范围for编译器最终是将其转化为迭代器来进行处理的
2. 下面关于列表初始化说法错误的是
A.在C++98中,{}只能用来初始化数组
B.在C++98中,new单个int类型空间可以直接初始化,new一段连续int类型空间不能直接初始化
C.在C++11中,{}的初始化范围增大了,任意类型都可以初始化
D.使用{}初始化时,必须要加=号
3. 下面关于auto的说法错误的是
A.auto主要用于类型推导,可以让代码的书写更简洁
B.在C++11中,auto即可以用来声明自动类型变量,也可以用来进行变量类型推导
C.auto不能推导函数参数的类型
D.auto是占位符,在编译阶段,推演出初始化表达式的实际类型来替换auto位置
4. 下列关于final说法正确的是()
A.final只能修饰类,表示该类不能被继承
B.final可以修饰任意成员函数
C.final修饰成员函数时,表示该函数不能被子类继承
D.final修饰派生类虚函数时,表示该虚函数再不能被其子类重写
5. 下面关于override说法正确的是()
A.override的作用发生在运行时期
B.override修饰子类成员函数时,编译时编译器会自动检测是否对基类中那个成员函数进行重写
C.override可以修饰基类的虚函数
D.override只能修饰子类的虚函数
6. 下面关于默认的构造函数说法正确的是()
A.C++98中用户可以选择让编译器生成或者不生成构造函数
B.在C++11中,即使用户定义了带参的构造函数,也可以通过default让编译器生成默认的构造函数
C.delete的作用是删除new的资源,别无它用
D.以下代码会编译通过: class A { public: A(){} A(int)=delete; }
7. 下面关于lambda表达式说法错误的是()
A.lambda表达式的捕获列表不能省略,但可以使空
B.lambda表达式就是定义了一个函数
C.lambda表达式底层编译器是将其转化为仿函数进行处理的
D.[]{}是一个lambda表达式
8. 关于右值引用说法正确的是()
A.引用是别名,使用比指针更方便安全,右值引用有点鸡肋
B.右值引用不能引用左值
C.右值引用只能引用右值
D.右值引用于引用一样,都是别名
9. 关于引用和右值引用的区别,说法正确的是()
A.引用只能引用左值,不能引用右值
B.右值引用只能引用右值,不能引用左值
C.引用和右值引用都可以引用左值和右值
D.以上说法都不对
10. 下面关于右值引用作用说法错误的是()
A.右值引用于引用一样,只是一个别名,别无它用
B.通过右值引用可以实现完美转发
C.通过右值引用可以将临时对象中的资源转移出去
D.通过右值引用可以实现移动构造函数,提高程序运行效率
11. 下面关于列表初始化说法正确的是()
A.C++语言从C++98开始,就支持列表方式的初始化
B.列表初始化没有什么实际作用,直接调用对应的构造函数就可以了
C.自定义类型可以支持多个对象初始化,只需要增加initializer_list类型的构造函数即可
D.以下关于c和d的初始化,结果完全相同 // short c = 65535; short d { 65535 };
答案及解析
1. C
A:正确,只要是范围确定的,都可以直接使用范围for
B:正确,对于STL提供的容器,采用范围for来进行遍历时,编译器最后还是将范围for转化为迭代 器来访问元素的
C:错误,stack不需要遍历,也没有提供迭代器,因此不能使用范围for遍历
D:正确,因为范围for最终被编译器转化为迭代器来遍历的
E:正确
2. D
A:正确,C++98中只能初始化数组,C++11中支持列表初始化,才可以初始化容器
B:正确,C++11对于new[]申请的空间,可以直接初始化
C:正确,对于自定义类型,需要提供initializer_list<T>类型的构造函数
D:错误,加=和不加=没有区别
3. B
A:正确
B:错误,C++11中已经去除了auto声明自动类型变量的功能,只可以用来进行变量类型推到
C:正确,因为函数在编译时,还没有传递参数,因此在编译时无法推演出形参的实际类型
D:正确,auto仅仅只是占位符,编译阶段编译器根据初始化表达式推演出实际类型之后会替换auto
4. D
A:正确
B:错误,C++11中已经去除了auto声明自动类型变量的功能,只可以用来进行变量类型推到
C:正确,因为函数在编译时,还没有传递参数,因此在编译时无法推演出形参的实际类型
D:正确,auto仅仅只是占位符,编译阶段编译器根据初始化表达式推演出实际类型之后会替换auto
5. D
A:override的作用时让编译器帮助用户检测是否派生类是否对基类总的某个虚函数进行重写,如 果重写成功,编译 通过,否则,编译失败,因此其作用发生在编译时。
B:错误,修饰子类虚函数时,编译时编译器会自动检测是否对基类中那个成员函数进行重写
C:错误,不能,因为override主要是检测是否重写成功的,而基类的虚函数不可能再去重写那个 类的虚函数
D:正确
6. B
A:错误,C++98中用户不能选择,用户如果没有定义构造函数,编译器会生成默认的,如果显式定义,编译器将不再生成
B:正确,C++11扩展了delete和default的用法,可以用来控制默认成员函数的生成与不生成
C:错误,C++11扩展了delete的用法,可以让用户控制让编译器不生成默认的成员函数
D:错误,类定义结束后没有分号
7. B
A:正确,捕获列表是编译器判断表达式是否为lambda的依据,即使为空,也不能省略
B:错误,lambda表达式不是一个函数,在底层编译器将其转化为仿函数
C:正确
D:正确,lambda表达式原型:[捕获列表](参数列表)mutable->返回值类型{} ,如果不需要捕获父作用域中内容时,可以为空,但是[]不能省略,如果没有参数,参数列表可以省略,如果不需要改变捕获到父作用域中内容时,mutable可以省略,返回值类型也可以省略,让编译器根据返回的结果进行推演,但是{}不能省略,因此[]{}是最简单的lambda表达式,但是该lambda表达式没有任何意义
8. D
A:错误,右值引用是C++11中的一个重点,可以实现移动语义、完美转发。
B:错误,一般右值引用只能引用右值,如果需要引用左值时,可以通过move函数转。
C:错误,同上。
D:正确,右值引用也是引用,是别名。
9. C
A:错误,T&只能引用左值,const T&是万能引用,左值和右值都可以引用。
B:错误,一般右值引用只能引用右值,如果需要引用左值时,可以通过move函数转。
C:正确,参考A和B的解析。
D:错误。
10. A
A:错误,右值引用是C++11中的一个重点,可以实现移动语义、完美转发
B:正确,实现完美转发时,需要用到forward函数
C:正确,右值引用的一个主要作用就是实现移动语义,以提高程序的效率
D:正确
11. C
A:错误,列表初始化是从C++11才开始支持的
B:错误,列表初始化可以在定义变量时就直接给出初始化,非常方便
C:正确
D:错误,不同,列表初始化在初始化时,如果出现类型截断,是会报警告或者错误的
本篇完。
下一篇:C++异常的使用+异常体系+优缺点。
相关文章:
从C语言到C++_34(C++11_下)可变参数+ lambda+function+bind+笔试题
目录 1. 可变参数模板 1.1 展开参数包 1.1.1 递归函数方式展开 1.1.2 逗号表达式展开 1.2 emplace相关接口 2. lambda表达式(匿名函数) 2.1 C11之前函数的缺陷 2.2 lambda表达式语法 2.3 函数对象与lambda表达式 3. 包装器 3.1 function包装器…...

喜报|星瑞格荣获“2022-2023年度国产数据库应用优秀解决方案”奖项
近日,赛迪网为表彰数字赛道上的先行者,联合《数字经济》杂志社和北京科创互联,共同组织以“树立行业标杆,引领服务创新”为中心的“2022-2023年度产业数字服务案例及创新成果征集活动”。该活动旨在鼓励各行业数字化应用技术创新树…...

【Spring Cloud系列】- 分布式系统中实现幂等性的几种方式
【Spring Cloud系列】- 分布式系统中实现幂等性的几种方式 文章目录 【Spring Cloud系列】- 分布式系统中实现幂等性的几种方式一、概述二、什么是幂等性三、幂等性需关注几个重点四、幂等性有什么用五、常见用来保证幂等的手段5.1 MVCC方案5.2 去重表5.3 去重表5.4 select in…...
2023.8.26-2023.9.3 周报【3D+GAN+Diffusion基础知识+训练测试】
目录 学习目标 学习内容 学习时间 学习产出 学习目标 1. 3D方向的基础知识 2. 图像生成的基础知识(GAN \ Diffusion) 3. 训练测试GAN和Diffusion 学习内容 1. 斯坦福cv课程-3D (网课含PPT) 2. sjtu生成模型课件 3. ge…...

如何使用CSS创建渐变阴影?
随着网络的不断发展,制作漂亮的 UI 是提高客户在网站上的参与度的最重要的工作之一。改善前端外观的方法之一是在 CSS 中应用渐变阴影。应用渐变阴影的两种最重要的方法是线性渐变和径向渐变。 渐变阴影可用于吸引用户对特定信息的注意力,应用悬停或焦点…...

perl send HTTP Request
perl send HTTP Request 使用Perl进行发送HttP请求 use LWP::UserAgent; use HTTP::Request; use HTTP::Headers; use JSON::PP;my $test_url "htttp://127.0.0.1:8080/update/";sub sendHttp{my $user_agent LWP::UserAgent->new(timeout>60);my ($url, $…...
阿里云CDN缓存预热与刷新以及常见的故障汇总
文章目录 1.为CDN缓存的文件增加过期时间2.CDN缓存预热配置3.CDN缓存刷新配置4.常见故障 CDN缓存预热指的是主动将要缓存的文件推送到全国各地的CDN边缘加速器上,减少回源率,提供命中率。 缓存刷新指的是后期上传了同名的文件,之前的缓存已经…...
Oracle创建控制列表ACL(Access Control List)
Oracle创建控制列表ACL(Access Control List) Oracle ACL简介一、先登陆163邮箱设置开启SMTP。二、Oracle ACL控制列表处理(一)创建ACL(create_acl)(二)添加ACL权限(add_…...

3D模型转换工具HOOPS Exchange助力打造虚拟现实应用程序
挑战: 支持使用各种 CAD 系统和 CAD 文件格式的客户群向可视化硬件提供快速、准确的数据加载提供对详细模型信息的访问,同时确保高帧率性能 解决方案: HOOPS Exchange领先的CAD数据转换工具包 结果: 确保支持来自领先工程软件…...
python web GUI框架-NiceGUI 教程(二)
python web GUI框架-NiceGUI 教程(二) streamlit可以在一些简单的场景下仍然推荐使用,但是streamlit实在不灵活,受限于它的核心机制,NiceGUI是一个灵活的web框架,可以做web网站也可以打包成独立的exe。 基…...

RT_Thread内核机制学习(二)
对于RTT来说,每个线程创建时都自带一个定时器 rt_err_t rt_thread_sleep(rt_tick_t tick) {register rt_base_t temp;struct rt_thread *thread;/* set to current thread */thread rt_thread_self();RT_ASSERT(thread ! RT_NULL);RT_ASSERT(rt_object_get_type(…...
线性代数的学习和整理12: 矩阵与行列式,计算上的差别对比
目录 1 行列式和矩阵的比较 2 简单总结矩阵与行列式的不同 3 加减乘除的不同 3.1 加法不同 3.2 减法不同 3.3 标量乘法/数乘 3.3.1 标准的数乘对比 3.3.2 数乘的扩展 3.4 乘法 4 初等线性变换的不同 4.1 对矩阵进行线性变换 4.2 对行列式进行线性变换 1 行列式和…...

2023年MySQL核心技术面试第一篇
目录 一 . 存储:一个完整的数据存储过程是怎样的? 1.1 数据存储过程 1.1.1 创建MySQl 数据库 1.1.1.1 为什么我们要先创建一个数据库,而不是直接创建数据表? 1.1.1.2基本操作部分 1.2 选择索引问题 二 . 字段:这么多的…...

linux启动jar 缺失lib
linux启动jar包时,找不到报错 [rootebs-141185 xl-admin]# java -Djava.library.path/home/kabangke/xl-admin/lib -jar /home/kabangke/xl-admin/xl-admin.jar Exception in thread "main" java.lang.NoClassDefFoundError: org/springframework/web/se…...

【Bash】常用命令总结
文章目录 1. 文件查询1.1 查看文件夹内(包含子文件夹)文件数量1.2 查看文件夹大小 任务简介: 对bash常用命令进行总结。 任务说明: 对平时工作中使用bash的相关命令做一个记录和说明,方便以后查阅。 1. 文件查询 1.…...
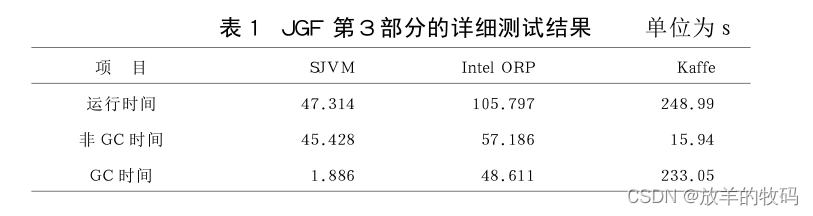
小研究 - Java虚拟机性能及关键技术分析
利用specJVM98和Java Grande Forum Benchmark suite Benchmark集合对SJVM、IntelORP,Kaffe3种Java虚拟机进行系统测试。在对测试结果进行系统分析的基础上,比较了不同JVM实现对性能的影响和JVM中关键模块对JVM性能的影响,并提出了提高JVM性能的一些展望。…...

Repo manifests默认default.xml清单文件中的各个标签详解
Repo简介 “Repo” 是一个用于管理多个Git存储库的工具,通常与Google的Android开发项目一起使用。它允许您在一个命令下轻松地进行多个Git存储库的同步、下载和管理。 repo下载安装 从清华镜像源下载 mkdir ~/bin PATH~/bin:$PATH curl https://mirrors.tun…...
javacv基础02-调用本机摄像头并预览摄像头图像画面视频
引入架包: <dependency><groupId>org.openpnp</groupId><artifactId>opencv</artifactId><version>4.5.5-1</version></dependency><dependency><groupId>org.bytedeco</groupId><artifactId…...
缓冲区与响应头)
【Nginx21】Nginx学习:FastCGI模块(三)缓冲区与响应头
Nginx学习:FastCGI模块(三)缓冲区与响应头 缓存相关的内容占了 FastCGI 模块将近一小半的内容,当然,用过的人可能不多。而今天的内容说实话,我平常也没怎么用过。第一个是缓冲区相关的知识,其实…...
)
正则表达式(常用字符简单版)
量词 字符类 边界匹配 分组和捕获 特殊字符 字符匹配 普通字符:普通字符按照字面意义进行匹配,例如匹配字母 "a" 将匹配到文本中的 "a" 字符。元字符:元字符具有特殊的含义,例如 \d 匹配任意数字字符…...

LVGL在无显存TFT屏上的驱动适配:双缓冲与DMA优化实践
1. 项目概述:当TFT屏幕遇上LVGL最近在做一个嵌入式GUI项目,核心任务是把LVGL这个轻量级图形库,适配到一块分辨率不算高但接口比较“个性”的TFT屏幕上。这活儿听起来像是把标准插头插到非标插座上,得自己动手改改线序。LVGL这几年…...

LLVM开发实战指南:从入门到精通编译器与程序分析
1. 项目概述:为什么你需要一份LLVM指南?如果你是一名C开发者,或者对编译器、程序分析、代码优化这些底层技术感兴趣,那么“LLVM”这个名字对你来说一定不陌生。它早已不是象牙塔里的学术玩具,而是驱动着从iOS、macOS到…...

基于MCP与Apify构建AI驱动的投资另类数据研究工具
1. 项目概述:当投资研究遇上AI代理如果你是一名量化研究员、对冲基金分析师,或者只是一个对金融市场充满好奇、希望用数据驱动决策的独立投资者,那么你肯定对“另类数据”这个词不陌生。传统的财报、股价、宏观经济指标,这些“传统…...

从零部署开源语音助手:OpenClaw项目实战与二次开发指南
1. 项目概述:从开源代码到可用的语音助手看到leilei926524-tech/openclaw-voice-assistant这个项目标题,我的第一反应是:又一个基于开源代码的语音助手项目。在GitHub上,类似的项目多如牛毛,但真正能让一个普通开发者&…...

MCP服务器部署模板:容器化与CI/CD自动化实践指南
1. 项目概述:一个为MCP服务器量身定制的部署蓝图如果你正在开发或维护一个基于模型上下文协议(Model Context Protocol, MCP)的服务器,并且对如何将其优雅、可靠地部署到生产环境感到头疼,那么你很可能已经…...

从实验设计到代理模型:我是如何用拉丁超立方抽样节省了80%的仿真成本
从实验设计到代理模型:我是如何用拉丁超立方抽样节省了80%的仿真成本 去年夏天,当我接手某新型电动汽车外形的空气动力学优化项目时,团队正面临一个典型的多参数优化困境:每次计算流体力学(CFD)仿真需要6小…...

ctfileGet:城通网盘直连地址解析工具的技术原理与实用指南
ctfileGet:城通网盘直连地址解析工具的技术原理与实用指南 【免费下载链接】ctfileGet 获取城通网盘一次性直连地址 项目地址: https://gitcode.com/gh_mirrors/ct/ctfileGet ctfileGet是一个基于Web的开源工具,专门用于解析城通网盘分享链接并获…...
)
别再只盯着图片了!用3DCNN处理视频动作识别,从原理到代码实战(PyTorch版)
3DCNN实战:从视频动作识别到PyTorch代码实现 当监控摄像头捕捉到一场突如其来的争执,或是体育赛事中运动员的关键动作,传统图像识别技术往往力不从心。这些场景中的信息不仅存在于每一帧画面里,更隐藏在帧与帧之间的动态变化中——…...

Excalidraw结合MCP协议:实现智能架构图与开发生态动态连接
1. 项目概述:当Excalidraw遇见MCP,架构图绘制的效率革命如果你和我一样,日常工作中需要频繁绘制系统架构图、流程图,那么你一定对Excalidraw不陌生。这款开源的、手绘风格的绘图工具,以其简洁、直观和强大的协作能力&a…...

Spring Boot+Vue前后端分离项目Linux部署实战与避坑指南
1. 项目概述与核心价值最近在社区里看到不少朋友在问,自己用Spring Boot和Vue.js前后端分离开发的项目,在本地跑得好好的,一到要部署到Linux服务器上就各种报错,从环境变量到端口占用,再到静态资源404,问题…...