AIGC - 生成模型
AIGC - 生成模型
- 0. 前言
- 1. 生成模型
- 2. 生成模型与判别模型的区别
- 2.1 模型对比
- 2.2 条件生成模型
- 2.3 生成模型的发展
- 2.4 生成模型与人工智能
- 3. 生成模型示例
- 3.1 简单示例
- 3.2 生成模型框架
- 4. 表示学习
- 5. 生成模型与概率论
- 6. 生成模型分类
- 小结
0. 前言
生成式人工智能 (Generative Artificial Intelligence, GAI) 是一种人工智能方法,旨在通过学习训练数据的分布模型来生成新的、原创的数据。人工智能生成内容 (Artificial Intelligence Generated Content, AIGC) 是生成式人工智能的一个具体应用和实现方式,是指利用人工智能技术生成各种形式的内容,如文字、图像、音频和视频等。本节将介绍生成模型基本概念,首先介绍生成模型的基本概念,然后,构建用于衡量生成模型性能的框架,并介绍一些重要的核心概念。然后,介绍当前主流的生成模型技术及其分类。
1. 生成模型
生成模型 (Generative Model) 是机器学习的一个分支,通过训练模型以生成与给定数据集类似的新数据,换句话说模型通过学习训练数据的分布特征,生成与之类似但又不完全相同的新数据。
假设有一个包含猫图片的数据集,如果在该数据集上训练一个生成模型,以捕捉图像中像素之间的复杂关系。然后,我们可以利用该模型进行采样,生成原始数据集中不存在的逼真(猫)图像,如下图所示。

为了构建生成模型,我们需要一个包含许多我们要生成的实例的数据集,这被称为训练数据 (training data),其中每一个数据点称为一个观测值 (observation)。
每个观测值由许多特征 (features) 组成,对于图像生成问题,特征通常是各个像素的像素值;对于文本生成问题,特征通常是单词或字母组合。我们的目标是构建一个模型,可以生成看起来像是使用与原始数据相同规则创建的新特征集。对于图像生成来说,这是一个非常困难的任务,不仅由于生成的图像需要具有真实世界的特征和细节,包括纹理、颜色、形状等,同时图像生成模型通常需要大量的训练数据来学习图像的特征和分布。
生成模型还必须是概率性的 (probabilistic),而不是确定性的 (deterministic),因为我们希望能够采样出具有不同变化的输出,而不是每次得到相同的输出,对于图像数据而言,生成的图像应该具有不同的风格、角度和变化,而不是仅仅复制训练数据中的图像。如果我们的模型仅仅是一个固定的计算,例如在训练数据集中每个像素的平均值,那么它就不是生成模型,生成模型必须包含一个影响模型生成的随机因素。
换句话说,我们假设存在某种未知的概率分布,其可以解释图像在训练数据集中存在(或不存在)的合理性。生成模型的目标是构建一个尽可能精确地模仿这个分布的模型,然后从中进行采样,生成看起来像是原始训练集中可能包含的新的、独特的样本数据。
2. 生成模型与判别模型的区别
2.1 模型对比
为了了解生成模型及其重要性,首先需要介绍判别模型。假设我们有一个绘画的数据集,其中包含莫奈与一些其他艺术家的画作。通过使用足够的数据,可以训练一个判别模型,以预测给定的画作是否由莫奈绘制。判别模型能够学到画作中的颜色、形状和纹理特征,以便判断画作是否由莫奈所绘制,对于具有莫奈画作特征的绘画,模型会相应地增加其预测权重。下图展示了判别模型的构建过程:

在构建判别模型时,训练数据中的每个观测值都有一个标签 (label)。对于二分类问题,比如上述画作鉴别器,将莫奈的画作标记为 1,非莫奈的画作标记为 0。然后,判别模型学习如何区分这两组画作,并预测新数据样本属于标签 1 的概率,即样本是由莫奈绘制的概率。
而生成模型不需要数据集带有标签,因为生成模型关注的是生成新图像,而非试图预测给定图像的标签。接下来,使用公式正式定义生成模型和判别模型。
- 判别模型估计 p ( y ∣ x ) p(y|x) p(y∣x),即在给定输入 x x x 的情况下,输出 y y y 的概率。其中 y y y 是标签, x x x 是观测值
- 生成模型估计 p ( x ) p(x) p(x),即生成给定输入 x x x 的观测值的概率,而不考虑标签
- 判别模型关注如何根据观测值来预测标签,而生成模型关注如何根据概率分布来生成观测值
- 在判别模型中,可以使用逻辑回归、支持向量机等算法来构建模型。而在生成模型中,常使用生成对抗网络 (
Generative Adversarial Networks,GAN) 或扩散模型等算法来生成新的观测值
总结而言,判别模型和生成模型是两种不同的机器学习方法。判别模型通过观测值预测标签,而生成模型通过学习数据分布来生成新的观测值。
生成模型估计 p ( x ) p(x) p(x),即生成观测值 x x x 的概率。也就是说,生成模型旨在对观测值 x x x 进行建模,从所学分布中进行采样可以生成新的观测值。
2.2 条件生成模型
也可以构建生成模型来建模条件概率 p ( x ∣ y ) p(x|y) p(x∣y),即观察到具有特定标签 y y y 的观测值 x x x 的概率。例如,如果数据集包含不同类型的水果,可以训练生成模型仅仅生成苹果图像。
需要注意的,即使我们能够构建一个完美的判别模型识别莫奈的画作,但它仍然无法创作一幅具备莫奈风格的画作,它只是被训练用于输出关于现有图像的类别概率。相反,生成模型被训练用于从该模型中进行采样,以生成具有高概率属于原始训练数据集的图像。
2.3 生成模型的发展
数年来,判别模型一直是推动机器学习发展的主要动力。这是因为相对于判别问题,相应的生成问题通常更难解决。例如,训练一个模型预测一幅画是否是莫奈所作比起训练一个模型来生成莫奈风格的画作要容易得多;同样,训练一个模型来预测一篇小说是否是莎士比亚所写比起构建一个模型来生成一篇莎士比亚风格的小说要容易得多。
近来,随着机器学习技术的发展,解决生成问题变得不再遥不可及。通过将机器学习应用于构建生成模型的新颖应用得到了快速发展。下图展示了图像生成模型在面部图像生成方面的研究进展。

除了更容易解决的优势之外,判别模型在实际问题中的应用也比生成模型更广泛。例如,能够预测给定视网膜图像是否隐含青光眼迹象的模型对医疗领域具有重要作用,但能够生成眼部图片的模型可能并无作用。
但随着越来越多的公司开始提供面向特定业务问题的生成服务,生成模型的应用范围正在快速扩展。例如,只需提供特定的主题材料,就可以通过 API 访问生成原创博客文章的服务,还可以生成在不同场景下的产品图像,或者编写与品牌和目标信息相匹配的社交媒体内容和广告文案。同时,生成式AI在游戏设计和电影制作等行业也逐渐得到应用。
2.4 生成模型与人工智能
除了生成模型的实际应用,生成模型的发展还有三个更深层次的原因,生成模型是实现更精细人工智能形式的关键,超越了仅靠判别模型所能实现的范围。
首先,从理论角度来看,不应该局限于对数据进行简单分类。为了完整性,还应该关注能够捕捉数据分布更完整(超越特定标签)理解的模型。由于输出空间的维度较高,生成模型的构建无疑是一个更难解决的问题。许多判别模型中的关键技术,如深度学习等,也可以被生成模型所利用。
其次,生成模型现在正被用于推动人工智能的其他领域取得进展,例如强化学习等。假设要训练一个机器人在给定的地形上移动,传统方法是在计算机中模拟运行许多实验,其中智能体尝试使用不同的策略。随着实验的进行,智能体将学会哪些策略更有效,从而逐渐改善性能。这种方法的一个缺点是它的可扩展性较差,因为它是为一个特定任务优化策略。最近流行起来的另一种方法是放弃训练智能体优化特定任务的策略,转而使用生成模型训练智能体学习环境的世界模型,其独立于特定任务。智能体可以通过在自己的世界模型中测试策略来快速适应新任务,而不是在真实环境中进行测试,这种方法通常更高效,并且不需要为每个新任务重新训练。
最后,如果我们真的已经构建了一台具有与人类相媲美智能形式的机器,那么生成模型将是其中必不可少的部分。自然界中最好的生成模型之一就是人类,我们能够想象以任何可能的角度看小猫的样子;可以想象出电视节目几种不同的合理结局。当前神经科学理论表明,我们对现实的感知并不是一个在感官输入上运算的高度复杂的判别模型,用于预测我们经历的事物,而是一个从出生开始便不断训练的生成模型,用于产生准确匹配未来的环境模拟。显然,如何构建具备这种能力的机器对于我们了解解大脑运作和人工智能至关重要。
3. 生成模型示例
3.1 简单示例
首先,我们将使用一个简单示例展示生成模型。在二维空间中,使用 P d a t a P_{data} Pdata 规则生成如下图所示点集,我们的目标是得到二维空间中新的点 x = ( x 1 , x 2 ) x=(x_1,x_2) x=(x1,x2),使其看起来像是由相同规则生成的。
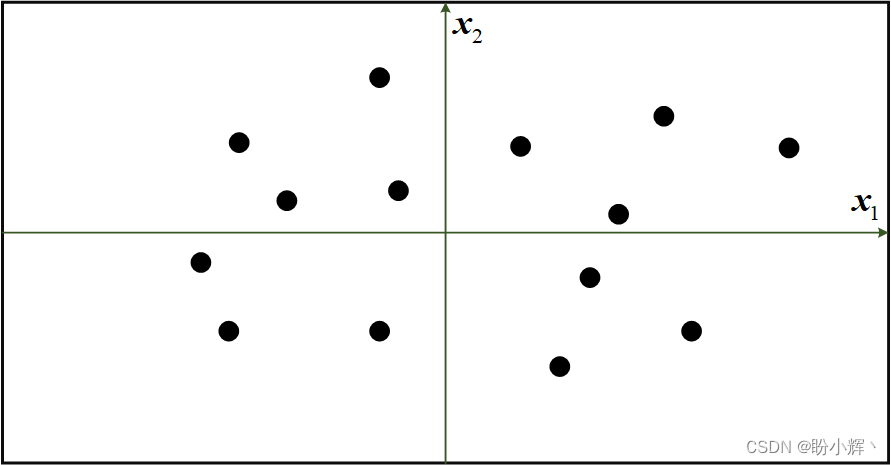
我们可以根据已有数据点的知识选择一个位置,构建模型 p m o d e l p_{model} pmodel,用于估计该点可能出现的位置。此时, p m o d e l p_{model} pmodel 是 p d a t a p_{data} pdata 的一个估计。 p m o d e l p_{model} pmodel 可能如下图中的矩形框所示,点只可能出现在框内,而框外的区域则可能没有任何点。

为了生成一个新的观测值,可以在框内随机选择一个点,或者说从分布 p m o d e l p_{model} pmodel 中进行采样。这就可以视为一个简单的生成模型,我们利用训练数据(黑色点)构建了一个模型(橙色区域),可以从中进行采样,生成看起来属于训练集的点。
3.2 生成模型框架
我们可以通过以下框架来表达我们构建生成模型的目标:
- 准备一组观测数据 X X X
- 假设这些观测数据是根据某一分布 p d a t a p_{data} pdata 生成的
- 目标是构建生成模型 p m o d e l p_{model} pmodel,以近似 p d a t a p_{data} pdata,如果实现了此目标,就可以从 p m o d e l p_{model} pmodel 中进行采样,生成看起来像是从 p d a t a p_{data} pdata 中抽取的观测数据
因此, p m o d e l p_{model} pmodel 需要包含以下属性:
- 准确性:如果 p m o d e l p_{model} pmodel 生成的观测样本准确性较高,则观测样本应该看起来像是从 p d a t a p_{data} pdata 中抽取的;如果 p m o d e l p_{model} pmodel 生成的观测样本准确性较低,则观测样本不应该看起来像是从 p d a t a p_{data} pdata 中抽取的
- 生成性:能够简单地从 p m o d e l p_{model} pmodel 中进行采样生成新的观测样本
- 表示性:能够理解 p m o d e l p_{model} pmodel 如何表示数据中不同的高级特征
接下来,我们使用简单数据生成分布 p d a t a p_{data} pdata,并利用上述框架进行处理,如下图所示,数据生成规则设定数据样本在蓝色区域均匀分布,且数据样本不能出现在黄色区域。

我们使用的模型 p m o d e l p_{model} pmodel (灰色区域)是对真实数据生成分布 p d a t a p_{data} pdata 的简化模型。数据样本 A、B 和 C 是模型 p m o d e l p_{model} pmodel 模拟 p d a t a p_{data} pdata 生成的数据:
- 点
A是由模型生成的观测样本,但看起来并不像是由 p d a t a p_{data} pdata 生成的,因为它位于黄色区域中 - 点
B无法由模型生成,因为它位于灰色区域之外,因此,可以说B为模型无法在整个可能性范围内的生成观测样本 - 点
C是一个合理的数据样本点,因为它既可以由模型 p m o d e l p_{model} pmodel 生成,也可以由真实分布 p d a t a p_{data} pdata 生成
尽管模型 p m o d e l p_{model} pmodel 存在缺陷,但该模型易于进行抽样,因为它是一个灰色框内的均匀分布,我们可以简单地从该框中随机选择一个点来进行抽样。
此外,生成模型 p m o d e l p_{model} pmodel 是对底层复杂分布的简单表示,但其也捕捉了一些底层高级特征。真实分布被划分为多个蓝色区域和黄色区域,这相当于本例的高级特征,虽然模型 p m o d e l p_{model} pmodel 也捕捉到这一高级特征,但其将其近似为单个蓝色区域。
上述示例演示了生成模型的基本概念,虽然生成模型是一个丰富多彩的领域,且问题的定义与处理也多种多样,但处理生成模型问题时基本遵循上述基本框架。
4. 表示学习
假设我们想向一个不认识的人描述自己的外貌,我们并不会逐个描述自己照片的每个像素。相反,我们会首先合理地假设对方对普通人的外貌有基本的了解,然后通过描述外貌特征,例如黑色的头发、褐色的眼睛等,对方就能够将这个描述映射回照片像素,从而在脑海中生成一个基本图像,虽然这个图像可能并不完美,但足够接近真实外貌,能够用于在数百个人中准确的识别。
据此,表示学习 (Representation Learning) 的核心思想可以描述如下:模型并不会尝试直接对高维样本空间建模,而是使用一些低维潜空间 (Latent Space) 描述训练集中的每个观测样本,然后学习一个映射函数,可以将潜空间中的点映射到原始领域中。换句话说,潜空间中的每个点都是某一高维观测样本的表示 (Representation)。
假设有如下训练集,其中包含了大量圆柱体的灰度图像。

对于人类而言,很明显可以使用圆柱体的高度和半径这两个特征唯一的表示这些圆柱体。也就是说,我们可以将每个圆柱体的图像转换为两维潜空间中的一个点,即使训练集中的图像是以高维像素空间表示的。这也意味着我们可以通过将适当的映射函数 f 应用于潜空间中的新点来生成不在训练集中的圆柱体图像。
对于机器而言,使用较简单的潜空间来描述原始数据集并非易事,机器首先需要确定高度和半径是最适合描述该数据集的两个潜空间维度,然后学习能够将该空间中的点映射到灰度圆柱体图像的映射函数 f f f。机器学习(尤其是深度学习)能够训练机器在没有人类指导的情况下学习这些高度复杂的映射函数。

表示学习能够以更易管理、且能够影响图像高级属性的隐空间中进行操作。例如,通过调整每个像素来增加圆柱体图像的高度并非易事,但在潜空间中,只需要增加高度对应的潜维度,然后应用映射函数即可反映到图像域上。
表示学习能够学习用于描述给定观测样本最为重要的特征,以及如何根据原始数据生成这些特征。将训练数据集编码为潜空间,以便可以从中进行采样,并将采样点解码回原始域,是许多生成模型构建的基础。从数学角度来说,表示学习试图将数据所处的高度非线性流形 (nonlinear manifold) (例如,像素空间)转化为更简单的潜空间,以便可以从中进行采样,从概率上而言,潜空间中的任何一点都能作为一个图像的表示。通过调整隐空间中的特征值,就可以生成新的表示,然后将其映射回原始数据域(例如图像)时,就可以得到逼真数据样本(例如图像数据)。

5. 生成模型与概率论
生成模型与概率分布的统计建模密切相关,因此,需要了解一些核心统计概念,用于解释每个生成模型的理论背景。为了充分理解要解决的任务,需要建立对基本概率理论的扎实理解,以理解不同类型的生成模型。
样本空间
样本空间 (sample space) 是观测样本 x \textbf x x 可以获取的所有值的完整集合。例如,在上述数据分布示例中,样本空间图像中的横纵坐标 ( x , y ) (x, y) (x,y) 组成。例如, x = ( 40 , 10 ) \textbf x=(40,10) x=(40,10) 是样本空间中属于真实数据生成分布的一个点。
概率密度函数
概率密度函数( probability density function,或简称密度函数)是一种将样本空间中的点 x \textbf x x 映射到 0 到 1 之间的数值的函数 p ( x ) p(\textbf x) p(x)。密度函数在样本空间中所有点上的积分必须等于 1,以确保其是一个明确定义的概率分布。
在上述数据分布示例中,生成模型的密度函数在灰色框之外为 0,在灰色框内为常数,因此密度函数在整个样本空间上的积分等于 1。
虽然只有一个真实的密度函数 p d a t a ( x ) p_{data}(\textbf x) pdata(x) 能够真正生成可观测数据集,但有无限多个密度函数 p m o d e l ( x ) p_{model}(\textbf x) pmodel(x) 可以用来估计 p d a t a ( x ) p_{data}(\textbf x) pdata(x)。为了能够找出合适的 p m o d e l ( x ) p_{model}(\textbf x) pmodel(x),可以使用参数化建模 (parametric modeling) 技术。
参数化建模
参数化建模 (parametric modeling) 是一种用来寻找合适 p m o d e l ( x ) p_{model}(\textbf x) pmodel(x) 的方法。参数模型 p θ ( x ) p_θ(\textbf x) pθ(x) 是一系列密度函数,可以通过有限数量的参数 θ θ θ 来描述。
如果我们将均匀分布假设为模型簇,那么在上述数据分布示例中,我们可以绘制的所有可能框的集合就是参数化模型的一个例子。在这种情况下,我们需要四个参数:方框的左下角 ( θ 1 , θ 2 ) (θ_1, θ_2) (θ1,θ2) 和右上角 ( θ 3 , θ 4 ) (θ_3, θ_4) (θ3,θ4) 的坐标。
因此,该参数模型中的每个密度函数 p θ ( x ) p_θ(\textbf x) pθ(x) (即每个方框)可以由四个数字 θ = ( θ 1 , θ 2 , θ 3 , θ 4 ) θ=(θ_1, θ_2, θ_3, θ_4) θ=(θ1,θ2,θ3,θ4) 唯一的表示。
似然函数
给定某个观测样本 x \textbf x x,参数集 θ θ θ 的似然函数 L ( θ ∣ x ) L(θ|\textbf x) L(θ∣x) 是一个量度 θ θ θ 在给定观测点 x \textbf x x 处的合理性的函数,其定义如下:
L ( θ ∣ x ) = p θ ( x ) \mathscr{L}(θ|\textbf x) = p_θ(\textbf x) L(θ∣x)=pθ(x)
也就是说,给定某个观测样本 x \textbf x x, θ θ θ 的似然性表示用参数 θ θ θ 表示点 x \textbf x x 上的密度函数值,如果我们有一个完整的独立观测数据集 X \textbf X X,则可以写成:
L ( θ ∣ X ) = Π x ∈ X p θ ( x ) \mathscr L(θ|\textbf X) = \underset {\textbf x \in \textbf X} {\Pi}p_θ(\textbf x) L(θ∣X)=x∈XΠpθ(x)
由于计算 0 到 1 之间大量项的乘积可能非常困难,因此通常使用对数似然度ℓ代替:
ℓ ( θ ∣ x ) = ∑ x ∈ X l o g p θ ( x ) \ell (θ|\textbf x) = \sum_{\textbf x\in \textbf X} log p_θ(\textbf x) ℓ(θ∣x)=x∈X∑logpθ(x)
在上述数据分布示例中,只覆盖图像左半部分的灰色框的似然性为 0,因为我们观察到的数据点位于图像右半部分,因此该框不可能生成数据集。图像中的灰色框的似然性为正数,因为在该模型下所有数据点的密度函数都是正数。
似然函数的此种定义方式是具有统计意义的,但我们也可以直观地理解这个定义。我们可以简单的将参数集 θ θ θ 的似然函数定义为:在由参数集 θ θ θ 定义的模型中,观测到数据的概率。
需要注意的是,似然函数是参数的函数,而不是数据的函数。不应将其解释为给定参数集正确的概率,换句话说,它不是参数空间上的概率分布(即在参数方面不会求和/积分为1)。
直观而言,参数化建模应该专注于找到最优的参数 θ ^ \hat θ θ^,以最大化数据集 X \textbf X X 观测值的似然性。
最大似然估计
最大似然估计 (maximum likelihood estimation) 是一种估计密度函数 p θ ( x ) p_θ(\textbf x) pθ(x) 的参数集 θ ^ \hat θ θ^ 的方法,该参数集能够最合理的解释观测数据集 X \textbf X X,更正式的定义如下:
θ ^ = a r g m a x θ L ( θ ∣ X ) \hat θ = \underset {θ} {argmax}\mathscr L(θ|\textbf X) θ^=θargmaxL(θ∣X)
θ ^ \hat θ θ^ 也被称为最大似然估计 (maximum likelihood estimate, MLE)。在上述数据分布示例中,MLE 是包含训练集中所有点的最小矩形。
神经网络通常需要最小化损失函数,等价的,我们可以找到使负对数似然最小化的参数集:
θ ^ = a r g m i n θ − L ( θ ∣ X ) = a r g m i n θ − l o g p θ ( x ) \hat θ = \underset {θ} {argmin} -\mathscr L(θ|\textbf X) = \underset {θ} {argmin} -log p_θ(\textbf x) θ^=θargmin−L(θ∣X)=θargmin−logpθ(x)
生成模型可以视为最大似然估计的一种形式,其中参数 θ θ θ 是模型中包含的神经网络的权重。我们试图找到这些参数的值,以最大化观察到的数据的似然性(或等价地,最小化负对数似然)。
然而,在高维问题中,直接计算 p θ ( x ) p_θ(\textbf x) pθ(x) 通常是不可能的,因为它过于复杂的,不同类型的生成模型采用不同的方法来解决这一问题。
6. 生成模型分类
尽管所有类型的生成模型最终都旨在解决同一任务,但它们在对密度函数 p θ ( x ) p_θ(\textbf x) pθ(x) 进行建模时采取了不同的方法。广义上说,有以下三种方法:
- 显式地对密度函数进行建模,但通过一定方式对模型进行约束,使密度函数可计算
- 显式地对密度函数的可计算近似进行建模
- 通过直接生成数据的随机过程来隐式地对密度函数进行建模
生成模型分类方式如下所示,这些模型簇并不是互斥的,有很多模型混合使用了两种及以上的不同方法。
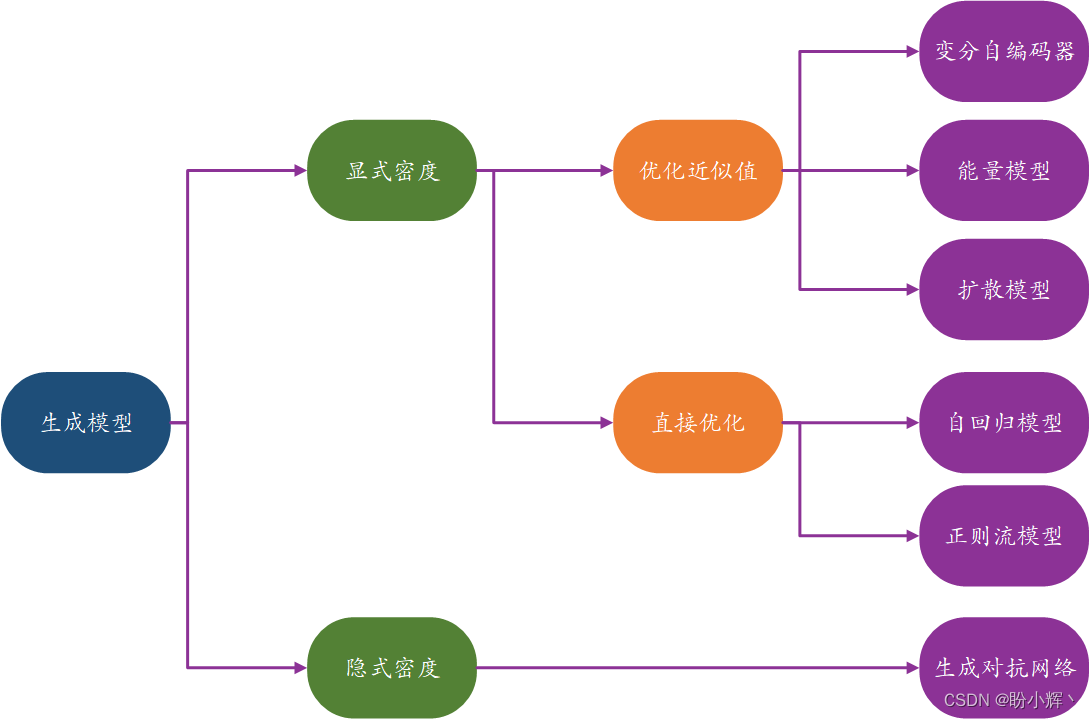
我们可以首先将模型分为显式建模概率密度函数 p ( x ) p(\textbf x) p(x) 的模型和隐式建模概率密度函数的模型。
隐式密度模型并不直接估计概率密度,而专注于直接生成数据的随机过程。生成对抗网络 (Generative Adversarial Networks, GAN) 是典型的隐式生成模型。显式密度模型可以进一步分为直接优化密度函数(可计算密度模型)和优化其近似值的模型。
可计算密度模型通过对模型架构进行约束,使得密度函数具有易于计算的形式。例如,自回归模型对输入特征进行排序,以便可以按序生成输出,比如逐字生成或逐像素生成。正则流模型将一系列可计算的可逆函数应用于简单分布,以生成更复杂的分布。
近似密度模型包括变分自编码器,引入潜变量并优化联合密度函数的近似值。能量模型也利用近似方法,但是其通过马尔可夫链采样而非变分方法。扩散模型通过训练模型逐渐去噪给定图像来近似密度函数。
小结
本节介绍了人工智能的一个重要分支——生成模型,介绍了生成模型理论和应用的最新进展。我们从一个简单的示例开始,了解了生成模型最终关注的是对数据的潜在分布进行建模。通过总结生成模型框架,以理解生成模型的重要属性。然后,介绍了有助于理解生成模型的理论基础和关键概率概念,并概述了生成模型的分类方法。
相关文章:
AIGC - 生成模型
AIGC - 生成模型 0. 前言1. 生成模型2. 生成模型与判别模型的区别2.1 模型对比2.2 条件生成模型2.3 生成模型的发展2.4 生成模型与人工智能 3. 生成模型示例3.1 简单示例3.2 生成模型框架 4. 表示学习5. 生成模型与概率论6. 生成模型分类小结 0. 前言 生成式人工智能 (Generat…...

如何优雅地创建一个自定义的Spring Boot Starter
优雅永不过时,希望看完本文,你会觉得starter如此优雅! Spring Boot Starter是一种简化Spring Boot应用开发的机制,它可以通过引入一些预定义的依赖和配置,让我们快速地集成某些功能模块,而无需繁琐地编写代…...

Hbase--技术文档--单机docker基础安装(非高可用)
环境准备-docker 配置Linux服务器华为云耀云服务器之docker安装,以及环境变量安装 java (虚拟机一样适用)_docker配置java环境变量_一单成的博客-CSDN博客 说明: 本文章安装方式为学习使用的单体hbase项目。主要是学习ÿ…...
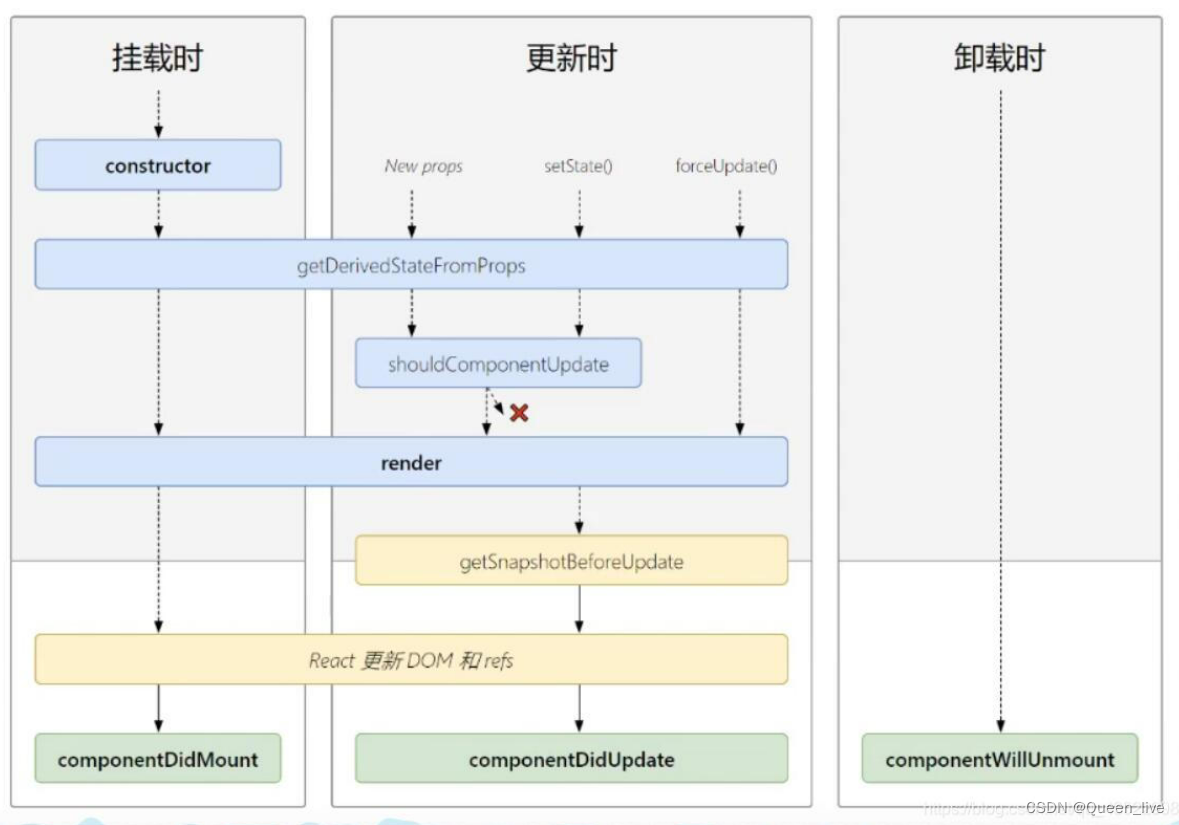
React 生命周期新旧对比
前言 React16.4版本之后使用了新的生命周期,它使用了一些新的生命周期钩子(getDerivedStateFromProps、getSnapshotBeforeUpdate),并且即将废弃老版的3个生命周期钩子(componentWillMount、componentWillReceiveProps…...

云计算存储类型
一、共享存储模式 NAS: ①一种专门用于存储和共享文件的设备,它通过网络连接到计算机或其他设备, 提供了一个中心化的存储解决方案 ②存储网络使用IP网络 ,数据存储共享基于文件 ③本质上为:NFS和CIFS文件共享服务器 ④提供的不是一个磁盘块…...
javacv基础03-调用本机摄像头并截图保存到本地磁盘
基于基础02 的基础上对视频进行取帧保存 代码如下: package com.example.javacvstudy;/*** 本地摄像头截图*/import org.bytedeco.javacv.CanvasFrame; import org.bytedeco.javacv.FrameGrabber; import org.bytedeco.javacv.OpenCVFrameConverter; import org.b…...

Python读取Windows注册表的实战代码
大家好,我是爱编程的喵喵。双985硕士毕业,现担任全栈工程师一职,热衷于将数据思维应用到工作与生活中。从事机器学习以及相关的前后端开发工作。曾在阿里云、科大讯飞、CCF等比赛获得多次Top名次。现为CSDN博客专家、人工智能领域优质创作者。喜欢通过博客创作的方式对所学的…...

macOS 安装 Homebrew 详细过程
文章目录 macOS 安装 Homebrew 详细过程Homebrew 简介Homebrew 安装过程设置环境变量安装 Homebrew安装完成后续设置(重要)设置环境变量homebrew 镜像源设置macOS 安装 Homebrew 详细过程 本文讲解了如何使用中科大源安装 Homebrew 的安装过程,文章里面的所有步骤都是必要的,需…...
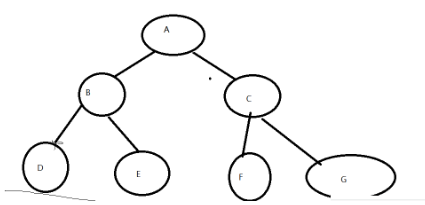
数据结构之树型结构
相关概念树的表示二叉树二叉树性质二叉树储存 实现一颗二叉树创建遍历(前中后序)获取树中节点个数获取叶子节点个数获取第k层节点个数获取二叉树高度检测值为value元素是否存在层序遍历(需要队列来实现)判断是否为完全二叉树&…...
指针进阶详解
个人主页:点我进入主页 专栏分类:C语言初阶 C语言程序设计————KTV C语言小游戏 C语言进阶 欢迎大家点赞,评论,收藏。 一起努力,一起奔赴大厂。 目录 1.字符指针 2.指针数组 3.数组指针 4.数组传…...
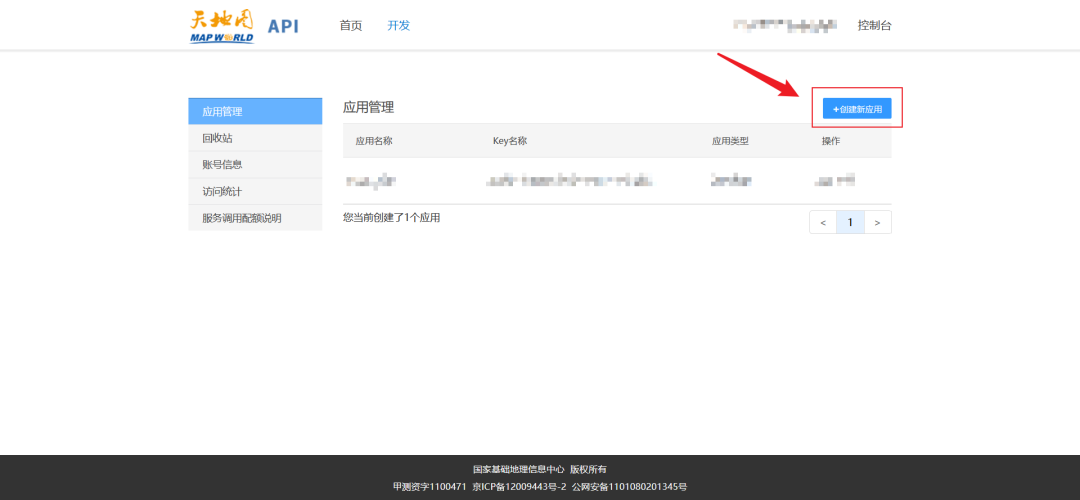
QGIS 如何添加天地图
相信很多小伙伴在 QGIS 里面添加天地图的时候一定感觉很困惑,按照官网的操作申请 Key 之后,添加相对应的服务地址之后看不到地图或者地图不正常显示,今天我们就来解决这个问题 以下所有操作基于 QGIS 3.22 版本 申请 Key 1. 添加天地图的第一步需要申请 Key,首先要注册天…...

PHP8内置函数中的数学函数-PHP8知识详解
php8中提供了大量的内置函数,以便程序员直接使用常见的内置函数包括数学函数、变量函数、字符串函数、时间和日期函数等。今天介绍内置函数中的数学函数。 本文讲到了数学函数中的随机数函数rand()、舍去法取整函数floor()、向上取整函数 ceil()、对浮点数进行四舍…...
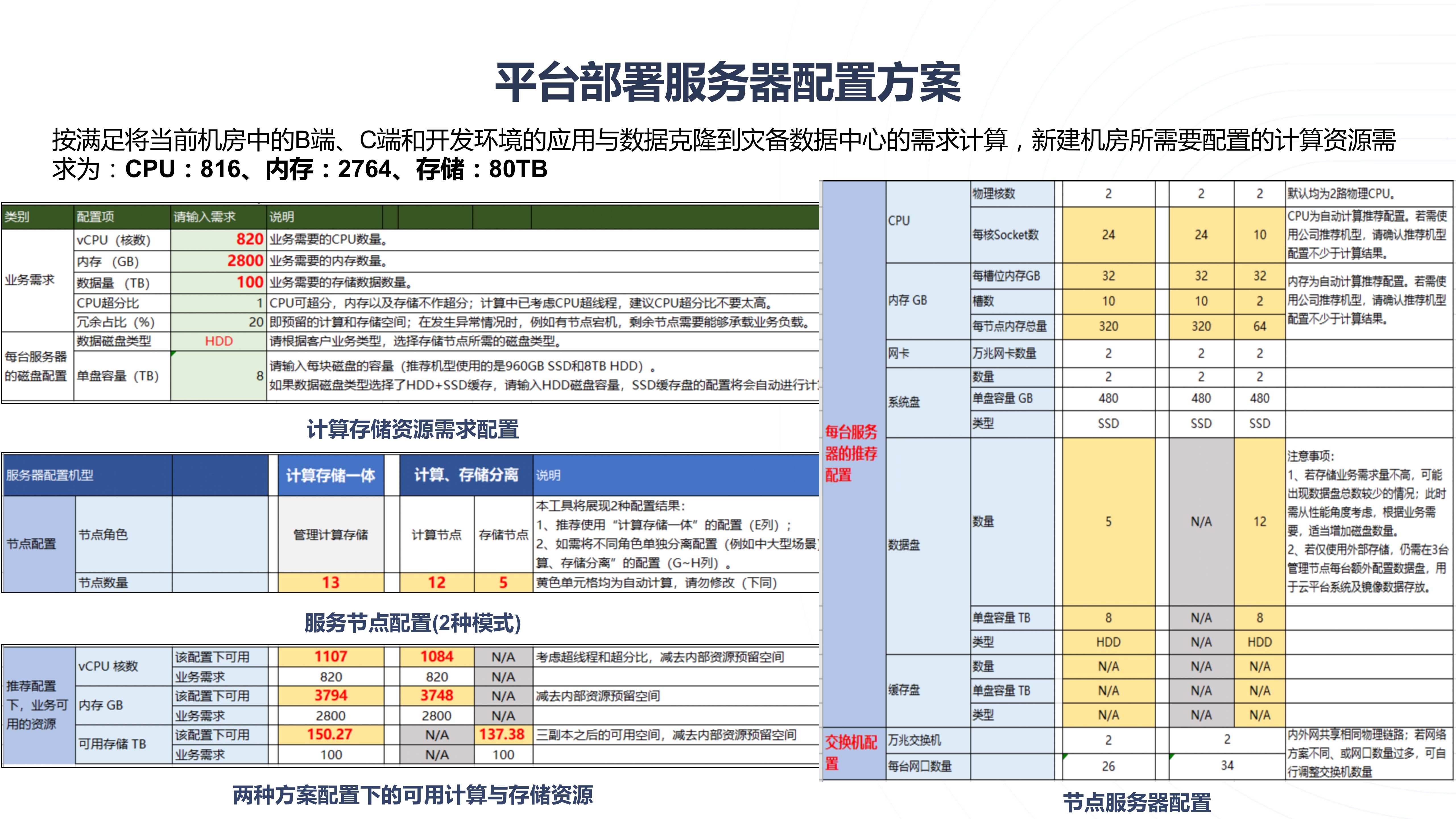
云计算企业私有云平台建设方案PPT
导读:原文《云计算企业私有云平台建设方案PPT》(获取来源见文尾),本文精选其中精华及架构部分,逻辑清晰、内容完整,为快速形成售前方案提供参考。 喜欢文章,您可以点赞评论转发本文,…...

ORA-01174: DB_FILES be compatible RAC rolling fashion complete outage
How to change the DB_FILES parameter in RAC (Doc ID 1636681.1)编辑To Bottom In this Document Goal Solution APPLIES TO: Oracle Database - Enterprise Edition - Version 10.1.0.2 and later Oracle Database Cloud Schema Service - Version N/A and later Oracle…...

线性代数(五) 线性空间
前言 《线性代数(三) 线性方程组&向量空间》我通过解线性方程组的方式去理解线性空间。此章从另一个角度去理解 空间是什么 大家较熟悉的:平面直角坐标系是最常见的二维空间 空间由无穷多个坐标点组成 每个坐标点就是一个向量 反过来,也可说&…...
kafka--技术文档--spring-boot集成基础简单使用
阿丹: 查阅了很多资料了解到,使用了spring-boot中整合的kafka的使用是被封装好的。也就是说这些使用其实和在linux中的使用kafka代码的使用其实没有太大关系。但是逻辑是一样的。这点要注意! 使用spring-boot整合kafka 1、导入依赖 核心配…...
【核磁共振成像】部分傅里叶重建
目录 一、部分傅里叶重建二、部分傅里叶重建算法2.1 填零2.2 零差处理 一、部分傅里叶重建 在部分傅里叶采集中,数据并不是绕K空间中心对称收集的,而是K空间的一半是完全填充的,另一半只收集了一小部分数据。 部分傅里叶采集所依据的原理…...

React中的flushSync与Vue中的nextTick的比较
React中的flushSync与Vue中的nextTick是两种用于处理异步更新的机制。它们在React和Vue这两个流行的前端框架中起着重要的作用。 首先,让我们来看看flushSync。在React中,当需要更新UI时,React会将更新操作放入一个队列中,然后异…...

golang设置国内镜像源
以windows为例, 在cmd 窗口中执行下列语句 go env -w GO111MODULEon go env -w GOPROXYhttps://goproxy.io,direct 或者 1.运行 go env -w GO111MODULEon //开启mod 运行 go env -w GOPROXYhttps://goproxy.cn,direct //设置代理 执…...

linux切换到root没有conda环境
这个错是因为 没有将anaconda添加到环境变量 export PATH"/home/tao/anaconda3/bin:$PATH"然后 source ~/.bashrc或者写入 nano ~/.bashrc在文件的末尾添加以下行 export PATH"/home/tao/anaconda3/bin:$PATH"再 source ~/.bashrc就可以了...

基于CLUE与加速度计的鸡蛋坠落实验:从传感器数据到缓冲设计优化
1. 项目概述:用传感器数据为物理实验“上保险” 鸡蛋坠落实验,一个听起来就充满童年乐趣和“悲剧”风险的经典物理项目。它的核心挑战在于,如何设计一个缓冲装置,让一枚脆弱的生鸡蛋从高处坠落而不破裂。传统上,我们依…...

用Ruby实现RISC-V模拟器:从指令集架构到交互式教学工具
1. 项目概述:一个为Ruby语言量身打造的RISC-V模拟器如果你是一名Ruby开发者,或者对RISC-V这个新兴的指令集架构充满好奇,那么你很可能已经听说过RuriOSS/rurima这个名字。简单来说,这是一个用Ruby语言实现的RISC-V指令集模拟器。但…...

2026运营经理学习数据分析对职场能力提升的影响
一、数据分析在运营管理中的核心价值数据分析能力帮助运营经理优化决策流程,通过数据驱动的方法提升业务效率。掌握用户行为分析、市场趋势预测等技能,能够更精准地制定运营策略。数据可视化工具(如Tableau、Power BI)的应用&…...

AI对话记忆管理实战:memory-organizer库解决长上下文难题
1. 项目概述:一个为AI记忆体“瘦身”与“归档”的利器最近在折腾一些本地大语言模型(LLM)的应用,比如搭建个人知识库助手或者长期对话机器人,一个绕不开的痛点就是“记忆”的管理。模型本身没有持久记忆,每…...

1987年4月26日中午11-13点出生性格、运势和命运
在1987年4月26日中午11 - 13点出生的人,正处于火兔年的特定时段。从性格层面来看,这一时间段出生者往往有着热情似火且积极向上的特质。他们如同正午炽热的阳光,充满活力与冲劲,对生活始终保持着乐观的态度,面对困难时…...
)
告别3D-DNA的卡顿:用Chromap+Yahs快速搞定植物Hi-C辅助组装(附完整代码)
植物基因组Hi-C辅助组装新方案:ChromapYahs全流程解析 在植物基因组研究中,Hi-C技术已成为提升组装连续性的重要手段。然而传统3D-DNA流程在植物数据上的表现常令研究者头疼——运行速度缓慢、内存占用高,且对植物特有的重复序列处理效果欠佳…...

Arduino蓝牙HID键盘实战:Bluefruit LE模块AT命令与控制器模式详解
1. 项目概述与核心价值如果你正在寻找一种能让你的Arduino项目“开口说话”或者“隔空操作”手机、电脑的方法,那么Adafruit的Bluefruit LE系列蓝牙低功耗模块绝对是一个绕不开的明星选手。它不仅仅是一个简单的蓝牙串口模块,更是一个集成了丰富AT命令集…...

手工打造柔性LED眼罩:从SMD焊接入门到可穿戴电路实践
1. 项目概述:从零打造你的赛博格之眼如果你和我一样,对《银翼杀手》里那些闪烁着冷光的义眼,或是赛博朋克美学中标志性的发光装饰着迷,那么亲手制作一个属于自己的LED眼罩,绝对是一次令人兴奋的旅程。这不仅仅是一个酷…...

MOXA NPort 5110串口服务器避坑指南:网线直连、波特率设置与Web管理那些事儿
MOXA NPort 5110串口服务器实战避坑手册:从硬件部署到批量管理的深度解析 第一次接触工业级串口服务器时,我对着那个巴掌大的金属盒子发呆了十分钟——RJ45、DB9、电源接口密密麻麻挤在一起,配套光盘里还有三个不同功能的配置工具。直到现场调…...

Unity 2019.4.7f1实战:从零复刻Flappy Bird,搞定PC/Web/Android三端发布
Unity 2019.4.7f1实战:从零复刻Flappy Bird,搞定PC/Web/Android三端发布 当你第一次打开Unity时,面对那个空荡荡的3D场景,可能会有些不知所措。但别担心,今天我们就用这个看似简单的Flappy Bird游戏,带你走…...