机器学习笔记之优化算法(二十)牛顿法与正则化
机器学习笔记之优化算法——再回首:牛顿法与正则化
- 引言
- 回顾:经典牛顿法及其弊端
- 牛顿法:算法步骤
- 迭代过程中可能出现的问题
- 正则化 Hessian Matrix \text{Hessian Matrix} Hessian Matrix与相应问题
引言
本节我们介绍经典牛顿法在训练神经网络过程中的迭代步骤,并介绍正则化在牛顿法中的使用逻辑。
回顾:经典牛顿法及其弊端
经典牛顿法自身是一个典型的线搜索方法 ( Line-Search Method ) (\text{Line-Search Method}) (Line-Search Method)。它的迭代过程使用数学符号表示如下:
x k + 1 = x k + α k ⋅ P k x_{k+1} = x_k + \alpha_k \cdot \mathcal P_k xk+1=xk+αk⋅Pk
其中标量 α k \alpha_k αk表示当前第 k k k次迭代情况下的更新步长;向量 P k \mathcal P_k Pk表示当前迭代步骤的更新方向。与梯度下降法区分的是,在经典牛顿法中:
- 步长并不是我们关注的信息,我们通常设置 α k = 1 ( k = 1 , 2 , 3 , ⋯ ) \alpha_k = 1(k=1,2,3,\cdots) αk=1(k=1,2,3,⋯),从而迭代结果 x k + 1 x_{k+1} xk+1可看作是关于方向变量 P \mathcal P P的函数:
而P k \mathcal P_k Pk则表示当前迭代步骤的最优更新方向。
{ x k + 1 = x k + P P k = arg min P f ( x k + 1 ) = arg min P f ( x k + P ) \begin{cases} \begin{aligned} x_{k+1} & = x_k + \mathcal P \\ \mathcal P_k & = \mathop{\arg\min}\limits_{\mathcal P} f(x_{k+1}) \\ & = \mathop{\arg\min}\limits_{\mathcal P} f(x_k + \mathcal P) \end{aligned} \end{cases} ⎩ ⎨ ⎧xk+1Pk=xk+P=Pargminf(xk+1)=Pargminf(xk+P) - 关于目标函数 f ( ⋅ ) f(\cdot) f(⋅),我们对其要求是: f ( ⋅ ) f(\cdot) f(⋅)至少二阶可微。这意味着 Hessian Matrix ⇒ ∇ 2 f ( ⋅ ) \text{Hessian Matrix} \Rightarrow \nabla^2 f(\cdot) Hessian Matrix⇒∇2f(⋅)存在。因此对目标函数 f ( x k + P ) f(x_k + \mathcal P) f(xk+P)进行二阶泰勒展开:
f ( x k + P ) = ϕ ( P ) = f ( x k ) + 1 1 ! [ ∇ f ( x k ) ] T P + 1 2 ! P T [ ∇ 2 f ( x k ) ] ⋅ P + O ( ∥ P ∥ 2 ) f(x_k + \mathcal P) = \phi(\mathcal P) = f(x_k) + \frac{1}{1!} [\nabla f(x_k)]^T \mathcal P + \frac{1}{2!} \mathcal P^T [\nabla^2 f(x_k)] \cdot \mathcal P + \mathcal O(\|\mathcal P\|^2) f(xk+P)=ϕ(P)=f(xk)+1!1[∇f(xk)]TP+2!1PT[∇2f(xk)]⋅P+O(∥P∥2)
忽略掉高阶无穷小 O ( ∥ P ∥ 2 ) \mathcal O(\|\mathcal P\|^2) O(∥P∥2),通过令 ∇ ϕ ( P ) ≜ 0 \nabla \phi(\mathcal P) \triangleq 0 ∇ϕ(P)≜0来求解 P k \mathcal P_k Pk,使 ϕ ( P k ) \phi(\mathcal P_k) ϕ(Pk)取得最小值:
∇ ϕ ( P ) ≜ 0 ⇒ ∇ 2 f ( x k ) ⋅ P = − ∇ f ( x k ) \nabla \phi(\mathcal P) \triangleq 0 \Rightarrow \nabla^2 f(x_k) \cdot \mathcal P = -\nabla f(x_k) ∇ϕ(P)≜0⇒∇2f(xk)⋅P=−∇f(xk)
我们称该方程组为牛顿方程:- 如果 ∇ 2 f ( ⋅ ) \nabla^2 f(\cdot) ∇2f(⋅)在 x k x_k xk出的 Hessian Matrix ⇒ ∇ 2 f ( x k ) \text{Hessian Matrix} \Rightarrow \nabla^2 f(x_k) Hessian Matrix⇒∇2f(xk)是正定矩阵,那么:本次迭代步骤存在合适的 P k \mathcal P_k Pk,使 ϕ ( P k ) \phi(\mathcal P_k) ϕ(Pk)达到最小值:
需要注意的是,这仅仅是当前迭代步骤的最小值,而不是全局最小值。
P k = − [ ∇ 2 f ( x k ) ] − 1 ∇ f ( x k ) \mathcal P_k = - [\nabla^2 f(x_k)]^{-1} \nabla f(x_k) Pk=−[∇2f(xk)]−1∇f(xk)
并且解 P k \mathcal P_k Pk描述的方向一定是下降方向。 - 相反,如果 ∇ 2 f ( x k ) \nabla^2 f(x_k) ∇2f(xk)不是正定矩阵,那么至少说:无法直接求解,方程组 ∇ 2 f ( x k ) ⋅ P = − ∇ f ( x k ) \nabla^2 f(x_k) \cdot \mathcal P = -\nabla f(x_k) ∇2f(xk)⋅P=−∇f(xk)的解是 P k \mathcal P_k Pk的解。
- 如果 ∇ 2 f ( ⋅ ) \nabla^2 f(\cdot) ∇2f(⋅)在 x k x_k xk出的 Hessian Matrix ⇒ ∇ 2 f ( x k ) \text{Hessian Matrix} \Rightarrow \nabla^2 f(x_k) Hessian Matrix⇒∇2f(xk)是正定矩阵,那么:本次迭代步骤存在合适的 P k \mathcal P_k Pk,使 ϕ ( P k ) \phi(\mathcal P_k) ϕ(Pk)达到最小值:
牛顿法:算法步骤
在训练神经网络的方法中,牛顿法是二阶近似方法的代表。这里为了简单表述,将上面提到的目标函数 f ( ⋅ ) f(\cdot) f(⋅)具象化为经验风险 ( Empirical Risk ) (\text{Empirical Risk}) (Empirical Risk):
J ( θ ) = E P d a t a { L [ G ( x ( i ) ; θ ) , y ( i ) ] } = 1 N ∑ i = 1 N L [ G ( x ( i ) ; θ ) , y ( i ) ] P d a t a = { ( x ( i ) , y ( i ) ) } i = 1 N \begin{aligned} \mathcal J(\theta) & = \mathbb E_{\mathcal P_{data}} \left\{\mathcal L[\mathcal G(x^{(i)};\theta),y^{(i)}]\right\} \\ & = \frac{1}{N} \sum_{i=1}^N \mathcal L [\mathcal G(x^{(i)};\theta),y^{(i)}] \end{aligned}\quad P_{data} = \{(x^{(i)},y^{(i)})\}_{i=1}^N J(θ)=EPdata{L[G(x(i);θ),y(i)]}=N1i=1∑NL[G(x(i);θ),y(i)]Pdata={(x(i),y(i))}i=1N
其中 θ \theta θ可看作是需要学习的模型参数; G ( ⋅ ) \mathcal G(\cdot) G(⋅)可看作是模型关于 x x x的预测函数; L ( ⋅ ) \mathcal L(\cdot) L(⋅)可看作是损失函数,描述预测结果与真实标签的差异性信息。
假设 θ 0 \theta_0 θ0表示当前迭代过程的起始位置,是已知项;而 θ \theta θ是一个变量,描述当前迭代过程结束后的参数位置。这里直接使用: θ − θ 0 \theta -\theta_0 θ−θ0表示当前迭代步骤的更新方向,对 J ( θ ) \mathcal J(\theta) J(θ)进行二阶泰勒展开:
实际上,书中θ − θ 0 \theta - \theta_0 θ−θ0本身就将步长 α = 1 \alpha = 1 α=1包含在内。这里关于J ( θ ) \mathcal J(\theta) J(θ)高于二阶的高阶无穷小直接省略掉了~关于Hessian Matrix ⇒ ∇ 2 J ( θ 0 ) \text{Hessian Matrix} \Rightarrow \nabla^2 \mathcal J(\theta_0) Hessian Matrix⇒∇2J(θ0)直接使用H \mathcal H H进行表示。
J ( θ ) ≈ J ( θ 0 ) + 1 1 ! ( θ − θ 0 ) T ∇ θ J ( θ 0 ) + 1 2 ! ( θ − θ 0 ) T H ( θ − θ 0 ) \mathcal J(\theta) \approx \mathcal J(\theta_0) + \frac{1}{1!}(\theta - \theta_0)^T \nabla_{\theta} \mathcal J(\theta_0) + \frac{1}{2!}(\theta - \theta_0)^T \mathcal H (\theta - \theta_0) J(θ)≈J(θ0)+1!1(θ−θ0)T∇θJ(θ0)+2!1(θ−θ0)TH(θ−θ0)
依然令 ∇ J ( θ ) ≜ 0 \nabla \mathcal J(\theta) \triangleq 0 ∇J(θ)≜0,有:
∇ J ( θ ) = ( 1 − 0 ) ⋅ ∇ J θ ( θ 0 ) + 1 2 ⋅ 2 ( θ − θ 0 ) ⋅ H ≜ 0 ⇒ H ( θ − θ 0 ) = − ∇ J θ ( θ 0 ) \begin{aligned} \nabla\mathcal J(\theta) & = (1 - 0) \cdot \nabla \mathcal J_{\theta}(\theta_0) + \frac{1}{2} \cdot 2 (\theta - \theta_0)\cdot \mathcal H \triangleq 0\\ & \Rightarrow \mathcal H(\theta - \theta_0) = -\nabla \mathcal J_{\theta}(\theta_0) \end{aligned} ∇J(θ)=(1−0)⋅∇Jθ(θ0)+21⋅2(θ−θ0)⋅H≜0⇒H(θ−θ0)=−∇Jθ(θ0)
假设 H \mathcal H H是正定的条件下,关于 θ \theta θ与 θ 0 \theta_0 θ0的递推关系表示如下:
θ = θ 0 − H − 1 ∇ θ J ( θ 0 ) \theta = \theta_0 - \mathcal H^{-1} \nabla_{\theta} \mathcal J(\theta_0) θ=θ0−H−1∇θJ(θ0)
基于递推关系,对应的算法步骤表示如下:
-
初始化:初始参数 θ s t a r t \theta_{start} θstart以及包含 N N N个样本的训练数据集;
-
While \text{While} While:
- 计算 ∇ θ J ( θ 0 ) \nabla_{\theta} \mathcal J(\theta_0) ∇θJ(θ0):
牛顿-莱布尼兹公式~,这是书上的表达。详细位置见末尾~
∇ θ J ( θ 0 ) = ∇ θ { 1 N ∑ i = 1 N L [ G ( x ( i ) ; θ 0 ) , y ( i ) ] } = 1 N ∇ θ ∑ i = 1 N L [ G ( x ( i ) ; θ 0 ) , y ( i ) ] \begin{aligned} \nabla_{\theta} \mathcal J(\theta_0) & = \nabla_{\theta} \left\{\frac{1}{N} \sum_{i=1}^N \mathcal L[\mathcal G(x^{(i)};\theta_0),y^{(i)}]\right\} \\ & = \frac{1}{N} \nabla_{\theta} \sum_{i=1}^N \mathcal L[\mathcal G(x^{(i)};\theta_0),y^{(i)}] \end{aligned} ∇θJ(θ0)=∇θ{N1i=1∑NL[G(x(i);θ0),y(i)]}=N1∇θi=1∑NL[G(x(i);θ0),y(i)] - 计算 θ 0 \theta_0 θ0位置的 Hessian Matrix ⇒ H \text{Hessian Matrix} \Rightarrow \mathcal H Hessian Matrix⇒H:
该公式同样也是书上描述。
H = ∇ θ 2 J ( θ 0 ) = ∇ θ 2 { 1 N ∑ i = 1 N L [ G ( x ( i ) ; θ 0 ) , y ( i ) ] } = 1 N ∇ θ 2 ∑ i = 1 N L [ G ( x ( i ) ; θ 0 ) , y ( i ) ] \begin{aligned} \mathcal H & = \nabla_{\theta}^2 \mathcal J(\theta_0) \\ & = \nabla_{\theta}^2 \left\{\frac{1}{N} \sum_{i=1}^N \mathcal L[\mathcal G(x^{(i)};\theta_0),y^{(i)}]\right\} \\ & = \frac{1}{N} \nabla_{\theta}^2 \sum_{i=1}^N \mathcal L[\mathcal G(x^{(i)};\theta_0),y^{(i)}] \end{aligned} H=∇θ2J(θ0)=∇θ2{N1i=1∑NL[G(x(i);θ0),y(i)]}=N1∇θ2i=1∑NL[G(x(i);θ0),y(i)] - 计算 Hessian Matrix \text{Hessian Matrix} Hessian Matrix的逆: H − 1 \mathcal H^{-1} H−1;
- 计算变量 θ \theta θ的变化量 Δ θ \Delta \theta Δθ:
Δ θ = − H − 1 ∇ θ J ( θ 0 ) \Delta \theta = -\mathcal H^{-1} \nabla_{\theta} \mathcal J(\theta_0) Δθ=−H−1∇θJ(θ0) - 对变量 θ \theta θ进行更新:
θ = θ 0 + Δ θ \theta = \theta_0 + \Delta \theta θ=θ0+Δθ
- 计算 ∇ θ J ( θ 0 ) \nabla_{\theta} \mathcal J(\theta_0) ∇θJ(θ0):
-
End While \text{End While} End While
迭代过程中可能出现的问题
观察上述迭代步骤,一个核心问题是:该算法必须建立在迭代过程中,各步骤的 θ \theta θ对应的 Hessian Matrix \text{Hessian Matrix} Hessian Matrix必须均是正定的,否则 H − 1 \mathcal H^{-1} H−1无法求解。在凸函数 VS \text{VS} VS强凸函数中介绍过关于强凸函数的二阶条件:如果函数 f ( ⋅ ) f(\cdot) f(⋅)二阶可微,有:
其中 I \mathcal I I表示单位矩阵。
f ( ⋅ ) is m-Strong Convex ⇔ ∇ 2 f ( x ) ≽ m ⋅ I f(\cdot) \text{is m-Strong Convex} \Leftrightarrow \nabla^2 f(x) \succcurlyeq m \cdot \mathcal I f(⋅)is m-Strong Convex⇔∇2f(x)≽m⋅I
也就是说:要想 H = ∇ θ 2 J ( θ 0 ) \mathcal H = \nabla_{\theta}^2 \mathcal J(\theta_0) H=∇θ2J(θ0)正定,必然需要目标函数 J ( θ ) \mathcal J(\theta) J(θ)在 θ = θ 0 \theta= \theta_0 θ=θ0处不仅是凸的,甚至是强凸的。
但在深度学习中,目标函数的表面由于特征较多,从而在局部呈现非凸的情况。例如鞍点,二阶梯度函数 ∇ θ 2 J ( θ ) \nabla_{\theta}^2 \mathcal J(\theta) ∇θ2J(θ)在该处的特征值并不都是正的,也就是说:鞍点处的 Hessian Matrix \text{Hessian Matrix} Hessian Matrix可能不是正定的,从而可能导致在该点出迭代过程中选择的 θ \theta θ,使得更新方向 θ − θ 0 \theta - \theta_0 θ−θ0是个错误的方向。
正则化 Hessian Matrix \text{Hessian Matrix} Hessian Matrix与相应问题
上述情况可以使用正则化 Hessian Matrix \text{Hessian Matrix} Hessian Matrix来避免。一种常用的正则化策略是 Hessian Matrix \text{Hessian Matrix} Hessian Matrix加上一个对角线元素均为 α \alpha α的对角阵:
θ = θ 0 − [ ∇ θ 2 J ( θ 0 ) ⏟ H + α ⋅ I ] − 1 ∇ θ J ( θ 0 ) \theta = \theta_0 - \left[\underbrace{\nabla_{\theta}^2 \mathcal J(\theta_0)}_{\mathcal H} + \alpha \cdot \mathcal I\right]^{-1} \nabla_{\theta} \mathcal J(\theta_0) θ=θ0− H ∇θ2J(θ0)+α⋅I −1∇θJ(θ0)
这种操作我们早在正则化与岭回归中就已介绍过。由于 Hessian Matrix ⇒ H \text{Hessian Matrix} \Rightarrow \mathcal H Hessian Matrix⇒H至少是实对称矩阵,那么必然有:
H = Q Λ Q T Q Q T = Q T Q = I \mathcal H = \mathcal Q\Lambda \mathcal Q^T \quad \mathcal Q\mathcal Q^T = \mathcal Q^T\mathcal Q = \mathcal I H=QΛQTQQT=QTQ=I
并且 λ I = Q ( λ I ) Q T \lambda \mathcal I = \mathcal Q(\lambda \mathcal I) \mathcal Q^T λI=Q(λI)QT,从而 H + λ ⋅ I \mathcal H + \lambda \cdot \mathcal I H+λ⋅I可表示为:
H + λ ⋅ I = Q Λ Q T + Q ( λ I ) Q T = Q ( Λ + λ I ) Q T \begin{aligned} \mathcal H + \lambda \cdot \mathcal I & = \mathcal Q \Lambda\mathcal Q^T + \mathcal Q(\lambda \mathcal I) \mathcal Q^T \\ & = \mathcal Q(\Lambda + \lambda \mathcal I) \mathcal Q^T \end{aligned} H+λ⋅I=QΛQT+Q(λI)QT=Q(Λ+λI)QT
这相当于:给 H \mathcal H H的所有特征值加上一个正值 α \alpha α。
相比于最小二乘法模型参数 W \mathcal W W的矩阵形式表达: W = ( X T X ) − 1 X T Y \mathcal W = (\mathcal X^T \mathcal X)^{-1} \mathcal X^T \mathcal Y W=(XTX)−1XTY, H \mathcal H H可能更不稳定。因为 X T X \mathcal X^T\mathcal X XTX必然是半正定的,但 H \mathcal H H中的特征值有可能是负的。
由于 H \mathcal H H中的特征值有可能是负的,甚至是负定矩阵。如果 H \mathcal H H中存在特征值负的很厉害的情况下(存在很强的负曲率),我们需要增大 α \alpha α结果来抵消负特征值。如果 α \alpha α持续增大,对应特征值可能会被 α \alpha α主导。从而导致迭代步骤选择的方向收敛到 1 α × \begin{aligned}\frac{1}{\alpha} \times\end{aligned} α1×普通梯度。
使用牛顿法训练大型的神经网络,更多还受限于计算负担。由于 H ∈ R p × p \mathcal H \in \mathbb R^{p \times p} H∈Rp×p,其中 p p p表示样本特征维度,求解 H − 1 \mathcal H^{-1} H−1的时间复杂度是 O ( k 3 ) \mathcal O(k^3) O(k3)。并且由于迭代过程中随着 θ \theta θ的变化,因而需要每次迭代过程都要计算对应 H − 1 \mathcal H^{-1} H−1。因而,最终结果是:只有少量参数的神经网络,才能在实际中使用牛顿法进行训练。
相关参考:
《深度学习》(花书)P190 - 8.6 二阶近似方法
相关文章:
牛顿法与正则化)
机器学习笔记之优化算法(二十)牛顿法与正则化
机器学习笔记之优化算法——再回首:牛顿法与正则化 引言回顾:经典牛顿法及其弊端牛顿法:算法步骤迭代过程中可能出现的问题正则化 Hessian Matrix \text{Hessian Matrix} Hessian Matrix与相应问题 引言 本节我们介绍经典牛顿法在训练神经网络过程中的迭…...

【Go 基础篇】深入探索:Go语言中的切片遍历与注意事项
嗨,Go语言学习者!在我们的编程旅程中,切片(Slice)是一个极其重要的工具。它可以帮助我们处理各种类型的数据,从而让我们的代码更加灵活和高效。本文将围绕Go语言中切片的遍历方法以及在遍历时需要注意的事项…...

一些经典的SQL语句
查sql中as的用法搜索到的一些经典的sql语句 convert(2008-11-20 18:03:50) In:等值连接,用来查找多表相同字段的记录 Not In:非等值连接,用来查找不存在的记录 Inner join:内连接,主要用来查找都符合条件的记录 Left join:左连接ÿ…...

〔018〕Stable Diffusion 之 批量替换人脸 篇
✨ 目录 🎈 下载插件🎈 插件基础使用🎈 基础使用效果🎈 批量处理图片🎈 多人脸部替换 🎈 下载插件 如果重绘图片的时候,你只想更换人物面部的话,可以参考这篇文章扩展地址ÿ…...

Unity字符串性能问题
前言 分享一些通过书籍和网络学到的知识 每次动态创建一个string,C#都会在堆内存分配一个内存用来分配字符串,因为C#没有对字符串的缓存机制,会导致每次连接、切割、组合的时候都会申请新的内存,并且抛弃原来的内存,等…...

深入浅出SSD:固态存储核心技术、原理与实战(文末赠书)
名字:阿玥的小东东 学习:Python、C/C 主页链接:阿玥的小东东的博客_CSDN博客-python&&c高级知识,过年必备,C/C知识讲解领域博主 目录 内容简介 作者简介 使用Python做一个计算器 本期赠书 近年来国家大力支持半导体行业࿰…...

关于layui+php,三级联动-编辑回显的问题。
注 忍不住吐槽一波。都什么年代了。现在都前后端分离,但是公司老项目非得用tplayui。。 代码如下 layui.use([form], function () {var form layui.form;//php代码渲染页面的时候,将一级分类id和二级分类id带过来,存到页面input框中&#x…...
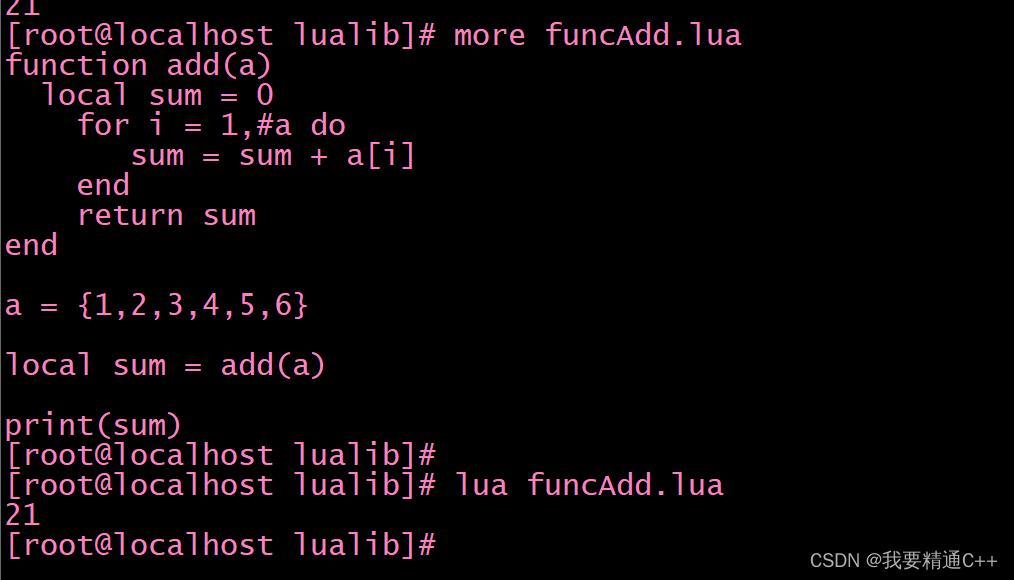
lua的函数
1.一个示例实现列表的元素的求和 [root]# more funcAdd.lua function add(a)local sum 0for i 1,#a dosum sum a[i]endreturn sum enda {1,2,3,4,5,6}local sum add(a)print(sum)...

pytorch/tensorflow 直接给张量中的某个位置的值赋值,操作不可导。
问题:给一个tensor A中[i,j],赋值p。直接操作A[i,j]p可能会导致值覆盖,操作不可导。 解决方案:通过引入一个额外的mask实现。 mask[i,j] 0 mask tf.convert_to_tensor(mask, dtypetf.float32) A (A * mask) (p * (1-mask))p…...

如何使用CSS实现一个平滑滚动到页面顶部的效果(回到顶部按钮)?
聚沙成塔每天进步一点点 ⭐ 专栏简介⭐ 平滑滚动到页面顶部的效果(回到顶部按钮)⭐ 创建HTML结构⭐ 编写CSS样式⭐ 编写JavaScript函数⭐ 添加滚动事件监听器⭐ 写在最后 ⭐ 专栏简介 前端入门之旅:探索Web开发的奇妙世界 记得点击上方或者右…...
【RuoYi移动端】uniApp导入和引用uView2.0插件
一、打开uiew官网 安装 | uView 2.0 - 全面兼容 nvue 的 uni-app 生态框架 - uni-app UI 框架uView UI,是 uni-app 生态最优秀的 UI 框架,全面的组件和便捷的工具会让您信手拈来,如鱼得水https://uviewui.com/components/install.html 也可直…...

etcd 备份还原
etcd 备份还原 查看 etcdctl 是否已经安装 # quick check if etcdctl is available or not ETCDCTL_API3 etcdctl --help | head安装 etcdctl # 获取 etcd 版本信息 kubectl exec -it etcd-master -n kube-system -- /bin/sh -c ETCDCTL_API3 /usr/local/bin/etcd --version…...

LInux之chrony服务器
目录 场景 重要性 LInux的两个时钟 硬件时钟 系统时钟 NTP协议 Chrony介绍 定义 组成 --- chronyd和chronyc 安装与配置 安装 Chrony配置文件分析 同步时间服务器 chronyc命令 chronyc sources输出分析 其它命令 查看时间服务器的状态 查看时间服务器是否在线 …...

《Flink学习笔记》——第七章 处理函数
为了让代码有更强大的表现力和易用性,Flink 本身提供了多层 API 在更底层,我们可以不定义任何具体的算子(比如 map,filter,或者 window),而只是提炼出一个统一的“处理”(process&a…...
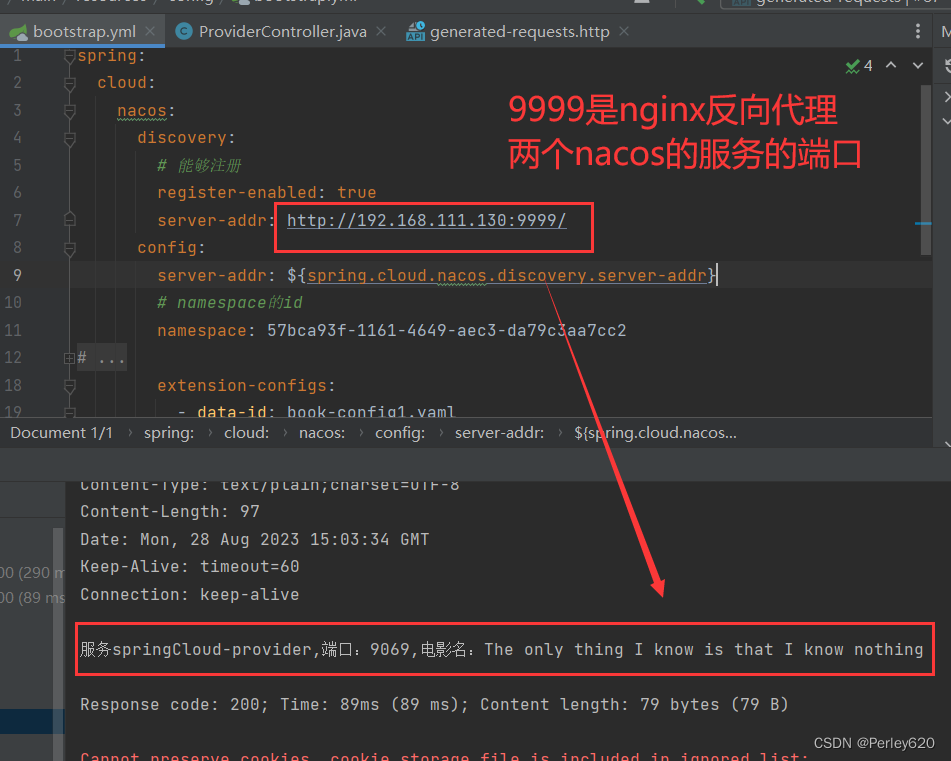
Nacos基础(3)——nacos+nginx 集群的配置和启动 端口开放 nginx反向代理nacos集群
目录 引出nacos集群nginx反向代理nacos集群停止单例nacos准备8848和8858修改cluster.conf配置【配置】修改启动配置文件【配置】开放8858的端口分别以集群方式启动【启动】前端访问查看生产者测试8858nacos nginx反向代理配置代理tcp代理http启动nginx反向代理容器生产者访问测…...

传承精神 缅怀伟人——湖南多链优品科技有限公司赴韶山开展红色主题活动
8月27日上午, 湖南多链优品科技有限公司全体员工怀着崇敬之情,以红色文化为引领,参加了毛泽东同志诞辰130周年的纪念活动。以董事长程小明为核心的公司班子成员以及全国优秀代表近70人一行专赴韶山,缅怀伟人毛泽东同志的丰功伟绩。…...

安全知识普及-如何创建一个安全的密码
文章目录 安全密码的特点创建安全密码的方法为何要创建一个安全的密码推荐阅读 安全密码是一种强化的密码,旨在提供更高级别的安全性,以防止未经授权的访问、数据泄露和其他安全威胁。 安全密码的特点 安全密码,有七大特点,特点如…...

Lua基础知识
文章目录 1. Lua简介1.1 设计目的:1.2 特性1.3 应用场景 2. Lua脚本学习2.1 安装2.2 lua操作2.3 lua案例 学习lua主要是为了后续做高性能缓存架构所准备的基础技术。可以先了解下基础,在实际使用时,再查缺补漏。 1. Lua简介 Lua 是一种轻量小…...

Java Math方法记录
Java 提供 java.lang.Math 类,很方便的进行数学运算。 Math 类是基于浮点数的运算,可能导致精度损失,不适用于高精度计算。 记录如下 常量 提供了两个常量, Math.PI :圆周率πMath.E :自然对数的底数 …...
)
Java XPath 使用(2023/08/29)
Java XPath 使用(2023/08/29) 文章目录 Java XPath 使用(2023/08/29)1. 前言2. 技术选型3. 技术实现 1. 前言 众所周知,Java 语言适合应用于 Web 开发领域,不擅长用来编写爬虫。但在 Web 开发过程中有时又…...

LibreCAD符号库创建终极指南:快速构建您的专业CAD图库
LibreCAD符号库创建终极指南:快速构建您的专业CAD图库 【免费下载链接】LibreCAD LibreCAD is a cross-platform 2D CAD program. It can read DXF and write DXF/PDF/SVG files, with basic support for DWG reading. It supports point/line/circle/ellipse/parab…...

量化交易自动化框架设计:从API客户端到策略回测的工程实践
1. 项目概述与核心价值最近在量化交易和自动化策略开发的圈子里,一个名为cbonoz/kalshi-skill的项目引起了我的注意。乍一看,这像是一个针对特定交易平台 Kalshi 的技能或工具包。对于不熟悉的朋友,Kalshi 是一个新兴的事件合约交易平台&…...

把旧路由器变成全能开发板:OpenWrt安装ADB、Python3和FFmpeg,远程调试手机还能玩推流
旧路由器改造指南:打造OpenWrt全能开发平台 在科技快速迭代的今天,路由器更新换代的速度远超实际需求。许多家庭和企业都堆积着性能过剩的旧路由器,它们往往被束之高阁或直接丢弃。然而,这些被淘汰的设备实际上隐藏着巨大的潜力—…...

别再用docker tag了!深入理解Containerd生态:crictl、ctr与nerdctl到底该怎么选?
深入解析Containerd生态:crictl、ctr与nerdctl的镜像管理实战指南 在容器技术快速发展的今天,越来越多的开发者正从Docker生态转向Containerd这一更轻量、更符合Kubernetes标准的运行时环境。但当我们真正开始使用Containerd时,往往会遇到一个…...

ACK多集群配置同步:MCP Server架构、部署与实战指南
1. 项目概述:ACK多集群管理平台的服务端核心如果你正在或计划使用阿里云容器服务ACK来管理多个Kubernetes集群,并且对如何高效、统一地分发应用配置感到头疼,那么你很可能已经接触或正在寻找类似“ack-mcp-server”这样的解决方案。这个项目&…...

独立硬件看门狗芯片Air153C:提升嵌入式系统可靠性的终极方案
1. 项目概述:为什么我们需要一颗独立的看门狗芯片?最近在做一个户外数据采集终端的项目,设备部署在野外,需要长期稳定运行。最头疼的问题不是功能实现,而是如何应对各种意想不到的“死机”。电源波动、电磁干扰、程序跑…...

别再为OSGB数据导入SuperMap iDesktop发愁了!手把手教你搞定倾斜摄影配置文件生成与常见报错
三维GIS实战:从OSGB到SuperMap iDesktop的完整避坑指南 当无人机航拍的倾斜摄影数据第一次在SuperMap iDesktop中成功加载时,那种从二维平面跃入三维空间的震撼感,是每个GIS从业者都难忘的体验。然而,这份喜悦往往被配置文件生成失…...

tchMaterial-parser:5分钟快速上手,轻松获取国家中小学智慧教育平台电子课本的完整指南
tchMaterial-parser:5分钟快速上手,轻松获取国家中小学智慧教育平台电子课本的完整指南 【免费下载链接】tchMaterial-parser 国家中小学智慧教育平台 电子课本下载工具,帮助您从智慧教育平台中获取电子课本的 PDF 文件网址并进行下载&#x…...

免费音频编辑终极指南:Audacity如何让专业音频处理变得简单
免费音频编辑终极指南:Audacity如何让专业音频处理变得简单 【免费下载链接】audacity Audio Editor 项目地址: https://gitcode.com/GitHub_Trending/au/audacity 还在为音频编辑软件的高昂价格而烦恼?是否曾因复杂的音频工具而放弃创作&#x…...

基于树莓派与ROS的桌面机器人开发:从硬件组装到AI集成实战
1. 项目概述:一个“会思考”的桌面机器人伙伴最近在机器人爱好者圈子里,一个名为“Wall-E”的开源项目热度不低。这可不是那个动画电影里可爱的垃圾处理机器人,而是一个由SRA-VJTI团队开发的、运行在树莓派上的桌面级智能机器人项目。我第一次…...