ruoyi--数据权限
这篇文章我先和大家分析一下 RuoYi-Vue 脚手架中 @DataScope 注解的实现原理,在 TienChin 项目视频中到时候还会有深入讲解。
1. 思路分析
首先我们先来捋一捋这里的权限实现的思路。
@DataScope 注解处理的内容叫做数据权限,就是说你这个用户登录后能够访问哪些数据。传统的做法就是根据当前认证用户的 id 或者角色或者权限等信息去查询,但是这种做法比较麻烦比较费事,每次查询都要写大量 SQL,而这些 SQL 中又有大量雷同的地方,所以我们希望能够将之进行统一处理,进而就引出了 @DataScope 注解。
在 RuoYi-Vue 脚手架中,将用户的数据权限分为了五类,分别如下:
1:这个表示全部数据权限,也就是这个用户登录上来之后可以访问所有的数据,一般来说只有超级管理员具备此权限。
2:这个表示自定义数据权限,自定义数据权限就表示根据用户的角色查找到这个用户可以操作哪个部门的数据,以此为依据进行数据查询。
3:这个表示部门数据权限,这个简单,就是这个用户只能查询到本部门的数据。
4:这个表示本部门及以下数据权限,这个意思就是用户可以查询到本部门以及本部门下面子部门的数据。
5:这个就表示这个用户仅仅只能查看自己的数据。
在 TienChin 这个项目中,数据权限也基本上是按照这个脚手架的设计来的,我们只需要搞懂这里的实现思路,将来就可以随心所欲的去自定义数据权限注解了。
2. 表结构分析
捋清楚了思路,再来看看表结构。
这里涉及到如下几张表:
sys_user:用户表
sys_role:角色表
sys_dept:部门表
sys_user_role:用户角色关联表
sys_role_dept:角色部门关联表
这几个表中有一些细节我来和大家梳理下。一个一个来看。
用户表中有一个 dept_id 表示这个用户所属的部门 id,一个用户属于一个部门。
角色表中有一个字段叫做 data_scope,表示这个角色所对应的数据权限,取值就是 1-5,含义就是我们上面所列出来的含义,这个很重要哦。
部门表在设计的时候,有一个 ancestors 字段,通过这个字段可以非常方便的查询一个部门的子部门。
最后两张关联表就没啥好说了。
好了,这些都分析完了,我们就来看看具体的实现。
3. 具体实现
3.1 @DataScope
先来看数据权限注解的定义:
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface DataScope {/*** 部门表的别名*/public String deptAlias() default "";/*** 用户表的别名*/public String userAlias() default "";
}
这个注解中有两个属性,一个是 deptAlias 和 userAlias。由于数据权限实现的核心思路就是在要执行的 SQL 上动态追加查询条件,那么动态追加的 SQL 必须要考虑到原本 SQL 定义时的部门表别名和用户表别名。这两个属性就是用来干这事的。
所以小伙伴们可能也看出来,这个 @DataScope 跟我们以前的注解还不太一样,以前自定义的其他注解跟业务耦合度比较小,这个 @DataScope 跟业务的耦合度则比较高,必须要看一下你业务 SQL 中对于部门表和用户表取的别名是啥,然后配置到这个注解上。
因此,@DataScope 注解不算是一个特别灵活的注解,咱们就抱着学习的态度了解下他的实现方式就行了。
3.2 切面分析
注解定义好了,接下来就是切面分析了。
我把 RuoYi-Vue 脚手架中,解析这个注解的切面代码列出来,咱们逐行进行分析。
@Aspect
@Component
public class DataScopeAspect {/*** 全部数据权限*/public static final String DATA_SCOPE_ALL = "1";/*** 自定数据权限*/public static final String DATA_SCOPE_CUSTOM = "2";/*** 部门数据权限*/public static final String DATA_SCOPE_DEPT = "3";/*** 部门及以下数据权限*/public static final String DATA_SCOPE_DEPT_AND_CHILD = "4";/*** 仅本人数据权限*/public static final String DATA_SCOPE_SELF = "5";/*** 数据权限过滤关键字*/public static final String DATA_SCOPE = "dataScope";@Before("@annotation(controllerDataScope)")public void doBefore(JoinPoint point, DataScope controllerDataScope) throws Throwable {clearDataScope(point);handleDataScope(point, controllerDataScope);}protected void handleDataScope(final JoinPoint joinPoint, DataScope controllerDataScope) {// 获取当前的用户LoginUser loginUser = SecurityUtils.getLoginUser();if (StringUtils.isNotNull(loginUser)) {SysUser currentUser = loginUser.getUser();// 如果是超级管理员,则不过滤数据if (StringUtils.isNotNull(currentUser) && !currentUser.isAdmin()) {dataScopeFilter(joinPoint, currentUser, controllerDataScope.deptAlias(),controllerDataScope.userAlias());}}}/*** 数据范围过滤** @param joinPoint 切点* @param user 用户* @param userAlias 别名*/public static void dataScopeFilter(JoinPoint joinPoint, SysUser user, String deptAlias, String userAlias) {StringBuilder sqlString = new StringBuilder();for (SysRole role : user.getRoles()) {String dataScope = role.getDataScope();if (DATA_SCOPE_ALL.equals(dataScope)) {sqlString = new StringBuilder();break;} else if (DATA_SCOPE_CUSTOM.equals(dataScope)) {sqlString.append(StringUtils.format(" OR {}.dept_id IN ( SELECT dept_id FROM sys_role_dept WHERE role_id = {} ) ", deptAlias,role.getRoleId()));} else if (DATA_SCOPE_DEPT.equals(dataScope)) {sqlString.append(StringUtils.format(" OR {}.dept_id = {} ", deptAlias, user.getDeptId()));} else if (DATA_SCOPE_DEPT_AND_CHILD.equals(dataScope)) {sqlString.append(StringUtils.format(" OR {}.dept_id IN ( SELECT dept_id FROM sys_dept WHERE dept_id = {} or find_in_set( {} , ancestors ) )",deptAlias, user.getDeptId(), user.getDeptId()));} else if (DATA_SCOPE_SELF.equals(dataScope)) {if (StringUtils.isNotBlank(userAlias)) {sqlString.append(StringUtils.format(" OR {}.user_id = {} ", userAlias, user.getUserId()));} else {// 数据权限为仅本人且没有userAlias别名不查询任何数据sqlString.append(" OR 1=0 ");}}}if (StringUtils.isNotBlank(sqlString.toString())) {Object params = joinPoint.getArgs()[0];if (StringUtils.isNotNull(params) && params instanceof BaseEntity) {BaseEntity baseEntity = (BaseEntity) params;baseEntity.getParams().put(DATA_SCOPE, " AND (" + sqlString.substring(4) + ")");}}}/*** 拼接权限sql前先清空params.dataScope参数防止注入*/private void clearDataScope(final JoinPoint joinPoint) {Object params = joinPoint.getArgs()[0];if (StringUtils.isNotNull(params) && params instanceof BaseEntity) {BaseEntity baseEntity = (BaseEntity) params;baseEntity.getParams().put(DATA_SCOPE, "");}}
}
- 首先一上来就定义了五种不同的数据权限类型,这五种类型咱们前面已经介绍过了,这里就不再赘述了。
- 接下来的 doBefore 方法是一个前置通知。由于 @DataScope 注解是加在 service 层的方法上,所以这里使用前置通知,为方法的执行补充 SQL 参数,具体思路是这样:加了数据权限注解的 service 层方法的参数必须是对象,并且这个对象必须继承自 BaseEntity,BaseEntity 中则有一个 Map 类型的 params 属性,我们如果需要为 service 层方法的执行补充一句 SQL,那么就把补充的内容放到这个 params 变量中,补充内容的 key 就是前面声明的 dataScope,value 则是一句 SQL。在 doBefore 方法中先执行 clearDataScope 去清除 params 变量中已有的内容,防止 SQL 注入(因为这个 params 的内容也可以从前端传来);然后执行 handleDataScope 方法进行数据权限的过滤。
- 在 handleDataScope 方法中,主要是查询到当前的用户,然后调用 dataScopeFilter 方法进行数据过滤,这个就是过滤的核心方法了。
- 由于一个用户可能有多个角色,所以在 dataScopeFilter 方法中要先遍历角色,不同的角色有不同的数据权限,这些不同的数据权限之间通过 OR 相连,最终生成的补充 SQL 的格式类似这样 AND(xxx OR xxx OR xxx) 这样,每一个 xxx 代表一个角色生成的过滤条件。
- 接下来就是根据各种不同的数据权限生成补充 SQL 了:如果数据权限为 1,则生成的 SQL 为空,即查询 SQL 不添加限制条件;如果数据权限为 2,表示自定义数据权限,此时根据用户的角色查询出用户的部门,生成查询限制的 SQL;如果数据权限为 3,表示用户的数据权限仅限于自己所在的部门,那么将用户所属的部门拎出来作为查询限制;如果数据权限为 4,表示用户的权限是自己的部门和他的子部门,那么就将用户所属的部门以及其子部门拎出来作为限制查询条件;如果数据权限为 5,表示用户的数据权限仅限于自己,即只能查看自己的数据,那么就用用户自身的 id 作为查询的限制条件。最后,再把生成的 SQL 稍微处理下,变成 AND(xxx OR xxx OR xxx) 格式,这个就比较简单了,就是字符串截取+字符串拼接。
好啦,大功告成,接下来我们通过几个具体的查询来看看这个切面的应用。
4. 案例分析
我们来看一下 @DataScope 注解三个具体的应用大家就明白了。
在 RuoYi-Vue 脚手架中,这个注解主要有三个使用场景:
查询部门。
查询角色。
查询用户。
假设我现在以 ry 这个用户登录,这个用户的角色是普通角色,普通角色的数据权限是 2,即自定义数据权限,我们就来看看这个用户是如何查询数据的。
我们分别来看。
4.1 查询部门
首先查询部门的方法位于
org.javaboy.tienchin.system.service.impl.SysDeptServiceImpl#selectDeptList
位置,具体方法如下:
@Override
@DataScope(deptAlias = "d")
public List<SysDept> selectDeptList(SysDept dept) {return deptMapper.selectDeptList(dept);
}
这个参数 SysDept 继承自 BaseEntity,而 BaseEntity 中有一个 params 属性,这个咱们前面也已经介绍过了,不再赘述。
我们来看下这个 selectDeptList 方法对应的 SQL:
<sql id="selectDeptVo">select d.dept_id, d.parent_id, d.ancestors, d.dept_name, d.order_num, d.leader, d.phone, d.email, d.status, d.del_flag, d.create_by, d.create_time from sys_dept d
</sql>
<select id="selectDeptList" parameterType="SysDept" resultMap="SysDeptResult"><include refid="selectDeptVo"/>where d.del_flag = '0'<if test="deptId != null and deptId != 0">AND dept_id = #{deptId}</if><if test="parentId != null and parentId != 0">AND parent_id = #{parentId}</if><if test="deptName != null and deptName != ''">AND dept_name like concat('%', #{deptName}, '%')</if><if test="status != null and status != ''">AND status = #{status}</if><!-- 数据范围过滤 -->${params.dataScope}order by d.parent_id, d.order_num
</select>
大家可以看到,在 SQL 的最后面有一句 ${params.dataScope},就是把在 DataScopeAspect 切面中拼接的 SQL 追加进来。
所以这个 SQL 最终的形式类似下面这样:
select d.dept_id, d.parent_id, d.ancestors, d.dept_name, d.order_num, d.leader, d.phone, d.email, d.status, d.del_flag, d.create_by, d.create_time from sys_dept d where d.del_flag = '0' AND (d.dept_id IN ( SELECT dept_id FROM sys_role_dept WHERE role_id = 2 ) ) order by d.parent_id, d.order_num
可以看到,追加了最后面的 SQL 之后,就实现了数据过滤(这里是根据自定义数据权限进行过滤)。那么这里还涉及到一个细节,前面 SQL 在定义时,用的表别名是什么,我们在 @DataScope 中指定的别名就要是什么。
4.2 查询角色
首先查询角色的方法位于 org.javaboy.tienchin.system.service.impl.SysRoleServiceImpl#selectRoleList 位置,具体方法如下:
@Override
@DataScope(deptAlias = "d")
public List<SysRole> selectRoleList(SysRole role) {return roleMapper.selectRoleList(role);
}
这个参数 SysRole 继承自 BaseEntity,而 BaseEntity 中有一个 params 属性,这个咱们前面也已经介绍过了,不再赘述。
我们来看下这个 selectRoleList 方法对应的 SQL:
<sql id="selectRoleVo">select distinct r.role_id, r.role_name, r.role_key, r.role_sort, r.data_scope, r.menu_check_strictly, r.dept_check_strictly,r.status, r.del_flag, r.create_time, r.remark from sys_role rleft join sys_user_role ur on ur.role_id = r.role_idleft join sys_user u on u.user_id = ur.user_idleft join sys_dept d on u.dept_id = d.dept_id
</sql>
<select id="selectRoleList" parameterType="SysRole" resultMap="SysRoleResult"><include refid="selectRoleVo"/>where r.del_flag = '0'<if test="roleId != null and roleId != 0">AND r.role_id = #{roleId}</if><if test="roleName != null and roleName != ''">AND r.role_name like concat('%', #{roleName}, '%')</if><if test="status != null and status != ''">AND r.status = #{status}</if><if test="roleKey != null and roleKey != ''">AND r.role_key like concat('%', #{roleKey}, '%')</if><if test="params.beginTime != null and params.beginTime != ''"><!-- 开始时间检索 -->and date_format(r.create_time,'%y%m%d') >= date_format(#{params.beginTime},'%y%m%d')</if><if test="params.endTime != null and params.endTime != ''"><!-- 结束时间检索 -->and date_format(r.create_time,'%y%m%d') <= date_format(#{params.endTime},'%y%m%d')</if><!-- 数据范围过滤 -->${params.dataScope}order by r.role_sort
</select>
大家可以看到,在 SQL 的最后面有一句 ${params.dataScope},就是把在 DataScopeAspect 切面中拼接的 SQL 追加进来。
所以这个 SQL 最终的形式类似下面这样:
select distinct r.role_id, r.role_name, r.role_key, r.role_sort, r.data_scope, r.menu_check_strictly, r.dept_check_strictly, r.status, r.del_flag, r.create_time, r.remark from sys_role r left join sys_user_role ur on ur.role_id = r.role_id left join sys_user u on u.user_id = ur.user_id left join sys_dept d on u.dept_id = d.dept_id where r.del_flag = '0' AND (d.dept_id IN ( SELECT dept_id FROM sys_role_dept WHERE role_id = 2 ) ) order by r.role_sort LIMIT ?
可以看到,追加了最后面的 SQL 之后,就实现了数据过滤(这里是根据自定义数据权限进行过滤)。
过滤的逻辑就是根据用户所属的部门 id 找到用户 id,然后根据用户 id 找到对应的角色 id,最后再把查询到的角色返回。
其实我觉得查询部门和查询用户进行数据过滤,这个都好理解,当前登录用户能够操作哪些部门,能够操作哪些用户,这些都容易理解,能操作哪些角色该如何理解呢?特别是上面这个查询 SQL 绕了一大圈,有的小伙伴可能会说,系统本来不就有一个 sys_role_dept 表吗?这个表就是关联角色信息和部门信息的,直接拿着用户的部门 id 来这张表中查询用户能操作的角色 id 不就行行了?此言差矣!这里我觉得大家应该这样来理解:用户所属的部门这是用户所属的部门,用户能操作的部门是能操作的部门,这两个之间没有必然联系。sys_user 表中的 dept_id 字段是表示这个用户所属的部门 id,而 sys_role_dept 表中是描述某一个角色能够操作哪些部门,这是不一样的,把这个捋清楚了,上面的 SQL 就好懂了。
4.3 查询用户
最后再来看查询用户。
查询用户的方法在 org.javaboy.tienchin.system.service.impl.SysUserServiceImpl#selectUserList 位置,对应的 SQL 如下
<select id="selectUserList" parameterType="SysUser" resultMap="SysUserResult">select u.user_id, u.dept_id, u.nick_name, u.user_name, u.email, u.avatar, u.phonenumber, u.password, u.sex, u.status, u.del_flag, u.login_ip, u.login_date, u.create_by, u.create_time, u.remark, d.dept_name, d.leader from sys_user uleft join sys_dept d on u.dept_id = d.dept_idwhere u.del_flag = '0'<if test="userId != null and userId != 0">AND u.user_id = #{userId}</if><if test="userName != null and userName != ''">AND u.user_name like concat('%', #{userName}, '%')</if><if test="status != null and status != ''">AND u.status = #{status}</if><if test="phonenumber != null and phonenumber != ''">AND u.phonenumber like concat('%', #{phonenumber}, '%')</if><if test="params.beginTime != null and params.beginTime != ''"><!-- 开始时间检索 -->AND date_format(u.create_time,'%y%m%d') >= date_format(#{params.beginTime},'%y%m%d')</if><if test="params.endTime != null and params.endTime != ''"><!-- 结束时间检索 -->AND date_format(u.create_time,'%y%m%d') <= date_format(#{params.endTime},'%y%m%d')</if><if test="deptId != null and deptId != 0">AND (u.dept_id = #{deptId} OR u.dept_id IN ( SELECT t.dept_id FROM sys_dept t WHERE find_in_set(#{deptId}, ancestors) ))</if><!-- 数据范围过滤 -->${params.dataScope}
</select>
这个就比较容易了,根据部门查询用户或者就是查询当前用户。最终生成的 SQL 类似下面这样(这是自定义数据权限,即根据用户部门查找用户):
select u.user_id, u.dept_id, u.nick_name, u.user_name, u.email, u.avatar, u.phonenumber, u.password, u.sex, u.status, u.del_flag, u.login_ip, u.login_date, u.create_by, u.create_time, u.remark, d.dept_name, d.leader from sys_user u left join sys_dept d on u.dept_id = d.dept_id where u.del_flag = '0' AND (d.dept_id IN ( SELECT dept_id FROM sys_role_dept WHERE role_id = 2 ) ) LIMIT ?
5. 小结
好啦,通过上面的分析,大家对于 @DataScope 应该也认识的差不多了吧?
相关文章:

ruoyi--数据权限
这篇文章我先和大家分析一下 RuoYi-Vue 脚手架中 DataScope 注解的实现原理,在 TienChin 项目视频中到时候还会有深入讲解。 1. 思路分析 首先我们先来捋一捋这里的权限实现的思路。 DataScope 注解处理的内容叫做数据权限,就是说你这个用户登录后能够…...
快速开发平台是什么?和传统开发平台相比有哪些区别?
本文可以从【快速开发平台的价值、和传统平台的区别、使用感受】三个方面来说明。 首先,我们要清楚快速开发平台是什么: 快速开发平台也称为低代码或无代码平台,旨在通过可视化工具、拖放式界面和预构建组件,使应用程序的开发过…...

Android基于JNI的Java与C++互调
java调用C++: #include <jni.h> //导出c函数格式 extern "C" JNIEXPORT //供JNI调用 JNICALL 函数名格式 Java_包名_类名_函数名(包名.替换为_) Java_com_example_getapplist_MainActivity_stringFromJNI 包名:com_example_getapplist 类名:MainActi…...
【算法与数据结构】513、LeetCode找树左下角的值
文章目录 一、题目二、解法三、完整代码 所有的LeetCode题解索引,可以看这篇文章——【算法和数据结构】LeetCode题解。 一、题目 二、解法 思路分析:这道题用层序遍历来做比较简单,最底层最左边节点就是层序遍历当中最底层元素容器的第一个值…...

React——组件缓存 react-activation
1、安装依赖 npm i -S react-activation 2、包裹根组件 import { AliveScope } from "react-activation"<AliveScope><App /> </AliveScope> 3、缓存组件 import { KeepAlive } from "react-activation"export default () > {co…...

EV代码签名证书是什么?
在数字世界中,很多软件和应用都需要进行代码签名,以确保其来源可靠和安全,EV代码签名证书恰好都能做到,那么EV代码签名证书是什么?它有什么功能特点呢?下面的内容可以给到答案。 EV代码签名证书是什么&…...

融媒行业落地客户旅程编排,详解数字化用户运营实战
移动互联网时代是流量红利的时代,企业常用低成本的方式进行获客,“增长黑客”的概念大范围传播。与此同时,机构媒体受到传播环境的影响,也开始启动全行业的媒体融合转型。在此背景下,2015 年神策数据成立,核…...
PDF制作成翻页电子书
在日常工作中,大部分人使用的都是PDF文档发送给客户,但是PDF文档通常是静态的,缺乏交互性和视觉吸引力。那你有没有想过把它转换成翻页的电子书呢? 小编将告诉你操作步骤,非常简单 1.搜索FLBOOK在线制作电子杂志平台 …...
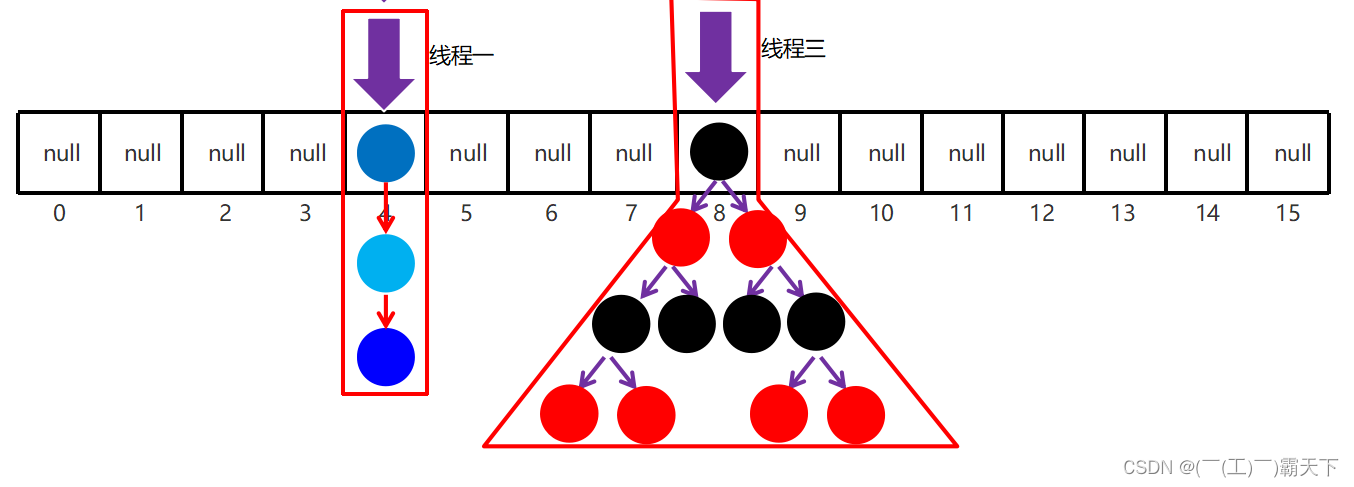
多线程
1. 线程池 1.1 线程状态介绍 当线程被创建并启动以后,它既不是一启动就进入了执行状态,也不是一直处于执行状态。线程对象在不同的时期有不同的状态。那么Java中的线程存在哪几种状态呢?Java中的线程 状态被定义在了java.lang.Thread.Stat…...

BingChat与ChatGPT比较,哪个聊天机器人能让你获益更多?
人工智能领域的最新进展为普通人创造新的收入来源提供了更多机会。今年早些时候,微软对OpenAI进行了大量投资。此后,微软在Microsoft Edge浏览器中推出了自家的聊天机器人Bing Chat。 在论坛和社交媒体上,你可以发现这两个AI工具都吸引了很…...
、XML)
Qt读写ini配置文件(QSettings)、XML
1、ini相关的 总结:Qt读写ini配置文件(QSettings) - 布丁Plus - 博客园 (cnblogs.com) Qt读写ini文件(含源码注释)_qt ini文件读写_lw向北.的博客-CSDN博客 2、XML相关的 Qt读写XML文件(含源码注释)_qt写xml_lw向北…...
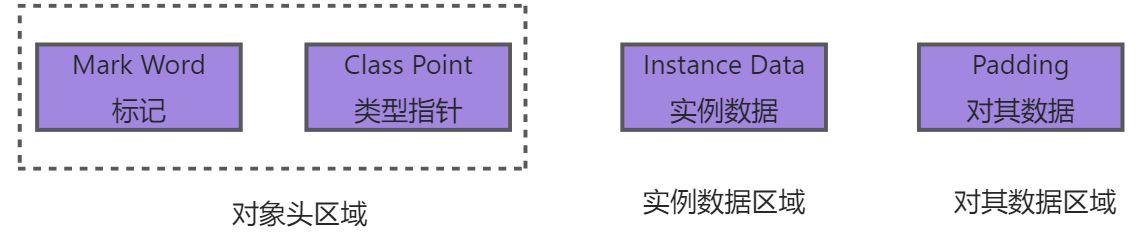
JVM知识点(二)
1、G1垃圾收集器 -XX:MaxGCPauseMillis10,G1的参数,表示在任意1s时间内,停顿时间不能超过10ms;G1将堆切分成很多小堆区(Region),每一个Region可以是Eden、Survivor或Old区;这些区在…...

代码随想录算法训练营day44 | LeetCode 518. 零钱兑换 II 377. 组合总和 Ⅳ
今晚学习了完全背包的做法,和01背包的差别具体来说就是一个可以重复,一个不可以重复。体现在数组的遍历中来说就是完全背包不能用二维数组做法(因为二维dp数组一定不会重复,但是还没验证过),只能用一维dp数…...

Vue2向Vue3过度核心技术工程化开发和脚手架
目录 1 工程化开发和脚手架1.1 开发Vue的两种方式1.2.脚手架Vue CLI 2 项目目录介绍和运行流程2.1 项目目录介绍2.2 运行流程 3 组件化开发4 根组件 App.vue4.1 根组件介绍4.2 组件是由三部分构成4.3 总结 5 普通组件的注册使用-局部注册5.1 特点:5.2 步骤ÿ…...

Expected all tensors to be on the same device, but found at least two devices
Expected all tensors to be on the same device, but found at least two devices, 原因是计算的过程中,两个不同类型的变量在一起进行运算,即一个变量存储在gpu中,一个变量存储在cpu中,两个变量的存储位置冲突,导致无…...

Mysql备份命令Mysqldump导入、导出以及压缩成zip、gz格式
1、导出 命令:mysqldump -u用户名 -p数据库密码 数据库名 > 文件名 如果用户名需要密码,则需要在此命令执行后输入一次密码核对;如果数据库用户名不需要密码,则不要加“-p”参数,导入的时候相同。注意输入的用户名…...
App卡帧与BlockCanary
作者:图个喜庆 一,前言 app卡帧一直是性能优化的一个重要方面,虽然现在手机硬件性能越来越高,明显的卡帧现象越来越少,但是了解卡帧相关的知识还是非常有必要的。 本文分两部分从app卡帧的原理出发,讨论屏…...

bpmnjs Properties-panel拓展(ExtensionElements拓展篇)
接上文bpmnjs Properties-panel拓展(属性设置篇),继续记录下第三个拓展需求的实现。 需求简述 在ExclusiveGateway标签的extensionElements标签中增加子标签<activiti:executionListener>子标签,可增加复数子标签。子标签…...
虚拟机的使用
首先需要安装VMware软件,这是虚拟机,在里面可以实现在windows的笔记本上运行包括,windows11和linux系统的开发和研究。 VMware是一种虚拟化技术,可以让你在一台物理计算机上运行多个操作系统和应用程序,而不需要重启或…...
CSS Flex布局
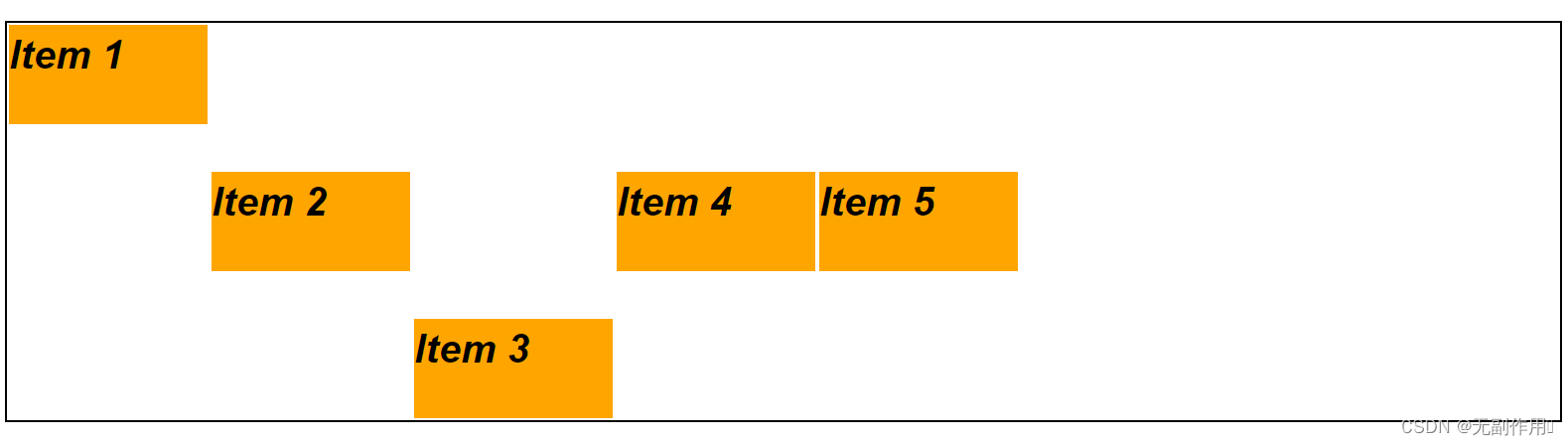
前言 Flex布局(弹性盒子布局) 是一种用于在容器中进行灵活和自适应布局的CSS布局模型。通过使用Flex布局,可以更方便地实现各种不同尺寸和比例的布局,使元素在容器内自动调整空间分配。 Flex-组成 Flex布局由以下几个主要组成部分…...

模块四-数据转换与操作——24. 数据分箱
24. 数据分箱 1. 概述 数据分箱(Binning)是将连续变量离散化的过程,将数值范围划分为多个区间,每个区间称为一个"箱"。分箱常用于将连续变量转换为分类变量,便于分析和建模。 import pandas as pd import nu…...

Intel Lunar Lake核显架构解析:Xe2-LPG如何重塑轻薄本图形性能
1. 项目概述:一次架构驱动的核显革命最近,Intel Lunar Lake(月亮湖)移动处理器的核显性能数据开始陆续曝光,行业内讨论的热度很高。作为一个长期关注移动平台图形性能的从业者,我第一时间梳理了目前能获取到…...

从白噪声到ARMA谱:平稳随机信号功率谱的实战解析
1. 平稳随机信号功率谱密度的工程意义 第一次接触功率谱密度这个概念时,我也被那一堆数学公式搞得头晕。直到有次在调试通信设备时,发现接收端总是有奇怪的干扰,导师让我做个频谱分析,这才真正明白功率谱密度到底有什么用。简单来…...

终极指南:三分钟掌握全网盘高速下载神器LinkSwift
终极指南:三分钟掌握全网盘高速下载神器LinkSwift 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼云盘…...

Numba-SciPy:无缝集成SciPy函数到Numba JIT编译的终极指南
1. 项目概述:当高性能计算遇上科学计算库如果你在Python高性能计算领域摸爬滚打过一阵子,大概率听说过Numba这个名字。它通过即时编译(JIT)技术,让纯Python代码,尤其是那些包含大量循环和数值运算的代码&am…...

【模块化设计-14】深入解析 RT-Thread syswatch 系统监控模块:保障系统稳定的核心卫士
在嵌入式系统开发中,系统的稳定性是重中之重。RT-Thread 提供的 syswatch(系统监控)模块,专为解决线程异常阻塞、保障系统持续运行设计。本文将从模块设计理念、核心功能、配置项、工作流程到实际测试,全方位解析 sysw…...

架构设计经验分享:从方法论到落地的完整实践
写在前面 “架构"是技术圈里被滥用最严重的词之一。很多人一说架构就开始画框图、讲中间件、列技术栈,但问一句"你这个架构解决了什么问题”,答不上来。 我做架构这些年,最深的体会是:架构不是技术选型的堆砌࿰…...

TI毫米波雷达IWR1642原始数据采集避坑指南:DCA1000配置、IQ顺序与帧大小限制
TI毫米波雷达IWR1642原始数据采集实战:DCA1000高级配置与数据解析精要 毫米波雷达在自动驾驶、工业检测等领域的应用日益广泛,而原始数据采集作为研发和算法验证的基础环节,其稳定性和准确性至关重要。本文将深入探讨IWR1642与DCA1000搭配使用…...

BACnet实战:从协议栈到楼宇自控系统集成
1. BACnet协议栈基础解析 第一次接触BACnet协议时,我被它复杂的文档和术语搞得晕头转向。经过几个实际项目的打磨,我发现理解这个协议最有效的方式就是从它的四层架构开始。BACnet采用了精简的OSI模型,只保留了最核心的四层:物理层…...

第14章:C++ 代码规范评审
第14章:C++ 代码规范评审 本章定位:第四卷《实战卷》第四篇"工程化与编译链接"第 14 章。 与第 13 章《静态分析工具》构成"机器查 + 人查"互补:能机器查的让 lint 拦,必须人脑判断的进 review。 目录 01.规范与评审定位 1.1 规范的三个层级 1.2 评审解…...