暴力递归转动态规划(二)
上一篇已经简单的介绍了暴力递归如何转动态规划,如果在暴力递归的过程中发现子过程中有重复解的情况,则证明这个暴力递归可以转化成动态规划。
这篇帖子会继续暴力递归转化动态规划的练习,这道题有点难度。
题目
给定一个整型数组arr[],代表数值不同的纸牌排成一条线。玩家A和玩家B依次拿走每张纸牌。规定玩家A先拿,玩家B后拿,但是每个玩家每次只能拿走最左边或者最右边的牌,玩家A和玩家B都绝顶聪明,请返回最后获胜者的分数。
暴力递归
依然是先从暴力递归开始写起,一个先手拿,一个后手拿,两个人都绝顶聪明,都知道怎么拿可以利益最大化。
先手的拿完第一个之后,再拿的时候,就要从后手拿完的数组里再挑选了。
同理,如果后手的等先手的拿了之后,是不是就可以从剩余的数组里挑选最大利益的拿了。
依然先确定base case:
如果先手拿,最理想的状态就是当数组剩下最后一个数,依然可以被我拿走。
如果后手拿,最悲催的连数组最后一个数我都拿不到。
代码中f()函数是代表在数组L~ R范围上返回上先手拿能拿到的最大值返回。
g()函数代表在数组L ~ R范围上后手拿,能够获取的最大值。
需要注意的是身份的转变,如果先手拿之后,再拿的时候就会变成后手,第二个后手拿的时候,虽然我是后手,但是也是从数组中挑选利益最大的拿,留给先手拿的人的也是不好的,所以我会变成先手。
//先手方法
public static int f(int[] arr,int L,int R){//base case:先手拿,并且数组中剩一个元素,我拿走if(L == R){return arr[L];}//因为可以选择从左边拿和右边拿,从左边拿下一次就是L + 1开始,右边拿就是 R - 1 开始。//需要注意的是我从左或者从右拿完之后,再拿就是拿别人拿剩下的了,要以后手姿态获取其余分数,所以要调用g()方法int p1 = arr[L] + g(arr,L + 1,R);int p2 = arr[R] + g(arr, L, R -1);//两种决策中取最大值return Math.max(p1,p2);
}
//后手方法
public static int g(int[] arr,int L,int R){//剩最后一个也不是我的,毛都拿不到,return 0if(L == R){return 0;}//后手方法是在先手方法后,挑选最大值,那如果先手方法选择了L,则我要从L + 1位置选,//如果先手选择了R,那我要从R - 1位置开始往下选。//是从对手选择后再次选择最大值int p1 = f(arr,L + 1,R);int p2 = f(arr,L,R - 1);//因为是后手,是在先手后做决定,是被迫的,所以取Min。return Math.min(p1,p2);
}
先手后手方法已经确定,来看主流程怎么调用
public static int win1(int[] arr){//如果是无效数组,则返回一个无效数字 -1 if(arr == null || arr.length == 0){return -1;}int first = f(arr, 0 ,arr.length - 1);int second = g(arr,0,arr.length - 1);return Math.max(first,second);
}
暴力递归的分析和代码已经搞定,接下来我们通过分析暴力递归的调用过程来实现第一步的优化,找它的依赖,找它的重复解。
举一个具体的例子,arr[]范围 0~ 7,根据上面暴力递归的代码逻辑,我们来看看它的依赖关系和调用过程。如果确定了可变参数以及依赖关系,是不是就可以尝试着优化成动态规划。
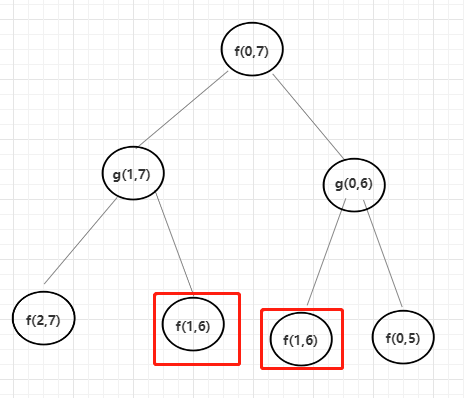
根据代码逻辑,要么是取左边L + 1,要么是取右边 R - 1,所以可以确定可变参数是L和R,并且整个流程下来会发现有重复解的情况。
不过有些不同的是,这个是双层递归循环依赖调用,所以如果根据可变参数参数L,R来构建缓存表的话,则需要2个不同的缓存表分别记录。
优化
前面已经分析出整个暴力递归的调用过程,并发现了重复解,其中可变参数是L、R,根据L、R构建缓存表,因为是f()和g()的循环依赖调用,所以需要准备两张缓存表。
public static int win2(int[] arr) {if (arr == null || arr.length == 0) {return -1;}int N = arr.length;int[][] fmap = new int[N][N];int[][] gmap = new int[N][N];for (int i = 0; i < N; i++) {for (int j = 0; j < N; j++) {fmap[i][j] = -1;gmap[i][j] = -1;}}int first = f1(arr, 0, arr.length - 1, fmap, gmap);int second = g1(arr, 0, arr.length - 1, fmap, gmap);return Math.max(first, second);}public static int f1(int[] arr, int L, int R, int[][] fmap, int[][] gmap) {// != -1,说明之前计算过该值,直接返回即可if (fmap[L][R] != -1) {return fmap[L][R];}int ans = 0;if (L == R){ans = arr[L];}else{int p1 = arr[L] + g1(arr, L + 1, R, fmap, gmap);int p2 = arr[R] + g1(arr, L, R - 1, fmap, gmap);ans = Math.max(p1, p2);}//这一步能够取得的最大值fmap[L][R] = ans;return ans;}public static int g1(int[] arr, int L, int R, int[][] fmap, int[][] gmap) {if (gmap[L][R] != -1){return gmap[L][R];}//因为如果 L == R,后手方法会返回0,默认ans也是等于0,省略一步判断int ans = 0;if (L != R){int p1 = f1(arr,L + 1,R,fmap,gmap);int p2 = f1(arr,L,R - 1,fmap,gmap);ans = Math.min(p1,p2);}gmap[L][R] = ans;return ans;}
二次优化
我们上面已经创建了缓存表,并找到了变量L、R,我们现在不妨举一个例子,并将缓存表画出来,来看一下表中每一列的对应关系,如果我们能找到这个缓存表的对应关系,是不是将表构建出来以后,就可以直接获取获胜者的最大值。
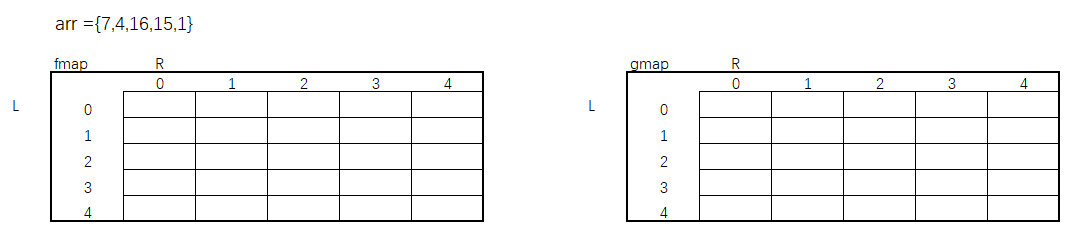
数组arr = {7,4,16,15,1} 因为有两张缓存表,所以需要将两张表的依赖关系都找出。接下来,回到最开始的暴力递归方法,根据代码逻辑一步一步找出依赖关系。
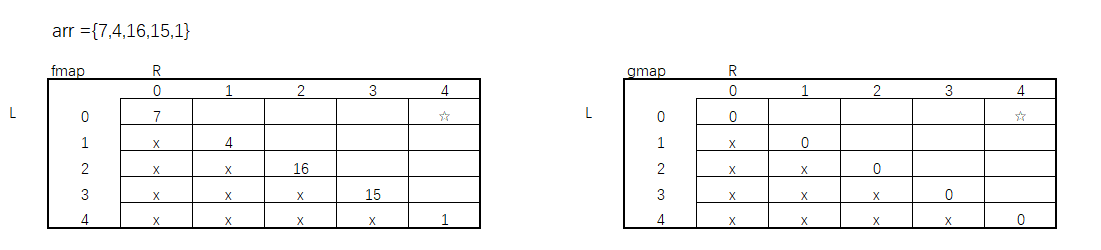
public static int win1(int[] arr) {if (arr == null || arr.length == 0) {return -1;}int first = f(arr, 0, arr.length - 1);int second = g(arr, 0, arr.length - 1);return Math.max(first, second);}public static int f(int[] arr, int L, int R) {if (L == R) {return arr[L];}int p1 = arr[L] + g(arr, L + 1, R);int p2 = arr[R] + g(arr, L, R - 1);return Math.max(p1, p2);}public static int g(int[] arr, int L, int R) {if (L == R) {return 0;}int p1 = f(arr, L + 1, R);int p2 = f(arr, L, R - 1);return Math.min(p1, p2);}
从先手方法f()和后手方法g()的base case可以看出,如果当L == R时,f()方法中此时就是等于数组arr[L]本身的值,而g()中为0,又因为,每次我只选L或只选R,当L = R时就return了,所以我的L始终不会 > R。我们所要求的L ~ R 范围是整个数组0 ~ 4的值,此时图可以填充成这样。
再来接着往下看,如果此时LR随便给一个值,比如说当前fmap中L = 1,R = 3,来接着看它的依赖过程。
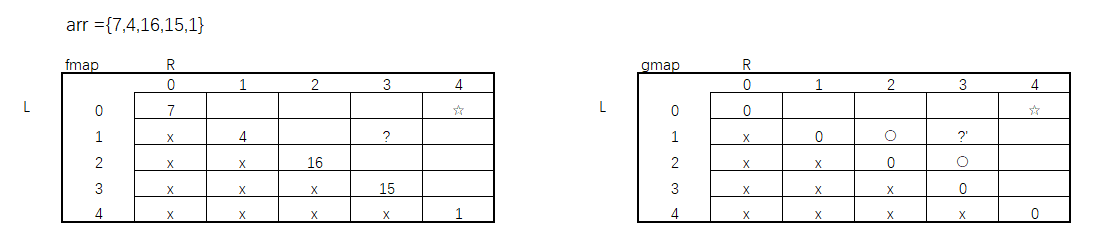
根据代码可以看出,它依赖的是g()方法中L +1和R - 1,所以对应在gmap中的依赖就是圆圈标记的部分。对应的,同样 L = 1 R = 3在gmap中也是依赖fmap对应的位置。
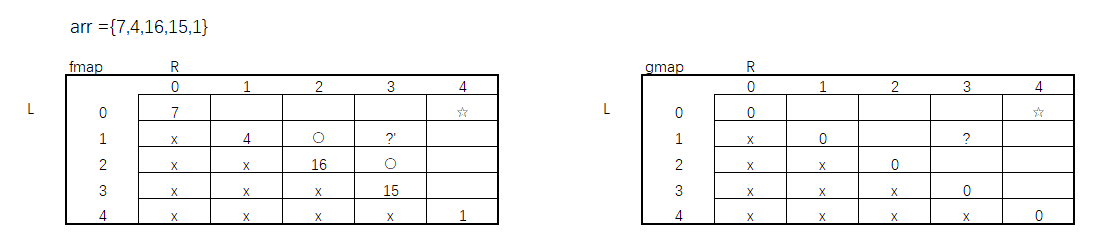
那现在有缓存表中每个位置的依赖关系,还有fmap和gmap当L == R时的值,是不是就可以推算出其他格子中的值。
代码
public static int win3(int[] arr) {if (arr == null || arr.length == 0) {return -1;}int N = arr.length;int[][] fmap = new int[N][N];int[][] gmap = new int[N][N];//根据base case填充fmap,gmap都是0,数组初始化值也是0,不用填充for (int i = 0; i < N; i++) {fmap[i][i] = arr[i];}//根据对角线填充,从第一列开始for (int startCol = 1; startCol < N; startCol++) {int L = 0;int R = startCol;while (R < N) {//将调用的g()和f()都替换成对应的缓存表fmap[L][R] = Math.max(arr[L] + gmap[L + 1][R], arr[R] + gmap[L][R - 1]);gmap[L][R] = Math.min(fmap[L + 1][R], fmap[L][R - 1]);L++;R++;}}//最后从L ~ R位置,取最大值return Math.max(fmap[0][N -1],gmap[0][N-1]);}
相关文章:
暴力递归转动态规划(二)
上一篇已经简单的介绍了暴力递归如何转动态规划,如果在暴力递归的过程中发现子过程中有重复解的情况,则证明这个暴力递归可以转化成动态规划。 这篇帖子会继续暴力递归转化动态规划的练习,这道题有点难度。 题目 给定一个整型数组arr[]&…...

debian apt error: Package ‘xxx‘ has no installation candidate
新的debian虚拟机可能会出现这个问题。 修改apt的source.list,位于/etc/apt/source.list,添加两行: deb http://deb.debian.org/debian bullseye main deb-src http://deb.debian.org/debian bullseye main执行: sudo apt-get u…...
c#设计模式-结构型模式 之 外观模式
概述 外观模式(Facade Pattern)又名门面模式,隐藏系统的复杂性,并向客户端提供了一个客户端可以访问系统的接口。这种类型的设计模式属于结构型模式,它向现有的系统添加一个接口,来隐藏系统的复杂性。该模式…...

Focal Loss-解决样本标签分布不平衡问题
文章目录 背景交叉熵损失函数平衡交叉熵函数 Focal Loss损失函数Focal Loss vs Balanced Cross EntropyWhy does Focal Loss work? 针对VidHOI数据集Reference 背景 Focal Loss由何凯明提出,最初用于图像领域解决数据不平衡造成的模型性能问题。 交叉熵损失函数 …...

运算符(个人学习笔记黑马学习)
算数运算符 加减乘除 #include <iostream> using namespace std;int main() {int a1 10;int a2 20;cout << a1 a2 << endl;cout << a1 - a2 << endl;cout << a1 * a2 << endl;cout << a1 / a2 << endl;/*double a3 …...

开源与专有软件:比较与对比
🌷🍁 博主猫头虎 带您 Go to New World.✨🍁 🦄 博客首页——猫头虎的博客🎐 🐳《面试题大全专栏》 文章图文并茂🦕生动形象🦖简单易学!欢迎大家来踩踩~🌺 &a…...

openResty+lua+redis实现接口访问频率限制
openResty简介: OpenResty 是一个基于 Nginx 与 Lua 的高性能 Web 平台,其内部集成了大量精良的 Lua 库、第三方模块以及大多数的依赖项。用于方便地搭建能够处理超高并发、扩展性极高的动态 Web 应用、Web 服务和动态网关。 OpenResty 通过汇聚各种设…...
自动化测试(三):接口自动化pytest测试框架
文章目录 1. 接口自动化的实现2. 知识要点及实践2.1 requests.post传递的参数本质2.2 pytest单元测试框架2.2.1 pytest框架简介2.2.2 pytest装饰器2.2.3 断言、allure测试报告2.2.4 接口关联、封装改进YAML动态传参(热加载) 2.3 pytest接口封装ÿ…...

Python --datetime模块
目录 1, 获取datetime时间 2, datetime与timestamp转换 2-1, datetime转timestamp 2-2, timestamp转datetime 3, str格式与datetime转换 3-1, datetime转str格式 3-2, str格式转datetime…...
顺序表链表OJ题(3)——【数据结构】
W...Y的主页 😊 代码仓库分享 💕 前言: 今天是链表顺序表OJ练习题最后一次分享,每一次的分享题目的难度也再有所提高,但是我相信大家都是非常机智的,希望看到博主文章能学到东西的可以一键三连关注一下博主…...

【Azure】Virtual Hub vWAN
虚拟 WAN 文档 Azure 虚拟 WAN 是一个网络服务,其中整合了多种网络、安全和路由功能,提供单一操作界面。 我们主要讨论两种连接情况: 通过一个 vWAN 来连接不通的 vNET 和本地网络。以下是一个扩展的拓扑 结合 vhub,可以把两个中…...

React Navigation 使用导航
在 Web 浏览器中,您可以使用锚标记链接到不同的页面。当用户单击链接时,URL 会被推送到浏览器历史记录堆栈中。当用户按下后退按钮时,浏览器会从历史堆栈顶部弹出该项目,因此活动页面现在是以前访问过的页面。React Native 不像 W…...
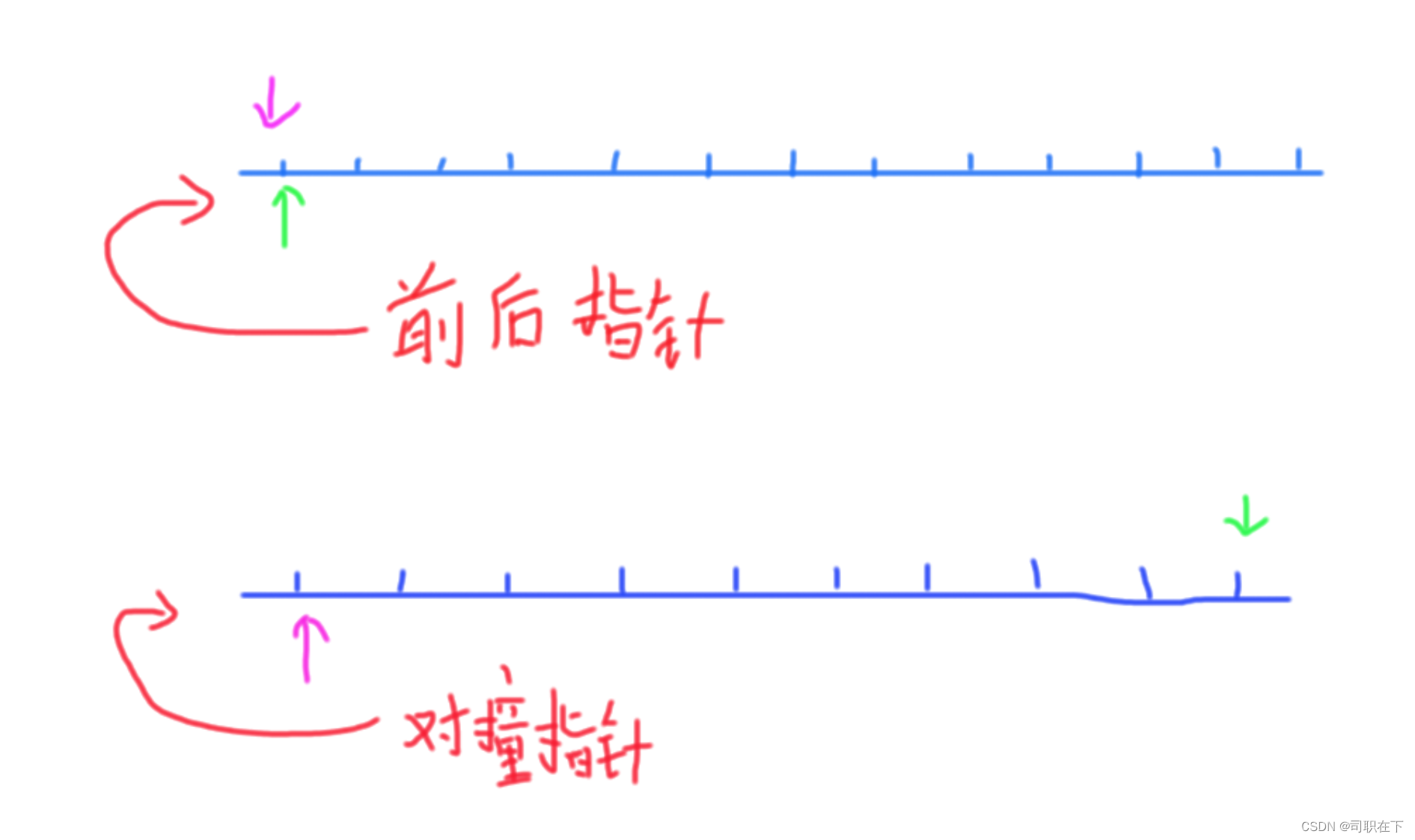
双指针算法,基础算法实践,基本的算法的思想,双指针算法的实现
一,定义 双指针算法是一种常用于解决数组和链表问题的算法技巧。它的核心思想是使用两个指针在数据结构中按照一定的规则移动,从而达到快速搜索或处理数据的目的。这个技巧通常用于优化算法,降低时间复杂度,提高程序的执行效率。…...
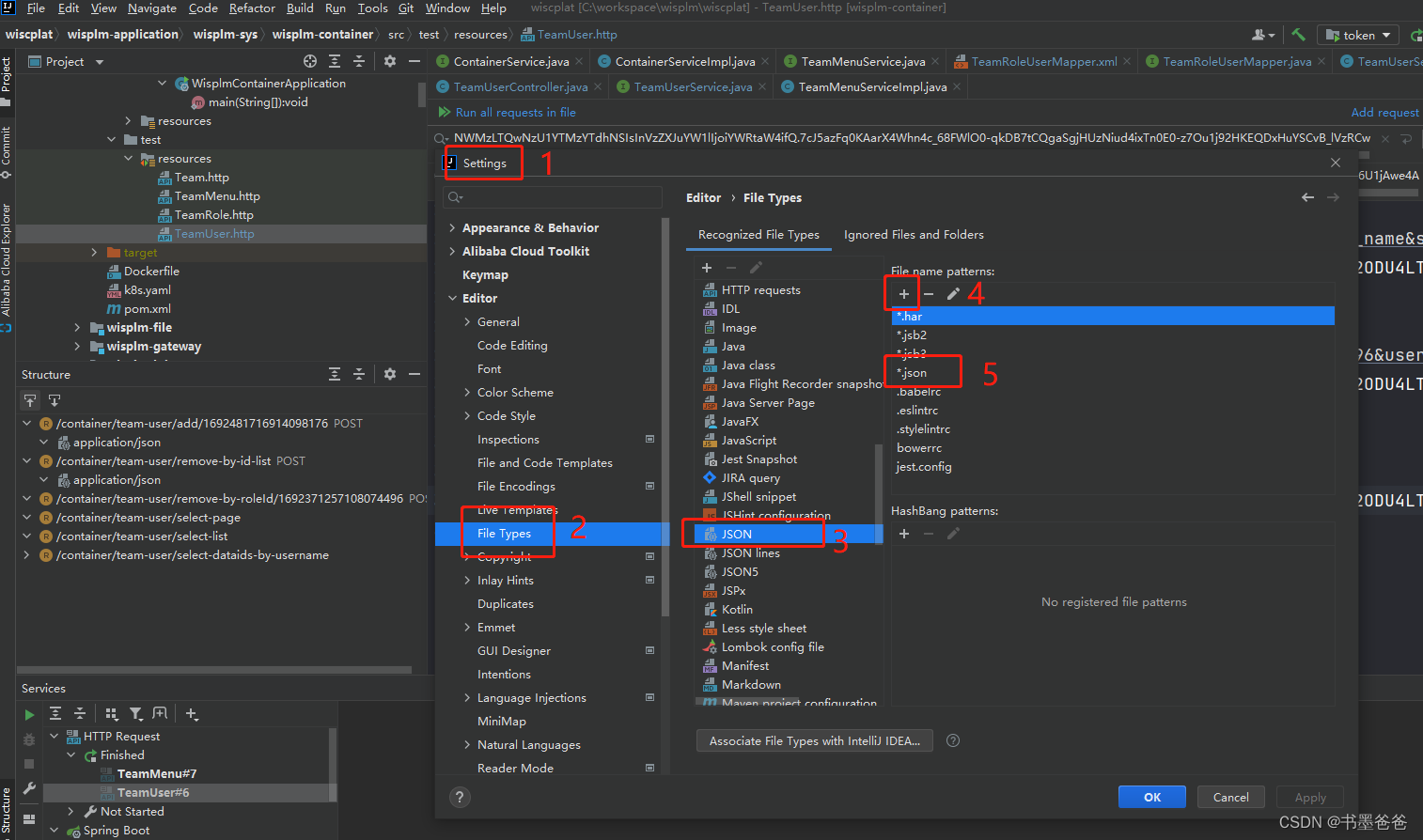
idea http request无法识别环境变量
问题描述 创建了环境变量文件 http-client.env.json,然后在*.http 文件中引用环境变量,运行 HTTP 请求无法读取环境变量文件中定义的变量。 事故现场 IDEA 版本:2020.2 2021.2 解决步骤 2020.2 版本环境变量无法读取 2021.2 版本从 2020.…...

性能测试常见的测试指标
一、什么是性能测试 先看下百度百科对它的定义 性能测试是通过自动化的测试工具模拟多种正常、峰值以及异常负载条件来对系统的各项性能指标进行测试。我们可以认为性能测试是:通过在测试环境下对系统或构件的性能进行探测,用以验证在生产环境下系统性能…...
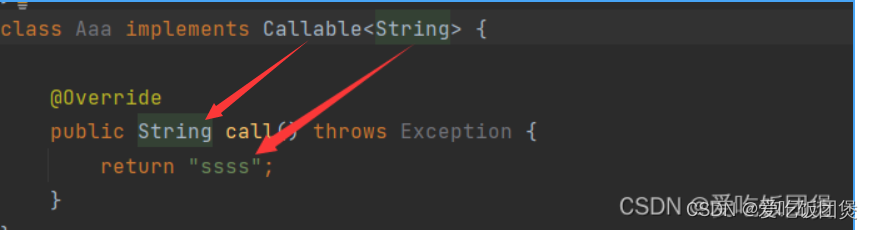
并发 04(Callable,CountDownLatch)详细讲解
并发 Callable 1 可以返回值 2可以抛出异常 泛型指的是返回值的类型 public class Send {public static void main(String[] args) {//怎么启动Callable//new Thread().start();Aaa threadnew Aaa();FutureTask futureTasknew FutureTask(thread);new Thread(futureTask,&qu…...

Json路径表达式
原json路径 {"timeStamp": "20220801110008","transIDO": "6ba9088c981b407fb38feasdf09","version": "1.0.0","signMethod": "md5","content": "{\"companyName\&quo…...

【uniapp 上传图片示例】
以下是 uniapp 上传图片的详细步骤示例: 定义一个方法,用于选择图片并上传: methods: {chooseImage() {uni.chooseImage({count: 1, // 最多选择的图片数量sizeType: [original, compressed], // 可以指定原图或压缩图sourceType: [album, …...

apache2配置文件 Require all granted是什么意思
修改apache2的配置文件 /etc/apache2/apache2.conf,需要增加网站代码的路径,下列配置是什么意思呢 <Directory "/var/www/html">Options FollowSymLinksAllowOverride AllRequire all granted </Directory> 1. Options Options …...

c/c++ 的一些知识
c 面向对象是一种思想,通常情况下都是以组合为主,也就是在子类里定义一个基类struct base_t {void (*method)(base_t *base_p); };struct children_t {int a;int b;base_t base;void (*method)(children_t *children_p); };children_t children_creat(i…...

Ketcher:三步掌握开源化学绘图工具的完整使用指南
Ketcher:三步掌握开源化学绘图工具的完整使用指南 【免费下载链接】ketcher Web-based molecule sketcher 项目地址: https://gitcode.com/gh_mirrors/ke/ketcher 你是否曾因绘制复杂分子结构而烦恼?传统化学绘图软件要么操作复杂,要么…...

Spek音频频谱分析器:3分钟掌握专业音频分析技术
Spek音频频谱分析器:3分钟掌握专业音频分析技术 【免费下载链接】spek Acoustic spectrum analyser 项目地址: https://gitcode.com/gh_mirrors/sp/spek 音频频谱分析是理解音频文件内在结构的关键技术,而Spek正是这一领域的专业工具。这款免费开…...

基于Circuit Playground Express与MakeCode的阿基米德螺旋桨智能小船制作
1. 项目概述:当古老智慧遇见现代创客阿基米德螺旋,这个诞生于两千多年前的巧妙发明,最初被用来从低处向高处提水。它的核心原理简单而强大:一个旋转的螺旋面,能将流体或颗粒物沿着轴向“推”动。今天,我们不…...

深度解析RPG资源解密:Java-RPG-Maker-MV-Decrypter的3大核心技术揭秘
深度解析RPG资源解密:Java-RPG-Maker-MV-Decrypter的3大核心技术揭秘 【免费下载链接】Java-RPG-Maker-MV-Decrypter You can decrypt whole RPG-Maker MV Directories with this Program, it also has a GUI. 项目地址: https://gitcode.com/gh_mirrors/ja/Java-…...

ZoneMinder开源监控系统:30分钟打造专业级安防解决方案,支持IP/USB/模拟摄像头全兼容
ZoneMinder开源监控系统:30分钟打造专业级安防解决方案,支持IP/USB/模拟摄像头全兼容 【免费下载链接】zoneminder ZoneMinder is a free, open source Closed-circuit television software application developed for Linux which supports IP, USB and…...
)
2026年小白程序员必看:5项吃香AI技能,助你薪资翻倍(建议收藏)
2026年小白程序员必看:5项吃香AI技能,助你薪资翻倍(建议收藏) 随着AI大模型重构职场规则,掌握相关技能将极大提升工作效率和薪资。本文为小白和程序员推荐了5项最吃香的AI技能:RAG、提示词工程、多模态大模…...

macOS开发环境标准化实践:基于Homebrew的CUR环境构建
1. 项目概述与核心价值最近在折腾macOS开发环境,尤其是涉及到一些需要特定编译工具链的项目时,经常被各种依赖和版本问题搞得焦头烂额。相信很多从Linux或Windows转过来的开发者都有同感,macOS虽然优雅,但在某些底层开发工具的生态…...

书匠策AI到底在干嘛?用“拆快递“的方式,给你科普它的毕业论文功能全流程
各位同学,你们有没有拆过那种"一步一步跟着说明书就能装好"的宜家家具? 今天我要用拆快递的逻辑,帮你把书匠策AI(官网:h 官网直达:www.shujiangce.com,微信公众号搜一搜"书匠策…...

如何免费解锁英雄联盟历史回放?ROFL-Player终极解决方案
如何免费解锁英雄联盟历史回放?ROFL-Player终极解决方案 【免费下载链接】ROFL-Player (No longer supported) One stop shop utility for viewing League of Legends replays! 项目地址: https://gitcode.com/gh_mirrors/ro/ROFL-Player 你是否曾因为英雄联…...

工业 DC-DC 性能深度对比解析|钡特电源 DF1-05D15LS 与 E0515S-1WR3 封装互通
在工业控制、仪器仪表、低功耗传感设备等场景中,1W 级隔离工业 DC-DC 模块因体积小、功率密度高、适配性强,成为硬件研发工程师常用的直流电源模块核心器件。随着国产化进程加速,国产工业 DC-DC 模块在性能、稳定性、性价比上逐步实现突破&am…...