[oneAPI] 基于BERT预训练模型的SWAG问答任务
[oneAPI] 基于BERT预训练模型的SWAG问答任务
- 基于Intel® DevCloud for oneAPI下的Intel® Optimization for PyTorch
- 基于BERT预训练模型的SWAG问答任务
- 数据集下载和描述
- 数据集构建
- 问答选择模型
- 训练
- 结果
- 参考资料
比赛:https://marketing.csdn.net/p/f3e44fbfe46c465f4d9d6c23e38e0517
Intel® DevCloud for oneAPI:https://devcloud.intel.com/oneapi/get_started/aiAnalyticsToolkitSamples/
基于Intel® DevCloud for oneAPI下的Intel® Optimization for PyTorch
在Intel® DevCloud for oneAPI平台上,我们搭建了实验环境,充分发挥其完全虚拟化的优势,使我们能够专注于模型开发和优化,无需过多关心底层配置和维护工作。为了进一步提升我们的实验效果,我们充分利用了Intel® Optimization for PyTorch,将其应用于我们的PyTorch模型中,从而实现了高效的优化。这一优化策略不仅提升了模型的训练速度和推断性能,还使模型在英特尔硬件上的表现更加卓越,从而加速了实验的整体进程。
在我们的实验中,我们选择了Bert预训练模型,并将其应用于SQuAD英文问答任务中。通过数据预处理、Fine-tuning等步骤,我们成功地将Bert模型应用于问答任务中,取得了令人满意的效果。在这一过程中,Intel® Optimization for PyTorch的应用进一步加速了模型的训练和推断过程,提高了整体效率。
这一实验方案不仅仅是技术上的创新,更是在实际应用中带来的价值。通过提升模型的性能,我们不仅可以更快地训练和部署模型,还可以提供更高质量的问答结果,从而提升用户体验。这对于自然语言处理领域的研究和应用都具有重要意义。
基于BERT预训练模型的SWAG问答任务
SWAG任务是一项常见的自然语言处理任务,旨在对给定的句子上下文中的多个选项进行排列,从而确定最可能的下一句。该任务有助于模型理解句子的语境和逻辑,具有广泛的应用价值。下来介绍该任务的我们使用的解决方案:
- 数据准备: 首先,从SWAG数据集中获取句子上下文和多个选项。每个样本包含一个上下文句子以及四个候选选项,其中一个是正确的。需要将这些文本数据转换成Bert模型可以理解的输入格式。
- 预训练模型选择: 选择合适的预训练Bert模型,如BERT-base或BERT-large。这些模型在大规模语料库上进行了预训练,捕捉了丰富的语义信息。
- Fine-tuning: 将预训练的Bert模型应用于SWAG任务,使用已标注的训练数据进行Fine-tuning。在Fine-tuning时,使用正确的选项作为标签,通过最大化正确选项的预测概率来优化模型。
- 模型推断: 使用Fine-tuned的模型对测试数据进行预测,从多个选项中选择最可能的下一句。
数据集下载和描述
在这里,我们使用到的也是论文中所提到的SWAG(The Situations With Adversarial Generations )数据集,即给定一个情景(一个问题或一句描述),任务是模型从给定的四个选项中预测最有可能的一个。
如下所示便是部分原始示例数据:
1 ,video-id,fold-ind,startphrase,sent1,sent2,gold-source,ending0,ending1,ending2,ending3,label
2 0,anetv_NttjvRpSdsI,19391,The people are in robes. They,The people are in robes.,They,gold,are wearing colorful costumes.,are doing karate moves on the floor.,shake hands on their hips.,do a flip to the bag.,0
3 1,lsmdc3057_ROBIN_HOOD-27684,16344,She smirks at someone and rides off. He,She smirks at someone and rides off.,He,gold,smiles and falls heavily.,wears a bashful smile.,kneels down behind her.,gives him a playful glance.,1
如上所示数据集中一共有12个字段包含两个样本,我们这里需要用到的就是sent1,ending0,ending1,ending2,ending3,label这6个字段。例如对于第一个样本来说,其形式如下:
The people are in robes. TheyA) wearing colorful costumes.# 正确选项B) are doing karate moves on the floor.C) shake hands on their hips. D) do a flip to the bag.
同时,由于该数据集已经做了训练集、验证集和测试集(没有标签)的划分,所以后续我们也就不需要来手动划分了。
数据集构建
import torch
from torch.utils.data import DataLoader
from tqdm import tqdm
import pandas as pd
import json
import logging
import os
from sklearn.model_selection import train_test_split
import collections
import sixclass Vocab:"""根据本地的vocab文件,构造一个词表vocab = Vocab()print(vocab.itos) # 得到一个列表,返回词表中的每一个词;print(vocab.itos[2]) # 通过索引返回得到词表中对应的词;print(vocab.stoi) # 得到一个字典,返回词表中每个词的索引;print(vocab.stoi['我']) # 通过单词返回得到词表中对应的索引print(len(vocab)) # 返回词表长度"""UNK = '[UNK]'def __init__(self, vocab_path):self.stoi = {}self.itos = []with open(vocab_path, 'r', encoding='utf-8') as f:for i, word in enumerate(f):w = word.strip('\n')self.stoi[w] = iself.itos.append(w)def __getitem__(self, token):return self.stoi.get(token, self.stoi.get(Vocab.UNK))def __len__(self):return len(self.itos)def build_vocab(vocab_path):"""vocab = Vocab()print(vocab.itos) # 得到一个列表,返回词表中的每一个词;print(vocab.itos[2]) # 通过索引返回得到词表中对应的词;print(vocab.stoi) # 得到一个字典,返回词表中每个词的索引;print(vocab.stoi['我']) # 通过单词返回得到词表中对应的索引"""return Vocab(vocab_path)def pad_sequence(sequences, batch_first=False, max_len=None, padding_value=0):"""对一个List中的元素进行paddingPad a list of variable length Tensors with ``padding_value``a = torch.ones(25)b = torch.ones(22)c = torch.ones(15)pad_sequence([a, b, c],max_len=None).size()torch.Size([25, 3])sequences:batch_first: 是否把batch_size放到第一个维度padding_value:max_len :当max_len = 50时,表示以某个固定长度对样本进行padding,多余的截掉;当max_len=None是,表示以当前batch中最长样本的长度对其它进行padding;Returns:"""if max_len is None:max_len = max([s.size(0) for s in sequences])out_tensors = []for tensor in sequences:if tensor.size(0) < max_len:tensor = torch.cat([tensor, torch.tensor([padding_value] * (max_len - tensor.size(0)))], dim=0)else:tensor = tensor[:max_len]out_tensors.append(tensor)out_tensors = torch.stack(out_tensors, dim=1)if batch_first:return out_tensors.transpose(0, 1)return out_tensorsdef cache(func):"""本修饰器的作用是将SQuAD数据集中data_process()方法处理后的结果进行缓存,下次使用时可直接载入!:param func::return:"""def wrapper(*args, **kwargs):filepath = kwargs['filepath']postfix = kwargs['postfix']data_path = filepath.split('.')[0] + '_' + postfix + '.pt'if not os.path.exists(data_path):logging.info(f"缓存文件 {data_path} 不存在,重新处理并缓存!")data = func(*args, **kwargs)with open(data_path, 'wb') as f:torch.save(data, f)else:logging.info(f"缓存文件 {data_path} 存在,直接载入缓存文件!")with open(data_path, 'rb') as f:data = torch.load(f)return datareturn wrapperclass LoadSingleSentenceClassificationDataset:def __init__(self,vocab_path='./vocab.txt', #tokenizer=None,batch_size=32,max_sen_len=None,split_sep='\n',max_position_embeddings=512,pad_index=0,is_sample_shuffle=True):""":param vocab_path: 本地词表vocab.txt的路径:param tokenizer::param batch_size::param max_sen_len: 在对每个batch进行处理时的配置;当max_sen_len = None时,即以每个batch中最长样本长度为标准,对其它进行padding当max_sen_len = 'same'时,以整个数据集中最长样本为标准,对其它进行padding当max_sen_len = 50, 表示以某个固定长度符样本进行padding,多余的截掉;:param split_sep: 文本和标签之前的分隔符,默认为'\t':param max_position_embeddings: 指定最大样本长度,超过这个长度的部分将本截取掉:param is_sample_shuffle: 是否打乱训练集样本(只针对训练集)在后续构造DataLoader时,验证集和测试集均指定为了固定顺序(即不进行打乱),修改程序时请勿进行打乱因为当shuffle为True时,每次通过for循环遍历data_iter时样本的顺序都不一样,这会导致在模型预测时返回的标签顺序与原始的顺序不一样,不方便处理。"""self.tokenizer = tokenizerself.vocab = build_vocab(vocab_path)self.PAD_IDX = pad_indexself.SEP_IDX = self.vocab['[SEP]']self.CLS_IDX = self.vocab['[CLS]']# self.UNK_IDX = '[UNK]'self.batch_size = batch_sizeself.split_sep = split_sepself.max_position_embeddings = max_position_embeddingsif isinstance(max_sen_len, int) and max_sen_len > max_position_embeddings:max_sen_len = max_position_embeddingsself.max_sen_len = max_sen_lenself.is_sample_shuffle = is_sample_shuffle@cachedef data_process(self, filepath, postfix='cache'):"""将每一句话中的每一个词根据字典转换成索引的形式,同时返回所有样本中最长样本的长度:param filepath: 数据集路径:return:"""raw_iter = open(filepath, encoding="utf8").readlines()data = []max_len = 0for raw in tqdm(raw_iter, ncols=80):line = raw.rstrip("\n").split(self.split_sep)s, l = line[0], line[1]tmp = [self.CLS_IDX] + [self.vocab[token] for token in self.tokenizer(s)]if len(tmp) > self.max_position_embeddings - 1:tmp = tmp[:self.max_position_embeddings - 1] # BERT预训练模型只取前512个字符tmp += [self.SEP_IDX]tensor_ = torch.tensor(tmp, dtype=torch.long)l = torch.tensor(int(l), dtype=torch.long)max_len = max(max_len, tensor_.size(0))data.append((tensor_, l))return data, max_lendef load_train_val_test_data(self, train_file_path=None,val_file_path=None,test_file_path=None,only_test=False):postfix = str(self.max_sen_len)test_data, _ = self.data_process(filepath=test_file_path, postfix=postfix)test_iter = DataLoader(test_data, batch_size=self.batch_size,shuffle=False, collate_fn=self.generate_batch)if only_test:return test_itertrain_data, max_sen_len = self.data_process(filepath=train_file_path,postfix=postfix) # 得到处理好的所有样本if self.max_sen_len == 'same':self.max_sen_len = max_sen_lenval_data, _ = self.data_process(filepath=val_file_path,postfix=postfix)train_iter = DataLoader(train_data, batch_size=self.batch_size, # 构造DataLoadershuffle=self.is_sample_shuffle, collate_fn=self.generate_batch)val_iter = DataLoader(val_data, batch_size=self.batch_size,shuffle=False, collate_fn=self.generate_batch)return train_iter, test_iter, val_iterdef generate_batch(self, data_batch):batch_sentence, batch_label = [], []for (sen, label) in data_batch: # 开始对一个batch中的每一个样本进行处理。batch_sentence.append(sen)batch_label.append(label)batch_sentence = pad_sequence(batch_sentence, # [batch_size,max_len]padding_value=self.PAD_IDX,batch_first=False,max_len=self.max_sen_len)batch_label = torch.tensor(batch_label, dtype=torch.long)return batch_sentence, batch_labelclass LoadMultipleChoiceDataset(LoadSingleSentenceClassificationDataset):def __init__(self, num_choice=4, **kwargs):super(LoadMultipleChoiceDataset, self).__init__(**kwargs)self.num_choice = num_choice@cachedef data_process(self, filepath, postfix='cache'):data = pd.read_csv(filepath)questions = data['startphrase']answers0, answers1 = data['ending0'], data['ending1']answers2, answers3 = data['ending2'], data['ending3']labels = [-1] * len(questions)if 'label' in data: # 测试集中没有标签labels = data['label']all_data = []max_len = 0for i in tqdm(range(len(questions)), ncols=80):# 将问题中的每个word转换为字典中的token idt_q = [self.vocab[token] for token in self.tokenizer(questions[i])]t_q = [self.CLS_IDX] + t_q + [self.SEP_IDX]# 将答案中的每个word转换为字典中的token idt_a0 = [self.vocab[token] for token in self.tokenizer(answers0[i])]t_a1 = [self.vocab[token] for token in self.tokenizer(answers1[i])]t_a2 = [self.vocab[token] for token in self.tokenizer(answers2[i])]t_a3 = [self.vocab[token] for token in self.tokenizer(answers3[i])]# 计算最长序列的长度max_len = max(max_len, len(t_q) + max(len(t_a0), len(t_a1), len(t_a2), len(t_a3)))seg_q = [0] * len(t_q)# 加1表示还要加上问题和答案组合后最后一个[SEP]的长度seg_a0 = [1] * (len(t_a0) + 1)seg_a1 = [1] * (len(t_a1) + 1)seg_a2 = [1] * (len(t_a2) + 1)seg_a3 = [1] * (len(t_a3) + 1)all_data.append((t_q, t_a0, t_a1, t_a2, t_a3, seg_q,seg_a0, seg_a1, seg_a2, seg_a3, labels[i]))return all_data, max_lendef generate_batch(self, data_batch):batch_qa, batch_seg, batch_label = [], [], []def get_seq(q, a):seq = q + aif len(seq) > self.max_position_embeddings - 1:seq = seq[:self.max_position_embeddings - 1]return torch.tensor(seq + [self.SEP_IDX], dtype=torch.long)for item in data_batch:# 得到 每个问题组合其中一个答案的 input_ids 序列tmp_qa = [get_seq(item[0], item[1]),get_seq(item[0], item[2]),get_seq(item[0], item[3]),get_seq(item[0], item[4])]# 得到 每个问题组合其中一个答案的 token_type_idsseg0 = (item[5] + item[6])[:self.max_position_embeddings]seg1 = (item[5] + item[7])[:self.max_position_embeddings]seg2 = (item[5] + item[8])[:self.max_position_embeddings]seg3 = (item[5] + item[9])[:self.max_position_embeddings]tmp_seg = [torch.tensor(seg0, dtype=torch.long),torch.tensor(seg1, dtype=torch.long),torch.tensor(seg2, dtype=torch.long),torch.tensor(seg3, dtype=torch.long)]batch_qa.extend(tmp_qa)batch_seg.extend(tmp_seg)batch_label.append(item[-1])batch_qa = pad_sequence(batch_qa, # [batch_size*num_choice,max_len]padding_value=self.PAD_IDX,batch_first=True,max_len=self.max_sen_len)batch_mask = (batch_qa == self.PAD_IDX).view([-1, self.num_choice, batch_qa.size(-1)])# reshape 至 [batch_size, num_choice, max_len]batch_qa = batch_qa.view([-1, self.num_choice, batch_qa.size(-1)])batch_seg = pad_sequence(batch_seg, # [batch_size*num_choice,max_len]padding_value=self.PAD_IDX,batch_first=True,max_len=self.max_sen_len)# reshape 至 [batch_size, num_choice, max_len]batch_seg = batch_seg.view([-1, self.num_choice, batch_seg.size(-1)])batch_label = torch.tensor(batch_label, dtype=torch.long)return batch_qa, batch_seg, batch_mask, batch_label
问答选择模型
我们只需要在原始BERT模型的基础上再加一个分类层即可,因此这部分代码相对来说也比较容易理解
定义一个类以及相应的初始化函数
from model.Bert import BertModel
import torch.nn as nnclass BertForMultipleChoice(nn.Module):"""用于类似SWAG数据集的下游任务"""def __init__(self, config, bert_pretrained_model_dir=None):super(BertForMultipleChoice, self).__init__()self.num_choice = config.num_labelsif bert_pretrained_model_dir is not None:self.bert = BertModel.from_pretrained(config, bert_pretrained_model_dir)else:self.bert = BertModel(config)self.dropout = nn.Dropout(config.hidden_dropout_prob)self.classifier = nn.Linear(config.hidden_size, 1)def forward(self, input_ids,attention_mask=None,token_type_ids=None,position_ids=None,labels=None):""":param input_ids: [batch_size, num_choice, src_len]:param attention_mask: [batch_size, num_choice, src_len]:param token_type_ids: [batch_size, num_choice, src_len]:param position_ids::param labels::return:"""flat_input_ids = input_ids.view(-1, input_ids.size(-1)).transpose(0, 1)flat_token_type_ids = token_type_ids.view(-1, token_type_ids.size(-1)).transpose(0, 1)flat_attention_mask = attention_mask.view(-1, token_type_ids.size(-1))pooled_output, _ = self.bert(input_ids=flat_input_ids, # [src_len,batch_size*num_choice]attention_mask=flat_attention_mask, # [batch_size*num_choice,src_len]token_type_ids=flat_token_type_ids, # [src_len,batch_size*num_choice]position_ids=position_ids)pooled_output = self.dropout(pooled_output) # [batch_size*num_choice, hidden_size]logits = self.classifier(pooled_output) # [batch_size*num_choice, 1]shaped_logits = logits.view(-1, self.num_choice) # [batch_size, num_choice]if labels is not None:loss_fct = nn.CrossEntropyLoss()loss = loss_fct(shaped_logits, labels.view(-1))return loss, shaped_logitselse:return shaped_logits
定义一个ModelConfig类来对分类模型中的超参数以及其它变量进行管理,代码如下所示:
class ModelConfig:def __init__(self):self.project_dir = os.path.dirname(os.path.abspath(__file__))self.dataset_dir = os.path.join(self.project_dir, 'MultipleChoice')self.pretrained_model_dir = os.path.join(self.project_dir, "weight")self.vocab_path = os.path.join(self.pretrained_model_dir, 'vocab.txt')self.device = torch.device('xpu' if torch.cuda.is_available() else 'cpu')self.train_file_path = os.path.join(self.dataset_dir, 'train.csv')self.val_file_path = os.path.join(self.dataset_dir, 'val.csv')self.test_file_path = os.path.join(self.dataset_dir, 'test.csv')self.model_save_dir = os.path.join(self.project_dir, 'cache')self.logs_save_dir = os.path.join(self.project_dir, 'logs')self.is_sample_shuffle = Trueself.batch_size = 16self.max_sen_len = Noneself.num_labels = 4 # num_choiceself.learning_rate = 2e-5self.epochs = 10self.model_val_per_epoch = 2logger_init(log_file_name='choice', log_level=logging.INFO,log_dir=self.logs_save_dir)if not os.path.exists(self.model_save_dir):os.makedirs(self.model_save_dir)# 把原始bert中的配置参数也导入进来bert_config_path = os.path.join(self.pretrained_model_dir, "config.json")bert_config = BertConfig.from_json_file(bert_config_path)for key, value in bert_config.__dict__.items():self.__dict__[key] = value# 将当前配置打印到日志文件中logging.info(" ### 将当前配置打印到日志文件中 ")for key, value in self.__dict__.items():logging.info(f"### {key} = {value}")
训练
最后,我们便可以通过如下方法完成整个模型的微调:
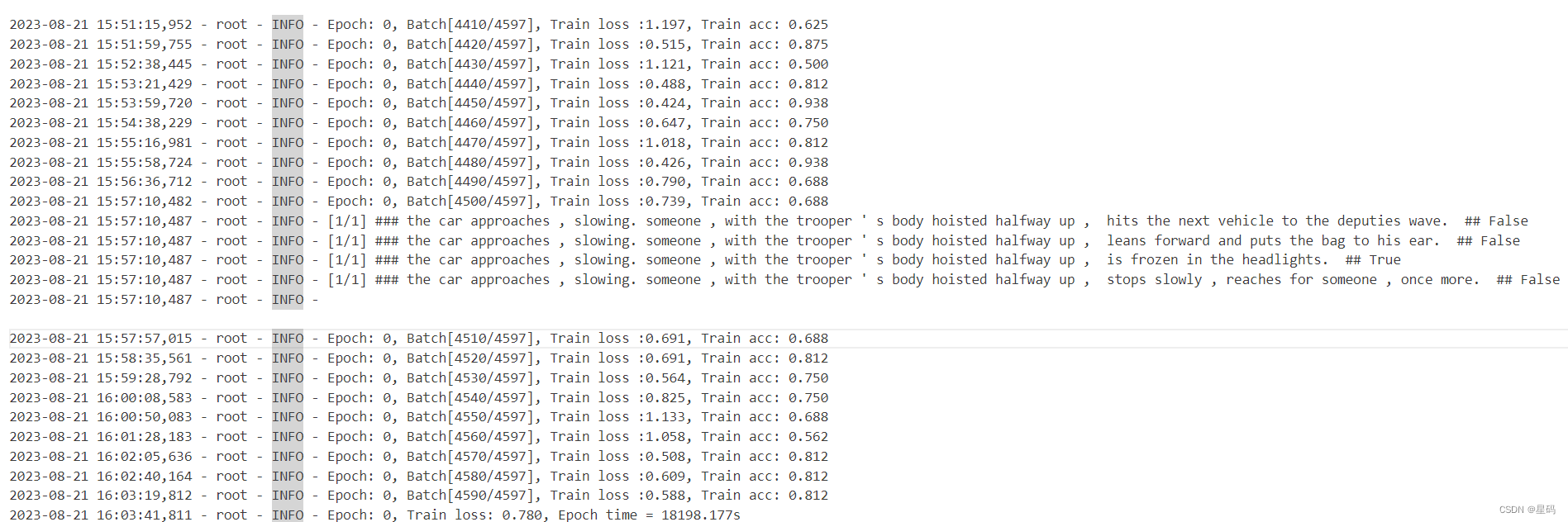
def train(config):model = BertForMultipleChoice(config,config.pretrained_model_dir)model_save_path = os.path.join(config.model_save_dir, 'model.pt')if os.path.exists(model_save_path):loaded_paras = torch.load(model_save_path)model.load_state_dict(loaded_paras)logging.info("## 成功载入已有模型,进行追加训练......")model = model.to(config.device)optimizer = torch.optim.Adam(model.parameters(), lr=config.learning_rate)'''Apply Intel Extension for PyTorch optimization against the model object and optimizer object.'''model, optimizer = ipex.optimize(model, optimizer=optimizer)model.train()bert_tokenize = BertTokenizer.from_pretrained(model_config.pretrained_model_dir).tokenizedata_loader = LoadMultipleChoiceDataset(vocab_path=config.vocab_path,tokenizer=bert_tokenize,batch_size=config.batch_size,max_sen_len=config.max_sen_len,max_position_embeddings=config.max_position_embeddings,pad_index=config.pad_token_id,is_sample_shuffle=config.is_sample_shuffle,num_choice=config.num_labels)train_iter, test_iter, val_iter = \data_loader.load_train_val_test_data(config.train_file_path,config.val_file_path,config.test_file_path)max_acc = 0for epoch in range(config.epochs):losses = 0start_time = time.time()for idx, (qa, seg, mask, label) in enumerate(train_iter):qa = qa.to(config.device) # [src_len, batch_size]label = label.to(config.device)seg = seg.to(config.device)mask = mask.to(config.device)loss, logits = model(input_ids=qa,attention_mask=mask,token_type_ids=seg,position_ids=None,labels=label)optimizer.zero_grad()loss.backward()optimizer.step()losses += loss.item()acc = (logits.argmax(1) == label).float().mean()if idx % 10 == 0:logging.info(f"Epoch: {epoch}, Batch[{idx}/{len(train_iter)}], "f"Train loss :{loss.item():.3f}, Train acc: {acc:.3f}")if idx % 100 == 0:y_pred = logits.argmax(1).cpu()show_result(qa, y_pred, data_loader.vocab.itos, num_show=1)end_time = time.time()train_loss = losses / len(train_iter)logging.info(f"Epoch: {epoch}, Train loss: "f"{train_loss:.3f}, Epoch time = {(end_time - start_time):.3f}s")if (epoch + 1) % config.model_val_per_epoch == 0:acc, _ = evaluate(val_iter, model,config.device, inference=False)logging.info(f"Accuracy on val {acc:.3f}")if acc > max_acc:max_acc = acctorch.save(model.state_dict(), model_save_path)
结果
参考资料
基于BERT预训练模型的SWAG问答任务:https://mp.weixin.qq.com/s/GqsbMBNt9XcFIjmumR04Pg
相关文章:
[oneAPI] 基于BERT预训练模型的SWAG问答任务
[oneAPI] 基于BERT预训练模型的SWAG问答任务 基于Intel DevCloud for oneAPI下的Intel Optimization for PyTorch基于BERT预训练模型的SWAG问答任务数据集下载和描述数据集构建问答选择模型训练 结果参考资料 比赛:https://marketing.csdn.net/p/f3e44fbfe46c465f4d…...
如何为winform控件注册事件
有很多winform的初学者不知道如何为winform注册的事件代码,本篇博文就是以button控件为例子,为winform注册单击事件,如下: 1、新建一个winform 以visual studio 2019 社区版为例子,新建一个winform程序,如下: 关于visual studio 2019 社区版下载方式点击这里:手把手教…...
【LeetCode-面试经典150题-day15】
目录 104.二叉树的最大深度 100.相同的树 226.翻转二叉树 101.对称二叉树 105.从前序与中序遍历序列构造二叉树 106.从中序与后序遍历序列构造二叉树 117.填充每个节点的下一个右侧节点指针Ⅱ 104.二叉树的最大深度 题意: 给定一个二叉树 root ,返回其…...

git查看和修改项目远程仓库地址
git查看和修改项目远程仓库地址 一、背景 项目代码仓库迁移,需要本地更新远程仓库地址,进行代码同步与提交。 二、查看项目的远程仓库地址 # 查看远程地址 git remote -v # 查看远程仓库信息(分支、地址等) git remote show origin三、修…...
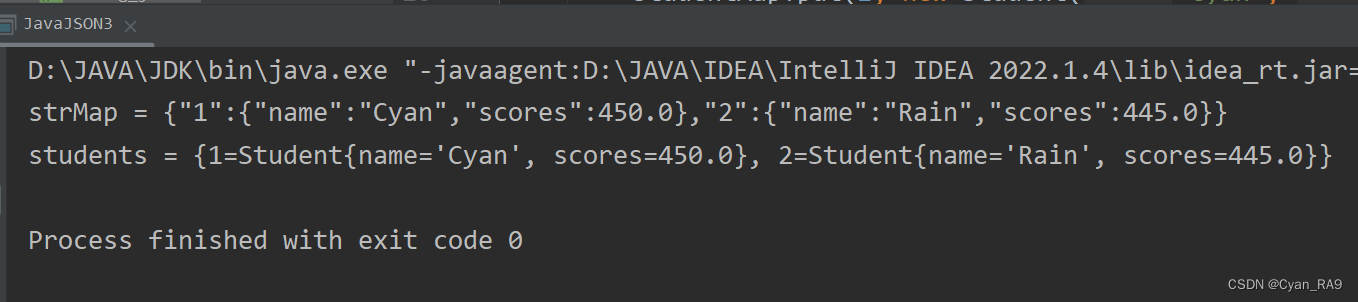
JavaWeb 速通JSON
目录 一、JSON快速入门 1.基本介绍 : 2.定义格式 : 3.入门案例 : 二、JSON对象和字符串的相互转换 1.常用方法 : 2.应用实例 : 3.使用细节 : 三、JSON在Java中的使用 1.基本说明 : 2.应用场景 : 2.1 JSON <---> JavaBean 2.2 JSON <---> List 2.3 JSON …...
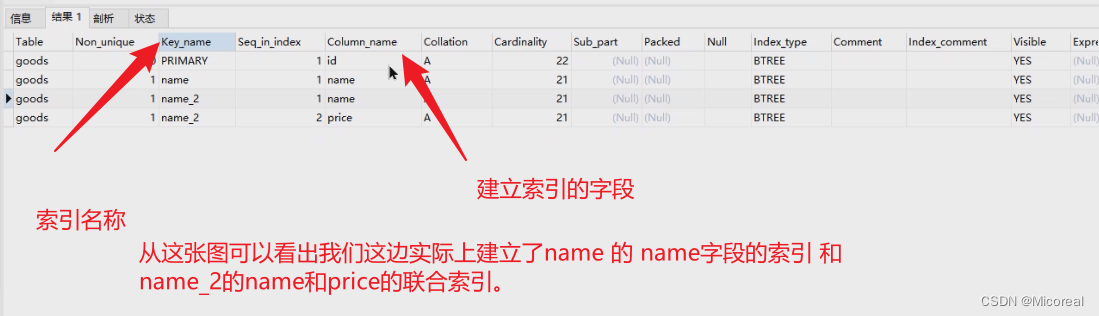
20 MySQL(下)
文章目录 视图视图是什么定义视图查看视图删除视图视图的作用 事务事务的使用 索引查询索引创建索引删除索引聚集索引和非聚集索引影响 账户管理(了解非DBA)授予权限 与 账户的相关操作 MySQL的主从配置 视图 视图是什么 通俗的讲,视图就是…...
测试圈的网红工具:Jmeter到底难在哪里?!
雨果的公司最近推出了一款在线购物应用,吸引了大量用户。然而随着用户数量的增加,应用的性能开始出现问题。用户抱怨说购物过程中页面加载缓慢,甚至有时候无法完成订单,小欧作为负责人员迫切需要找到解决方案。 在学习JMeter之前…...
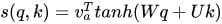
深度学习10:Attention 机制
目录 Attention 的本质是什么 Attention 的3大优点 Attention 的原理 Attention 的 N 种类型 Attention 的本质是什么 Attention(注意力)机制如果浅层的理解,跟他的名字非常匹配。他的核心逻辑就是「从关注全部到关注重点」。 Attention…...
)
简单着色器编写(中下)
这篇我们来介绍另一部分函数。 static unsigned int CreateShader(const std::string& vertexShader, const std::string& fragmentShader) {unsigned int program glCreateProgram();unsigned int vs CompileShader(GL_VERTEX_SHADER,vertexShader);unsigned int f…...
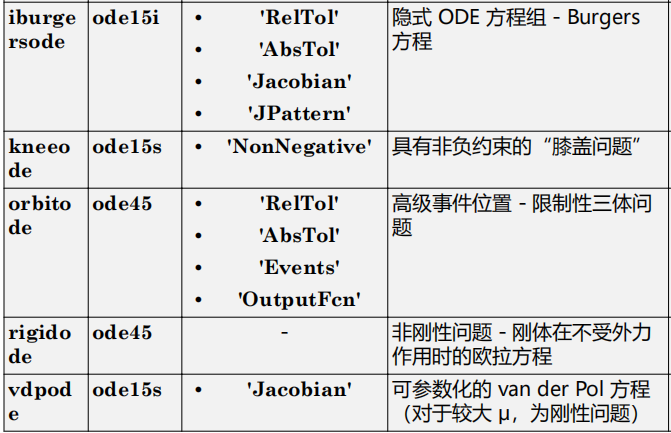
matlab使用教程(24)—常微分方程(ODE)求解器
1.常微分方程 常微分方程 (ODE) 包含与一个自变量 t(通常称为时间)相关的因变量 y 的一个或多个导数。此处用于表示 y 关于 t 的导数的表示法对于一阶导数为 y ′ ,对于二阶导数为 y ′′,依此类推。ODE 的阶数等于 y 在方程中…...

企业级数据共享规模化模式
数据共享正在成为企业数据战略的重要元素。对于公司而言,Amazon Data Exchange 这样的亚马逊云科技服务提供了与其他公司共享增值数据或从这些数据获利的途径。一些企业希望有一个数据共享平台,他们可以在该平台上建立协作和战略方法,在封闭、…...
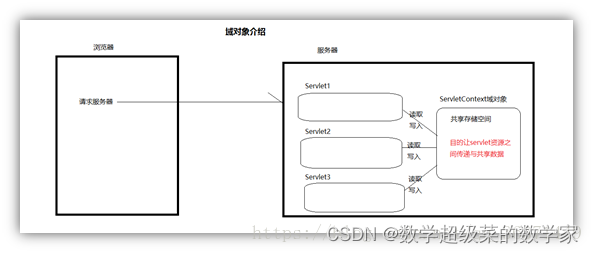
Web服务器-Tomcat详细原理与实现
Tomcat 安装与使用 :MAC 安装配置使用Tomcat - 掘金 安装后本计算机就相当于一台服务器了!!! 方式一:使用本地安装的Tomcat 1、将项目文件移动到Tomcat的webapps目录下。 2、启动Tomcat 3、在浏览器输入想要加载的…...
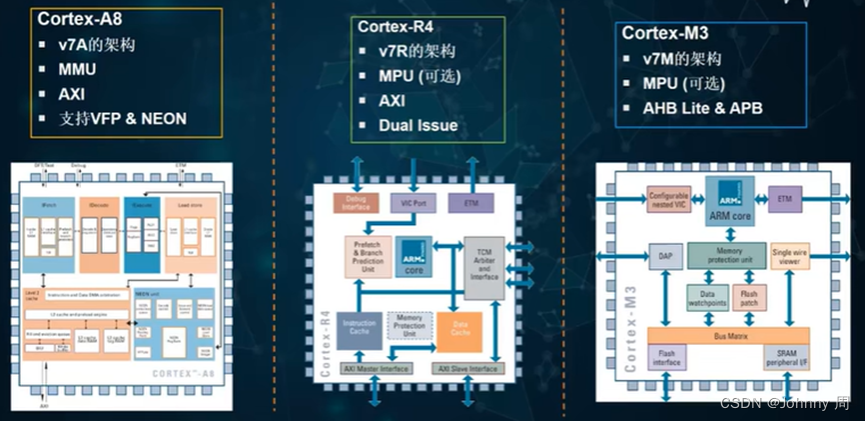
ARM处理器核心概述
一、基于ARM处理器的嵌入式系统 ARM核深度嵌入SOC中,通过JTAG口进行外部调试。计通常既有外部内存又有内部内存,从而支持不通的内存宽度、速度和大小。一般会包含一个中断控制器。可能包含一些Primece外设,需要从ARM公司取得授权。总线使用A…...
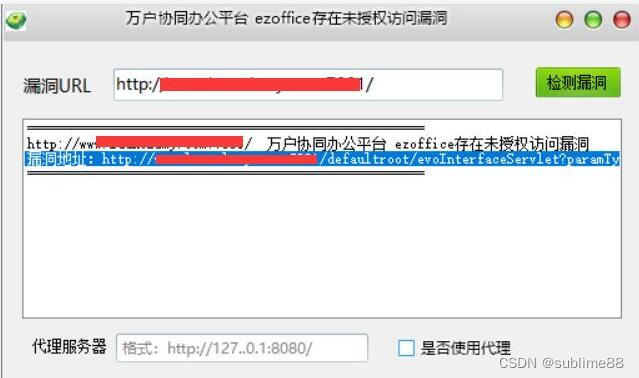
万户协同办公平台 ezoffice存在未授权访问漏洞 附POC
文章目录 万户协同办公平台 ezoffice存在未授权访问漏洞 附POC1. 万户协同办公平台 ezoffice简介2.漏洞描述3.影响版本4.fofa查询语句5.漏洞复现6.POC&EXP7.整改意见8.往期回顾 万户协同办公平台 ezoffice存在未授权访问漏洞 附POC 免责声明:请勿利用文章内的相…...
使用ctcloss训练矩阵生成目标字符串
首先我们需要明确 c t c l o s s ctcloss ctcloss是用来做什么的。比如说要生成的目标字符串长度为 l l l,而这个字符串包含 s s s个字符,字符串允许的最大长度为 L L L,这里认为一个位置是一个时间步,就是一拍,记为 T…...
驱动 - 20230829
练习 基于platform实现 在根节点下,增加设备树 myplatform {compatible"hqyj,myplatform";interrupts-extended<&gpiof 9 0>, <&gpiof 7 0>, <&gpiof 8 0>;led1-gpio<&gpioe 10 0>;reg<0x12345678 59>;}…...

数组(个人学习笔记黑马学习)
一维数组 1、定义方式 #include <iostream> using namespace std;int main() {//三种定义方式//1.int arr[5];arr[0] 10;arr[1] 20;arr[2] 30;arr[3] 40;arr[4] 50;//访问数据元素/*cout << arr[0] << endl;cout << arr[1] << endl;cout &l…...

layui表格事件分析实例
在 layui 的表格组件中,区分表头事件和行内事件是通过事件类型(toolbar 和 tool)以及 lay-filter 值来实现的。 我们有一个表格,其中有一个工具栏按钮和操作按钮。我们将使用 layui 的 table 组件来处理这些事件。 HTML 结构&…...

Android NDK JNI与Java的相互调用
一、Jni调用Java代码 jni可以调用java中的方法和java中的成员变量,因此JNIEnv定义了一系列的方法来帮助我们调用java的方法和成员变量。 以上就是jni调用java类的大部分方法,如果是静态的成员变量和静态方法,可以使用***GetStaticMethodID、CallStaticObjectMethod等***。就…...

装备制造企业如何执行精益管理?
导 读 ( 文/ 2358 ) 精益管理是一种以提高效率、降低成本和优化流程为目标的管理方法。装备制造行业具备人工参与度高,产成品价值高,质量要求高的特点。 在装备制造企业中实施精益管理可以帮助企业提高竞争力、提升生产效率并提供高质量的产品。本文将…...

软件许可优化,别被销售忽悠了,看看这几家到底谁管用
以前我们公司被Adobe审计过一次,赔了不少钱。之后老板让我专门研究软件许可优化这件事。市面上这几家都聊过、试过,我把真实感受跟你说说。先说你可能不太熟的:(gofarlic)这家是国内武汉的,一开始我也有点怀…...

3步完成AI化学逆合成规划:让复杂分子合成变得简单高效的终极指南
3步完成AI化学逆合成规划:让复杂分子合成变得简单高效的终极指南 【免费下载链接】aizynthfinder A tool for retrosynthetic planning 项目地址: https://gitcode.com/gh_mirrors/ai/aizynthfinder 你是否曾为设计复杂分子的合成路线而烦恼?传统…...

ODT怎么转PDF?2026年实测5种转换方法与在线工具对比
ODT(OpenDocument Text)是开源办公软件默认的文档格式,但在实际工作和分享中,PDF的通用性和防篡改特性让它成为更优选择。很多人拿到ODT文件后都会面临同一个问题:怎样才能快速转成PDF?本文将从多个角度展示…...

PSLab Desktop性能优化:提升仪器响应速度与数据精度的终极指南
PSLab Desktop性能优化:提升仪器响应速度与数据精度的终极指南 【免费下载链接】pslab-desktop PSLab Desktop Application https://pslab.io 项目地址: https://gitcode.com/gh_mirrors/ps/pslab-desktop PSLab Desktop是一款强大的开源硬件实验平台应用程序…...

零代码自动化终极指南:用taskt在5分钟内解放你的双手
零代码自动化终极指南:用taskt在5分钟内解放你的双手 【免费下载链接】taskt taskt (pronounced tasked and formely sharpRPA) is free and open-source robotic process automation (rpa) built in C# powered by the .NET Framework 项目地址: https://gitcode…...

使用电脑快速测试 CANopen 设备通讯
Anybus CANopen主站仿真工具介绍日常对客户进行技术支持的时候,我们发现工厂自动化领域的不同部门不同职能的人员对于工业通讯设备都面临着一些使用的困难,例如设备研发人员,尤其是嵌入式研发部门,对于工厂自动化使用的工业通讯协…...

情感演绎有多强?顶伯实测愤怒、喜悦、悲伤等 9 种语气
🎭 微软 TTS 的情感演绎有多强?顶伯实测愤怒、喜悦、悲伤等 9 种语气🎯 引言:语音合成的情感革命在人工智能语音合成领域,情感表达一直是技术难点。微软 TTS(文本转语音)通过深度学习模型&#…...

openpilot深度解析:开源驾驶辅助系统的技术实现与架构设计
openpilot深度解析:开源驾驶辅助系统的技术实现与架构设计 【免费下载链接】openpilot openpilot is an operating system for robotics. Currently, it upgrades the driver assistance system on 300 supported cars. 项目地址: https://gitcode.com/GitHub_Tre…...
如何彻底解决TranslucentTB的Microsoft.VCLibs依赖缺失问题:3步诊断与修复指南
如何彻底解决TranslucentTB的Microsoft.VCLibs依赖缺失问题:3步诊断与修复指南 【免费下载链接】TranslucentTB A lightweight utility that makes the Windows taskbar translucent/transparent. 项目地址: https://gitcode.com/gh_mirrors/tr/TranslucentTB …...

Beyond Compare 5密钥生成器技术解析与高效配置指南
Beyond Compare 5密钥生成器技术解析与高效配置指南 【免费下载链接】BCompare_Keygen Keygen for BCompare 5 项目地址: https://gitcode.com/gh_mirrors/bc/BCompare_Keygen 当Beyond Compare 5的30天评估期结束后,软件会进入受限模式,许多高级…...