hadoop学习:mapreduce入门案例二:统计学生成绩
这里相较于 wordcount,新的知识点在于学生实体类的编写以及使用
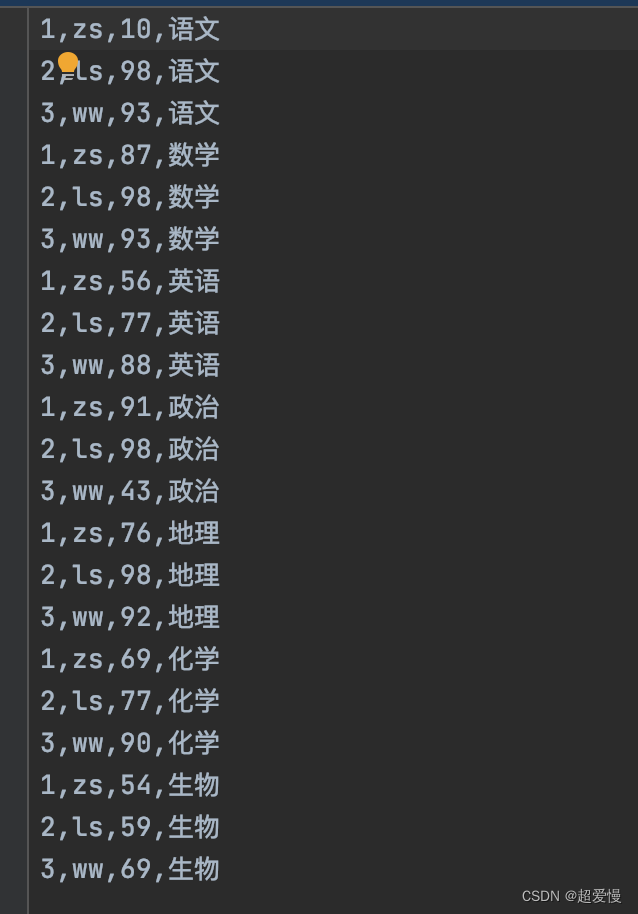
数据信息:
1. Student 实体类
import org.apache.hadoop.io.WritableComparable;import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;public class Student implements WritableComparable<Student> {
// Objectprivate long stuid;private String stuName;private int score;public Student(long stuid, String stuName, int score) {this.stuid = stuid;this.stuName = stuName;this.score = score;}@Overridepublic String toString() {return "Student{" +"stuid=" + stuid +", stuName='" + stuName + '\'' +", score=" + score +'}';}public Student() {}public long getStuid() {return stuid;}public void setStuid(long stuid) {this.stuid = stuid;}public String getStuName() {return stuName;}public void setStuName(String stuName) {this.stuName = stuName;}public int getScore() {return score;}public void setScore(int score) {this.score = score;}// 自动整理文件格式 ctrl + shift + f 英文输放状态@Overridepublic int compareTo(Student o) {return this.score > o.score ? 1 : 0;}@Overridepublic void write(DataOutput dataOutput) throws IOException {dataOutput.writeLong(stuid);dataOutput.writeUTF(stuName);dataOutput.writeInt(score);}@Overridepublic void readFields(DataInput dataInput) throws IOException {this.stuid = dataInput.readLong();this.stuName = dataInput.readUTF();this.score = dataInput.readInt();}
}
2. mapper 阶段,StudentMapper 类
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;/*** 输出 key:学生id value:Student对象*/
public class StudentMapper extends Mapper<LongWritable, Text,LongWritable,Student> {@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {String[] split = value.toString().split(",");LongWritable stuidKey = new LongWritable(Long.parseLong(split[0]));Student stuValue = new Student(Long.parseLong(split[0]),split[1],Integer.parseInt(split[2]));context.write(stuidKey,stuValue);}
}
3. reduce 阶段,StudentReduce 类
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;public class StudentReducer extends Reducer<LongWritable,Student,Student, NullWritable> {@Overrideprotected void reduce(LongWritable key, Iterable<Student> values, Context context) throws IOException,InterruptedException {Student stuOut = new Student();int sumScore = 0;String stuName = "";for (Student stu :values) {sumScore+=stu.getScore();stuName = stu.getStuName();}stuOut.setScore(sumScore);stuOut.setStuid(key.get());stuOut.setStuName(stuName);System.out.println(stuOut.toString());context.write(stuOut, NullWritable.get());}
}
4. 驱动类,studentDriver 类
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;public class StudentDriver {public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {Configuration conf = new Configuration();Job job = Job.getInstance(conf);job.setJarByClass(StudentDriver.class);//配置 job中map阶段处理类和map阶段的输出类型job.setMapperClass(StudentMapper.class);job.setMapOutputKeyClass(LongWritable.class);job.setMapOutputValueClass(Student.class);//配置 job中deduce阶段处理类和reduce阶段的输出类型job.setReducerClass(StudentReducer.class);job.setOutputKeyClass(Student.class);job.setOutputValueClass(NullWritable.class);// 输入路径配置 "hdfs://kb131:9000/kb23/hadoopstu/stuscore.csv"Path inpath = new Path(args[0]); // 外界获取文件输入路径FileInputFormat.setInputPaths(job, inpath);// 输出路径配置 "hdfs://kb131:9000/kb23/hadoopstu/out2"Path path = new Path(args[1]); //FileSystem fs = FileSystem.get(path.toUri(), conf);if (fs.exists(path))fs.delete(path,true);FileOutputFormat.setOutputPath(job,path);job.waitForCompletion(true);}
}
相关文章:
hadoop学习:mapreduce入门案例二:统计学生成绩
这里相较于 wordcount,新的知识点在于学生实体类的编写以及使用 数据信息: 1. Student 实体类 import org.apache.hadoop.io.WritableComparable;import java.io.DataInput; import java.io.DataOutput; import java.io.IOException;public class Stude…...

自学TypeScript-基础、编译、类型
自学TypeScript-基础、编译、类型 TS 编译为 JS类型支持类型注解基础类型typeof 运算符高级类型class 类构造函数和实例方法继承可见性只读 类型兼容性交叉类型泛型泛型约束多个泛型泛型接口泛型类泛型工具 索引签名类型映射类型索引查询(访问)类型 类型声明文件 TypeScript 是…...

nginx配置https
1.安装nginx 安装完成后检查 nginx -V2.申请证书与上传 阿里云申请免费的证书 然后上传到某个目录 3.修改nginx配置 #user nobody; worker_processes 1;#error_log logs/error.log; #error_log logs/error.log notice; #error_log logs/error.log info;#pid …...
windows Etcd的安装与使用
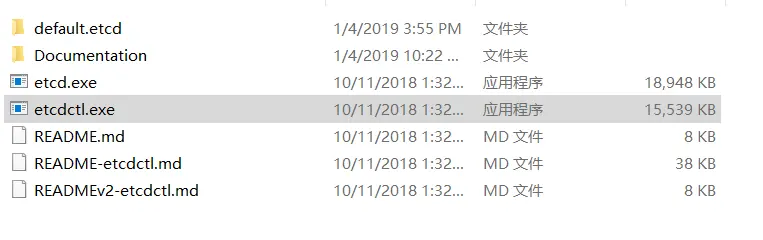
一、简介 etcd是一个分布式一致性键值存储,其主要用于分布式系统的共享配置和服务发现。 etcd由Go语言编写 二、下载并安装 1.下载地址: https://github.com/coreos/etcd/releases 解压后的目录如下:其中etcd.exe是服务端,e…...

【py】为什么用 import tkinter 不能运行
为什么用 import tkinter 不能运行 ━━━━━━━━━━━━━━━━━━━━━━ 要显示一个信息框,为什么用 import tkinter 不能运行,改成from tkinter import messagebox 就可以运行了? 可能是因为您的代码中只使用了 messagebox 这个模…...

【深度学习】实验04 交叉验证
文章目录 交叉验证划分自定义划分K折交叉验证留一交叉验证留p交叉验证随机排列交叉验证分层K折交叉验证分层随机交叉验证 分割组 k-fold分割留一组分割留 P 组分割随机分割时间序列分割 交叉验证 # 导入相关库# 交叉验证所需函数 from sklearn.model_selection import train_t…...

whisper语音识别部署及WER评价
1.whisper部署 详细过程可以参照:🏠 创建项目文件夹 mkdir whisper cd whisper conda创建虚拟环境 conda create -n py310 python3.10 -c conda-forge -y 安装pytorch pip install --pre torch torchvision torchaudio --extra-index-url 下载whisper p…...

java太卷了,怎么办?
忧虑: 马上就到30岁了,最近对于自己职业生涯的规划甚是焦虑。在网站论坛上,可谓是哀鸿遍野,大家纷纷叙述着自己被裁后求职的艰辛路程,这更加加深了我的忧虑,于是在各大论坛开始“求医问药”,想…...

android多屏触摸相关的详解方案-安卓framework开发手机车载车机系统开发课程
背景 直播免费视频课程地址:https://www.bilibili.com/video/BV1hN4y1R7t2/ 在做双屏相关需求开发过程中,经常会有对两个屏幕都要求可以正确触摸的场景。但是目前我们模拟器默认创建的双屏其实是没有办法进行触摸的 修改方案1 静态修改方案 使用命令…...
微信小程序 实时日志
目录 实时日志 背景 如何使用 如何查看日志 注意事项 实时日志 背景 为帮助小程序开发者快捷地排查小程序漏洞、定位问题,我们推出了实时日志功能。从基础库2.7.1开始,开发者可通过提供的接口打印日志,日志汇聚并实时上报到小程序后台…...
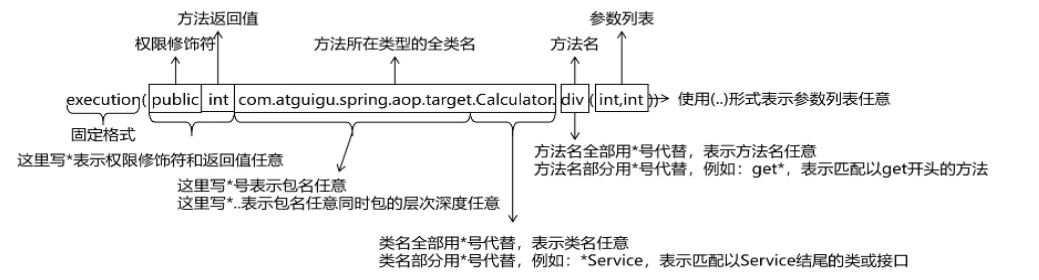
Spring AOP基于注解方式实现和细节
目录 一、Spring AOP底层技术 二、初步实现AOP编程 三、获取切点详细信息 四、 切点表达式语法 五、重用(提取)切点表达式 一、Spring AOP底层技术 SpringAop的核心在于动态代理,那么在SpringAop的底层的技术是依靠了什么技术呢&#x…...

CVPR2023论文及代码合集来啦~
以下内容由马拉AI整理汇总。 下载:点我跳转。 狂肝200小时的良心制作,529篇最新CVPR2023论文及其Code,汇总成册,制作成《CVPR 2023论文代码检索目录》,包括以下方向: 1、2D目标检测 2、视频目标检测 3、…...
基于ETLCloud的自定义规则调用第三方jar包实现繁体中文转为简体中文
背景 前面曾体验过通过零代码、可视化、拖拉拽的方式快速完成了从 MySQL 到 ClickHouse 的数据迁移,但是在实际生产环境,我们在迁移到目标库之前还需要做一些过滤和转换工作;比如,在诗词数据迁移后,发现原来 MySQL 中…...
TDesign在按钮上加入图标组件
在实际开发中 我们经常会遇到例如 添加或者查询 我们需要在按钮上加入图标的操作 TDesign自然也有预备这样的操作 首先我们打开文档看到图标 例如 我们先用某些图标 就可以点开下面的代码 可以看到 我们的图标大部分都是直接用tdesign-icons-vue 导入他的组件就可以了 而我…...

Linux 终端命令行 产品介绍
Linux命令手册内置570多个Linux 命令,内容包含 Linux 命令手册。 【软件功能】: 文件传输 bye、ftp、ftpcount、ftpshut、ftpwho、ncftp、tftp、uucico、uucp、uupick、uuto、scp备份压缩 ar、bunzip2、bzip2、bzip2recover、compress、cpio、dump、gun…...
计算机毕设 基于深度学习的植物识别算法 - cnn opencv python
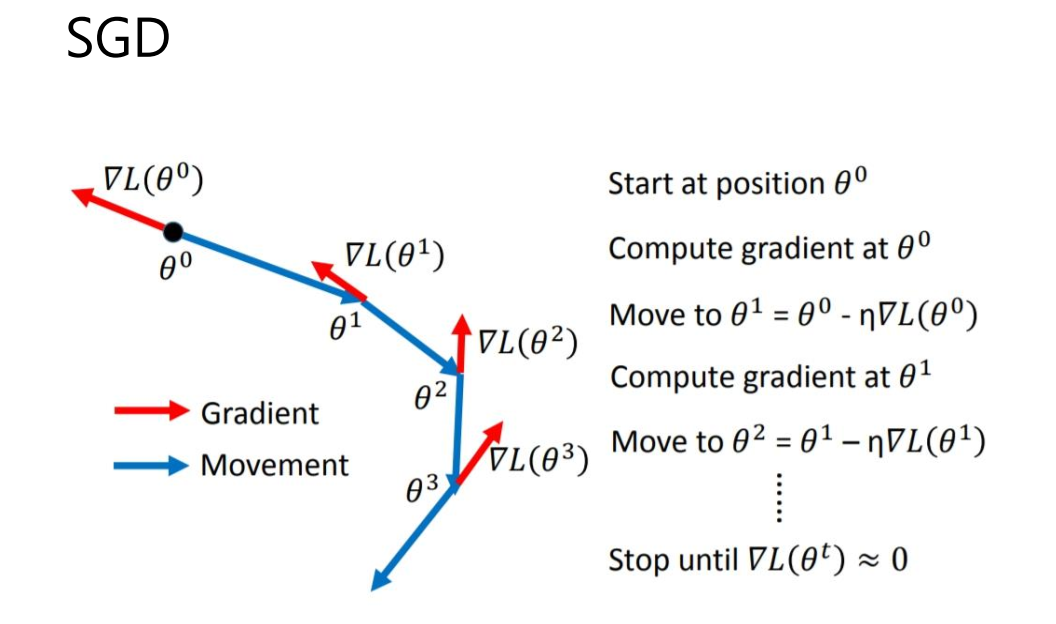
文章目录 0 前言1 课题背景2 具体实现3 数据收集和处理3 MobileNetV2网络4 损失函数softmax 交叉熵4.1 softmax函数4.2 交叉熵损失函数 5 优化器SGD6 最后 0 前言 🔥 这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设题目缺少创新和亮点&a…...
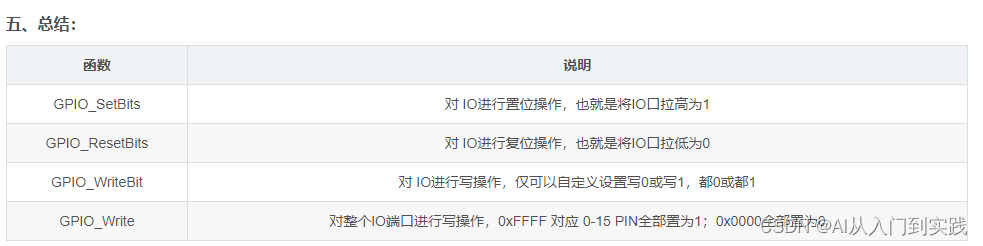
【STM32】学习笔记-江科大
【STM32】学习笔记-江科大 1、STM32F103C8T6的GPIO口输出 2、GPIO口输出 GPIO(General Purpose Input Output)通用输入输出口可配置为8种输入输出模式引脚电平:0V~3.3V,部分引脚可容忍5V输出模式下可控制端口输出高低电平&#…...
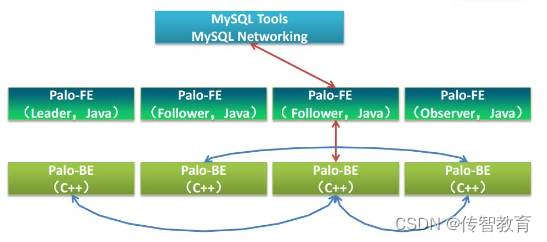
Doris架构中包含哪些技术?
Doris主要整合了Google Mesa(数据模型),Apache Impala(MPP Query Engine)和Apache ORCFile (存储格式,编码和压缩)的技术。 为什么要将这三种技术整合? Mesa可以满足我们许多存储需求的需求,但是Mesa本身不提供SQL查询引擎。 Impala是一个…...
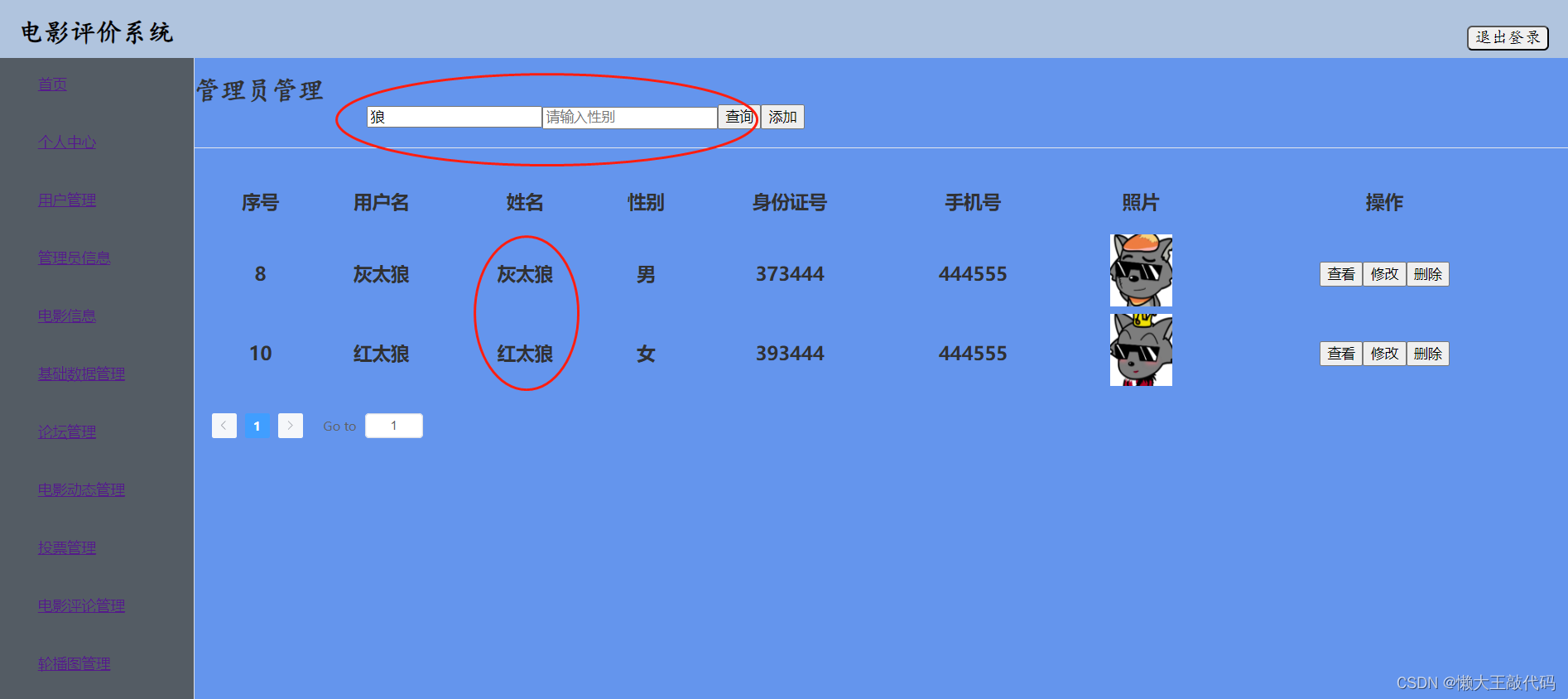
《vue3实战》通过indexOf方法实现电影评价系统的模糊查询功能
目录 前言 一、indexOf是什么?indexOf有什么作用? 含义: 作用: 二、功能实现 这段是查询过程中过滤筛选功能的代码部分: 分析: 这段是查询用户和性别功能的代码部分: 分析: 三、最终效…...

java对时间序列每x秒进行分组
问题:将一个时间序列每5秒分一组,返回嵌套的list; 原理:int除int会得到一个int(也就是损失精度) 输入:排序后的list,每几秒分组值 private static List<List<Long>> get…...

SD-PPP:打破Photoshop与AI壁垒的革命性插件
SD-PPP:打破Photoshop与AI壁垒的革命性插件 【免费下载链接】sd-ppp A Photoshop AI plugin 项目地址: https://gitcode.com/gh_mirrors/sd/sd-ppp 你是否曾在Photoshop中精心设计到一半,却不得不切换到其他AI工具进行图像生成,然后再…...

Ollama 进阶:如何给本地大模型投喂你公司的测试文档?
——2026年企业级RAG知识库搭建全指南 写在前面:一个测试团队的真实痛点 上个月,一位测试团队负责人在交流群里发了这么一段话: “我们团队累积了大概3万+份测试用例、2000多份测试报告和无数迭代过程中留下的缺陷记录。每次新人入职,至少要花两周时间翻阅历史文档;每次…...

STM32F407VE的FSMC时序调优笔记:如何让320x480的ILI9488屏幕刷得更快更稳
STM32F407VE的FSMC时序调优笔记:如何让320x480的ILI9488屏幕刷得更快更稳 当一块320x480分辨率的ILI9488屏幕在STM32F407VE上成功点亮后,真正的挑战才刚刚开始。许多工程师会发现,虽然屏幕能显示内容,但刷新率低下、画面闪烁甚至偶…...

告别抓包焦虑:Win10下搞定8812BU网卡驱动与Omnipeek联动的保姆级避坑指南
告别抓包焦虑:Win10下搞定8812BU网卡驱动与Omnipeek联动的保姆级避坑指南 在无线网络分析领域,8812BU芯片的无线网卡因其出色的抓包能力备受青睐,但许多用户在Windows 10环境下配置驱动与Omnipeek抓包工具时,往往会陷入驱动安装失…...
)
告别手写解析!用Python Cantools 39.4.5一键生成CAN/CANFD DBC的C代码(附批处理脚本)
从DBC到C代码:Python Cantools全自动转换实战指南 在汽车电子和嵌入式开发领域,CAN总线通信是核心基础设施,而DBC文件则是定义CAN/CANFD通信协议的行业标准。传统开发流程中,工程师需要手动解析DBC文件并编写大量信号打包/解包代码…...

甲级钢制隔热平开防火窗:技术参数、结构工艺与工程应用解析
一、产品概述甲级钢制隔热平开防火窗严格依照国家消防标准制造,采用加厚冷轧镀锌钢板打造框架,搭配防火填充材料、隔热防火玻璃与专用密封配件,防火隔热、密闭性强,耐用抗腐蚀。相较于低等级防火窗,本品耐火隔热性能更…...

墨水屏高效开发:架构、开源库与实战优化指南
1. 项目概述:为什么墨水屏开发值得深挖?如果你接触过电子墨水屏,第一印象可能是“反应慢”、“刷新有残影”、“只能显示黑白”。确实,相比我们手机、电脑上那些流光溢彩的LCD或OLED屏幕,墨水屏在响应速度和色彩表现上…...

Arduino步进电机控制:按键调速与定时器中断实现
1. 项目概述与核心需求解析最近在捣鼓一个自动化小装置,核心需求就是通过几个物理按键来控制步进电机的动作,比如正转、反转、加速、减速或者停止。这听起来像是很多创客项目、小型自动化设备或者教学演示里最基础的一环。我猜你可能是电子爱好者、学生&…...

CANN/HCOMM拓扑层级查询
HcclRankGraphGetLayers 【免费下载链接】hcomm HCOMM(Huawei Communication)是HCCL的通信基础库,提供通信域以及通信资源的管理能力。 项目地址: https://gitcode.com/cann/hcomm 产品支持情况 Ascend 950PR/Ascend 950DT࿱…...
)
告别Modelsim命令行!用Notepad++插件NppExec一键检查Verilog语法(附详细配置命令)
硬件工程师的效率革命:Notepad与Verilog语法检查的终极整合方案 在数字电路设计领域,Verilog作为主流硬件描述语言,其语法检查是每位工程师日常工作中不可或缺的环节。传统工作流程中,工程师们不得不在文本编辑器与EDA工具之间频繁…...