unordered-------Hash
✅<1>主页:我的代码爱吃辣
📃<2>知识讲解:数据结构——哈希表
☂️<3>开发环境:Visual Studio 2022
💬<4>前言:哈希是一种映射的思想,哈希表即使利用这种思想,在查找上进行很少的比较次数就能够将元素找到,非常的高效,在一定程度上,效率比红黑树还要强,因此在C++11中,STL又提供了4个unordered系列的关联式容器,他们的底层就是哈希。
目录
一.unordered系列关联式容器
1. unordered_map
1.1 unordered_map的构造
1.2unordered_map的容量
1.3unordered_map的迭代器
1.4 unordered_map的元素访问
1.5unordered_map的查询
1.6unordered_map的修改操作
1.2unordered_set
二.哈希
1.哈希概念
2. 哈希冲突
3.哈希冲突解决
三.实现闭散列除留余数法+线性探测
1.整体结构
2.插入
3.查询
4.删除
四.开散列
1.开散列实现
2.插入
3.查询
4.删除
5.析构函数
五.完整代码即测试

一.unordered系列关联式容器
在C++98中,STL提供了底层为红黑树结构的一系列关联式容器,在查询时效率可达到 ,即最差情况下需要比较红黑树的高度次,当树中的节点非常多时,查询效率也不理想。最好
的查询是,进行很少的比较次数就能够将元素找到,因此在C++11中,STL又提供了4个unordered系列的关联式容器,这四个容器与红黑树结构的关联式容器使用方式基本类似,只是其底层结构不同,本文中只对unordered_map和unordered_set进行介绍,unordered_multimap和unordered_multiset学生可查看文档介绍。
1. unordered_map
reference-------unordered_map
- unordered_map是存储<key, value>键值对的关联式容器,其允许通过keys快速的索引到与其对应的value。
- 在unordered_map中,键值通常用于惟一地标识元素,而映射值是一个对象,其内容与此键关联。键和映射值的类型可能不同。
- 在内部,unordered_map没有对<kye, value>按照任何特定的顺序排序, 为了能在常数范围内找到key所对应的value,unordered_map将相同哈希值的键值对放在相同的桶中。
- unordered_map容器通过key访问单个元素要比map快,但它通常在遍历元素子集的范围迭代方面效率较低。
- unordered_maps实现了直接访问操作符(operator[]),它允许使用key作为参数直接访问value。
- 它的迭代器至少是前向迭代器。
1.1 unordered_map的构造
| 函数声明 | 功能介绍 |
| unordered_map | 构造不同格式的unordered_map对象 |
1.2unordered_map的容量
| 函数声明 | 功能介绍 |
| bool empty() const | 检测unordered_map是否为空 |
| size_t size() const | 获取unordered_map的有效元素个数 |
1.3unordered_map的迭代器
| 函数声明 | 功能介绍 |
| begin | 返回unordered_map第一个元素的迭代器 |
| end | 返回unordered_map最后一个元素下一个位置的迭代器 |
| cbegin | 返回unordered_map第一个元素的const迭代器 |
| cend | 返回unordered_map最后一个元素下一个位置的const迭代器 |
1.4 unordered_map的元素访问
| 函数声明 | 功能介绍 |
| operator[] | 返回与key对应的value,没有一个默认值 |
注意:该函数中实际调用哈希桶的插入操作,用参数key与V()构造一个默认值往底层哈希桶
中插入,如果key不在哈希桶中,插入成功,返回V(),插入失败,说明key已经在哈希桶中,
将key对应的value返回。
1.5unordered_map的查询
| 函数声明 | 功能介绍 |
| iterator find(const K& key) | 返回key在哈希桶中的位置 |
| size_t count(const K& key) | 返回哈希桶中关键码为key的键值对的个数 |
1.6unordered_map的修改操作
| 函数声明 | 功能介绍 |
| insert | 向容器中插入键值对 |
| erase | 删除容器中的键值对 |
| void clear() | 清空容器中有效元素个数 |
| void swap(unordered_map&) | 交换两个容器中的元素 |
1.2unordered_set
reference-------unordered_set
二.哈希
unordered系列的关联式容器之所以效率比较高,是因为其底层使用了哈希结构。
1.哈希概念
顺序结构以及平衡树中,元素关键码与其存储位置之间没有对应的关系,因此在查找一个元素
时,必须要经过关键码的多次比较。顺序查找时间复杂度为O(N),平衡树中为树的高度,即
O(),搜索的效率取决于搜索过程中元素的比较次数。
理想的搜索方法:可以不经过任何比较,一次直接从表中得到要搜索的元素。
如果构造一种存储结构,通过某种函数(hashFunc)使元素的存储位置与它的关键码之间能够建立
一一映射的关系,那么在查找时通过该函数可以很快找到该元素。
当向该结构中:
- 插入元素
根据待插入元素的关键码,以此函数计算出该元素的存储位置并按此位置进行存放。
- 搜索元素
对元素的关键码进行同样的计算,把求得的函数值当做元素的存储位置,在结构中按此位置
取元素比较,若关键码相等,则搜索成功。
该方式即为哈希(散列)方法,哈希方法中使用的转换函数称为哈希(散列)函数,构造出来的结构称
为哈希表(Hash Table)(或者称散列表)。
例如:数据集合{1,7,6,4,5,9};
哈希函数设置为:hash(key) = key % capacity; capacity为存储元素底层空间总的大小。
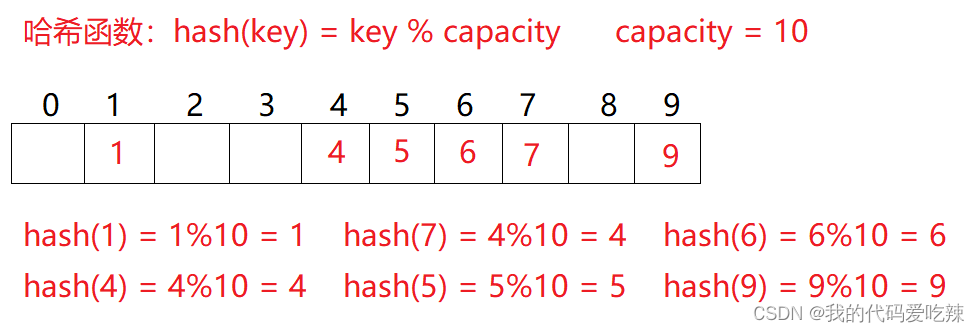
用该方法进行搜索不必进行多次关键码的比较,因此搜索的速度比较快
问题:按照上述哈希方式,向集合中插入元素44,会出现什么问题?发生位置冲突。
2. 哈希冲突
对于两个数据元素的关键字k1和k2,有k1 != k2,但有:Hash(k1) ==
Hash(k2),即:不同关键字通过相同哈希哈数计算出相同的哈希地址,该种现象称为哈希冲突
或哈希碰撞。
把具有不同关键码而具有相同哈希地址的数据元素称为“同义词”。
哈希碰撞的产生一部分原因是,哈希函数设计的不够合理。
哈希函数设计原则:
- 哈希函数的定义域必须包括需要存储的全部关键码,而如果散列表允许有m个地址时,其值域必须在0到m-1之间
- 哈希函数计算出来的地址能均匀分布在整个空间中
- 哈希函数应该比较简单
常见哈希函数:
1.直接定址法--(常用)
取关键字的某个线性函数为散列地址:Hash(Key)= A*Key + B
优点:简单、均匀。
缺点:需要事先知道关键字的分布情况。
使用场景:适合查找比较小且连续的情况。
2. 除留余数法--(常用)
设散列表中允许的地址数为m,取一个不大于m,但最接近或者等于m的质数p作为除数,
按照哈希函数:Hash(key) = key% p(p<=m),将关键码转换成哈希地址。
3. 平方取中法--(了解)
假设关键字为1234,对它平方就是1522756,抽取中间的3位227作为哈希地址;
再比如关键字为4321,对它平方就是18671041,抽取中间的3位671(或710)作为哈希地址
平方取中法比较适合:不知道关键字的分布,而位数又不是很大的情况。
4. 折叠法--(了解)
折叠法是将关键字从左到右分割成位数相等的几部分(最后一部分位数可以短些),然后将这
几部分叠加求和,并按散列表表长,取后几位作为散列地址。
折叠法适合事先不需要知道关键字的分布,适合关键字位数比较多的情况。
5. 随机数法--(了解)
选择一个随机函数,取关键字的随机函数值为它的哈希地址,即H(key) = random(key),其中
random为随机数函数。通常应用于关键字长度不等时采用此法。
6. 数学分析法--(了解)
设有n个d位数,每一位可能有r种不同的符号,这r种不同的符号在各位上出现的频率不一定
相同,可能在某些位上分布比较均匀,每种符号出现的机会均等,在某些位上分布不均匀只
有某几种符号经常出现。可根据散列表的大小,选择其中各种符号分布均匀的若干位作为散
列地址。例如:

假设要存储某家公司员工登记表,如果用手机号作为关键字,那么极有可能前7位都是 相同
的,那么我们可以选择后面的四位作为散列地址,如果这样的抽取工作还容易出现 冲突,还
可以对抽取出来的数字进行反转(如1234改成4321)、右环位移(如1234改成4123)、左环移
位、前两数与后两数叠加(如1234改成12+34=46)等方法。
数字分析法通常适合处理关键字位数比较大的情况,如果事先知道关键字的分布且关键字的
若干位分布较均匀的情况。
注意:哈希函数设计的越精妙,产生哈希冲突的可能性就越低,但是无法避免哈希冲突。
3.哈希冲突解决
解决哈希冲突两种常见的方法是:闭散列和开散列。
闭散列:
闭散列:也叫开放定址法,当发生哈希冲突时,如果哈希表未被装满,说明在哈希表中必然还有
空位置,那么可以把key存放到冲突位置中的“下一个” 空位置中去。那如何寻找下一个空位置
呢?
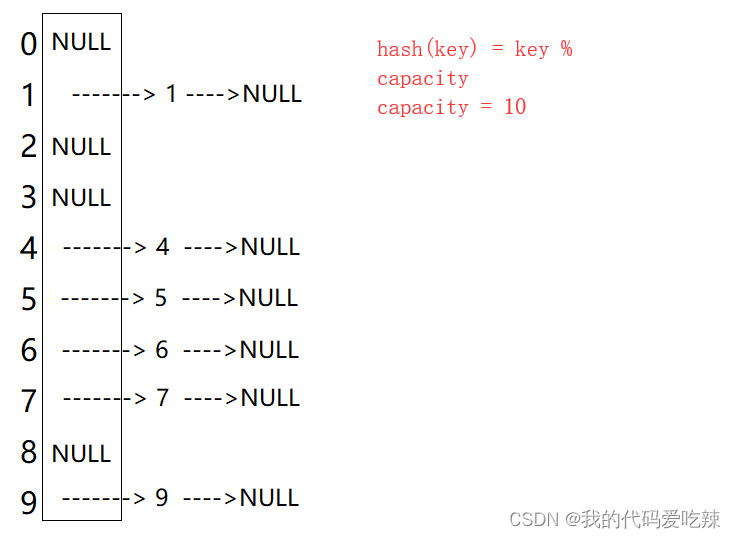
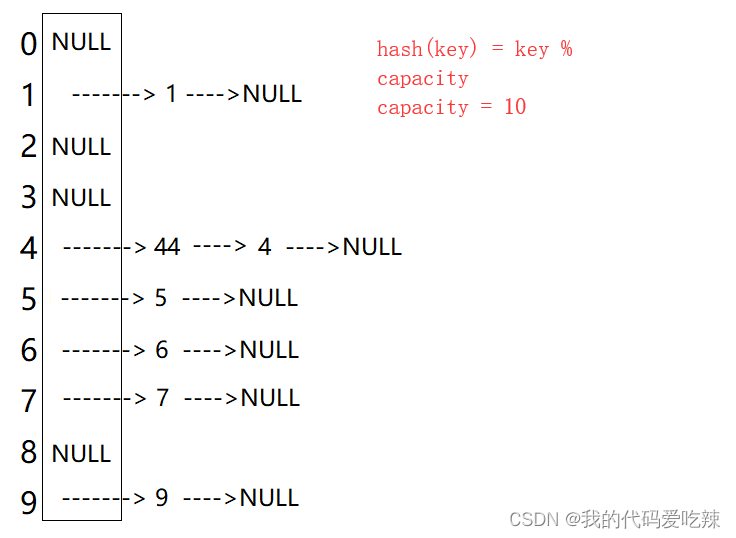
1. 线性探测
比如下面中的场景,现在需要插入元素44,先通过哈希函数计算哈希地址,hashAddr为4,
因此44理论上应该插在该位置,但是该位置已经放了值为4的元素,即发生哈希冲突。
线性探测:从发生冲突的位置开始,依次向后探测,直到寻找到下一个空位置为止。
- 插入
通过哈希函数获取待插入元素在哈希表中的位置如果该位置中没有元素则直接插入新元素,如果该位置中有元素发生哈希冲突,使用线性探测找到下一个空位置,插入新元素。

- 删除
采用闭散列处理哈希冲突时,不能随便物理删除哈希表中已有的元素,若直接删除元素
会影响其他元素的搜索。比如删除元素4,如果直接删除掉,44查找起来可能会受影
响。因此线性探测采用标记的伪删除法来删除一个元素。
// 哈希表每个空间给个标记
// EMPTY此位置空, EXIST此位置已经有元素, DELETE元素已经删除
enum State{EMPTY, EXIST, DELETE};三.实现闭散列除留余数法+线性探测
1.整体结构
//状态 enum State{ EXIST,EMPTY,DELETE };//数据结点template<class K, class V>struct HashDate {HashDate(){}HashDate(pair<K,V> kv):_kv(kv){}pair<K, V> _kv;State state = EMPTY;};//开放定址法哈希表template<class K, class V>class HashTable{typedef HashDate<K, V> Date;public://插入bool insert(pair<K, V> kv){}//删除bool erase(const K& key){}//查询pair<int,bool> find(const K& key){}private:vector<Date> _sh; //数据存储size_t _n = 0; //存储数据的个数};
}2.插入
插入的步骤:
- 计算插入位置
- 线性探测
bool insert(pair<K, V> kv){//开放定值法,线性探测解决冲突//1.计算插入位置int hashi = kv.first % _sh.size();int i = 1; int hashn = hashi;//r如果插入的位置已经有数据了,进行线性探测while (_sh[hashn].state == EXIST){hashn = hashi + i;hashn %= _sh.size();i++;}//探测空位置,插入数据_sh[hashn] = Date(kv);//修改状态_sh[hashn].state = EXIST;_n++;return true;}注意:在计算插入位置时,我们楚留余数法,使用的是表的size,而不是capacity,是因为我们真正合法插入的位置,是size控制的。
扩容:
哈希表什么情况下进行扩容?如何扩容?
这里引入一个新的概念:负载因子

我们约定当负载因子达到0.7时就扩容,扩容的步骤:
bool insert(pair<K, V> kv){//如果插入的值已经存在if (find(kv.first).second){return false;}//扩容//负载因子为0.7if (_sh.size() == 0 || _n * 10 / _sh.size() == 7){//1.确定新的容量int newsize = _sh.size() == 0 ? 10 : _sh.size() * 2;//每一次扩容都要重新插入数据//2.创建新的哈希表HashTable<K, V> newHash;//3.将原表数据插入进去,复用已经实现的逻辑newHash._sh.resize(newsize);for (auto e : _sh){newHash.insert(e._kv);}//最后将新表与旧表交换即可_sh.swap(newHash._sh);}//开放定值法,线性探测解决冲突int hashi = kv.first % _sh.size();int i = 1; int hashn = hashi;while (_sh[hashn].state == EXIST){hashn = hashi + i;hashn %= _sh.size();i++;}_sh[hashn] = Date(kv);_sh[hashn].state = EXIST;_n++;return true;}
3.查询
查询步骤:
- 判空
- 探测查找
pair<K,bool> find(const K& key){//如果表中是空的,返回坐标,和插入falseif (_sh.empty()){return pair<K, bool>(-1, false);}//计算位置size_t hashi = key % _sh.size();int i = 1; int hashn = hashi;//线性探测直到遇到空while (_sh[hashn].state!=EMPTY){if (_sh[hashn].state == EXIST && _sh[hashn]._kv.first == key){//如果探测到,存在且键值相等,就返回该键值和turereturn pair<K, bool>(hashn,true);}hashn = hashi + i;hashn %= _sh.size();i++;if (hashn == hashi){//已经探测一圈回到了原点,即没找到return pair<K, bool>(-1, false);}}//遇到空没找到return pair<K, bool>(-1, false);}4.删除
//删除bool erase(const K& key){//先查询,存在就删除,不存在直接返回falsepair<int, bool> retfind = find(key);if (!retfind.second){return false;}//删除后修改状态_sh[retfind.first].state = DELETE;return true;}线性探测优点:实现非常简单。
线性探测缺点:一旦发生哈希冲突,所有的冲突连在一起,容易产生数据“堆积”,即:不同
关键码占据了可利用的空位置,使得寻找某关键码的位置需要许多次比较,导致搜索效率降
低。如何缓解呢?
四.开散列
开散列概念:
开散列法又叫链地址法(开链法),首先对关键码集合用散列函数计算散列地址,具有相同地
址的关键码归于同一子集合,每一个子集合称为一个桶,各个桶中的元素通过一个单链表链
接起来,各链表的头结点存储在哈希表中。
从上图可以看出,开散列中每个桶中放的都是发生哈希冲突的元素。
1.开散列实现
开散列的结点和结构:
template<class K, class V>struct HashDate{HashDate(pair<K, V> kv):_kv(kv),_next(nullptr){}pair<K, V> _kv; //键值对HashDate* _next; //下一个结点的指针};template<class K,class V>class Hashbucket{typedef HashDate<K, V> Date;typedef pair<K, V> KV;public:bool insert(KV kv){//...}Date* find(const K& key){//....}bool erase(const K& key){//...}~Hashbucket(){//....}private:vector<Date*> _table; //数据存储size_t _n = 0; //数据存储个数};
}2.插入
因为_table的表中存储都是每个结点的指针,每一个桶实际上就是一个链表,所以对哈希的插入实际就是对链表的头插。
bool insert(KV kv)
{//插入//计算桶的位置size_t hashi = kv.first % _table.size();//创建结点Date* newNode = new Date(kv);//新节点的next指向头节点newNode->_next = _table[hashi];//新插入的结点变成新的头_table[hashi] = newNode;_n++;
}扩容:
约定当数据个数达到桶的个数时,进行扩容:
扩容步骤:
bool insert(KV kv){//如果待插入的数据已经存在if ( find(kv.first)){return false;}//扩容if (_n == _table.size()){//计算新的桶数size_t newsize = _table.size() == 0 ? 10 : _table.size() * 2;//创建一个新的表vector<Date*> newtable;newtable.resize(newsize);//将就表中的结点拿过来,注意此处直接拿旧的结点插入新表,//而不是拿到数据后创建新的结点,减少不必要的消耗for (auto& cur : _table){while (cur){size_t hashi = cur->_kv.first % newtable.size();Date* next = cur->_next;cur->_next = newtable[hashi];newtable[hashi] = cur;cur = next;}}//新旧表交换_table.swap(newtable);}//插入size_t hashi = kv.first % _table.size();Date* newNode = new Date(kv);newNode->_next = _table[hashi];_table[hashi] = newNode;_n++;}3.查询
查询步骤:
- 找到桶
- 遍历桶中数据
找到了返回结点指针,没找到返回nullptr
Date* find(const K& key){//如果表是空的,即就是没有一个数据if (_table.empty()){return nullptr;}//1.计算桶的位置size_t hashi = key % _table.size();Date* cur = _table[hashi];//2.在桶里面遍历查询while (cur){if (cur->_kv.first == key){return cur;}cur = cur->_next;}return nullptr;}4.删除
删除归根结底还是链表的删除:
删除的步骤:
- 判断在不在表中
- 计算出桶的位置
- 找打待删除结点,并记录其前一个结点
- 改变指向,释放结点
bool erase(const K& key){//1.查找在不在表中if (!find(key)){return false;}//2.计算桶的位置size_t hashi = key % _table.size();Date* cur = _table[hashi];//记录前驱结点Date* prov = nullptr;//3.找到待删除的结点while (cur){if (cur->_kv.first == key){if (prov == nullptr){_table[hashi] = cur->_next; }else{prov->_next = cur->_next;}//4.删除改变指向,释放结点delete cur;return true;}else{prov = cur;cur = cur->_next;}}}5.析构函数
遍历表中每一个桶,并对每一个桶进行释放,对桶的销毁,就是对链表的销毁。
~Hashbucket(){for (auto& cur : _table){while (cur){Date* next = cur->_next;delete cur;cur = next;}cur = nullptr;}}五.完整代码即测试
#pragma once
#include<vector>
#include<iostream>
using namespace std;namespace HashOpenAdress
{enum State{EXIST,EMPTY,DELETE};template<class K, class V>struct HashDate{HashDate(){}HashDate(pair<K,V> kv):_kv(kv){}pair<K, V> _kv;State state = EMPTY;};template<class K, class V>class HashTable{typedef HashDate<K, V> Date;public:bool insert(pair<K, V> kv){//如果插入的值已经存在if (find(kv.first).second){return false;}//扩容//负载因子为0.7if (_sh.size() == 0 || _n * 10 / _sh.size() == 7){//确定新的容量int newsize = _sh.size() == 0 ? 10 : _sh.size() * 2;//每一次扩容都要重新插入数据HashTable<K, V> newHash;newHash._sh.resize(newsize);for (auto e : _sh){newHash.insert(e._kv);}_sh.swap(newHash._sh);}//开放定值法,线性探测解决冲突int hashi = kv.first % _sh.size();int i = 1; int hashn = hashi;while (_sh[hashn].state == EXIST){hashn = hashi + i;hashn %= _sh.size();i++;}_sh[hashn] = Date(kv);_sh[hashn].state = EXIST;_n++;return true;}bool erase(const K& key){pair<int, bool> retfind = find(key);if (!retfind.second){return false;}_sh[retfind.first].state = DELETE;return true;}pair<int,bool> find(const K& key){if (_sh.empty()){return pair<int, bool>(-1, false);}size_t hashi = key % _sh.size();int i = 1; int hashn = hashi;while (_sh[hashn].state!=EMPTY){if (_sh[hashn].state == EXIST && _sh[hashn]._kv.first == key){return pair<int,bool>(hashn,true);}hashn = hashi + i;hashn %= _sh.size();i++;if (hashn == hashi){return pair<int, bool>(-1, false);}}return pair<int, bool>(-1, false);}private:vector<Date> _sh; //数据存储size_t _n = 0; //存储数据的个数};
}namespace HashBucket
{template<class K, class V>struct HashDate{HashDate(pair<K, V> kv):_kv(kv),_next(nullptr){}pair<K, V> _kv;HashDate* _next;};template<class K,class V>class Hashbucket{typedef HashDate<K, V> Date;typedef pair<K, V> KV;public:bool insert(KV kv){//如果待插入的数据已经存在if ( find(kv.first)){return false;}//扩容if (_n == _table.size()){//计算新的桶数size_t newsize = _table.size() == 0 ? 10 : _table.size() * 2;//创建一个新的表vector<Date*> newtable;newtable.resize(newsize);//将就表中的结点拿过来,注意此处直接拿旧的结点插入新表,//而不是拿到数据后创建新的结点,减少不必要的消耗for (auto& cur : _table){while (cur){size_t hashi = cur->_kv.first % newtable.size();Date* next = cur->_next;cur->_next = newtable[hashi];newtable[hashi] = cur;cur = next;}}//新旧表交换_table.swap(newtable);}//插入size_t hashi = kv.first % _table.size();Date* newNode = new Date(kv);newNode->_next = _table[hashi];_table[hashi] = newNode;_n++;}Date* find(const K& key){//如果表是空的,即就是没有一个数据if (_table.empty()){return nullptr;}//1.计算桶的位置size_t hashi = key % _table.size();Date* cur = _table[hashi];//2.在桶里面遍历查询while (cur){if (cur->_kv.first == key){return cur;}cur = cur->_next;}return nullptr;}bool erase(const K& key){//1.查找在不在表中if (!find(key)){return false;}//2.计算桶的位置size_t hashi = key % _table.size();Date* cur = _table[hashi];//记录前驱结点Date* prov = nullptr;//3.找到待删除的结点while (cur){if (cur->_kv.first == key){if (prov == nullptr){_table[hashi] = cur->_next; }else{prov->_next = cur->_next;}//4.删除改变指向,释放结点delete cur;return true;}else{prov = cur;cur = cur->_next;}}}~Hashbucket(){for (auto& cur : _table){while (cur){Date* next = cur->_next;delete cur;cur = next;}cur = nullptr;}}private:vector<Date*> _table;size_t _n = 0;};
}相关文章:
unordered-------Hash
✅<1>主页:我的代码爱吃辣📃<2>知识讲解:数据结构——哈希表☂️<3>开发环境:Visual Studio 2022💬<4>前言:哈希是一种映射的思想,哈希表即使利用这种思想,…...

数据仓库总结
1.为什么要做数仓建模 数据仓库建模的目标是通过建模的方法更好的组织、存储数据,以便在性能、成本、效率和数据质量之间找到最佳平衡点。 当有了适合业务和基础数据存储环境的模型(良好的数据模型),那么大数据就能获得以下好处&…...
hadoop学习:mapreduce入门案例二:统计学生成绩
这里相较于 wordcount,新的知识点在于学生实体类的编写以及使用 数据信息: 1. Student 实体类 import org.apache.hadoop.io.WritableComparable;import java.io.DataInput; import java.io.DataOutput; import java.io.IOException;public class Stude…...

自学TypeScript-基础、编译、类型
自学TypeScript-基础、编译、类型 TS 编译为 JS类型支持类型注解基础类型typeof 运算符高级类型class 类构造函数和实例方法继承可见性只读 类型兼容性交叉类型泛型泛型约束多个泛型泛型接口泛型类泛型工具 索引签名类型映射类型索引查询(访问)类型 类型声明文件 TypeScript 是…...

nginx配置https
1.安装nginx 安装完成后检查 nginx -V2.申请证书与上传 阿里云申请免费的证书 然后上传到某个目录 3.修改nginx配置 #user nobody; worker_processes 1;#error_log logs/error.log; #error_log logs/error.log notice; #error_log logs/error.log info;#pid …...
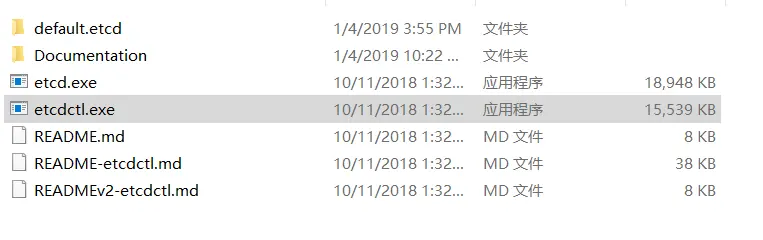
windows Etcd的安装与使用
一、简介 etcd是一个分布式一致性键值存储,其主要用于分布式系统的共享配置和服务发现。 etcd由Go语言编写 二、下载并安装 1.下载地址: https://github.com/coreos/etcd/releases 解压后的目录如下:其中etcd.exe是服务端,e…...

【py】为什么用 import tkinter 不能运行
为什么用 import tkinter 不能运行 ━━━━━━━━━━━━━━━━━━━━━━ 要显示一个信息框,为什么用 import tkinter 不能运行,改成from tkinter import messagebox 就可以运行了? 可能是因为您的代码中只使用了 messagebox 这个模…...

【深度学习】实验04 交叉验证
文章目录 交叉验证划分自定义划分K折交叉验证留一交叉验证留p交叉验证随机排列交叉验证分层K折交叉验证分层随机交叉验证 分割组 k-fold分割留一组分割留 P 组分割随机分割时间序列分割 交叉验证 # 导入相关库# 交叉验证所需函数 from sklearn.model_selection import train_t…...

whisper语音识别部署及WER评价
1.whisper部署 详细过程可以参照:🏠 创建项目文件夹 mkdir whisper cd whisper conda创建虚拟环境 conda create -n py310 python3.10 -c conda-forge -y 安装pytorch pip install --pre torch torchvision torchaudio --extra-index-url 下载whisper p…...

java太卷了,怎么办?
忧虑: 马上就到30岁了,最近对于自己职业生涯的规划甚是焦虑。在网站论坛上,可谓是哀鸿遍野,大家纷纷叙述着自己被裁后求职的艰辛路程,这更加加深了我的忧虑,于是在各大论坛开始“求医问药”,想…...

android多屏触摸相关的详解方案-安卓framework开发手机车载车机系统开发课程
背景 直播免费视频课程地址:https://www.bilibili.com/video/BV1hN4y1R7t2/ 在做双屏相关需求开发过程中,经常会有对两个屏幕都要求可以正确触摸的场景。但是目前我们模拟器默认创建的双屏其实是没有办法进行触摸的 修改方案1 静态修改方案 使用命令…...
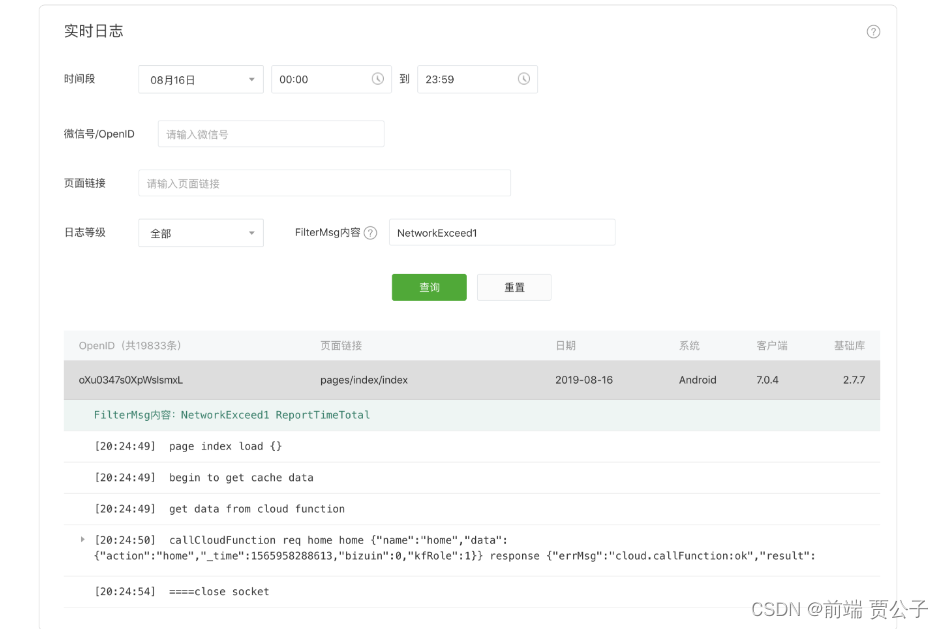
微信小程序 实时日志
目录 实时日志 背景 如何使用 如何查看日志 注意事项 实时日志 背景 为帮助小程序开发者快捷地排查小程序漏洞、定位问题,我们推出了实时日志功能。从基础库2.7.1开始,开发者可通过提供的接口打印日志,日志汇聚并实时上报到小程序后台…...
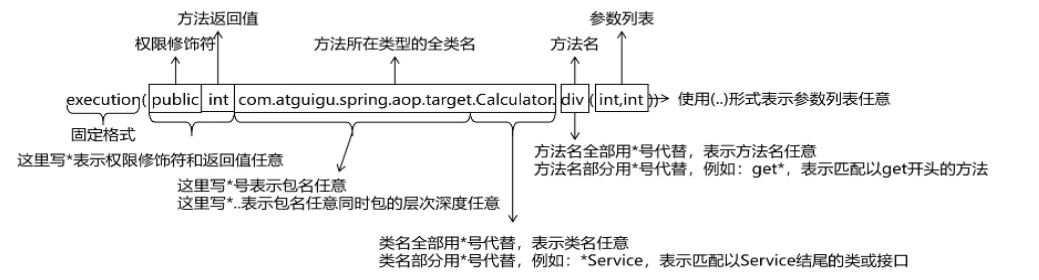
Spring AOP基于注解方式实现和细节
目录 一、Spring AOP底层技术 二、初步实现AOP编程 三、获取切点详细信息 四、 切点表达式语法 五、重用(提取)切点表达式 一、Spring AOP底层技术 SpringAop的核心在于动态代理,那么在SpringAop的底层的技术是依靠了什么技术呢&#x…...

CVPR2023论文及代码合集来啦~
以下内容由马拉AI整理汇总。 下载:点我跳转。 狂肝200小时的良心制作,529篇最新CVPR2023论文及其Code,汇总成册,制作成《CVPR 2023论文代码检索目录》,包括以下方向: 1、2D目标检测 2、视频目标检测 3、…...
基于ETLCloud的自定义规则调用第三方jar包实现繁体中文转为简体中文
背景 前面曾体验过通过零代码、可视化、拖拉拽的方式快速完成了从 MySQL 到 ClickHouse 的数据迁移,但是在实际生产环境,我们在迁移到目标库之前还需要做一些过滤和转换工作;比如,在诗词数据迁移后,发现原来 MySQL 中…...
TDesign在按钮上加入图标组件
在实际开发中 我们经常会遇到例如 添加或者查询 我们需要在按钮上加入图标的操作 TDesign自然也有预备这样的操作 首先我们打开文档看到图标 例如 我们先用某些图标 就可以点开下面的代码 可以看到 我们的图标大部分都是直接用tdesign-icons-vue 导入他的组件就可以了 而我…...

Linux 终端命令行 产品介绍
Linux命令手册内置570多个Linux 命令,内容包含 Linux 命令手册。 【软件功能】: 文件传输 bye、ftp、ftpcount、ftpshut、ftpwho、ncftp、tftp、uucico、uucp、uupick、uuto、scp备份压缩 ar、bunzip2、bzip2、bzip2recover、compress、cpio、dump、gun…...
计算机毕设 基于深度学习的植物识别算法 - cnn opencv python
文章目录 0 前言1 课题背景2 具体实现3 数据收集和处理3 MobileNetV2网络4 损失函数softmax 交叉熵4.1 softmax函数4.2 交叉熵损失函数 5 优化器SGD6 最后 0 前言 🔥 这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设题目缺少创新和亮点&a…...
【STM32】学习笔记-江科大
【STM32】学习笔记-江科大 1、STM32F103C8T6的GPIO口输出 2、GPIO口输出 GPIO(General Purpose Input Output)通用输入输出口可配置为8种输入输出模式引脚电平:0V~3.3V,部分引脚可容忍5V输出模式下可控制端口输出高低电平&#…...
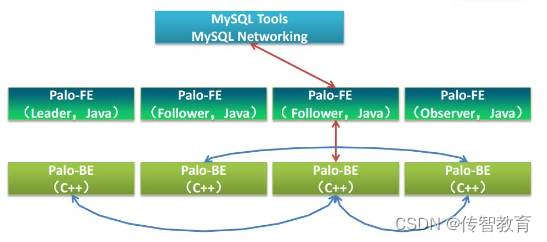
Doris架构中包含哪些技术?
Doris主要整合了Google Mesa(数据模型),Apache Impala(MPP Query Engine)和Apache ORCFile (存储格式,编码和压缩)的技术。 为什么要将这三种技术整合? Mesa可以满足我们许多存储需求的需求,但是Mesa本身不提供SQL查询引擎。 Impala是一个…...

华为昇腾Atlas200边缘设备开箱即用指南:从CANN环境到YOLOv8模型部署的保姆级避坑教程
华为昇腾Atlas200边缘设备实战:YOLOv8模型部署全流程避坑指南 第一次拿到华为昇腾Atlas200边缘计算设备时,那种既兴奋又忐忑的心情记忆犹新。作为一款专为AI推理设计的边缘设备,Atlas200凭借其强大的算力和紧凑的体型,在智能安防…...

Taotoken控制台提供的API Key管理与访问控制功能详解
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken控制台提供的API Key管理与访问控制功能详解 对于团队管理者或项目负责人而言,如何安全、高效地分发和管理大模…...

GD32F4xx内部FLASH读写避坑指南:从用户手册到代码调试,手把手教你搞定0x08040000地址操作
GD32F4xx内部FLASH操作实战:从手册解读到调试验证的完整指南 第一次接触GD32F4系列MCU的内部FLASH操作时,很多开发者都会遇到各种"坑":为什么擦除后数据变成了0xFF?为什么写入操作会失败?地址0x08040000到底…...

2026 运营实战:AI 电商生图能快速上手的工具深度测评,哪款是你的大促生产力?
随着 618 电商节 大促之战打响,电商圈可以说是全行业交付压力最高的地方。尤其是现在的跨平台视觉竞争,不仅对视觉的高级感和 3D 渲染有要求,更看重一个字——快。如果一个爆款链接需要快速延展出厨房电器、宠物用品等不同类目的几百张不同尺…...

TPS5450同步降压转换器设计:从宽压输入到5V/3.3V输出的工程实践
1. 项目概述与芯片选型考量最近在做一个需要从较高直流电压(比如12V或24V)降压到5V和3.3V为系统供电的项目,电流需求还不小,峰值可能达到3A以上。这种场景下,传统的线性稳压器(LDO)效率太低&…...

5分钟快速上手:Parsec VDD虚拟显示器完整指南,彻底释放游戏串流潜能
5分钟快速上手:Parsec VDD虚拟显示器完整指南,彻底释放游戏串流潜能 【免费下载链接】parsec-vdd ✨ Perfect virtual display for game streaming 项目地址: https://gitcode.com/gh_mirrors/pa/parsec-vdd 想要在没有物理显示器的情况下畅享4K游…...

赶Due救急必看!从飙红到安全线:5款降AI工具红黑榜与免费指令微调法
为了找到真正靠谱的解决方案,我过去测试了市面上大部分号称能降低ai率的方法。从一分钱不花的模型指令,到各种付费的专业降ai率工具,用手头的文本做了几十次实操对比。说心里话,里面套路确实不少,有些方法用完后语句颠…...

给企业主机穿上安全防护“黄金甲”,打造金城汤池
主机安全主要的风险来源——漏洞众所周知,软件是构成数字世界的基础,但是软件都是人为编写的,与一切皆可编程相对应的是,一切软件都存在漏洞。平均每千行代码就有4-6个安全缺陷,漏洞是网络安全的命门。但是,…...

告别复制粘贴:如何在 Cursor / 各种 IDE 中丝滑接入本地 AI 模型?
引言:AI 编程时代的囚徒困境 2026 年,AI 编程助手已经像 Git 一样成为每个开发者的标配。Cursor 的订阅量持续暴涨,GitHub Copilot 的免费版已经吸引了上千万用户,JetBrains 全线 IDE 都深度集成了 AI Agent。但在这个表面繁荣的生态之下,每一位开发者都在不知不觉中交出…...

vscode过滤文件
const fs require(fs); const { exec } require(child_process);// 在这里输入你的关键词,每行一个 const keywordsStr BV1wmXwBCEsZ BV1MR6wBREhY BV1DuoSYuEpX ; // // 将多行字符串按换行符分割,过滤掉空行 const keywords keywordsStr.trim()…...