扩散模型实战(八):微调扩散模型
推荐阅读列表:
扩散模型实战(一):基本原理介绍
扩散模型实战(二):扩散模型的发展
扩散模型实战(三):扩散模型的应用
扩散模型实战(四):从零构建扩散模型
扩散模型实战(五):采样过程
扩散模型实战(六):Diffusers DDPM初探
扩散模型实战(七):Diffusers蝴蝶图像生成实战
微调在LLM中并不是新鲜的概念,从头开始训练一个扩散模型需要很长的时间,特别是使用高分辨率图像训练。那么其实我们可以在已经训练好的”去噪“扩散模型基础上使用微调数据集进行二次微调训练。
本文将介绍基于蝴蝶数据集上微调人脸生成的扩散模型:
一、环境准备
1.1 安装相关库
!pip install -qq diffusers datasets accelerate wandb open-clip-torch1.2 登录Huggingface Hub
如果需要开源微调好的模型到Huggingface Hub上,那么需要使用如下代码登录,否则可忽略此步骤:
from huggingface_hub import notebook_loginnotebook_login()
1.3 导入相关库
import numpy as npimport torchimport torch.nn.functional as Fimport torchvisionfrom datasets import load_datasetfrom diffusers import DDIMScheduler, DDPMPipelinefrom matplotlib import pyplot as pltfrom PIL import Imagefrom torchvision import transformsfrom tqdm.auto import tqdmdevice = ("mps"if torch.backends.mps.is_available()else "cuda"if torch.cuda.is_available()else "cpu")
二、导入预训练的扩散模型
下面我们导入人脸生成的扩散模型,观察一下生成的效果,代码如下:
image_pipe = DDPMPipeline.from_pretrained("google/ddpm-celebahq-256")image_pipe.to(device);
查看生成的图像,代码如下:
images = image_pipe().imagesimages[0]

生成的效果虽然不错,但是速度稍微有点慢,其实有更快的采样器可以加速这一过程,比如下面介绍的DDIM
三、DDIM-更快的采样器
在生成图像的每一步中,模型都会接收一个带有噪声的输入,并且需要预测这个噪声,以此来估计没有噪声的完整图像是什么。这个过程被称为采样过程,在Diffusers库中,采样通过调度器控制的,之前的文章中介绍过DDPMScheduler调度器,本文介绍的DDIMScheduler可以通过更少的迭代周期来产生很好的采样样本(1000多步采样不是必须的)。
# 创建一个新的调度器并设置推理迭代次数scheduler = DDIMScheduler.from_pretrained("google/ddpm-celebahq-256")scheduler.set_timesteps(num_inference_steps=40)
scheduler.timesteps# 输出tensor([975, 950, 925, 900, 875, 850, 825, 800, 775, 750, 725,700, 675, 650, 625, 600, 575, 550, 525, 500, 475, 450, 425,400, 375, 350, 325, 300, 275, 250, 225, 200, 175, 150,125, 100, 75, 50, 25, 0])
下面使用4幅随机噪声图像进行循环采样,并观察每一步的输入与输出的”去噪“图像,代码如下:
# 从随机噪声开始x = torch.randn(4, 3, 256, 256).to(device)# batch size为4,三通道,长、宽均为256像素的一组图像# 循环一整套时间步for i, t in tqdm(enumerate(scheduler.timesteps)):# 准备模型输入:给“带躁”图像加上时间步信息model_input = scheduler.scale_model_input(x, t)# 预测噪声with torch.no_grad():noise_pred = image_pipe.unet(model_input, t)["sample"]# 使用调度器计算更新后的样本应该是什么样子scheduler_output = scheduler.step(noise_pred, t, x)# 更新输入图像x = scheduler_output.prev_sample# 时不时看一下输入图像和预测的“去噪”图像if i % 10 == 0 or i == len(scheduler.timesteps) - 1:fig, axs = plt.subplots(1, 2, figsize=(12, 5))grid = torchvision.utils.make_grid(x, nrow=4).permute(1, 2, 0)axs[0].imshow(grid.cpu().clip(-1, 1) * 0.5 + 0.5)axs[0].set_title(f"Current x (step {i})")pred_x0 = (scheduler_output.pred_original_sample)grid = torchvision.utils.make_grid(pred_x0, nrow=4).permute(1, 2, 0)axs[1].imshow(grid.cpu().clip(-1, 1) * 0.5 + 0.5)axs[1].set_title(f"Predicted denoised images (step {i})")plt.show()





第二步生成图像的采样器是DDPMScheduler,我们可以使用新的DDIMScheduler来代替DDPMScheduler看看image_pipe生成的效果是否有提升,代码如下:
image_pipe.scheduler = schedulerimages = image_pipe(num_inference_steps=40).imagesimages[0]

上述介绍了生成人脸的扩散模型以及生成的效果,也介绍了更快的采样器DDIMScheduler,下面我们使用蝴蝶数据集来微调人脸生成扩散模型:
四、微调人脸生成扩散模型
4.1 加载蝴蝶数据集
dataset_name = "huggan/smithsonian_butterflies_subset"dataset = load_dataset(dataset_name, split="train")image_size = 256batch_size = 4preprocess = transforms.Compose([transforms.Resize((image_size, image_size)),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize([0.5], [0.5]),])def transform(examples):images = [preprocess(image.convert("RGB")) for image inexamples["image"]]return {"images": images}dataset.set_transform(transform)train_dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size, shuffle=True)
输出4幅蝴蝶图像,便于观察
print("Previewing batch:")batch = next(iter(train_dataloader))grid = torchvision.utils.make_grid(batch["images"], nrow=4)plt.imshow(grid.permute(1, 2, 0).cpu().clip(-1, 1) * 0.5 + 0.5)

4.2 微调人脸生成扩散模型
num_epochs = 2lr = 1e-5grad_accumulation_steps = 2optimizer = torch.optim.AdamW(image_pipe.unet.parameters(), lr=lr)losses = []for epoch in range(num_epochs):for step, batch in tqdm(enumerate(train_dataloader),total=len(train_dataloader)):clean_images = batch["images"].to(device)# 随机生成一个噪声,稍后加到图像上noise = torch.randn(clean_images.shape).to(clean_images.device)bs = clean_images.shape[0]# 随机选取一个时间步timesteps = torch.randint(0,image_pipe.scheduler.num_train_timesteps,(bs,),device=clean_images.device,).long()# 根据选中的时间步和确定的幅值,在干净图像上添加噪声# 此处为前向扩散过程noisy_images = image_pipe.scheduler.add_noise(clean_images,noise, timesteps)# 使用“带噪”图像进行网络预测noise_pred = image_pipe.unet(noisy_images, timesteps,return_dict=False)[0]# 对真正的噪声和预测的结果进行比较,注意这里是预测噪声loss = F.mse_loss(noise_pred, noise)# 保存损失值losses.append(loss.item())# 根据损失值更新梯度loss.backward()# 进行梯度累积,在累积到一定步数后更新模型参数if (step + 1) % grad_accumulation_steps == 0:optimizer.step()optimizer.zero_grad()print(f"Epoch {epoch} average loss: {sum(losses[-len(train_dataloader):])/len(train_dataloader)}")# 画出损失曲线,效果如图所示plt.plot(losses)
4.3 使用微调好的模型生成图像
x = torch.randn(8, 3, 256, 256).to(device)for i, t in tqdm(enumerate(scheduler.timesteps)):model_input = scheduler.scale_model_input(x, t)with torch.no_grad():noise_pred = image_pipe.unet(model_input, t)["sample"]x = scheduler.step(noise_pred, t, x).prev_samplegrid = torchvision.utils.make_grid(x, nrow=4)plt.imshow(grid.permute(1, 2, 0).cpu().clip(-1, 1) * 0.5 + 0.5)

从图中可以看出生成的图像有蝴蝶数据的风格。
4.4 保持微调好的扩散模型,并且上传到Huggingface Hub中
image_pipe.save_pretrained("my-finetuned-model")from huggingface_hub import HfApi, ModelCard, create_repo, get_full_repo_name# 配置Hugging Face Hub,上传文件model_name = "ddpm-celebahq-finetuned-butterflies-2epochs"# 使用@param 脚本程序对上传到# Hugging Face Hub的文件进行命名local_folder_name = "my-finetuned-model" # @param脚本程序生成的名字,# 你也可以通过 image_pipe.save_pretrained('savename')自行指定description = "Describe your model here" # @paramhub_model_id = get_full_repo_name(model_name)create_repo(hub_model_id)api = HfApi()api.upload_folder(folder_path=f"{local_folder_name}/scheduler",path_in_repo="",repo_id=hub_model_id )api.upload_folder(folder_path=f"{local_folder_name}/unet", path_in_repo="",repo_id=hub_model_id )api.upload_file(path_or_fileobj=f"{local_folder_name}/model_index.json",path_in_repo="model_index.json",repo_id=hub_model_id,)# 添加一个模型卡片,这一步虽然不是必需的,但可以给他人提供一些模型描述信息content = f"""---license: mittags:- pytorch- diffusers- unconditional-image-generation- diffusion-models-class---# 用法from diffusers import DDPMPipelinepipeline = DDPMPipeline.from_pretrained(' {hub_model_id}')image = pipeline().images[0]image'''"""card = ModelCard(content)card.push_to_hub(hub_model_id)
微调Trick:
- 设置合适的batch_size,batch_size要在不超过GPU显存的前提下,尽量大一些,这样可以提高GPU计算效果;如果特别小,可以采用梯度累积的方式来更新模型参数,达到和大batch_size类似的效果,也就是多运行几次loss.backward(),再调用optimizer.step()和optimizer.zero_grad();
- 训练过程中,要时不时生成一些图像样本来观察模型性能;
- 训练过程中,可以把损失值、生成的图像样本等信息记录在日志中,可以使用Weights and Biases、TensorBoard等工具;
相关文章:
扩散模型实战(八):微调扩散模型
推荐阅读列表: 扩散模型实战(一):基本原理介绍 扩散模型实战(二):扩散模型的发展 扩散模型实战(三):扩散模型的应用 扩散模型实战(四…...

Android 全局控件属性设置
一 使用需求: 如 设置全局字体、全局文本属性设置 二 实现方式: 在App使用的主题中,添加属性及属性值 如给所有的文本设置属性,注释部分作用是设置应用全局字体 <style name"Theme.AppDemo" parent"Base.Theme.AppDemo&q…...

下面是实践百度飞桨上面的pm2.5分类项目_logistic regression相关
part1:数据的引入,和前一个linear regression基本是一样 part2:数据解析——也就是数据的“规格化” 首先,打算用dataMat[]和labelMat[]数据存储feature和label,并且文件变量fr 然后,是这个for line in fr.readlines()循环&#…...

阿里云误删Python后域yum报错解决方案
阿里云误删Python后域yum报错解决方案 1:找回所有依赖 这里依赖可能很多,也搞不清楚有哪些,建议买一台临时服务器,系统选择跟你当前的系统一致的,配置选最低就行 2:登录临时服务器,创建临时文件夹 mkdir /usr/local/yum-fix cd /usr/local/yum-fix3:查找并下载所有云依赖 r…...
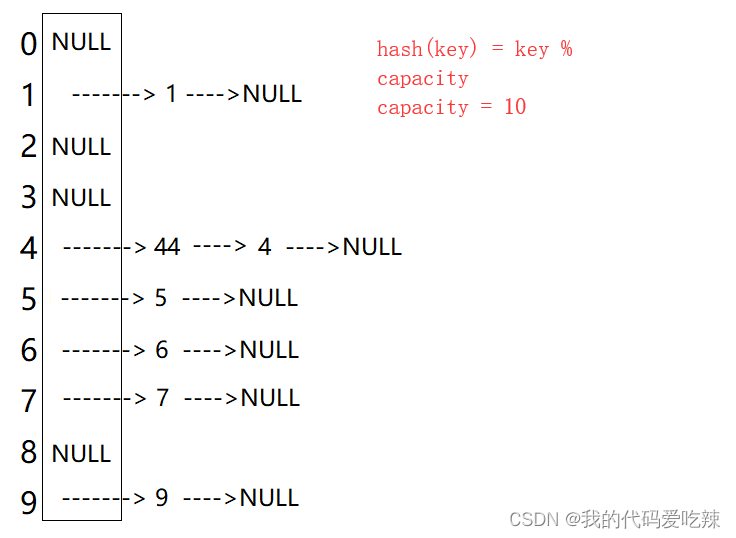
unordered-------Hash
✅<1>主页:我的代码爱吃辣📃<2>知识讲解:数据结构——哈希表☂️<3>开发环境:Visual Studio 2022💬<4>前言:哈希是一种映射的思想,哈希表即使利用这种思想,…...

数据仓库总结
1.为什么要做数仓建模 数据仓库建模的目标是通过建模的方法更好的组织、存储数据,以便在性能、成本、效率和数据质量之间找到最佳平衡点。 当有了适合业务和基础数据存储环境的模型(良好的数据模型),那么大数据就能获得以下好处&…...
hadoop学习:mapreduce入门案例二:统计学生成绩
这里相较于 wordcount,新的知识点在于学生实体类的编写以及使用 数据信息: 1. Student 实体类 import org.apache.hadoop.io.WritableComparable;import java.io.DataInput; import java.io.DataOutput; import java.io.IOException;public class Stude…...

自学TypeScript-基础、编译、类型
自学TypeScript-基础、编译、类型 TS 编译为 JS类型支持类型注解基础类型typeof 运算符高级类型class 类构造函数和实例方法继承可见性只读 类型兼容性交叉类型泛型泛型约束多个泛型泛型接口泛型类泛型工具 索引签名类型映射类型索引查询(访问)类型 类型声明文件 TypeScript 是…...

nginx配置https
1.安装nginx 安装完成后检查 nginx -V2.申请证书与上传 阿里云申请免费的证书 然后上传到某个目录 3.修改nginx配置 #user nobody; worker_processes 1;#error_log logs/error.log; #error_log logs/error.log notice; #error_log logs/error.log info;#pid …...
windows Etcd的安装与使用
一、简介 etcd是一个分布式一致性键值存储,其主要用于分布式系统的共享配置和服务发现。 etcd由Go语言编写 二、下载并安装 1.下载地址: https://github.com/coreos/etcd/releases 解压后的目录如下:其中etcd.exe是服务端,e…...

【py】为什么用 import tkinter 不能运行
为什么用 import tkinter 不能运行 ━━━━━━━━━━━━━━━━━━━━━━ 要显示一个信息框,为什么用 import tkinter 不能运行,改成from tkinter import messagebox 就可以运行了? 可能是因为您的代码中只使用了 messagebox 这个模…...

【深度学习】实验04 交叉验证
文章目录 交叉验证划分自定义划分K折交叉验证留一交叉验证留p交叉验证随机排列交叉验证分层K折交叉验证分层随机交叉验证 分割组 k-fold分割留一组分割留 P 组分割随机分割时间序列分割 交叉验证 # 导入相关库# 交叉验证所需函数 from sklearn.model_selection import train_t…...

whisper语音识别部署及WER评价
1.whisper部署 详细过程可以参照:🏠 创建项目文件夹 mkdir whisper cd whisper conda创建虚拟环境 conda create -n py310 python3.10 -c conda-forge -y 安装pytorch pip install --pre torch torchvision torchaudio --extra-index-url 下载whisper p…...

java太卷了,怎么办?
忧虑: 马上就到30岁了,最近对于自己职业生涯的规划甚是焦虑。在网站论坛上,可谓是哀鸿遍野,大家纷纷叙述着自己被裁后求职的艰辛路程,这更加加深了我的忧虑,于是在各大论坛开始“求医问药”,想…...

android多屏触摸相关的详解方案-安卓framework开发手机车载车机系统开发课程
背景 直播免费视频课程地址:https://www.bilibili.com/video/BV1hN4y1R7t2/ 在做双屏相关需求开发过程中,经常会有对两个屏幕都要求可以正确触摸的场景。但是目前我们模拟器默认创建的双屏其实是没有办法进行触摸的 修改方案1 静态修改方案 使用命令…...
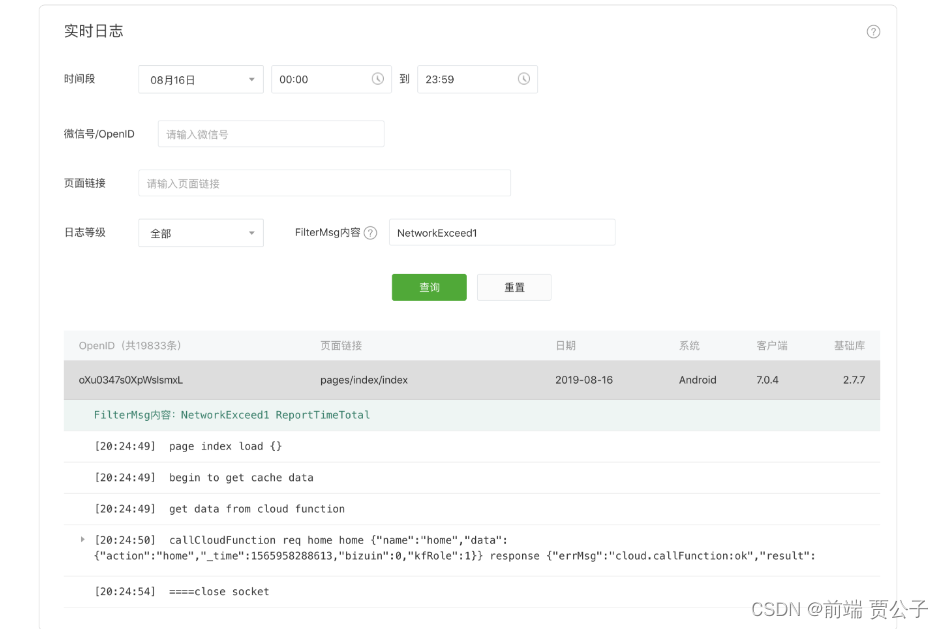
微信小程序 实时日志
目录 实时日志 背景 如何使用 如何查看日志 注意事项 实时日志 背景 为帮助小程序开发者快捷地排查小程序漏洞、定位问题,我们推出了实时日志功能。从基础库2.7.1开始,开发者可通过提供的接口打印日志,日志汇聚并实时上报到小程序后台…...
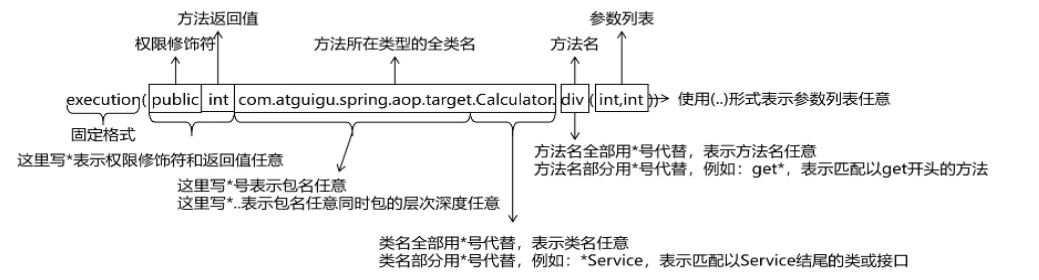
Spring AOP基于注解方式实现和细节
目录 一、Spring AOP底层技术 二、初步实现AOP编程 三、获取切点详细信息 四、 切点表达式语法 五、重用(提取)切点表达式 一、Spring AOP底层技术 SpringAop的核心在于动态代理,那么在SpringAop的底层的技术是依靠了什么技术呢&#x…...

CVPR2023论文及代码合集来啦~
以下内容由马拉AI整理汇总。 下载:点我跳转。 狂肝200小时的良心制作,529篇最新CVPR2023论文及其Code,汇总成册,制作成《CVPR 2023论文代码检索目录》,包括以下方向: 1、2D目标检测 2、视频目标检测 3、…...
基于ETLCloud的自定义规则调用第三方jar包实现繁体中文转为简体中文
背景 前面曾体验过通过零代码、可视化、拖拉拽的方式快速完成了从 MySQL 到 ClickHouse 的数据迁移,但是在实际生产环境,我们在迁移到目标库之前还需要做一些过滤和转换工作;比如,在诗词数据迁移后,发现原来 MySQL 中…...
TDesign在按钮上加入图标组件
在实际开发中 我们经常会遇到例如 添加或者查询 我们需要在按钮上加入图标的操作 TDesign自然也有预备这样的操作 首先我们打开文档看到图标 例如 我们先用某些图标 就可以点开下面的代码 可以看到 我们的图标大部分都是直接用tdesign-icons-vue 导入他的组件就可以了 而我…...

从MSP430到MSPM0L1306:嵌入式工程迁移实战与SDK应用指南
1. 项目概述:从零理解MSPM0L1306的工程迁移最近在帮一个朋友处理一个老项目升级,核心需求是把一个基于TI老款MSP430系列MCU的温控器,迁移到TI新推出的MSPM0L1306这颗芯片上。朋友的原话是:“老芯片快买不到了,新出的MS…...

智能安卓主板选型指南:从需求分析到量产落地的全流程解析
1. 项目概述:智能安卓主板选型的核心价值在嵌入式开发和智能硬件项目里,选对一块主板,往往意味着项目成功了一半。我见过太多团队,前期功能设计得天花乱坠,结果卡在了硬件选型上,要么性能过剩成本失控&…...

录音总结会议纪要推荐,零基础新手避坑可直接上手指南
这是专为零基础新手整理的2026年录音转会议纪要避坑指南,适配喜欢尝试效率工具、想借助AI节省整理时间的朋友,所有推荐均按实际场景适配度排序,内容简洁易懂,看完可直接上手,无需自行试错踩坑。很多新手接触录音转会议…...

如何快速使用TestDisk PhotoRec:数据恢复的完整终极指南
如何快速使用TestDisk & PhotoRec:数据恢复的完整终极指南 【免费下载链接】testdisk TestDisk & PhotoRec 项目地址: https://gitcode.com/gh_mirrors/te/testdisk 当您不小心删除了重要的工作文档,或者硬盘分区突然消失不见,…...

重载大件物料输送选滚筒线还是倍速链?
在自动化输送行业摸爬滚打十几年,见过太多工厂因为选错输送线栽跟头——有厂家跟风选倍速链输送重型模具,运行不到一个月就出现链条磨损、滚筒卡死,停产检修花了几万块;也有工厂明明是大件重载输送,却选了轻型滚筒线&a…...

如何用四探针精确测量半导体电阻率
在半导体行业中,准确测量晶圆电阻率是材料研发和制程质量控制的关键环节。随着工艺节点不断缩小,器件对电性一致性的要求日益严格,仅靠经验无法满足现代制造的需求。因此工程师们大量采用四探针方法对电阻率进行高精度测量。相比传统测量方式…...

Python 浅拷贝与深拷贝:为什么我改了 b,a 也跟着变了?
Python 浅拷贝与深拷贝:为什么我改了 b,a 也跟着变了? 在 Python 中,列表、字典、集合这类对象都属于可变对象。 也正因为它们“可变”,所以在复制数据时,经常会遇到一个非常经典的问题:明明我改…...

Microblaze软核处理器在SRAM型FPGA中的抗单粒子效应高可靠加固方案
1. 项目概述:为什么要在太空里“加固”一个软核处理器?在工业自动化、医疗影像或者汽车电子领域,你或许听说过Xilinx FPGA里的Microblaze软核处理器。它就像一个可以随心所欲“捏”出来的32位或64位CPU大脑,开发者能根据项目需求&…...

低代码平台推荐:零基础业务人员专属
在数字化转型加速的当下,低代码已成为打破IT资源瓶颈的关键抓手。本文专为零基础业务人员深度拆解零门槛低代码平台的选型逻辑与落地路径。通过7大核心问答,系统梳理从技能门槛、平台评估到架构融合的实战经验。据行业调研显示,采用成熟低代码…...

网络工程师避坑指南:eNSP中配置Eth-Trunk链路聚合的5个常见错误与排查方法
网络工程师避坑指南:eNSP中配置Eth-Trunk链路聚合的5个常见错误与排查方法 在华为eNSP模拟器中配置Eth-Trunk链路聚合时,许多网络工程师都会遇到各种"翻车"现场。明明按照教程一步步操作,却发现带宽没有叠加、端口状态异常…...