性能提升3-4倍!贝壳基于Flink + OceanBase的实时维表服务

作者介绍:肖赞,贝壳找房(北京)科技有限公司 OLAP 平台负责人,基础研发线大数据平台部架构师。
贝壳找房是中国最大的居住服务平台。作为居住产业数字化服务平台,贝壳致力于推进居住服务的产业数字化、智能化进程,通过聚合、助力优质服务者,为中国家庭提供包括二手房交易、新房交易、租赁、家装、家居、家服等一站式、高品质、高效率服务。
前几天,我们在《贝壳降本提效实践:基于 OceanBase 的实时字典服务》中,介绍了实时字典服务的应用场景,在上线 OceanBase 后,贝壳获得了更高的查询性能和稳定性。今天为大家介绍 OceanBase 在贝壳的第二个应用场景——实时维表服务,通过替代原有的 HBase 维表服务,让贝壳的性能提升了 3-4 倍,硬件成本节省了一半,与此同时,运维成本获得了极大降低。

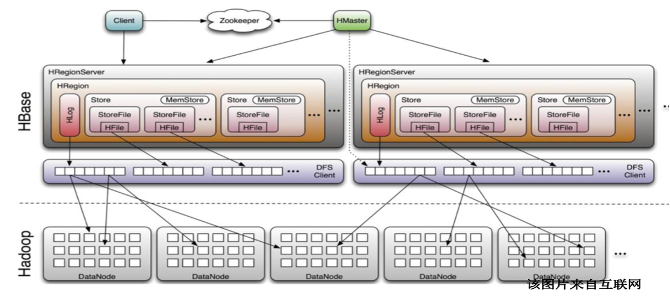
在典型的实时数仓或实时业务场景里,Flink 实时流处理过程中,经常需要将事实表与外部维度表进行关联,查询维度表,补全事实表中的信息。例如,在贝壳家居等业务场景中,需要在用户下单后将订单信息与维度表中商品信息的相关信息进行实时关联。考虑到维表数据量较大,并且 Flink 实时查询 QPS 较高,传统数据库 MySQL 等难以支撑,因此,贝壳采用 HBase 作为维表。HBase 是一个分布式列存储 NoSQL 数据库,具有较好地查询性能,但是也存在一些痛点。
痛点 1:HBase 不支持二级索引
在许多应用场景中,Flink 任务关联维度表时,除了需要基于主键字段进行关联外,还需要其他非主键字段进行关联。但是,HBase 只支持行键(Row Key)作为单一索引,本身并不直接支持二级索引。Apache Phoenix 等项目对 HBase 的基础上进行扩展,能够实现类似于二级索引的功能,但是需要更多的开发和维护成本。
痛点 2:HBase 依赖较多,部署复杂,成本高
HBase 是构建在 Hadoop 生态系统之上的,它依赖于分布式文件系统 HDFS 用于数据的持久化存储,依赖 ZooKeeper 来完成选举、节点管理、集群元数据维护等,因此,在生产环境中部署 HBase 之前,需要先部署和配置 Hadoop、ZooKeeper 等组件,涉及组件多,部署较复杂,运维成本较高,硬件成本也较高,特别是在一些特殊场景下需要分别为其部署独立的 HBase 集群。
基于上述背景,贝壳将目光投向分布式数据库,并锁定具备高性能、高可靠性和可扩展性的 OceanBase。同时,OceanBase 能够很好地解决贝壳业务痛点。
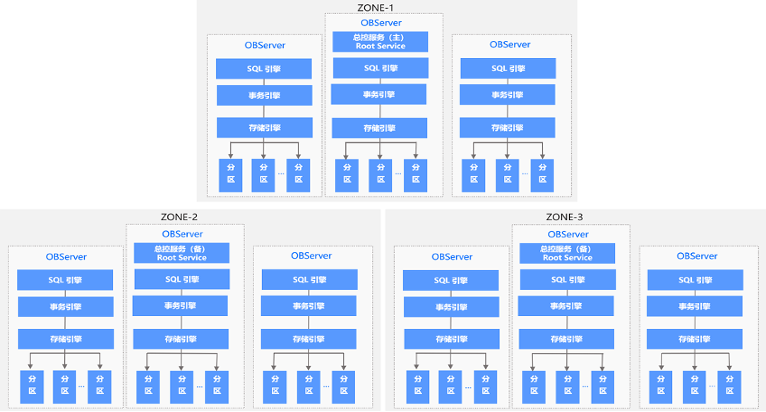
首先,OceanBase 原生支持二级索引功能,可以直接在维表上创建额外的索引,提升维表的查询性能。其次,OceanBase 只有 OBServer 一个角色,不依赖任何外部组件,天然具备高可用能力,部署非常简单。同时,其自带的周边工具也可以快速安装,比如通过 OCP(OceanBase Cloud Platform)白屏化安装或通过 OBD(OceanBase Deployer)命令行安装集群,运维很方便。
在部署资源消耗方面,HBase 方案机器成本大概是 OceanBase 的 2 倍。因为 HBase 为了保证高可用, 采用了双 HRegionServer,而 HBase 又是基于三副本的 Hadoop 存储数据, 所以,一份数据通常需要六副本。在集群规模不大时,使用 Zookeeper、Hadoop 会带来大量额外的机器冗余。但是,使用 OceanBase 存储数据只需要三副本,成本降低一半。
因此,贝壳决定在实时计算平台中引入 OceanBase 作为实时维表存储,在此之前,对 OceanBase 和 HBase 在实时维表 1 对 N 关联和维表 1 对 N 关联场景进行了全面的性能测试对比。

第一,环境准备
OceanBase 和 HBase 测试集群均采用 3 台 Dell EMC PowerEdge R740 服务器节点组成,节点配置规格为:80C/188G/2.9T Nvme SSD,所有的测试任务均运行在同一个 Hadoop 实时集群。HBase 版本为 1.4.9,HBase 集群由 HBase DBA 协助部署和配置,OceanBase 版本为 3.1.2,使用默认配置。
第二,测试方案
首先,为验证维表数据量对于查询性能影响,分别准备了 1 亿、2000 万、10 万的随机测试数据插入 OceanBase 及 HBase,其中主键(HBase为 rowKey)为从 1 至测试数据量的顺序值,OceanBase 建表 DDL 及样例数据如下:
show create table tb_dim_benchmark_range_partitioned;create table `tb_dim_benchmark_range_partitioned`(t1 bigint(20) NOT NULL,t2 varchar(200) DEFAULT NULL,……t30 varchar(200) DEFAULT NULL,)PRIMARY KEY (`t1`)) DEFAULT CHARSET = utf8mb4ROW_FORMAT = COMPACTCOMPRESSION = 'zstd_1.3.8' REPLICA_NUM = 3 BLOCK_SIZE = 16384 USE_BLOOM_FILTER = FALSE TABLET_SIZE =134217728 PCTFREE = 0partition by range(t1)(partition PT1 values less than (10000000),partition PT2 values less than (20000000),partition PT3 values less than (30000000),partition PT4 values less than (40000000),partition PT5 values less than (50000000),partition PT6 values less than (60000000),partition PT7 values less than (70000000),partition PT8 values less than (80000000),partition PT9 values less than (90000000),partition PT10 values less than (100000000));select * from tb_dim_benchmark_range_partitioned limit 1;# 10000000,c5181f1335efd950960f41cbecb1ab0ed97c43502252b99834f4b6905ea7f7490ca72e1d676bbe9b77016d23e52ada249f2c,2b5480769a360133d57f09cba16d1c449cc06b42b614bcfa3f9db6bbf7a04bac2be1d373d11c63a77676daf53111c2321b32,db88f926925d87175aa4be6740f6f2f49d8f8b38f0d0efff2e5e832f3c1aec21e06cc4f2f0b5053e0b9fbab8a16cce80b9ff,9c0b94cdde25b68264704c890d141444d28544a7ce4955856b3115f913442ec4bc741f033477e366005c927e41842a7cd9be,4d69eedaae9e42b4ab7388e66992efddfa39cbb6802cf69b97c5892070a68e6eed51f823770587771a49cbbd1b7be1f2e024,c60b30f6c4e1b3c02d6fb2de58badf8097f782a8534e0c9dc78497ede12b2573e2d9441e0596f37739d26f0830918fb03ff5,a8a01cbe3bd44e6d52b7e83bd020a23ae305713fd376a0627f610302018c39ec3aa540519dccceb764324282dfbf0bdda6cc,fd358773a94c1770980e92e66fcd9e4f70d6f3ef35dff86c65a97826698c750489682c2d1d36ab75ddb588da65b61cd6fc63,cb8a60222389c9ff9ff4e4e492a4f16ed7ea0e6b781379afc7fad78539fbf8da54b0ef8ea7ef9680543ebc0c18a908092bd1,9cdbf58a3d454d2b14ebf17167d045887ab5eb3a21d3916acc393475011a079c350295fa8b4b324dab63a00f1fbadfb22edb,cda510824ef5bc82cd4e014c851ed367dbd6da8828cc261070a0db9cc9341764baf445506a12a7eb7265434f29d63c65b3a1,8d7c4bbcd42364b93b8cae11eff8f50115e36f1f4f4e6a492687bc2374444c4eaf80e1903eb13fcdfbea6f00de999e0f0587,107b23e4b7e5a16149a8ea7f75c45c607bb5974cbbdf36077615d92591f4830ec5b2b33945d82e8e526f92cb0072cbf8a260,cda4ab39b6f2b67d1d283077a1beb01771639eff1ae371372bb2555de594699821d43509fdd7014bcf3e5098bd13c30c8199,a330f59ee2e48051362241f9a24ba1adad4b61fdd18676cd209799bbec6775dc01120abb0e157589d3f594051b5ae2dd6572,b8e98c3979610c67ea65433a560ab6cf8663c9de201ae1051a14034b317f90aaa1085b49eba3d86748677f4e0575169fb76c,6753542147a9cf38f4d040f205483a798d1d2a2c0cf2283ec98c735bf82422a8ecdea432cee8c76a00917b8add7eac5aa0b4,8d8e0c2caeed82f21ddb288affe2fb567c008e8982cb5a4d07343dc4fd6679f550856649fe4bd40eec9747485c660b01e55e,,c261014cf13c462815e0afece1512409d2549a699e33eaf8cb23b0b23719c870c83817fcaa7466d5d88a1ae240458ba0201a,2ac55e6bc39eb79694bf00c2b69768365b7833d9f0cb7df078525d9ab98eba5ce2bfc3cc1fb9f4398c49c16073fb5d863172,77ab6010d7bc664b6861927322276b2d35d4f5ff2d6bc2eec3da9ef936ae836dfbed6783a8c7f9970e19d46e43b52e49a0f6,4109f993c94f8ca40c6932d01a726fb173beb60e34b57bf488f86fe9e6c12f7f7497c720fa95099c6a43cb3442444b367ea4,7891bdf8a52dc19d311f392fa5f34509c6dcb33b8b8e291131ca5d46c517ea0933868874244aff1b3345ea5279fe0c659709,200e69e8ec8e6104834596c2fefe8ed772ba9b7de4f1287c91c3b91469dd985fbb93d55a9497b2606ae9003975458b6b054b,a2de28933b2cf1f9166cf3aab732f5c6b68967eddef0472a8577a82f37e77bcfc45a5e0adc11d382160d3c84ec14e0e75b5d,1fa6bcf4d9ef2076aa016e78db575595a9155dfe6484a9812ae690fc20c244bf2d09355ba7dbc32495330a21b6e3c893ba6b,b01a0b4ba3d8ae159d330720bb8baffe3ad2504b221151b8f68304ed7c14a03d21f75a4e6ad16873ea0c8904717478d3f7c4,a00ae3e9a8c89f5a0f0fae92934d23adeb9117ef7c91f80f0d5306eca558b77422f273283e867a6b7320e91895087e652ed7
其次,为避免测试流程中其他依赖组件(例如物理 Source、Sink)对维表关联性能造成影响,对 SQL 的测试数据源使用 DataGen SQL Connector (支持在内存中随机或顺序 生成记录)及 BlackHole SQL Connector(吞掉所有输入数据,用于性能测试)。
CREATE TABLE `data_gen_source` (`t1` BIGINT, `t2` VARCHAR, `proctime` AS PROCTIME()) WITH ('connector' = 'datagen','fields.t1.kind' = 'random','fields.t1.min' = '1','fields.t1.max' = '100000','rows-per-second' = '100000000');CREATE TABLE `tb_dim_benchmark_1`(`t1` BIGINT,`t2` VARCHAR,……`t30` VARCHAR,PRIMARY KEY (`t1`) NOT ENFORCED) WITH ('connector' = 'jdbc','url' = '','driver' = 'com.mysql.jdbc.Driver','sink.buffer-flush.max-rows' = '500','table-name' = 'tb_dim_benchmark_range_partitioned_10w');CREATE TABLE blackhole_table (`t1` BIGINT,`t2` VARCHAR,……`t30` VARCHAR) WITH ('connector' = 'blackhole');INSERT INTO blackhole_tableSELECT tb1.`t1`,tb2.`t2`,tb2.`t3`,tb2.`t4`,tb2.`t5`,tb2.`t6`,tb2.`t7`,tb2.`t8`,tb2.`t9`,tb2.`t10`,tb2.`t11`,tb2.`t12`,tb2.`t13`,tb2.`t14`,tb2.`t15`,tb2.`t16`,tb2.`t17`,tb2.`t18`,tb2.`t19`,tb2.`t21`,tb2.`t22`,tb2.`t23`,tb2.`t24`,tb2.`t25`,tb2.`t26`,tb2.`t27`,tb2.`t28`,tb2.`t29`,tb2.`t30`FROM `data_gen_source` tb1LEFT JOIN `tb_dim_benchmark_1` FOR SYSTEM_TIME as of tb1.`proctime` as tb2 ON tb1.`t1` = tb2.`t1`;
第三,测试结果
-
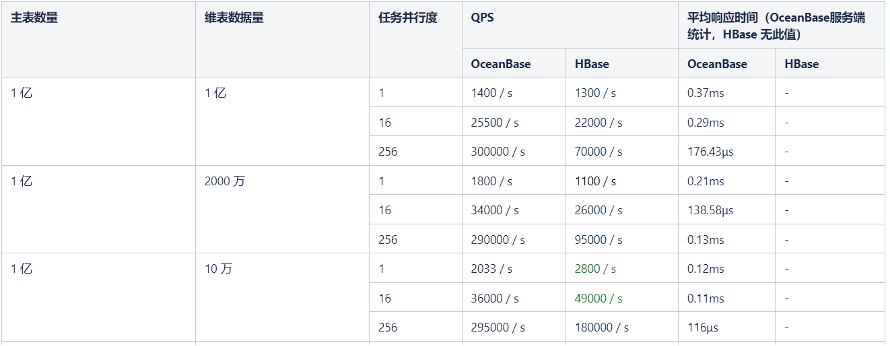
维表 1 对 1 关联,即 DataGen 生成随机值与 OceanBase(索引字段)和HBase(RowKey)关联,测试数据如下表所示。
-
维表 1 对 N 关联,即 DataGen 生成随机值与 OceanBase(二级索引列)关联, 测试那颗数据如下表所示。

基于测试结果,可以得到四个结论:
-
维表数据量在 2000 万及 1 亿条(大数据量)时,低任务并行度下的 OceanBase QPS 优于 HBase,高任务并行度下 OceanBase 相比 HBase 有 3-4 倍性能提升,优势明显。
-
维表数据量在 10w(小数据量)时,低任务并行度下 HBase QPS 略高于 OceanBase,高并行度下 OceanBase 优势明显。
-
对 OceanBase 使用非索引列关联性能较差,后续使用需注意大维表关联时关联字段加索引,实时计算平台可从平台功能角度优化,例如用户关联了非索引列则在 SQL 校验阶段提示用户创建索引。
-
对 OceanBase 使用二级索引列关联(1 对 N 关联)性能良好,可满足较高 QPS 业务场景需求。

从以上测试结果来看,在相同环境下,OceanBase 综合性能要优于 HBase,并且原生支持二级索引能力,部署简单,具有更低的硬件成本和运维成本,因此,贝壳选择使用 OceanBase 替换 HBase,作为实时计算平台的实时维表存储。
在 OceanBase 的应用过程中,贝壳也提出了一些建议:比如,发现普通的关系表不支持 TTL(当前使用的是 OceanBase 3.1.2 社区版本),经与社区沟通,OceanBase 的 3.1.4 版本已经支持 table API 或 Hbase API 等 API 模型,OceanBase 4.0 版本已经支持全局二级索引。
另外,贝壳建议 OceanBase 在与大数据生态打通(例如导入导出、计算等)方面可以进一步加强,更好地支持大数据到 OceanBase 的导入导出等。
相关文章:
性能提升3-4倍!贝壳基于Flink + OceanBase的实时维表服务
作者介绍:肖赞,贝壳找房(北京)科技有限公司 OLAP 平台负责人,基础研发线大数据平台部架构师。 贝壳找房是中国最大的居住服务平台。作为居住产业数字化服务平台,贝壳致力于推进居住服务的产业数字化、智能…...

取数组中每个元素的最高位
1 题目 /*程序将一维数组a中N个元素的最高位取出,保存在一维数组b的对应位置。 程序运行结果为: a:82 756 71629 5 2034 b: 8 7 7 5 2 */ 2 思考 简单来说就是取一个数据的最高位。 一开始的笨方法没有办法判断数据的长度,后来…...

Docker一键部署Nacos
官方参考文档: https://nacos.io/zh-cn/docs/quick-start-docker.html 本人实践 一、创建数据库&数据表 使用sql脚本创建:https://github.com/alibaba/nacos/blob/master/config/src/main/resources/META-INF/nacos-db.sql 二、新建文件夹并赋权…...

【数学建模】-- 模糊综合评价
模糊综合评价(Fuzzy Comprehensive Evaluation)是一种用于处理不确定性和模糊性信息的决策分析方法。它通常用于解决复杂的多指标决策问题,其中各指标之间可能存在交叉影响和模糊性的情况。模糊综合评价通过将不确定性和模糊性量化࿰…...
Java 数据库改了一个字段, 前端传值后端接收为null问题解决
前端传值后端为null的原因可能有很多种,我遇到一个问题是,数据库修改了一个字段,前端传值了,但是后台一直接收为null值, 原因排查: 1、字段没有匹配上,数据库字段和前端字段传值不一致 2、大…...

lnmp架构-mysql1
1.MySQL数据库编译 make完之后是这样的 mysql 初始化 所有这种默认不在系统环境中的路径里 就这样加 这样就可以直接调用 不用输入路径调用 2.初始化 重置密码 3.mysql主从复制 配置master 配置slave 当master 端中还没有插入数据时 在server2 上配slave 此时master 还没进…...

Threadlocal在项目中的应用
ThreadLocal为每一线程提供一份单独的存储空间,具有线程隔离的作用 PageHelper.startPage()方法使用ThreadLocal来保存分页参数,保证线程安全性。PageHelper通过集成MyBatis的拦截器机制来实现对SQL语句的拦截和修改 项目中使用了ThreadLocal保存每个线程…...

个性化定制你的AI助手,AI指令提示词专家
『个性化定制你的AI助手』围观不如下场!需要学习AI指令提升能力的,精准输出想要内容的,快来订阅 javastarboy『AI指令保姆级拆解』合集! ▶️你是否尚未挖掘到 AI 的潜力? ▶️你是否经常遇到“答非所问”的“人工智障…...
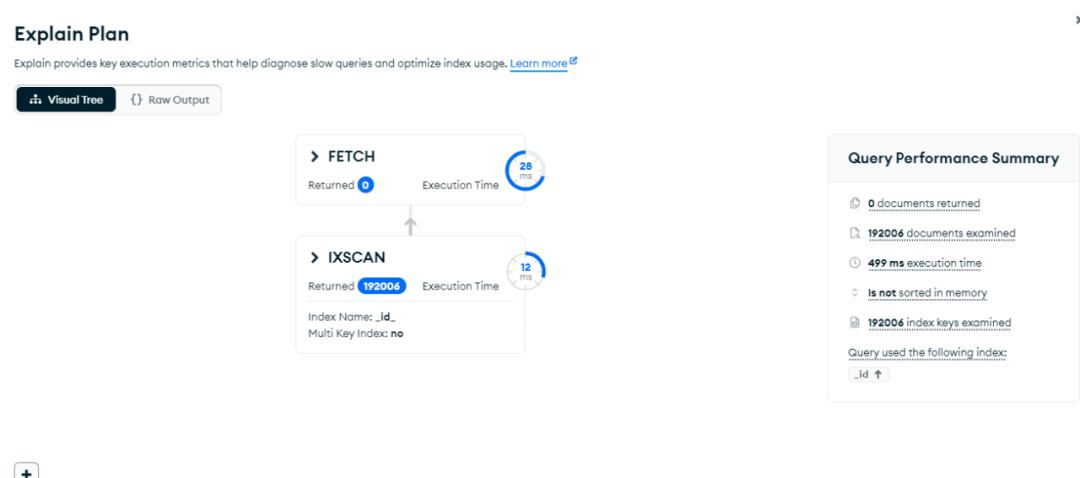
mongodb聚合排序的一个巨坑
现象: mongodb cpu动不动要100%,如下图 分析原因: 查看慢日志发现,很多条这样的查询,一直未执行行完成,占用大量的CPU [{$match: {"tags.taskId": "64dae0a9deb52d2f9a1bd71e",grnty: …...

无涯教程-分类算法 - 随机森林
随机森林是一种监督学习算法,可用于分类和回归,但是,它主要用于分类问题,众所周知,森林由树木组成,更多树木意味着更坚固的森林。同样,随机森林算法在数据样本上创建决策树,然后从每…...

c#常见的排序算法
在C#中,常见的排序算法包括以下几种: 1. 冒泡排序(Bubble Sort):比较相邻的元素,如果顺序不对就交换它们,重复多次直到排序完成。 2. 插入排序(Insertion Sort)…...
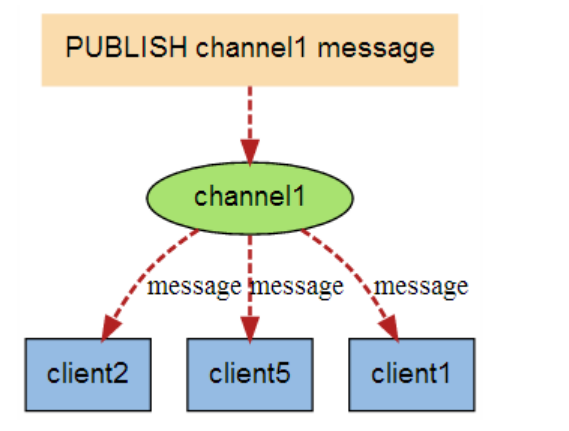
Redis 持久化和发布订阅
一、持久化 Redis 是内存数据库,如果不将内存中的数据库状态保存到磁盘,那么一旦服务器进程退出,服务器中的数据库状态也会消失。所以 Redis 提供了持久化功能! 1.1、RDB(Redis DataBase) 1.1.1 …...
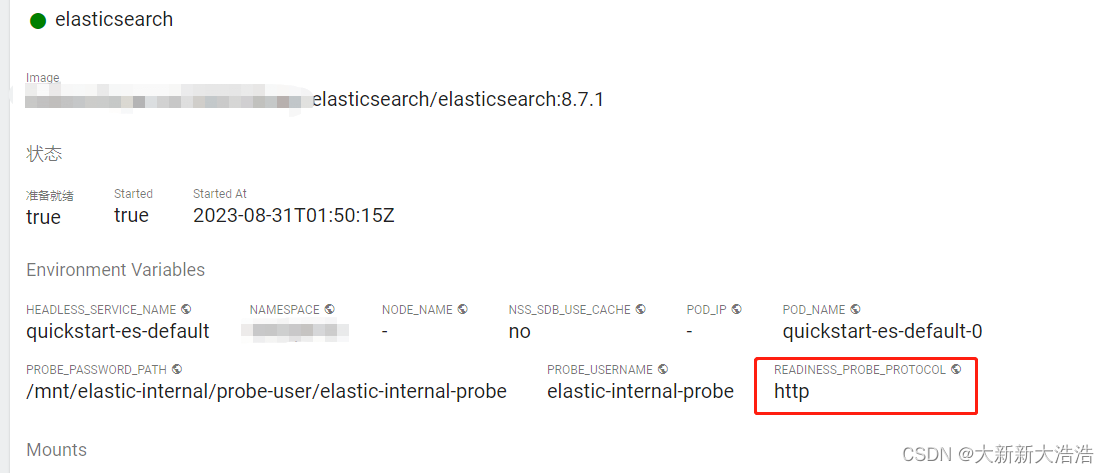
k8s使用ECK(2.4)形式部署elasticsearch+kibana-http协议
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、准备elasticsearch-cluster.yaml二、部署并测试总结 前言 之前写了eck2.4部署eskibana,默认的话是https协议的,这里写一个使用http…...
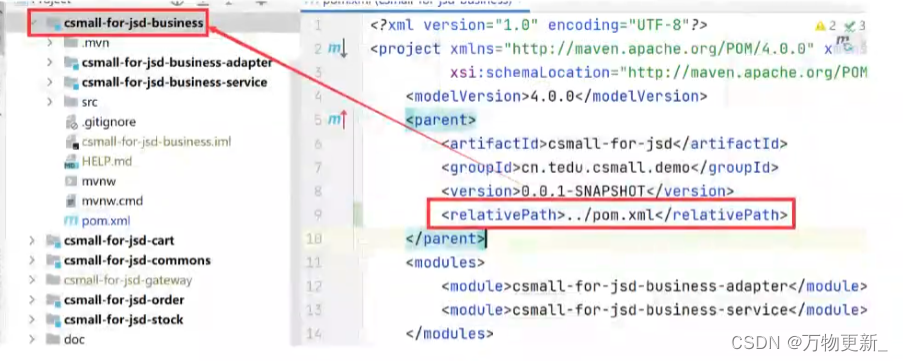
[maven]关于pom文件中的<relativePath>标签
关于pom文件中的<relativePath>标签 为什么子工程要使用relativePath准确的找到父工程pom.xml.因为本质继承就是pom的继承。父工程pom文件被子工程复用了标签。(可以说只要我在父工程定义了标签,子工程就可以没有,因为他继承过来了&…...
11. 网络模型保存与读取
11.1 网络模型保存(方式一) import torchvision import torch vgg16 torchvision.models.vgg16(pretrainedFalse) torch.save(vgg16,"./model/vgg16_method1.pth") # 保存方式一:模型结构 模型参数 print(vgg16) 结果: VGG((feature…...

新SDK平台下载开源全志V853的SDK
获取SDK SDK 使用 Repo 工具管理,拉取 SDK 需要配置安装 Repo 工具。 Repo is a tool built on top of Git. Repo helps manage many Git repositories, does the uploads to revision control systems, and automates parts of the development workflow. Repo is…...

多图详解VSCode搭建Java开发环境
大家好,我是爱编程的喵喵。双985硕士毕业,现担任全栈工程师一职,热衷于将数据思维应用到工作与生活中。从事机器学习以及相关的前后端开发工作。曾在阿里云、科大讯飞、CCF等比赛获得多次Top名次。现为CSDN博客专家、人工智能领域优质创作者。喜欢通过博客创作的方式对所学的…...
基于JavaWeb和mysql实现网上书城前后端管理系统(源码+数据库+开题报告+论文+答辩技巧+项目功能文档说明+项目运行指导)
一、项目简介 本项目是一套基于JavaWeb和mysql实现网上书城前后端管理系统,主要针对计算机相关专业的正在做毕设的学生与需要项目实战练习的Java学习者。 包含:项目源码、项目文档、数据库脚本等,该项目附带全部源码可作为毕设使用。 项目都…...

Swift创建单例
Objective-C使用GCD 中的dispatch_once_t 可以保证里面的代码只被调用一次,以此保证单例在线程上的安全。 但是在Swift 中由于废弃了原有的Dispatch once方法,因此无法使用once 进行单例的创建。 我们可以使用struct 存储类型变量,并且使用…...

问道管理:市盈率怎么计算?
市盈率是衡量一家公司股票价格是否合理的重要目标之一,核算市盈率的公式是将一家公司的股票价格除以每股收益,也便是市盈率 股票价格 每股收益。市盈率能够告诉你一个公司的股票价格是否高估或轻视,是投资者在买入或卖出一家公司股票时需求…...

城通网盘高速解析终极指南:如何免费实现40倍下载提速
城通网盘高速解析终极指南:如何免费实现40倍下载提速 【免费下载链接】ctfileGet 获取城通网盘一次性直连地址 项目地址: https://gitcode.com/gh_mirrors/ct/ctfileGet 你是否厌倦了城通网盘那令人抓狂的蜗牛下载速度?每次下载大文件都要面对漫长…...

m4s-converter终极指南:如何无损转换B站缓存视频并保留弹幕
m4s-converter终极指南:如何无损转换B站缓存视频并保留弹幕 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 在数字内容日益丰富的今天…...

Redis高效开发工具集:从SCAN迭代到数据迁移的Python实践
1. 项目概述:一个Redis开发者的“瑞士军刀”如果你和我一样,日常开发中重度依赖Redis,那你一定遇到过这些场景:想快速查看某个大Key的内存占用,得写脚本遍历;想分析某个Pattern下的所有键,得手动…...

CircuitPython硬件交互实战:引脚命名、模块管理与内存优化
1. 项目概述:CircuitPython硬件交互的基石 如果你刚开始接触CircuitPython,或者从Arduino转过来,可能会对如何控制板子上的某个引脚感到困惑。板子上明明印着“A0”、“D13”,但在代码里到底该怎么写? board.A0 和 …...

基于Go的轻量级自托管IM系统OpenWhisp部署与架构解析
1. 项目概述:一个开源的即时通讯解决方案最近在折腾一个内部协作工具,需要集成一个轻量级的即时通讯模块。市面上成熟的方案不少,但要么是SaaS服务,数据不在自己手里,心里不踏实;要么是像Rocket.Chat、Matt…...

ARM CoreSight SoC-400调试系统勘误解析与解决方案
1. CoreSight SoC-400调试系统深度解析在嵌入式系统开发领域,调试与跟踪技术是确保系统可靠性的关键环节。作为ARM架构下的核心调试解决方案,CoreSight SoC-400系列为开发者提供了强大的硬件支持。今天我将结合多年实战经验,深入剖析这个系统…...
)
尼泊尔语语音合成落地难?ElevenLabs官方未公开的3个语言模型限制(附2024年Q2实测延迟/错误率/重音支持对比表)
更多请点击: https://intelliparadigm.com 第一章:尼泊尔语语音合成落地难?ElevenLabs官方未公开的3个语言模型限制(附2024年Q2实测延迟/错误率/重音支持对比表) 尼泊尔语(नेपाली)作为IS…...

等保2.0合规实战:Redis安全配置核查与加固指南
1. Redis安全配置入门:为什么等保2.0要求这么严格? 我第一次接触Redis安全配置是在一次等保2.0合规检查中。当时客户系统因为Redis默认配置导致数据泄露,整个项目组连夜加班整改。从那以后,我就养成了每次部署Redis必做安全检查的…...

如何快速掌握BepInEx:从游戏玩家到插件开发者的完整指南
如何快速掌握BepInEx:从游戏玩家到插件开发者的完整指南 【免费下载链接】BepInEx Unity / XNA game patcher and plugin framework 项目地址: https://gitcode.com/GitHub_Trending/be/BepInEx BepInEx是一款强大的Unity游戏插件框架,为游戏模组…...

树莓派BlueZ源码编译安装与蓝牙协议栈深度配置指南
1. 项目概述与背景 如果你手头有一块树莓派,并且想用它来玩点物联网或者智能硬件项目,蓝牙功能几乎是绕不开的一环。无论是连接一个BLE温湿度传感器读取数据,还是控制一个蓝牙音箱,底层都需要一个稳定、功能完整的蓝牙协议栈来支…...