5.10 汇编语言:汇编过程与结构
过程的实现离不开堆栈的应用,堆栈是一种后进先出(LIFO)的数据结构,最后压入栈的值总是最先被弹出,而新数值在执行压栈时总是被压入到栈的最顶端,栈主要功能是暂时存放数据和地址,通常用来保护断点和现场。
栈是由CPU管理的线性内存数组,它使用两个寄存器(SS和ESP)来保存栈的状态,SS寄存器存放段选择符,而ESP寄存器的值通常是指向特定位置的一个32位偏移值,我们很少需要直接操作ESP寄存器,相反的ESP寄存器总是由CALL,RET,PUSH,POP等这类指令间接性的修改。
CPU提供了两个特殊的寄存器用于标识位于系统栈顶端的栈帧。
- ESP 栈指针寄存器:栈指针寄存器,其内存放着一个指针,该指针永远指向系统栈最上面一个栈帧的栈顶。
- EBP 基址指针寄存器:基址指针寄存器,其内存放着一个指针,该指针永远指向系统栈最上面一个栈帧的底部。
在通常情况下ESP是可变的,随着栈的生成而逐渐变小,而EBP寄存器是固定的,只有当函数的调用后,发生入栈操作而改变。
- 执行PUSH压栈时,堆栈指针自动减4,再将压栈的值复制到堆栈指针所指向的内存地址。
- 执行POP出栈时,从栈顶移走一个值并将其复制给内存或寄存器,然后再将堆栈指针自动加4。
- 执行CALL调用时,CPU会用堆栈保存当前被调用过程的返回地址,直到遇到RET指令再将其弹出。
10.1 PUSH/POP
PUSH和POP是汇编语言中用于堆栈操作的指令,它们通常用于保存和恢复寄存器的值,参数传递和函数调用等。
PUSH指令用于将操作数压入堆栈中,它执行的操作包括将操作数复制到堆栈的栈顶,并将堆栈指针(ESP)减去相应的字节数。指令格式如下:
PUSH operand
其中,operand可以是8位,16位或32位的寄存器,立即数,以及内存中的某个值。例如,要将寄存器EAX的值压入堆栈中,可以使用以下指令:
PUSH EAX
从汇编代码的角度来看,PUSH指令将操作数存储到堆栈中,它实际上是一个入栈操作。
POP指令用于将堆栈中栈顶的值弹出到指定的目的操作数中,它执行的操作包括将堆栈顶部的值移动到指定的操作数,并将堆栈指针增加相应的字节数。指令格式如下:
POP operand
其中,operand可以是8位,16位或32位的寄存器,立即数,以及内存中的某个位置。例如,要将从堆栈中弹出的值存储到BX寄存器中,可以使用以下指令:
POP EBX
从汇编代码的角度来看,POP指令将从堆栈中取出一个值,并将其存储到目的操作数中,它是一个出栈操作。
在函数调用时,PUSH指令被用于向堆栈中推送函数的参数,这些参数可以是寄存器、立即数或者内存中的某个值。在函数返回之前,POP指令被用于将堆栈顶部的值弹出,并将其存储到寄存器或者内存中。
读者需要特别注意,在使用PUSH和POP指令时需要保证堆栈的平衡,也就是说,每个PUSH指令必须有对应的POP指令,否则堆栈会失去平衡,最终导致程序出现错误。
在读者了解了这两条指令时则可以执行一些特殊的操作,如下代码我们以数组入栈与出栈为例,执行PUSH指令时,首先减小ESP的值,然后把源操作数复制到堆栈上,执行POP指令则是先将数据弹出到目的操作数中,然后再执行ESP值增加4,并以此分别将数组中的元素压入栈,最终再通过POP将元素反弹出来。
.386p.model flat,stdcalloption casemap:noneinclude windows.inc
include kernel32.inc
includelib kernel32.lib
include msvcrt.inc
includelib msvcrt.lib.dataArray DWORD 1,2,3,4,5,6,7,8,9,10szFmt BYTE '%d ',0dh,0ah,0
.codemain PROC; 使用Push指令将数组正向入栈mov eax,0mov ecx,10S1:push dword ptr ds:[Array + eax * 4]inc eaxloop S1; 使用pop指令将数组反向弹出mov ecx,10S2:push ecx ; 保护ecxpop ebx ; 将Array数组元素弹出到ebxinvoke crt_printf,addr szFmt,ebxpop ecx ; 弹出ecxloop S2int 3main ENDP
END main
至此当读者理解了这两个指令之后,那么利用堆栈的先进后出特定,我们就可以实现将特殊的字符串反转后输出的效果,首先我们循环将字符串压入堆栈,然后再从堆栈中反向弹出来,这样就可以实现字符串的反转操作,这段代码的实现也相对较为容易;
.386p.model flat,stdcalloption casemap:noneinclude windows.inc
include kernel32.inc
includelib kernel32.lib
include msvcrt.inc
includelib msvcrt.lib.dataMyString BYTE "hello lyshark",0NameSize DWORD ($ - MyString) - 1szFmt BYTE '%s',0dh,0ah,0
.codemain PROC; 正向压入字符串mov ecx,dword ptr ds:[NameSize]mov esi,0S1: movzx eax,byte ptr ds:[MyString + esi]push eaxinc esiloop S1; 反向弹出字符串mov ecx,dword ptr ds:[NameSize]mov esi,0S2: pop eaxmov byte ptr ds:[MyString + esi],alinc esiloop S2invoke crt_printf,addr szFmt,addr MyStringint 3main ENDP
END main
10.2 PROC/ENDP
PROC/ENDP 伪指令是用于定义过程(函数)的伪指令,这两个伪指令可分别定义过程的开始和结束位置。此处读者需要注意,这两条伪指令并非是汇编语言中所兼容的,而是MASM编译器为我们提供的一个宏,是MASM的一部分,它允许程序员使用汇编语言定义过程(函数)可以像标准汇编指令一样使用。
对于不使用宏定义来创建函数时我们通常会自己管理函数栈参数,而有了宏定义这些功能都可交给编译器去管理,下面的一个案例中,我们通过使用过程创建ArraySum函数,实现对整数数组求和操作,函数默认将返回值存储在EAX中,并打印输出求和后的参数。
.386p.model flat,stdcalloption casemap:noneinclude windows.inc
include kernel32.inc
includelib kernel32.lib
include msvcrt.inc
includelib msvcrt.lib.dataMyArray DWORD 1,2,3,4,5,6,7,8,9,10Sum DWORD ?szFmt BYTE '%d',0dh,0ah,0
.code; 数组求和过程ArraySum PROCpush esi ; 保存ESI,ECXpush ecxxor eax,eaxS1: add eax,dword ptr ds:[esi] ; 取值并相加add esi,4 ; 递增数组指针loop S1pop ecx ; 恢复ESI,ECXpop esiretArraySum endpmain PROClea esi,dword ptr ds:[MyArray] ; 取出数组基址mov ecx,lengthof MyArray ; 取出元素数目call ArraySum ; 调用方法mov dword ptr ds:[Sum],eax ; 得到结果invoke crt_printf,addr szFmt,Sumint 3main ENDP
END main
接着我们来实现一个具有获取随机数功能的案例,在C语言中如果需要获得一个随机数一般会调用Seed函数,如果读者逆向分析过这个函数的实现原理,那么读者应该能理解,在调用取随机数之前会生成一个随机数种子,这个随机数种子的生成则依赖于0x343FDh这个特殊的常量地址,当我们每次访问该地址都会产出一个随机的数据,当得到该数据后,我们再通过除法运算取出溢出数据作为随机数使用实现了该功能。
.386p.model flat,stdcalloption casemap:noneinclude windows.inc
include kernel32.inc
includelib kernel32.lib
include msvcrt.inc
includelib msvcrt.lib.dataseed DWORD 1szFmt BYTE '随机数: %d',0dh,0ah,0
.code; 生成 0 - FFFFFFFFh 的随机种子Random32 PROCpush edxmov eax, 343FDhimul seedadd eax, 269EC3hmov seed, eaxror eax,8pop edxretRandom32 endp; 生成随机数RandomRange PROCpush ebxpush edxmov ebx,eaxcall Random32mov edx,0div ebxmov eax,edxpop edxpop ebxretRandomRange endpmain PROC; 调用后取出随机数call RandomRangeinvoke crt_printf,addr szFmt,eaxint 3main ENDP
END main
10.3 局部参数传递
在汇编语言中,可以使用堆栈来传递函数参数和创建局部变量。当程序执行到函数调用语句时,需要将函数参数传递给被调用函数。为了实现参数传递,程序会将参数压入栈中,然后调用被调用函数。被调用函数从栈中弹出参数并执行,然后将返回值存储在寄存器中,最后通过跳转返回到调用函数。
局部变量也可以通过在栈中分配内存来创建。在函数开始时,可以使用push指令将局部变量压入栈中。在函数结束时,可以使用pop指令将变量从栈中弹出。由于栈是后进先出的数据结构,局部变量的创建可以很方便地通过在栈上压入一些数据来实现。
局部变量是在程序运行时由系统动态的在栈上开辟的,在内存中通常在基址指针(EBP)之下,尽管在汇编时不能给定默认值,但可以在运行时初始化,如下一段C语言伪代码:
void MySub()
{int var1 = 10;int var2 = 20;
}
上述的代码经过C编译后,会变成如下汇编指令,其中EBP-4必须是4的倍数,因为默认就是4字节存储,如果去掉了mov esp,ebp,那么当执行pop ebp时将会得到EBP等于10,执行RET指令会导致控制转移到内存地址10处执行,从而程序会崩溃。
MySub PROCpush ebp ; 将EBP存储在栈中mov ebp,esp ; 堆栈框架的基址sub esp,8 ; 创建局部变量空间(分配2个局部变量)mov DWORD PTR [ebp-8],10 ; var1 = 10mov DWORD PTR [ebp-4],20 ; var2 = 20mov esp,ebp ; 从堆栈上删除局部变量pop ebp ; 恢复EBP指针ret 8 ; 返回,清理堆栈
MySub ENDP
为了使上述代码片段更易于理解,可以在上述的代码的基础上给每个变量的引用地址都定义一个符号,并在代码中使用这些符号,如下代码所示,代码中定义了一个名为MySub的过程,该过程将两个局部变量分别设置为10和20。
在该过程中,首先使用push ebp指令将旧的基址指针压入栈中,并将ESP寄存器的值存储到ebp中。这个旧的基址指针将在函数执行完毕后被恢复。然后,我们使用sub esp,8指令将8字节的空间分配给两个局部变量。在堆栈上分配的空间可以通过var1_local和var2_local符号来访问。在这里,我们定义了两个符号,将它们与ebp寄存器进行偏移以访问这些局部变量。var1_local的地址为[ebp-8],var2_local的地址为[ebp-4]。然后,我们使用mov指令将10和 20分别存储到这些局部变量中。最后,我们将ESP寄存器的值存储回ebp中,并使用pop ebp指令将旧的基址指针弹出堆栈。现在,栈顶指针(ESP)下移恢复上面分配的8个字节的空间,最后通过ret 8返回到调用函数。
在使用堆栈传参和创建局部变量时,需要谨慎考虑栈指针的位置,并确保遵守调用约定以确保正确地传递参数和返回值。
var1_local EQU DWORD PTR [ebp-8] ; 添加符号1
var2_local EQU DWORD PTR [ebp-4] ; 添加符号2MySub PROCpush ebpmov ebp,espsub esp,8mov var1_local,10mov var2_local,20mov esp,ebppop ebpret 8
MySub ENDP
接着我们来实现一个具有功能的案例,首先为了能更好的让读者理解我们先使用C语言方式实现MakeArray()函数,该函数的内部是动态生成的一个MyString数组,并通过循环填充为星号字符串,最后使用POP弹出,并输出结果,观察后尝试用汇编实现。
void makeArray()
{char MyString[30];for(int i=0;i<30;i++){myString[i] = "*";}
}call makeArray()
上述C语言代码如果翻译为汇编格式则如下所示,代码使用汇编语言实现makeArray的程序,该程序开辟了一个长度为30的数组,将其中的元素填充为*,然后弹出两个元素,并将它们输出到控制台。
.386p.model flat,stdcalloption casemap:noneinclude windows.inc
include kernel32.inc
includelib kernel32.lib
include msvcrt.inc
includelib msvcrt.lib.dataszFmt BYTE '出栈数据: %x ',0dh,0ah,0
.codemakeArray PROCpush ebpmov ebp,esp; 开辟局部数组sub esp,32 ; MyString基地址位于 [ebp - 30]lea esi,[ebp - 30] ; 加载MyString的地址; 填充数据mov ecx,30 ; 循环计数S1: mov byte ptr ds:[esi],'*' ; 填充为*inc esi ; 每次递增一个字节loop S1; 弹出2个元素并输出,出栈数据pop eaxinvoke crt_printf,addr szFmt,eaxpop eaxinvoke crt_printf,addr szFmt,eax ; 以下平栈,由于我们手动弹出了2个数据; 则平栈 32 - (2 * 4) = 24 add esp,24 ; 平栈mov esp,ebppop ebp ; 恢复EBPretmakeArray endpmain PROCcall makeArrayinvoke ExitProcess,0main ENDP
END main
在该程序的开始部分,我们首先通过push ebp和mov ebp,esp指令保存旧的基址指针并将当前栈顶指针(ESP)存储到ebp中。然后,我们使用sub esp, 32指令开辟一个长度为30的数组MyString。我们将MyString数组的基地址存储在[ebp - 30]的位置。使用lea esi, [ebp - 30]指令将MyString的基地址加载到esi寄存器中。该指令偏移ebp-30是因为ebp-4是MakeArray函数的第一个参数的位置,因此需要增加四个字节。我们利用MOV byte ptr ds:[esi],'*'指令将MyString中的所有元素填充为*。
然后,使用pop eax和invoke crt_printf, addr szFmt, eax指令两次弹出两个元素,并使用crt_printf函数输出这些元素。该函数在msvcrt.dll库中实现,用于将格式化的信息输出到控制台。在输出数据之后,我们通过add esp,24和mov esp,ebp指令将堆栈平衡,恢复旧的基址指针ebp,然后从堆栈中弹出ebp,并通过ret指令返回到调用程序。
接着我们继续来对比一下堆栈中参数传递的异同点,平栈的方式一般可分为调用者平栈和被调用者平栈,在使用堆栈传参时,需要平衡栈以恢复之前的堆栈指针位置。
-
当平栈由被调用者完成时,被调用函数使用
ret指令将控制权返回到调用函数,并从堆栈中弹出返回地址。此时,被调用函数需要将之前分配的局部变量从堆栈中弹出,以便调用函数能够恢复堆栈指针的位置。因此,被调用函数必须知道其在堆栈上分配的内存大小,并将该大小与其ret指令中的参数相匹配,以便调用函数可以正确恢复堆栈指针位置。 -
当平栈由调用者完成时,调用函数需要在调用子函数之前平衡堆栈。因此,调用函数需要知道子函数在堆栈上分配的内存大小,并在调用子函数之前向堆栈提交额外的空间。调用函数可以使用
add esp, N指令来恢复堆栈指针的位置,其中 N 是被调用函数在堆栈上分配的内存大小。然后,调用函数调用被调用函数,该函数将返回并将堆栈指针恢复到调用函数之前的位置。
如下这段汇编代码中笔者分别实现了两种调用方式,其中MyProcA函数是一种被调用者平栈,由于调用者并没有堆栈修正所以需要在函数内部通过使用ret 12的方式平栈,之所以是12是因为我们使用了三个局部变量,而第二个MyProcB函数则是调用者平栈,该方式在函数内部并没有返回任何参数,所以在调用函数结束后需要通过add esp,4的方式对堆栈进行修正。
.386p.model flat,stdcalloption casemap:noneinclude windows.inc
include kernel32.inc
includelib kernel32.lib
include msvcrt.inc
includelib msvcrt.lib.dataszFmt BYTE '数据: %d ',0dh,0ah,0
.code; 第一种方式:被调用者平栈MyProcA PROCpush ebpmov ebp,espxor eax,eaxmov eax,dword ptr ss:[ebp + 16] ; 获取第一个参数mov ebx,dword ptr ss:[ebp + 12] ; 获取第二个参数mov ecx,dword ptr ss:[ebp + 8] ; 获取第三个参数add eax,ebxadd eax,ebxadd eax,ecxmov esp,ebppop ebpret 12 ; 此处ret12可平栈,也可使用 add ebp,12MyProcA endp; 第二种方式:调用者平栈MyProcB PROCpush ebpmov ebp,espmov eax,dword ptr ss:[ebp + 8]add eax,10mov esp,ebppop ebpretMyProcB endpmain PROC; 第一种被调用者MyProcA平栈 3*4 = 12push 1push 2push 3call MyProcAinvoke crt_printf,addr szFmt,eax; 第二种方式:调用者平栈push 10call MyProcBadd esp,4invoke crt_printf,addr szFmt,eaxint 3main ENDP
END main
当然了如果读者认为自己维护堆栈很繁琐,则此时可以直接使用MASM汇编器提供的PROC定义过程,使用该伪指令汇编器会自行计算所需要使用的变量数量并自行在结尾处添加对应的平栈语句,这段代码实现起来将变得非常容易理解。
.386p.model flat,stdcalloption casemap:noneinclude windows.inc
include kernel32.inc
includelib kernel32.lib
include msvcrt.inc
includelib msvcrt.lib.dataszFmt BYTE '计算参数: %d ',0dh,0ah,0.codemy_proc PROC x:DWORD,y:DWORD,z:DWORD ; 定义过程局部参数LOCAL @sum:DWORD ; 定义局部变量存放总和mov eax,dword ptr ds:[x]mov ebx,dword ptr ds:[y] ; 分别获取到局部参数mov ecx,dword ptr ds:[z]add eax,ebxadd eax,ecx ; 相加后放入eaxmov @sum,eaxretmy_proc endpmain PROCLOCAL @ret_sum:DWORDpush 10push 20push 30 ; 传递参数call my_procmov @ret_sum,eax ; 获取结果并打印invoke crt_printf,addr szFmt,@ret_sumint 3main ENDP
END main
这里笔者还需要扩展一个伪指令LOCAL,LOCAL是一种汇编语言中的伪指令,用于定义存储在堆栈上的局部变量。使用LOCAL指令定义的局部变量只在函数执行时存在,当函数返回后,该变量将被删除。根据使用LOCAL指令时指定的内存空间大小,汇编器将为每个变量保留足够的空间。
例如,下面是一个使用LOCAL定义局部变量的示例:
.386p.model flat,stdcalloption casemap:noneinclude windows.inc
include kernel32.inc
includelib kernel32.lib.codemain PROC; 定义局部变量,自动压栈/平栈LOCAL var_byte:BYTE,var_word:WORD,var_dword:DWORDLOCAL var_array[3]:DWORD; 填充局部变量mov byte ptr ds:[var_byte],1mov word ptr ds:[var_word],2mov dword ptr ds:[var_dword],3; 填充数组方式1lea esi,dword ptr ds:[var_array]mov dword ptr ds:[esi],10mov dword ptr ds:[esi + 4],20mov dword ptr ds:[esi + 8],30; 填充数组方式2mov var_array[0],100mov var_array[1],200mov var_array[2],300invoke ExitProcess,0main ENDP
END main
在上述示例代码中,main过程使用LOCAL指令定义了几个局部变量,包括一个字节类型的变量var_byte、一个字类型的变量var_word、一个双字类型的变量var_dword和一个包含三个双字元素的数组var_array。
在代码中,我们使用mov指令填充这些变量的值。对于字节类型、字类型和双字类型的变量,使用mov byte ptr ds:[var_byte], 1、mov word ptr ds:[var_word], 2和mov dword ptr ds:[var_dword], 3指令将相应的常数值存储到变量中。在填充数组时,分别使用了两种不同的方式。一种方式是使用lea指令将数组的地址加载到esi寄存器中,然后使用mov dword ptr ds:[esi],10等指令将相应的常数值存储到数组中。另一种方式是直接访问数组元素,如mov var_array[0], 100等指令。需要注意,由于数组元素在内存中是连续存储的,因此可以使用[]操作符访问数组元素。
在汇编中使用LOCAL伪指令来实现自动计算局部变量空间,以及最后的平栈操作,将会极大的提高开发效率。
10.4 USES/ENTER
USES是汇编语言中的伪指令,用于保存一组寄存器的状态,以便函数调用过程中可以使用这些寄存器。使用USES时,程序可以保存一组需要保护的寄存器,汇编器将在程序入口处自动向堆栈压入这些寄存器的值。读者需注意,我们可以在需要保存寄存器的程序段中使用USES来保护寄存器,但不应在整个程序中重复使用寄存器。
ENTER也是一种伪指令,用于创建函数调用过程中的堆栈帧。使用ENTER时,程序可以定义一个名为ENTER的指定大小的堆栈帧。该指令会将新的基准指针ebp 压入堆栈同时将当前的基准指针ebp存储到另一个寄存器ebx中,然后将堆栈指针esp减去指定大小的值,获取新的基地址,并将新的基地址存储到ebp 中。之后,程序可以在此帧上创建和访问局部变量,并使用LEAVE指令将堆栈帧删除,将ebp恢复为旧的值,同时将堆栈指针平衡。
在使用USES和ENTER指令时,需要了解这些指令在具体的平台上的支持情况,以及它们适用的调用约定。通常情况下,在函数开头,我们将使用ENTER创建堆栈帧,然后使用USES指定需要保护的寄存器。在函数末尾,我们使用LEAVE删除堆栈帧。
.386p.model flat,stdcalloption casemap:noneinclude windows.inc
include kernel32.inc
includelib kernel32.lib.code; USES 自动压入 eax,ebx,ecx,edxmy_proc PROC USES eax ebx ecx edx x:DWORD,y:DWORDenter 8,0 ; 自动保留8字节堆栈空间add eax,ebxleavemy_proc endpmain PROCmov eax,10mov ebx,20call my_procint 3main ENDP
END main
10.5 STRUCT/UNION
STRUCT和UNION是汇编语言中的数据类型,STRUCT是一种复合数据类型,它将多个不同类型的变量按顺序放置在一起,并使用单个名称来引用集合。使用STRUCT时,我们可以将不同类型的变量组合成一个结构体并定义其属性,如结构体中包含的成员变量的数据类型、名称和位置。
例如,下面是一个使用STRUCT定义自定义类型的示例:
; 定义一个名为 MyStruct 的结构体,包含两个成员变量。
MyStruct STRUCTVar1 DWORD ?Var2 WORD ?
MyStruct ENDS
在上述示例代码中,我们使用STRUCT定义了一个名为MyStruct 的结构体,其中包含两个成员变量Var1和Var2。其中,Var1是DWORD类型的数据类型,以问号?形式指定了其默认值,Var2是WORD类型的数据类型。
另一个数据类型是UNION,它也是一种复合数据类型,用于将多个不同类型的变量叠加在同一内存位置上。使用UNION时,程序内存中的数据将只占用所有成员变量中最大的数据类型变量的大小。与结构体不同,联合中的所有成员变量共享相同的内存位置。我们可以使用一种成员变量来引用内存位置,但在任何时候仅能有一种成员变量存储在该内存位置中。
例如,下面是一个使用UNION定义自定义类型的示例:
; 定义一个名为 MyUnion 的联合,包含两个成员变量。
MyUnion UNIONVar1 DWORD ?Var2 WORD ?
MyUnion ENDS
在上述示例代码中,我们使用UNION定义了一个名为MyUnion的联合,其中包含两个不同类型的成员变量Var1和Var2,将它们相对应地置于联合的同一内存位置上。
读者在使用STRUCT和UNION时,需要根据内存分布和变量类型来正确访问成员变量的值。在汇编语言中,结构体和联合主要用于定义自定义数据类型、通信协议和系统数据结构等,如下一段代码则是汇编语言中实现结构体赋值与取值的总结。
.386p.model flat,stdcalloption casemap:noneinclude windows.inc
include kernel32.inc
includelib kernel32.lib; 定义坐标结构
MyPoint Structpos_x DWORD ?pos_y DWORD ?pos_z DWORD ?
MyPoint ends; 定义人物结构
MyPerson StructFname db 20 dup(0)fAge db 100fSex db 20
MyPerson ends.data; 声明结构: 使用 <>,{}符号均可PtrA MyPoint <10,20,30>PtrB MyPoint {100,200,300}; 声明结构: 使用MyPerson声明结构UserA MyPerson <'lyshark',24,1>.codemain PROC; 获取结构中的数据lea esi,dword ptr ds:[PtrA]mov eax,(MyPoint ptr ds:[esi]).pos_xmov ebx,(MyPoint ptr ds:[esi]).pos_ymov ecx,(MyPoint ptr ds:[esi]).pos_z; 向结构中写入数据lea esi,dword ptr ds:[PtrB]mov (MyPoint ptr ds:[esi]).pos_x,10mov (MyPoint ptr ds:[esi]).pos_y,20mov (MyPoint ptr ds:[esi]).pos_z,30; 直接获取结构中的数据mov eax,dword ptr ds:[UserA.Fname]mov ebx,dword ptr ds:[UserA.fAge]int 3main ENDP
END main
接着我们来实现一个输出结构体数组的功能,结构数组其实就是一维的空间,因此使用两个比例因子即可实现寻址操作,如下代码我们先来实现一个简单的功能,只遍历第一层,结构数组外层的数据。
.386p.model flat,stdcalloption casemap:noneinclude windows.inc
include kernel32.inc
includelib kernel32.lib
include msvcrt.inc
includelib msvcrt.lib; 定义坐标结构
MyPoint Structpos_x DWORD ?pos_y DWORD ?pos_z DWORD ?
MyPoint ends; 定义循环结构
MyCount Structcount_x DWORD ?count_y DWORD ?
MyCount ends.data; 声明结构: 使用 <>,{}符号均可PtrA MyPoint <10,20,30>,<40,50,60>,<70,80,90>,<100,110,120>Count MyCount <0,0>szFmt BYTE '结构数据: %d',0dh,0ah,0.codemain PROC; 获取结构中的数据lea esi,dword ptr ds:[PtrA]mov eax,(MyPoint ptr ds:[esi]).pos_x ; 获取第一个结构Xmov eax,(MyPoint ptr ds:[esi + 12]).pos_x ; 获取第二个结构X; while 循环输出结构的每个首元素元素mov (MyCount ptr ds:[Count]).count_x,0S1: cmp (MyCount ptr ds:[Count]).count_x,48 ; 12 * 4 = 48jge lop_endmov ecx,(MyCount ptr ds:[Count]).count_xmov eax,dword ptr ds:[PtrA + ecx] ; 寻找首元素invoke crt_printf,addr szFmt,eaxmov eax,(MyCount ptr ds:[Count]).count_xadd eax,12 ; 每次递增12mov (MyCount ptr ds:[Count]).count_x,eaxjmp S1lop_end:int 3main ENDP
END main
接着我们递增难度,通过每次递增将两者的偏移相加,获得比例因子,通过因子嵌套双层循环实现寻址打印。
.386p.model flat,stdcalloption casemap:noneinclude windows.inc
include kernel32.inc
includelib kernel32.lib
include msvcrt.inc
includelib msvcrt.lib; 定义坐标结构
MyPoint Structpos_x DWORD ?pos_y DWORD ?pos_z DWORD ?
MyPoint ends; 定义循环结构
MyCount Structcount_x DWORD ?count_y DWORD ?
MyCount ends.data; 声明结构: 使用 <>,{}符号均可PtrA MyPoint <10,20,30>,<40,50,60>,<70,80,90>,<100,110,120>Count MyCount <0,0>szFmt BYTE '结构数据: %d',0dh,0ah,0.codemain PROC; 获取结构中的数据lea esi,dword ptr ds:[PtrA]mov eax,(MyPoint ptr ds:[esi]).pos_x ; 获取第一个结构Xmov eax,(MyPoint ptr ds:[esi + 12]).pos_x ; 获取第二个结构X; while 循环输出结构的每个首元素元素mov (MyCount ptr ds:[Count]).count_x,0S1: cmp (MyCount ptr ds:[Count]).count_x,48 ; 12 * 4 = 48jge lop_endmov (MyCount ptr ds:[Count]).count_y,0S3: cmp (MyCount ptr ds:[Count]).count_y,12 ; 3 * 4 = 12jge S2mov eax,(MyCount ptr ds:[Count]).count_xadd eax,(MyCount ptr ds:[Count]).count_y ; 相加得到比例因子mov eax,dword ptr ds:[PtrA + eax] ; 使用相对变址寻址invoke crt_printf,addr szFmt,eaxmov eax,(MyCount ptr ds:[Count]).count_yadd eax,4 ; 每次递增4mov (MyCount ptr ds:[Count]).count_y,eaxjmp S3 S2: mov eax,(MyCount ptr ds:[Count]).count_xadd eax,12 ; 每次递增12mov (MyCount ptr ds:[Count]).count_x,eaxjmp S1lop_end:int 3main ENDP
END main
结构体同样支持内嵌的方式,如下Rect指针中内嵌两个MyPoint分别指向左子域和右子域,这里顺便定义一个MyUnion联合体把,其使用规范与结构体完全一致,只不过联合体只能存储一个数据.
.386p.model flat,stdcalloption casemap:noneinclude windows.inc
include kernel32.inc
includelib kernel32.lib; 定义坐标结构
MyPoint Structpos_x DWORD ?pos_y DWORD ?pos_z DWORD ?
MyPoint ends; 定义左右结构
Rect StructLeft MyPoint <>Right MyPoint <>
Rect ends; 定义联合体
MyUnion Unionmy_dword DWORD ?my_word WORD ?my_byte BYTE ?
MyUnion ends.dataPointA Rect <>PointB Rect {<10,20,30>,<100,200,300>}test_union MyUnion {1122h}szFmt BYTE '结构数据: %d',0dh,0ah,0
.codemain PROC; 嵌套结构的赋值mov dword ptr ds:[PointA.Left.pos_x],100mov dword ptr ds:[PointA.Left.pos_y],200mov dword ptr ds:[PointA.Right.pos_x],100mov dword ptr ds:[PointA.Right.pos_y],200; 通过地址定位lea esi,dword ptr ds:[PointB]mov eax,dword ptr ds:[PointB] ; 定位第一个MyPointmov eax,dword ptr ds:[PointB + 12] ; 定位第二个内嵌MyPoint; 联合体的使用mov eax,dword ptr ds:[test_union.my_dword]mov ax,word ptr ds:[test_union.my_word]mov al,byte ptr ds:[test_union.my_byte]main ENDP
END main
当然有了结构体这一成员的加入,我们同样可以在汇编层面实现链表的定义与输出,如下代码所示,首先定义一个ListNode用于存储链表结构的数据域与指针域,接着使用TotalNodeCount定义链表节点数量,最后使用REPEAT伪指令开辟ListNode对象的多个实例,其中的NodeData域包含一个1-15的数据,后面的($ + Counter * sizeof ListNode)则是指向下一个链表的头指针,通过不断遍历则可输出整个链表。
.386p.model flat,stdcalloption casemap:noneinclude windows.inc
include kernel32.inc
includelib kernel32.lib
include msvcrt.inc
includelib msvcrt.libListNode StructNodeData DWORD ?NextPtr DWORD ?
ListNode endsTotalNodeCount = 15
Counter = 0.dataLinkList LABEL PTR ListNodeREPEAT TotalNodeCountCounter = Counter + 1ListNode <Counter,($ + Counter * sizeof ListNode)>ENDMListNode<0,0> ; 标志着结构链表的结束szFmt BYTE '结构地址: %x 结构数据: %d',0dh,0ah,0
.codemain PROCmov esi,offset LinkList; 判断下一个节点是否为<0,0>L1: mov eax,(ListNode PTR [esi]).NextPtrcmp eax,0je lop_end; 显示节点数据mov eax,(ListNode PTR [esi]).NodeDatainvoke crt_printf,addr szFmt,esi,eax; 获取到下一个节点的指针mov esi,(ListNode PTR [esi]).NextPtrjmp L1lop_end:int 3main ENDP
END main
本文作者: 王瑞
本文链接: https://www.lyshark.com/post/e43f6d19.html
版权声明: 本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
相关文章:

5.10 汇编语言:汇编过程与结构
过程的实现离不开堆栈的应用,堆栈是一种后进先出(LIFO)的数据结构,最后压入栈的值总是最先被弹出,而新数值在执行压栈时总是被压入到栈的最顶端,栈主要功能是暂时存放数据和地址,通常用来保护断点和现场。 栈是由CPU管…...

【每日一题Day304】LC1267统计参与通信的服务器 | 哈希表
统计参与通信的服务器【LC1267】 这里有一幅服务器分布图,服务器的位置标识在 m * n 的整数矩阵网格 grid 中,1 表示单元格上有服务器,0 表示没有。 如果两台服务器位于同一行或者同一列,我们就认为它们之间可以进行通信。 请你统…...

深度解读零信任身份安全—— 全面身份化:零信任安全的基石
事实上,无论是零信任安全在数据中心的实践,还是通用的零信任安全架构实践,全面身份化都是至关重要的,是“企业边界正在瓦解,基于边界的安全防护体系正在失效”这一大背景下,构筑全新的零信任身份安全架构的…...

音视频 ffmpeg命令提取音视频数据
保留封装格式 ffmpeg -i test.mp4 -acodec copy -vn audio.mp4 ffmpeg -i test.mp4 -vcodec copy -an video.mp4提取视频 保留编码格式:ffmpeg -i test.mp4 -vcodec copy -an test_copy.h264 强制格式:ffmpeg -i test.mp4 -vcodec libx264 -an test.h2…...

vscode 配置
vscode 配置 安装插件 Better C SyntaxC/CCMake、CMake Tools 、CMake Language SupportDoxygen Documentation GeneratorGit Graphhighlight-wordsPythonvscode-iconsClang-Format和clangdtyporahex editor .vscode 中的文件 在 VS Code 中,.vscode 文件夹是用于…...

企业数字化管控平台及信息化治理体系建设方案(附300份方案)
本资料来源公开网络,仅供个人学习,请勿商用,如有侵权请联系删除,更多浏览公众号:智慧方案文库 数字化校园整体解决方案.doc150页6万字数字化智能工厂信息化系统集成整合规划建设方案.docx2022年采购数字化市场研究报告…...

ABB PCD231B通信输入/输出模块
多通道输入和输出: PCD231B 模块通常配备多个输入通道和输出通道,用于连接传感器、执行器和其他设备。 通信接口: 这种模块通常支持各种通信接口,如以太网、串口(RS-232、RS-485)、Profibus、CAN 等&#…...
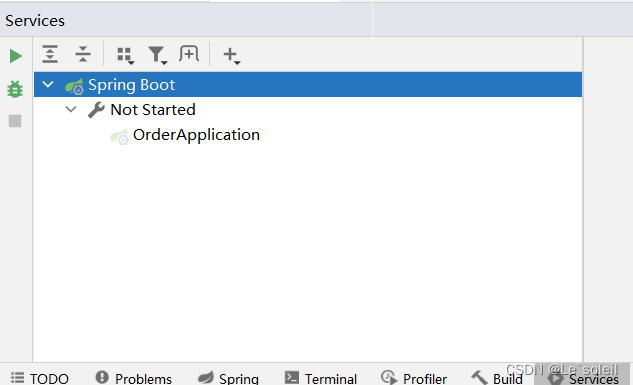
在springboot项目中显示Services面板的方法
文章目录 前言方法一:Alt8快捷键方法二:使用Component标签总结 前言 在一个springboot项目中,通过开启Services面板,可以快速的启动、配置、管理多个子项目。 方法一:Alt8快捷键 1、在idea界面输入Alt8,在…...

spring之AOP简介
1.AOP简介 什么是AOP Aspect Oriented Program面向切面编程在不改变原有逻辑上增加额外的功能,比如解决系统层面的问题,或者增加新的功能 场景 权限控制缓存日志处理事务控制 AOP思想把功能分两个部分,分离系统中的各种关注点 核心关注点&a…...

ros::init用途用法
文章目录 用途:用法:ros::init 是 ROS(Robot Operating System)中的一个重要函数,它用于初始化 ROS 节点。在启动任何 ROS 节点之前,都必须首先调用这个函数。以下是其用途和基本用法。 用途: 节点初始化:为ROS系统中的节点进行初始化。一个节点是ROS计算图中的一个可…...

逻辑回归的含义
参考:线性回归 & 逻辑回归 问题 1、线性回归(Linear Regression)和逻辑回归(Logistic Regression)有什么联系? 2、逻辑回归的“逻辑”、“回归是什么意思”? 回答1 线性回归假设因变量…...

解决Apache Tomcat “Request header is too large“ 异常
🌷🍁 博主猫头虎(🐅🐾)带您 Go to New World✨🍁 🦄 博客首页——🐅🐾猫头虎的博客🎐 🐳 《面试题大全专栏》 🦕 文章图文…...
腾讯音乐如何基于大模型 + OLAP 构建智能数据服务平台
本文导读: 当前,大语言模型的应用正在全球范围内引发新一轮的技术革命与商业浪潮。腾讯音乐作为中国领先在线音乐娱乐平台,利用庞大用户群与多元场景的优势,持续探索大模型赛道的多元应用。本文将详细介绍腾讯音乐如何基于 Apach…...
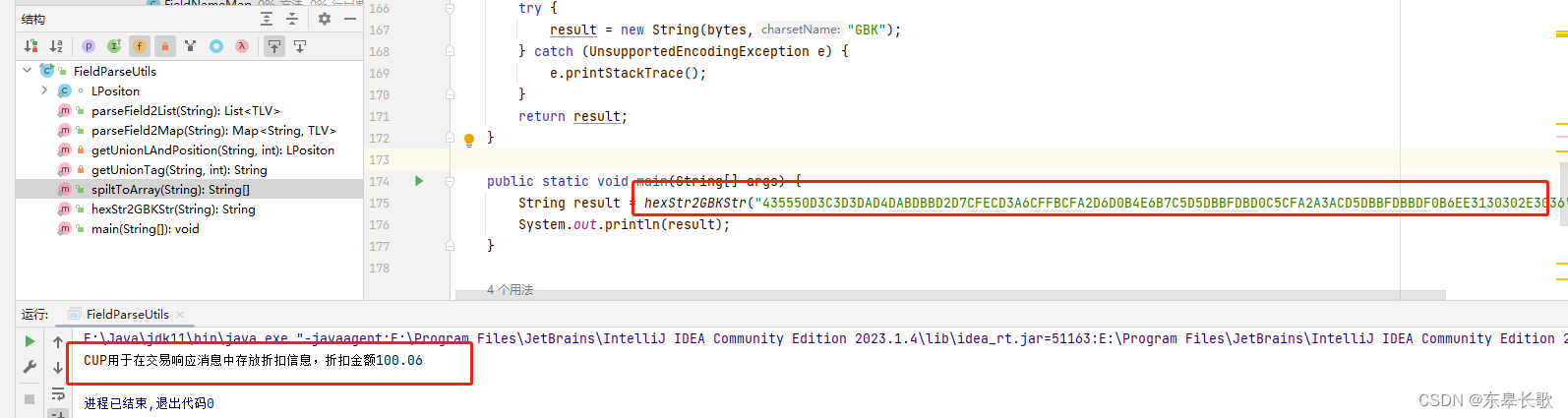
Java 16进制字符串转换成GBK字符串
问题: 现在已知有一个16进制字符串 435550D3C3D3DAD4DABDBBD2D7CFECD3A6CFFBCFA2D6D0B4E6B7C5D5DBBFDBD0C5CFA2A3ACD5DBBFDBBDF0B6EE3130302E3036 而且知道这串的字符串对应的内容是: CUP用于在交易响应消息中存放折扣信息,折扣金额100.06 但…...

【ES6】JavaScript中的Symbol
Symbol是JavaScript中的一种特殊的、不可变的、不可枚举的数据类型。它通常用于表示一个唯一的标识符,可以作为对象的属性键,确保对象的属性键的唯一性和不可变性。 Symbol.for()是Symbol的一个方法,它用于创建一个已经注册的Symbol对象。当…...

理解React页面渲染原理,如何优化React性能?
React JSX转换成真实DOM过程 当使用React编写应用程序时,可以使用JSX语法来描述用户界面的结构。JSX是一种类似于HTML的语法,但实际上它是一种JavaScript的扩展,用于定义React元素。React元素描述了我们想要在界面上看到的内容和结构。 在运…...
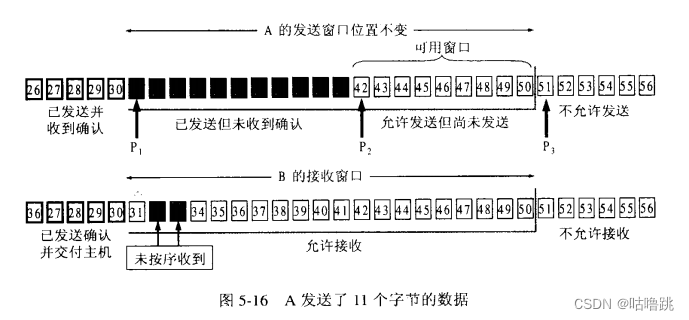
数据通信——传输层TCP(可靠传输机制的滑动窗口)
引言 之前提到过拥塞问题,如果大量数据疯狂涌入,接收端无法及时处理就会导致数据丢包,从而使得通信受到干扰。之前的连续ARQ如果不加以节制,疯狂发送报文,接收端无法及时返回ACK就会导致网络瘫痪。 滑动窗口机制协议 这…...
Mycat之前世今生
如果我有一个32核心的服务器,我就可以实现1个亿的数据分片,我有32核心的服务器么?没有,所以我至今无法实现1个亿的数据分片。——MyCAT ‘s Plan 话说“每一个成功的男人背后都有一个女人”,自然MyCAT也逃脱不了这个诅…...
和标准错误(stderr))
Linux- 重定向标准输出(stdout)和标准错误(stderr)
在Linux或Unix系统中,可以通过重定向标准输出(stdout)和标准错误(stderr)来将脚本的输出保存到一个文件中。以下是一些方法: 只重定向标准输出到文件: ./your_script.sh > output.txt这将只捕…...
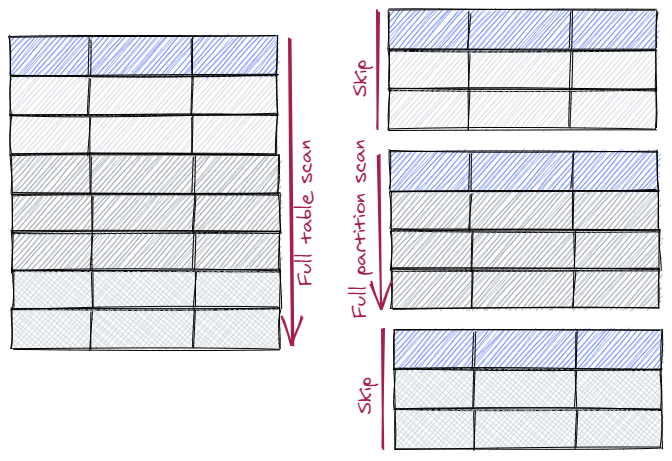
PostgreSQL分区表
什么是分区表 数据库分区表将表数据分成更小的物理分片,以此提高性能、可用性、易管理性。分区表是关系型数据库中比较常见的对大表的优化方式,数据库管理系统一般都提供了分区管理,而业务可以直接访问分区表而不需要调整业务架构,…...

eLabFTW深度解析:开源电子实验记录本的技术架构与实战应用
eLabFTW深度解析:开源电子实验记录本的技术架构与实战应用 【免费下载链接】elabftw :notebook: eLabFTW is the most popular open source electronic lab notebook for research labs. 项目地址: https://gitcode.com/gh_mirrors/el/elabftw eLabFTW作为最…...

经手100万+终端后,聊聊校园门锁Sub-1G和Cat.1怎么选
做校园联网门锁项目的人大概都遇到过这个纠结:组网方案到底选Sub-1G还是4G Cat.1?我们团队(KEENZY中科易安)经手了100万在线终端的运行数据,可以明确地说——两种方案没有绝对的优劣,只有场景是否匹配。选错…...

2026 年 Haskell 基金会大变革:执行董事卸任、组织重组、董事会人员调整!
执行董事卸任过去几年担任执行董事的 Jos 决定在 2026 年 6 月卸任。Jos 是 Haskell 基金会任职时间最长的执行董事,他花费大量时间与社区互动并提供支持,很多工作都是在幕后默默完成的。Jos 做出了个人牺牲,让 Haskell 基金会度过了艰难时期…...

FLUX.1-dev-Controlnet-Union:一站式多模态图像控制解决方案,让AI生成更精准可控
FLUX.1-dev-Controlnet-Union:一站式多模态图像控制解决方案,让AI生成更精准可控 【免费下载链接】FLUX.1-dev-Controlnet-Union 项目地址: https://ai.gitcode.com/hf_mirrors/InstantX/FLUX.1-dev-Controlnet-Union 你是否曾经在AI图像生成中遇…...

数据类型与变量-Part1-基础篇
C语言数据类型与变量(基础篇) 系列导航 📍 Part 1: C语言数据类型与变量(基础篇)← 你在这里🔜 Part 2: C语言内存探秘(进阶篇)🔜 Part 3: C语言输入输出格式化艺术 大家…...

从理论到UI:手把手教你用PyQt5给MTCNN人脸检测算法做个可视化界面
从理论到UI:手把手教你用PyQt5给MTCNN人脸检测算法做个可视化界面 在计算机视觉领域,人脸检测一直是热门研究方向之一。MTCNN(Multi-task Cascaded Convolutional Networks)作为经典的人脸检测算法,凭借其高精度和实时…...

ElevenLabs瑞典文语音生成延迟超800ms?独家逆向分析其WebRTC音频缓冲机制,给出3行代码级低延迟注入方案
更多请点击: https://codechina.net 第一章:ElevenLabs瑞典文语音生成延迟超800ms?独家逆向分析其WebRTC音频缓冲机制,给出3行代码级低延迟注入方案 ElevenLabs 在瑞典语(sv-SE)TTS 服务中默认启用高保真音…...
)
别再傻傻重启了!用JRebel插件实现Spring Boot项目秒级热更新(附2024最新激活与配置避坑指南)
解锁Spring Boot开发新姿势:JRebel热更新实战全攻略 每次修改完代码后,那个漫长的等待重启进度条的过程,是不是让你忍不住想砸键盘?作为经历过数百次Spring Boot项目重启的老司机,我完全理解这种抓狂感。直到遇见了JR…...

从“佩戴感知”到“无感融入”:UWB vs 镜像视界——空间智能的代际跃迁
从“佩戴感知”到“无感融入”:UWB vs 镜像视界——空间智能的代际跃迁空间智能产业正迎来划时代理念革新,行业认知正式完成从主动佩戴式感知向全域无感化融入的核心转变。以UWB为代表的传统定位技术,始终停留在依托外接设备实现信息采集的初…...

YimMenu:GTA V终极开源菜单的完整实战指南
YimMenu:GTA V终极开源菜单的完整实战指南 【免费下载链接】YimMenu YimMenu, a GTA V menu protecting against a wide ranges of the public crashes and improving the overall experience. 项目地址: https://gitcode.com/GitHub_Trending/yi/YimMenu Yi…...