SpringCloud(十)——ElasticSearch简单了解(三)数据聚合和自动补全
文章目录
- 1. 数据聚合
- 1.1 聚合介绍
- 1.2 Bucket 聚合
- 1.3 Metrics 聚合
- 1.4 使用 RestClient 进行聚合
- 2. 自动补全
- 2.1 安装补全包
- 2.2 自定义分词器
- 2.3 自动补全查询
- 2.4 拼音自动补全查询
- 2.5 RestClient 实现自动补全
- 2.5.1 建立索引
- 2.5.2 修改数据定义
- 2.5.3 补全查询
- 2.5.4 解析结果
1. 数据聚合
1.1 聚合介绍
聚合(aggregations)可以实现对文档数据的统计、分析、运算。
聚合常见的有三类:
- 桶(Bucket)聚合:用来对文档做分组
- TermAggregation:按照文档字段值分组
- Date Histogram:按照日期阶梯分组,例如一周为一组,或者一月为一组
- 度量(Metric)聚合:用以计算一些值,比如:最大值、最小值、平均值等
- Avg:求平均值
- Max:求最大值
- Min:求最小值
- Stats:同时求max、min、avg、sum等
- 管道(pipeline)聚合:其它聚合的结果为基础做聚合
参与聚合的字段为以下字段:
- keyword
- 数值
- 日期
- 布尔
注意,不能是 text 字段
1.2 Bucket 聚合
这里假如我们需要对不同品牌的酒店进行聚合人,那么我们就可以使用桶聚合,桶聚合的例子如下:
GET /hotel/_search
{"size": 0, // 设置size为0,结果中不包含文档,只包含聚合结果"aggs": { // 定义聚合"brandAgg": { //给聚合起个名字"terms": { // 聚合的类型,按照品牌值聚合,所以选择term"field": "brand", // 参与聚合的字段"order": {"_count": "asc"// 按照聚合数量进行升序排列,默认降序},"size": 20 // 希望获取的聚合结果数量}}}
}
聚合结果如下:

如果我们需要在一些查询的条件下进行聚合,比如我们只对200元一下的酒店文档进行聚合,那么聚合条件如下:
GET /hotel/_search
{"query": {"range": {"price": {"lte": 200 // 只对200元以下的文档聚合}}}, "size": 0, "aggs": {"brandAgg": {"terms": {"field": "brand","size": 20}}}
}
1.3 Metrics 聚合
如果我们需要按照每个品牌的用户的评分的最大值、最小值、平均值等进行排序,那么这就需要用到 Metrics 聚合了,我们使用 stats 查看所有的聚合属性,该聚合的实现如下:
GET /hotel/_search
{"size": 0, "aggs": {"brandAgg": { "terms": { "field": "brand", "size": 20},"aggs": { // 是brands聚合的子聚合,也就是分组后对每组分别计算"scoreAgg": { // 聚合名称"stats": { // 聚合类型,这里stats可以计算min、max、avg等"field": "score" // 聚合字段,这里是score}}}}}
}
聚合结果如下:

如果我们想要对按照聚合的平均值进行排序,那么DSL语句如下:
GET /hotel/_search
{"size": 0, "aggs": {"brandAgg": { "terms": { "field": "brand", "size": 20,"order": {"scoreAgg.avg": "asc" //按照平均值进行排序}},"aggs": { "scoreAgg": { "stats": {"field": "score" }}}}}
}
1.4 使用 RestClient 进行聚合
我们以各个酒店的品牌聚合为例,其中java语句与DSL语句的一一对应关系如下:

使用RestClient进行聚合的代码如下:
@Testvoid testAgg() throws IOException {//1.准备Request对象SearchRequest request = new SearchRequest("hotel");//2.准备sizerequest.source().size(0);//3.进行聚合request.source().aggregation(AggregationBuilders.terms("brandAgg").field("brand").size(10));//4.发送请求SearchResponse response = restHighLevelClient.search(request, RequestOptions.DEFAULT);//解析聚合结果Aggregations aggregations = response.getAggregations();//根据名称获取聚合结果Terms brandterms = aggregations.get("brandAgg");//获取桶List<? extends Terms.Bucket> buckets = brandterms.getBuckets();// 遍历for (Terms.Bucket bucket: buckets){// 获取key,也就是品牌信息String brandName = bucket.getKeyAsString();System.out.println(brandName);}}
结果如下:

2. 自动补全
2.1 安装补全包
自动补全我们需要实现的效果是当我们输入拼音的时候,就有一些产品的提示,这种情况下就需要我们对拼音有一定的处理,所以我们在这里下载一个拼音分词器,下载的方式与上面下载 IK 分词器相差不大,都是首先进入容器内部,然后在容器插件目录下进行安装,
# 进入容器内部
docker exec -it es /bin/bash# 在线下载并安装
/usr/share/elasticsearch/bin/elasticsearch-plugin install --batch \https://github.com/medcl/elasticsearch-analysis-pinyin/releases/download/v7.12.1/elasticsearch-analysis-pinyin-7.12.1.zip#退出
exit#重启容器
docker restart es
重启后,使用拼音分词器试试效果,如下:
POST /_analyze
{"text": ["你干嘛哎哟"],"analyzer": "pinyin"
}

2.2 自定义分词器
从上面的例子我们可以看出,拼音分词器是将一句话的每个字都进行分开,并且首字母的拼音全部都在一起的,这肯定不是我们想要看到的,我们想要的是对句子进行分词后还能根据词语来创建拼音的索引,所以,这就需要我们自定义分词器了。
首先,我们需要了解分词器的工作步骤,elasticsearch中分词器(analyzer)的组成包含三部分:
- character filters:在tokenizer之前对文本进行处理。例如删除字符、替换字符
- tokenizer:将文本按照一定的规则切割成词条(term)。例如keyword,就是不分词;还有ik_smart tokenizer
- filter:将tokenizer输出的词条做进一步处理。例如大小写转换、同义词处理、拼音处理等
自定义分词器的DSL代码如下:
PUT /test //针对的是test索引库
{"settings": {"analysis": {"analyzer": { //自定义分词器"my_analyzer": { //分词器名称"tokenizer": "ik_max_word","filter": "py" //过滤器名称}},"filter": { "py": { "type": "pinyin", //拼音分词器"keep_full_pinyin": false,"keep_joined_full_pinyin": true,"keep_original": true,"limit_first_letter_length": 16,"remove_duplicated_term": true,"none_chinese_pinyin_tokenize": false}}}},"mappings": { //创建的索引库的映射"properties": {"name": {"type": "text","analyzer": "my_analyzer",//创建索引时的"search_analyzer": "ik_smart"}}}
}
进行测试如下:
POST /test/_doc/1
{"id": 1,"name": "下雪"
}POST /test/_doc/2
{"id": 2,"name": "瞎学"
}GET /test/_search
{"query": {"match": {"name": "武汉在下雪嘛"}}
}
查询结果如下:

2.3 自动补全查询
elasticsearch提供了 Completion Suggester 查询来实现自动补全功能。这个查询会匹配以用户输入内容开头的词条并返回。为了提高补全查询的效率,对于文档中字段的类型有一些约束:
- 参与补全查询的字段必须是
completion类型。 - 字段的内容一般是用来补全的多个词条形成的数组。
首先我们先建立索引库以及索引库约束,
PUT test2
{"mappings": {"properties": {"title":{"type": "completion"}}}
}
在 test2 索引库中添加数据
// 示例数据
POST test2/_doc
{"title": ["Sony", "WH-1000XM3"]
}POST test2/_doc
{"title": ["SK-II", "PITERA"]
}POST test2/_doc
{"title": ["Nintendo", "switch"]
}
进行自动补全查询,我们给出一个关键字 s ,对其进行补全查询如下,
GET /test2/_search
{"suggest": {"title_suggest": {"text": "s", // 关键字"completion": {"field": "title", // 补全查询的字段"skip_duplicates": true, // 跳过重复的"size": 10 // 获取前10条结果}}}
}
查询结果如下:

2.4 拼音自动补全查询
如果想要使用拼音自动补全进行查询,那么就必须自定义分词器了,自定义分词器如下:
PUT /test3
{"settings": {"analysis": {"analyzer": { "my_analyzer": {"tokenizer": "ik_max_word","filter": "py"},"completion_analyzer": {"tokenizer": "keyword","filter": "py"}},"filter": { "py": { "type": "pinyin", "keep_full_pinyin": false,"keep_joined_full_pinyin": true,"keep_original": true,"limit_first_letter_length": 16,"remove_duplicated_term": true,"none_chinese_pinyin_tokenize": false}}}},"mappings": {"properties": {"title": {"type": "completion","analyzer": "completion_analyzer"}}}
}
然后创建一个索引库,并添加一些文档,如下:
PUT /test3
{"mappings": {"properties": {"title":{"type": "completion"}}}
}POST test3/_doc
{"title": ["上子", "熵字", "下雪"]
}POST test3/_doc
{"title": ["赏金", "秀色", "猎人"]
}
然后就可以根据首字母缩写或者拼音来进行查询了,DSL代码如下:
GET /test3/_search
{"suggest": {"suggestions": {"text": "xx","completion": {"field": "title","skip_duplicates": true,"size": 10}}}
}
如上,我们输入的是下雪的拼音缩写 xx ,进行查询时,结果如下:

当然,也可以对拼音进行按顺序的补全查询。
2.5 RestClient 实现自动补全
2.5.1 建立索引
要实现对索引库的内容进行自动补全,我们需要重新创建索引库,我们的索引库需要多出一个 completion 字段的类型,所以删除原有的索引库后创建新的索引库如下:
DELETE /hotelPUT /hotel
{"settings": {"analysis": {"analyzer": { "my_analyzer": {"tokenizer": "ik_max_word","filter": "py"},"completion_analyzer": {"tokenizer": "keyword","filter": "py"}},"filter": { "py": { "type": "pinyin", "keep_full_pinyin": false,"keep_joined_full_pinyin": true,"keep_original": true,"limit_first_letter_length": 16,"remove_duplicated_term": true,"none_chinese_pinyin_tokenize": false}}}},"mappings": {"properties": {"id": {"type": "keyword"},"name": {"type": "text","analyzer": "ik_max_word","copy_to": "all"},"address": {"type": "keyword","index": false},"price": {"type": "integer"},"score": {"type": "integer"},"brand": {"type": "keyword","copy_to": "all"},"city": {"type": "keyword"},"starName": {"type": "keyword"},"bussiness": {"type": "keyword","copy_to": "all"},"location": {"type": "geo_point"},"pic": {"type": "keyword","index": false},"all": {"type": "text","analyzer": "ik_max_word"},"suggestion": {"type": "completion","analyzer": "completion_analyzer"}}}
}
2.5.2 修改数据定义
除此之外,还需要将 Hotel 的定义进行修改,因为自动补全的字段不止一个字段,所以我们使用列表类型,定义如下:
@Data
@NoArgsConstructor
@ToString
public class HotelDoc {private Long id;private String name;private String address;private Integer price;private Integer score;private String brand;private String city;private String starName;private String business;private String location;private String pic;private List<String> suggestion;public HotelDoc(Hotel hotel) {this.id = hotel.getId();this.name = hotel.getName();this.address = hotel.getAddress();this.price = hotel.getPrice();this.score = hotel.getScore();this.brand = hotel.getBrand();this.city = hotel.getCity();this.starName = hotel.getStarName();this.business = hotel.getBusiness();this.location = hotel.getLatitude() + ", " + hotel.getLongitude();this.pic = hotel.getPic();this.suggestion = Arrays.asList(this.brand, this.business);}
}
以上定义就是将 brand 和 business 都进行补全的数据结构定义。
之后再按照之前的批量添加将数据库中的数据进行批量新增即可。
2.5.3 补全查询
以下是RestClient与DSL语句的一一对应关系,
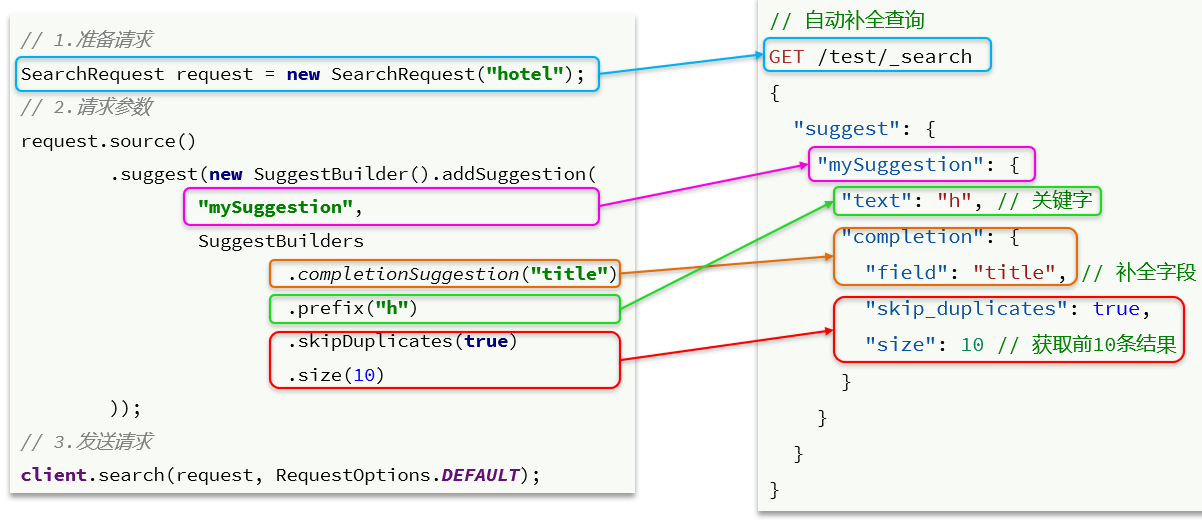
补全查询的语句如下:
@Testvoid testSuggest() throws IOException{//1. 准备RequestSearchRequest request = new SearchRequest("hotel");//2. 准备DSLrequest.source().suggest(new SuggestBuilder().addSuggestion("suggestions",SuggestBuilders.completionSuggestion("suggestion").prefix("hu").skipDuplicates(true).size(10)));//3. 发起请求SearchResponse response = restHighLevelClient.search(request, RequestOptions.DEFAULT);//4. 输出结果System.out.println(response);}
2.5.4 解析结果
输出的查询结果是一个包含很多形式的信息的Map类型,我们需要对其进行解析,获取其中想要的结果才行,解析的语句与DSL查询的结果对应关系如下:

解析的结果的语句如下:
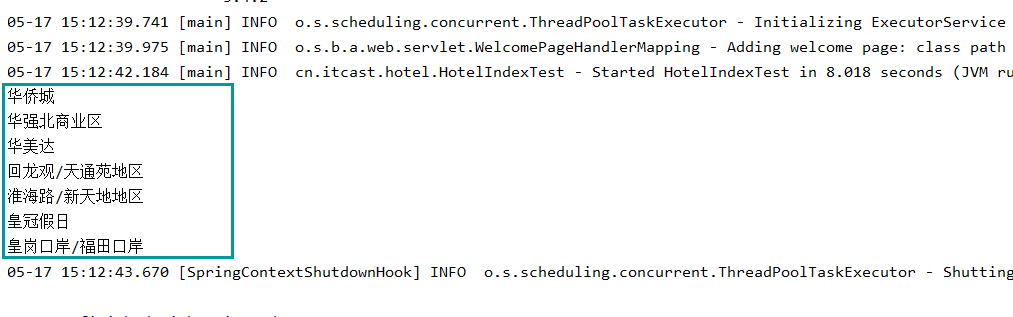
@Testvoid testSuggest() throws IOException{//1. 准备RequestSearchRequest request = new SearchRequest("hotel");//2. 准备DSLrequest.source().suggest(new SuggestBuilder().addSuggestion("suggestions",SuggestBuilders.completionSuggestion("suggestion").prefix("hu").skipDuplicates(true).size(10)));//3. 发起请求SearchResponse response = restHighLevelClient.search(request, RequestOptions.DEFAULT);//4. 解析结果Suggest suggest = response.getSuggest();//4.1 根据补全查询名称,获取补全结果CompletionSuggestion suggestions = suggest.getSuggestion("suggestions");//4.2 获取optionsList<CompletionSuggestion.Entry.Option> options = suggestions.getOptions();//4.3 遍历for (CompletionSuggestion.Entry.Option option : options) {String text = option.getText().toString();System.out.println(text);}}
处理后的结果输出如下:
相关文章:
SpringCloud(十)——ElasticSearch简单了解(三)数据聚合和自动补全
文章目录 1. 数据聚合1.1 聚合介绍1.2 Bucket 聚合1.3 Metrics 聚合1.4 使用 RestClient 进行聚合 2. 自动补全2.1 安装补全包2.2 自定义分词器2.3 自动补全查询2.4 拼音自动补全查询2.5 RestClient 实现自动补全2.5.1 建立索引2.5.2 修改数据定义2.5.3 补全查询2.5.4 解析结果…...
二叉查找树(binary search tree)(难度7)
C数据结构与算法实现(目录) 答案在此:二叉查找树(binary search tree)(答案) 写在前面 部分内容参《算法导论》 基本接口实现 1 删除 删除值为value的第一个节点 删除叶子节点1 删除叶子节…...
windows环境装MailHog
背景:win10系统,windows 宝塔,laravel 项目,邮件相关需要装一个MailHog 下载地址:https://sourceforge.net/projects/mailhog.mirror/ 直接下载,下载后双击运行就可以了,系统可能提示”不信任“…...

Ubuntu 22.04.2 LTS 安装python3.6后报错No module named ‘ufw‘
查明原因: vim /usr/sbin/ufw 初步判断是python版本的问题。 # 查看python3软链接 ll /usr/bin/python3 将python3的软链接从python3.6换成之前的3.10,根据自己电脑情况。 可以查看下 /usr/bin 下有什么 我这是python3.10 所以解决办法是 # 移除py…...
Flutter小功能实现-咖啡店
1 导航栏实现 效果图: 1.Package google_nav_bar: ^5.0.6 使用文档: google_nav_bar | Flutter Package 2.Code //MyBottomNavBar class MyBottomNavBar extends StatelessWidget {void Function(int)? onTabChange;MyBottomNavBar({super.key, …...

JavaSE 集合框架及背后的数据结构
目录 1 介绍2 学习的意义2.1 Java 集合框架的优点及作用2.2 笔试及面试题 3 接口 interfaces3.1 基本关系说明3.2 Collection 常用方法说明3.3 Collection 示例3.4 Map 常用方法说明3.5 Map 示例 4 实现 classes5 Java数据结构知识体系5.1 目标5.2 知识点 1 介绍 集合…...

-9501 MAL系统没有配置或者服务器不是企业版(dm8达梦数据库)
dm8达梦数据库 -9501 MAL系统没有配置或者服务器不是企业版) 环境介绍1 环境检查2 问题原因 环境介绍 搭建主备集群时,遇到报错-9501 MAL系统没有配置或者服务器不是企业版 1 环境检查 检查dmmal.ini配置文件权限正确 dmdba:dinstall,内容正…...

云备份——第三方库简单介绍并使用(上)
目录 一,Jsoncpp库序列化和反序列化 二,bundle文件压缩库 2.1 文件压缩 2.2 文件解压 一,Jsoncpp库序列化和反序列化 首先我们需要先了解一下json是什么,json是一种数据交换格式,采用完全独立于编程语言的文本格式来…...
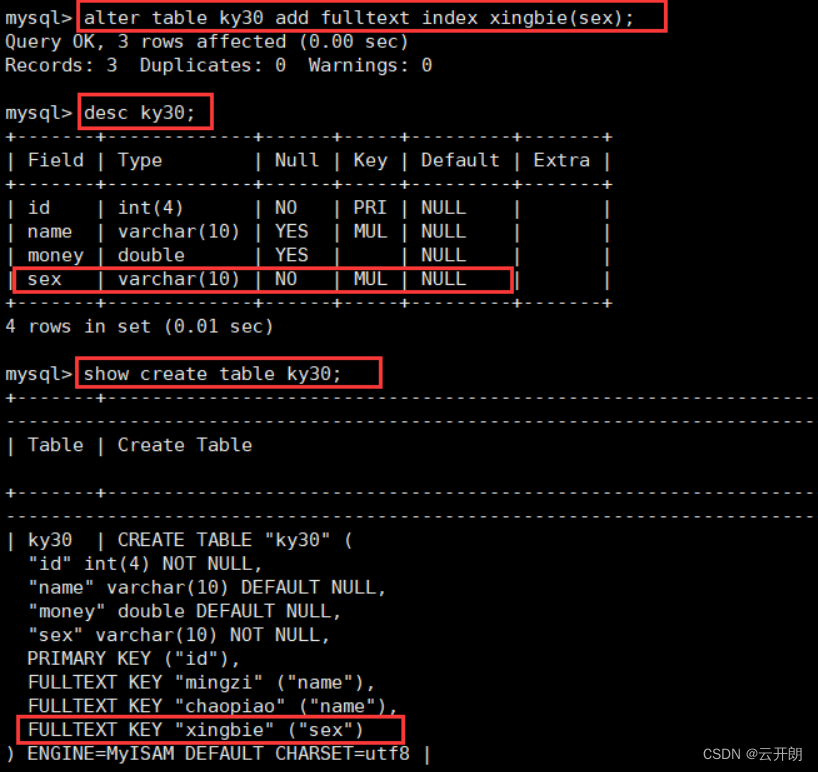
MySQL数据库之索引
目录 一、索引的概念 二、索引的作用 三、索引的副作用 四、创建索引的规则 1、适合创建为索引的字段的规则 2、MySQL的优化 哪些字段/场景适合创建索引,哪些不适合 五、索引的分类和创建 1、索引的分类 2、三种创建方式 3、索引的创建演示 1、创建普通索…...
:Mat支持的运算)
OpenCV(四):Mat支持的运算
目录 1.对两个 Mat 对象按元素进行运算,有加法、减法、乘法和除法等运算。 2.Mat类支持逻辑与、或、非等逻辑运算, 1.对两个 Mat 对象按元素进行运算,有加法、减法、乘法和除法等运算。 加法:Mat Mat,保存到 resul…...
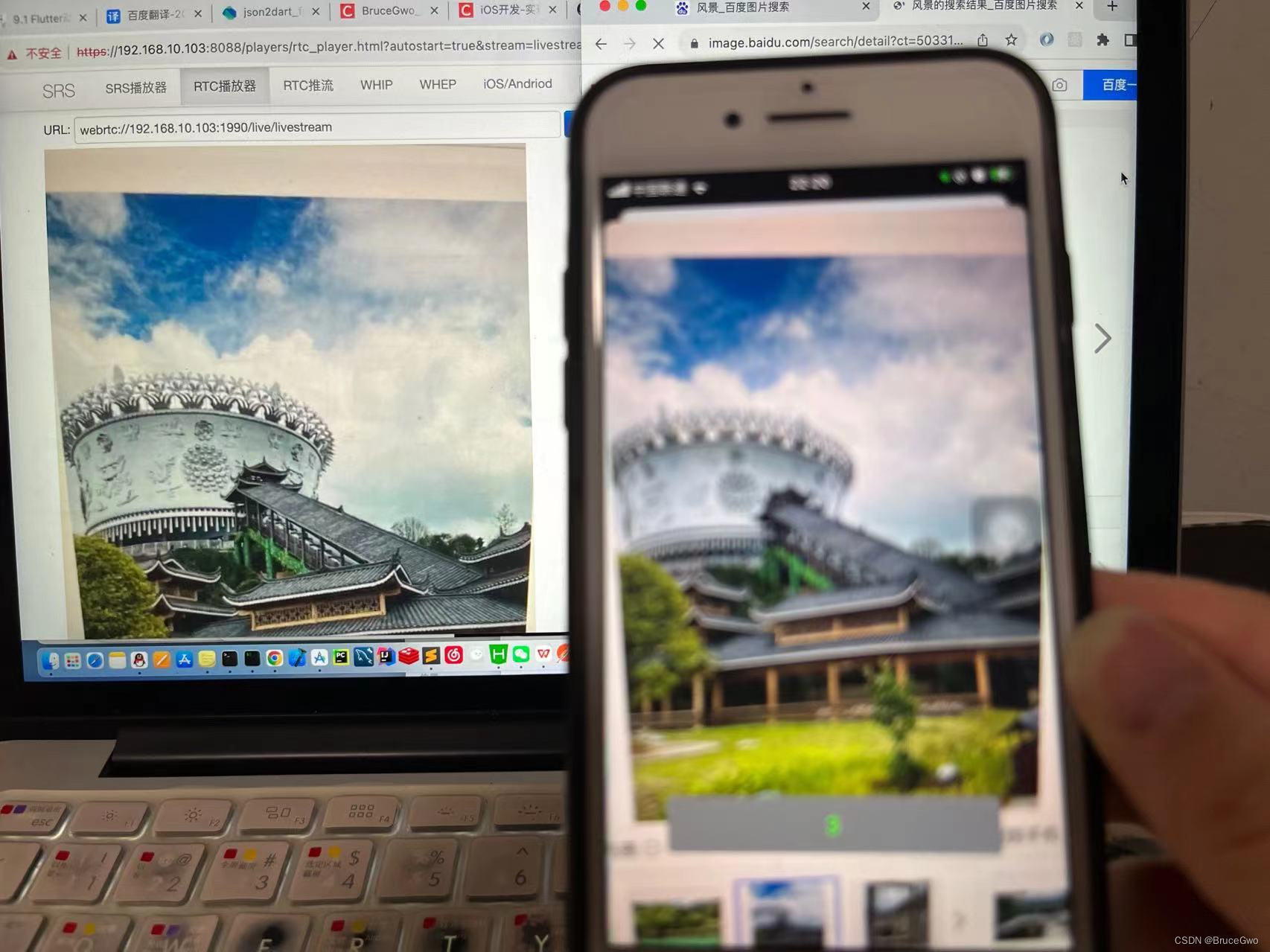
WebRTC音视频通话-WebRTC推拉流过程中日志log输出
WebRTC音视频通话-WebRTC推拉流过程中日志log输出 之前实现iOS端调用ossrs服务实现推拉流流程。 推流:https://blog.csdn.net/gloryFlow/article/details/132262724 拉流:https://blog.csdn.net/gloryFlow/article/details/132417602 在推拉流过程中的…...

用Jmeter压测问题解决
最近做一个基于duboo服务的接口,需要进行稳定性测试。但是用Jmeter GUI 方式跑只能持续2个小时左右,Jmeter就崩溃了,日志报错:out of memory 解决方法如下: 直接运行jmeter的java包试试: 1、打开jmeter.…...

C语言:字符函数和字符串函数(一篇拿捏字符串函数!)
目录 求字符串长度: 1. strlen(字符串长度) 长度不受限制函数: 2. strcpy(字符串拷贝) 3. strcat(字符串追加) 4. strcmp(字符串比较) 长度受限制函数: 5. strncpy(字符串拷贝) 6. strncat(字符串追加) 7. strncmp(字符串比较) 字…...

问道管理:成交量买卖公式?
跟着股票商场的如火如荼,人们对于怎么解读和使用成交量进行股票生意的需求日积月累。成交量是指在某一特定时间内进行的股票生意的数量,它是投资者们研判商场状况和制定生意战略的重要指标之一。那么,是否存在一种最厉害的成交量生意公式呢&a…...

【MySQL】5、MySQL高阶语句
一、常用查询(增、删、改、查) 对 MySQL 数据库的查询,除了基本的查询外,有时候需要对查询的结果集进行处理。 例如只取 10 条数据、对查询结果进行排序或分组等等 模板表: 数据库有一张info表,记录了学生…...

【Linux】redhat7.8配置yum在线源【redhat7.8镜像容器内配置yum在线源】通用
👨🎓博主简介 🏅云计算领域优质创作者 🏅华为云开发者社区专家博主 🏅阿里云开发者社区专家博主 💊交流社区:运维交流社区 欢迎大家的加入! 🐋 希望大家多多支…...

强大的处理器和接口支持BL304ARM控制器
在智慧医疗领域,BL304可以用于实现医疗设备的智能化、远程监控和数据交换。在智慧电力领域,BL304可以帮助实现电网的智能化管理,提升电力供应的效率。在智慧安防领域,BL304可以实现智能监控、智能门锁等应用,保障安全。…...
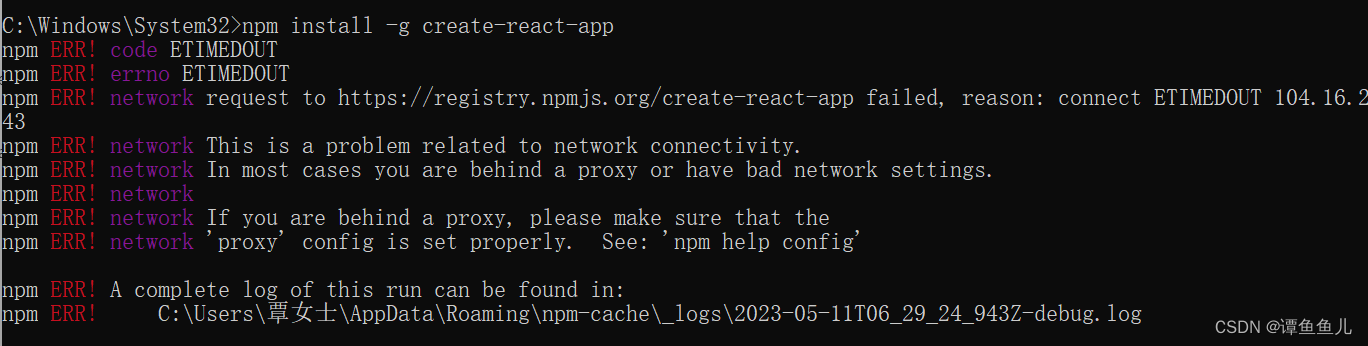
react 基础知识(一)
1、 安装1 (版本 react 18) // 安装全局脚手架(create-react-app基于webpackes6) npm install -g create-react-app //使用脚手架搭建项目 create-react-app my-app // 打开目录 cd my-app // 运行项目 npm start2、初体验 impo…...

SpringBoot整合JUnit、MyBatis、SSM
🐌个人主页: 🐌 叶落闲庭 💨我的专栏:💨 c语言 数据结构 javaEE 操作系统 石可破也,而不可夺坚;丹可磨也,而不可夺赤。 SpringBoot整合 一、SpringBoot整合JUnit二、Spri…...
virtuoso61x中集成calibre
以virtuoso618为例,在搭建完电路、完成前仿工作之后绘制版图,版图绘制完成之后需要进行drc和lvs【仅对于学校内部通常的模拟后端流程而言】,一般采用mentor的calibre来完成drc和lvs。 服务器上安装有virtuoso和calibre,但是打开la…...

一文搞懂:Git分支管理与团队协作规范——从GitFlow到GitHub Flow,从rebase到merge,打造高效协作流
📌 写在前面以前自己一个人写项目的时候,Git对我来说就是个“高级另存为”:一个master分支从头走到尾,写完就git push,从没觉得分支管理有什么难的。直到最近和朋友一起开发一个项目,问题来了:他…...

上海AI实验室发布WildClawBench:AI智能体究竟能走多远?
这项由上海人工智能实验室联合香港中文大学、复旦大学、中国科学技术大学、上海交通大学、清华大学、浙江大学及南洋理工大学等多所顶尖机构共同完成的研究,于2026年5月11日以预印本形式发布,论文编号为arXiv:2605.10912v1。感兴趣的读者可通过该编号在a…...

避开DSP28335内存管理的坑:堆、栈、CMD文件配置全解析与最佳实践
DSP28335内存管理深度优化:从堆栈原理到CMD文件实战配置 在嵌入式系统开发中,内存管理往往是决定项目成败的关键因素之一。对于基于TI C2000系列DSP28335的开发者而言,合理规划有限的内存资源不仅能提升系统性能,更能避免那些难以…...

【Spring】 AOP 核心原理,与声明式事务传播机制
一、什么是 AOPAOP(Aspect Oriented Programming,面向切面编程)核心思想在不修改原有业务代码的情况下,对方法进行统一增强。例如:日志记录;权限校验;事务管理;性能统计;…...

抖音下载器技术深度解析:构建高效稳定的多媒体内容采集系统
抖音下载器技术深度解析:构建高效稳定的多媒体内容采集系统 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback …...

Java智能地址解析架构深度解析:构建高精度企业级地址识别系统
Java智能地址解析架构深度解析:构建高精度企业级地址识别系统 【免费下载链接】address-parse Java 版智能解析收货地址 项目地址: https://gitcode.com/gh_mirrors/addr/address-parse 面对海量非结构化地址数据的处理挑战,传统规则引擎已无法满…...

Servlet 容器 vs Spring 容器 超详细对比
目录 一、先搞懂两个容器本质 1. Servlet 容器(Web 容器) 2. Spring 容器(IoC 容器) 二、核心相同点 三、核心不同点(重点) 四、最直白通俗理解 五、Web 项目完整启动顺序(必背面试题) 容器层级关系 六、请求处理流程差异 1. 原生 Servlet 模式(只有 Servle…...

站长日记:实测一款神仙工具,终于搞定了Bing和360的收录难题
最近真的很想吐槽一句:现在做个小站怎么就这么难? 事情是这样的,上个月为了测试一个新出的长尾词,我花周末两天火速搭了个新站,内容全部手写,绝对原创。按照以前的经验,这种质量的站,…...

别再只删node_modules了!npm run serve报错‘There is likely additional logging output above’的完整排查与修复手册
从日志溯源到根治:npm run serve报错的系统性排查指南 当你满怀期待地敲下npm run serve,却迎面撞上那句"There is likely additional logging output above"时,是否感到一阵无力?删除node_modules重装就像重启电脑——…...

AI 不锈钢保温杯智能功率 MOSFET 完整选型方案
2026年随着 AI 技术在智能保温杯领域的深度渗透(如精准温控、语音交互、健康监测、无线充电管理),对功率 MOSFET 提出更高要求:高集成度、低功耗、小封装、高可靠性。微碧半导体(VBsemi)基于 SGT 及 Trench…...