学习 使用pandas库 DataFrame 使用

1 、 数据排序 sort_values()函数
by:要排序的名称或名称列表,
sorted_df = df.sort_values(by='Age',ascending=False) 由大到小排序;
sorted_df = df.sort_values(by='Age') 由小到大排序;
# 创建一个示例数据帧
data = {'Name': ['Tom', 'Nick', 'John', 'Amy'],'Age': [25, 29, 35, 21],'City': ['New York', 'Paris', 'London', 'Berlin']}
df = pd.DataFrame(data)# 按照Age列进行排序
sorted_df = df.sort_values(by='Age')
sorted_df.to_csv('test1.csv')
print(sorted_df)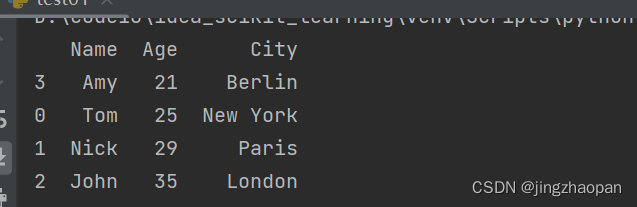
2 把字典,列表,迭代器 数据写入csv文件,to_csv() 函数
方式1:
lis_offer, lis_revenue = self.get_offer_revenue()data = {'offerid': lis_offer,'revenue': lis_revenue}result = pd.DataFrame(data)result.to_csv(data_path + start_time + "offer_revenue.csv")方式2:
lis_offer, lis_revenue = self.get_offer_revenue()x_offer = np.array(lis_offer).reshape(-1, 1)x_revenue = np.array(lis_revenue).reshape(-1, 1)result = np.concatenate((x_offer, x_revenue), axis=1)result = pd.DataFrame(result, columns=['offerid', 'revenue'])result.to_csv(data_path + start_time + "offer_revenue.csv") def read4(self):active_score_lit = []li = ['90-100.tsv']for i in li:with open(i, mode='r+', encoding='utf-8') as file:for i in file.readlines():aa = json.loads(i)active_score_lit.append(aa)data = pd.DataFrame(active_score_lit) access_cat ... conv_score
0 {"IAB9-5":7.32514399521715,"IAB9-30":7.3255896... ... NaN
1 {"IAB9-30":1.2948738821508443,"IAB1":1.2948738... ... NaN
2 {"IAB9-5":6.751567110240471,"IAB9-30":7.859169... ... NaN
3 NaN ... 2013.6735
4 {"IAB1":17.93415291298408,"IAB5":3.91909391671... ... NaN
方式3:
class GetOfferid():def get_numpage(self):'''通过请求 task任务接口 num::return:输出 迭代器:offerid, strategy, country, sendSuccessCount, deviceCount'''for page in range(1, 15+1):url1 = host + "api/admin/v3/task/page?pageNum="+str(page)+"&pageSize=10"res = (requests.get(url=url1, headers=header, verify=False).json())['result']['records']time.sleep(1)for result in res:yield result['offerId'],result['strategy'],result['country'],result['sendSuccessCount'],result['deviceCount']def write_csv(self):lis_deviceCount = self.get_numpage()# 迭代器 generator for i in lis_deviceCount: 遍历结果: ('9702', 'vba', 'IN', 155917, 48412574)result = pd.DataFrame(lis_deviceCount, columns=['offerid', 'strategy', 'country', 'sendSuccessCount', 'deviceCount'])result.to_csv(filename)方式3: 已存在表格中写入一列数据:
df = pd.read_csv(filename)df['expect_cvr'] = self.get_expect_cvr()df.to_csv(filename, index=False, encoding="utf_8_sig")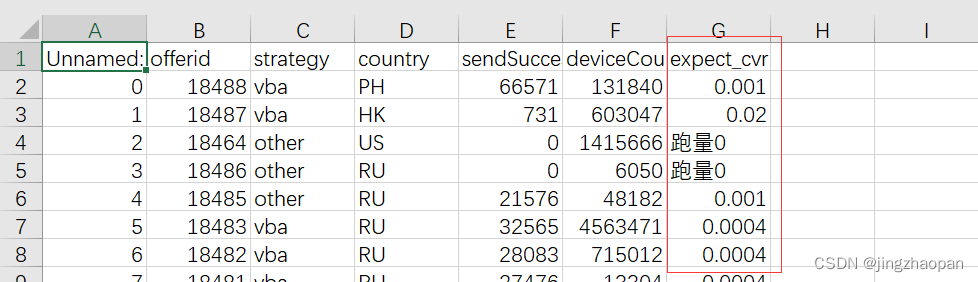
方式4: 已存在表格中写入几行数据:
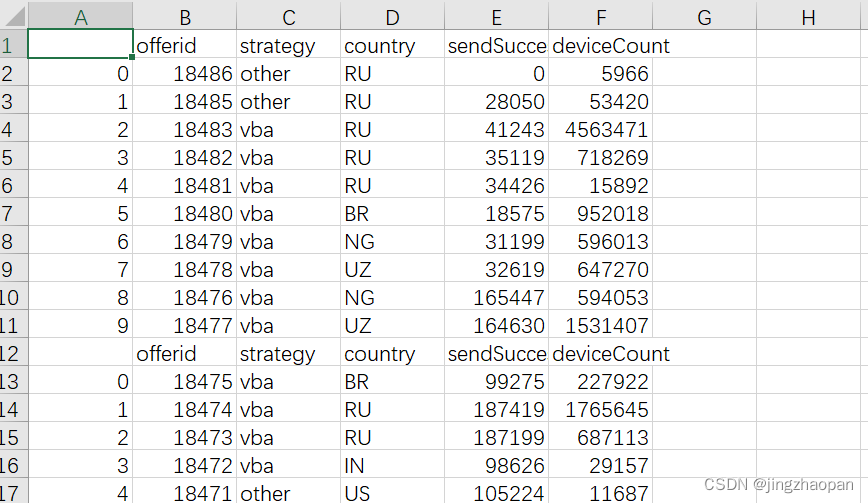
原数据:

追加写入 result.to_csv(filename, mode='a'), 加上mode='a',便可以追加写入数据;
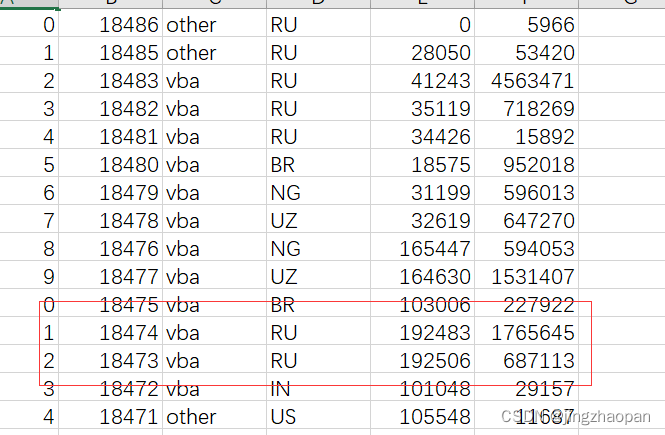
追加写入 header=False, 不写出列名;
result.to_csv(filename, mode='a', header=False)
3 查询 内容
3-0 查询单行数据【索引】,遍历所有行的数据
# 创建一个示例数据帧
data = {'Name': ['Tom', 'Nick', 'John', 'Nick'],'Age': [25, 29, 35, 21],'City': ['New York', 'Paris', 'London', 'Berlin']}
df = pd.DataFrame(data)
print(df)
print("``````````````````````")
print(df[2:3])
print("``````````````````````")
for rr in df.values:print(rr)Name Age City
0 Tom 25 New York
1 Nick 29 Paris
2 John 35 London
3 Nick 21 Berlin
``````````````````````Name Age City
2 John 35 London
``````````````````````
['Tom' 25 'New York']
['Nick' 29 'Paris']
['John' 35 'London']
['Nick' 21 'Berlin']3-1根据内容查询出对应的索引: np.flatnonzero(df['Name'] == 'Nick')
data = {'Name': ['Tom', 'Nick', 'John', 'Nick'],'Age': [25, 29, 35, 21],'City': ['New York', 'Paris', 'London', 'Berlin']}
df = pd.DataFrame(data)
print(df)
print("``````````````````````")
d = np.flatnonzero(df['Name'] == 'Nick')
print(d)Name Age City
0 Tom 25 New York
1 Nick 29 Paris
2 John 35 London
3 Nick 21 Berlin
``````````````````````
[1 3]3-2根据内容查询出对应的行的内容: df.loc[df['Name'] == 'Nick']
data = {'Name': ['Tom', 'Nick', 'John', 'Nick'],'Age': [25, 29, 35, 21],'City': ['New York', 'Paris', 'London', 'Berlin']}
df = pd.DataFrame(data)
print(df)
print("``````````````````````")
f = df.loc[df['Name'] == 'Nick']
print(f)Name Age City
0 Tom 25 New York
1 Nick 29 Paris
2 John 35 London
3 Nick 21 Berlin
``````````````````````Name Age City
1 Nick 29 Paris
3 Nick 21 BerlinDataFrame 增删改
2.3.1 行的操作
1.1 添加行
pd._append(new_series, ignore_index =True) ignore_index =True忽略标签意识
返回一个新的DataFrame
lis_dic2 = {'offerId':[12078,18379,1817],'click':[1663,18492024,6379911],
}pd2 = pd.DataFrame(lis_dic2)
new_series = pd.Series([999,1000],index=['offerId','click'])
pd3 = pd2._append(new_series, ignore_index =True)1.2 修改行
pd.loc[行标签] = [列标签内容,列标签内容] x 表示要修改的行标签,填写所有内容不用添加标签
pd.locx[行位置] = [列位置内容,列位置内容,] x 表示要修改的行标签,填写所有内容不用添加标签
lis_dic2 = {'offerId':[12078,18379,1817,999],'click':[1663,18492024,6379911,1000],
}pd2 = pd.DataFrame(lis_dic2)
pd2.loc[2] = [1819,181918]1.3 删除行
pd.drop([x]), X表示要删除的行号,可以是多行,删除返回一个新的DataFrame
lis_dic2 = {'offerId':[12078,18379,1817,999],'click':[1663,18492024,6379911,1000],
}
pd2 = pd.DataFrame(lis_dic2)
pd3 = pd2.drop([2])2.3.2 列的操作
1.1 新增/修改 列
方式1: df['列标签'] = 新列
方式2: pd.loc[:,'列标签'] =新列
如果DataFrame 不存在这一列,则新增一列; 如果DataFrame存在这一列则修改值;
new_result = DataFrame(result,columns=['sourceManager','sex','tel']) # 新增一个列
new_result['tel'] = ['15829041959','15829041969','15829041979','15829041989'] 新增这一列赋值;1.2 删除列
pd.drop([x],axis=1), X表示要删除的列,删除返回一个新的DataFrame
lis_dic2 = {'offerId':[12078,18379,1817,999],'click':[1663,18492024,6379911,1000],
}
pd2 = pd.DataFrame(lis_dic2)
pd2.loc[:,'sourceManager'] = ['ber','amie','terch','lisi']
pd3 = pd2.drop(['click'],axis=1)DataFrame 数据查询
2.4.1 df.nlargest(n,columns) 按照columns 指定的列进行降序排序,并取前N行数据;
2.4.2 df.nsmallest(n,columns) 按照columns 指定的列进行升序排序,并取前N行数据;
lis_dic2 = {'offerId':[12078,18379,1817,999],'click':[1663,18492024,6379911,1000],
}
pd2 = pd.DataFrame(lis_dic2)
pd3 = pd2.nsmallest(2,'click')2.4.3 按条件查询:
方式1: pd3 =pd2.loc[ 查询条件 ]
方式2: pd2.query(查询条件)
lis_dic2 = {'offerId':[12078,18379,1817,999],'click':[1663,18492024,6379911,1000],
}
pd2 = pd.DataFrame(lis_dic2)
pd3 =pd2.loc[(pd2['click'] >1500)& (pd2['click'] < 6379912)]
pd4 = pd2.query('click > 1500 & click< 6379912')2.4.4 分组聚合
方式1:pd2.groupby(列标签,···). 列标签 . 聚合函数()
按指定列分组,并对分组数据的相应列进行相应的聚合操作;
lis_dic2 = {'offerId':[12078,18379,1817,999],'click':[1663,18492024,6379911,1000],'sex':['A','B','A','B']
}
pd2 = pd.DataFrame(lis_dic2)
# 安装sex 字段分组, 求 ‘click’字段平均值
pd4 = pd2.groupby('sex').click.mean()方式2:pd2.groupby(列标签,···).agg({'列标签':'聚合函数()',······})
按指定列分组,并对分组数据的相应列进行相应的聚合操作
lis_dic2 = {'offerId':[12078,18379,1817,999],'click':[1663,18492024,6379911,1000],'sex':['A','B','A','B']
}
pd2 = pd.DataFrame(lis_dic2)
# # 安装sex 字段分组, 求 'offerId'的个数 和 ‘click’字段平均值
pd3 = pd2.groupby('sex').agg({'offerId':'count','click':'mean'})2.5 排序
2.5.1 将DataFrame 按照指定列的数据进行排序;ascending=False,降序,True,升序;
pd2.sort_values(by='列标签',ascending=False)
lis_dic2 = {'offerId':[12078,18379,1817,999],'click':[1663,18492024,6379911,1000],'sex':['A','B','A','B']
}
pd2 = pd.DataFrame(lis_dic2)
# 排序
pd3 = pd2.sort_values('click',ascending=False)2.5.2 将DataFrame 按照行标签进行排序;ascending=False,降序,True,升序;
pd2.sort_index(ascending=True)
lis_dic2 = {'offerId':[12078,18379,1817,999],'click':[1663,18492024,6379911,1000],'sex':['A','B','A','B']
}
pd2 = pd.DataFrame(lis_dic2)
# 排序
pd4 = pd2.sort_index(ascending=True)相关文章:
学习 使用pandas库 DataFrame 使用
1 、 数据排序 sort_values()函数 by:要排序的名称或名称列表, sorted_df df.sort_values(byAge,ascendingFalse) 由大到小排序; sorted_df df.sort_values(byAge) 由小到大排序; # 创建一个示例数据帧 data {Name: [Tom, Nick, John…...
C++字符串详解
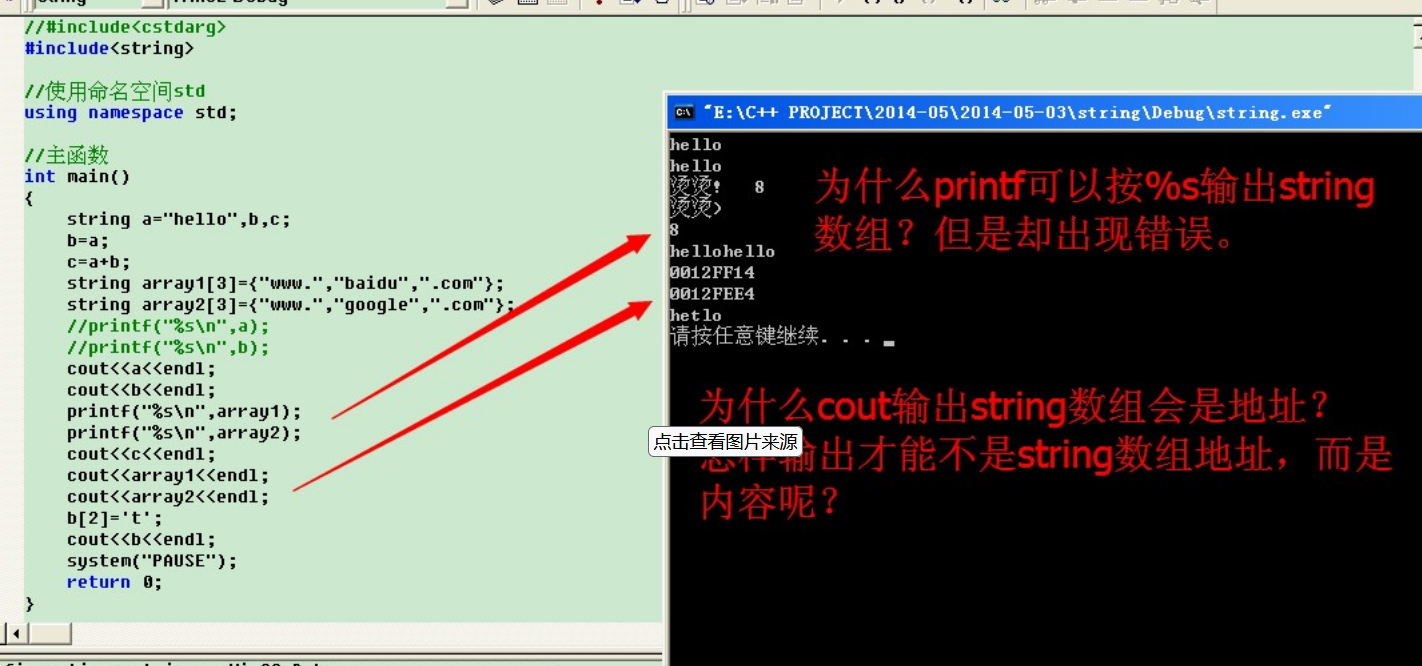
C 大大增强了对字符串的支持,除了可以使用C风格的字符串,还可以使用内置的 string 类。string 类处理起字符串来会方便很多,完全可以代替C语言中的字符数组或字符串指针。 string 是 C 中常用的一个类,它非常重要,我们…...

vant2 van-calendar组件增加清除按钮和确定按钮
利用自定义插槽增加一个清除按钮 <van-calendar ref"fTime1" select"selectTimePicker" confirm"changeTimePicker" :default-date"null" :show-confirm"false" v-model"timePickerShow" type"range&quo…...
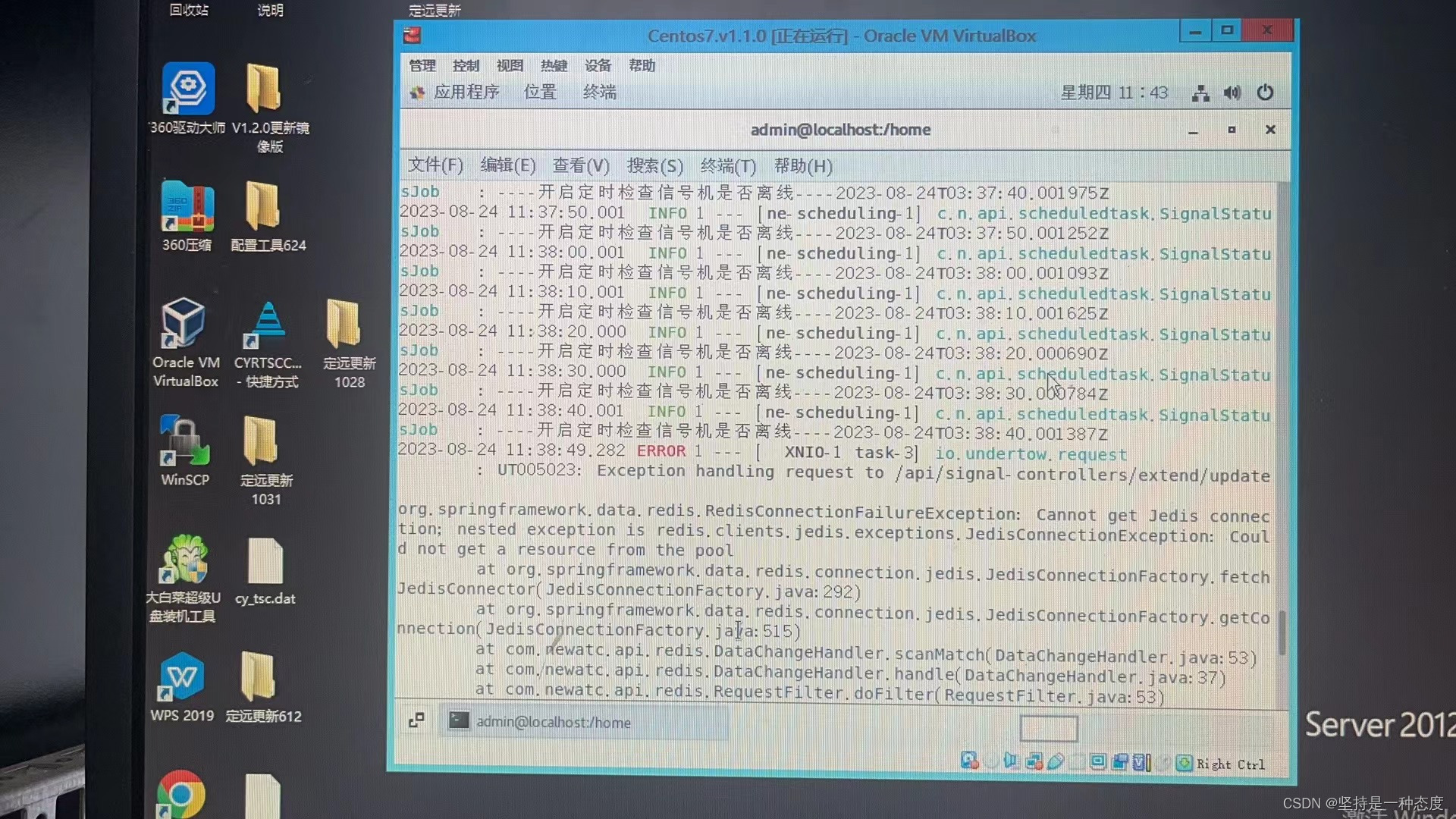
Spring redis使用报错Read timed out排查解决
文章目录 使用场景报错信息解决方式 使用场景 我们使用redis作为缓存服务,缓存一些业务数据,如路口点位信息、渠化信息、设备信息等有一些需要实时计算的数据,缓存在redis里,如实时信号周期相位、周期内过车数量等有需要不同服务…...
C语言每日一练-------Day(9)
本专栏为c语言练习专栏,适合刚刚学完c语言的初学者。本专栏每天会不定时更新,通过每天练习,进一步对c语言的重难点知识进行更深入的学习。 今日练习题关键字:字符个数统计 多数元素 投票法 💓博主csdn个人主页…...
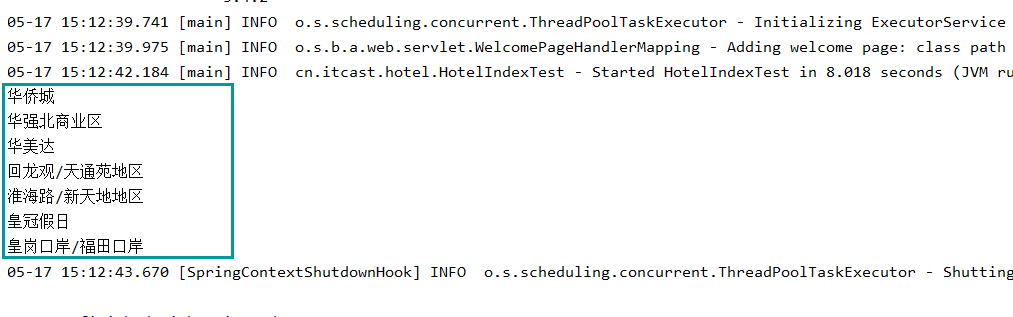
SpringCloud(十)——ElasticSearch简单了解(三)数据聚合和自动补全
文章目录 1. 数据聚合1.1 聚合介绍1.2 Bucket 聚合1.3 Metrics 聚合1.4 使用 RestClient 进行聚合 2. 自动补全2.1 安装补全包2.2 自定义分词器2.3 自动补全查询2.4 拼音自动补全查询2.5 RestClient 实现自动补全2.5.1 建立索引2.5.2 修改数据定义2.5.3 补全查询2.5.4 解析结果…...
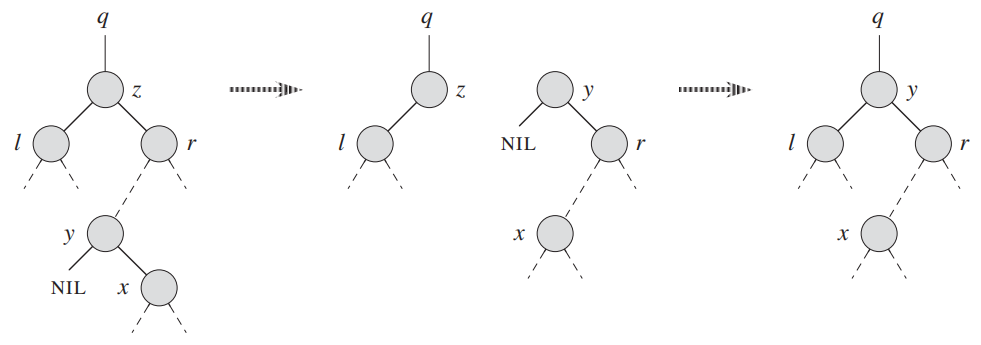
二叉查找树(binary search tree)(难度7)
C数据结构与算法实现(目录) 答案在此:二叉查找树(binary search tree)(答案) 写在前面 部分内容参《算法导论》 基本接口实现 1 删除 删除值为value的第一个节点 删除叶子节点1 删除叶子节…...
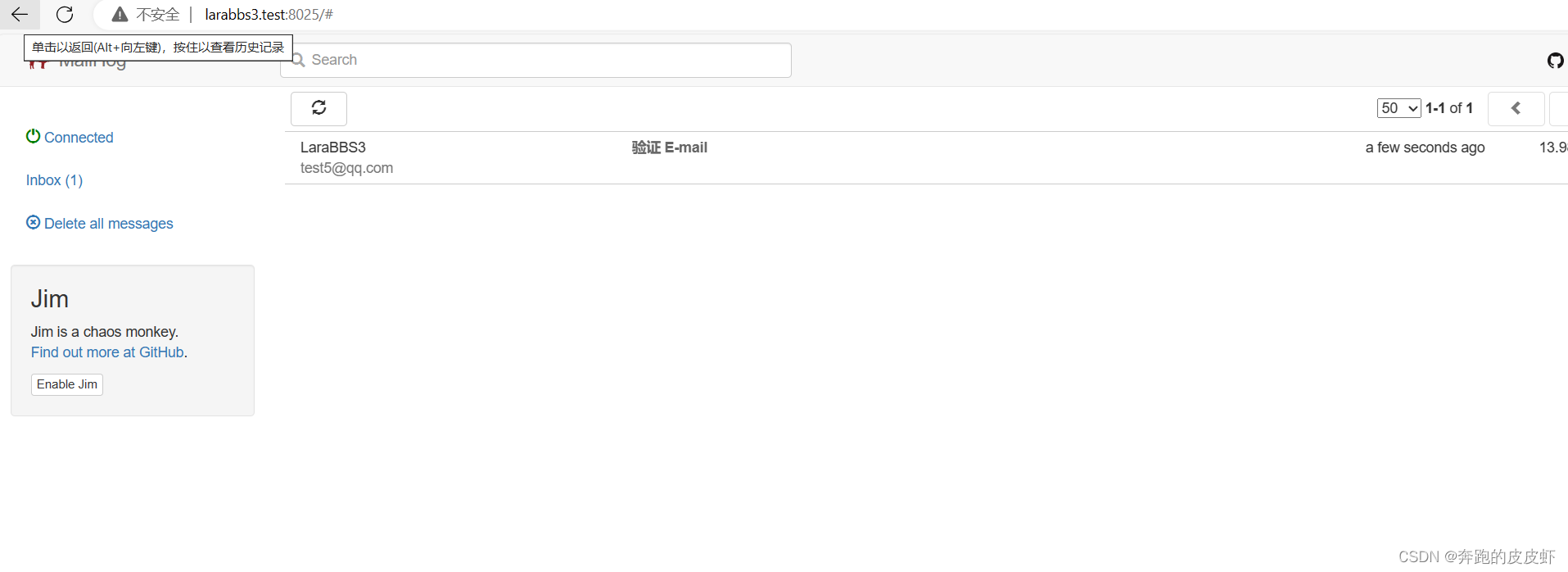
windows环境装MailHog
背景:win10系统,windows 宝塔,laravel 项目,邮件相关需要装一个MailHog 下载地址:https://sourceforge.net/projects/mailhog.mirror/ 直接下载,下载后双击运行就可以了,系统可能提示”不信任“…...

Ubuntu 22.04.2 LTS 安装python3.6后报错No module named ‘ufw‘
查明原因: vim /usr/sbin/ufw 初步判断是python版本的问题。 # 查看python3软链接 ll /usr/bin/python3 将python3的软链接从python3.6换成之前的3.10,根据自己电脑情况。 可以查看下 /usr/bin 下有什么 我这是python3.10 所以解决办法是 # 移除py…...
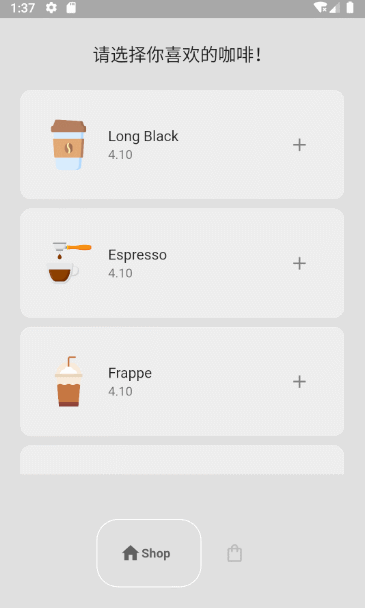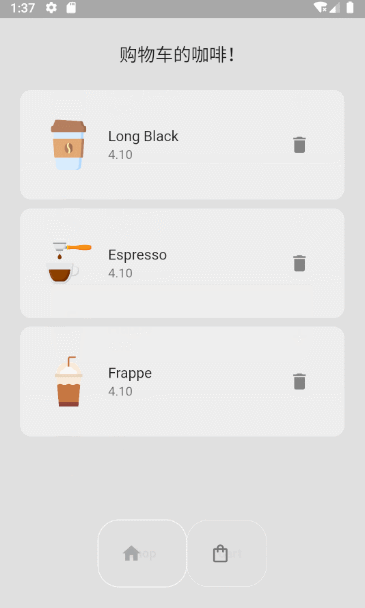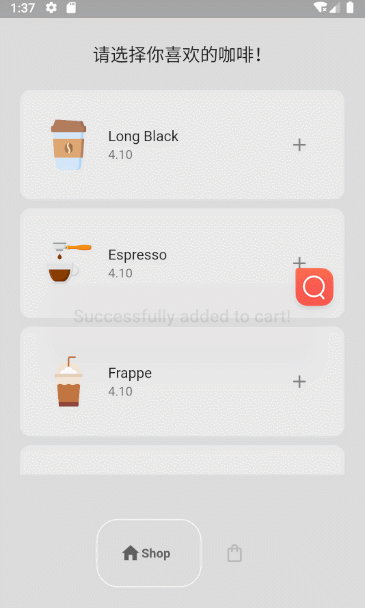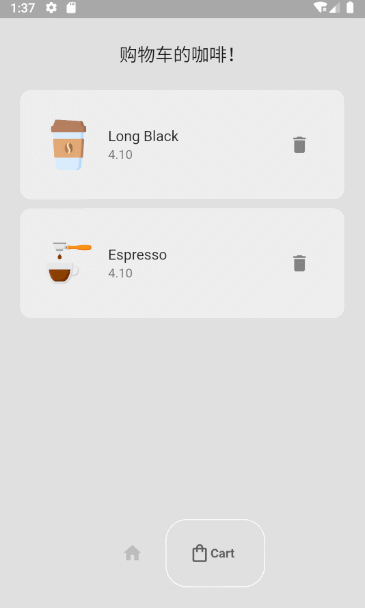
Flutter小功能实现-咖啡店
1 导航栏实现 效果图: 1.Package google_nav_bar: ^5.0.6 使用文档: google_nav_bar | Flutter Package 2.Code //MyBottomNavBar class MyBottomNavBar extends StatelessWidget {void Function(int)? onTabChange;MyBottomNavBar({super.key, …...

JavaSE 集合框架及背后的数据结构
目录 1 介绍2 学习的意义2.1 Java 集合框架的优点及作用2.2 笔试及面试题 3 接口 interfaces3.1 基本关系说明3.2 Collection 常用方法说明3.3 Collection 示例3.4 Map 常用方法说明3.5 Map 示例 4 实现 classes5 Java数据结构知识体系5.1 目标5.2 知识点 1 介绍 集合…...

-9501 MAL系统没有配置或者服务器不是企业版(dm8达梦数据库)
dm8达梦数据库 -9501 MAL系统没有配置或者服务器不是企业版) 环境介绍1 环境检查2 问题原因 环境介绍 搭建主备集群时,遇到报错-9501 MAL系统没有配置或者服务器不是企业版 1 环境检查 检查dmmal.ini配置文件权限正确 dmdba:dinstall,内容正…...

云备份——第三方库简单介绍并使用(上)
目录 一,Jsoncpp库序列化和反序列化 二,bundle文件压缩库 2.1 文件压缩 2.2 文件解压 一,Jsoncpp库序列化和反序列化 首先我们需要先了解一下json是什么,json是一种数据交换格式,采用完全独立于编程语言的文本格式来…...
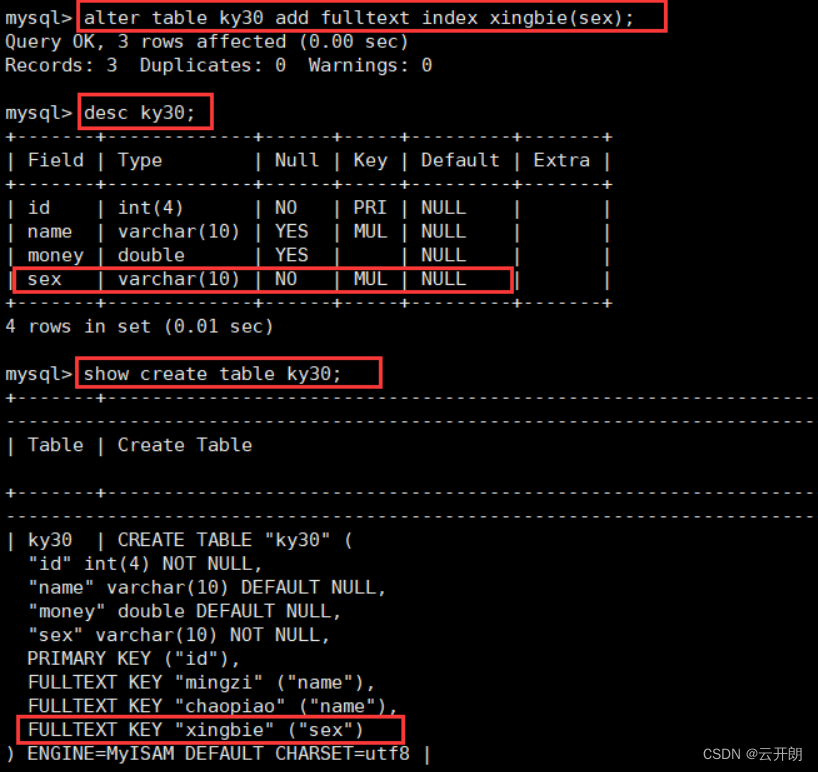
MySQL数据库之索引
目录 一、索引的概念 二、索引的作用 三、索引的副作用 四、创建索引的规则 1、适合创建为索引的字段的规则 2、MySQL的优化 哪些字段/场景适合创建索引,哪些不适合 五、索引的分类和创建 1、索引的分类 2、三种创建方式 3、索引的创建演示 1、创建普通索…...
:Mat支持的运算)
OpenCV(四):Mat支持的运算
目录 1.对两个 Mat 对象按元素进行运算,有加法、减法、乘法和除法等运算。 2.Mat类支持逻辑与、或、非等逻辑运算, 1.对两个 Mat 对象按元素进行运算,有加法、减法、乘法和除法等运算。 加法:Mat Mat,保存到 resul…...
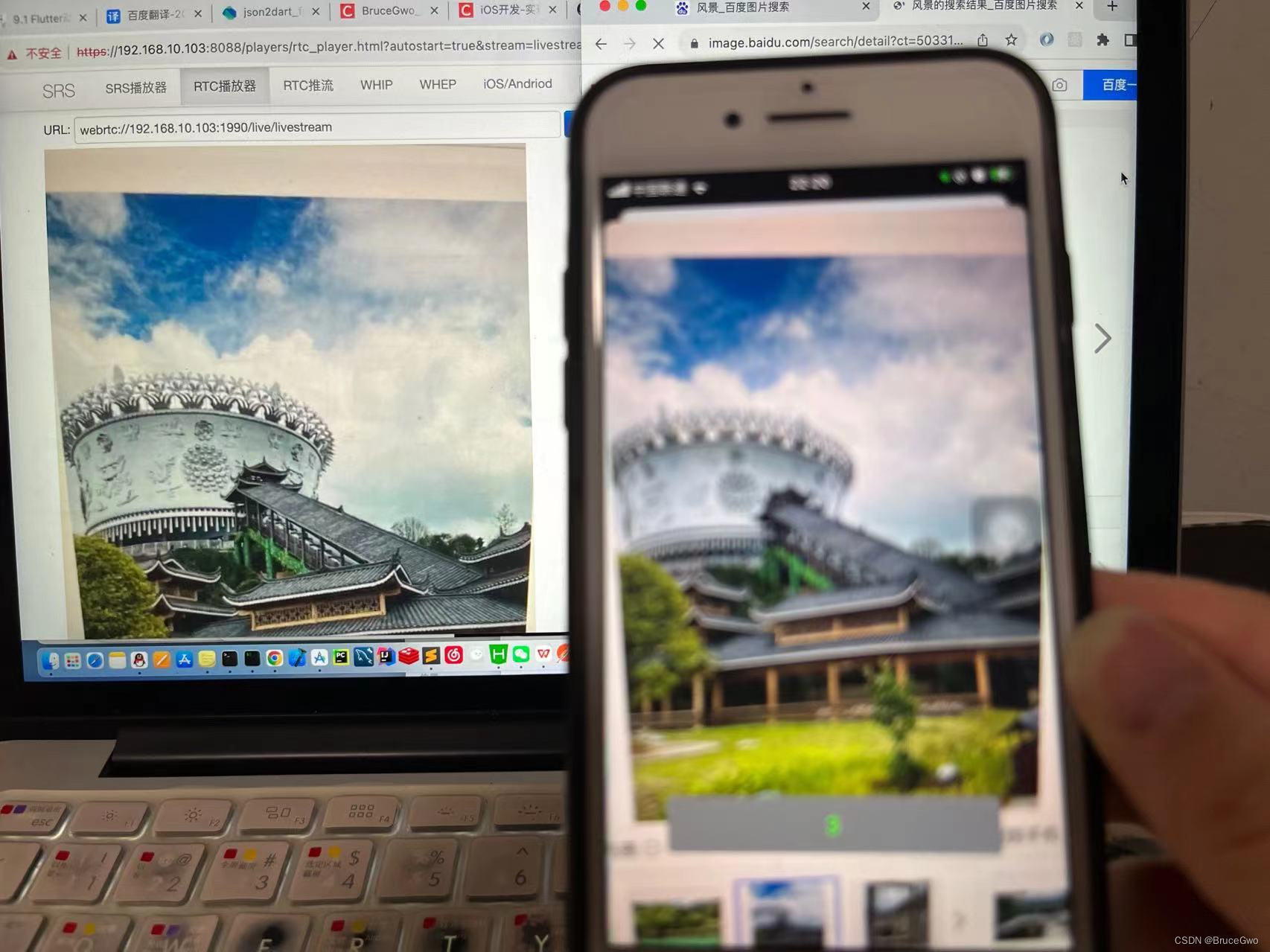
WebRTC音视频通话-WebRTC推拉流过程中日志log输出
WebRTC音视频通话-WebRTC推拉流过程中日志log输出 之前实现iOS端调用ossrs服务实现推拉流流程。 推流:https://blog.csdn.net/gloryFlow/article/details/132262724 拉流:https://blog.csdn.net/gloryFlow/article/details/132417602 在推拉流过程中的…...

用Jmeter压测问题解决
最近做一个基于duboo服务的接口,需要进行稳定性测试。但是用Jmeter GUI 方式跑只能持续2个小时左右,Jmeter就崩溃了,日志报错:out of memory 解决方法如下: 直接运行jmeter的java包试试: 1、打开jmeter.…...

C语言:字符函数和字符串函数(一篇拿捏字符串函数!)
目录 求字符串长度: 1. strlen(字符串长度) 长度不受限制函数: 2. strcpy(字符串拷贝) 3. strcat(字符串追加) 4. strcmp(字符串比较) 长度受限制函数: 5. strncpy(字符串拷贝) 6. strncat(字符串追加) 7. strncmp(字符串比较) 字…...

问道管理:成交量买卖公式?
跟着股票商场的如火如荼,人们对于怎么解读和使用成交量进行股票生意的需求日积月累。成交量是指在某一特定时间内进行的股票生意的数量,它是投资者们研判商场状况和制定生意战略的重要指标之一。那么,是否存在一种最厉害的成交量生意公式呢&a…...

【MySQL】5、MySQL高阶语句
一、常用查询(增、删、改、查) 对 MySQL 数据库的查询,除了基本的查询外,有时候需要对查询的结果集进行处理。 例如只取 10 条数据、对查询结果进行排序或分组等等 模板表: 数据库有一张info表,记录了学生…...

终极AI评估指南:用DeepEval开源框架轻松保障你的大语言模型质量
终极AI评估指南:用DeepEval开源框架轻松保障你的大语言模型质量 【免费下载链接】deepeval The LLM Evaluation Framework 项目地址: https://gitcode.com/GitHub_Trending/de/deepeval 你是否曾担心AI助手给出错误的医疗建议?是否焦虑金融AI客服…...

ElevenLabs台湾话语音上线后用户留存率骤降47%?揭秘方言语料清洗盲区与3步合规性校验法
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs台湾话语音上线后用户留存率骤降47%?揭秘方言语料清洗盲区与3步合规性校验法 ElevenLabs于2024年Q2正式上线台湾话(闽南语)语音合成服务,初期D…...

3步掌握Jellyfin智能字幕插件:新手快速上手指南
3步掌握Jellyfin智能字幕插件:新手快速上手指南 【免费下载链接】jellyfin-plugin-maxsubtitle 一个 Jellyfin 中文字幕插件(未来可以不局限中文) 项目地址: https://gitcode.com/gh_mirrors/je/jellyfin-plugin-maxsubtitle MaxSubti…...

如何将企业微信 RPA 抽象为高可用的外部群自动化 API?
在做企业微信外部群(如跨群互动、自动化精准群发、批量建群)的自动化能力时,业界通常面临两种选型:一种是直接攻克底层协议,但面临极高的安全风控与多变协议的维护成本;另一种是基于 RPA(机器人…...
)
苹果手机快速开启开发者模式教程(iOS 16+)
在Mac Xcode 给 iPhone 安装自签 IPA、做苹果 App 打包测试时,iOS 16 及以上的系统第一次启动这类"非 App Store 来源"的 App,都会弹一个 “需要启用开发者模式” 的提示,点"好"就退出了,App 根本进不去。 这是苹果从 iOS 16 开始加的安全限制:任何用开发…...
)
用C#手搓ABB IRB 2600机器人正逆运动学(附完整代码与避坑指南)
从零实现ABB IRB 2600机器人运动学:C#实战与工业级代码优化 在工业机器人编程领域,能够将教科书上的数学公式转化为可靠的生产线代码是一项核心技能。ABB IRB 2600作为经典的六轴工业机器人,其运动学实现过程中存在诸多教科书不会提及的工程细…...

三星固件下载全攻略:Bifrost跨平台工具的快速上手指南
三星固件下载全攻略:Bifrost跨平台工具的快速上手指南 【免费下载链接】Bifrost Cross-platform tool for downloading Samsung mobile device firmware. 项目地址: https://gitcode.com/gh_mirrors/sa/Bifrost 还在为三星设备刷机找不到官方固件而烦恼吗&am…...

如何通过本地解析技术彻底解决九大网盘下载限速问题
如何通过本地解析技术彻底解决九大网盘下载限速问题 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼云盘 / 迅雷云…...
 2026)
渝中区宜居、 韧性、智慧城市建设“十五五”规划(征求意见稿) 2026
这份《渝中区宜居、韧性、智慧城市建设 “十五五” 规划(征求意见稿)》,立足渝中区 “重庆母城、都市极核、品质半岛、首善之区” 定位,总结 “十四五” 成效、分析机遇挑战,明确 2026—2030 年总体目标、核心任务与保…...

MCP协议技术架构深度解析:构建AI工具生态系统的标准化方案
MCP协议技术架构深度解析:构建AI工具生态系统的标准化方案 【免费下载链接】Awesome-MCP-ZH MCP 资源精选, MCP指南,Claude MCP,MCP Servers, MCP Clients 项目地址: https://gitcode.com/gh_mirrors/aw/Awesome-MCP-ZH MC…...