特征工程:特征构造以及时间序列特征构造
数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。由此可见,特征工程在机器学习中占有相当重要的地位。在实际应用当中,可以说特征工程是机器学习成功的关键。
那特征工程是什么?
特征工程是利用数据领域的相关知识来创建能够使机器学习算法达到最佳性能的特征的过程。
特征工程又包含了 Data PreProcessing(数据预处理)、Feature Extraction(特征提取)、Feature Selection(特征选择)和 Feature construction(特征构造)等子问题,本章内容主要讨论特征构造的方法。
技术提升
技术要学会分享、交流,不建议闭门造车。一个人走的很快、一堆人可以走的更远。
好的技术文章离不开粉丝的分享、推荐,资料干货、资料分享、数据、技术交流提升,均可加交流群获取,群友已超过2000人,添加时切记的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、添加微信号:pythoner666,备注:来自 CSDN + python
方式②、微信搜索公众号:Python学习与数据挖掘,后台回复:加群
特征构造介绍
时间特构造以及时间序列特征构造的具体方法:

时间特征构造
对于时间型数据来说,即可以把它转换成连续值,也可以转换成离散值。
1.连续值时间特征
-
持续时间(单页浏览时长);
-
间隔时间;
-
上次购买/点击离现在的时长;
-
产品上线到现在经过的时长;
2.离散值时间特征
1)时间特征拆解
-
年;
-
月;
-
日;
-
时;
-
分;
-
数;
-
一天中的第几分钟;
-
星期几;
-
一年中的第几天;
-
一年中的第几个周;
-
一天中哪个时间段:凌晨、早晨、上午、中午、下午、傍晚、晚上、深夜;
-
一年中的哪个季度;
程序实现
import pandas as pd
# 构造时间数据
date_time_str_list = ['2019-01-01 01:22:26', '2019-02-02 04:34:52', '2019-03-03 06:16:40','2019-04-04 08:11:38', '2019-05-05 10:52:39', '2019-06-06 12:06:25','2019-07-07 14:05:25', '2019-08-08 16:51:33', '2019-09-09 18:28:28','2019-10-10 20:55:12', '2019-11-11 22:55:12', '2019-12-12 00:55:12',
]
df = pd.DataFrame({'时间': date_time_str_list})
# 把字符串格式的时间转换成Timestamp格式
df['时间'] = df['时间'].apply(lambda x: pd.Timestamp(x))# 年份
df['年']=df['时间'].apply(lambda x: x.year)# 月份
df['月']=df['时间'].apply(lambda x: x.month)# 日
df['日']=df['时间'].apply(lambda x: x.day)# 小时
df['时']=df['时间'].apply(lambda x: x.hour)# 分钟
df['分']=df['时间'].apply(lambda x: x.minute)# 秒数
df['秒']=df['时间'].apply(lambda x: x.second)# 一天中的第几分钟
df['一天中的第几分钟']=df['时间'].apply(lambda x: x.minute + x.hour*60)# 星期几;
df['星期几']=df['时间'].apply(lambda x: x.dayofweek)# 一年中的第几天
df['一年中的第几天']=df['时间'].apply(lambda x: x.dayofyear)# 一年中的第几周
df['一年中的第几周']=df['时间'].apply(lambda x: x.week)# 一天中哪个时间段:凌晨、早晨、上午、中午、下午、傍晚、晚上、深夜;
period_dict ={23: '深夜', 0: '深夜', 1: '深夜',2: '凌晨', 3: '凌晨', 4: '凌晨',5: '早晨', 6: '早晨', 7: '早晨',8: '上午', 9: '上午', 10: '上午', 11: '上午',12: '中午', 13: '中午',14: '下午', 15: '下午', 16: '下午', 17: '下午',18: '傍晚',19: '晚上', 20: '晚上', 21: '晚上', 22: '晚上',
}
df['时间段']=df['时'].map(period_dict)# 一年中的哪个季度
season_dict = {1: '春季', 2: '春季', 3: '春季',4: '夏季', 5: '夏季', 6: '夏季',7: '秋季', 8: '秋季', 9: '秋季',10: '冬季', 11: '冬季', 12: '冬季',
}
df['季节']=df['月'].map(season_dict)

2)时间特征判断
-
是否闰年;
-
是否月初;
-
是否月末;
-
是否季节初;
-
是否季节末;
-
是否年初;
-
是否年尾;
-
是否周末;
-
是否公共假期;
-
是否营业时间;
-
两个时间间隔之间是否包含节假日/特殊日期;
程序实现
import pandas as pd
# 构造时间数据
date_time_str_list = ['2010-01-01 01:22:26', '2011-02-03 04:34:52', '2012-03-05 06:16:40','2013-04-07 08:11:38', '2014-05-09 10:52:39', '2015-06-11 12:06:25','2016-07-13 14:05:25', '2017-08-15 16:51:33', '2018-09-17 18:28:28','2019-10-07 20:55:12', '2020-11-23 22:55:12', '2021-12-25 00:55:12','2022-12-27 02:55:12', '2023-12-29 03:55:12', '2024-12-31 05:55:12',
]
df = pd.DataFrame({'时间': date_time_str_list})
# 把字符串格式的时间转换成Timestamp格式
df['时间'] = df['时间'].apply(lambda x: pd.Timestamp(x))# 是否闰年
df['是否闰年'] = df['时间'].apply(lambda x: x.is_leap_year)# 是否月初
df['是否月初'] = df['时间'].apply(lambda x: x.is_month_start)# 是否月末
df['是否月末'] = df['时间'].apply(lambda x: x.is_month_end)# 是否季节初
df['是否季节初'] = df['时间'].apply(lambda x: x.is_quarter_start)# 是否季节末
df['是否季节末'] = df['时间'].apply(lambda x: x.is_quarter_end)# 是否年初
df['是否年初'] = df['时间'].apply(lambda x: x.is_year_start)# 是否年尾
df['是否年尾'] = df['时间'].apply(lambda x: x.is_year_end)# 是否周末
df['是否周末'] = df['时间'].apply(lambda x: True if x.dayofweek in [5, 6] else False)# 是否公共假期
public_vacation_list = ['20190101', '20190102', '20190204', '20190205', '20190206','20190207', '20190208', '20190209', '20190210', '20190405','20190406', '20190407', '20190501', '20190502', '20190503','20190504', '20190607', '20190608', '20190609', '20190913','20190914', '20190915', '20191001', '20191002', '20191003','20191004', '20191005', '20191006', '20191007',
] # 此处未罗列所有公共假期
df['日期'] = df['时间'].apply(lambda x: x.strftime('%Y%m%d'))
df['是否公共假期'] = df['日期'].apply(lambda x: True if x in public_vacation_list else False)# 是否营业时间
df['是否营业时间'] = False
df['小时']=df['时间'].apply(lambda x: x.hour)
df.loc[((df['小时'] >= 8) & (df['小时'] < 22)), '是否营业时间'] = Truedf.drop(['日期', '小时'], axis=1, inplace=True)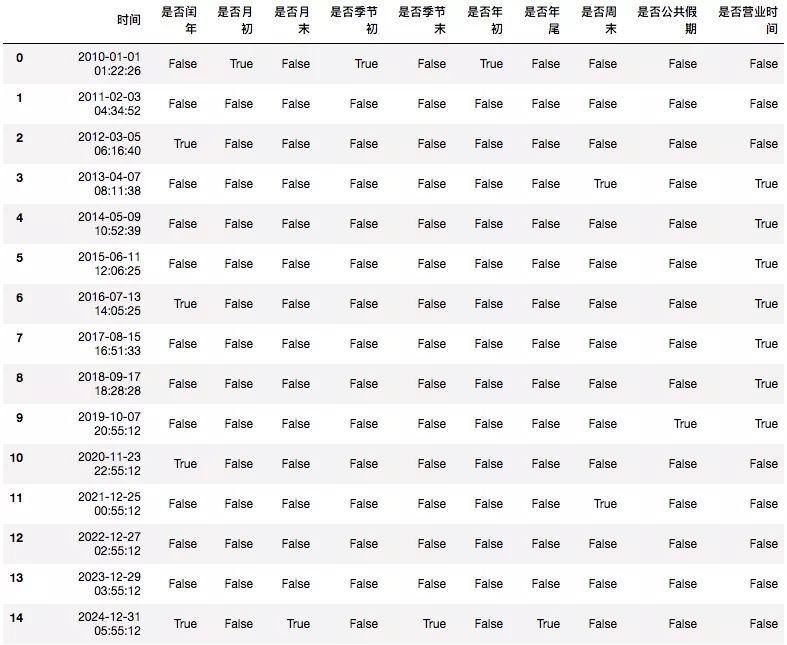
3.结合时间维度的聚合特征
具体就是指结合时间维度来进行聚合特征构造,聚合特征构造的具体方法可以参考《聚合特征构造以及转换特征构造》中的《聚合特征构造》章节。
1)首日聚合特征
例如:注册首日投资总金额、注册首日页面访问时长、注册首日总点击次数等;
2)最近时间聚合特征
例如:最近N天APP登录天数、最近一个月的购买金额、最近购物至今天数等;
3)区间内的聚合特征
例如:2018年至2019年的总购买金额、每天下午的平均客流量、在某公司工作期间加班的天数等;
时间序列特征构造
时间序列不仅包含一维时间变量,还有一维其他变量,如股票价格、天气温度、降雨量、订单量等。时间序列分析的主要目的是基于历史数据来预测未来信息。对于时间序列,我们关心的是长期的变动趋势、周期性的变动(如季节性变动)以及不规则的变动。
按固定时间长度把时间序列划分成多个时间窗,然后构造每个时间窗的特征。
1.时间序列聚合特征
按固定时间长度把时间序列划分成多个时间窗,然后使用聚合操作构造每个时间窗的特征。
1)平均值
例子:历史销售量平均值、最近N天销售量平均值。
2)最小值
例子:历史销售量最小值、最近N天销售量最小值。
3)最大值
例子:历史销售量最大值、最近N天销售量最大值。
4)扩散值
分布的扩散性,如标准差、平均绝对偏差或四分位差,可以反映测量的整体变化趋势。
5)离散系数值
离散系数是策略数据离散程度的相对统计量,主要用于比较不同样本数据的离散程度。
6)分布性
时间序列测量的边缘分布的高阶特效估计(如偏态系数或峰态系数),或者更进一步对命名分布进行统计测试(如标准或统一性),在某些情况下比较有预测力。
程序实现:洗发水销售数据
import pandas as pd
# 加载洗发水销售数据集
df = pd.read_csv('shampoo-sales.csv')
df.dropna(inplace=True)
df.rename(columns={'Sales of shampoo over a three year period': 'value'}, inplace=True)# 平均值
mean_v = df['value'].mean()
print('mean: {}'.format(mean_v))# 最小值
min_v = df['value'].min()
print('min: {}'.format(min_v))# 最大值
max_v = df['value'].max()
print('max: {}'.format(max_v))# 扩散值:标准差
std_v = df['value'].std()
print('std: {}'.format(std_v))# 扩散值:平均绝对偏差
mad_v = df['value'].mad()
print('mad: {}'.format(mad_v))# 扩散值:四分位差
q1 = df['value'].quantile(q=0.25)
q3 = df['value'].quantile(q=0.75)
irq = q3 - q1
print('q1={}, q3={}, irq={}'.format(q1, q3, irq))# 离散系数
variation_v = std_v/mean_v
print('variation: {}'.format(variation_v))# 分布性:偏态系数
skew_v = df['value'].skew()
print('skew: {}'.format(skew_v))
# 分布性:峰态系数
kurt_v = df['value'].kurt()
print('kurt: {}'.format(kurt_v))# 输出:
mean: 312.59999999999997
min: 119.3
max: 682.0
std: 148.93716412347473
mad: 119.66666666666667
q1=192.45000000000002, q3=411.1, irq=218.65
variation: 0.47644646232717447
skew: 0.8945388528534595
kurt: 0.11622821118738624
注:
-
上面是单个时间序列的实现代码,多个时间序列的数据集构造特征时需要先进行分组再计算。如IJCAI-17口碑商家客流量预测比赛中,数据集中包含多个商家的历史销售数据,构造特征时需要先按商家分组,然后再构建特征。
-
上述代码都是使用所有历史数据来构造特征,实际项目中如果待预测目标为t时刻的值,则使用t时刻之前的值来构造特征,不同的t值都可以分别构造训练样本对应的特征。 如:使用t时刻的y值作为label,则使用t-1时刻之前的y值来构造特征;使用t-1时刻的y值作为label时,则使用t-2时刻之前的y值来构造特征。如此类推,我们可以得到多个训练样本,每个样本有多个特征。
2.时间序列历史特征
1)前一(或n)个窗口的取值
例子:昨天、前天和3天前的销售量。
2)周期性时间序列前一(或n)周期的前一(或n)个窗口的取值
例子:写字楼楼下的快餐店的销售量一般具有周期性,周期长度为7天,7天前和14天前的销售量。
程序实现:洗发水销售数据
import pandas as pd
# 加载洗发水销售数据集
df = pd.read_csv('shampoo-sales.csv')
df.dropna(inplace=True)
df.rename(columns={'Sales of shampoo over a three year period': 'value'}, inplace=True)df['-1day'] = df['value'].shift(1)
df['-2day'] = df['value'].shift(2)
df['-3day'] = df['value'].shift(3)df['-1period'] = df['value'].shift(1*12)
df['-2period'] = df['value'].shift(2*12)display(df.head(60))

3.时间序列复合特征
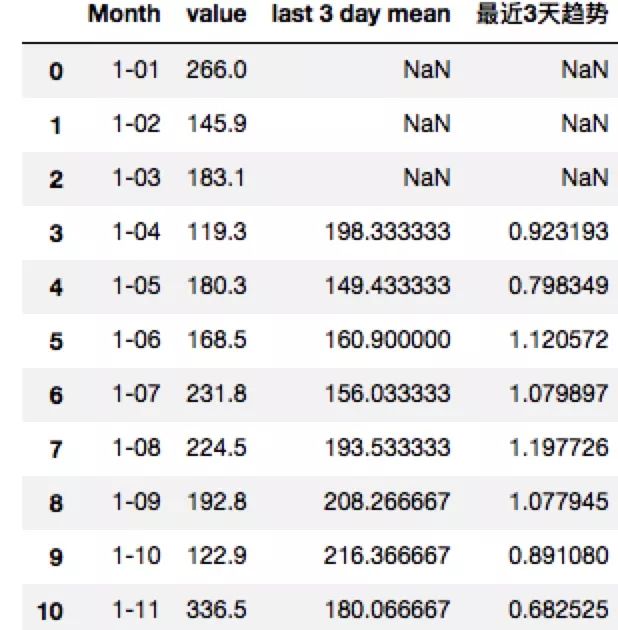
1)趋势特征
趋势特征可以刻画时间序列的变化趋势。
例子:每个用户每天对某个Item行为次数的时间序列中,User一天对Item的行为次数/User三天对Item的行为次数的均值,表示短期User对Item的热度趋势,大于1表示活跃逐渐在提高;三天User对Item的行为次数的均值/七天User对Item的行为次数的均值表示中期User对Item的活跃度的变化情况;七天User对Item的行为次数的均值/ 两周User对Item的行为次数的均值表示“长期”(相对)User对Item的活跃度的变化情况。
程序实现:
import pandas as pd
# 加载洗发水销售数据集
df = pd.read_csv('shampoo-sales.csv')
df.dropna(inplace=True)
df.rename(columns={'Sales of shampoo over a three year period': 'value'}, inplace=True)df['last 3 day mean'] = (df['value'].shift(1) + df['value'].shift(2) + df['value'].shift(3))/3
df['最近3天趋势'] = df['value'].shift(1)/df['last 3 day mean']
display(df.head(60))
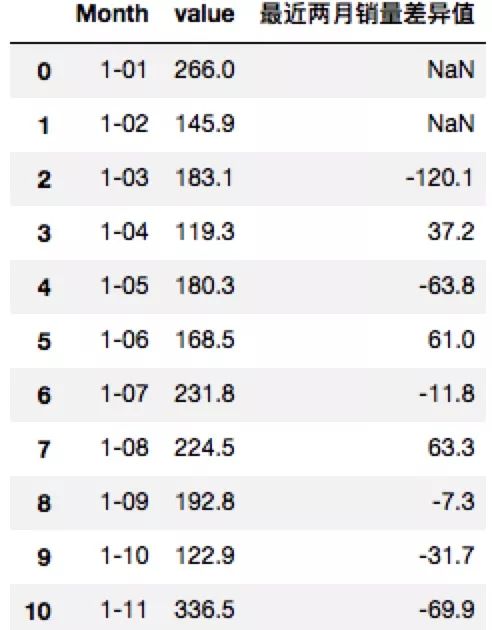
2)窗口差异值特征
一个窗口到下一个窗口的差异。例子:商店销售量时间序列中,昨天的销售量与前天销售量的差值。
程序实现:
import pandas as pd
# 加载洗发水销售数据集
df = pd.read_csv('shampoo-sales.csv')
df.dropna(inplace=True)
df.rename(columns={'Sales of shampoo over a three year period': 'value'}, inplace=True)df['最近两月销量差异值'] = df['value'].shift(1) - df['value'].shift(2)
display(df.head(60))
3)自相关性特征
原时间序列与自身左移一个时间空格(没有重叠的部分被移除)的时间序列相关联。
程序实现:
import statsmodels.tsa.api as smt
import pandas as pd
# 加载洗发水销售数据集
df = pd.read_csv('shampoo-sales.csv')
df.dropna(inplace=True)
df.rename(columns={'Sales of shampoo over a three year period': 'value'}, inplace=True)print('滞后数为1的自相关系数:{}'.format(df['value'].autocorr(1)))
print('滞后数为2的自相关系数:{}'.format(df['value'].autocorr(2)))
# 输出:
滞后数为1的自相关系数:0.7194822398024308
滞后数为2的自相关系数:0.8507433352850972
除了上面描述的特征外,时间序列还有历史波动率、瞬间波动率、隐含波动率、偏度、峰度、瞬时相关性等特征。
总结
1.时间特征主要有两大类:
1)从时间变量提取出来的特征
- 如果每条数据为一条训练样本,时间变量提取出来的特征可以直接作为训练样本的特征使用。
例子:用户注册时间变量。对于每个用户来说只有一条记录,提取出来的特征可以直接作为训练样本的特征使用,不需要进行二次加工。
- 如果每条数据不是一条训练样本,时间变量提取出来的特征需要进行二次加工(聚合操作)才能作为训练样本的特征使用。
例子:用户交易流水数据中的交易时间。由于每个用户的交易流水数量不一样,从而导致交易时间提取出来的特征的数据不一致,所以这些特征不能直接作为训练样本的特征来使用。我们需要进一步进行聚合操作才能使用,如先从交易时间提取出交易小时数,然后再统计每个用户在每个小时(1-24小时)的交易次数来作为最终输出的特征。
2)对时间变量进行条件过滤,然后再对其他变量进行聚合操作所产生的特征
主要是针对类似交易流水这样的数据,从用户角度进行建模时,每个用户都有不定数量的数据,因此需要对数据进行聚合操作来为每个用户构造训练特征。而包含时间的数据,可以先使用时间进行条件过滤,过滤后再构造聚合特征。
2. 时间序列数据可以从带有时间的流水数据统计得到,实际应用中可以分别从带有时间的流水数据以及时间序列数据中构造特征,这些特征可以同时作为模型输入特征。
例如:美团的商家销售量预测中,每个商家的交易流水经过加工后可以得到每个商家每天的销售量,这个就是时间序列数据。
参考文献
[1] https://machinelearning-notes.readthedocs.io/zh_CN/latest/feature/%E7%89%B9%E5%BE%81%E5%B7%A5%E7%A8%8B%E2%80%94%E2%80%94%E6%97%B6%E9%97%B4.html
[2] https://www.cnblogs.com/nxf-rabbit75/p/11141944.html#_nav_12
[3] https://gplearn.readthedocs.io/en/stable/examples.html#symbolic-classifier
[4] 利用 gplearn 进行特征工程. https://bigquant.com/community/t/topic/120709
[5] Practical Lessons from Predicting Clicks on Ads at Facebook. https://pdfs.semanticscholar.org/daf9/ed5dc6c6bad5367d7fd8561527da30e9b8dd.pdf
[6] Feature Tools:可自动构造机器学习特征的Python库. https://www.jiqizhixin.com/articles/2018-06-21-2
[7] 各种聚类算法的系统介绍和比较. https://blog.csdn.net/abc200941410128/article/details/78541273
相关文章:
特征工程:特征构造以及时间序列特征构造
数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。由此可见,特征工程在机器学习中占有相当重要的地位。在实际应用当中,可以说特征工程是机器学习成功的关键。 那特征工程是什么? 特征工程是利用数据领域的相关…...

单master部署简要步骤
准备多台服务器,选定一台为master例如设置ip为192.168.0.10,host: k8s.master,其他分别为 k8s.s11 192.168.0.11k8s.s12 192.168.0.12....hostname可以使用命令配置hostname k8s.masterip解析可以在hosts文件中写入,如果有内部dns解析可以在内…...
基础算法 --- 前缀和与差分)
【算法基础】(一)基础算法 --- 前缀和与差分
✨个人主页:bit me ✨当前专栏:算法基础 🔥专栏简介:该专栏主要更新一些基础算法题,有参加蓝桥杯等算法题竞赛或者正在刷题的铁汁们可以关注一下,互相监督打卡学习 🌹 🌹 dz…...

c++提高篇——stack容器
一、stack容器的基本概念 stack是一种先进后出(FILO)的数据结构,它只有一个出口。栈中只有顶端的元素才可以被外界使用。因此该容器不能有遍历行为。基本的结构如下: stack容器有些像手枪子弹的弹夹,其数据的出入栈可以以弹夹为参考。 二、…...

HTTP安全与HTTPS协议
目录 Http协议的安全问题 常见的加密方式 防止窃听 单向散列函数 单向散列值的特点 加密与解密 对称加密与非对称加密 对称加密的密钥配送问题 密钥配送问题的解决 非对称加密 前言: 公钥与私钥 非对称加密过程 混合密码系统 前言: 混合…...

【c++】类和对象4—c++对象模型和this指针
文章目录成员变量和成员函数分开存储this指针的用途空指针访问成员函数const修饰成员函数成员变量和成员函数分开存储 在c中,类内的成员变量和成员函数分开存储 只有非静态成员变量才属于类的对象上 #include<iostream> using namespace std;class Person1…...
嵌入式Qt 开发一个视频播放器
上篇文章:嵌入式 Qt开发一个音乐播放器,使用Qt制作了一个音乐播放器,并在OK3568开发板上进行了运行测试,实际测试效果还不错。 本篇继续来实现一个Qt视频播放器软件,可以实现视频列表的显示与选择播放等,先…...

阿里巴巴内网 Spring Cloud Alibaba 强势来袭,开创微服务的新时代
Spring Cloud 发展史 Spring Cloud 从 15 年的 3 月份推出之后,迅速在 Java 微服务生态中,成为开发人员的首选技术栈。 Spring Cloud 在 Spring Boot 的基础上,保留 Java 开发习惯,加入分布式特性,提供了一系列通用工…...
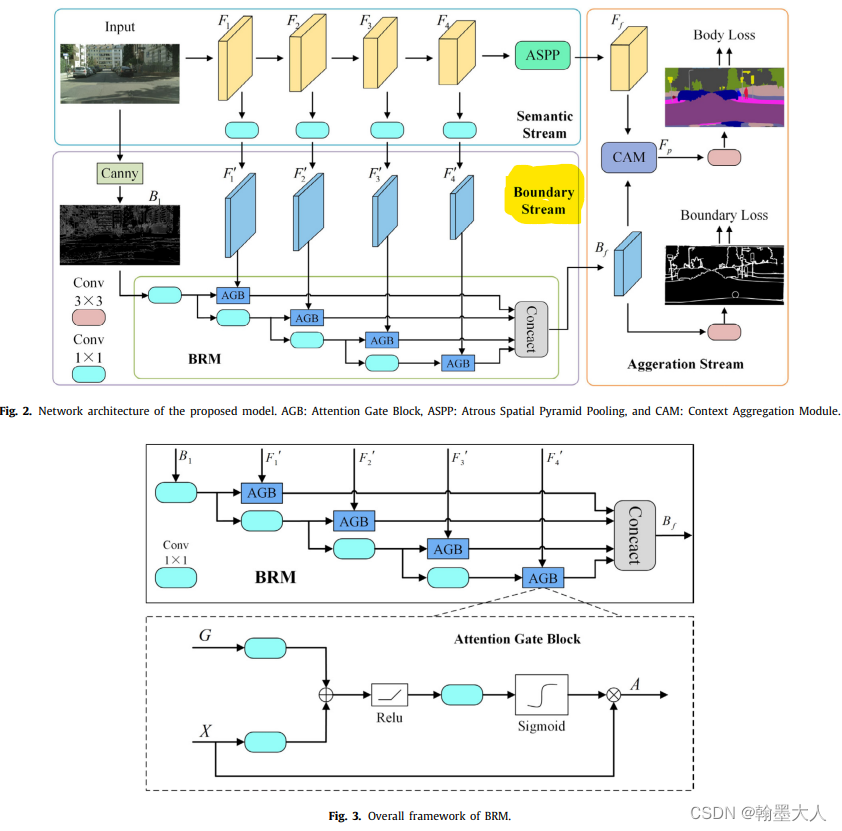
边界检测方法总结
1:经典的边界检测方法有sobel,拉普拉斯,canny等。 sobel: def get_sobel(in_chan, out_chan):filter_x np.array([[1, 0, -1],[2, 0, -2],[1, 0, -1],]).astype(np.float32)filter_y np.array([[1, 2, 1],[0, 0, 0],[-1, -2, -…...

Softing dataFEED OPC Suite Extended新版本支持从XML文件中读取生产数据
Softing dataFEED OPC Suite Extended V5.25的新功能——“文件读取(File Read)”,支持访问XML文件中可用的过程数据。 (文件读取功能支持获取由XML文件提供的过程数据)dataFEED OPC Suite Extended是用于OPC通信和云连…...
央行罚单!金融机构被罚原因揭秘
近日,人民银行公布了2023年首批行政处罚罚单,引发业内广泛关注。 顶象防御云业务安全情报中心统计了人民银行官网,2020年1月至2023年2月10日期间,公布的101份行政处罚。 统计显示,16家金融机构被罚27066.9万元&#…...

js中var、let、const详解
首先 var、let、const 在项目开发中都是用来声明变量的,在ES5中只有两种声明变量的方法:var和function,在ES6中新增了 let、const、class、import 四种声明变量的方法,本文主要讲解 var、let 与 const 的语法,其他的大…...
,真的很详细,一篇文章你就会了)
【数据库】MySQL概念知识语法-基础篇(DCL),真的很详细,一篇文章你就会了
目录通用语法及分类DCL(数据控制语言)管理用户查询用户权限控制函数字符串函数数值函数日期函数流程函数约束外键约束多表查询一对多多对多一对一通用语法及分类 ● DDL: 数据定义语言,用来定义数据库对象(数据库、表、字段&…...
Blender骨骼动画快速教程
有关创建模型的更多详细信息,请参阅在 Blender 中创建模型。 我们将为这个例子做一个非常简单的模型——蠕虫! 从我们的初始立方体开始,进入编辑模式,切换到面选择,然后选择任何面: 推荐:将 NSD…...
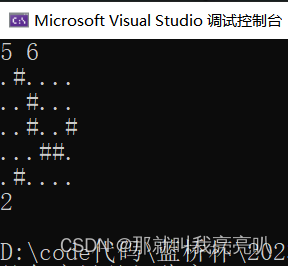
【C++算法】dfs深度优先搜索(下) ——【全面深度剖析+经典例题展示】
💃🏼 本人简介:男 👶🏼 年龄:18 🤞 作者:那就叫我亮亮叭 📕 专栏:关于C/C那点破事 文章目录0.0 写在前面1. 中国象棋1.1 题干信息① 背景说明概述② 问题描述…...
HIVE 基础(三)
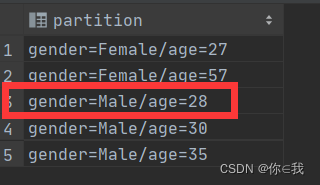
目录 建表语句 表数据 Hive建表高阶语句 - CTAS and WITH CTAS – as select方式建表 CTE (CTAS with Common Table Expression) LIKE 创建临时表 清空表数据 修改表(Alter针对元数据) 改名 修正表文件格式 修改列名 添加列 替换列 动态分…...

redis-cluster集群搭建
安装redis所需环境 yum install -y gcc-c yum install -y wget 创建文件夹 cd / mkdir redis/redis-cluster/7001 cd redis/redis-cluster mkdir 7002 7003 7004 7005 7006 7007 7008下载redis压缩包并解压安装 wget https://download.redis.io/redis-stable.tar.gz tar -…...

【C语言】可变参数列表va_list
本篇博客让我们来认识一下C语言学习过程中往往被忽略的可变参数列表 所谓可变参数,就是一个不限定参数数量的函数,我们可以往里面传入任意个数的参数,以达成某些目的。 关联:C11可变模板参数 1.函数 #include <stdarg.h>…...
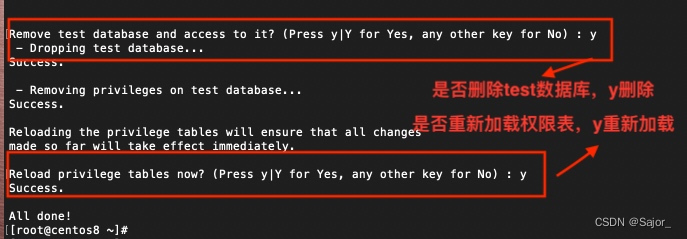
CentOS7.6 MySQL8安装
1 检查是否安装过 MySQL rpm -qa | grep -i mysqlmariadb rpm -qa | grep mariadb2 卸载之前的安装 MySQL rpm -e --nodeps 软件名 //强力删除,对相关依赖的文件也进行强力删除卸载 rpm -e --nodeps mariadb-libs-5.5.60-1.el7_5.x86_643 官网下载 MySQL :: D…...

安装Tomcat的步骤?
首先先完成JDK配置,javac -version 检测 1.把tomcat下载到本地硬盘 2.创建tomcat8.0文件夹,完成解压(免安装)4.打开解压之后的目录,进入bin目录,双击startup.bat,启动tomcat5.可以看到弹出一个黑色的窗口,不要关闭,如果关闭意味着…...

硬件答辩问题总结
一、电源纹波是什么,为什么LDO的小,DCDC的大1.电源纹波电源纹波 是指直流电源输出电压上叠加的 交流波动成分,表现为电压在理想直流值附近上下波动。2.LDO 纹波小原理LDO 内部是一个 调整管(可变电阻) 串联在输入和输出…...

亚马逊 Rufus 关停,Alexa 正式上线:卖家必须读懂的6条新规则
2026年5月13日,亚马逊官方正式宣布,下线Rufus,推出全新AI购物助手:Alexa for Shopping。但是,这不是粗暴地直接下线 Rufus,而是一次购物AI底层架构的重组 —— 将 Rufus 的商品专长 与 Alexa的用户理解力&a…...

Veo 2胶片质感生成器失效?——深度解析Color Science v2.3内核中被屏蔽的Cinematic Grain Injection层
更多请点击: https://kaifayun.com 第一章:Veo 2胶片质感生成器失效现象全景透视 近期大量用户反馈,Veo 2 胶片质感生成器在调用 generate_film_effect() 接口后返回空纹理、纯灰帧或 HTTP 503 Service Unavailable 错误,且该问题…...

全链路压测实战:双十一级别的流量,我是这样扛住的
作为一名在质量保障领域摸爬滚打多年的测试工程师,我深知传统的单接口压测在如今分布式架构下的无力感。当业务流量达到双十一这种脉冲式、高并发的级别时,任何一个非核心链路上的“短板”都可能引发系统性的雪崩。全链路压测不再是选择题,而…...

WPF虚拟桌宠组件:可嵌入、高性能、工程化UI生命体
1. 这不是“桌面宠物”,而是一个可嵌入的WPF UI组件化生命体你可能在Windows XP时代见过那只晃着尾巴、偶尔打哈欠的3D小猫,也可能在Win10系统托盘里点开过一个会眨眼的像素狐狸——但那些是独立进程、是系统级小工具、是“看一眼就关掉”的轻量娱乐。而…...

基于ESP32的AIS转WiFi转换器:实现NMEA 0183数据无线传输
1. 项目概述:从VHF-AIS接收器到iPad的无线桥梁作为一名经常在海上折腾电子设备的航海爱好者,我最近遇到了一个挺实际的需求:我的主力导航设备是iPad上的iSailor应用,它功能强大、界面友好,但有个“硬伤”——它需要通过…...

关于psthon问题
我想问问各位 我python可以查到 但是我的bit文件查不到python怎么回事...

【Lindy营销自动化工作流终极指南】:20年实战验证的7大反脆弱性设计原则,92%企业漏掉的关键衰减阈值
更多请点击: https://intelliparadigm.com 第一章:Lindy营销自动化工作流的基本范式与历史验证 Lindy效应指出,一个事物的预期剩余寿命与其当前年龄成正比——在营销自动化领域,Lindy范式体现为:经时间检验仍被广泛采…...

别再盲调temperature=0.2!DeepSeek补全效果突变的4个隐藏参数,资深架构师压箱底调参清单
更多请点击: https://intelliparadigm.com 第一章:别再盲调temperature0.2!DeepSeek补全效果突变的4个隐藏参数,资深架构师压箱底调参清单 DeepSeek-R1/VL 等开源大模型在实际部署中,仅靠调节 temperature 往往收效甚…...

基于EMA与轻量级机器学习的Wi-Fi链路质量预测实战
1. 项目概述与核心价值在工业自动化、仓储物流和智能制造等场景里,无线网络的稳定性正变得前所未有的重要。想象一下,一个自动导引运输车(AGV)正在执行物料搬运任务,或者一个机械臂正在与中央控制系统进行实时数据同步…...