mysql性能测试工具选择 mysql软件测试
1.理论知识:
1.1 定义
1. 基准测试是一种测量和评估软件性能指标的活动,用于建立某个时刻的性能基准,以便当系统发生软硬件变化时重新进行基准测试以评估变化对性能的影响
2. 基准测试是针对系统设置的一种压力测试,但是和压力测试还是有区别的
基准测试:直接、简单,易于比较,用于评估服务器的处理能力
基准测试:可能不关心业务逻辑,所使用的查询和业务的真实性可以和业务环境没有关系
压力测试:对真实的业务数据进行测试,获得真实系统所能承受的压力
压力测试:需要针对不同的应用场景,所使用的数据和查询也是真实用到的
1.2 测试步骤
选择sysbench为测试工具
1.安装sysbench
1)下载安装包
wget https://github.com/akopytov/sysbench/archive/0.5.zip2)安装依赖工具
apt -y install make automake libtool pkg-config libaio-dev vim-common
# For MySQL support
apt -y install libmysqlclient-dev
# For PostgreSQL support
apt -y install libpq-dev3)编译安装
unzip 0.5.zip
cd sysbench-0.5
./autogen.sh
# Add --with-pgsql to build with PostgreSQL support
./configure
make
make install2. 准备测试
1) 创建测试库
create database sysbenchtest;2) 创建测试用户
grant all privileges on sysbenchtest.* to sysbench@'localhost' identified by '4rfv$RFV';
flush privileges;3) 准备测试数据:构建5张表,每张表10万条数据
sysbench --test=./sysbench/tests/db/oltp.lua --mysql-host=127.0.0.1 --mysql-db=sysbenchtest --mysql-user=sysbench \
--mysql-password='4rfv$RFV' --oltp-test-mode=complex --oltp-tables-count=5 --oltp-table-size=100000 --threads=10 --time=120 \
--rand-init=on --report-interval=10 --mysql-table-engine=innodb prepare* 参数说明
mysql-db=dbtest1a:测试使用的目标数据库,这个库名要事先创建--oltp-tables-count=10:产生表的数量--oltp-table-size=500000:每个表产生的记录行数--oltp-dist-type=uniform:指定随机取样类型,可选值有 uniform(均匀分布), Gaussian(高斯分布), special(空间分布)。默认是special--oltp-read-only=off:表示不止产生只读SQL,也就是使用oltp.lua时会采用读写混合模式。默认 off,如果设置为on,则不会产生update,delete,insert的sql。--oltp-test-mode=nontrx:执行模式,这里是非事务式的。可选值有simple,complex,nontrx。默认是complexsimple:简单查询,SELECT c FROM sbtest WHERE id=Ncomplex (advanced transactional):事务模式在开始和结束事务之前加上begin和commit, 一个事务里可以有多个语句,如点查询、范围查询、排序查询、更新、删除、插入等,并且为了不破坏测试表的数据,该模式下一条记录删除后会在同一个事务里添加一条相同的记录。nontrx (non-transactional):与simple相似,但是可以进行update/insert等操作,所以如果做连续的对比压测,你可能需要重新cleanup,prepare。--oltp-skip-trx=[on|off]:省略begin/commit语句。默认是off--rand-init=on:是否随机初始化数据,如果不随机化那么初始好的数据每行内容除了主键不同外其他完全相同--num-threads=12: 并发线程数,可以理解为模拟的客户端并发连接数--report-interval=10:表示每10s输出一次测试进度报告--max-requests=0:压力测试产生请求的总数,如果以下面的max-time来记,这个值设为0--max-time=120:压力测试的持续时间,这里是2分钟。注意,针对不同的选项取值就会有不同的子选项。比如oltp-dist-type=special,就有比如oltp-dist-pct=1、oltp-dist-res=50两个子选项,代表有50%的查询落在1%的行(即热点数据)上,另外50%均匀的(sample uniformly)落在另外99%的记录行上。再比如oltp-test-mode=nontrx时, 就可以有oltp-nontrx-mode,可选值有select(默认), update_key, update_nokey, insert, delete,代表非事务式模式下使用的测试sql类型。以上代表的是一个只读的例子,可以把num-threads依次递增(16,36,72,128,256,512),或者调整my.cnf参数,比较效果。另外需要注意的是,大部分mysql中间件对事务的处理,默认都是把sql发到主库执行,所以只读测试需要加上oltp-skip-trx=on来跳过测试中的显式事务。ps1: 只读测试也可以使用share/tests/db/select.lua进行,但只是简单的point select。
ps2: 我在用sysbench压的时候,在mysql后端会话里有时看到大量的query cache lock,如果使用的是uniform取样,最好把查询缓存关掉。当然如果是做两组性能对比压测,因为都受这个因素影响,关心也不大。3. 运行基准测试
1) 运行测试:混合操作测试
sysbench --test=./sysbench/tests/db/oltp.lua --mysql-table-engine=innodb --mysql-host=127.0.0.1 --mysql-db=sysbenchtest --mysql-user=sysbench \
--mysql-password='4rfv$RFV' --num-threads=8 --oltp-table-size=100000 --oltp_tables_count=5 --oltp-read-only=off --report-interval=10 \
--rand-type=uniform --max-time=300 --max-requests=0 --percentile=99 run >> ./log/sysbench.log2) 如果多次测试清理记录
sysbench --test=./sysbench/tests/db/oltp.lua --mysql-table-engine=innodb --mysql-host=127.0.0.1 --mysql-db=sysbenchtest --num-threads=8 \
--oltp-table-size=100000 --oltp_tables_count=5 --oltp-read-only=off --report-interval=10 --rand-type=uniform --max-time=600 --max-requests=0 \--mysql-user=test --mysql-password='4rfv$RFV' cleanup* 参数说明
--num-threads=8 表示发起 8个并发连接
--oltp-read-only=off 表示不要进行只读测试,也就是会采用读写混合模式测试
--report-interval=10表示每10秒输出一次测试进度报告 --rand-type=uniform
表示随机类型为固定模式,其他几个可选随机模式:uniform(固定),gaussian(高斯),special(特定的),pareto(帕累托)--max-time=120 表示最大执行时长为 120秒,实际环境中建议30分钟--max-requests=0 表示总请求数为 0,因为上面已经定义了总执行时长,所以总请求数可以设定为 0;也可以只设定总请求数,不设定最大执行时长
--percentile=99 表示设定采样比例,默认是 95%,即丢弃1%的长请求,在剩余的99%里取最大值4. 分析调优效果:通过脚本控制测试,测试多次取平均值,运行脚本需要清空上一次的日志。
1) 参数分析
queries performed:read: 938224 -- 读总数write: 268064 -- 写总数other: 134032 -- 其他操作总数(SELECT、INSERT、UPDATE、DELETE之外的操作,例如COMMIT等)total: 1340320 -- 全部总数transactions: 67016 (1116.83 per sec.) -- 总事务数(每秒事务数)deadlocks: 0 (0.00 per sec.) -- 发生死锁总数read/write requests: 1206288 (20103.01 per sec.) -- 读写总数(每秒读写次数)other operations: 134032 (2233.67 per sec.) -- 其他操作总数(每秒其他操作次数)
General statistics: -- 一些统计结果total time: 60.0053s -- 总耗时total number of events: 67016 -- 共发生多少事务数total time taken by event execution: 479.8171s -- 所有事务耗时相加(不考虑并行因素)response time: -- 响应时长统计,主要参考指标min: 4.27ms -- 最小耗时avg: 7.16ms -- 平均耗时max: 13.80ms -- 最长耗时approx. 99 percentile: 9.88ms -- 超过99%平均耗时
Threads fairness:events (avg/stddev): 8377.0000/44.33execution time (avg/stddev): 59.9771/0.005. 测试分析脚本
analysis_mysql.py吗,控制测试次数,并取得平均值,但是要在每次测试前清空sysbench.log日志文件
#!/usr/bin/env python
import re
import os#logFile = open('C:\\Users\\Administrator\\Desktop\\sysbench.log','r')
logFile = open('/root/sysbench-0.5/log/sysbench.log','r')
analysisFile = open('/root/sysbench-0.5/log/analysis.log','a+')
#analysisFile = open('C:\\Users\\Administrator\\Desktop\\analysis.log','a+')# 结果分析
def closeFile(file):file.close()def analysis():print("开始分析...")transacion = []readeWrite = []mintime = []avgtime = []maxtime = []approxtime = []# 读取文件数据for line in logFile:transacion_persec = re.search(r'transactions:.*\((\d+\.*\d*).*\).*',line)readeWrite_persec = re.search(r'read/write requests:.*\((\d+\.*\d*).*\).*',line)mintime_response = re.search(r'min:\s*(\d+\.?\d*).*',line)avgtime_response = re.search(r'avg:\s*(\d+\.?\d*).*',line)maxtime_response = re.search(r'max:\s*(\d+\.?\d*).*',line)approxtime_response = re.search(r'approx.*?(\d+\.{1}\d*).*',line)if transacion_persec:transacion.append(transacion_persec.group(1))elif readeWrite_persec:readeWrite.append(readeWrite_persec.group(1))elif mintime_response:mintime.append(mintime_response.group(1))elif avgtime_response:avgtime.append(avgtime_response.group(1))elif maxtime_response:maxtime.append(maxtime_response.group(1))elif approxtime_response:approxtime.append(approxtime_response.group(1))sum = 0.0# 统计事务for data in transacion:sum += float(data)avgtransaction = ('%.2f'%(sum / len(transacion)))analysisFile.write("transacion每秒:" + str(avgtransaction) + "\n")sum = 0.0# 统计读写for data in readeWrite:sum += float(data)read_write = ('%.2f'%(sum / len(readeWrite)))analysisFile.write("read/write每秒:" + str(read_write) + "\n")sum = 0.0# 统计最小时间for data in mintime:sum += float(data)if len(mintime) !=0:min_time = ('%.2f'%(sum / len(mintime)))analysisFile.write("min time:" + str(min_time) + "\n")sum = 0.0# 统计最大时间for data in maxtime:sum += float(data)max_time = ('%.2f'%(sum / len(maxtime)))analysisFile.write("max time:" + str(max_time) + "\n")sum = 0.0# 统计平均时间for data in avgtime:sum += float(data)avg_time = ('%.2f'%(sum / len(avgtime)))analysisFile.write("avg time:" + str(avg_time) + "\n")analysisFile.write("="*20 + "\n")print("分析完成...")closeFile(analysisFile)
# 数据准备
def prepare():print("准备数据...")os.system("sysbench --test=/root/sysbench-0.5/sysbench/tests/db/oltp.lua --mysql-host=127.0.0.1 --mysql-db=sysbenchtest --mysql-user=sysbench --mysql-password='4rfv$RFV' --oltp-test-mode=complex --oltp-tables-count=5 --oltp-table-size=100000 --threads=10 --time=120 --rand-init=on --report-interval=10 --mysql-table-engine=innodb prepare")# 测试函数
def experiment():print("测试数据...")os.system("sysbench --test=/root/sysbench-0.5/sysbench/tests/db/oltp.lua --mysql-table-engine=innodb --mysql-host=127.0.0.1 --mysql-db=sysbenchtest --mysql-user=sysbench --mysql-password='4rfv$RFV' --num-threads=8 --oltp-table-size=100000 --oltp_tables_count=5 --oltp-read-only=off --report-interval=10 --rand-type=uniform --max-time=30 --max-requests=0 --percentile=99 run >> /root/sysbench-0.5/log/sysbench.log")
#
# # 清空数据
def clean():print("清空测试数据库...")os.system("sysbench --test=/root/sysbench-0.5/sysbench/tests/db/oltp.lua --mysql-table-engine=innodb --mysql-host=127.0.0.1 --mysql-db=sysbenchtest --num-threads=8 --oltp-table-size=100000 --oltp_tables_count=5 --oltp-read-only=off --report-interval=10 --rand-type=uniform --max-time=600 --max-requests=0 --mysql-user=test --mysql-password='4rfv$RFV' cleanup")if __name__ == '__main__':for i in range(0,3):prepare()experiment()clean()analysis()最后感谢每一个认真阅读我文章的人,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走:

这些资料,对于【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴上万个测试工程师们走过最艰难的路程,希望也能帮助到你!有需要的小伙伴可以点击下方小卡片领取
相关文章:
mysql性能测试工具选择 mysql软件测试
1.理论知识: 1.1 定义 1. 基准测试是一种测量和评估软件性能指标的活动,用于建立某个时刻的性能基准,以便当系统发生软硬件变化时重新进行基准测试以评估变化对性能的影响 2. 基准测试是针对系统设置的一种压力测试,但是和压力测试还是有区…...

GPS全球卫星定位系统原理
GPS全球卫星定位系统是一种利用导航卫星进行定位、导航和时间测量的系统。它由三部分组成:空间部分、地面控制部分和用户设备部分。其中,空间部分由24颗卫星组成,分布在6个轨道面上,每个轨道面有4颗卫星;地面控制部分由…...
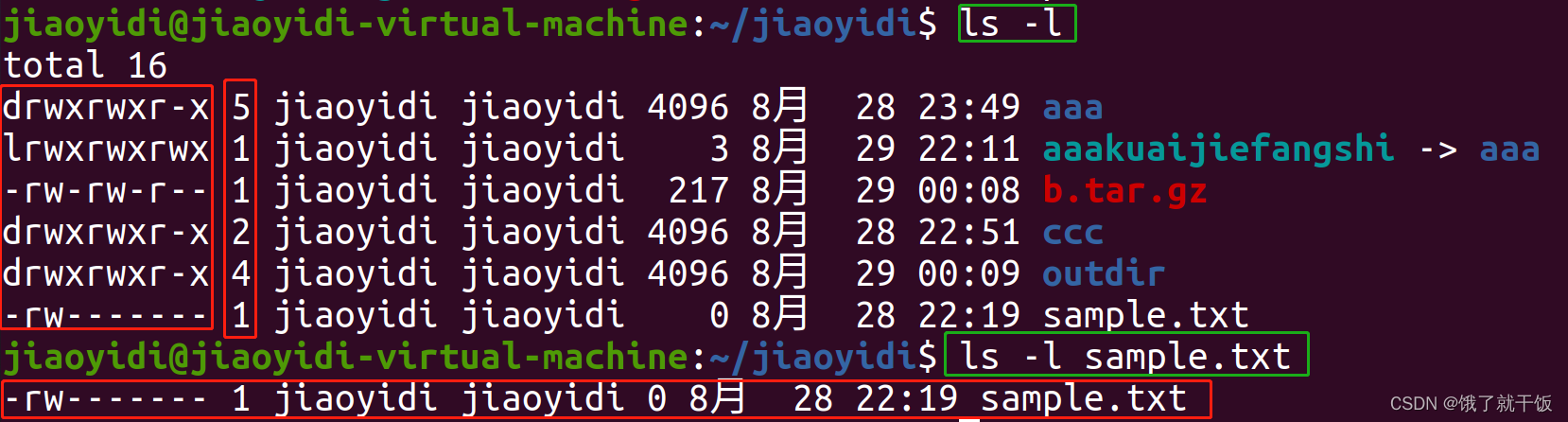
Ubuntu学习---跟着绍发学linux课程记录(第一部分)
文章目录 1、启动、关闭、挂起、恢复(电源)2、更多虚拟机操作2.1 电源设置2.2 硬件参数设置2.3 状态栏2.4 全屏显示 3、快照与系统恢复4、桌面环境5、文件系统6、用户目录7、创建目录和文件8、命令行:文件列表ls 9、命令行:切换目…...
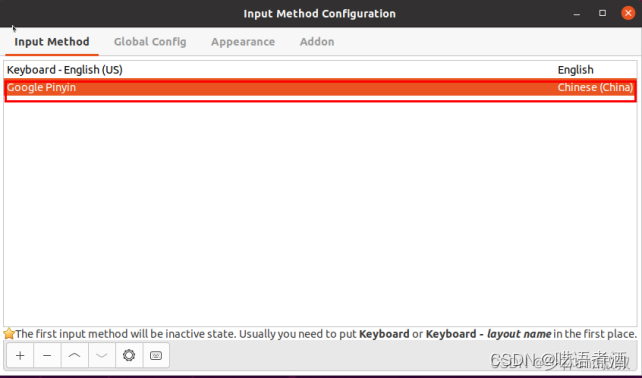
Ubuntu20.04下安装google输入法
Ubuntu20.04下安装google输入法 1、添加中文语言支持 打开 系统设置——区域和语言——管理已安装的语言——在“语言”tab下——点击“添加或删除语言” 弹出“已安装语言”窗口,勾选中文(简体),点击应用 回到“语言支持”窗…...
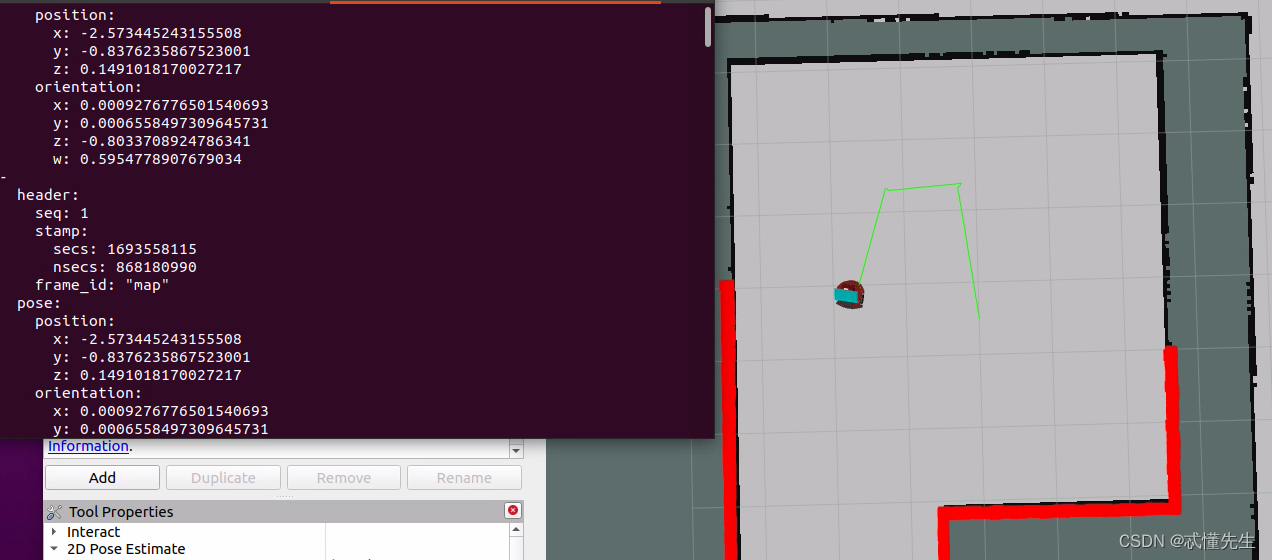
Ros noetic 机器人坐标记录运动路径和发布 实战教程(A)
前言: 网上记录Path的写入文件看了一下还挺多的,有用yaml作为载体文件,也有用csv文件的路径信息,也有用txt来记录当前生成的路径信息,载体不重要,反正都是记录的方式,本文主要按yaml的方式写入,后文中将补全其余两种方式。 其中两种方式的主要区别在于,加载yaml所需要…...
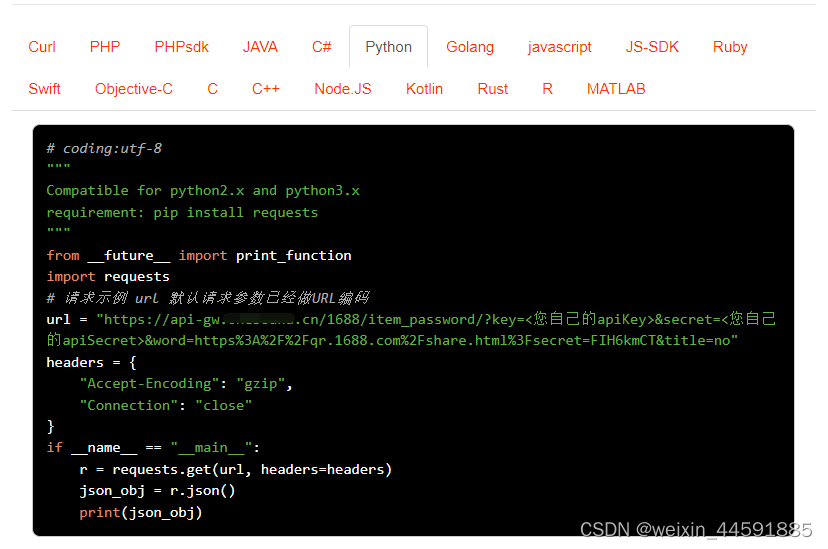
Java“牵手”1688淘口令转换API接口数据,1688API接口申请指南
1688平台商品淘口令接口是开放平台提供的一种API接口,通过调用API接口,开发者可以获取1688商品的标题、价格、库存、商品快递费用,宝贝ID,发货地,区域ID,快递费用,月销量、总销量、库存、详情描…...

Python实现自动关键词提取
随着互联网的发展,越来越多的人喜欢在网络上阅读小说。本文将通过详细示例,向您介绍如何使用Python编写爬虫程序来获取网络小说,并利用自然语言处理技术实现自动文摘和关键词提取功能。 1. 网络小说数据抓取 首先,请确保已安装必…...

java八股文面试[多线程]——sleep wait join yield
sleep和wait有什么区别 sleep 方法和 wait 方法都是用来将线程进入阻塞状态的,并且 sleep 和 wait 方法都可以响应 interrupt 中断,也就是线程在休眠的过程中,如果收到中断信号,都可以进行响应并中断,且都可以抛出 In…...

Vue/React 项目部署到服务器后,刷新页面出现404报错
问题描述:在本地启动项目一切正常,部署到服务器上线后出现BUG,项目刷新页面出现404。 起初以为是自己路由守卫或是token丢失问题,找了一圈终于解决了 产生原因:我们打开vue/react打包后生成的dist文件夹,可…...

通信笔记:RSRP、RSRQ、RSNNR
0 基础概念:RE、RS和RB RE (Resource Element):资源元素是 LTE 和 5G 网络中的最小物理资源单位。一个资源元素对应于一个子载波的一个符号周期。 RS (Reference Signal):参考信号是在 LTE 和 5G 网络中用于多种目的的特定类型的信号。它们可…...

前端:html实现页面切换、顶部标签栏(可删、可切换,点击左侧超链接出现标签栏)
一、在一个页面(不跨页面) 效果: 代码 <!DOCTYPE html> <html><head><style>/* 设置标签页外层容器样式 */.tab-container {width: 100%;background-color: #f1f1f1;overflow: hidden;}/* 设置标签页选项卡的样式 …...

python print格式化输出
在 Python 中,以 f 或 F 前缀开始的字符串表示格式化字符串字面量,通常称为 “f-string”。从 Python 3.6 开始引入,它们是一种在字符串中嵌入表达式的新方法。这些表达式在运行时会被评估,然后使用 {} 将它们插入到字符串中。 这…...

钢筋水泥中的信仰--爱摸鱼的美工(16)
好久没有更新了,爱摸鱼的美工摸鱼太久可,终于出了一起钢筋水泥中的信仰,希望人们更加坚定个人的信仰。...
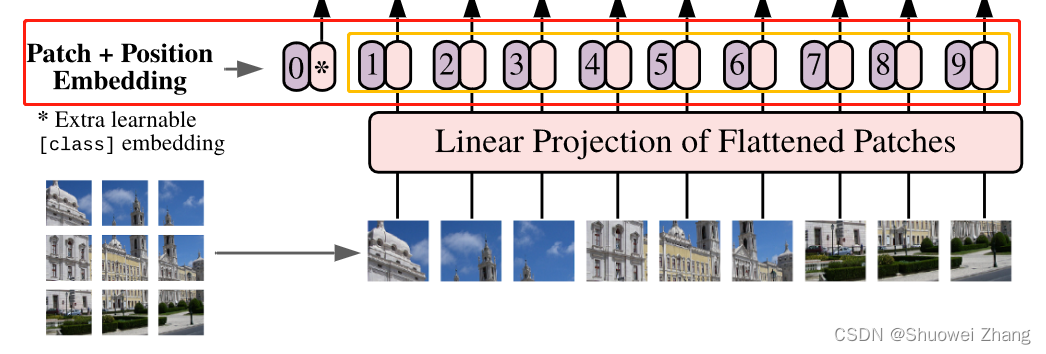
ViT论文Pytorch代码解读
ViT论文代码实现 论文地址:https://arxiv.org/abs/2010.11929 Pytorch代码地址:https://github.com/lucidrains/vit-pytorch ViT结构图 调用代码 import torch from vit_pytorch import ViTdef test():v ViT(image_size 256, patch_size 32, num_cl…...

Harbor查看密码
已经登录过的harbor 查看密码 cat /root/.docker/config.json {"auths": {"172.28.120.140": {"auth": "YWRtaW43QDIwMTg"}}使用base64解码...

Boa服务器与Cgi简介
Boa是一个单任务的HTTP服务器,Boa只能依次完成用户的请求,而不会fork出新的进程来处理并发连接请求。Boa支持CGI。Boa的设计目标是速度和安全,这很符合嵌入式的需要,他的特点就是可靠性和可移植性。 Boa的作用: 负责h…...
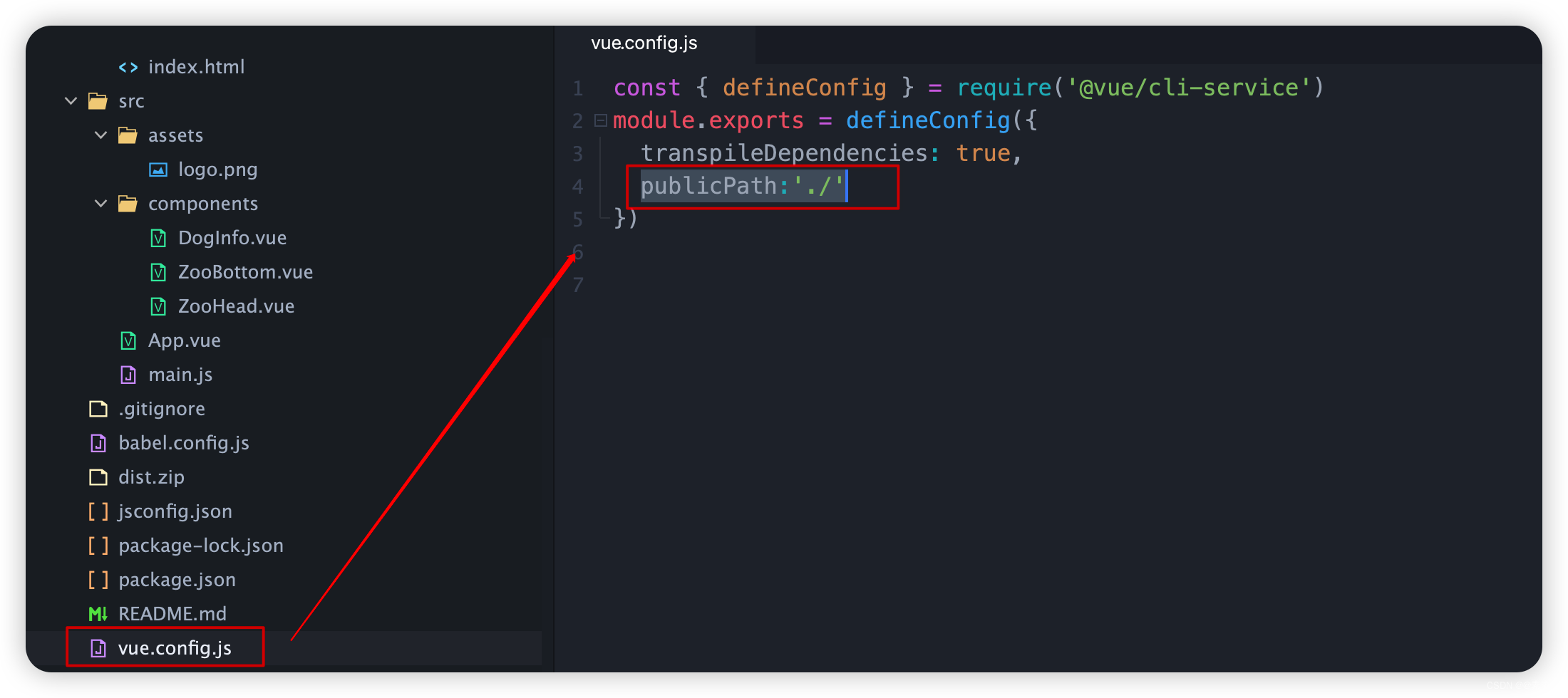
入门vue——创建vue脚手架项目 以及 用tomcat和nginx分别部署vue项目(vue2)
入门vue——创建vue脚手架项目 以及 用tomcat和nginx分别部署vue项目(vue2) 1. 安装npm2. 安装 Vue CLI3. 创建 vue_demo1 项目(官网)3.1 创建 vue_demo1 项目3.1.1 创建项目3.1.2 解决 sudo 问题 3.2 查看创建的 vue_demo1 项目3…...
)
oracle中的(+)
一、()为何意? oracle中的()是一种特殊的用法,()表示外连接,并且总是放在非主表的一方。 二、举例 左外连接: select A.a,B.a from A LEFT JOIN B ON A.bB.b; 等价于 select A.a,B.…...

五种永久免费 内网穿透傻瓜式使用
方法一(使用qydev) 官网:点击访问 1、官网 页面:找到客户端下载 2、找到自己电脑或者运行平台对应的版本(我的是windows 64位) 3、下载完成后解压到 自己熟悉的文件内保存,解压后,暂时不管她,继续第4步 4、登录官网…...
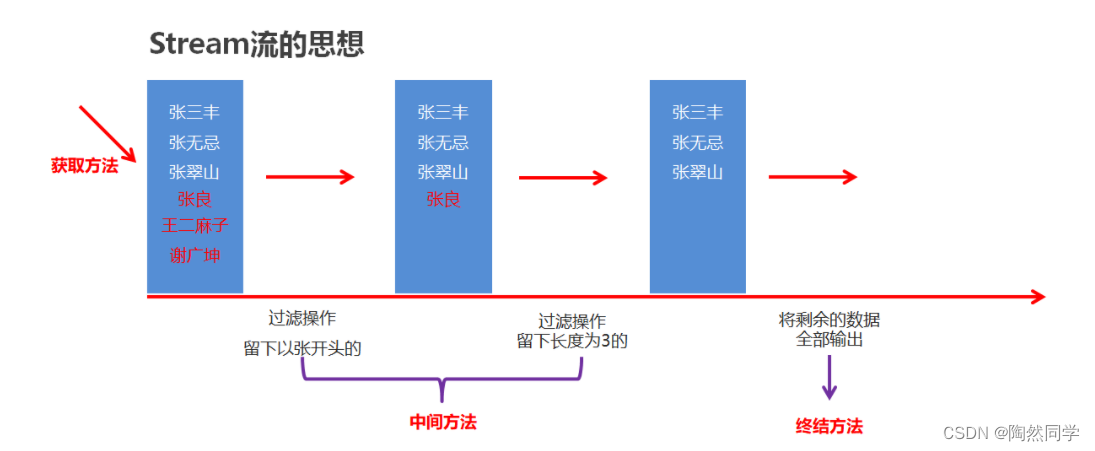
【Java基础增强】Stream流
1.Stream流 1.1体验Stream流【理解】 案例需求 按照下面的要求完成集合的创建和遍历 创建一个集合,存储多个字符串元素 把集合中所有以"张"开头的元素存储到一个新的集合 把"张"开头的集合中的长度为3的元素存储到一个新的集合 遍历上一步得…...

三小时搞定百年乐谱数字化:Audiveris光学音乐识别技术实战指南
三小时搞定百年乐谱数字化:Audiveris光学音乐识别技术实战指南 【免费下载链接】audiveris Latest generation of Audiveris OMR engine 项目地址: https://gitcode.com/gh_mirrors/au/audiveris 你是否曾面对堆积如山的古典乐谱束手无策?那些泛黄…...

5分钟快速上手:抖音下载器完整使用指南
5分钟快速上手:抖音下载器完整使用指南 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support. 抖音批量下…...
)
手把手教你用USB ISP下载器给Arduino Nano烧写Bootloader(含ProgISP软件详细配置)
手把手教你用USB ISP下载器为Arduino Nano烧录Bootloader 当你拿到一块全新的Arduino Nano开发板,或是遇到程序无法上传的"变砖"情况时,很可能需要重新烧写Bootloader。Bootloader是存储在微控制器中的一小段特殊程序,它负责与Ard…...

告别手动对照!用OrCAD Design Sync功能,5分钟自动化同步你的原理图与Allegro PCB变更
告别手动对照!用OrCAD Design Sync功能,5分钟自动化同步你的原理图与Allegro PCB变更 在高速迭代的电子设计领域,每一次原理图修改都可能引发PCB布局的连锁反应。传统手动同步方式不仅耗时费力,还容易遗漏关键变更。OrCAD Design…...

Brushes项目部署教程:从源码编译到App Store发布完整指南 [特殊字符]
Brushes项目部署教程:从源码编译到App Store发布完整指南 🎨 【免费下载链接】Brushes Painting app for the iPhone and iPad. 项目地址: https://gitcode.com/gh_mirrors/br/Brushes Brushes是一款专为iPhone和iPad设计的开源绘画应用ÿ…...

2026年3大知识竞赛软件测评:告别抢答器,手机闯关如何玩出高级感?
在2026年的今天,组织一场知识竞赛不再需要搬运笨重的抢答硬件,也不再需要人工统计分数。无论是学校的百科竞赛,还是企业的安全生产月活动,组织者最核心的需求已经演变为:如何在保证万人并发稳定的前提下,玩…...

终极AMD Ryzen性能调优指南:SMUDebugTool完全掌握手册
终极AMD Ryzen性能调优指南:SMUDebugTool完全掌握手册 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https://gi…...

Unity渐变透明效果实现原理与生产级方案
1. 这不是调个Alpha值那么简单:为什么90%的Unity透明效果都“假”得明显 在Unity项目里做淡入淡出,很多人第一反应就是 renderer.material.color new Color(1,1,1,0.5f) ——改个alpha完事。我刚入行那会儿也这么干,直到上线前被美术揪着耳…...

Logisim-evolution数字电路设计实战:从图形化设计到FPGA实现的完整工作流
Logisim-evolution数字电路设计实战:从图形化设计到FPGA实现的完整工作流 【免费下载链接】logisim-evolution Digital logic design tool and simulator 项目地址: https://gitcode.com/gh_mirrors/lo/logisim-evolution Logisim-evolution作为一款功能强大…...

驱动教学模式革新:广凌智慧教学融合平台如何实现个性化教学?
随着高等教育从“知识为主”向“能力为先”深刻转型,千人千面的个性化学习已成为未来教育的核心诉求。传统的统一内容、统一路径的教学模式,已难以满足学生差异化的发展需要。如何借助技术手段实现真正的因材施教?广凌智慧教学融合平台以人工…...