Flink SQL你用了吗?
分析&回答
- Flink 1.1.0:第一次引入 SQL 模块,并且提供 TableAPI,当然,这时候的功能还非常有限。
- Flink 1.3.0:在 Streaming SQL 上支持了 Retractions,显著提高了 Streaming SQL 的易用性,使得 Flink SQL 支持了复杂的 Unbounded 聚合连接。
- Flink 1.5.0:SQL Client 的引入,标志着 Flink SQL 开始提供纯 SQL 文本。
- Flink 1.9.0:抽象了 Table 的 Planner 接口,引入了单独的 Blink Table 模块。Blink Table 模块是阿里巴巴内部的 SQL 层版本,不仅在结构上有重大变更,在功能特性上也更加强大和完善。
- Flink 1.10.0:作为第一个 Blink 基本完成 merge 的版本,修复了大量遗留的问题,并给 DDL 带来了 Watermark 的语法,也给 Batch SQL 带来了完整的 TPC-DS 支持和高效的性能。
CDC 支持
SQL 1.11 Flink SQL 在原有的基础上扩展了新场景的支持:
- Flink SQL 引入了对 CDC(Change Data Capture,变动数据捕获)的支持,它使 Flink 可以方便地通过像 Debezium 这类工具来翻译和消费数据库的变动日志。
- Flink SQL 扩展了类 Filesystem connector 对实时化用户场景和格式的支持,从而可以支持将流式数据从 Kafka 写入 Hive 等场景。
CDC 支持
CDC 格式是数据库中一种常用的模式,业务上典型的应用是通过工具(比如 Debezium 或 Canal)将 CDC 数据通过特定的格式从数据库中导出到 Kafka 中。在以前,业务上需要定义特殊的逻辑来解析 CDC 数据,并把它转换成一般的 Insert-only 数据,后续的处理逻辑需要考虑到这种特殊性,这种 work-around 的方式无疑给业务上带来了不必要的复杂性。如果 Flink SQL 引擎能原生支持 CDC 数据的输入,将 CDC 对接到 Flink SQL 的 Changelog Stream 概念上,将会大大降低用户业务的复杂度。

流计算的本质是就是不断更新、不断改变结果的计算。考虑一个简单的聚合 SQL,流计算中,每次计算产生的聚合值其实都是一个局部值,所以会产生 Changelog Stream。在以前想要把聚合的数据输出到 Kafka 中,如上图所示,几乎是不可能的,因为 Kafka 只能接收 Insert-only 的数据。Flink 之前主要是因为 Source&Sink 接口的限制,导致不能支持 CDC 数据的输入。
Flink SQL 1.11 经过了大量的接口重构,在新的 Source&Sink 接口上,支持了 CDC 数据的输入和输出,并且支持了 Debezium 与 Canal 格式(FLIP-105)。这一改动使动态 Table Source 不再只支持 append-only 的操作,而且可以导入外部的修改日志(插入事件)将它们翻译为对应的修改操作(插入、修改和删除)并将这些操作与操作的类型发送到后续的流中。
如上图所示,理论上,CDC 同步到 Kafka 的数据就是 Append 的一个流,只是在格式中含有 Changelog 的标识:
- 一种方式是把 Changlog 标识看做一个普通字段,这也是目前普遍的使用方式。
- 在 Flink 1.11 后,可以将它声明成 Changelog 的格式,Flink 内部机制支持 Interpret Changelog,可以原生识别出这个特殊的流,将其转换为 Flink 的 Changlog Stream,并按照 SQL 的语义处理;同理,Flink SQL 也具有输出 Change Stream 的能力 (Flink 1.11 暂无内置实现),这就意味着,你可以将任意类型的 SQL 写入到 Kafka 中,只要有 Changelog 支持的 Format。
- Flink 1.11 彻底的抛弃了推断 PK这个机制,不再从 Query 来推断 PK 了,而是完全依赖 Create table 语法。比如 Create 一个 jdbc_table,需要在定义中显式地写好 Primary Key(后面 NOT ENFORCED 的意思是不强校验,因为 Connector 也许没有具备 PK 的强校验的能力)。当指定了 PK,就相当于就告诉框架这个Jdbc Sink 会按照对应的 Key 来进行更新。如此,就跟 Query 完全没有关系了,这样的设计可以定义得非常清晰,如何更新完全按照设置的定义来。
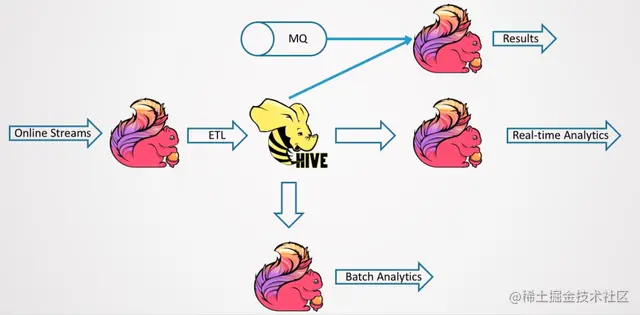
Hive 流批一体
首先看传统的 Hive 数仓。一个典型的 Hive 数仓如下图所示。一般来说,ETL 使用调度工具来调度作业,比如作业每天调度一次或者每小时调度一次。这里的调度,其实也是一个叠加的延迟。调度产生 Table1,再产生 Table2,再调度产生 Table3,计算延时需要叠加起来。

问题是慢,延迟大,并且 Ad-hoc 分析延迟也比较大,因为前面的数据入库,或者前面的调度的 ETL 会有很大的延迟。Ad-hoc 分析再快返回,看到的也是历史数据。
所以现在流行构建实时数仓,从 Kafka 读计算写入 Kafka,最后再输出到 BI DB,BI DB 提供实时的数据服务,可以实时查询。Kafka 的 ETL 为实时作业,它的延时甚至可能达到毫秒级。实时数仓依赖 Queue,它的所有数据存储都是基于 Queue 或者实时数据库,这样实时性很好,延时低。但是:
- 第一,基于 Queue,一般来说就是行存加 Queue,存储效率其实不高。
- 第二,基于预计算,最终会落到 BI DB,已经是聚合好的数据了,没有历史数据。而且 Kafka 存的一般来说都是 15 天以内的数据,没有历史数据,意味着无法进行 Ad-hoc 分析。所有的分析全是预定义好的,必须要起对应的实时作业,且写到 DB 中,这样才可用。对比来说,Hive 数仓的好处在于它可以进行 Ad-hoc 分析,想要什么结果,就可以随时得到什么结果。
能否结合离线数仓和实时数仓两者的优势,然后构建一个 Lambda 的架构?
核心问题在于成本过高。无论是维护成本、计算成本还是存储成本等都很高。并且两边的数据还要保持一致性,离线数仓写完 Hive 数仓、SQL,然后实时数仓也要写完相应 SQL,将造成大量的重复开发。还可能存在团队上分为离线团队和实时团队,两个团队之间的沟通、迁移、对数据等将带来大量人力成本。如今,实时分析会越来越多,不断的发生迁移,导致重复开发的成本也越来越高。少部分重要的作业尚可接受,如果是大量的作业,维护成本其实是非常大的。
如何既享受 Ad-hoc 的好处,又能实现实时化的优势?一种思路是将 Hive 的离线数仓进行实时化,就算不能毫秒级的实时,准实时也好。所以,Flink 1.11 在 Hive 流批一体上做了一些探索和尝试,如下图所示。它能实时地按 Streaming 的方式来导出数据,写到 BI DB 中,并且这套系统也可以用分析计算框架来进行 Ad-hoc 的分析。这个图当中,最重要的就是 Flink Streaming 的导入。
反思&扩展
其实用与没用不需要绝对回答,根据你自己实际的使用来就好了。
Flink SQL很多时候在测试的时候很好用,在单纯实时计算的时候也非常不错,如果你要做实时数仓,其实并不一定是最好的选择,能高效低成本的打通离线数据和实时数据才是王道。
喵呜面试助手:一站式解决面试问题,你可以搜索微信小程序 [喵呜面试助手] 或关注 [喵呜刷题] -> 面试助手 免费刷题。如有好的面试知识或技巧期待您的共享!
相关文章:
Flink SQL你用了吗?
分析&回答 Flink 1.1.0:第一次引入 SQL 模块,并且提供 TableAPI,当然,这时候的功能还非常有限。Flink 1.3.0:在 Streaming SQL 上支持了 Retractions,显著提高了 Streaming SQL 的易用性,使…...

【位运算】leetcode面试题:消失的两个数字
一.题目描述 消失的两个数字 二.思路分析 本题难度标签是困难,但实际上有了只出现一次的数字iii这道题的铺垫,本题的思路还是很容易想到的。 温馨提示:阅读本文前可以先查看我的【位运算】专栏的第一篇文章,其中包含位运算这类…...
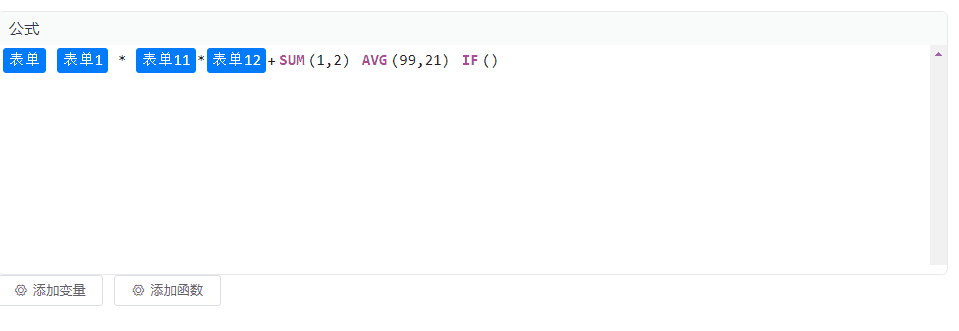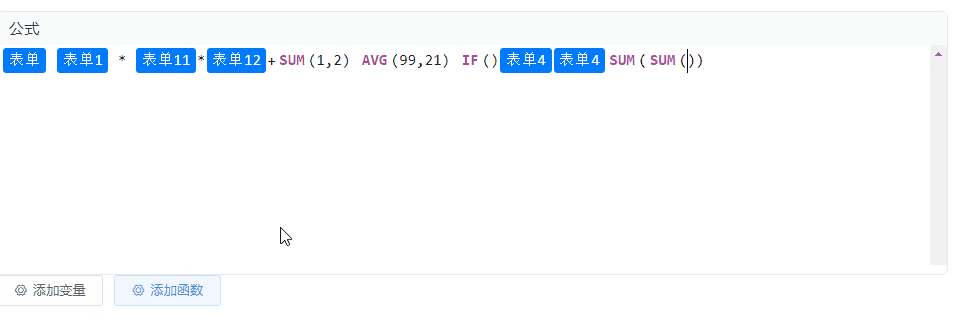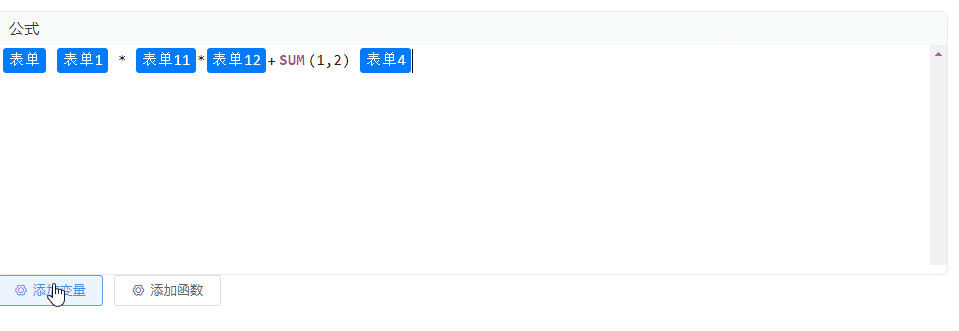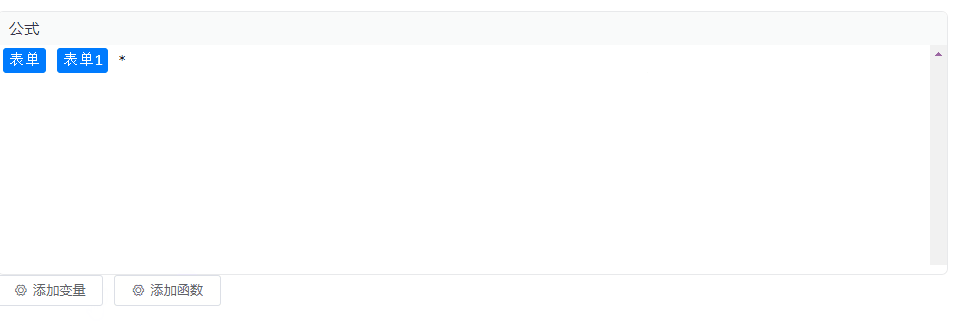
Vue2 集成 CodeMirror 实现公式编辑、块状文本编辑,TAG标签功能
效果图 安装codemirror依赖 本示例为Vue2项目,安装低版本的依赖 npm i codemirror5.65.12 npm i vue-codemirror4.0.6 实现 实现代码如下,里边涉及到的变量和函数自行替换即可,没有其他复杂逻辑。 <template><div class"p…...

CCF-CSP 30次 第二题【矩阵运算】
计算机软件能力认证考试系统 #include<bits/stdc.h> using namespace std; const int N1e410; #define int long long int n,d; int q[N][22],k[22][N],v[N][22],w[N]; int ans1[N][22],ans2[N][22]; signed main() {scanf("%lld %lld",&n,&d);for(in…...

最大子数组和【贪心算法】
最大子数组和 给你一个整数数组 nums ,请你找出一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。 子数组 是数组中的一个连续部分。 class Solution {public int maxSubArray(int[] nums) {//记录最大结果&…...

linux并发服务器 —— Makefile与GDB调试(二)
Makefile Makefile:定义规则指定文件的编译顺序;类似shell脚本,执行操作系统命令 优点:自动化编译——通过make(解释Makefile文件中指令的命令)命令完全编译整个工程,提高软件开发效率&#x…...
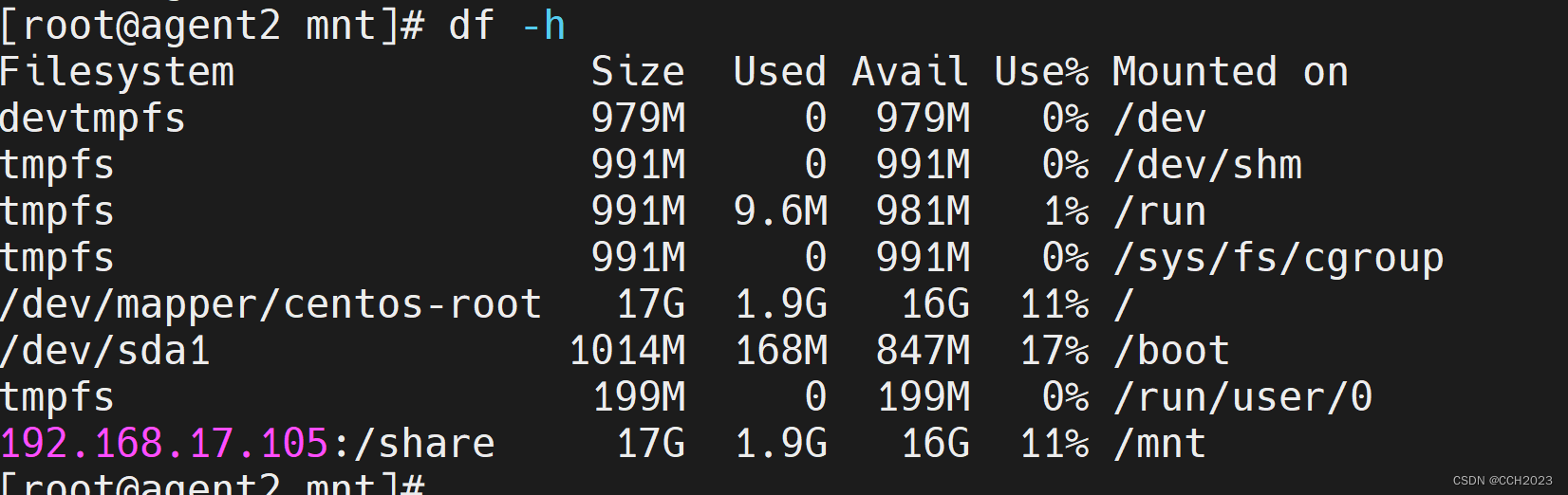
Ansible学习笔记14
实现多台的分离实现: [rootlocalhost playbook]# cat example3.yaml --- - hosts: 192.168.17.105remote_user: roottasks:- name: create test1 directoryfile: path/test1/ statedirectory- hosts: 192.168.17.106remote_user: roottasks:- name: create test2 d…...

docker 安装 mysql 并挂载 配置文件和数据目录
1、宿主机创建挂载目录 sudo mkdir /path/mysql/data sudo mkdir /path/mysql/conf2、搜索镜像 docker search mysql拉取官方支持版本(OFFICIAL 为 ok的版本) docker pull mysql:latest3、以 mysql 作为基础镜像构建容器并挂载目录 docker run -d -p…...

代码随想录训练营 DP01
代码随想录训练营 DP01 509. 🌸斐波那契数🌸code 70. 🌸爬楼梯🌸code 746. 🌸使用最小花费爬楼梯🌸code 509. 🌸斐波那契数🌸 斐波那契数 (通常用 F(n) 表示)…...

github+hexo 博客搭建
文章目录 1.安装Node.js、Git和Hexo2.创建 GitHub 仓库并配置ssh3.初始化Hexo4.配置Hexo5.创建博客内容6.部署7.查看8.参考:9.选择主题: 环境:win11wsl 1.安装Node.js、Git和Hexo 打开终端安装以下软件 sudo apt update sudo apt-get insta…...
)
Spring Security bug记录:antMatchers找不到符号(已解决)
目录 Spring Security bug记录:antMatchers找不到符号(已解决)原因:解决:参考链接: Spring Security bug记录:antMatchers找不到符号(已解决) 原因: 新版本…...
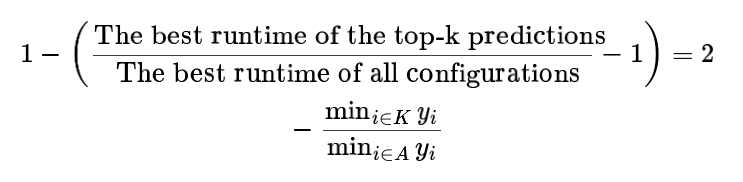
kaggle新赛:谷歌AI模型运行时间预测赛题解析【数据挖掘】
赛题名称:Google - Fast or Slow? Predict AI Model Runtime 赛题链接:https://www.kaggle.com/competitions/predict-ai-model-runtime 赛题背景 Alice 是一名 AI 模型开发人员,但她的团队开发的一些模型运行速度非常慢。她最近发现了编…...

mysql性能测试工具选择 mysql软件测试
1.理论知识: 1.1 定义 1. 基准测试是一种测量和评估软件性能指标的活动,用于建立某个时刻的性能基准,以便当系统发生软硬件变化时重新进行基准测试以评估变化对性能的影响 2. 基准测试是针对系统设置的一种压力测试,但是和压力测试还是有区…...

GPS全球卫星定位系统原理
GPS全球卫星定位系统是一种利用导航卫星进行定位、导航和时间测量的系统。它由三部分组成:空间部分、地面控制部分和用户设备部分。其中,空间部分由24颗卫星组成,分布在6个轨道面上,每个轨道面有4颗卫星;地面控制部分由…...
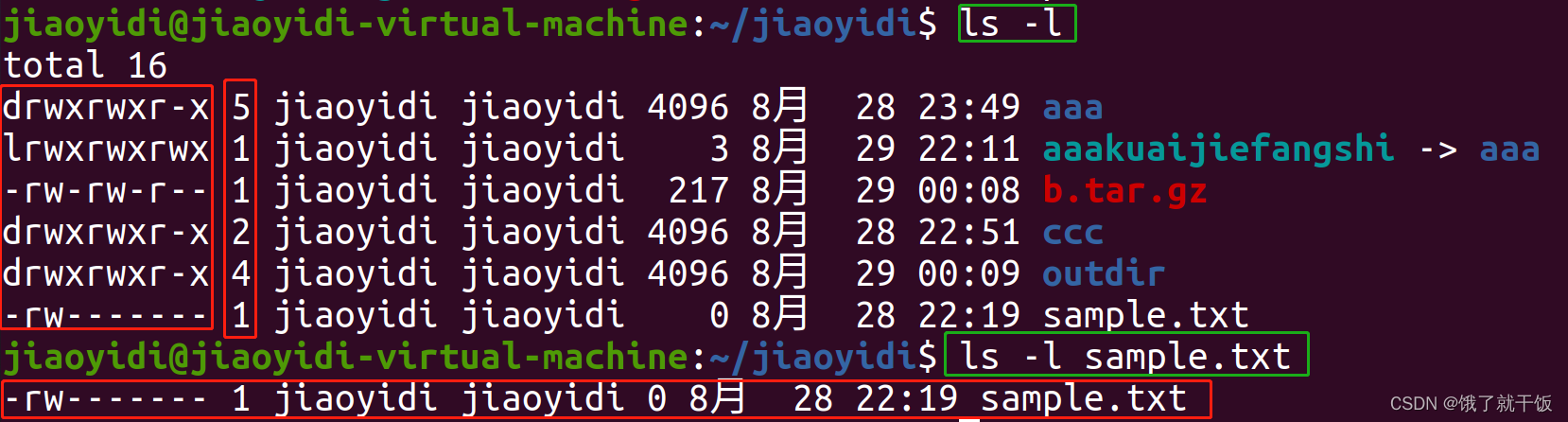
Ubuntu学习---跟着绍发学linux课程记录(第一部分)
文章目录 1、启动、关闭、挂起、恢复(电源)2、更多虚拟机操作2.1 电源设置2.2 硬件参数设置2.3 状态栏2.4 全屏显示 3、快照与系统恢复4、桌面环境5、文件系统6、用户目录7、创建目录和文件8、命令行:文件列表ls 9、命令行:切换目…...
Ubuntu20.04下安装google输入法
Ubuntu20.04下安装google输入法 1、添加中文语言支持 打开 系统设置——区域和语言——管理已安装的语言——在“语言”tab下——点击“添加或删除语言” 弹出“已安装语言”窗口,勾选中文(简体),点击应用 回到“语言支持”窗…...
Ros noetic 机器人坐标记录运动路径和发布 实战教程(A)
前言: 网上记录Path的写入文件看了一下还挺多的,有用yaml作为载体文件,也有用csv文件的路径信息,也有用txt来记录当前生成的路径信息,载体不重要,反正都是记录的方式,本文主要按yaml的方式写入,后文中将补全其余两种方式。 其中两种方式的主要区别在于,加载yaml所需要…...
Java“牵手”1688淘口令转换API接口数据,1688API接口申请指南
1688平台商品淘口令接口是开放平台提供的一种API接口,通过调用API接口,开发者可以获取1688商品的标题、价格、库存、商品快递费用,宝贝ID,发货地,区域ID,快递费用,月销量、总销量、库存、详情描…...

Python实现自动关键词提取
随着互联网的发展,越来越多的人喜欢在网络上阅读小说。本文将通过详细示例,向您介绍如何使用Python编写爬虫程序来获取网络小说,并利用自然语言处理技术实现自动文摘和关键词提取功能。 1. 网络小说数据抓取 首先,请确保已安装必…...

java八股文面试[多线程]——sleep wait join yield
sleep和wait有什么区别 sleep 方法和 wait 方法都是用来将线程进入阻塞状态的,并且 sleep 和 wait 方法都可以响应 interrupt 中断,也就是线程在休眠的过程中,如果收到中断信号,都可以进行响应并中断,且都可以抛出 In…...

TrollInstallerX终极指南:iOS 14.0-16.6.1一键安装TrollStore的完整教程
TrollInstallerX终极指南:iOS 14.0-16.6.1一键安装TrollStore的完整教程 【免费下载链接】TrollInstallerX A TrollStore installer for iOS 14.0 - 16.6.1 项目地址: https://gitcode.com/gh_mirrors/tr/TrollInstallerX 你是否厌倦了iOS系统的种种限制&…...

智能家居语音交互进阶:从离线识别到场景化意图推理的本地化实现
1. 项目概述:从“听见”到“听懂”的智能家居进化 “小爱同学,打开客厅灯。” “天猫精灵,空调调到26度。” 这类语音交互如今已司空见惯。但你是否遇到过这样的场景:对着音箱说“我有点冷”,它却回答“对不起…...

Steam创意工坊下载难题终结者:WorkshopDL让你的模组下载从未如此简单
Steam创意工坊下载难题终结者:WorkshopDL让你的模组下载从未如此简单 【免费下载链接】WorkshopDL WorkshopDL - The Best Steam Workshop Downloader 项目地址: https://gitcode.com/gh_mirrors/wo/WorkshopDL 还在为想玩Steam创意工坊的模组却没有Steam账号…...

Raw Accel深度解析:从零掌握Windows内核级鼠标加速的终极指南
Raw Accel深度解析:从零掌握Windows内核级鼠标加速的终极指南 【免费下载链接】rawaccel kernel mode mouse accel 项目地址: https://gitcode.com/gh_mirrors/ra/rawaccel 你是否厌倦了Windows默认鼠标加速的不稳定表现?是否在游戏中苦苦寻找更精…...

线粒体氧化磷酸化的新靶点:S-Gboxin的发现与研究进展
在肿瘤治疗的探索历程中,科学家们始终在寻找能够精准打击癌细胞而又最大限度保护正常组织的新型药物。2019年,一项发表在Nature杂志上的研究引起了学界广泛关注——施宇峰团队首次报道了Gboxin这一化合物的发现与独特的作用机制[1]。作为Gboxin的代谢稳定…...

原神帧率解锁工具:如何安全突破60FPS限制获得流畅体验
原神帧率解锁工具:如何安全突破60FPS限制获得流畅体验 【免费下载链接】genshin-fps-unlock unlocks the 60 fps cap 项目地址: https://gitcode.com/gh_mirrors/ge/genshin-fps-unlock 《原神》作为一款画面精美的开放世界游戏,默认的60FPS帧率限…...

别再只用默认端口了!在Ubuntu 22.04上安全配置SSH的进阶指南:改端口、密钥登录与Fail2ban
Ubuntu 22.04服务器SSH安全加固实战:从基础防护到企业级防御 当你把Ubuntu服务器暴露在公网环境中,默认的SSH配置就像把家门钥匙挂在门把手上——方便但极度危险。每天都有数以万计的自动化脚本在扫描互联网上的22端口,尝试用常见用户名和弱密…...

无监督聚类挖掘声音语义:从音乐描述文本发现认知规律
1. 这不是传统聚类,而是一场对“声音语言”的考古式挖掘你有没有试过听一首歌,然后被某段音色击中——那种“像融化的玻璃糖纸裹着雨滴坠落”的感觉?或者在音乐评论区刷到“低频像沉入深海的青铜钟”“人声有未拆封的羊皮纸质感”这类描述&am…...

Tonzhon音乐:纯净无干扰的现代音乐播放平台终极指南
Tonzhon音乐:纯净无干扰的现代音乐播放平台终极指南 【免费下载链接】tonzhon-music 铜钟 Tonzhon (tonzhon.whamon.com): 干净纯粹的音乐平台 (铜钟已不再使用 tonzhon.com,现在的 tonzhon.com 不是正版的铜钟) 项目地址: https://gitcode.com/GitHub…...

AspectCore-Framework反射扩展:打造极致性能的.NET应用终极指南
AspectCore-Framework反射扩展:打造极致性能的.NET应用终极指南 【免费下载链接】AspectCore-Framework AspectCore is an AOP-based cross platform framework for .NET Standard. 项目地址: https://gitcode.com/gh_mirrors/as/AspectCore-Framework Aspec…...