ICLR 2023|VLDet:从图像-文本对中学习区域-词语对齐的开放词汇式目标检测
原文链接:https://www.techbeat.net/article-info?id=4614&isPreview=1
作者:林闯
目标检测任务在AI工业界具有非常广泛的应用,但由于数据获取和标注的昂贵,检测的目标一直被限制在预先设定好的有限类别上。而在学术界,研究者们开始探索如何识别更广泛的目标类别,扩大目标检测在实际场景中的应用范围。本文介绍一篇刚刚被ICLR 2023录用的文章,该文使用少量的目标检测标注数据和大量的图像-文本对作为训练数据,基于二分匹配的思想从图像-文本对中提取区域-词语对,扩展了目标检测的物体类别,实现开放世界中的目标检测。

论文链接:
https://arxiv.org/abs/2211.14843
代码链接:
https://github.com/clin1223/VLDet
一、 背景
什么是开放词汇式目标检测(open-vocabulary object detection)?
现今,目标检测任务在一些学术数据集上已经取得了很好的效果。这些数据集通常预先设定好一定的目标类别,如果需要扩大检测的目标种类,那么需要为新的类别标注数据,再重新训练模型来达到目的。然而这样的做法并不是人工智能的最终答案,因为人类可以在开放的环境中感知世界,而不局限于固定的类别。这开始让我们思考视觉模型可以不可以在开放的词汇下进行目标检测,也就是说我们希望视觉模型以零样本的方式识别任意之前未知的类别。很自然地,我们想到利用自然语言的监督,因为我们可以获得大量几乎免费的、具有丰富语义的多模态数据。
在这样的背景下,本文尝试用少量具有标注的目标检测数据和大量无标注的的图像-文本对作为训练数据,得到可扩展的目标检测器,从而达到对训练中未知的类别进行检测,提高检测器的可扩展性和效率。
此时面临的挑战是:训练一个传统的检测器需要人工标注的边界框和物体类别,同样的,如果想利用自然语言监督图像中的目标那么就需要区域-词语的对应关系。那么该如何从图像-文本对中学习细粒度的区域-词语对应关系?
二、核心想法
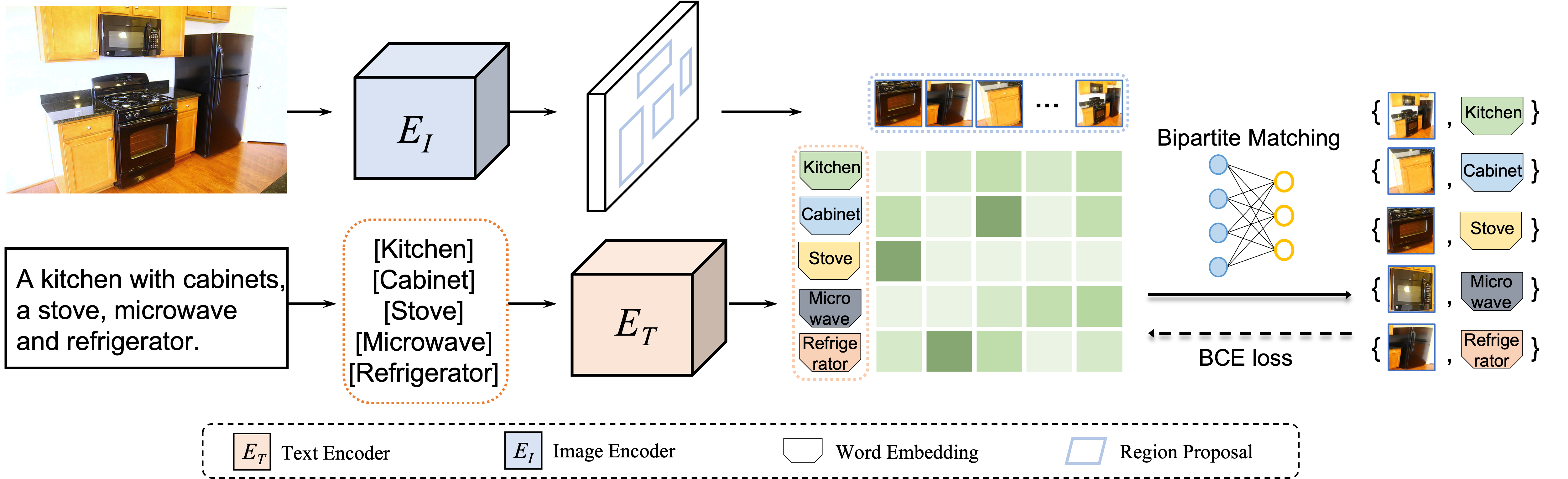
本文的主要思想是,从图像-文本对中提取区域-词语对可以表示为一个集合匹配问题,可以通过找到区域和词语之间具有最小全局匹配成本的二分匹配来有效地解决这个问题。
具体来说,我们将图像中的区域特征视为一个集合,将文本中的词语编码视为另一个集合,并将点积相似度作为区域-词语对齐分数。为了找到最低成本,最优二分匹配将强制每个图像区域在图像-文本对的全局监督下与其对应的词语对齐。通过用最佳区域-词语对齐损失代替目标检测中的分类损失,我们的方法可以帮助将每个图像区域与相应的词语匹配并完成目标检测任务。

针对以上宗旨,本文提出三大贡献。
- 本文提出了一种开放词汇式目标检测方法VLDet,可以直接从图像-文本对数据中学习区域-词语对齐。
- 本文将区域-词语对齐表述为一个集合匹配问题,并使用匈牙利算法有效地解决它。
- 在两个基准数据集 OV-COCO 和 OV-LVIS 上进行的广泛实验证明了VLDet的卓越性能,尤其是在检测未知类别方面。
三、方法
Recap on Bipartite Matching
在介绍我们的方法前先来回顾一下二分图匹配,假设有 XXX 个工人和 YYY 个工作。 每个工人都有他/她有能力完成的某些工作。 每个工作只能接受一个工人,每个工人只能被任命为一个工作。 因为每个工人都有不同的技能,将工人 xxx 分配执行工作 yyy 所需的成本是 dx,yd_{x,y}dx,y ,目标是确定最佳分配方案,使总成本最小化或团队效率最大化。约束条件是如果有更多的工人,确保每个工作分配给一个工人; 否则,确保每个工人都被分配到一份工作。
Learning Object-Language Alignments from Image-Text Pairs
本文将每个图像区域定义为试图找到最合适的“工人”的“工作”,并将每个文本词语定义为找到最有信心“工作”的“工人”。 在这种情况下,本文的方法从全局角度将区域和词语对齐任务转换为集合到集合的二分匹配问题。图像区域 R=[r1,r2,...,rm]R=[r_1,r_2,...,r_m]R=[r1,r2,...,rm] 和文本词语 W=[w1,w2,...,wn]W=[w_1,w_2,...,w_n]W=[w1,w2,...,wn] 之间的成本定义为对齐分数 S=WRTS = WR^TS=WRT , 然后可以通过匈牙利算法有效地解决二分匹配问题。 匹配后,将得到的区域-词语对作为优化目标,对检测模型的分类分枝通过以交叉熵损失进行优化。
目标词汇表: 本文将目标词汇设置为每个训练批次中图像标题中的所有名词。 从整个训练过程来看,本文的词汇表远大于数据集的标签空间。本文的实验表明,这种设置不仅实现了理想的开放词汇式检测,而且还达到了更好的性能。
Network Architecture
VLDet网络包括三个部分:视觉目标检测器,文本编码器和区域-词语之间的对齐。本文选择了Faster R-CNN作为目标检测模型。 目标检测的第一阶段与Faster R-CNN相同,通过RPN预测前景目标。为了适应开放词汇的设置,VLDet在两个方面修改了检测器的第二阶段:(1)使用所有类共享的定位分支,定位分支预测边界框而不考虑它们的类别。 (2) 使用文本特征替换可训练分类器权重,将检测器转换为开放词汇式检测器。 本文使用固定的预训练语言模型CLIP作为文本编码器。
四、实验
VLDet在OV-COCO和OV-LVIS的未知类上的表现都达到了SoTA,同时表明了从全局角度学习区域-词语对齐的有效性。
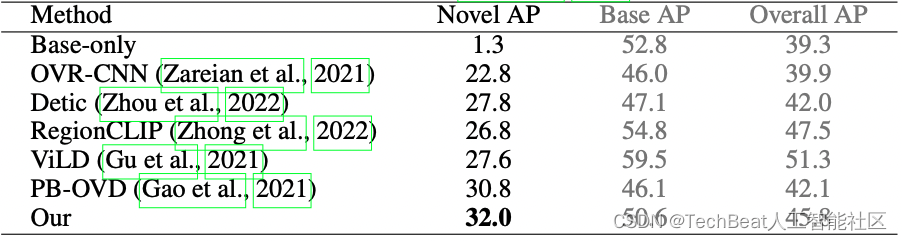
表1. VLDet在OV-COCO基准数据集上的结果。COCO被分为48个已知类和17个未知类,VLDet使用已知类作为检测训练数据和COCO Caption作为图像-文本对训练数据。
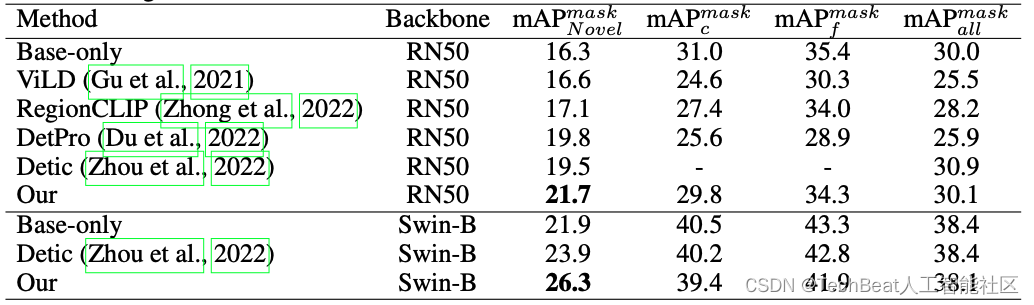
表2. VLDet在OV-LVIS基准数据集上的结果。LVIS被分为866个已知类和337个未知类,VLDet使用已知类作为检测训练数据和CC3M作为图像-文本对训练数据。
One-to-One vs. One-to-Many.
从图像-文本对中提取图像区域-文本词语对的关键是从全局角度优化分配问题。为了进一步研究分配算法的影响,本文考虑了两种全局算法,Hungarian和 Sinkhorn算法,其中前者进行一对一的区域-词语分配,后者提供一个词语-多个区域的分配。 考虑到图像中可能存在同一类别的多个实例,Sinkhorn算法能够为同一个词匹配多个区域,然而同时它也可能引入更多噪声。 从下表中可以观察到一对一分配的表现均优于一对多分配。其中的原因是一对一的分配假设通过为每个单词提供高质量的图像区域来大幅减少错误区域-词语对。

Object Vocabulary Size.
VLDet使用COCO Caption和CC3M中的所有名词并过滤掉低频词,统计共名词词语4764/6250个。我们分析了用不同的词汇量训练我们的模型的效果。我们将目标词汇表替换为 COCO 和 LVIS 数据集中的类别名称,即仅使用文本中的类别名称而不是所有名词。从下表中可以看出,更大的词汇量在 OV-COCO和OV-LVIS的未知类别上分别实现了 1.8% 和 1.5% 的增益,这表明使用大词汇量进行训练可以实现更好的泛化。 换句话说,随着词汇量的增加,模型可以学习更多的目标语言对齐方式,这有利于提高推理过程中的未知类性能。

更多的实现细节和消融实验请查看原文。
五、总结
本文的主要目标是探索开放词汇式的目标检测,希望检测模型以零样本的方式识别任意之前未知的类别。 本文将区域-词语对齐表述为一个集合匹配问题, 并提出了VLDet,模型可以直接从图像-文本对数据中学习区域-词语对齐。 希望本文能够推动 OVOD 的发展方向,并激发更多关于大规模免费图像-文本对数据的工作,从而实现更像人类、开放词汇式的计算机视觉技术。
Illustration by Twin Rizki from IconScout
-The End-
关于我“门”
▼
将门是一家以专注于发掘、加速及投资技术驱动型创业公司的新型创投机构,旗下涵盖将门创新服务、将门-TechBeat技术社区以及将门创投基金。
将门成立于2015年底,创始团队由微软创投在中国的创始团队原班人马构建而成,曾为微软优选和深度孵化了126家创新的技术型创业公司。
如果您是技术领域的初创企业,不仅想获得投资,还希望获得一系列持续性、有价值的投后服务,欢迎发送或者推荐项目给我“门”:
bp@thejiangmen.com
相关文章:
ICLR 2023|VLDet:从图像-文本对中学习区域-词语对齐的开放词汇式目标检测
原文链接:https://www.techbeat.net/article-info?id4614&isPreview1 作者:林闯 目标检测任务在AI工业界具有非常广泛的应用,但由于数据获取和标注的昂贵,检测的目标一直被限制在预先设定好的有限类别上。而在学术界…...
如何效率搭建企业流程系统?试试低代码平台吧
编者按:本文介绍了一款可私有化部署的低代码平台,可用于搭建团队流程管理体系,并详细介绍了该平台可实现的流程管理功能。关键词:可视化设计,集成能力,流程审批,流程调试天翎是国内最早从事快速开发平台研发…...

嵌入式开发:C++在深度嵌入式系统中的应用
深度嵌入式系统通常在C语言中实现。为什么会这样?这样的系统是否也能从C中获益?嵌入式开发人员在将广泛、高效的深度嵌入式代码库从C转换为C方面的实践经验的贡献。嵌入式和深度嵌入式系统通常用C而不是C实现。软件开发人员必须放弃C作为强类型系统、模板元编程(TMP)和面向对…...

快鲸scrm发布快递行业私域运营解决方案
现如今,快递行业竞争格局日益激烈,前有“四通一达”等传统快递企业,后有自带互联网基因、绑定电商流量新贵快递企业,如菜鸟、京东等。在这一背景下,很多快递企业开启了增长破局之旅,他们纷纷搭建起私域运营…...

【蓝桥杯集训·每日一题】AcWing 1497. 树的遍历
文章目录一、题目1、原题链接2、题目描述二、解题报告1、思路分析2、时间复杂度3、代码详解三、知识风暴递归一、题目 1、原题链接 1497. 树的遍历 2、题目描述 一个二叉树,树中每个节点的权值互不相同。 现在给出它的后序遍历和中序遍历,请你输出它的 …...

详解matplotlib的color配置
详解matplotlib的color配置 Matplotlib可识别的color格式 格式举例RGB或RGBA,由[0, 1]之间的浮点数组成的元组,分别代表红色、绿色、蓝色和透明度(0.1, 0.2, 0.5), (0.1, 0.2, 0.5, 0.3不区分大小写的十六进制RGB或RGBA字符串。‘#0f0f0f’, ‘#0f0f0f…...

Oracle删除表数据的三种方式
简介 oracle数据库mysql数据库都是如此 drop命令>truncate命令>delete命令,它们的执行方式、效率和结果各有不同。还是万年的student 学生表 自己可以建个尝试这玩一下。 drop命令 语句: drop table 表名; 理由:1、用drop删除表数据&…...
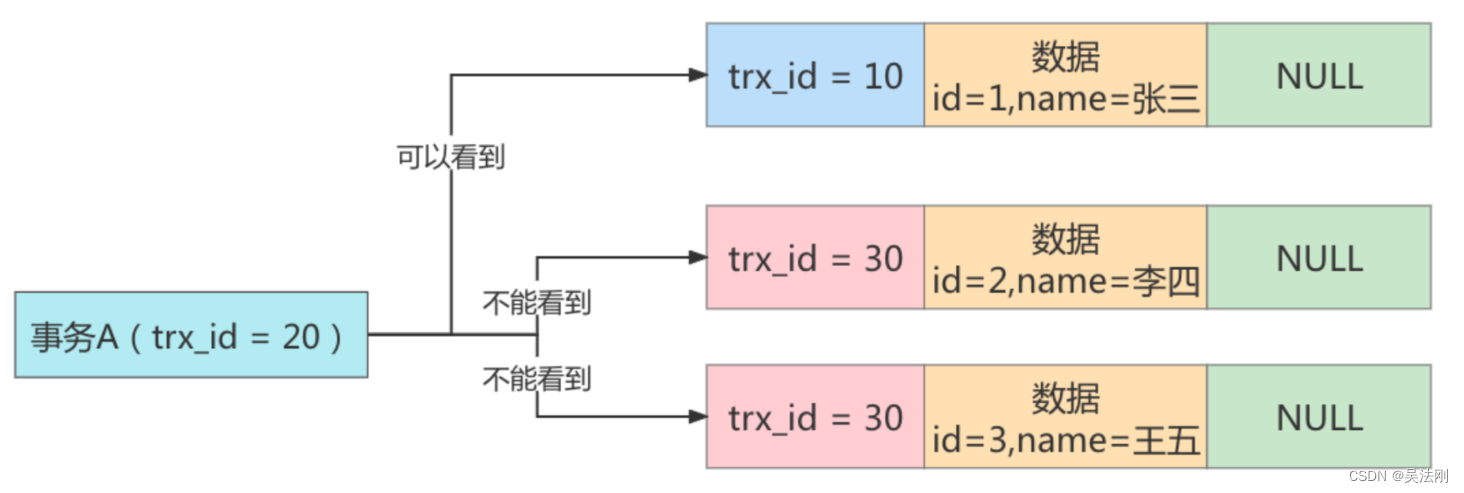
第 16 章_多版本并发控制
第 16 章_多版本并发控制 1. 什么是MVCC MVCC (Multiversion Concurrency Control),多版本并发控制。顾名思义,MVCC 是通过数据行的多个版本管理来实现数据库的并发控制。这项技术使得在InnoDB的事务隔离级别下执行一致性读操作…...

五种 IO 模型
文章目录操作系统和内存内核空间和用户空间应用程序的内核态和用户态网络 IO 和磁盘 IO简易的网络通信流程阻塞和非阻塞阻塞 IO 模型非阻塞 IO 模型IO 复用模型SelectPollEpoll小结信号驱动 IO 模型异步 IO 模型五种 IO 模型的对比IO 模型里的同步和异步5种 IO 模型分别是&…...

34-Golang中的结构体!!!
Golang中的结构体结构体和结构体变量(实例)的区别和联系结构体变量(实例)在内存中的布局如何声明结构体字段/属性注意事项和细节说明创建结构体实例的四种方式结构体使用细节结构体和结构体变量(实例)的区别和联系 1.结构体是自定义的数据类型,代表一类事物2.结构体…...

这6个视频剪辑素材库,你一定要知道~
推荐5个免费商用视频素材网站,建议收藏哦! 1、菜鸟图库 视频素材下载_mp4视频大全 - 菜鸟图库 网站素材量很大,有设计、图片、音频、视频等超多素材,大部分都能免费下载。视频素材都很高清,有自然、人物、科技、农业…...

RocketMQ WIN11 搭建
去官方下载 https://rocketmq.apache.org/zh/download/ 下载,博主下载的是 4.6.0 的版本,选择Binary版本 拓展 Source 下载:需要编译 Binary 下载:不需要编译 解压缩,运行 先解压缩环境变量中添加rocketMQ文件夹路…...
iPhone更换电池和屏幕后提醒非原厂配件的操作办法
---开局一张图,内容全靠编系列! 【图】 自从在iPhone系统iOS13开始支持原厂配件检测后,可以说苹果也动起了维修站商家利益的这块蛋糕。道理自然简单,卷嘛!全球汽车行业也不是靠卖新车才赚钱的,各种交通事故…...

chatGPT发布记录
发行说明(2 月 13 日)我们对 ChatGPT 进行了多项更新!这是新功能:我们更新了免费计划中 ChatGPT 模型的性能,以便为更多用户提供服务。根据用户反馈,我们现在默认让 Plus 用户使用更快的 ChatGPT 版本&…...
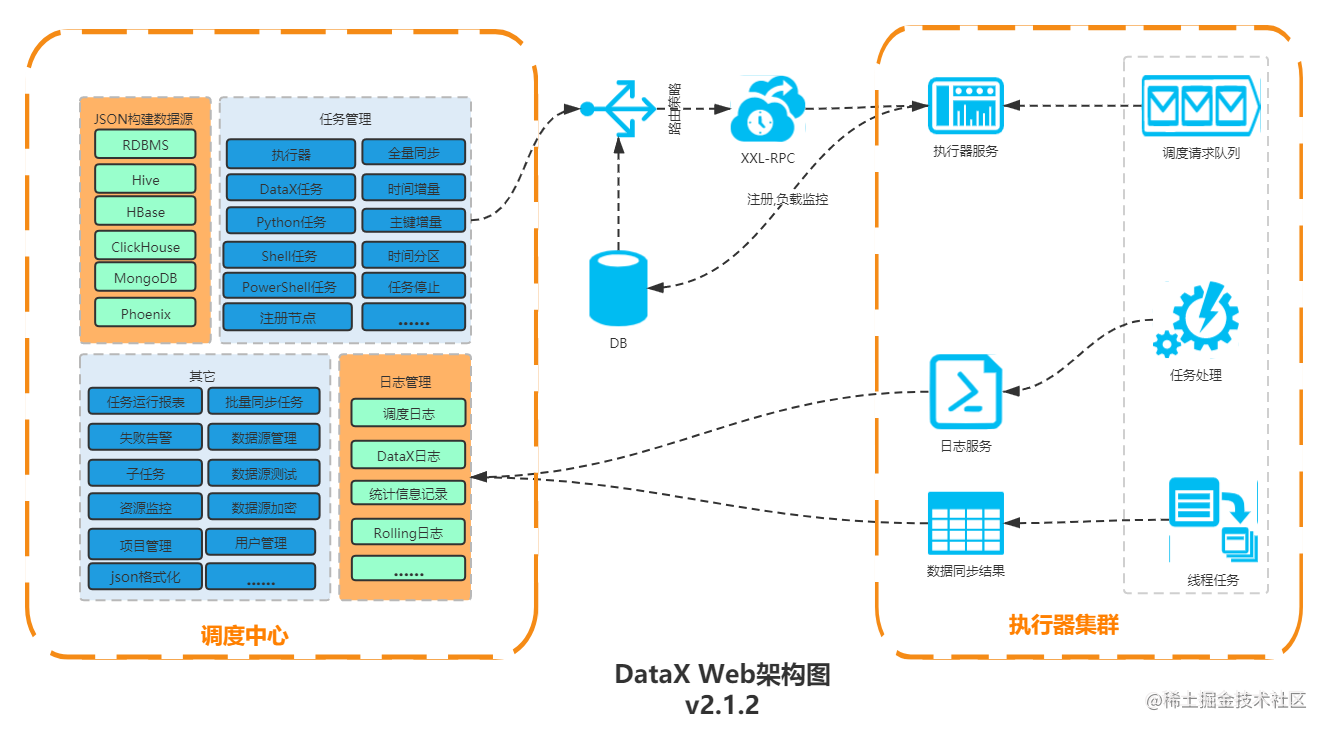
DataX及DataX-Web
大数据Hadoop之——数据同步工具DataX数据采集工具-DataX datax详细介绍及使用 一、概述 DataX 是阿里云DataWorks数据集成的开源版本,在阿里巴巴集团内被广泛使用的离线数据同步工具/平台。DataX 实现了包括 MySQL、Oracle、OceanBase、SqlServer、Postgre、HDFS、…...

数据结构与算法系列之kmp算法
什么是kmp算法 1.kmp算法是一种改进的字符串算法,其核心是利用匹配失败后的信息,尽量减少模式串与主串的匹配次数已达到快速匹配的目的。 它主要实现作用的是 在 (主串)中找到 (匹配)字符串。 例 BF算法与k…...

算法分析详解
自古老的公元前1世纪开始,《周髀算经》就作为中国最古老的天文学和数学著作。 《周髀算经》采用最简便可行的方法确定天文历法,揭示日月星辰的运行规律,包括四季更替,气候变化,南北有极,昼夜相推的道理。为…...

东南大学自然辩证法概论期末总结
写在前面 作者:夏日 博客地址:https://blog.csdn.net/zss192 本文为2022年东南大学自然辩证法概论期末总结,内容为根据老师所发题纲综合多个资料总结得来 考试形式:从老师所发题纲,10个题目中选出4个,题…...

《爆肝整理》保姆级系列教程python接口自动化(二十)--token登录(详解)
简介 为了验证用户登录情况以及减轻服务器的压力,减少频繁的查询数据库,使服务器更加健壮。有些登录不是用 cookie 来验证的,是用 token 参数来判断是否登录。token 传参有两种一种是放在请求头里,本质上是跟 cookie 是一样的&…...
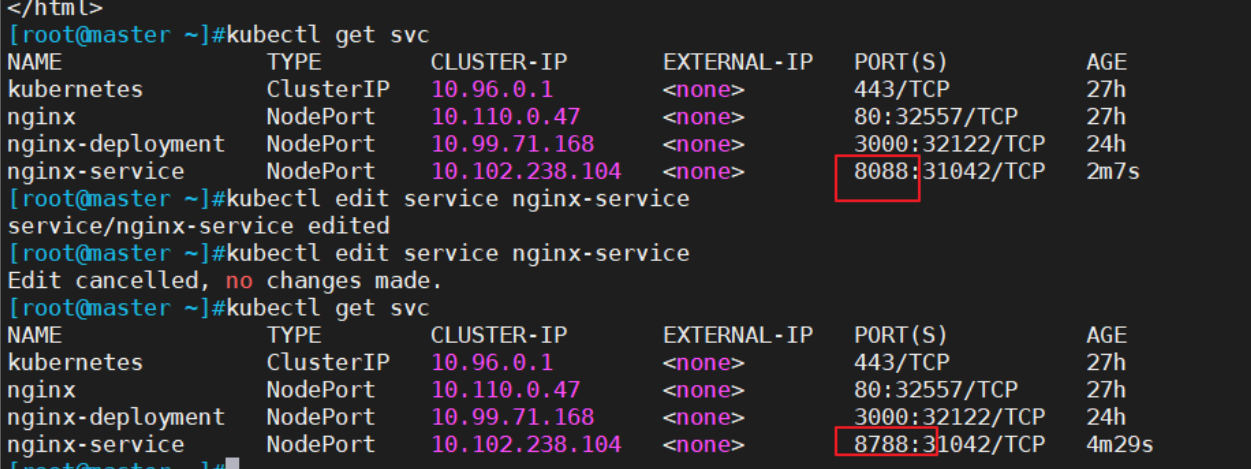
k8s种的kubectl命令
一.kubectl基本命令1.1 称述式资源管理的方法kubernetes集群管理集群资源的唯一入口是通过相应的方法调用apiserver的接口kubectl是官方的CLI命令行工具,用于与apiserver进行通信,将用户在命令行输入的命令,组织并转化为apiserver能识别的信息…...

四旋翼变形控制:RL与MPC在混合动力学中的对比
1. 四旋翼变形控制的技术挑战与解决方案四旋翼变形控制(Quadrotor Morpho-Transition)是当前机器人领域最具挑战性的前沿技术之一。这项技术使机器人能够在空中完成形态变换,实现从飞行模式到地面模式的平滑切换。想象一下,一架四…...

DeepSeek代码质量评估实战手册:7步完成从混沌到可度量的质变跃迁
更多请点击: https://kaifayun.com 第一章:DeepSeek代码质量评估的底层逻辑与核心价值 DeepSeek代码质量评估并非简单地统计行数或检测语法错误,而是基于多维语义理解构建的推理系统。其底层逻辑融合了静态分析、符号执行与大语言模型生成式…...
)
Windows10下V-REP教育版安装保姆级教程(附百度网盘资源与避坑点)
Windows10系统V-REP教育版完整安装指南:从下载到实战避坑在机器人仿真和自动化控制领域,V-REP(现更名为CoppeliaSim)作为一款功能强大的跨平台机器人仿真软件,已经成为众多工科学生和研究人员的首选工具。特别是其教育…...

【MySQL数据库 | 第一篇】 概述
数据库相关概念: 数据库(Database):数据库是指一组有组织的数据的集合,通过计算机程序进行管理和访问。数据库管理系统:操纵和管理数据库的大型软件SQL:操作关系型数据库的编程语言,定义了一套操作关系型数…...

为什么鸿蒙 App 最终都会走向状态驱动?
子玥酱 (掘金 / 知乎 / CSDN / 简书 同名) 大家好,我是 子玥酱,一名长期深耕在一线的前端程序媛 👩💻。曾就职于多家知名互联网大厂,目前在某国企负责前端软件研发相关工作,主要聚…...

AI IDE 革命:程序员正在被重新定义
很多开发者第一次使用 Cursor 的 CtrlK 或 Composer(高级多文件编辑模式)时,都会有一种强烈的、甚至让人有些脊背发凉的冲击感。 因为: 它已经不再是那个我们熟悉的、只能在原地等待光标落下的: “代码自动补全插件&am…...

基于IRS2092的200W D类功放设计:从PWM原理到保护电路实战
1. 项目概述与核心思路折腾音响功放,从经典的AB类玩到D类,感觉就像是从燃油车换到了电动车,动力响应和效率完全是两个维度。这次要聊的这块“200W Class-D Audio Power Amplifier [150115]”单板功放,就是一个非常典型的D类功放设…...

用图神经网络做缺陷定位,准确率比传统方法高出30%
在现代软件工程的复杂迷宫中,缺陷定位始终是测试团队面临的核心挑战。想象这样一个场景:一个电商系统在特定压力条件下偶发订单丢失,日志中只留下泛泛的超时错误,问题可能深藏在上百个微服务的调用链、分布式事务的竞态条件或某个…...

多模型聚合平台如何助力网站AIB测试与选型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 多模型聚合平台如何助力网站AIB测试与选型 对于网站产品经理而言,首页文案的生成质量直接影响用户的第一印象和转化率。…...

基于PGA2311的树莓派Hi-Fi模拟音量控制器设计与实现
1. 项目概述:为树莓派DAC打造的高品质模拟音量控制器玩过树莓派音频播放器的朋友都知道,用上像PCM1794A这类高性能DAC芯片后,音质确实能上一个台阶,但有个不大不小的麻烦:这类芯片本身不带音量控制。软件调音量&#x…...