Mysql的page,索引,Explain Type等基本常识
Mysql的基本问题
Mysql 为什么建议使用自增id?
- 因为id(主键)是自增的话,那么在有序的保存用户数据到页中的时候,可以天然的保存,并且是在聚集索引(id)中的叶子节点可以很好的减少插入和移动操作,可以提高效率。
- int或者bigInt占用的字符不是很大,并且方便保存或者建立索引
什么是回表?
索引分为两种
- primary index,通常也是clustered index(聚集、聚簇索引),它的叶子节点会保存实际的物理数据
- secondary index,通常也是辅助索引,非聚集索引,它叶子几点保存为主键,而不是实际的物理数据,一般来说除了主键索引,一般都是这个,因为为了降低索引的成本而设计的
如果通过secondary index查出了需要的数据行,但是在secondary index中没有需要的列怎么办呢?那就只能获取id,然后在primary index中去读取全部数据了,这个过程叫做回表。
什么是索引覆盖
和回表相比,假设查询的属性列都在secondary index中呢?我们还需要回表操作吗?显然不需要,那么这个时候呢?secondary index的工作覆盖了primary index的工作,这就叫索引覆盖,Explain中的extra通常会显示using index

什么是ICP?(index condition pushdown)
Index Condition Pushdown (ICP) is an optimization for the case where MySQL retrieves rows from a table using an index. Without ICP, the storage engine traverses the index to locate rows in the base table and returns them to the MySQL server which evaluates the WHERE condition for the rows. With ICP enabled, and if parts of the WHERE condition can be evaluated by using only columns from the index, the MySQL server pushes this part of the WHERE condition down to the storage engine. The storage engine then evaluates the pushed index condition by using the index entry and only if this is satisfied is the row read from the table. ICP can reduce the number of times the storage engine must access the base table and the number of times the MySQL server must access the storage engine.
如果没有ICP,那么正常流程是这样的
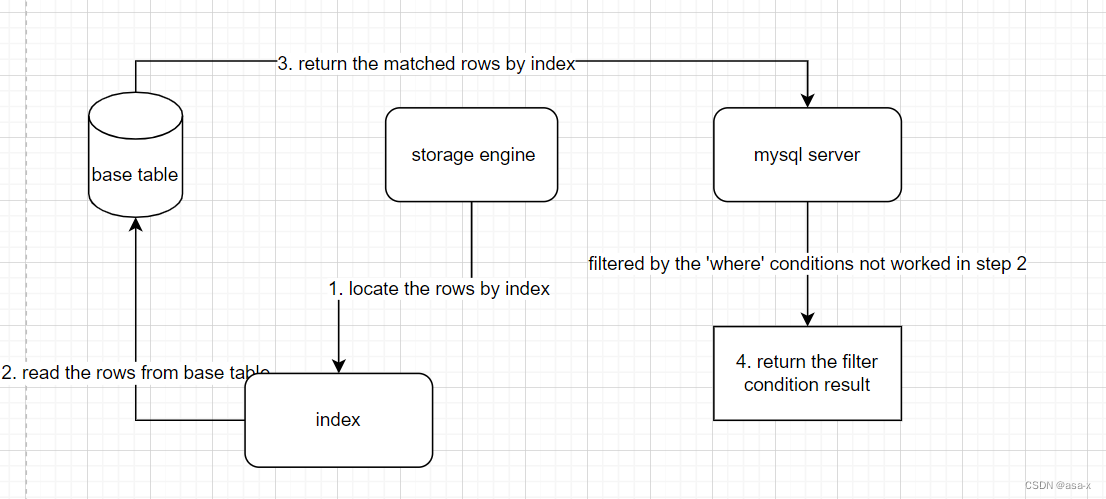
ICP优化下,流程是这样的
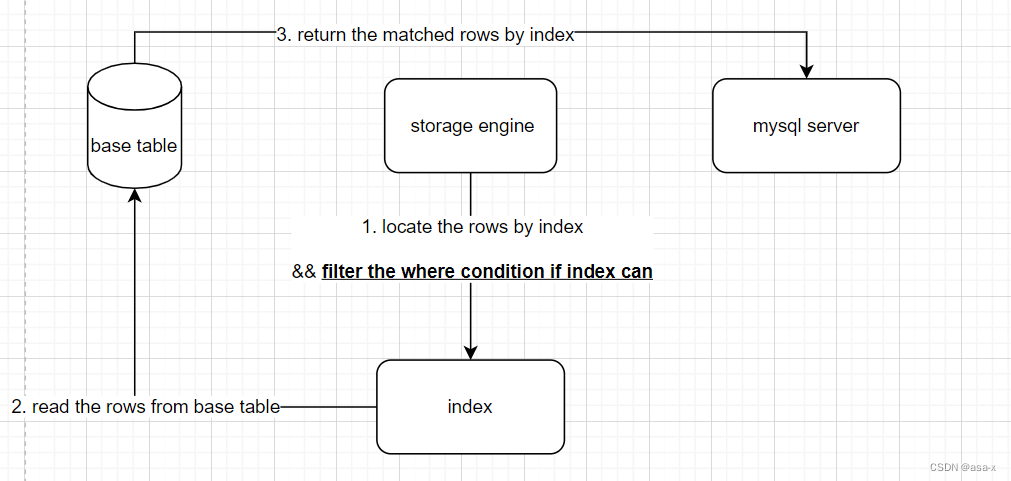
简单来说,就是如果index中存在where的过滤条件中的列但是因为最左原则或者其他的原因,导致index不能直接匹配的条件过去是先通过索引找到列,在放到缓存里过滤,现在这个过滤过程,放在index匹配的过程中了,匹配完再去表读取数据,这样就提升了读取速度。
但这个通常是有条件的:
- ICP is used for the range, ref, eq_ref, and ref_or_null access methods when there is a need to access full table rows. (需要回表操作)
- For InnoDB tables, ICP is used only for secondary indexes. The goal of ICP is to reduce the number of full-row reads and thereby reduce I/O operations. For InnoDB clustered indexes, the complete record is already read into the InnoDB buffer. Using ICP in this case does not reduce I/O. (需要辅助索引)
- Conditions that refer to subqueries cannot be pushed down.(子查询无法下沉)
有其他条件参考 ICP
Explain下type的类型
mysql explain type 访问类型解读
type显示的是访问类型,是一个较为重要的指标,值从优到劣分别为: system > const > eq_ref > ref > range > index > all
-
system
访问类型最高的,属于const类型的特例,表只有一条记录行(=系统表),一般不会出现这个,可以忽略. -
const
表示通过索引一次就能找到, const 用于比较primary或者unique(值是唯一的).因为只匹配一条数据,所以很快. 如果将主键置于where 子句中,mysql就能将该查询转为一个常量

-
eq_ref
唯一性索引扫描,对于每个索引建,表中只有一条记录与之对应,常见于唯一扫描或索引扫描.
与const不同的是eq_ref用于联合表的查询.读取连接表的一行,是system,const之外最好的连接类型.
SELECT * FROM bt_order left JOIN mt_user on (mt_user.id = bt_order.user_id)

It shows that one row is fetched from this table for each combination of rows of the previous table. If all the parts of the primary index or the unique not null index are used to fetch the data then the type is eq_ref
更偏重于表示一行数据通过了主键或者索引来锁定了这样的一个概念,而且这里会有个连表或者其他的组合‘combine’概念
- ref
非唯一索引扫描,返回匹配某个单独值的所有行.本质上也是一种索引访问,返回匹配单个值的所有行. 他可能会找到多个符合条件的行,所以说索引应该属于查找与扫描的混合体

The ref access method is slightly less efficient than const, but still an excellent choice if the right index is in place. Ref access is used when the query includes an indexed column that is being matched by an equality operator. If MySQL can locate the necessary rows based on the index, it can avoid scanning the entire table, speeding up the query considerably.
注意看到了吗? by an equality operator,表示用 =,如果不是话可能就会不同了

5. range
只检索给定范围的行,返回匹配指定区间的所有行,一般就是你的where子句中出现了如 between and , in , <,>等 的这种查询. 这种范围扫描的索引扫描比全表扫描要好,因为他只用开始于索引的某一点,结束与索引的某一点,不用扫描全部索引

When you use range in the where clause, MySQL knows that it will need to look through a range of values to find the right data. MySQL will use the B-Tree index to traverse from the top of the tree down to the first value of the range. From there, MySQL consults the linked list at the bottom of the tree to find the rows with values in the desired range. It’s essential to note that MySQL will examine every element in the range until a mismatch is found, so this can be slower than some of the other methods mentioned so far
上面有个概念:遍历直到不匹配,所以会性能比不过上面的几个
- index
Full index Scan ,与all 不同的是,index 为index类型只遍历索引数,这通常比all快,因为索引文件通常比数据文件小. 也就是说虽然all和index都是读全表,但是index是从index中读取的,而all是从磁盘读取的.
The index access method indicates that MySQL is scanning the entire index to locate the necessary data. Index access is the slowest access method listed so far, but it is still faster than scanning the entire table. When MySQL cannot use a primary or unique index, it will use index access if an index is available.

cannot use a primary or unique index, it will use index access if an index is available 这是指主键或者唯一键不可以使用+读取的属性列(necessary data)在索引中,不需要回表,否则会变成all

7. all
Full table Scan , 全表扫描,将遍历全表以找到匹配的行

性能最低的,没什么好说的。
附录:
Explain的各个字段的意义
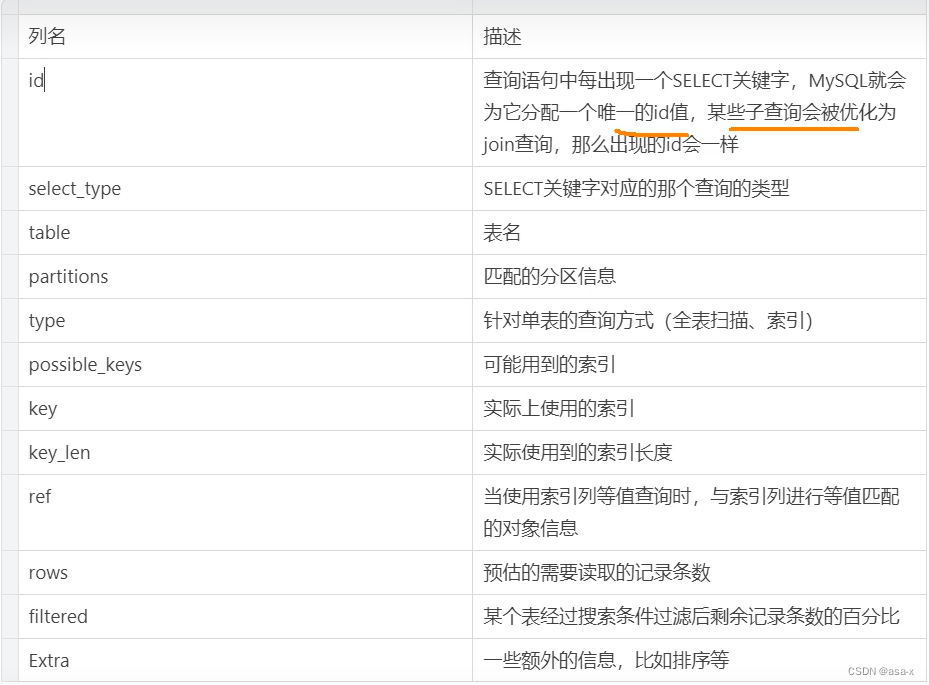
Extra的一些可能存在的信息
Mysql的基本结构
Page
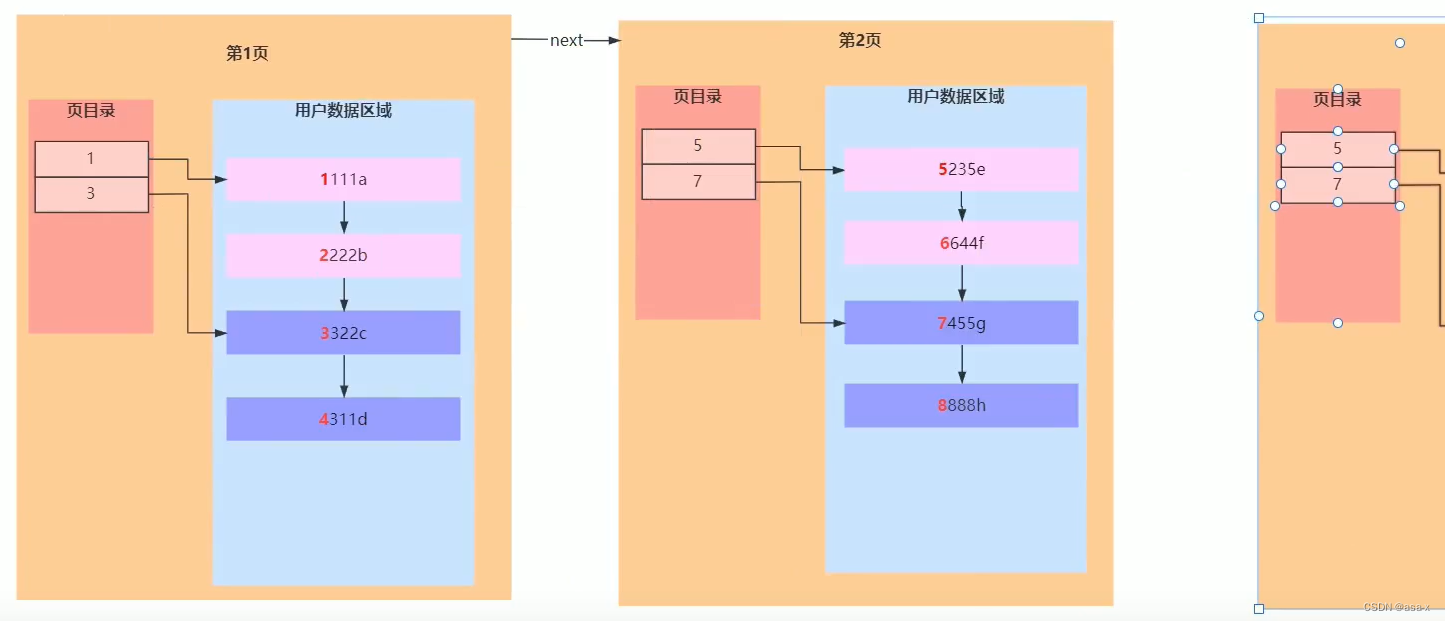
通常为了提高列表的查询速度,我们会简历目录来分组,同时指定对应的地址坐标
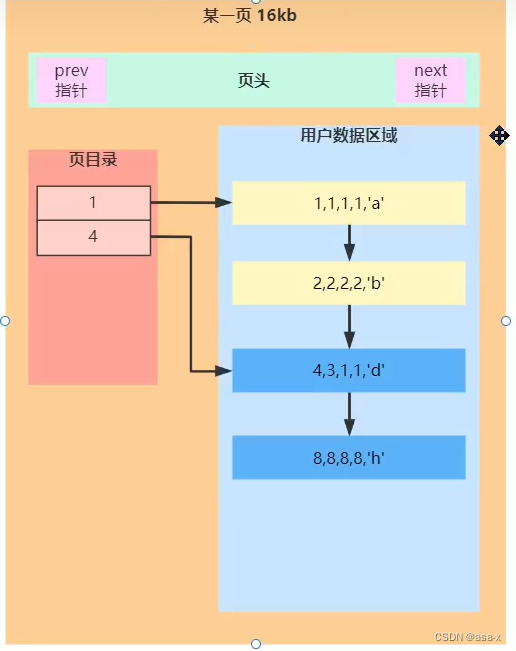
建立页目录的思想和文章目录,redis zset中的skipList的逻辑大差不差,只是不是树结构而已,但本质上依然是分治思想。
- 用户数据区,会通过主键来排序,所以,自增id会是很好的,效率比较高的主键选择方案
- 每页保存的数据条数是有限的,可以粗略的计算,假设为每条数据大小为1k,那么一页大概能保存16/1 = 16条数据
- 每页都有指向下一页和上一页的地址指针。
如何基于page来建立索引?
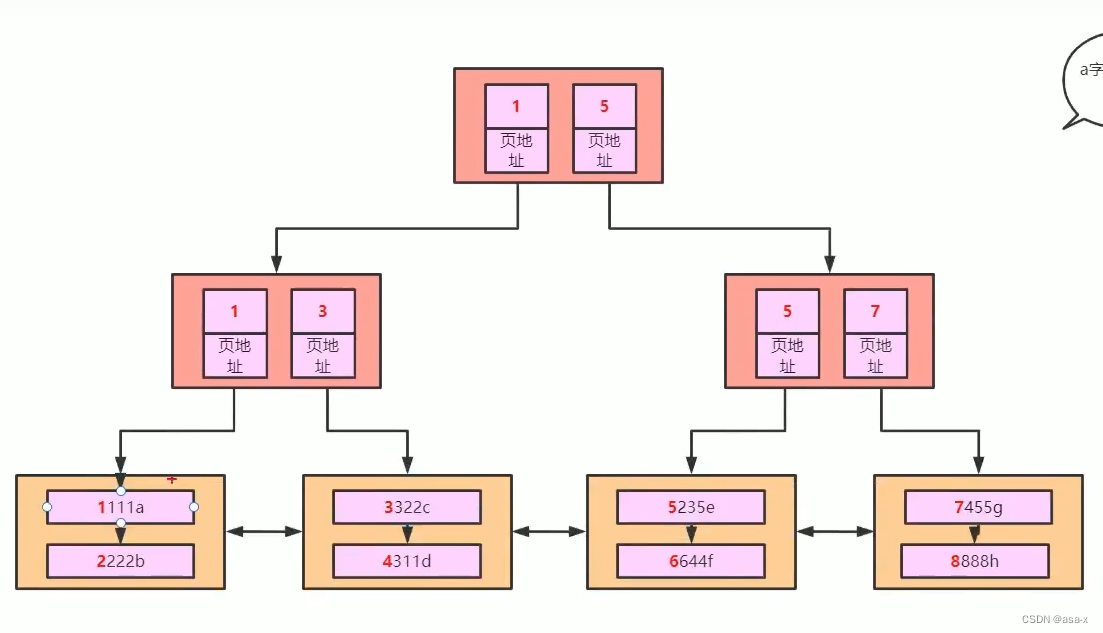
我们都知道叶子节点是数据(对于聚集索引来说),那么我们该如何建立索引呢?假设当前的实际数据页如下:
基于页的目录来说,我们可以提取一层索引(当前是基于聚集索引),建立索引的过程为,我们会在索引页中保存每个叶子结点的开始id(int=4b)和地址指针(6b)
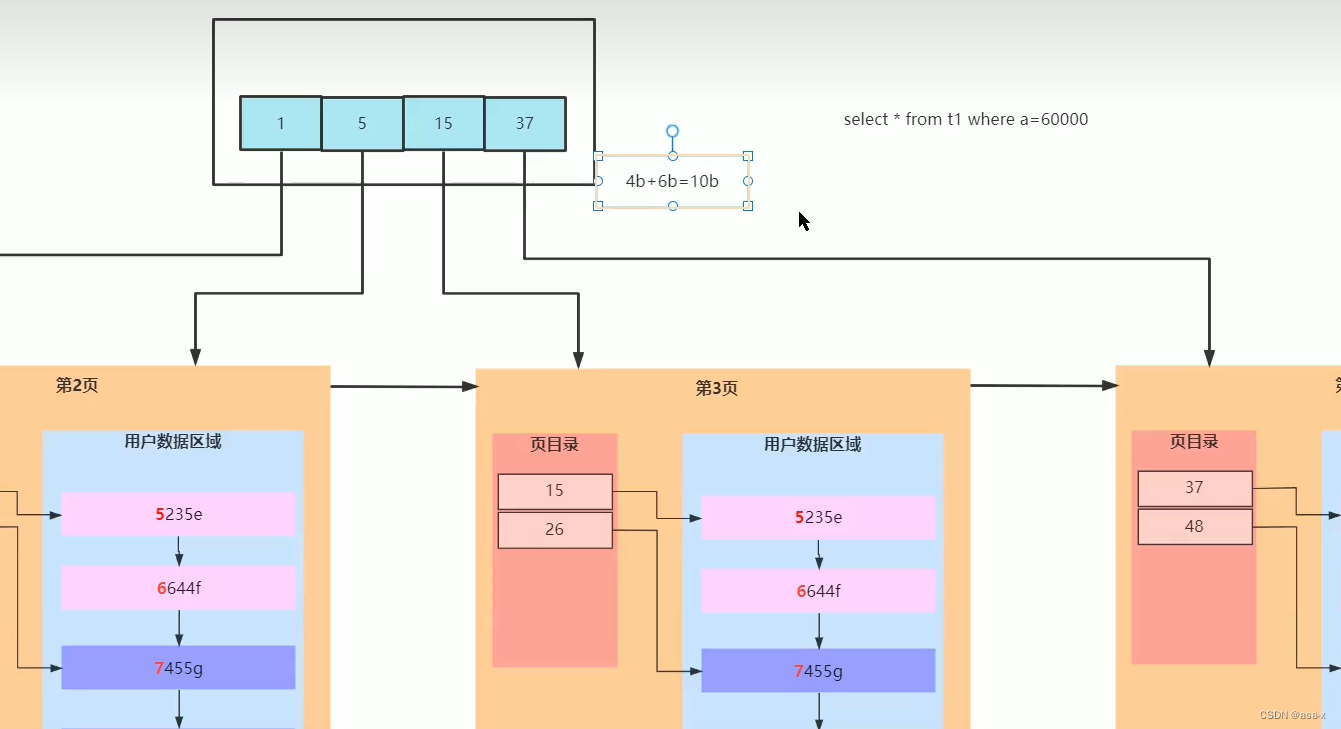
那么 一页的索引可以保存多少条索引数据呢?
16k/10b = 161024/10 = 1638
所以,如果是只有两层的索引的话,那么只能保存1638 * 16条数据,这显然是不够的,为了提升索引支持的数据,我们再加 一层,也就是三层,因为加的索引页结构是不变的,那么root的索引页可以保存 16k/10 = 1638个索引数据,总结起来就是
16381638*16 = 42928704,约4kw条数据,但是这是理想状态下,正常来说是约为2kw条数据左右。
相关文章:
Mysql的page,索引,Explain Type等基本常识
Mysql的基本问题 Mysql 为什么建议使用自增id? 因为id(主键)是自增的话,那么在有序的保存用户数据到页中的时候,可以天然的保存,并且是在聚集索引(id)中的叶子节点可以很好的减少插…...

【业务功能篇95】web中的重定向与转发
web接口的返回值: 转发: return “/reg” 跳转到reg的html页面 重定向 return “redirect:/login.html” 重定向重新发起请求路径是 login.html 比如我们写的接口 requestmap("/login.html")的的这个请求地址,重新请求 …...

IP对讲终端SV-6005带一路2×15W或1*30W立体声做广播使用
IP对讲终端SV-6005双按键是一款采用了ARMDSP架构,接收网络音频流,实时解码播放;配置了麦克风输入和扬声器输出,SV-6005带两路寻呼按键,可实现对讲、广播等功能,作为网络数字广播的播放终端,主要…...
ES6 新特性
🎄欢迎来到边境矢梦的csdn博文🎄 🎄本文主要梳理前端技术的JavaScript的知识点ES6 新特性文件上传下载🎄 🌈我是边境矢梦,一个正在为秋招和算法竞赛做准备的学生🌈 🎆喜欢的朋友可以…...

grafana用lark发告警python3接口
1.先在lark群聊里面创建机器人,并获取机器人链接。 2.后台运行下面python3脚本。 3.在grafana添加告警通道,设置告警。 # !/usr/bin/env python # _*_ coding: utf-8 _*_from flask import Flask, request,jsonify #import smtplib #from email.mime.te…...
Java 中数据结构HashSet的用法
Java HashSet HashSet 基于 HashMap 来实现的,是一个不允许有重复元素的集合。 HashSet 允许有 null 值。 HashSet 是无序的,即不会记录插入的顺序。 HashSet 不是线程安全的, 如果多个线程尝试同时修改 HashSet,则最终结果是…...

vue3下的密码输入框(antdesignvue)
参考:vue下的密码输入框 注意:这是个半成品,有些问题(input输入框加了文字间距letter-spaceing,会导致输入到第6位的时候会往后窜出来一个空白框、光标位置页会在数字前面),建议不采用下面这种方式,用另外的(画六个input框更方便) 效果预览 实现思路 制作6个小的正方…...
鸿鹄企业工程项目管理系统 Spring Cloud+Spring Boot+前后端分离构建工程项目管理系统源代码
鸿鹄工程项目管理系统 Spring CloudSpring BootMybatisVueElementUI前后端分离构建工程项目管理系统 1. 项目背景 一、随着公司的快速发展,企业人员和经营规模不断壮大。为了提高工程管理效率、减轻劳动强度、提高信息处理速度和准确性,公司对内部工程管…...
【爬虫】5.5 Selenium 爬取Ajax网页数据
目录 AJAX 简介 任务目标 创建Ajax网站 创建服务器程序 编写爬虫程序 AJAX 简介 AJAX(Asynchronous JavaScript And XML,异步 JavaScript 及 XML) Asynchronous 一种创建交互式、快速动态网页应用的网页开发技术通过在后台与服务器进行…...
thinkphp6 入门(3)--获取GET、POST请求的参数值
一、Request对象 thinkphp提供了Request对象,其可以 支持对全局输入变量的检测、获取和安全过滤 支持获取包括$_GET、$_POST、$_REQUEST、$_SERVER、$_SESSION、$_COOKIE、$_ENV等系统变量,以及文件上传信息 具体参考:https://www.kanclou…...

JSON简介
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式。它使用简洁的文本表示来存储和传输结构化数据。JSON数据由键值对组成,用逗号分隔。键是字符串,值可以是字符串、数字、布尔值、数组、对象或者null 1、JSON的优点 …...

[Java]_[初级]_[以SAX流的方式高效读取XML大文件]
场景 XML文件作为默认utf8格式的文件,它的作用和JSON文件相当。比如可以做为简单的数据存储格式,配置文件,网站的sitemap.xml导航等。它比json强的一点是它还有样式描述文件dtd,可以实现让XML里的结构化数据显示表格样式。 <?xml versi…...

Visual Studio中平台和配置的概念
在 Visual Studio 中,“平台”(Platform)和 “配置”(Configuration)是用于管理项目构建和设置的两个关键概念。在 “解决方案配置管理器” 中设置和管理 平台(Platform): 指项目构…...

【vue2第八章】工程化开发和使用脚手架和文件结构
vue工程化开发 & 使用脚手架VUE CLI: 1,核心包传统开发模式:基于js/html/css直接引入核心包开发vue。 2,工程化开发。基于构建工具如(webpack)的环境中开发vue。 vue cli是什么: vue cli是一个vue官方提供的一个…...

建造者模式简介
概念: 建造者模式(Builder Pattern)是一种创建型设计模式,用于将复杂对象的构建过程与其表示分离。它允许您逐步构造一个复杂对象,同时保持灵活性和可读性。 特点: 将对象的构建过程封装在指导者类中&am…...

虚拟世界指南:从零开始,一步步教你安装、配置和使用VMware,镜像ISO文件!
本章目录 CentOS简介镜像下载一、新建虚拟机(自定义)1、进入主页,在主页中点击“创建新的虚拟机”2、点击创建虚拟机创建自己的虚拟机。可以选择自定义3、在“硬件兼容性(H)中选择:Workststion 15.x” ->下一步4、选择“稍后安…...

服务器卡顿怎么查找原因?
虽然服务器出现卡顿的现象比较少见,但也不排除出现的可能,而服务器一旦出现卡顿,造成的后果会严重的多。这里分享点笔记,希望有所帮助 1. 性能评估: 首先,对服务器的性能进行全面评估。检查 CPU 使用率、内存占用、磁…...

Pnpm,npm,yarn
npm 最初的npm只是简单的通过依赖去递归安装包,所以说每个依赖都会有自己的node_modules,node_modules是嵌套的。一个项目会存在多个包,多个包之间难免会有公共的依赖,node_modules嵌套的话,这样公共依赖就会下载多次。会造成磁盘…...

Kubernetes技术--使用kubeadm快速部署一个K8s集群
这里我们配置一个单master集群。(一个Master节点,多个Node节点) 1.硬件环境准备 一台或多台机器,操作系统 CentOS7.x-86_x64。这里我们使用安装了CentOS7的三台虚拟机 硬件配置:2GB或更多RAM,2个CPU或更多CPU,硬盘30GB或更多 2.主机名称和IP地址规划 3. 初始化准备工作…...
LeetCode 45题:跳跃游戏
题目 给定一个长度为 n 的 0 索引整数数组 nums。初始位置为 nums[0]。 每个元素 nums[i] 表示从索引 i 向前跳转的最大长度。换句话说,如果你在 nums[i] 处,你可以跳转到任意 nums[i j] 处: 0 < j < nums[i] i j < n 返回到达 nums[n - …...

空馈方法导向的高增益天线方法【附模型】
✨ 长期致力于环焦反射面、反射阵、透射阵、相位效率、宽带、高效率、低剖面、口径场叠加、轨道角动量研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)…...

保姆级教程:用STM32F103ZET6+超声波+红外模块,从零搭建一个能报警的智能循迹小车
从零构建STM32智能循迹避障小车的全流程实战指南 在创客教育和嵌入式开发领域,智能小车一直是入门学习的经典项目。它不仅融合了传感器技术、电机控制和嵌入式编程等核心知识点,更能让学习者在完成一个完整产品的过程中获得成就感。本文将手把手带你使用…...

OpCore Simplify:一键生成OpenCore EFI的终极解决方案
OpCore Simplify:一键生成OpenCore EFI的终极解决方案 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 还在为黑苹果配置的复杂流程头疼吗&…...

【AI面试八股文 Vol.3.5:推理幻觉规模定律】CoT、幻觉与 Scaling Law:为什么模型会推理,也会一本正经胡说
摘要:这篇会把 CoT、幻觉和 Scaling Law 放到同一条工程主线上:CoT 不是教模型思考,而是触发模型把隐式路径显式写出来;幻觉不是单一 bug,而是训练知识边界、解码策略和指令跟随压力叠加后的结果;Scaling L…...

多卡训练加速:HCCL 集合通信实战
前言 单卡训练慢,多卡又踩坑——梯度同步怎么配、拓扑怎么选、带宽怎么压满,这些细节决定分布式训练能不能真正提速。 HCCL(Huawei Collective Communication Library)是昇腾的多卡通信库,对标 NVIDIA 的 NCCL。它封装…...

IntelliJ IDEA 2023.3 集成 Maven 3.8.3 保姆级避坑指南:从环境变量到项目构建全流程
IntelliJ IDEA 2023.3 与 Maven 3.8.3 深度集成实战:从零构建企业级Java项目 作为一名长期使用IntelliJ IDEA进行Java开发的工程师,我深刻体会到Maven与IDE无缝集成的重要性。每次新版本发布,那些看似简单的配置背后往往隐藏着令人头疼的兼容…...

Splunk紧急推送安全补丁:三枚高危漏洞同时曝光,企业数据面临泄露与瘫痪双重风险
2026年5月20日,Splunk官方安全团队一次性披露了旗下多款核心产品的重大安全隐患。此次波及范围相当广泛,从本地部署的Splunk Enterprise到云端服务Splunk Cloud Platform,再到新推出的Splunk AI Toolkit,无一幸免。三枚漏洞编号分…...

洛雪音乐音源终极指南:3步解锁全网无损音乐自由
洛雪音乐音源终极指南:3步解锁全网无损音乐自由 【免费下载链接】lxmusic- lxmusic(洛雪音乐)全网最新最全音源 项目地址: https://gitcode.com/gh_mirrors/lx/lxmusic- 还在为音乐平台会员费烦恼?或是被不同平台的独家版权搞得晕头转向ÿ…...

Infineon C167芯片Flash编程与MEMTOOL使用指南
1. C167系列芯片片上Flash编程方法解析在嵌入式系统开发中,片上Flash编程是每个工程师都需要掌握的核心技能。对于使用Infineon C167系列微控制器的开发者来说,了解如何可靠地编程片上Flash存储器尤为重要。本文将详细介绍使用MEMTOOL工具进行C167芯片Fl…...

Taotoken官方折扣活动如何帮助开发者降低大模型使用门槛
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken官方折扣活动如何帮助开发者降低大模型使用门槛 对于个人开发者和学生群体而言,探索和应用大模型技术时&#…...