使用多线程std::thread发挥多核计算优势(解答)
使用多线程std::thread发挥多核计算优势(题目)
单核无能为力
如果我们的电脑只有一个核,那么我们没有什么更好的办法可以让我们的程序更快。
因为这个作业限制了你修改算法函数。你唯一能做的就是利用你电脑的多核。
使用多线程
由于我们的电脑有多个内核,所以,我们可以创建多线程来把任务“平均”分配给多个核来计算。
这样多个核在“同时”运算的时候就可以加速程序的执行。
多核的细节
关于我们创建多少个线程比较合适,多个线程真的可以各自分配到多个核而“同时”运行吗?
试一下就知道了。
双线程的效果
我们先用两个线程,把任务固定的分配给这两个线程,看看完成任务总的执行时间是不是变短了。
代码如下:
#include <iostream>
#include <cmath>//sqrt
#include <iostream>
#include <iomanip>//format output
#include <chrono>
#include <thread>//for faster code
#include <mutex>//for faster code
#include <sstream>//stringstream
using namespace std::chrono;//time_piont duration
using namespace std;//test helper function begin 测试辅助代码开始
void check_do(bool b, int line = __LINE__)
{if (b) { cout << "line:" << line << " Pass" << endl; }else { cout << "line:" << line << " Ohh! not passed!!!!!!!!!!!!!!!!!!!!!!!!!!!" << " " << endl; exit(0); }
}
#define check(msg) check_do(msg, __LINE__);
//test helper function end 测试辅助代码结束//do not change this function! 不要修改这个函数
//if you want to check a number is prime number or not, you can use this function only.
//判断素数只能用这个函数
bool is_number_prime(int n)
{if (n == 2 || n == 3)//prime less than 5{return true;//is prime}if (n % 6 != 5 && n % 6 != 1)//is not prime{return false;}int cmb = (int)std::sqrt(n);for (int i = 5; i <= cmb; i += 6){if (n % i == 0 || n % (i + 2) == 0){return false;//is not prime}}return true;//is prime
}/*100以内的素数 primes within 1002 3 5 7 11 13 17 19 23 29 31 37 41 43 47 53 59 61 67 71 73 79 83 89 97
*/
//测试判断素数的函数是否正确
void test_is_prime_number(void)
{stringstream ss;for (int i = 2; i < 100; i++){if (is_number_prime(i)){ss << i << " ";}}check(ss.str() == "2 3 5 7 11 13 17 19 23 29 31 37 41 43 47 53 59 61 67 71 73 79 83 89 97 ");
}//do not change this function!
//不要修改此函数
long long test_the_sum_of_all_primes_within(long long scale)
{auto start = system_clock::now();long long sum = 0;for (int n = 2; n <= scale; n++) {if (is_number_prime(n)) {sum += n;}}cout << "the sum of all primes from 2~"<< setw(10) << scale << " is : " << setw(15) << sum<< ", elapled " << setw(10) << static_cast<long long>(duration<double, milli>(system_clock::now() - start).count()) << " milliseconds"<< endl;return sum;
}
//please change this function to let your program faster by use multi core in your CPU.
//请重新实现此函数以让你的CPU多核优势得到发挥
//hint: maybe you can use multi thread technology to let your code faster.
//提示:你可以使用多线程来发挥多核的计算优势从而让你的程序跑的更快
long long faster_test_the_sum_of_all_primes_within(long long scale)
{auto start = system_clock::now();long long sum = 0;std::mutex sum_mutex;auto fun = [&sum, &sum_mutex](long long scaleStart, long long scaleLast) {for (int n = scaleStart; n <= scaleLast; n++) {if (is_number_prime(n)) {std::lock_guard<std::mutex> lock(sum_mutex);//如果没有多线程互斥访问sum,那么sum的值就可能是错的。sum += n;}}};//区间平分,这样后面的第二个线程的计算量还是偏大,因为都是在处理更大的数字std::thread t1(fun, 2, scale / 2);std::thread t2(fun, scale / 2 + 1, scale);t1.join();//线程开始运行直到结束t2.join();//线程开始运行直到结束cout << "the sum of all primes from 2~" << setw(10) << scale << " is : " << setw(15) << sum<< ", elapled " << setw(10) << static_cast<long long>(duration<double, milli>(system_clock::now() - start).count()) << " milliseconds"<< endl;return sum;
}
//do not change the code in this function
//不要修改此函数中的内容
int main()
{test_is_prime_number();long long sum = 0;cout << "base slow version:" << endl;sum = test_the_sum_of_all_primes_within(10000 * 10);check(sum == 454396537);sum = test_the_sum_of_all_primes_within(10000 * 100);check(sum == 37550402023);sum = test_the_sum_of_all_primes_within(10000 * 1000);check(sum == 3203324994356);sum = test_the_sum_of_all_primes_within(10000 * 10000);check(sum == 279209790387276);cout << endl << "my faster version:" << endl;sum = faster_test_the_sum_of_all_primes_within(10000 * 10);check(sum == 454396537);sum = faster_test_the_sum_of_all_primes_within(10000 * 100);check(sum == 37550402023);sum = faster_test_the_sum_of_all_primes_within(10000 * 1000);check(sum == 3203324994356);sum = faster_test_the_sum_of_all_primes_within(10000 * 10000);check(sum == 279209790387276);cout << "please enter enter for exit." << endl;cin.get();return 0;
}
运行结果:
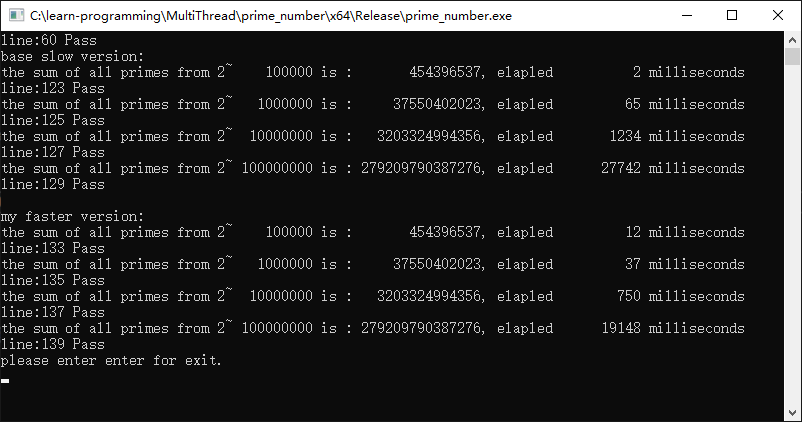
代码分析
如同代码注释中所说,我们把求解区间一分为二,后面的一个线程整体上任务还是偏重。因为处理的都是大数据。
但即便这样简单的划分,两个线程比一个线程耗时还是大幅度降低的。
在一百万个整数求解的时候时间降低了50%;
在一千万个整数求解的时候时间降低了50%;
在一亿个整数求解的时候时间降低了30%;这是因为后面一个线程的计算量过大,两个线程的任务没有起到平分导致的。
可以预见,随着数据量的继续增大,这种平分区间的算法,会导致第二个线程完全占据计算量的大头。这时候会导致这种算法的优势降低,甚至减少的时间可以忽略不计。
但是我们的目的达到了。那就是我们已经验证了多线程多核在计算速度上的确是可以完胜单线程的,只要我们合理分配计算任务给多个线程。
继续增加线程数量
下面我们把区间3等分,创建3个线程,看看是不是耗时会不会继续降低:
long long faster_test_the_sum_of_all_primes_within(long long scale)
{auto start = system_clock::now();long long sum = 0;std::mutex sum_mutex;auto fun = [&sum, &sum_mutex](long long scaleStart, long long scaleLast) {for (int n = scaleStart; n <= scaleLast; n++) {if (is_number_prime(n)) {std::lock_guard<std::mutex> lock(sum_mutex);//如果没有多线程互斥访问sum,那么sum的值就可能是错的。sum += n;}}};//区间平分,这样后面的第二个线程的计算量还是偏大,因为都是在处理更大的数字std::thread t1(fun, 2, scale / 3);std::thread t2(fun, scale / 3 + 1, scale / 3 * 2);std::thread t3(fun, scale / 3 * 2 + 1, scale);t1.join();//线程开始运行直到结束t2.join();//线程开始运行直到结束t3.join();//线程开始运行直到结束cout << "the sum of all primes from 2~" << setw(10) << scale << " is : " << setw(15) << sum<< ", elapled " << setw(10) << static_cast<long long>(duration<double, milli>(system_clock::now() - start).count()) << " milliseconds"<< endl;return sum;
}
运行输出:
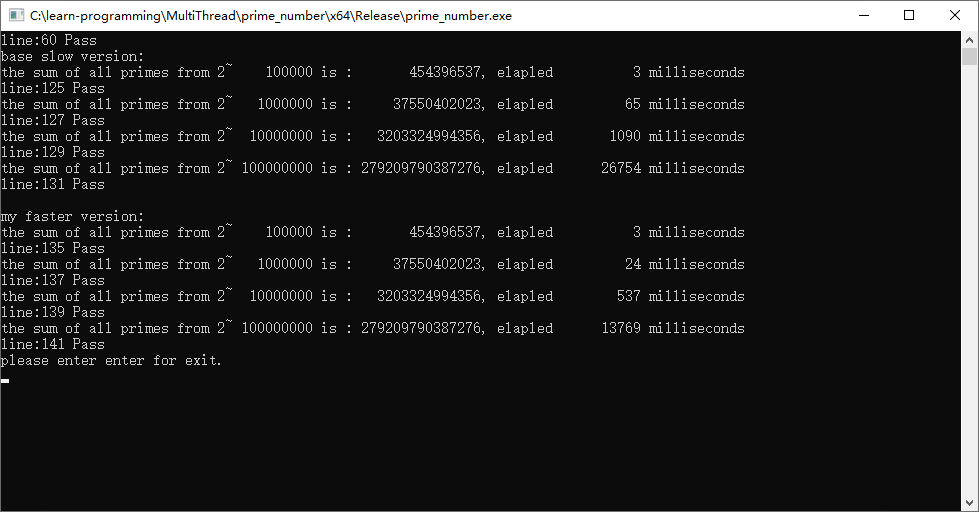
代码分析2
正如我们预期,时间继续下降,尤其是数据量达到一亿的时候,总耗时再次变为了原来的一半。
至此,多线程多核可以降低计算总时长已经被我们验证完毕。
怎么样?你学到了吗?
欢迎点赞收藏转发。让其他感兴趣的人也可以看到。
相关文章:
使用多线程std::thread发挥多核计算优势(解答)
使用多线程std::thread发挥多核计算优势(题目) 单核无能为力 如果我们的电脑只有一个核,那么我们没有什么更好的办法可以让我们的程序更快。 因为这个作业限制了你修改算法函数。你唯一能做的就是利用你电脑的多核。 使用多线程 由于我们…...
MySQL分页查询详解:优化大数据集的LIMIT和OFFSET
最近在工作中,我们遇到了一个需求,甲方要求直接从数据库导出一个业务模块中所有使用中的工单信息。为了实现这一目标,我编写了一条SQL查询语句,并请求DBA协助导出数据。尽管工单数量并不多,只有3000多条,但…...

解构赋值、函数默认值
暂时性死区,TDZ(Temporal Dead Zone) var x 1 {let x x//此处声明了x,但是没有对x赋值,相当于在赋值之前引用x,所以会造成报错console.log(x)//报错x is not defined,暂时性死区,…...

【已解决】Mybatis 实现 Group By 动态分组查询
🎉工作中遇到这样一个需求场景:实现一个统计查询,要求可以根据用户在前端界面筛选的字段进行动态地分组统计。也就是说,后端在实现分组查询的时候,Group By 的字段是不确定的,可能是一个字段、多个字段或者…...
Android修改默认gradle路径
Android Studio每次新建项目,都会默认在C盘生成并下载gradle相关文件,由于C盘空间有限,没多久C盘就飘红了,于是就需要把gradle相关文件转移到其他盘 1、到C盘找到gradle文件 具体路径一般是:C:\Users\用户\ .gradle …...

原生JS+canvas实现炫酷背景
原生JScanvas实现炫酷背景 可以在需要的背景页使用 <!doctype html> <html> <head> <meta charset"utf-8"> <title>HTML5 Canvas矩阵粒子波浪背景动画特效</title> <style> html,body { height:100%; } body { …...
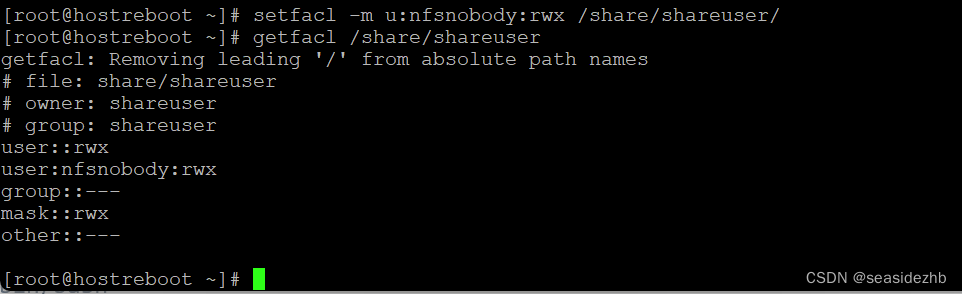
Linux学习之NAS服务器搭建
NAS是Network Attached Storage的缩写,也就是网络附属存储。可以使用自己已经不怎么使用的笔记本搭建一台NAS服务器。 fdisk -l可以看一下各个磁盘的状态。 可以看到有sda、sdb、sdc和sdd等四块硬盘。 lvs、vgs和pvs结合起来看,sdb和sdc没有被使用。 …...

分享码云上8个宝藏又有价值的开源图片编辑器
如果你需要高效地处理图片,那么这8款实用工具是可以尝试的! 它们能够进行一键抠图、放大、拼接、转矢量图、图标自动生成以及等操作,让你的工作效率飞升! 在Gitee这个最有价值的开源项目计划是Gitee综合评定出的优秀开源项目的展示…...

TCP Header都有啥?
分析&回答 源端口号(Source Port) :16位,标识主机上发起传送的应用程序; 目的端口(Destonation Port) :16位,标识主机上传送要到达的应用程序。 源端,目…...

无涯教程-Android - AutoCompleteTextView函数
AutoCompleteTextView是一个类似于EditText的视图,只是它在用户键入时自动显示补充数据。 AutoCompleteTextView - 属性 以下是与AutoCompleteTextView控件相关的重要属性。您可以查看Android官方文档以获取属性的完整列表以及可以在运行时更改这些属性的相关方法。…...

【Docker】 07-安装ElasticSearch、Kibana
安装ElasticSearch 1、拉取镜像 docker pull elasticsearch:6.4.2 2、运行 docker run -p 9200:9200 -p 9300:9300 --name es -d elasticsearch:6.4.2 启动会报错,按照下面流程修改 3、在宿主机中,修改配置sysctl.conf vim /etc/sysctl.conf 加入如下配…...
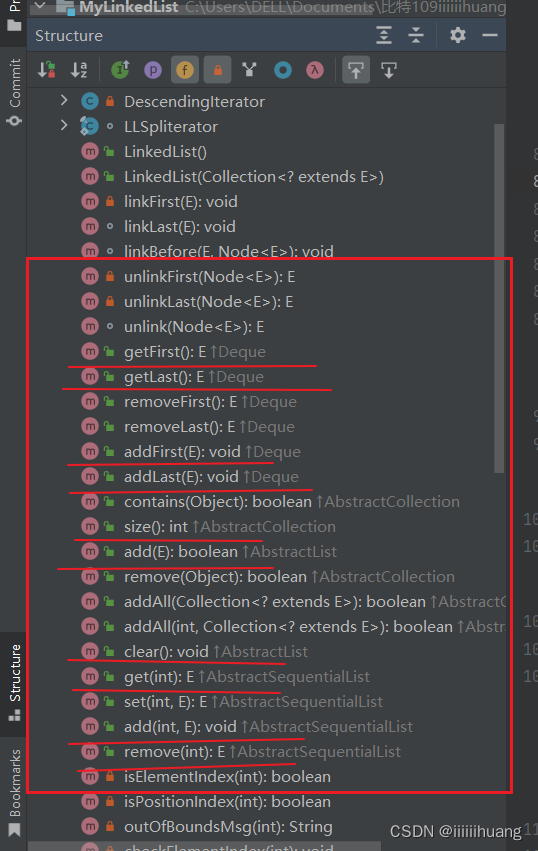
【数据结构篇】线性表1 --- 顺序表、链表 (万字详解!!)
前言:这篇博客我们重点讲 线性表中的顺序表、链表 线性表(linear list)是n个具有相同特性的数据元素的有限序列。 线性表是一种在实际中广泛使用的数据结构,常见的线性表:顺序表、链表、栈、队列... 线性表在逻辑上是…...

C语言每日一练--Day(17)
本专栏为c语言练习专栏,适合刚刚学完c语言的初学者。本专栏每天会不定时更新,通过每天练习,进一步对c语言的重难点知识进行更深入的学习。 今日练习题关键字:数对 截取字符串 💓博主csdn个人主页:小小unico…...
8月琐碎但值得的事情
8月份结束了,最近心态比较好,慢点就慢点,没有那么着急了,可能是因为着急也没啥办法, 8月是比较开心的一个月,可能是做的事情更有盼头了,可能是看了喜欢的书,可能是我变瘦了ÿ…...
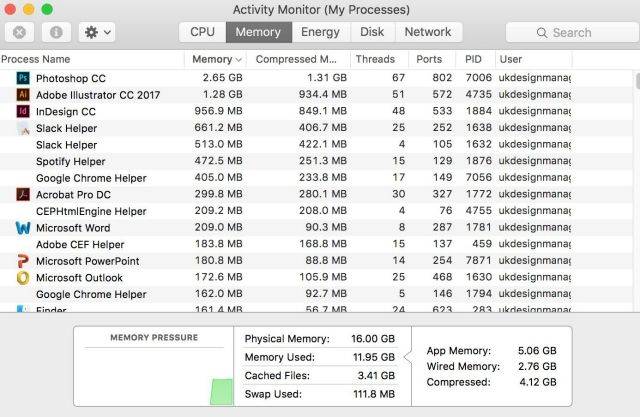
苹果Mac系统如何优化流畅的运行?提高运行速度
Mac系统的稳定性和流畅性一直备受大家称赞,这也是大多数人选择Mac的原因,尽管如此,我们仍不时地对Mac进行优化、调整,以使其比以前更快、更流畅地运行。以下是小编分享给各位的Mac优化方法,记得保存哦~ 一、释放被过度…...
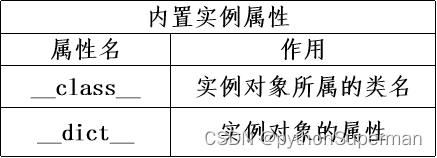
Python 类和对象
类的创建 Python语言中,使用class关键字来创建类,其创建方式如下: class ClassName(bases):# class documentation string 类文档字符串,对类进行解释说明class_suiteclass是关键字,bases是要继承的父类,…...
VC++使用Microsoft Speech SDK进行文字TTS朗读
Microsoft Speech SDK下载地址 https://www.microsoft.com/en-us/download/details.aspx?id10121 需要msttss22L.exe、SpeechSDK51.exe、SpeechSDK51LangPack.exe三个,下载后全部安装 使用VS2005建立一个win32控制台项目 朗读"hello word"、中文“你好”…...

FFmpeg4.3.1+h264在windows下编译与VS2017项目集成
前言 在Android音视频开发中,网上知识点过于零碎,自学起来难度非常大,不过音视频大牛Jhuster提出了《Android 音视频从入门到提高 - 任务列表》,结合我自己的工作学习经历,我准备写一个音视频系列blog。本文是音视频系…...

mapboxGL3新特性介绍
概述 8月7日,mapboxGL发布了3版本的更新,本文带大家一起来看看mapboxGL3有哪些新的特性。 新特新 如上图所示,是mapboxGL官网关于新版的介绍,大致翻译如下: 增强了web渲染的质量、便捷程度以及开发人员体验ÿ…...

类ChatGPT大模型LLaMA及其微调模型
1.LLaMA LLaMA的模型架构:RMSNorm/SwiGLU/RoPE/Transfor mer/1-1.4T tokens 1.1对transformer子层的输入归一化 对每个transformer子层的输入使用RMSNorm进行归一化,计算如下: 1.2使用SwiGLU替换ReLU 【Relu激活函数】Relu(x) max(0,x) 。 【GLU激…...

为什么92%的Sora 2初学者卡在第4步?——帧一致性崩塌诊断工具包+时间轴锚点校准法
更多请点击: https://kaifayun.com 第一章:Sora 2视频生成的核心原理与环境准备 Sora 2并非OpenAI官方发布的模型,而是社区基于Sora技术理念构建的开源复现与增强框架,其核心依托于时空联合建模的扩散变换器(Spacetim…...

App无辜躺枪?手把手教你搞定腾讯手机管家误报导致的应用商店下架
当合规应用遭遇误报下架:开发者系统性应对指南运动健康类应用被标记为金融诈骗软件?社交工具因"病毒风险"被各大商店紧急下架?这类看似荒谬的误报事件,正在成为中小开发团队的"无妄之灾"。某知名运动App开发团…...
叶绿素(CHL)数据,版本 2022.0)
Sentinel-3B OLCI 3 级全球分箱地球观测降分辨率(ERR)叶绿素(CHL)数据,版本 2022.0
Sentinel-3B OLCI Level-3 Global Binned Earth-observation Reduced Resolution (ERR) Chlorophyll (CHL) Data, version 2022.0 简介 叶绿素 a 数据集提供全球网格化的表层叶绿素 a 浓度(浮游植物生物量的替代指标)合成数据。CHL 支持时间序列和气候…...

Win10系统清理避坑指南:你的BAT脚本真的安全吗?盘点那些不能乱删的文件
Win10系统清理避坑指南:BAT脚本安全操作手册每次看到那些号称"一键清理系统垃圾"的BAT脚本在技术论坛被疯狂转发,我的工程师朋友老张就会忍不住摇头。上周他刚帮一位设计师修复了崩溃的Photoshop——原因正是某个清理脚本删除了Adobe的临时工作…...

开启Python GUI开发新纪元:Tkinter Designer可视化界面自动化生成终极指南
开启Python GUI开发新纪元:Tkinter Designer可视化界面自动化生成终极指南 【免费下载链接】Tkinter-Designer An easy and fast way to create a Python GUI 🐍 项目地址: https://gitcode.com/gh_mirrors/tk/Tkinter-Designer 在Python GUI开发…...

Unity iOS构建报错SDK version is 0的根因与精准修复
1. 这个报错不是Unity在“发脾气”,而是工程配置在“装死”刚接手一个老项目,打开Unity编辑器,点Build Settings准备打包iOS,结果弹出一行红字:“SDK version is 0, cannot build”。我第一反应是——这什么鬼…...

Matlab,plot绘图如何添加边框
matlab生成的图——编辑(E)——坐标区属性(A)——框样式——Box,勾选效果:...

如何通过Joy-Con Toolkit实现专业级Switch手柄控制与硬件逆向工程
如何通过Joy-Con Toolkit实现专业级Switch手柄控制与硬件逆向工程 【免费下载链接】jc_toolkit Joy-Con Toolkit 项目地址: https://gitcode.com/gh_mirrors/jc/jc_toolkit 在游戏开发、硬件调试和嵌入式系统研究中,与游戏手柄等专业输入设备进行深度交互一直…...

XZ1018,100V,40A,NMOS 封装:TO252
封装:TO252类型:NVDS:100V VGS: 20V ID:40ARDS(ON):10V <14mΩRDS(ON):4.5V <19mΩ型号: XZ1018 封装:TO252类型…...

Cesium动态数据可视化实战:CallbackProperty结合setInterval打造实时运动轨迹
Cesium动态数据可视化实战:CallbackProperty结合setInterval打造实时运动轨迹 在三维地理信息系统中,实时数据可视化一直是开发者面临的挑战之一。想象一下,当我们需要在地球表面追踪一架正在飞行的无人机,或者监控城市中数百辆出…...