【爬虫】7.1. JavaScript动态渲染界面爬取-Selenium
JavaScript动态渲染界面爬取-Selenium的简单学习
文章目录
- JavaScript动态渲染界面爬取-Selenium的简单学习
- 1. Selenium准备工作
- 2. Selenium简单用法
- 2.1. 初始化浏览器对象-webdriver.Chrome()
- 2.2. 访问界面-browser.get()
- 2.3. 查找节点-find_element()
- 2.4. 节点交互-send_keys()、clear()、click()
- 2.5. 动作链-ActionChains()
- 2.6. 运行JavaScript-execute_script()
- 2.7. 获取节点信息-get_attribute()、text、id、location、tag_name、size
- 2.8. 切换Frame-switch_to.frame()
- 2.9. 延时等待
- 2.9.1. 隐式等待-implicitly_wait()
- 2.9.2. 显式等待-WebDriverWait()
- 2.10. 前进和后退-forward()、back()
- 2.11. Cookie-add_cookie()、delete_all_cookies()
- 2.12. 选项卡管理-execute_script()
- 3. 反屏蔽
- 4. 无头模式
引言:在学习这一章之前,若之前对于Ajax数据的分析和爬取有过了解的会知道,Ajax是JavaScript动态渲染界面的一种情形,通过直接分析Ajax,使我们仍然可以借助requests或urllib实现数据爬取。不过JavaScript动态渲染的界面不止Ajax一种,而且在实际中Ajax接口中会含有很多加密参数,比如说xhr中request url的链接中含有token参数使我们难以找到规律,所以很难直接通过分析Ajax爬取数据。
Python提供了许多模拟浏览器运行的库,例如Selenium、Splash、Pyppetter、Playwright等,可以帮我们实现所见皆所爬,就不用再为如何爬取动态渲染的界面发愁了。
1. Selenium准备工作
Selenium是一个自动化测试工具,利用它可以驱动浏览器完成特定的操作,例如点击、下拉等,你还可以利用这个工具来恶搞别人浏览不良网站!!!言归正传,你可以利用它获取浏览器当前呈现的页面源代码,做到所见皆所爬,对于一些JavaScript动态渲染的界面来说,这种爬取方式非常有效。 本节以Chrome浏览器为例来讲解Selenium。首先先安装好Chrome和Selenium库。
首先来看看Selenium的功能:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
import timebrowser = webdriver.Chrome()
try:browser.get('https://www.baidu.com')input = browser.find_element(By.ID, 'kw')input.send_keys('Python')input.send_keys(Keys.ENTER)wait = WebDriverWait(browser, 10)wait.until(EC.presence_of_element_located((By.ID, 'content_left')))print(browser.current_url)print(browser.get_cookies())print(browser.page_source)time.sleep(1000)
finally:browser.close()
运行代码后,会自动弹出一个Chrome浏览器,接着浏览器会跳转到百度界面并在搜索框中输入Python,就会自动跳转到搜索结果页。输出页面源代码,此处省略源代码,可以知道,我们得到的当前URL、Cookie和页面源代码都是真实内容,而用requests请求的源代码却和使用Selenium的源代码不一样。所以说,用Selenium驱动浏览器加载的页面可以直接拿到JavaScript渲染的结果,无须关心是什么加密系统。
2. Selenium简单用法
2.1. 初始化浏览器对象-webdriver.Chrome()
Selenium支持的浏览器非常多,既有Chrome、Firefox、Edge、Safari等电脑端的浏览器,也有Android、BlackBerry等手机端的浏览器。下面是初始化浏览器对象:
from selenium import webdriver
browser1 = webdriver.Chrome()
# browser2 = webdriver.Firefox()
# browser3 = webdriver.Edge()
print(type(browser1)) # <class 'selenium.webdriver.chrome.webdriver.WebDriver'>
browser1.close()
2.2. 访问界面-browser.get()
上面我们已经初始化了浏览器对象,接下来就是要调用browser,执行各个方法模拟浏览器操作。访问界面:
from selenium import webdriver
url = "https://www.taobao.com/"
browser1 = webdriver.Chrome()
browser1.get(url)
browser1.close()
2.3. 查找节点-find_element()
我们想从淘宝页面提取搜索框这个节点,那就进入开发者选项快捷搜索就行了。
from selenium import webdriver
from selenium.webdriver.common.by import By
url = "https://www.taobao.com/"
browser1 = webdriver.Chrome()
browser1.get(url)
input_first = browser1.find_element(By.ID, "q")
print(input_first)
# <selenium.webdriver.remote.webelement.WebElement (session="dc29f31092c770c57925bbd74839af9d", element="C15004B057068D353AA2B162C5D9F24E_element_2")>
browser1.close()
但是这种方法只会查找第一个匹配的节点,要是想要查找多个节点那就使用find_elements(),这时返回的内容是列表类型的,列表里面每一个元素都是WebElement类型的。
2.4. 节点交互-send_keys()、clear()、click()
Selenium可以驱动浏览器执行一些操作。比较常见的用法有:用send_keys方法输入文字,用clear方法清空文字,用click方法点击按钮:
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
url = "https://www.taobao.com/"
browser1 = webdriver.Chrome()
browser1.get(url)
# 查找对话框,按钮
input_first = browser1.find_element(By.ID, "q")
button = browser1.find_element(By.CLASS_NAME, "btn-search")
# 输入文字
input_first.send_keys("IPad")
time.sleep(3)
# 清空文字
input_first.clear()
# 输入文字
input_first.send_keys("HUAWEI")
# 点击按钮
button.click()
time.sleep(3)
browser1.close()
更多操作请见官方文档
https://selenium-python.readthedocs.io/api.html#module-selenium.webdriver.remote.webelement
2.5. 动作链-ActionChains()
在上面示例中,交互操作都是针对某一个节点来执行的。其实还有一些操作,他们没有特定的执行对象,比如鼠标拖拽、按键键盘等,这些操作需要另一种方式执行,那就是动作链。例如可以这样实现拖拽节点的操作:
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
import timebrowser = webdriver.Chrome()
url = 'http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable'
browser.get(url)
# 切换到名为 'iframeResult' 的 iframe 内容(这个网页被分为很多个框架)
browser.switch_to.frame('iframeResult')
# 找到要拖拽的源元素和目标元素
source = browser.find_element(By.CSS_SELECTOR, '#draggable')
target = browser.find_element(By.CSS_SELECTOR,'#droppable')
# 创建 ActionChains 对象来执行操作
actions = ActionChains(browser)
# 进行拖拽操作
actions.drag_and_drop(source, target)
# 执行
actions.perform()
time.sleep(5)
更多的动作链请参考官方文档的介绍:
https://selenium-python.readthedocs.io/api.html#module-selenium.webdriver.common.action_chains
2.6. 运行JavaScript-execute_script()
还有一些操作,Selenium没有提供API,例如下拉进度条,面对这种情况可以模拟运行JavaScript,此时使用execute_script方法可以实现,代码如下:
from selenium import webdriverbrowser = webdriver.Chrome()
browser.get('https://www.zhihu.com/explore')
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
browser.execute_script('alert("To Bottom")')
2.7. 获取节点信息-get_attribute()、text、id、location、tag_name、size
当我们选中一个节点时候,我们可以获取它的属性、文本、ID、位置、标签名和大小:
- get_attribute():获取属性,参数传入属性名
- text:获取文本
- id:获取id
- location:获取位置
- tag_name:获取标签名
- size:获取大小
2.8. 切换Frame-switch_to.frame()
网页中有一种节点叫做iframe,也就是子Frame,相当于页面中的子页面,它的结构和外部网页的结构完全一致。Selenium打开一个页面之后,默认是在父Frame里操作,此时如果页面中含有子Frame,是不能在子Frame中操作的,这时就需要使用switch_to.frame方法切换Frame。
import time
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementExceptionbrowser = webdriver.Chrome()
url = 'http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable'
browser.get(url)
browser.switch_to.frame('iframeResult')
try:logo = browser.find_element_by_class_name('logo')
except NoSuchElementException:print('NO LOGO')
browser.switch_to.parent_frame()
logo = browser.find_element_by_class_name('logo')
print(logo)
print(logo.text)
2.9. 延时等待
在Selenium中,get方法在网页框架结束后才会结束执行,如果我们尝试在get方法执行完毕时获取网页源代码,可能结果不是浏览器加载完全的页面,因为某些页面需要额外的Ajax请求还会经过JavaScript渲染,所以有必要让浏览器延时一段时间。这里的等待方式有两种,一种是隐式等待,一种是显式等待。
2.9.1. 隐式等待-implicitly_wait()
使用隐式等待执行测试时,在查找节点而节点没有立即出现时,隐式等待会先等待一段时间再查找DOM,默认的等待时间为0
from selenium import webdriver
from selenium.webdriver.common.by import Bybrowser = webdriver.Chrome()
# 设置隐式等待时间
browser.implicitly_wait(10)
browser.get("https://spa2.scrape.center/")
input_first = browser.find_element(By.CLASS_NAME, "logo-image")
print(input_first.get_attribute("src"))
2.9.2. 显式等待-WebDriverWait()
隐式等待的效果其实并不好,因为我们只规定了一个固定时间,而页面加载时间会受网络条件的影响。还有一种更合适的等待方法——显式等待,这种方式会指定查找的节点和最长等待时间,如果在规定时间内加载出了要查找的节点,就返回这个节点;如果到规定时间内依然没有加载出节点,就抛出超时异常。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as ECbrowser = webdriver.Chrome()
browser.get("https://taobao.com")
# 设定wait对象,指定最长等待时间
wait = WebDriverWait(browser, 10)
# 调用wait的until方法,传入等待条件
input = wait.until(EC.presence_of_element_located((By.ID, "q")))
# 等待条件:代表按钮式可点击的
button = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, ".btn-search")))
print(input, button)
下面表格列出了所有等待条件(应该)
| 等待条件(Expected Conditions) | 描述 |
|---|---|
EC.presence_of_element_located | 元素出现在 DOM 中。 |
EC.visibility_of_element_located | 元素在页面上可见。 |
EC.visibility_of | 元素在页面上可见。 |
EC.invisibility_of_element_located | 元素在页面上不可见。 |
EC.element_to_be_clickable | 元素可被点击。 |
EC.element_to_be_selected | 元素被选中。 |
EC.element_located_to_be_selected | 元素被选中。 |
EC.text_to_be_present_in_element | 在元素中出现特定文本。 |
EC.text_to_be_present_in_element_value | 在元素的值中出现特定文本。 |
EC.frame_to_be_available_and_switch_to_it | 切换到指定的 iframe 或 frame 中。 |
EC.element_to_be_located | 元素出现在 DOM 中。 |
EC.staleness_of | 元素不再附加到 DOM 上(已过时)。 |
EC.element_located_selection_state_to_be | 元素的选中状态与给定状态匹配。 |
EC.element_selection_state_to_be | 元素的选中状态与给定状态匹配。 |
EC.alert_is_present | 存在警报。 |
EC.title_contains | 页面标题包含指定文本。 |
EC.title_is | 页面标题等于指定文本。 |
EC.url_contains | 页面 URL 包含指定文本。 |
EC.url_to_be | 页面 URL 完全等于指定 URL。 |
EC.url_matches | 页面 URL 匹配指定的正则表达式。 |
EC.invisibility_of_element_located | 元素在页面上不可见。 |
更多等待条件和参数及其用法可以参考官方文档:
https://selenium-python.readthedocs.io/api.html#module-selenium.webdriver.support.expected_conditions
2.10. 前进和后退-forward()、back()
平时使用浏览器时也有前进和后退的功能,用Selenium也可以完成这个操作。
from selenium import webdriver
import timebrowser = webdriver.Chrome()
browser.get("https://www.baidu.com/")
browser.get("https://www.taobao.com/")
browser.get("https://www.python.org")
browser.back()
time.sleep(3)
browser.forward()
time.sleep(3)
browser.close()
2.11. Cookie-add_cookie()、delete_all_cookies()
使用selenium还可以对Cookie进行操作
from selenium import webdriverbrowser = webdriver.Chrome()
browser.get("https://www.zhihu.com/explore")
print(browser.get_cookies())
cookie = {'name': 'AJ', 'value': 'BJ'}
browser.add_cookie(cookie)
print(browser.get_cookies())
browser.delete_all_cookies() # 去掉all也可以指定删除哪一个
print(browser.get_cookies())
2.12. 选项卡管理-execute_script()
访问网页的时候,会开启一个个选项卡。在Selenium中,我们也可以对选项卡进行操作:
import time
from selenium import webdriverbrowser = webdriver.Chrome()
browser.get("https://www.baidu.com/")
# 打开一个新的选项卡
browser.execute_script("window.open()")
print(browser.window_handles)
# 切换到新的选项卡
browser.switch_to.window(browser.window_handles[1])
browser.get("https://www.taobao.com")
time.sleep(2)
# 切换回去
browser.switch_to.window(browser.window_handles[0])
browser.get("https://python.org")
3. 反屏蔽
现在有很多网站增加了对Selenium的检测,防止一些爬虫的恶意爬取,如果检测到有人使用Selenium打开浏览器就会直接屏蔽。大多数情况下,检测的基本原理时检测当前浏览器窗口下的window.navigator对象中是否包含webdriver属性。是因为正常使用浏览器时,这个属性应该是undefined,一旦使用了Selenium。它就会给window.navigator对象设置为webdriver属性。很多网站会通过JavaScript语句判断是否存在webdriver属性。
在Selenium中,可以用CDP(即Chrome Devtools Protocol,Chrome 开发工具协议)解决这个问题,利用它可以实现在每个页面刚加载的时候就执行JavaScript语句,将webdriver属性置空。这里执行的CDP方法叫做Page.addScriptToEvaluateOnNewDocument,将上面的JavaScript语句传入其中即可。另外,还可以加入几个选项来隐藏WebDriver提示条和自动化扩展信息。
from selenium import webdriver
from selenium.webdriver import ChromeOptions
import timeoption = ChromeOptions()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
option.add_experimental_option('useAutomationExtension', False)
browser = webdriver.Chrome(options=option)
browser.execute_cdp_cmd('Page.addScriptToEvaluateOnNewDocument', {'source': 'Object.defineProperty(navigator, "webdriver", {get: () => undefined})'
})
browser.get('https://antispider1.scrape.center/')
time.sleep(10)
4. 无头模式
上面的案例在运行的时候总会弹出一个浏览器窗口,我们也可以把它去掉,这样可以减少一些资源的加载:
from selenium import webdriver
from selenium.webdriver import ChromeOptionsoption = ChromeOptions()
option.add_argument("--headless")
browser = webdriver.Chrome(options= option)
browser.set_window_size(1366, 768)
browser.get("https://www.baidu.com")
browser.get_screenshot_as_file("preview.png")
相关文章:

【爬虫】7.1. JavaScript动态渲染界面爬取-Selenium
JavaScript动态渲染界面爬取-Selenium的简单学习 文章目录 JavaScript动态渲染界面爬取-Selenium的简单学习1. Selenium准备工作2. Selenium简单用法2.1. 初始化浏览器对象-webdriver.Chrome()2.2. 访问界面-browser.get()2.3. 查找节点-find_element()2.4. 节点交互-send_keys…...
:推导式)
菜鸟教程《Python 3 教程》笔记(12):推导式
菜鸟教程《Python 3 教程》笔记(12) 12 推导式12.1 列表推导式12.2 字典推导式12.3 集合推导式12.4 元组推导式(生成器表达式) 笔记带有个人侧重点,不追求面面俱到。 12 推导式 出处: 菜鸟教程 - Python3 …...

MAC修改python3命令为py
1, 找到python3安装路径 2, vi ~/.bash_profile 3, 增加内容: alias py“/usr/bin/python3” 4, 重载source ~/.bash_profile 5,执行py...
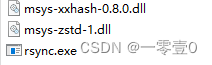
Windows下Git Bash调用rsync
rsync 提供了补充只需要在git安装目录下放入对应的文件即可。 需要将这个三个文件放到git的bin目录下 如果是默认安装路径是如下: C:\Program Files\Git\usr\bin 然后大功告成。...

springboot自定义事件发布及监听
自定义线程池 Configuration public class MyThreadPool {//ThreadPoolTaskExecutor不会自动创建ThreadPoolExecutor,需要手动调initialize才会创建。如果Bean就不需手动,会自动InitializingBean的afterPropertiesSet来调initializeBean("myExecut…...
手写RPC框架--2.介绍Zookeeper
RPC框架-Gitee代码(麻烦点个Starred, 支持一下吧) RPC框架-GitHub代码(麻烦点个Starred, 支持一下吧) 该项目的RPC通信将采用NettyZookeeper,所以会在前两章介绍使用方法 介绍Zookeeper Zookeepera.概述1) 数据模型2) Watcher机制 b.安装和基本操作1) Java操作zooke…...
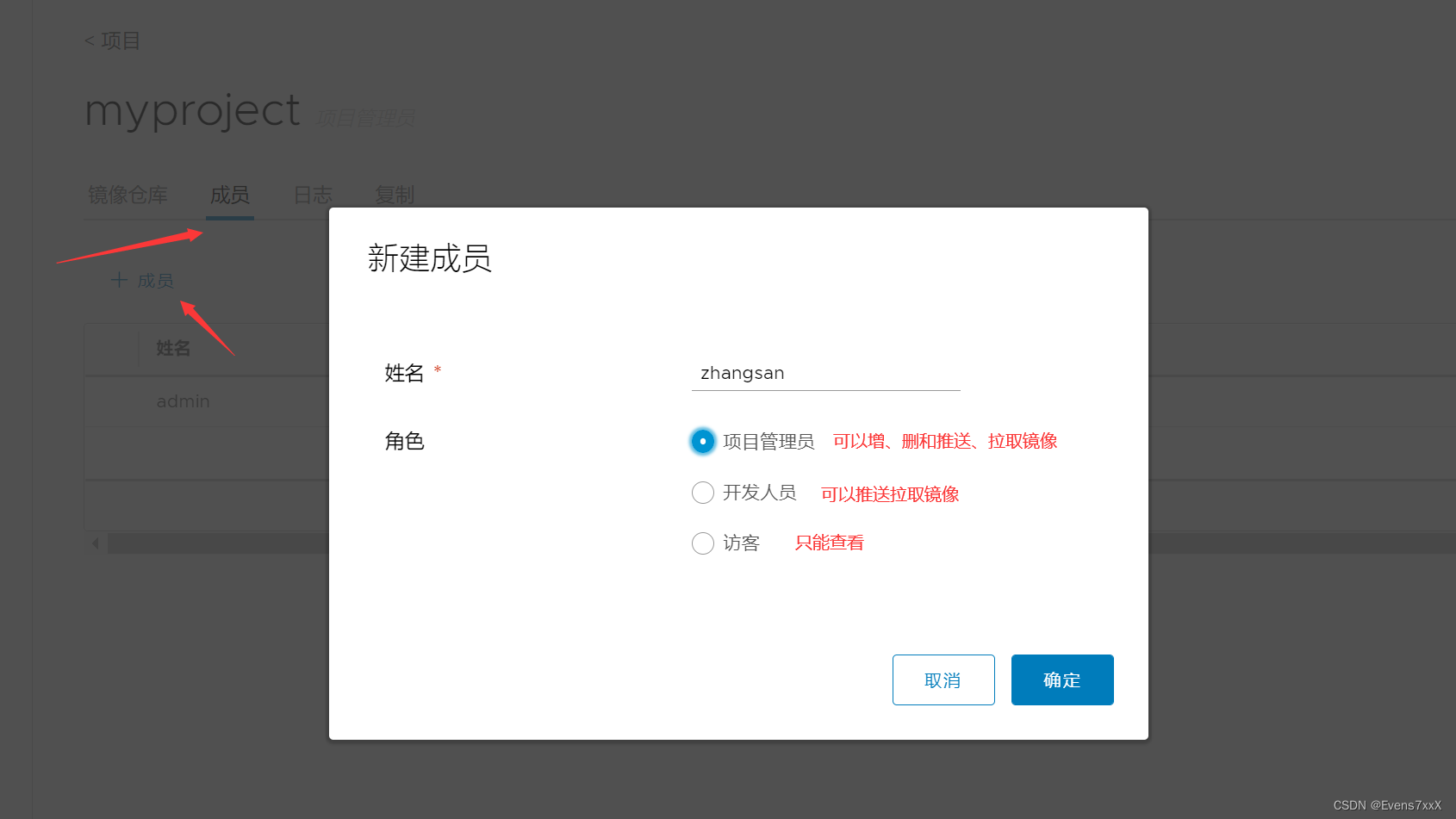
Docker harbor 私有仓库的部署和管理
目录 一、什么是Harbor 二、Harbor的特性 三、Harbor的构成 四、部署配置Docker Harbor 1. 首先需要安装 Docker-Compose 服务 2.部署 Harbor 服务 3.使用harbor仓库 (1)项目管理 (2)用户管理 一、什么是Harbor Harbor …...

从零开始搭建AI网站(6):如何使用响应式编程
响应式编程(Reactive Programming)是一种编程范式,旨在处理异步数据流和事件流。它通过使用观察者模式和函数式编程的概念,将数据流和事件流抽象为可观察的序列,然后通过操作这些序列来实现各种功能。 在响应式编程中…...
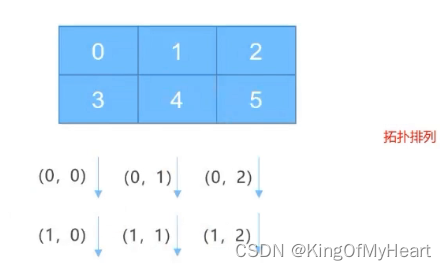
MPI之虚拟进程拓扑
什么是虚拟进程拓扑 在很多并行应用进程中,进程的线性排列不能充分的反映进程间在逻辑上的通信模型,通常由问题几何和所用的算法决定,进程经常被排列成二维或者三维网络形式的拓扑模型而通常用一个图来描述逻辑进程排列,此种逻辑…...

Three.js相机参数及Z-Fighting问题的解决方案
本主题讨论透视相机以及如何为远距离环境设置合适的视锥体。 推荐:用 NSDT编辑器 快速搭建可编程3D场景 透视相机是一种投影模式,旨在模仿人类在现实世界中看待事物的方式。 这是渲染 3D 场景最常用的投影模式。 - three.js 如果你看一下 Three.js 文档…...

微信小程序食疗微信小程序的设计与实现
摘要 现在人们的生活水平高了,大家都想在多活个几十年,要想实现这个想法,有很多事情都必须考虑到,第一个就是适当运动,第二个就是心情好,第三个就是要注意饮食。民以食为天,科学合理的饮食结构是…...

mac环境使用pkgbuild命令打pkg包的几个小细节
mac环境使用pkgbuild命令打pkg包的几个小细节 最近,研发提出要使用jenkins来自动生成mac环境下的pkg包,研究了一下,可以使用pkgbuild来打包。但是有几个小细节需要注意一下: 1 如果有pre-install和post-install脚本,…...
在 Spring Boot 中集成 MinIO 对象存储
MinIO 是一个开源的对象存储服务器,专注于高性能、分布式和兼容S3 API的存储解决方案。本文将介绍如何在 Spring Boot 应用程序中集成 MinIO,以便您可以轻松地将对象存储集成到您的应用中。 安装minio 拉取 minio Docker镜像 docker pull minio/minio创…...
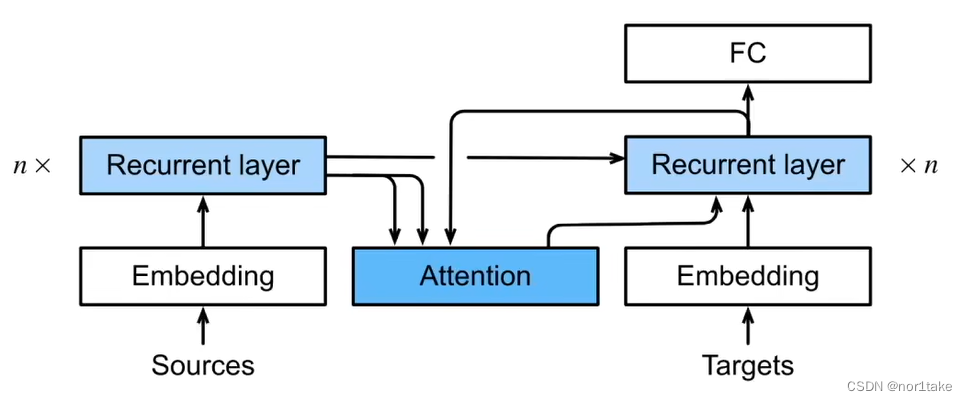
seq2seq与引入注意力机制的seq2seq
1、什么是 seq2seq? 就是字面意思,“句子 到 句子”。比如翻译。 2、seq2seq 有一些特点 seq2seq 的整体架构是 “编码器-解码器”。 其中,编码器是 RNN,并将 最后一个hidden state(隐藏状态)【即&…...
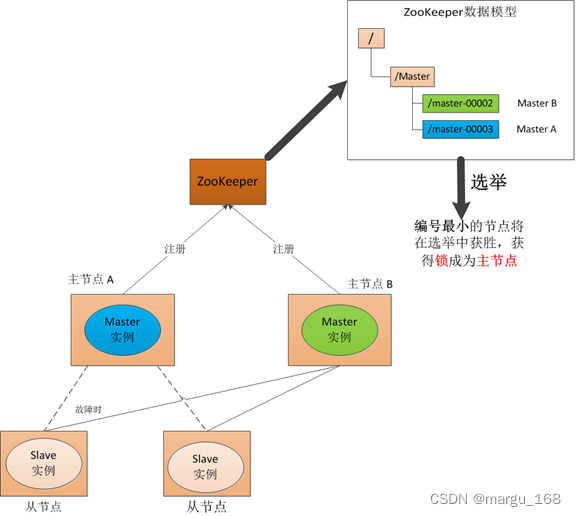
【zookeeper】zookeeper介绍
分布式协调技术 在学习ZooKeeper之前需要先了解一种技术——分布式协调技术。那么什么是分布式协调技术?其实分布式协调技术主要用来解决分布式环境当中多个进程之间的同步控制,让他们有序的去访问某种临界资源,防止造成"脏数据"的…...

2023高教社杯数学建模思路 - 案例:ID3-决策树分类算法
文章目录 0 赛题思路1 算法介绍2 FP树表示法3 构建FP树4 实现代码 建模资料 0 赛题思路 (赛题出来以后第一时间在CSDN分享) https://blog.csdn.net/dc_sinor?typeblog 1 算法介绍 FP-Tree算法全称是FrequentPattern Tree算法,就是频繁模…...

springboot docker
在Spring Boot中使用Docker可以帮助你将应用程序与其依赖的容器化,并简化部署和管理过程。 当你在Spring Boot中使用Docker时,你的代码不需要特殊的更改。你可以按照通常的方式编写Spring Boot应用程序。 java示例代码,展示了如何编写一个基…...
docker-compose 部署nacos 整合 postgresql 为DB
标题docker-compose 部署nacos 整合 postgresql 为DB 前提: 已经安装好postgresql数据库 先创建好一个数据库 nacos,执行以下sql: /** Copyright 1999-2018 Alibaba Group Holding Ltd.** Licensed under the Apache License, Version 2.0 (the "…...
详解 ElasticSearch Kibana 配置部署
默认安装部署所在机器允许外网 SSH工具 Putty 链接:https://pan.baidu.com/s/1b6gumtsjL_L64rEsOdhd4A 提取码:lxs9 Winscp 链接:https://pan.baidu.com/s/1tD8_2knvv0EJ5OYvXP6VTg 提取码:lxs9 WinSCP安装直接下一步到完成…...
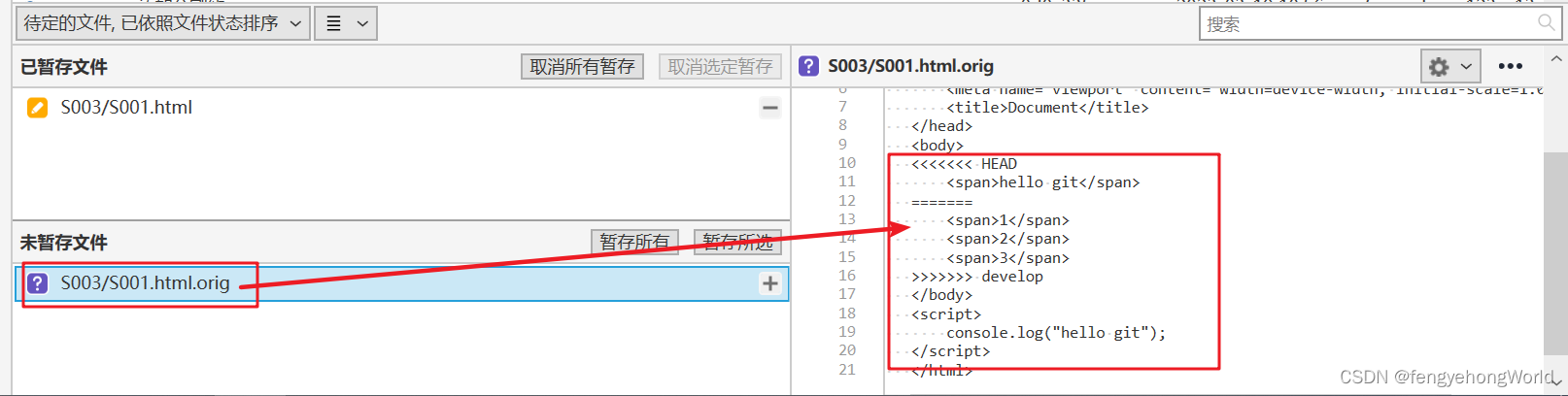
SourceTree 使用技巧
参考资料 SourceTree使用教程(一)—克隆、提交、推送SourceTree的软合并、混合合并、强合并区别SourceTree 合并分支上的多个提交,一次性合并分支的多次提交至另一分支,主分支前进时的合并冲突解决 目录 一. 基础设置1.1 用户信息…...

PA100K数据集实战:从下载到结构化解析全流程
1. PA100K数据集初探:为什么选择它?如果你正在研究行人属性识别,PA100K绝对是个绕不开的宝藏数据集。这个数据集包含了10万张真实监控场景下的行人图像,每张图都标注了26种常见属性——从衣着风格(比如是否穿T恤、裙子…...
)
ParaView时间戳设置全攻略:从基础标注到自定义格式(5.8.0实测)
ParaView时间戳设置全攻略:从基础标注到自定义格式(5.8.0实测) 在科学可视化领域,时间戳不仅是数据演变的见证者,更是研究成果呈现的专业语言。ParaView作为开源可视化工具链的标杆,其时间标注功能在学术论…...

DeepSeek系统设计辅助:如何在48小时内完成可审计、可回滚、可压测的AI服务架构图?
更多请点击: https://intelliparadigm.com 第一章:DeepSeek系统设计辅助 DeepSeek系统设计辅助模块面向架构师与后端工程师,提供模型能力调用、接口契约生成、异步任务编排等核心支撑能力。该模块不替代人工设计决策,而是通过结构…...

DIY复刻经典:Texar Audio Prism动态处理器克隆套件全攻略
1. 项目概述:Texar Audio Prism 克隆套件如果你在专业音频圈子里混过一段时间,尤其是对上世纪八九十年代那些经典的、带点“魔法”色彩的外置动态处理器感兴趣,那么“Texar Audio Prism”这个名字你大概率不会陌生。它不是最常见的1176或者LA…...

基于声卡与电流互感器的安全交流功率测量系统设计与实践
1. 项目概述:用声卡安全测量交流功率我一直对各种测量技术抱有浓厚的兴趣,毕竟“测量即认知”这句老话在今天依然适用。对于电力消耗和产出,没有什么比直接测量更能说明问题了。交流功率的测量,核心在于同时获取电压和电流的瞬时值…...

航空航天为什么离不开高强镁合金?国产替代到哪一步了
飞机每减重一千克,全年大约节省四千两百美元的燃油费用——这是航空工程师熟悉的经验值。在商业航空领域,这个数字还只是财务账;在战斗机、导弹和卫星的世界里,减重的收益被换算成更远的航程、更大的载荷、更高的机动性࿰…...

关于psthon问题
我想问问各位 我python可以查到 但是我的bit文件查不到python怎么回事...

AI圈神秘领袖Ilya一幅画引爆全网,OpenAI三件大事暗示AGI时代将至?
AI圈神秘精神领袖Ilya在Instagram上传一幅画引发疯狂解读,与此同时,OpenAI连续公布数学成果、升级Codex、筹备IPO,释放AGI到来的强烈信号。Ilya画作引猜测Ilya上传的画中,罗丹的「思考者」踩在芯片Die Shot上,右下角签…...

GEO生成引擎优化:当AI成为信息分发的主角,品牌如何抢占对话窗口?
当用户不再"搜索-浏览",而是直接"AI提问-获取答案",传统SEO的逻辑正在被彻底改写。2026年,GEO(Generative Engine Optimization,生成式引擎优化)已经从概念走向规模化落地。本文从技术…...

长期使用Token Plan套餐在项目开发中的成本观察
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Token Plan套餐在项目开发中的成本观察 在AI驱动的项目开发中,成本控制与预算管理是团队负责人必须面对的现实…...