hadoop1.2.1伪分布式搭建
0.使用host-only方式
将Windows上的虚拟网卡改成跟Linux上的网卡在同一网段
注意:一定要将widonws上的WMnet1的IP设置和你的虚拟机在同一网段,但是IP不能相同
1.Linux环境配置(windows下面的防火墙也要关闭)
1.1修改主机名
vim /etc/sysconfig/network
1.2修改IP
vim /etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE="eth0"
BOOTPROTO="static" ###
HWADDR="00:0C:29:BF:45:8B"
IPV6INIT="yes"
NM_CONTROLLED="yes"
ONBOOT="yes"
TYPE="Ethernet"
UUID="99339c27-0884-46c0-85d5-2612e5c1f149"
IPADDR="192.168.1.110" ###
NETMASK="255.255.255.0" ###
GATEWAY="192.192.1.1" ###
1.3修改主机名和IP的映射关系
vi /etc/hosts
192.168.1.110 itcast
1.4关闭防火墙
查看防护墙状态
service iptables status
关闭
service iptables stop
查看防火墙开机启动状态
chkconfig iptables --list
关闭开机启动
chkconfig iptables off
1.5安装JDK
上传JDK
添加执行权限
chmod u+x jdk-6u45-linux-i586.bin
解压
./jdk-6u45-linux-i586.bin
mkdir /usr/java
mv jdk1.6.0_45/ /usr/java/
将java添加到环境变量
vim /etc/profile
在文件的末尾添加如下内容
export JAVA_HOME=/usr/java/jdk1.6.0_45
export PATH=$PATH:$JAVA_HOME/bin
刷新配置
source /etc/profile
2.配置hadoop
2.1上传hadoop包
2.2解压hadoop包
首先在根目录创建一个cloud目录
mkdir /cloud
tar -zxvf hadoop-1.1.2.tar.gz -C /cloud/
2.3配置hadoop伪分布式(要修改4个文件)
第一个:hadoop-env.sh
vim hadoop-env.sh
export JAVA_HOME=/usr/java/jdk1.6.0_45
第二个:core-site.xml
vim core-site.xml
<configuration>
<!-- 指定HDFS的namenode的通信地址 -->
<property>
<name>fs.default.name</name>
<value>hdfs://itcast:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存放目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/cloud/hadoop-1.1.2/tmp</value>
</property>
</configuration>
第三个:hdfs-site.xml
vim hdfs-site.xml
<configuration>
<!-- 配置HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
第四个:mapred-site.xml
vim mapred-site.xml
<configuration>
<!-- 指定jobtracker地址 -->
<property>
<name>mapred.job.tracker</name>
<value>itcast:9001</value>
</property>
</configuration>
2.4将hadoop添加到环境变量
vim /etc/profile
export JAVA_HOME=/usr/java/jdk1.6.0_45
export HADOOP_HOME=/cloud/hadoop-1.1.2
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin
source /etc/profile
2.5格式化HDFS
hadoop namenode -format
2.6启动hadoop
start-all.sh
2.7验证集群是否启动成功
jps(不包括jps应该有5个)
NameNode
SecondaryNameNode
DataNode
JobTracker
TaskTracker
还可以通过浏览器的方式验证
http://192.168.1.110:50070 (hdfs管理界面)
http://192.168.1.110:50030 (mr管理界面)
在这个文件中添加linux主机名和IP的映射关系
C:\Windows\System32\drivers\etc
3.配置ssh免登陆
生成ssh免登陆密钥
ssh-keygen -t rsa
执行完这个命令后,会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
将公钥拷贝到要免登陆的机器上
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
相关文章:

hadoop1.2.1伪分布式搭建
0.使用host-only方式 将Windows上的虚拟网卡改成跟Linux上的网卡在同一网段 注意:一定要将widonws上的WMnet1的IP设置和你的虚拟机在同一网段,但是IP不能相同 1.Linux环境配置(windows下面的防火墙也要关闭) 1.1修改主…...

【校招VIP】前端JavaScript语言之跨域
考点介绍: 什么是跨域?浏览器从一个域名的网页去请求另一个域名的资源时,域名、端口、协议任一不同,都是跨域。跨域是前端校招的一个重要考点,在面试过程中经常遇到,需要着重掌握。本期分享的前端算法考点之…...

mysql调优小计
1.选择最合适的字段属性:类型、⻓度、是否允许NULL等;尽量把字段设为not null,⼀⾯查询时对⽐是否为null; 2.要尽量避免全表扫描,⾸先应考虑在 where 及 order by 涉及的列上建⽴索引。 3.应尽量避免在 where ⼦句中对…...

AI:04-基于机器学习的蘑菇分类
蘑菇是一类广泛分布的真菌,其中许多种类具有重要的食用和药用价值,但也存在着一些有毒蘑菇。因此,准确地区分可食用和有毒的蘑菇对于保障人们的食品安全和健康至关重要。本研究旨在基于机器学习技术开发一种蘑菇分类系统,以实现对蘑菇的自动分类和识别。通过构建合适的数据…...
算法——排序
排序 下面的代码会用到宏定义,因为再C中没有swap交换函数,所以对于swap的宏定义代码如下: #define swap(a, b) {\__typeof(a) __a a; a b; b __a;\ } 稳定排序: 1.插入排序: 插入排序会将数组,分位两个部…...
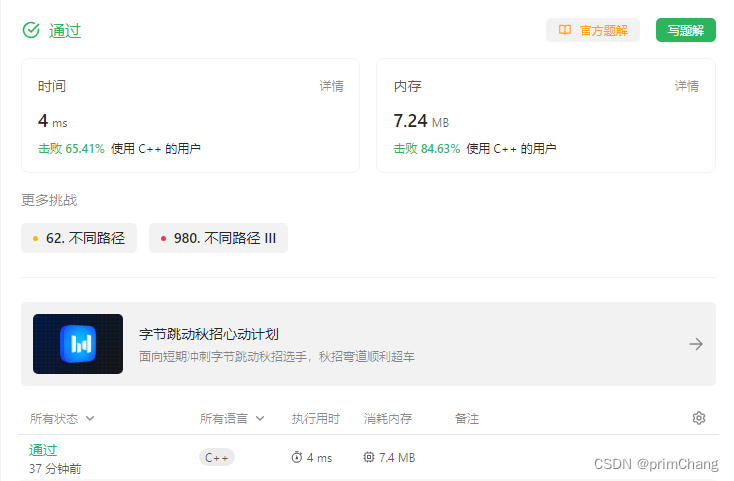
leetCode动态规划“不同路径II”
迷宫问题是比较经典的算法问题,一般可以用动态规划、回溯等方法进行解题,这道题目是我昨晚不同路径这道题趁热打铁继续做的,思路与原题差不多,只是有需要注意细节的地方,那么话不多说,直接上coding和解析&a…...

100天精通Python(可视化篇)——第99天:Pyecharts绘制多种炫酷K线图参数说明+代码实战
文章目录 专栏导读一、K线图介绍1. 说明2. 应用场景 二、配置说明三、K线图实战1. 普通k线图2. 添加辅助线3. k线图鼠标缩放4. 添加数据缩放滑块5. K线周期图表 书籍推荐 专栏导读 🔥🔥本文已收录于《100天精通Python从入门到就业》:本专栏专…...

哈希表与有序表
哈希表与有序表 Set结构 key Map结构 key-value 哈希表 哈希表的时间复杂度都是常数项级别的,但常数较大 增删改查的时间都是常数级别的,与数据量无关 当哈希表存储的值是基础数据类型(Integer - int),哈希表中内…...

什么时候使用RPA?如何使用RPA?需要什么样的硬件支持?需要安装哪些软件?
RPA(Robotic Process Automation)是一种用于自动化执行重复性任务的技术,它可以帮助企业提高工作效率,降低人力成本,并减少人为错误。RPA适用于各种行业和场景,例如财务、人力资源、客户服务、IT运维等。 …...
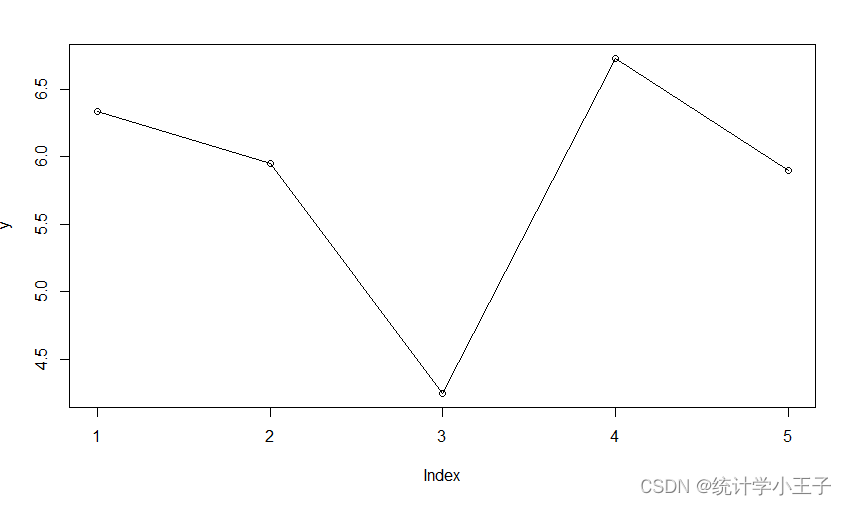
R语言入门——line和lines的区别
目录 0 引言一、 line()二、 lines() 0 引言 首先,从直观上看,lines比line多了一个s,但它们还是有很大的区别的,下面将具体解释这个两个函数的区别。 一、 line() 从R语言的帮助文档中找到,line()的使用,…...
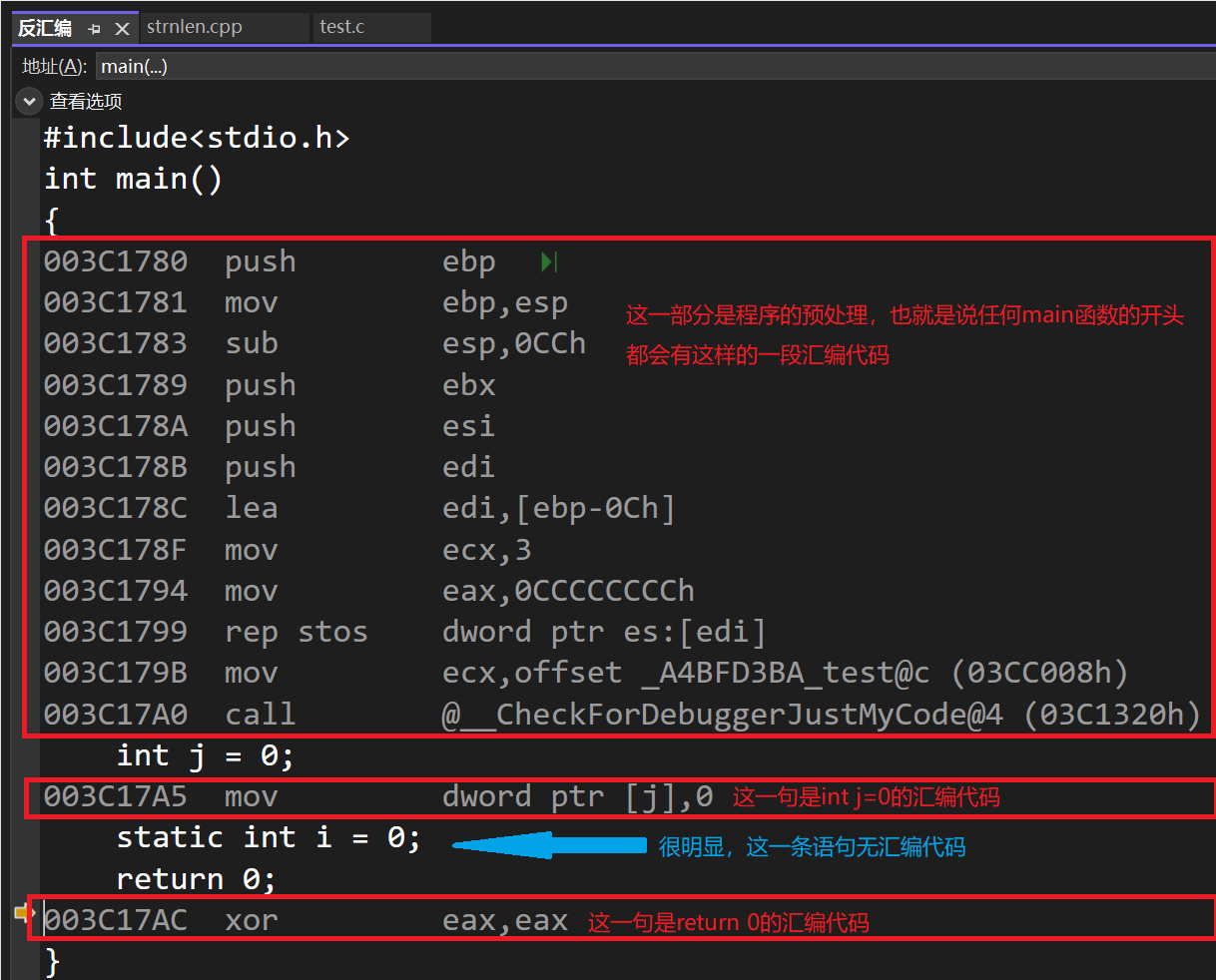
C语言:static关键字的使用
1.static修饰局部变量 这是static关键字使用最多的情况。我们知道局部变量是在程序运行阶段在栈上创建的,但是static修饰的局部变量是在程序编译阶段在代码段(静态区)创建的。所以在static修饰的变量所在函数执行结束后该变量依然存在。 //…...
:ECUM的ISOLAR-AB配置及代码解析)
AUTOSAR知识点 之 ECUM (三):ECUM的ISOLAR-AB配置及代码解析
目录 1、概述 2、ISOLAR-AB配置 2.1、EcuMGeneral 2.2、EcuMConfiguration 2.2.1、EcuMDefaultShutdownTarget 2.2.2、EcuMDriverInitListOne...
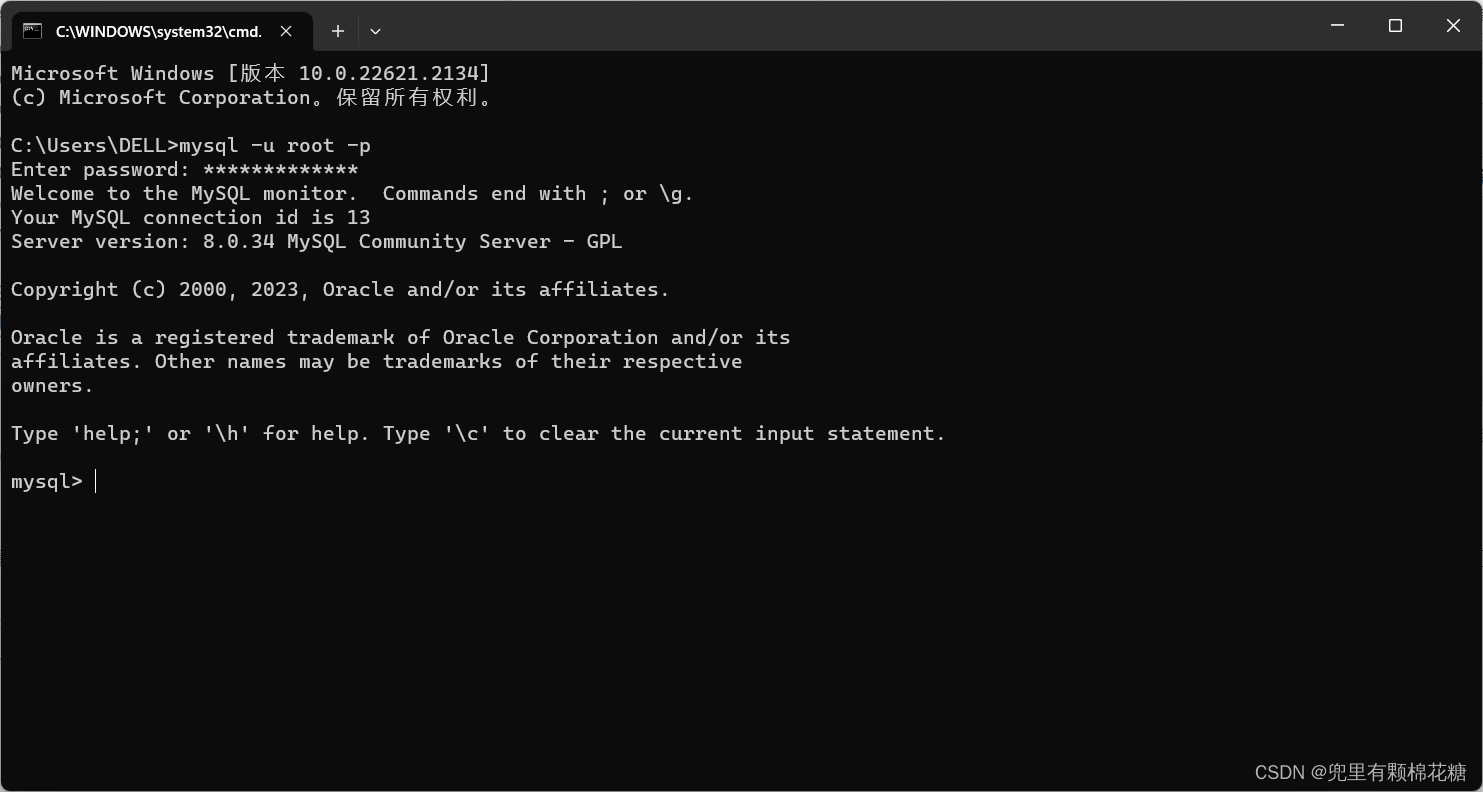
2023年MySQL-8.0.34保姆级安装教程
重点放前面:演示环境为windows环境。 MySQL社区版本安装教程如下: 一、MySQL安装包下载二、安装配置设置三、配置环境变量 大体分为3个步骤:①安装包的下载;②安装配置设置;③配置环境变量 一、MySQL安装包下载 下载官…...
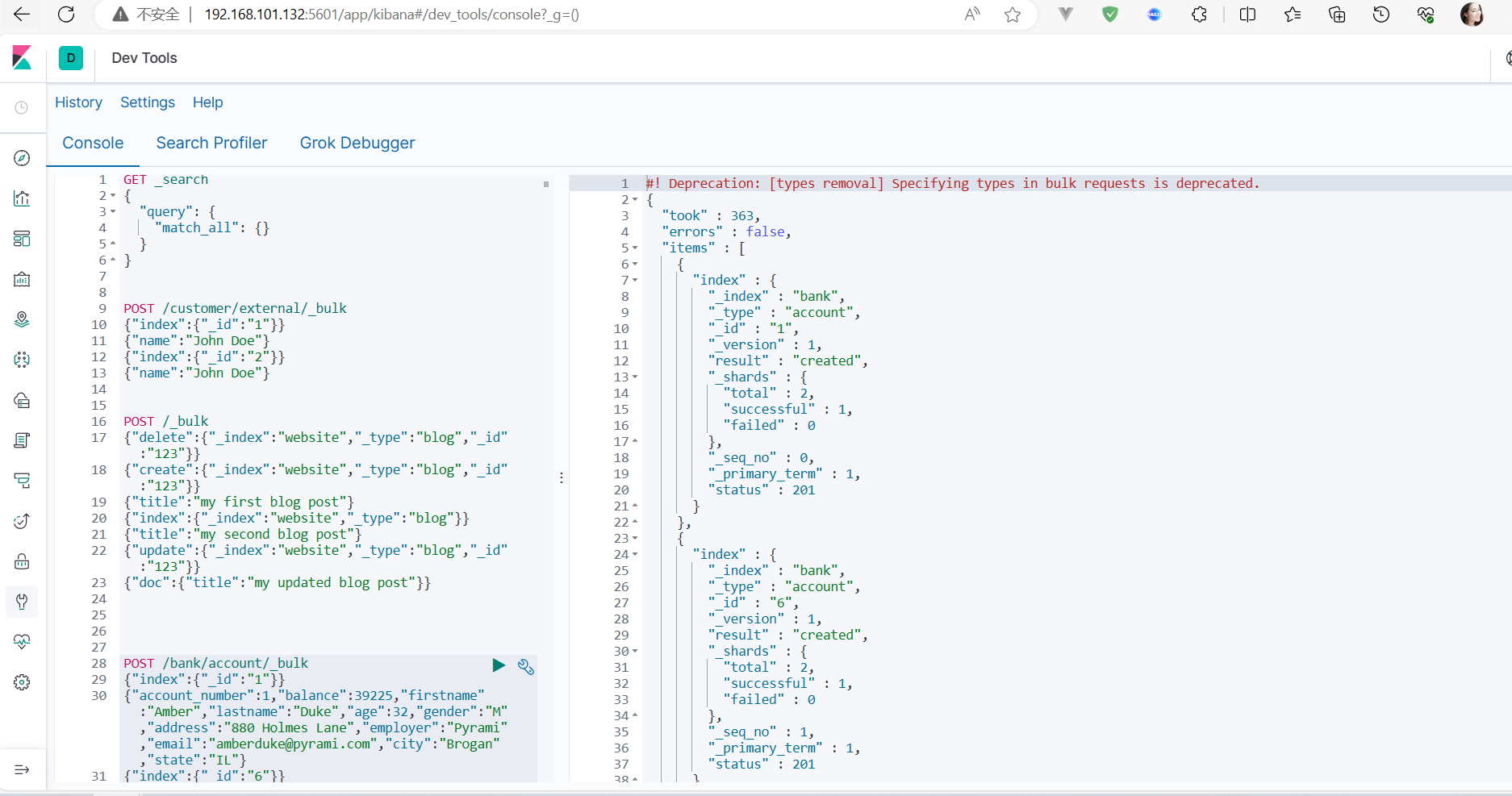
ElasticSearch入门
一、基本命令_cat 1、查看节点信息 http://192.168.101.132:9200/_cat/nodes2、查看健康状况 http://192.168.101.132:9200/_cat/health3、查看主节点的信息 http://192.168.101.132:9200/_cat/master4、查看所有索引 http://192.168.101.132:9200/_cat/indices二、索引一…...

RocketMQ的Broker
1 Broker角色 Broker角色分为ASYNC_MASTER (异步主机)、SYNC_MASTER (同步主机)以及SLAVE (从机)。如果对消息的可靠性要求比较严格,可以采用SYNC_MASTER加SLAV E的部署方式。如果对消息可靠性要求不高,可以采用ASYNC_MASTER加ASL AVE的部署方式。如果只…...

使用Puppeteer进行游戏数据可视化
导语 Puppeteer是一个基于Node.js的库,可以用来控制Chrome或Chromium浏览器,实现网页操作、截图、测试、爬虫等功能。本文将介绍如何使用Puppeteer进行游戏数据的爬取和可视化,以《英雄联盟》为例。 概述 《英雄联盟》是一款由Riot Games开…...

【Flask】from flask_sqlalchemy import SQLAlchemy报错
【可能出现的情况】 1、未安装 Flask-SQLAlchemy: 在使用 flask_sqlalchemy 之前,你需要确保已经通过 pip 安装了 Flask-SQLAlchemy。可以通过以下命令安装它: pip install Flask-SQLAlchemy 2、包名大小写问题: Python 是区分大…...

索引简单概述(SQL)
一、什么是索引? 索引是一种特殊的文件(InnoDB数据表上的索引是表空间的一个组成部分),他们包含着对数据表里所有记录的引用指针。 索引是一种数据结构。数据库索引,是数据库管理系统中一个排序的数据结构࿰…...

union all 和 union 的区别,mysql union全连接查询
602. 好友申请 II :谁有最多的好友(力扣mysql题,难度:中等) RequestAccepted 表: ------------------------- | Column Name | Type | ------------------------- | requester_id | int | | accepter_id | int | | accept_date …...

UDP和TCP的区别
UDP (User Datagram Protocol) 和 TCP (Transmission Control Protocol) 是两种常见的传输层协议。它们在设计和用途上有很大的区别,以下是它们的主要差异: 连接性: TCP: 是一个连接导向的协议。它首先需要建立连接,数据传输完毕后再终止连接…...
)
别再为VectorCAST环境变量头疼了!手把手教你配置.bat启动脚本(附DO-178C等标准切换指南)
VectorCAST启动脚本配置全指南:从环境变量到行业标准切换 第一次双击那个神秘的.bat文件时,我盯着闪退的命令行窗口足足愣了五分钟。作为刚接触航空电子单元测试的嵌入式工程师,VectorCAST的环境配置就像一堵无形的墙——编译器路径报错、环境…...

2026年玉米膨化机市场:谁是真正的行业领航者?
面对快速发展的休闲食品市场,如何在竞争激烈的玉米膨化机市场里抢占先机?随着消费者对健康食品需求的高涨,五谷杂粮膨化食品逐渐成为市场上的一股热潮。本篇将深度解析2026年玉米膨化机行业的趋势、选购要点,并对比测评几个行业知…...

5分钟快速上手:Parsec VDD虚拟显示器完整指南,彻底释放游戏串流潜能
5分钟快速上手:Parsec VDD虚拟显示器完整指南,彻底释放游戏串流潜能 【免费下载链接】parsec-vdd ✨ Perfect virtual display for game streaming 项目地址: https://gitcode.com/gh_mirrors/pa/parsec-vdd 想要在没有物理显示器的情况下畅享4K游…...
)
别再只怪外力了!手把手教你用砂纸“解剖”MLCC,排查电容失效真凶(附打磨实操图)
低成本破解MLCC失效之谜:砂纸打磨法的实战指南 当产线上突然出现大批量MLCC失效时,硬件工程师们常常陷入两难——既没有价值百万的金相显微镜,也无法承受将样品送往专业实验室的高昂成本和时间延误。这时,一套简单粗暴却行之有效的…...
)
保姆级教程:手把手教你搞定OpenPnP主次基准点矫正(附PCB制作与避坑心得)
OpenPnP主次基准点矫正实战指南:从硬件准备到精准调试 1. 准备工作:构建稳定的校准环境 在开始OpenPnP主次基准点矫正之前,充分的准备工作能避免80%的常见问题。首先需要理解基准点在贴片机坐标系中的核心作用——它们如同地图上的经纬度&…...
)
保姆级教程:用Python+OpenCV高效切割Potsdam语义分割数据集(附完整代码)
PythonOpenCV实战:Potsdam语义分割数据集高效切割全流程解析 第一次接触Potsdam数据集时,面对那些6000x6000像素的巨幅航拍图像,我的GPU在训练时直接报显存不足的错误。这让我意识到,高分辨率图像的切割预处理不是可选项…...
)
Midjourney年度订阅最后上车机会:官方邮件暗藏“早鸟密钥”,输入即解锁终身$129→$79(已验证有效期至2024-12-15)
更多请点击: https://kaifayun.com 第一章:Midjourney年度订阅优惠的官方政策与背景解析 Midjourney自2023年起正式将年度订阅(Annual Plan)纳入其核心付费体系,旨在为长期用户降低平均月成本并强化服务稳定性。该政策…...

手把手教你用网络分析仪调试CGH40010F:从S参数异常反推管子损坏原因与状态
深度解析CGH40010F氮化镓功率管故障诊断:从S参数异常到失效机理 在射频功率放大器设计中,CGH40010F作为一款经典的氮化镓(GaN)功率晶体管,因其高功率密度和高效率特性被广泛应用于基站、雷达等场景。然而在实际工程调试中,工程师们…...

告别Mac NTFS读写限制:免费开源的终极解决方案
告别Mac NTFS读写限制:免费开源的终极解决方案 【免费下载链接】Free-NTFS-for-Mac Nigate: An open-source NTFS utility for Mac. It supports all Mac models (Intel and Apple Silicon), providing full read-write access, mounting, and management for NTFS …...

WSL2 Ubuntu22.04 部署Geant4:从零到可视化实战指南
1. 环境准备与WSL2配置 在Windows系统上通过WSL2运行Ubuntu22.04来部署Geant4,首先要确保基础环境配置正确。我去年帮实验室三个同学搭建这个环境时发现,90%的初期问题都源于WSL2配置不当。下面这些步骤都是我踩坑后总结的最佳实践: 第一步&a…...