MySQL总复习
目录
登录
显示数据库
创建数据库
删除数据库
使用数据库
创建表
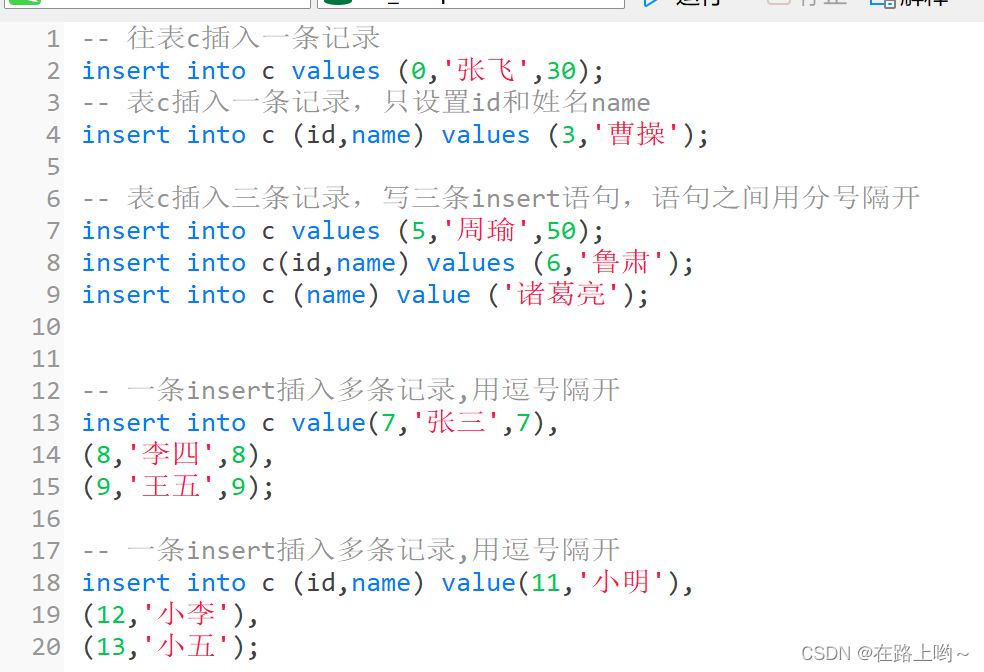
添加数据表数据
查询表
添加数据表多条数据
查询表中某数据
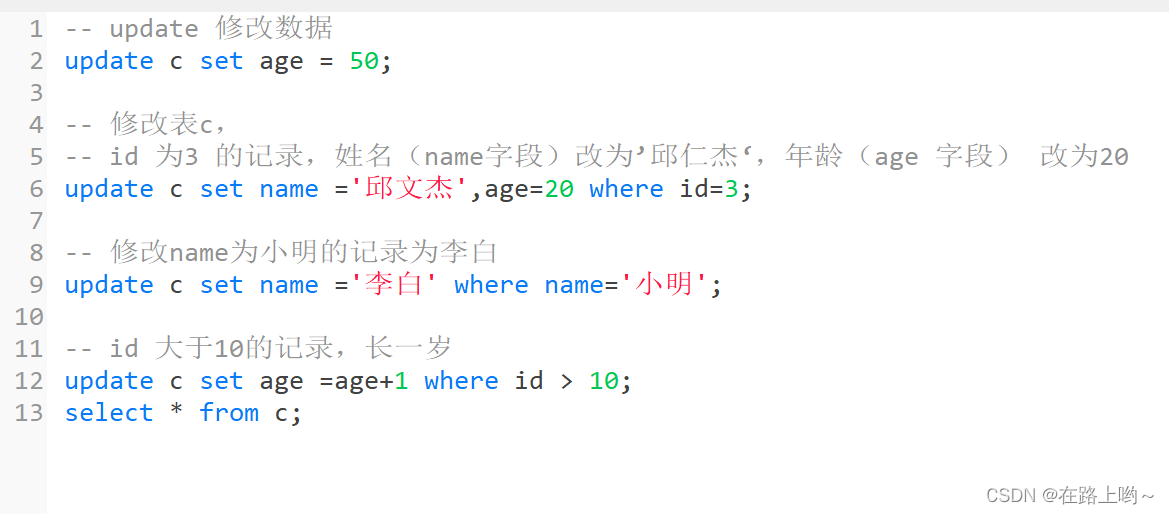
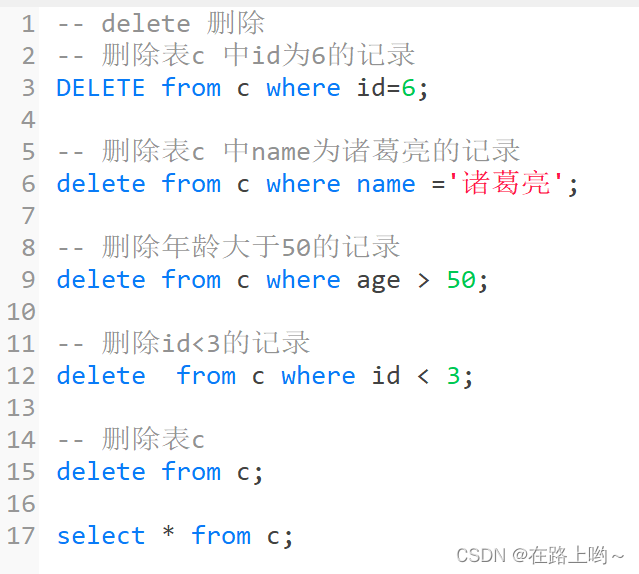
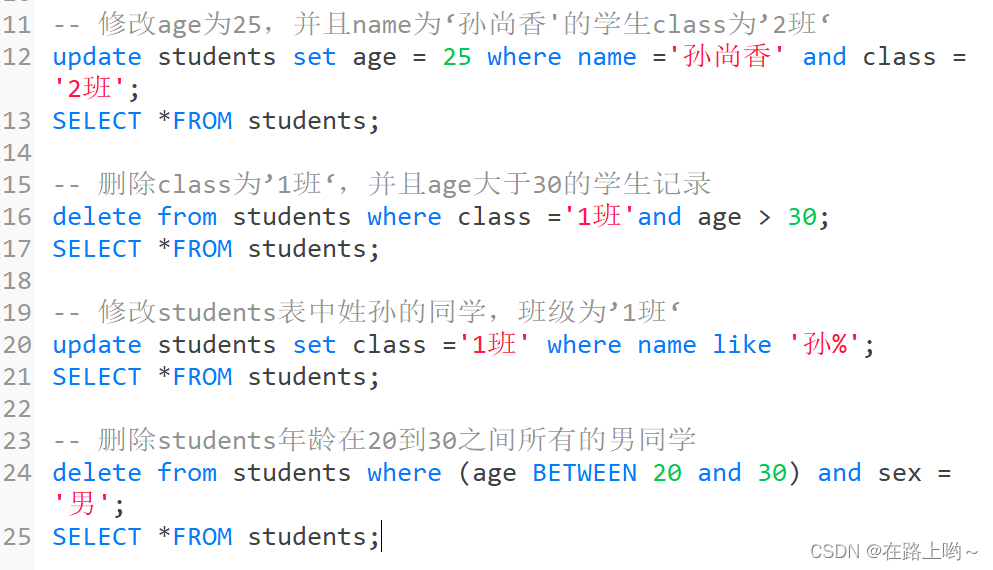
增insert 删delete 改update 查select
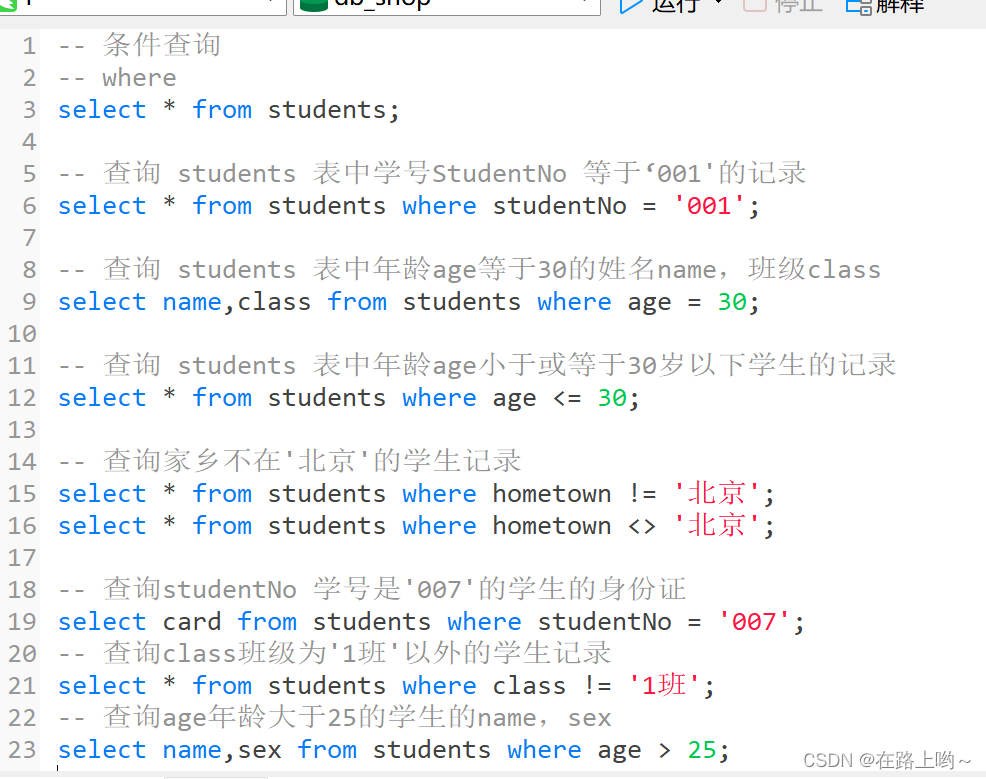
where
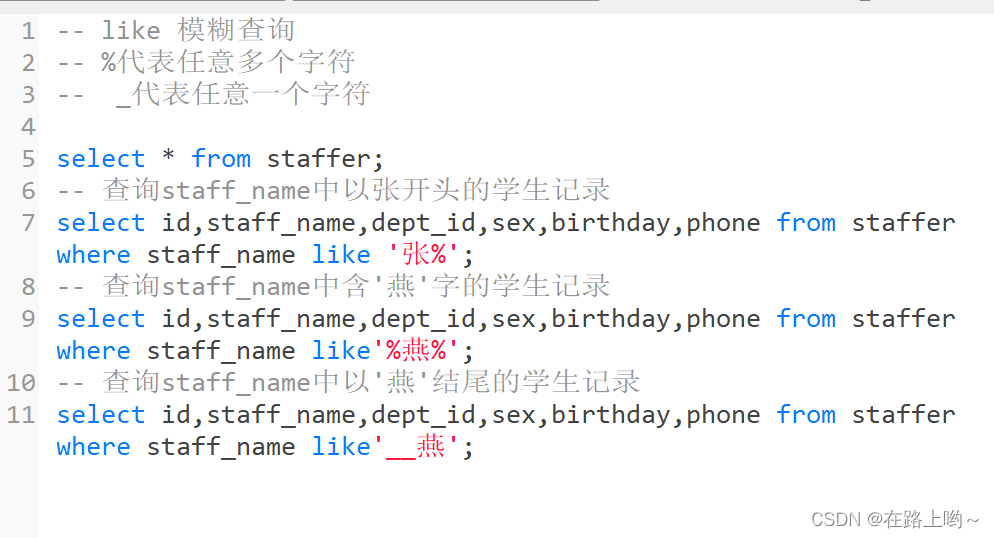
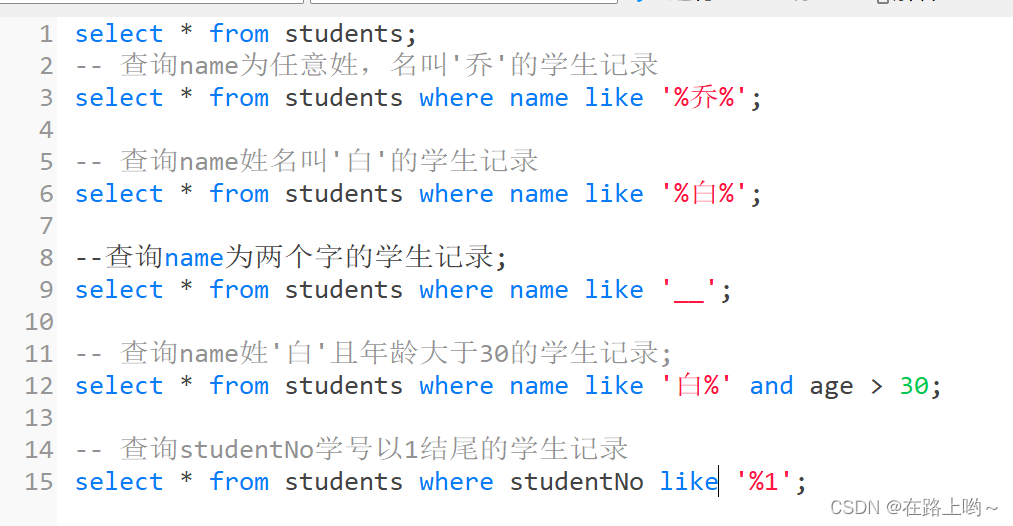
like
编辑
范围查找
order by
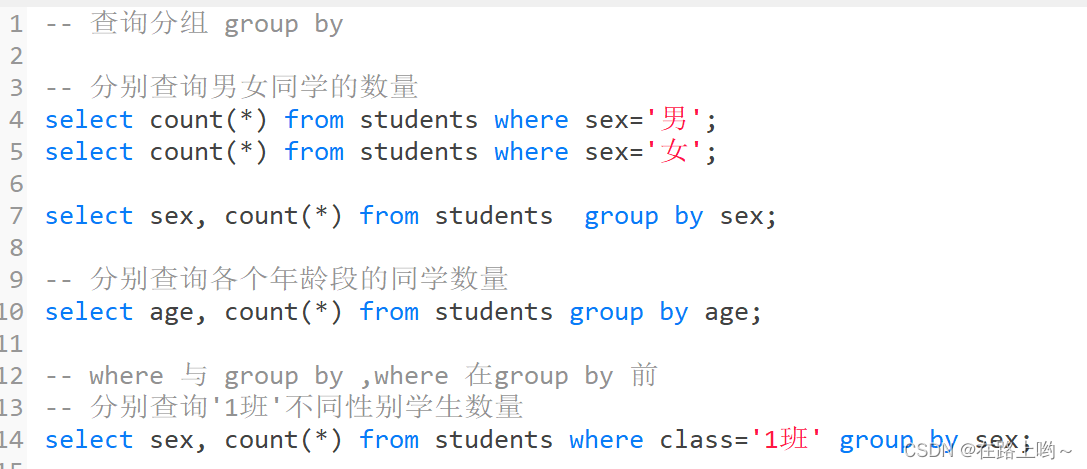
聚合函数
count
max
min sum avg
group by
having
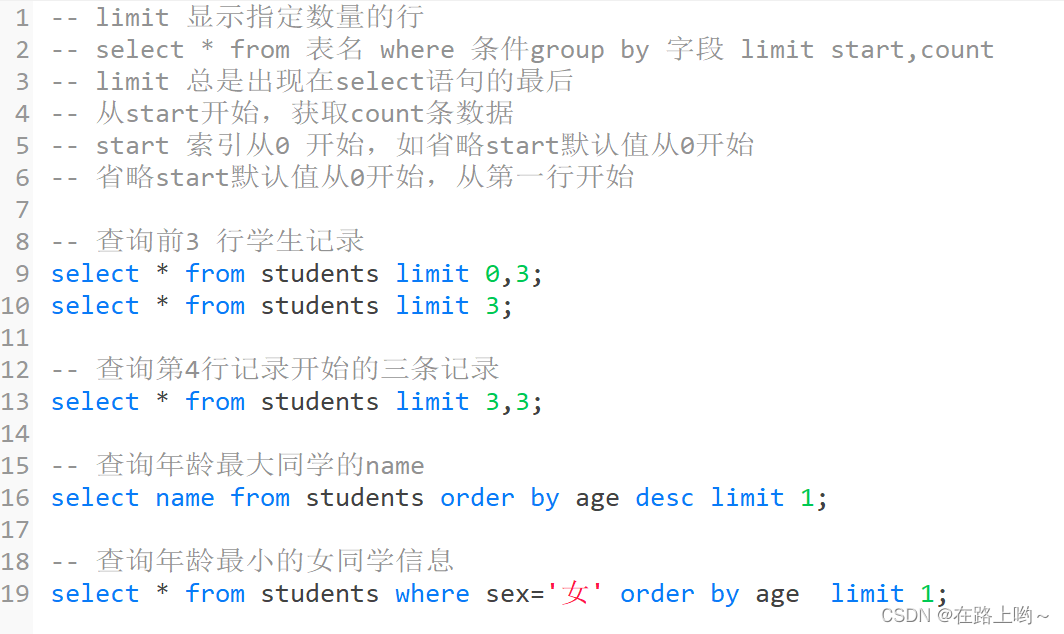
limit
空判断
视图
存储
登录
mysql -u root -p
显示数据库
show databases;
创建数据库
craate database <数据库名> ;

删除数据库
drop database <数据库名> ;

使用数据库
use <数据库名>

创建表
primary key 主键
not null 非空
unique 惟一
default 默认值
auto_increment 自增长
int unsigned 无符号整数
DROP TABLE IF EXISTS staffer;
CREATE TABLE staffer (id int NOT NULL AUTO_INCREMENT COMMENT '员工编号',dept_id int NOT NULL COMMENT '部门编号',staff_name varchar(10) NOT NULL COMMENT '员工名字',sex enum('F','M') DEFAULT 'F' COMMENT '性别',birthday date COMMENT '生日',phone char(11) COMMENT '电话',salary decimal(11,2) UNSIGNED DEFAULT 1.00 COMMENT '工资',staff_memo varchar(100) COMMENT '备注',PRIMARY KEY (id),FOREIGN KEY (dept_id) REFERENCES department (id),CHECK ((salary > 0) and (salary < 100000))
) AUTO_INCREMENT=10512;DROP TABLE IF EXISTS item ;
CREATE TABLE item(item_id int AUTO_INCREMENT,order_id int,goods_id int,quantity int,total_price decimal(11, 2),PRIMARY KEY ( item_id ),FOREIGN KEY ( goods_id ) REFERENCES goods ( goods_id ),FOREIGN KEY ( order_id ) REFERENCES orders ( order_id )
);添加数据表数据
INSERT INTO staffer VALUES (10501, 1, '燕南飞', 'M', '1995-09-18', '13011231890', '5000.10', '职员');
INSERT INTO staffer VALUES (10502, 2, '陈一南', 'M', '1990-09-12', '13011233333', '6000.10', '职员');
INSERT INTO staffer VALUES (10503, 4, '李思思', 'F', '1979-11-01', null, '9900.00', '总经理');
INSERT INTO staffer VALUES (10504, 1, '张燕红', 'F', '1985-06-01', '13566567456', '8000.00', '部门经理');
INSERT INTO staffer VALUES (10505, 3, '南海峰', 'M', '1986-04-01', null, '7000.00', '职员');
INSERT INTO staffer VALUES (10506, 3, '张红燕', 'F', '1982-09-21', '13823671111', '9000.00', '部门经理');
INSERT INTO staffer VALUES (10507, 2, '王南峰', 'M', '1986-04-01', '13668992222', '7000.00', '职员');
INSERT INTO staffer VALUES (10508, 5, '刘燕玲', 'F', '1981-07-01', '13823679988', '6000.00', '职员');
INSERT INTO staffer VALUES (10509, 5, '李玉燕', 'F', '1984-02-08', '13823677889', '9000.00', '部门经理');
INSERT INTO staffer VALUES (10510, 4, '王树思', 'M', '1996-04-01', '13668998888', '7000.00', '职员');
INSERT INTO staffer VALUES (10511, 1, '思灵玉', 'F', '1992-03-01', '13823679999', '6000.00', '职员');INSERT INTO item VALUES (1, 1, 1, 20, NULL);
INSERT INTO item VALUES (2, 1, 2, 2, NULL);
INSERT INTO item VALUES (3, 1, 3, 3, NULL);
INSERT INTO item VALUES (4, 2, 1, 7, NULL);
INSERT INTO item VALUES (5, 2, 2, 5, NULL);
INSERT INTO item VALUES (6, 2, 3, 6, NULL);
INSERT INTO item VALUES (7, 3, 1, 10, NULL);
INSERT INTO item VALUES (8, 3, 4, 10, NULL);
INSERT INTO item VALUES (9, 4, 1, 6, NULL);
INSERT INTO item VALUES (10, 4, 2, 3, NULL);SET FOREIGN_KEY_CHECKS = 1;查询表
select * from staffer;添加数据表多条数据
一次性在department表中添加2条记录,分别为:(部门名称:市场部;电话:020-87993093)、
(部门名称:宣传部;电话:020-87993065)
select * from department;
insert into department (dept_name,dept_phone) values ('市场部','020-87993093'),('宣传部','020-87993065');
select * from department;查询表中某数据
在goods表中查询各商品的3件费用
-- 3件费用是商品单价*3的价格,可使用表达式计算

select goods_name,unit_price,unit_price*3 as '3件费用' from goods_; 查询goods_表第一行开始的2条记录
select * from goods_ limit 1,2;查询staffer表中姓张的员工,并显示其staff_id,staff_name,deptartment_id,sex
select staff_id,staff_name,deptartment_id,sex from staffer where staff_name like '张%';item 表,按商品和供应商分组,查询各商品的各供应商提供的销售数量和总数量
-- 分析:当汇总有2个以上字段是需要用with rollup 子句才能达到按从左到右分类的目的
select * from item;
select goods_id,order_id,sum(quantity) from item group by goods_id,order_id with rollup;增insert 删delete 改update 查select






where
select 后面的"或者字段名,决定了返回什么样的字段(列):
select 中 where 子句,决定了返回什么样的记录(行);

like
范围查找

order by
当一条select语句出现了where和order by
select * from 表名 where 条件 order by 字段1,字段2;
一定要把where写在order by前面
asc 从小到大 可以省略
desc 从大到小
默认从小到大 (asc)

聚合函数
count

max

min sum avg



group by
select 聚合函数 from 表名 where 条件 group by 字段
select 聚合函数 from 表名 group by 字段
group by就是配合聚合函数使用的
where和group by 和order by的顺序:
select * from 表名 where 条件 group by 字段 order by 字段

having
having子句
总是出现在group by之后
select * from 表名 group by 字段 having 条件
对比 where 与 having:
where 是对 from 后面指定的表进行数据筛选属于对原始数据的筛选having 是对 group by 的结果进行筛选;
having 后面的条件中可以用聚合函数,where 后面的条件不可以使用聚合函数。
having语法:
select 字段1,字段2,聚合...from 表名group by 字段1,字段2,字段3...
having 字段1,...聚合...


limit
空判断
null不是0,也不是",null在SQL里面代表空,什么也没有
null不能用比较运算符的判断
is null ---是否为null
is not null ---是否不为null
(不能用字段名 = null 字段名 != null这些都是错误的)

视图
建立部门员工视图,显示部门名称和员工对外查阅资料 | staffer 表和 department 表
select * from staffer;
select * from department;
drop view if exists v_staffer;
create view v_staffer
as select dept_name,staff_name,sex,phone from staffer
inner join department on staffer.deptartment_id=department.dept_id;
select * from v_staffer;
存储
创建带入in 参数和输出 out 参数的存储过程
-若需要从存储过程中返回一个或多个检索或统计的值,则可以使用代out关键字定义的输出参数,将返回值传回调用环境
在数据库db_shop中建立一个存储过程,能够通过部门编号统计该部门员工的人数,返回统计值,并调佣该存储过程
-- 分析:部门编号是输入参数,统计的员工人数是输出参数
drop procedure if exists p_count;
delimiter //
create procedure p_count(in id int,out n int)
BEGIN
select count(*) into n from staffer where deptartment_id=id;
end //
delimiter ;
call p_count(1,@a);
select @a as '1号部门员工数';
编写一个函数,可按职员编号查询员工姓名。
use db_shop;
-- 创建函数时,mysql 默认开启了bin-log,因含有sql语句会出错,则需参加
drop function if exists staffer_search;
set global log_bin_trust_function_creators = 1;delimiter //
create FUNCTION staffer_search(sid int)
returns varchar(10)
begin
declare sname varchar (10);
select staff_name into sname from staffer where deptartment_id=sid;
if isnull(sname) then
return '无人';
else
return sname;
end if;
END //
delimiter ;
set @sname = staffer_search(6);
select @sname,staffer_search(7);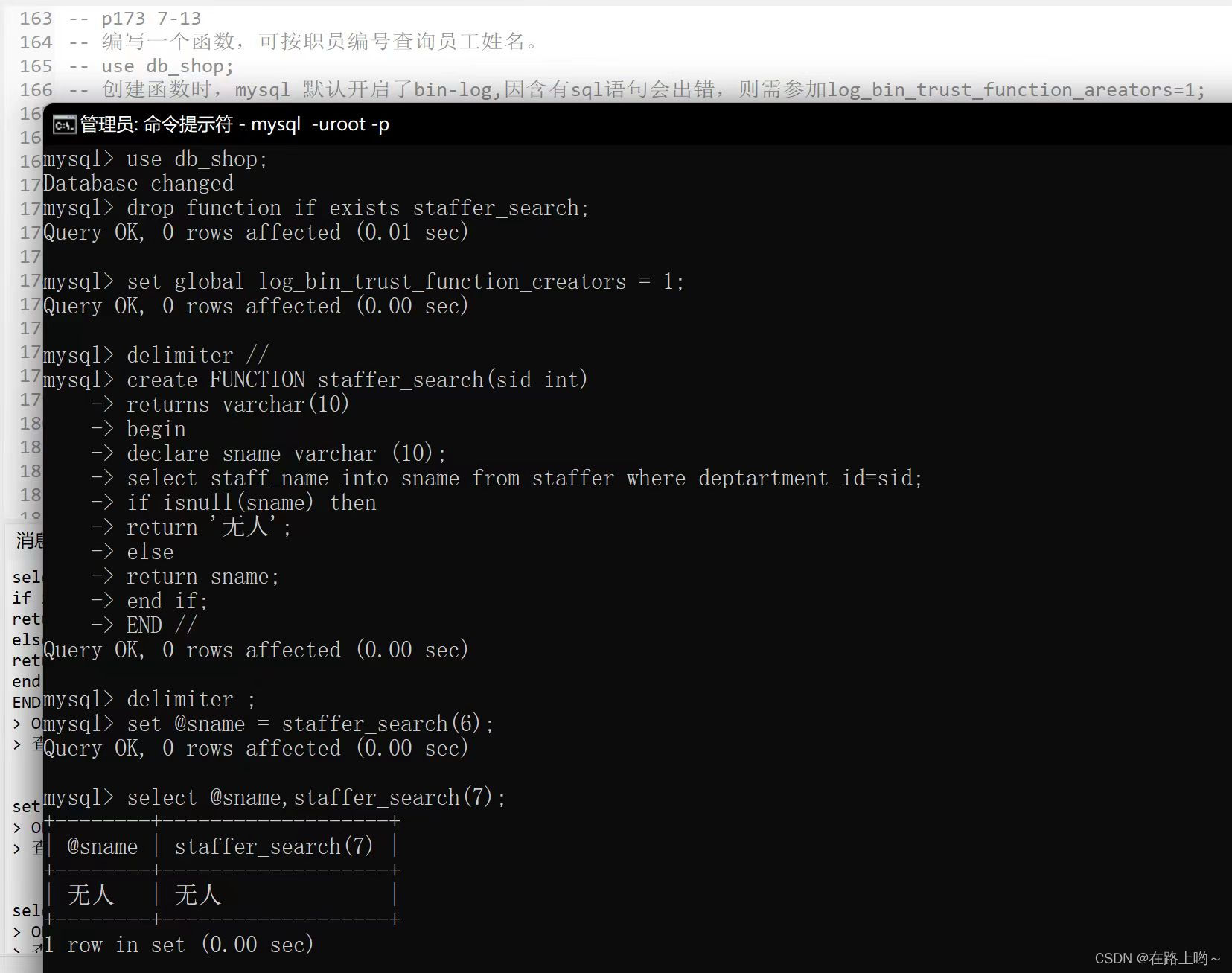
相关文章:
MySQL总复习
目录 登录 显示数据库 创建数据库 删除数据库 使用数据库 创建表 添加数据表数据 查询表 添加数据表多条数据 查询表中某数据 增insert 删delete 改update 查select where like 编辑 范围查找 order by 聚合函数 count max min sum avg g…...
桌面平台层安全随手记录
声明 本文是学习桌面云安全技术要求. 而整理的学习笔记,分享出来希望更多人受益,如果存在侵权请及时联系我们 桌面平台层安全 桌面接入安全 用户标识 一般要求 本项要求包括: a) 系统应为用户提供唯一的身份标识,同时将用户的身份标识与该用户的所…...
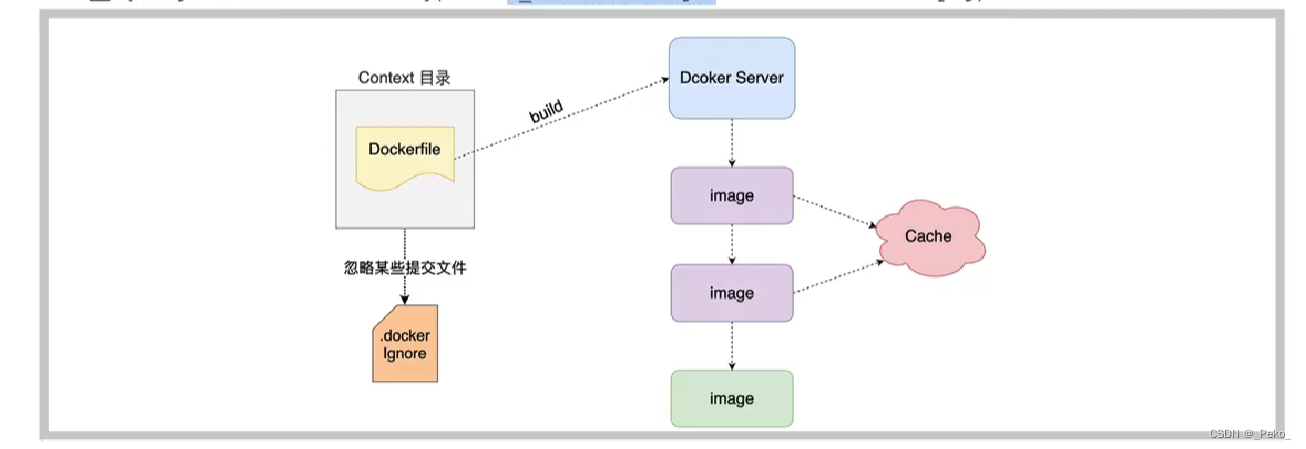
【Docker】 08-Dockerfile
什么是Dockerfile Dockerfile可以认为是Docker镜像的描述文件,是由一系列命令和参数构成的教程,主要作用是用来构建docker镜像的构建文件。 Dockerfile解析过程 Dockerfile的保留命令 保留字作用FROM当前镜像是基于哪个镜像的 第一个指令必须是FROMMA…...
【二等奖方案】大规模金融图数据中异常风险行为模式挖掘赛题「Aries」解题思路
第十届CCF大数据与计算智能大赛(2022 CCF BDCI)已圆满结束,大赛官方竞赛平台DataFountain(简称DF平台)正在陆续释出各赛题获奖队伍的方案思路,欢迎广大数据科学家交流讨论。 本方案为【大规模金融图数据中…...
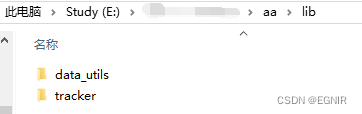
Github 下载指定文件夹(git sparse-checkout)
比如要下载这里的 data_utils 步骤 1、新建空文件夹,并进入新建的空文件夹。 2、git init 初始化 3、git remote add origin 添加远程仓库 4、git config core.sparsecheckout true 允许稀疏检出 5、git sparse-checkout set 设置需要拉取的文件夹(可…...

蚂蚁集团SQLess 开源,与内部版有何区别?
当我们使用关系型数据库时,SQL 是联系起用户和数据库的一座桥梁。 SQL 是一种高度非过程化的语言,当我们在编写SQL 时,表达的是想要什么数据,而不是怎么获取数据。因此,我们往往更关心SQL 有没有满足业务逻辑ÿ…...
An Efficient Memory-Augmented Transformer for Knowledge-Intensive NLP Tasks
本文是LLM系列文章,针对《An Efficient Memory-Augmented Transformer for Knowledge 一种用于知识密集型NLP任务的高效内存增强转换器 摘要1 引言2 相关工作3 高效内存增强Transformer4 EMAT的训练流程5 实验6 分析7 结论局限性 摘要 获取外部知识对于许多自然语言…...

Java项目中jar war pom包的区别
1、pom:用在父级工程或聚合工程中,用来做jar包的版本控制,必须指明这个聚合工程的打包方式为pom。 <project ...> <modelVersion>4.0.0</modelVersion> <groupId>com.wong.tech</groupId> <artifactI…...

整理mongodb文档:分页
个人博客 整理mongodb文档:分页 个人博客,求关注,如果文章不够清晰,麻烦指出。 文章概叙 本文主要讲下在聚合以及crud的find方法中如何使用limit还有skip进行排序。 分页的情况很经常出现,这也是这篇博客诞生的理由。 数据准备…...
社区团购新玩法,生鲜蔬菜配货发货小程序商城
在当前的电商市场中,生鲜市场具有巨大的潜力和发展空间。为了满足消费者的需求,许多生鲜店正在寻找创新的方法来提高销售和客户满意度。其中,制作一个个性且功能强大的生鲜小程序商城是一个非常有效的策略。以下是在乔拓云平台上制作生鲜小程…...

shell bash中设置命令set
1 Preface/Foreword set命令用于shell脚本在执行命令时候,遇到异常的处理机制。 2 Usage 2.1 set -e 当执行命令过程中遇到异常,那么就退出脚本,不会往下执行其它命令。 #!/bin/bash #set -eroot GIT_TAG${CI_BUILD_TAG-NOTAG} GIT_REV…...
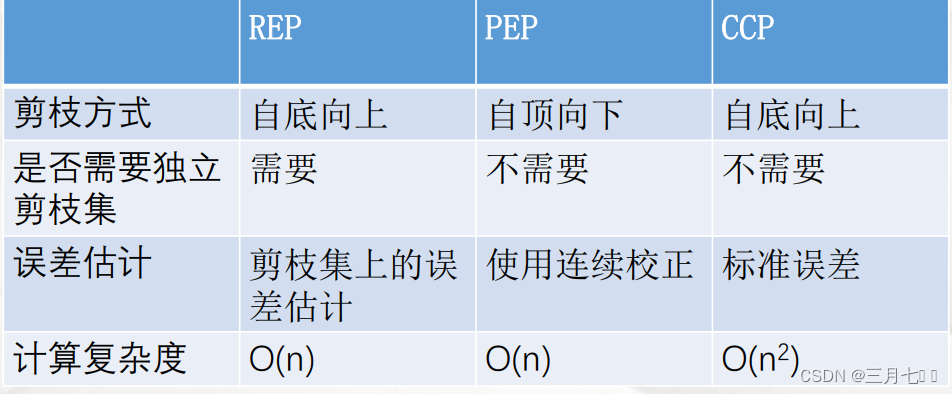
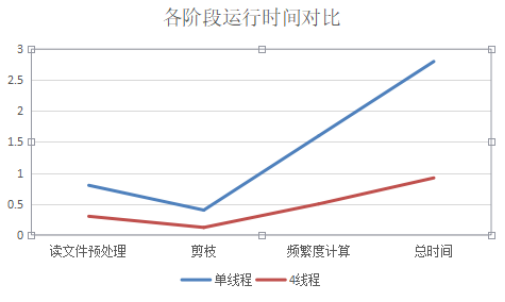
机器学习---预剪枝、后剪枝(REP、CCP、PEP、)
1. 为什么要进行剪枝 横轴表示在决策树创建过程中树的结点总数,纵轴表示决策树的预测精度。 实线显示的是决策树 在训练集上的精度,虚线显示的则是在⼀个独⽴的测试集上测量出来的精度。 随着树的增⻓,在 训练样集上的精度是单调上升的&…...

Python 爬虫—scrapy
scrapy用于从网站中提取所需数据的开源协作框架。以一种快速、简单但可扩展的方式。 该爬虫框架适合于那种静态页面, js 加载的话,如果你无法模拟它的 API 请求,可能就需要使用 selenium 这种使用无头浏览器的方式来完成你的需求了 入门 imp…...
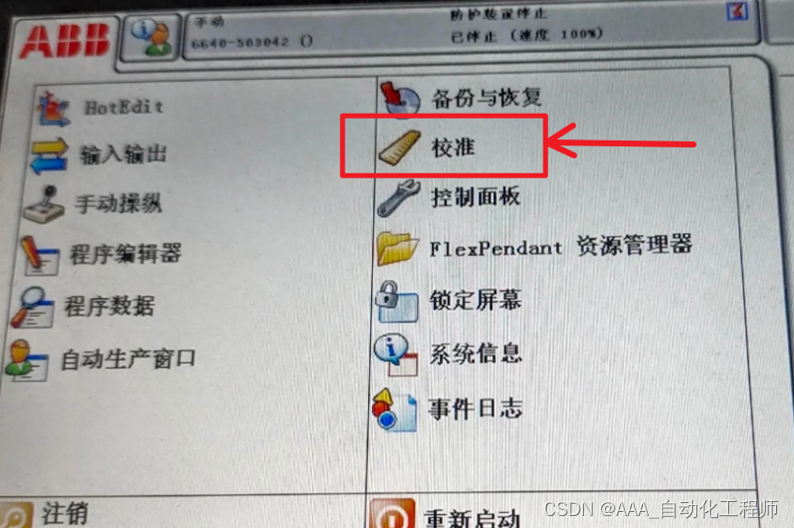
ABB机器人20032转数计数器未更新故障报警处理方法
ABB机器人20032转数计数器未更新故障报警处理方法 ABB的机器人上面安装有电池,需要定期进行更换(正常一年换一次),如果长时间不更换,电量过低,就会出现转数计数器未更新的报警,各轴编码器的位置就会丢失,在更换新电池后,需要更新转数计数器。 具体步骤如下: 先用手动…...

C# 记事本应用程序
using System; using System.Collections.Generic; using System.ComponentModel; using System.Data; using System.Drawing; using System...

模型训练:优化人工智能和机器学习,完善DevOps工具的使用
作者:JFrog大中华区总经理董任远 据说法餐的秘诀在于黄油、黄油、更多的黄油。同样,对于DevOps而言,成功的三大秘诀是自动化、自动化、更高程度的自动化,而这一切归根结底都在于构建能够更快速地不断发布新版软件的流程。 尽管人…...
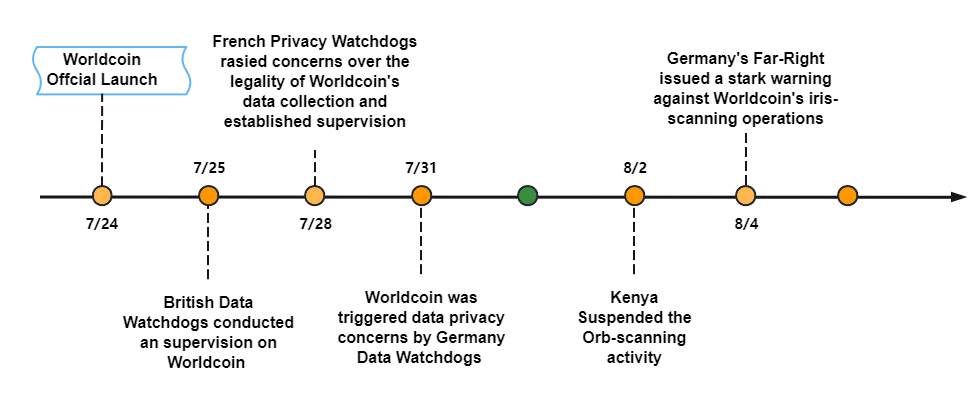
WorldCoin 运营数据,业务安全分析
WorldCoin 运营数据,业务安全分析 Worldcoin 的白皮书中声明,Worldcoin 旨在构建一个连接全球人类的新型数字经济系统,由 OpenAI 创始人 Sam Altman 于 2020 年发起。通过区块链技术在 Web3 世界中实现更加公平、开放和包容的经济体系&#…...

Java之Calender类的详细解析
Calendar类 3.1 概述 java.util.Calendar类表示一个“日历类”,可以进行日期运算。它是一个抽象类,不能创建对象,我们可以使用它的子类:java.util.GregorianCalendar类。 有两种方式可以获取GregorianCalendar对象: …...
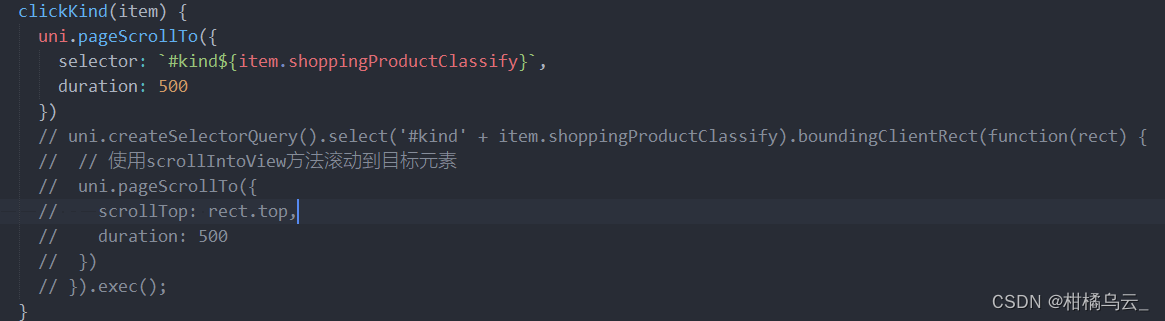
uniapp 微信小程序 锚点跳转
uniapp文档 以下是我遇到的业务场景,是点击商品分类的某一类 然后页面滚动至目标分类, 首先第一步是设置锚点跳转的目的地,在目标的dom上面添加id属性 然后给每个分类每一项添加点击事件,分类这里的item数据里面有一字段是和上…...

主成分分析笔记
主成分分析是指在尽量减少失真的前提下,将高维数据压缩成低微的方式。 减少失真是指最大化压缩后数据的方差。 记 P P P矩阵为 n m n\times m nm( n n n行 m m m列)的矩阵,表示一共有 m m m组数据,每组数据有 n n n…...

苏州晟雅泰电子:关于长鑫存储与兆易创新的关系
长鑫存储(及其母公司长鑫科技)与兆易创新的关系极为紧密,是由一位核心人物——董事长朱一明联结而成的深度战略联盟。这两家公司在股权、人事和业务等多个层面相互绑定,形成了“一个核心、两个支点”的独特格局。以下是其关系的具…...

咖啡一杯,Token 无限,Real-Time Cafe 深圳站来了!新增「硬件晒晒桌」与「AI 桌游试玩桌」
咖啡一杯,Token 无限——「Real-Time Cafe」是一个让开发者聚在一起实时 coding、实时 debug、实时互动的咖啡馆快闪计划。 Real-Time Cafe 深圳站来了!就在本周日 5 月 24 日下午。 本站特设「硬件晒晒桌」与「AI 桌游试玩桌」——带上你的电子宠物、…...

Agent Skills 万千应用 · 第04篇 Excel 分析 Skill:让 Agent 会整理表格、建公式、画图表
Agent Skills 万千应用 第04篇 Excel 分析 Skill:让 Agent 会整理表格、建公式、画图表01|场景痛点开场📊 周一早上,老板丢过来一份 Excel:销售流水 8000 行、客户名称有重复、日期格式不统一、金额里还混着“元”和空…...

5.12linux自学
1,安装vMware2,部署Kali Linux虚拟机3,了解Linux的优点:多人多任务环境安全性高4,格式化的概念:每种操作系统所配置的文件属性/权限并不相同,为了存放这些文件所需的数据,因此就需要进行格式化,以成为操作系…...

NVIDIA Profile Inspector完整指南:免费解锁显卡隐藏性能的终极工具
NVIDIA Profile Inspector完整指南:免费解锁显卡隐藏性能的终极工具 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector 你是否曾经想过,为什么你的NVIDIA显卡明明性能不错ÿ…...

Parsec虚拟显示驱动实战教程:5步创建完美游戏串流显示环境
Parsec虚拟显示驱动实战教程:5步创建完美游戏串流显示环境 【免费下载链接】parsec-vdd ✨ Perfect virtual display for game streaming 项目地址: https://gitcode.com/gh_mirrors/pa/parsec-vdd Parsec虚拟显示驱动(Parsec VDD)是一…...

AI气象模型统一基准:可复现、多源真值、时空一致的评测标尺
1. 这不是又一个“天气数据集”,而是一把标尺:为什么AI气象建模急需统一基准“AI Weather Models”这个词组最近两年在气象学会议、AI顶会和工业界技术白皮书里出现的频率,已经快赶上“大模型”本身了。但我和团队在去年参与三个不同机构的AI…...

TPU加速GAN训练实战:从设备配置到FID达标完整指南
1. 项目概述:为什么用TPU跑GAN不是“炫技”,而是解决实际瓶颈的刚需你有没有在Kaggle或Colab上训练过DCGAN、StyleGAN2或者哪怕一个简化版的WGAN?我试过——在单块P100 GPU上跑一个6464分辨率的生成器,50个epoch要花3小时17分钟&a…...

GitHub中文插件:打破语言壁垒,让代码世界更亲切
GitHub中文插件:打破语言壁垒,让代码世界更亲切 【免费下载链接】github-chinese GitHub 汉化插件,GitHub 中文化界面。 (GitHub Translation To Chinese) 项目地址: https://gitcode.com/gh_mirrors/gi/github-chinese 你是否曾因Git…...

“10车道变4车道“——一家建筑施工企业CFO的数字化突围实录
——业务说赚钱、财务说亏钱,这笔账到底听谁的?一个在建筑行业天天上演的场景项目经理拍着胸脯说:"这个项目我们肯定是赚钱的,利润至少15%。"财务部出完报表,毛利率只有3%,甚至亏损。项目经理冲到…...