Python 爬虫—scrapy
scrapy用于从网站中提取所需数据的开源协作框架。以一种快速、简单但可扩展的方式。
该爬虫框架适合于那种静态页面, js 加载的话,如果你无法模拟它的 API 请求,可能就需要使用 selenium 这种使用无头浏览器的方式来完成你的需求了
入门
import scrapyclass BlogSpider(scrapy.Spider):name = 'blogspider'start_urls = ['https://www.zyte.com/blog/']def parse(self, response):for title in response.css('.oxy-post-title'):# 返回对象yield {'title': title.css('::text').get()}for next_page in response.css('a.next'):# 返回一个连接,爬虫框架会继续请求这个连接,得到响应后再回调 parse 方法yield response.follow(next_page, self.parse)
运行
scrapy runspider myspider.py
代码中通过 main 方式运行调试
# _*_ coding: utf-8 _*_
import os, sys, pprint
from scrapy.cmdline import executedef build_base_config():current_dir_path = os.path.dirname(os.path.abspath(__file__))# sys.path.append(current_dir_name) # 入口文件 与模块查找路径、import 相对路径导入有影响print('\n当前路径 PATH:', current_dir_path)# pprint.pprint(sys.path)filepath, file_name = os.path.split(current_dir_path)spiders_name = file_namespiders_name = "bestbuy_new_ca"return current_dir_path, spiders_namedef run_product_review():"""运行产品评论"""current_dir_path, spiders_name = build_base_config()# 结果输出到本地 json 文件execute(['scrapy', 'crawl', spiders_name + '-products_review',f'-o{current_dir_path}/temp/product-review.json','-LDEBUG',f'-apath={current_dir_path}/temp/review-links.json','-acollect_exist=1'])if __name__ == '__main__':run_product_review()pass
简单说:使用了 scrapy.cmdline 提供的工具,执行的命令和在命令行中的一致,只是这种方式可以在 idea 工具中进行 debug 调试
入门和实际开发的不同之处:
- 开发上:
a.入门:例子相对简单,工程结构也不怎么注重
b.生产:相对复杂,在核心开发上差不多,也是如何去解析 html 结构,工程结构上为了调度和复用,可能会更复杂一点 - 调度平台:
a.有使用一些开源的调度平台,因为是通用
b.还有的可能会再开源的调度平台上,再包装一层自己的调度平台,仅用来展示(符合产品经理的设计)
官方对于动态内容的引导
https://docs.scrapy.org/en/latest/topics/dynamic-content.html
个人感觉这里提供的知识点还是非常具有参考价值的,简单总结:
- 使用 scrapy shell 工具定位数据源
$ scrapy shell "quotes.toscrape.com/scroll"
(...)
>>> view(response)
- 使用 scrapy fetch 工具获取响应到文件,这类似与查看网页源代码
scrapy fetch --nolog https://example.com > response.html
- 复制请求:在浏览器中可以将请求复制为 curl 格式,然后可以使用 form_curl() 来使用
from scrapy import Requestrequest = Request.from_curl("curl 'https://quotes.toscrape.com/api/quotes?page=1' -H 'User-Agent: Mozil""la/5.0 (X11; Linux x86_64; rv:67.0) Gecko/20100101 Firefox/67.0' -H 'Acce""pt: */*' -H 'Accept-Language: ca,en-US;q=0.7,en;q=0.3' --compressed -H 'X""-Requested-With: XMLHttpRequest' -H 'Proxy-Authorization: Basic QFRLLTAzM""zEwZTAxLTk5MWUtNDFiNC1iZWRmLTJjNGI4M2ZiNDBmNDpAVEstMDMzMTBlMDEtOTkxZS00MW""I0LWJlZGYtMmM0YjgzZmI0MGY0' -H 'Connection: keep-alive' -H 'Referer: http""://quotes.toscrape.com/scroll' -H 'Cache-Control: max-age=0'")
- 解析 JavaScript 代码:html 中有些网站会出现
<script>中间是大段的 json 数据有可能是变量,也有可能是初始化数据之类的</script>,就可以使用
比如是
var data = {"field": "value"};可以使用如下的方式匹配
pattern = r'\bvar\s+data\s*=\s*(\{.*?\})\s*;\s*\n'
json_data = response.css('script::text').re_first(pattern)
json.loads(json_data)
{'field': 'value'}
相关文章:

Python 爬虫—scrapy
scrapy用于从网站中提取所需数据的开源协作框架。以一种快速、简单但可扩展的方式。 该爬虫框架适合于那种静态页面, js 加载的话,如果你无法模拟它的 API 请求,可能就需要使用 selenium 这种使用无头浏览器的方式来完成你的需求了 入门 imp…...
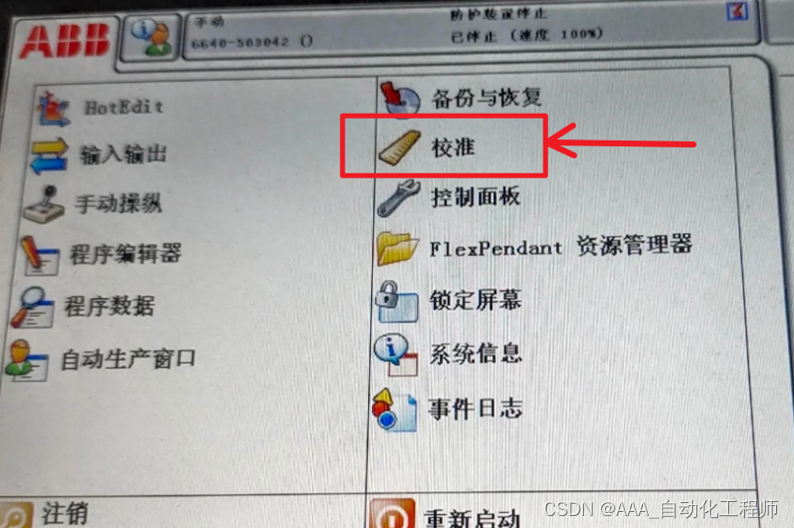
ABB机器人20032转数计数器未更新故障报警处理方法
ABB机器人20032转数计数器未更新故障报警处理方法 ABB的机器人上面安装有电池,需要定期进行更换(正常一年换一次),如果长时间不更换,电量过低,就会出现转数计数器未更新的报警,各轴编码器的位置就会丢失,在更换新电池后,需要更新转数计数器。 具体步骤如下: 先用手动…...

C# 记事本应用程序
using System; using System.Collections.Generic; using System.ComponentModel; using System.Data; using System.Drawing; using System...

模型训练:优化人工智能和机器学习,完善DevOps工具的使用
作者:JFrog大中华区总经理董任远 据说法餐的秘诀在于黄油、黄油、更多的黄油。同样,对于DevOps而言,成功的三大秘诀是自动化、自动化、更高程度的自动化,而这一切归根结底都在于构建能够更快速地不断发布新版软件的流程。 尽管人…...
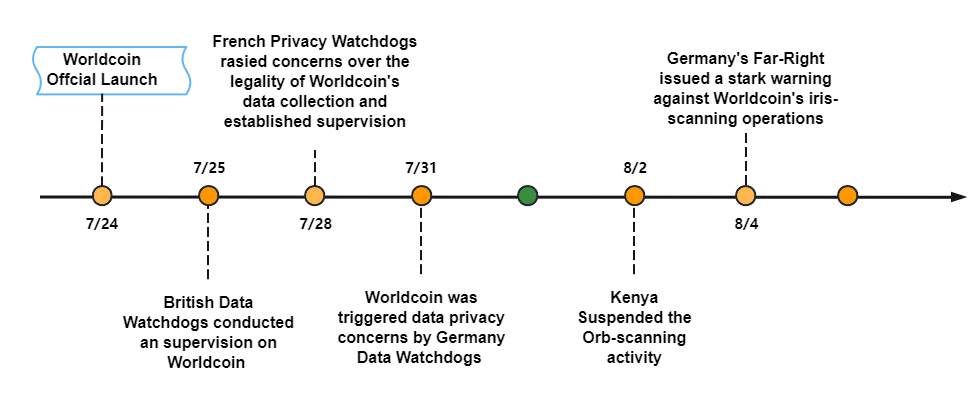
WorldCoin 运营数据,业务安全分析
WorldCoin 运营数据,业务安全分析 Worldcoin 的白皮书中声明,Worldcoin 旨在构建一个连接全球人类的新型数字经济系统,由 OpenAI 创始人 Sam Altman 于 2020 年发起。通过区块链技术在 Web3 世界中实现更加公平、开放和包容的经济体系&#…...

Java之Calender类的详细解析
Calendar类 3.1 概述 java.util.Calendar类表示一个“日历类”,可以进行日期运算。它是一个抽象类,不能创建对象,我们可以使用它的子类:java.util.GregorianCalendar类。 有两种方式可以获取GregorianCalendar对象: …...
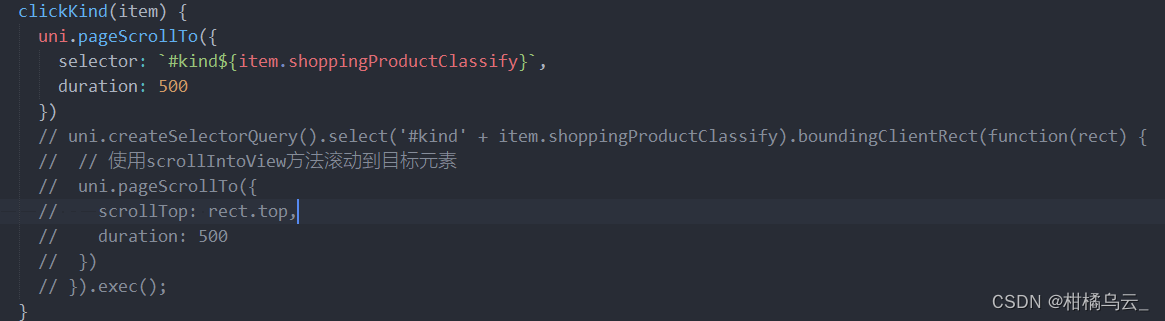
uniapp 微信小程序 锚点跳转
uniapp文档 以下是我遇到的业务场景,是点击商品分类的某一类 然后页面滚动至目标分类, 首先第一步是设置锚点跳转的目的地,在目标的dom上面添加id属性 然后给每个分类每一项添加点击事件,分类这里的item数据里面有一字段是和上…...

主成分分析笔记
主成分分析是指在尽量减少失真的前提下,将高维数据压缩成低微的方式。 减少失真是指最大化压缩后数据的方差。 记 P P P矩阵为 n m n\times m nm( n n n行 m m m列)的矩阵,表示一共有 m m m组数据,每组数据有 n n n…...
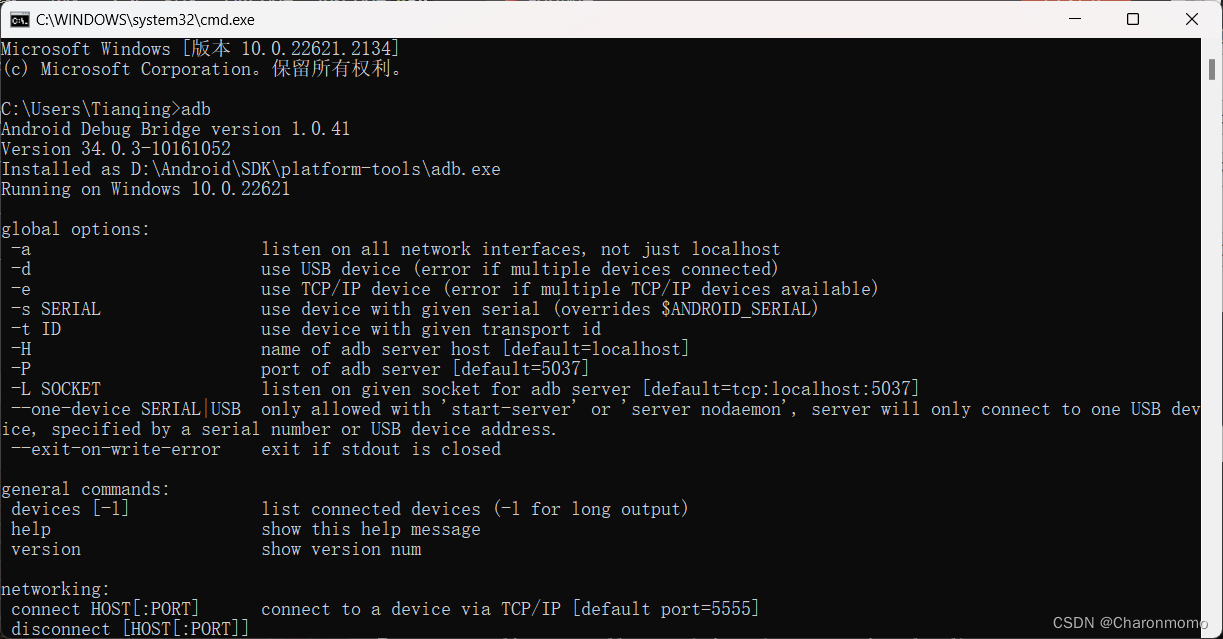
android studio 的 adb配置
首先在 Android Studio 中 打开 File -> Settings: 下载 “Google USB Driver” 这个插件 (真机调试的时候要用到), 并且记一下上面的SDK路径: 右键桌面上的 “我的电脑”, 点击 “高级系统设置”, 配置计算机的高级属性, 有两步: 添加一个新的环境变量 ANDROID_HOME, 变量…...

【HTML5高级第一篇】Web存储 - cookie、localStorage、sessionStorage
文章目录 一、数据存储1.1 cookie1.1.1 概念介绍1.1.2 存储与获取1.1.3 方法的封装1.1.4 总结 1.2 localstorage 与 sessionstorage1.2.1 概述1.2.2 操作数据的属性或方法1.2.3 案例-提交问卷1.2.4 Web Storage带来的好处 附录:1. HTML5提供的数据持久化技术&#x…...
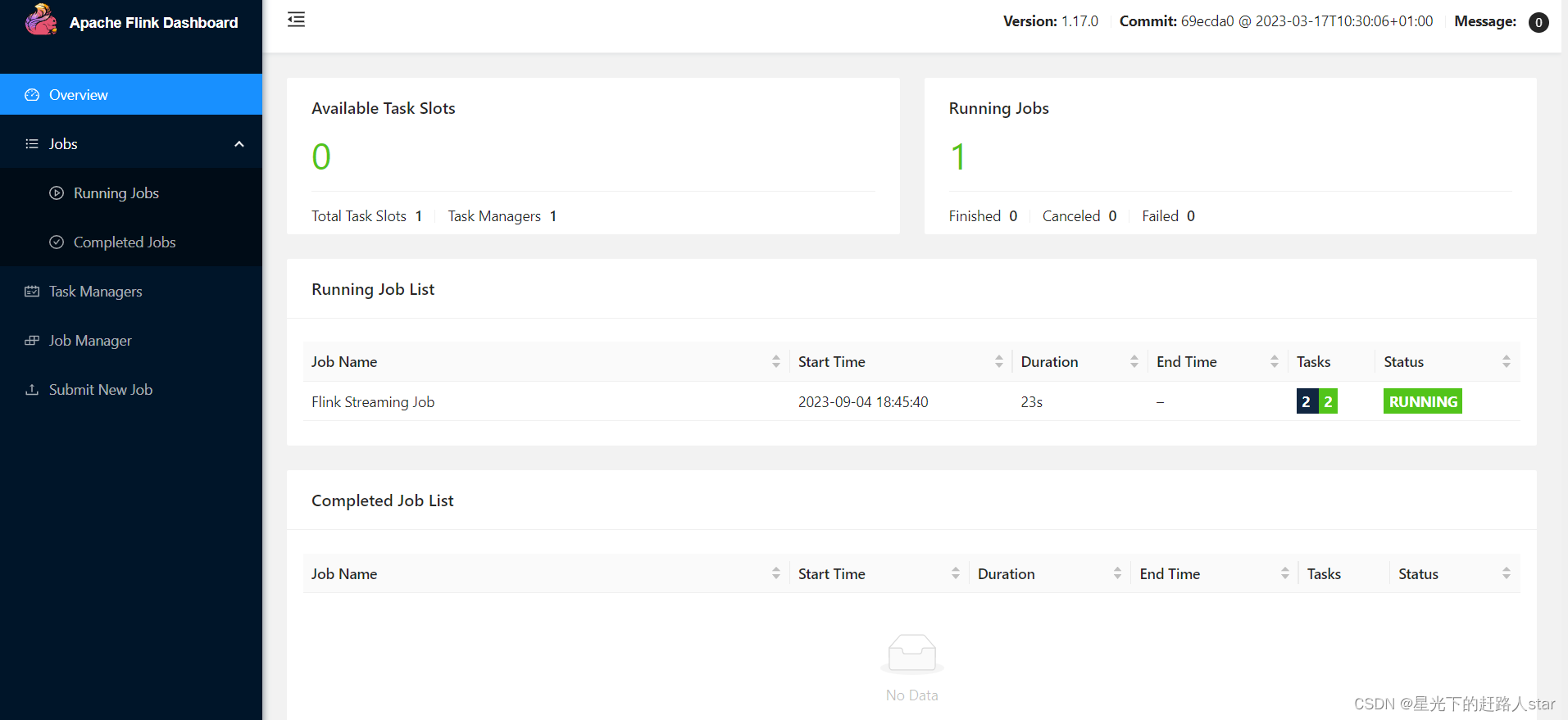
Flink---1、概述、快速上手
1、Flink概述 1.1 Flink是什么 Flink的官网主页地址:https://flink.apache.org/ Flink的核心目标是“数据流上有状态的计算”(Stateful Computations over Data Streams)。 具体说明:Apache Flink是一个“框架和分布式处理引擎”,用于对无界…...
QT实现TCP通信(服务器与客户端搭建)
一、TCP通信框架 二、QT中的服务器操作 创建一个QTcpServer类对象,该类对象就是一个服务器调用listen函数将该对象设置为被动监听状态,监听时,可以监听指定的ip地址,也可以监听所有主机地址,可以通过指定端口号&#x…...

云备份项目
云备份项目 1. 云备份认识 自动将本地计算机上指定文件夹中需要备份的文件上传备份到服务器中。并且能够随时通过浏览器进行查看并且下载,其中下载过程支持断点续传功能,而服务器也会对上传文件进行热点管理,将非热点文件进行压缩存储&…...

基础算法(一)
目录 一.排序 快速排序: 归并排序: 二.二分法 整数二分模板: 浮点二分: 一.排序 快速排序: 从数列中挑出一个元素,称为 "基准"重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面&#…...
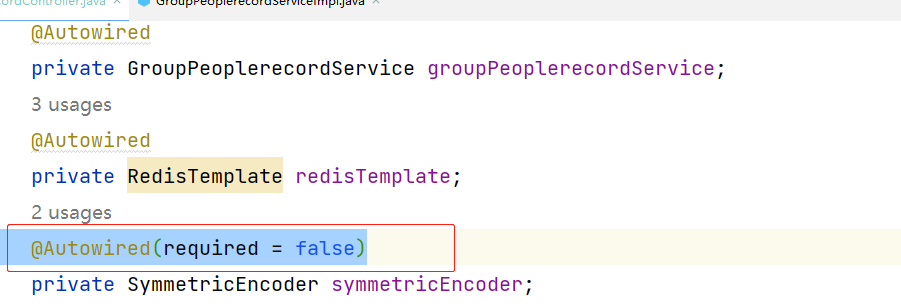
Consider defining a bean of type问题解决
Consider defining a bean of type问题解决 Consider defining a bean of type问题解决 包之后,发现项目直接报错Consider defining a bean of type。 会有一些包你明明Autowired 但是还是找不到什么bean 导致你项目启动不了 解决方法一: 这个问题主要是因为项目拆包…...

Android 1.2.1 使用Eclipse + ADT + SDK开发Android APP
1.2.1 使用Eclipse ADT SDK开发Android APP 1.前言 这里我们有两条路可以选,直接使用封装好的用于开发Android的ADT Bundle,或者自己进行配置 因为谷歌已经放弃了ADT的更新,官网上也取消的下载链接,这里提供谷歌放弃更新前最新…...
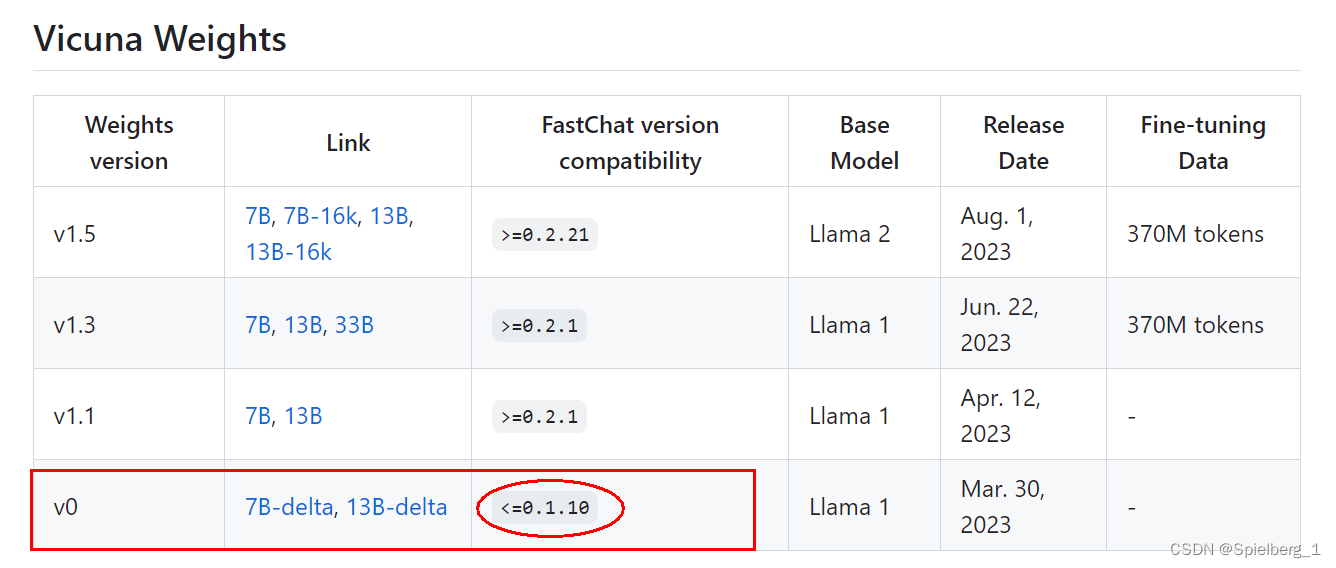
Llama-7b-hf和vicuna-7b-delta-v0合并成vicuna-7b-v0
最近使用pandagpt需要vicuna-7b-v0,重新过了一遍,前段时间部署了vicuna-7b-v3,还是有不少差别的,transforms和fastchat版本更新导致许多地方不匹配,出现很多错误,记录一下。 更多相关内容可见Fastchat实战…...

Centos、OpenEuler系统安装mysql
要在CentOS上安装MySQL并设置开机自启和root密码,请按照以下步骤进行操作: 确保您的CentOS系统已连接到Internet,并且具有管理员权限(root或sudo访问权限)。打开终端或SSH会话,使用以下命令安装MySQL&…...
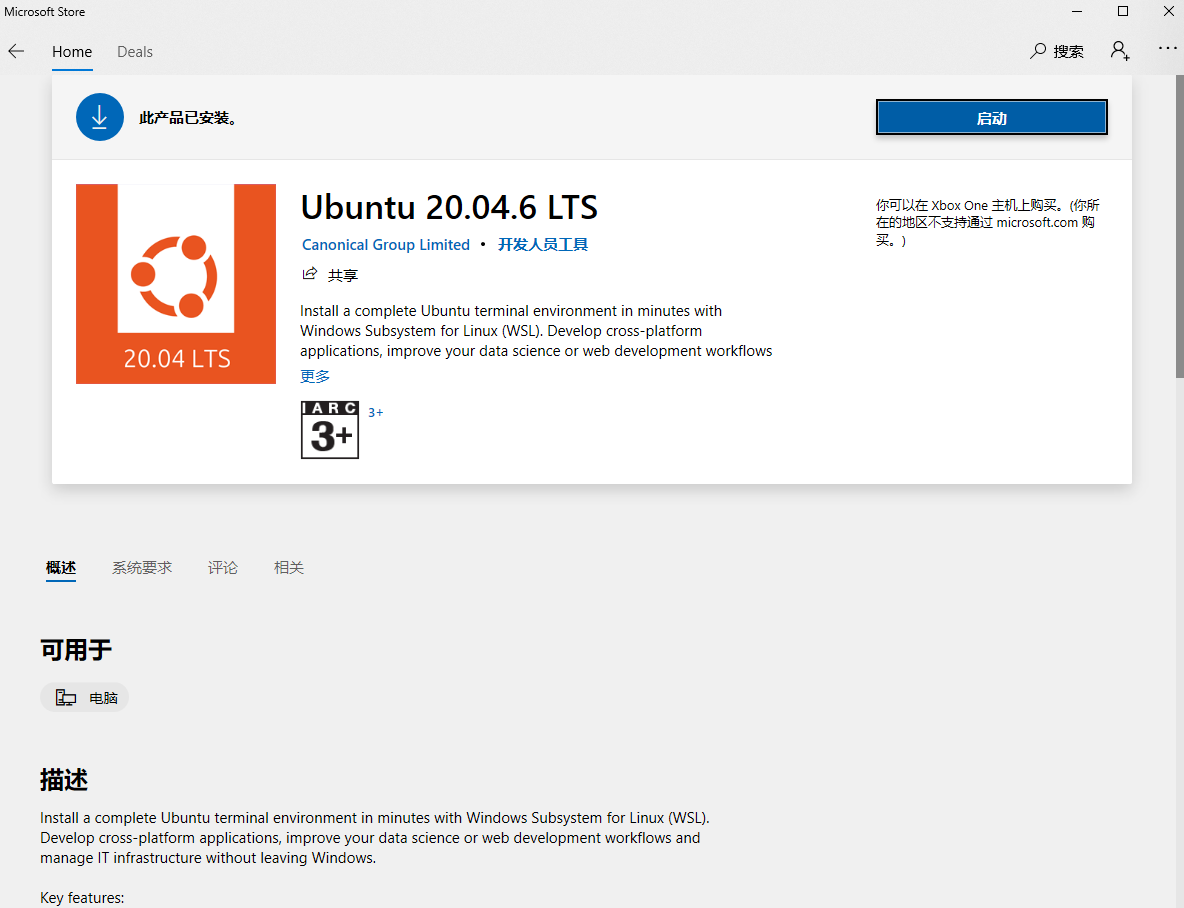
如何在Win10系统上安装WSL(适用于 Linux 的 Windows 子系统)
诸神缄默不语-个人CSDN博文目录 本文介绍的方法不是唯一的安装方案,但在我的系统上可用。 文章目录 1. 视频版2. 文字版和代码3. 本文撰写过程中使用到的其他网络参考资料 1. 视频版 B站版:在Windows上安装Linux (WSL, 适用于 Linux 的 Windows 子系统…...
单片机通用学习-什么是寄存器?
什么是寄存器? 寄存器是一种特殊的存储器,主要用于存储和检查微机的状态。CPU寄存器用于存储和检查CPU的状态,具体包括计算中途数据、程序因中断或子程序分支时的返回地址、计算结果为零时的负值、计算结果为零时的信息、进位值等。 由于CP…...

从零开始在Taotoken平台创建管理密钥并获取调用示例代码
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 从零开始在Taotoken平台创建管理密钥并获取调用示例代码 1. 开始前的准备 如果你刚开始接触大模型API,可能会觉得配置…...

超厉害!AI写教材,低查重且内容连贯,快速产出专业教材!
整理教材知识点实在是一项“精细工作”,最大的挑战在于如何保持平衡与衔接!我们常常担忧会遗漏核心概念,或是难以掌握合适的难度梯度——小学教材常常写得过于复杂,导致学生难以理解;而高中教材则可能显得过于简单&…...

Kubernetes故障排查与问题定位:实战指南
Kubernetes故障排查与问题定位:实战指南 一、故障排查概述 Kubernetes故障排查是运维工作中的重要环节。常见的故障类型包括: Pod故障:Pod无法启动、崩溃、重启网络故障:Pod之间无法通信、服务不可访问存储故障:持久…...

构造函数、this指向和原型链机制
今天在刷力扣 [146. LRU 缓存](https://leetcode.cn/problems/lru-cache/) 的时候,遇到了原型链的写法,想想这个写法我正式开发中从来都没有用过,到底是个什么玩意?遂将各个节点和变量都定义在外面,但是代码居然报错啦…...

【Coze工作流】零代码做AI自动化,小白也能5分钟上手
一、问题背景:手工做重复AI任务太累,想自动化但不会写代码在日常办公或者内容创作中,很多人都有过这样的痛点:每天要重复打开各种AI工具。比如你要写一篇爆款文章,先要找AI找选题,再让AI写大纲,…...

5分钟快速上手:Parsec VDD虚拟显示器终极指南,解锁Windows显示新境界
5分钟快速上手:Parsec VDD虚拟显示器终极指南,解锁Windows显示新境界 【免费下载链接】parsec-vdd ✨ Perfect virtual display for game streaming 项目地址: https://gitcode.com/gh_mirrors/pa/parsec-vdd 你是否遇到过这样的困扰?…...

5个关键功能:如何将普通鼠标打造成macOS生产力神器?
5个关键功能:如何将普通鼠标打造成macOS生产力神器? 【免费下载链接】mac-mouse-fix Mac Mouse Fix - Make Your $10 Mouse Better Than an Apple Trackpad! 项目地址: https://gitcode.com/GitHub_Trending/ma/mac-mouse-fix 你是否曾为macOS上的…...

三分钟永久备份QQ空间:让青春记忆永不褪色的终极方案
三分钟永久备份QQ空间:让青春记忆永不褪色的终极方案 【免费下载链接】QZoneExport QQ空间导出助手,用于备份QQ空间的说说、日志、私密日记、相册、视频、留言板、QQ好友、收藏夹、分享、最近访客为文件,便于迁移与保存 项目地址: https://…...

DroidCam OBS Plugin终极指南:3步将手机变身高清直播摄像头
DroidCam OBS Plugin终极指南:3步将手机变身高清直播摄像头 【免费下载链接】droidcam-obs-plugin DroidCam OBS Source 项目地址: https://gitcode.com/gh_mirrors/dr/droidcam-obs-plugin 想要零成本打造专业直播设备?DroidCam OBS Plugin就是你…...

3个妙招突破百度网盘限速:baidu-wangpan-parse终极解析指南
3个妙招突破百度网盘限速:baidu-wangpan-parse终极解析指南 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 你是否经历过这样的场景?急着下载一份重要的…...