Flink---1、概述、快速上手
1、Flink概述
1.1 Flink是什么
Flink的官网主页地址:https://flink.apache.org/
Flink的核心目标是“数据流上有状态的计算”(Stateful Computations over Data Streams)。
具体说明:Apache Flink是一个“框架和分布式处理引擎”,用于对无界和有界数据流进行有状态计算。
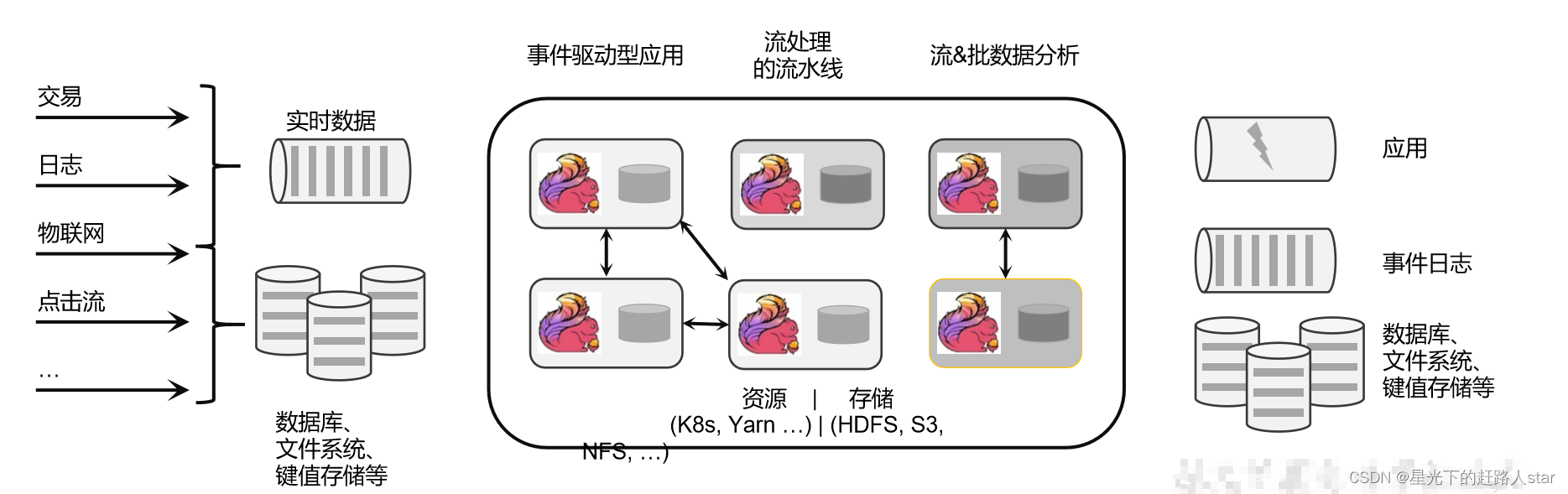
1.1.1 无界数据流
- 有定义流的开始,但是没有定义流的结束
- 它们会无休止的产生数据
- 无界流的数据必须持续处理,即数据被摄取后需要立即处理。我们不能等到所有数据都到达再处理,因为输入时无限的。
1.1.2 有界数据流
- 有定义流的开始,也有定义流的结束
- 有界流可以在摄取所有数据后再进行计算
- 有界流所有的数据可以被排序,所有并不需要有序摄取
- 有界流处理通常被称为批处理
1.1.3 有状态流处理
把流处理需要的额外数据保存成一个“状态”,然后针对这条数据进行处理,并且更新状态,这就是所谓的“有状态的流处理”。
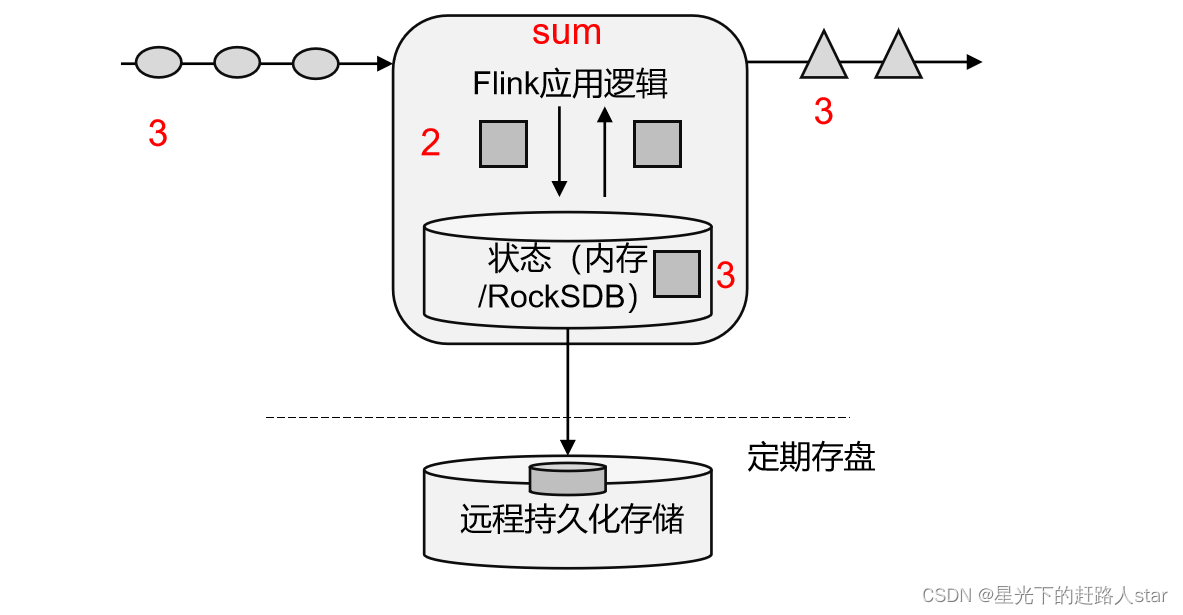
- 状态在内存中:优点:速度快;缺点:可靠性差
- 状态在分布式系统中:优点:可靠性高;缺点:速度慢
1.1.4 Flink发展历史

1.2 Flink特点
我们处理数据的目标是:低延迟、高吞吐、结果的准确性和良好的容错性。
Flink主要特点如下:
- 高吞吐和低延迟:每秒处理数百万个事件,毫秒级延迟
- 结果的准确性:Flink提供了事件时间(event-time)和处理时间(processing-time)语义。对于乱序事件流,事件时间语义仍然能提供一致且准确的结果。
- 精确一次(exactly-once)的状态一致性保证
- 可以连接到最常用的外部系统,如kafka、Hive、JDBC、HDFS、Redis等
- 高可用:本身高可用的设置,加上K8S,Yarn和Mesos的紧密集成,再加上从故障中快速恢复和动态扩展任务的能力,Flink能做到以极少的停机时间7x24全天候运行。
1.3 Flink和SparkStreaming(说实话没有比较的必要)
1、Spark是以批处理为根本。
2、Flink是以流处理为根本。
1.4 Flink的应用场景
1、电商和市场营销
2、物联网(IOT)
3、物流配送和服务业
4、银行和金融业
1.5 Flink分层API

- 有状态流处理:通过底层API(处理函数),对原始数据加工处理。底层API和DataStreamAPI相集成,可以处理复杂的计算。
- DataStreamAPI(流处理)和DataSetAPI(批处理)封装了底层处理函数,提供了通用的模块,比如转换(transformations,包括map,flatMap等),连接(joins),聚合(aggregations),窗口(Windows)操作等。注意:Flink1.12后,DataStreamAPI已经实现真正的流批一体,所以DataSetAPI已经过时。
- TableAPI是以表为中心的声明式编程,其中表可能会动态变化。TableAPI遵循关系模型;表有二维数据结构,类似于关系数据库中的表,同时API提供可比较的操作,例如select、project、join、group by、aggregate等。我们可以在表与DataStream/DataSet之间无缝切换,以允许程序将TableAPI与DataStream以及DataSet混用。
- SQL这一层在语法与表达能力上与TableAPI类似,但是是以SQL查询表达式的形式表现程序。SQL抽象与TableAPI交互密切,同时SQL查询可以直接在TableAPI定义的表上执行。
2、Flink快速上手
2.1 创建项目
在准备好所有的开发环境之后,我们就可以开始开发自己的第一个Flink程序了。首先我们要做的,就是在IDEA中搭建一个Flink项目的骨架。我们会使用Java项目中常见的Maven来进行依赖管理。
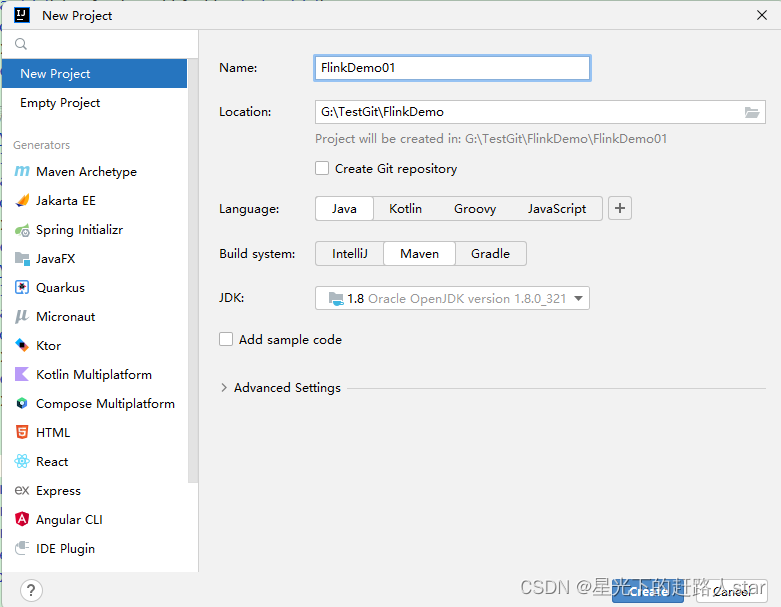
1、创建工程
(1)打开IntelliJ IDEA,创建一个Maven工程。
2、添加项目依赖
<properties><flink.version>1.17.0</flink.version>
</properties><dependencies><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients</artifactId><version>${flink.version}</version></dependency>
</dependencies>
2.2 WordCount代码编写(大数据常用的例子)
需求:统计一段文字中,每个单词出现的频次
环境准备:创建一个com.zhm.wordcount包
2.2.1 批处理
批处理的基本思路:先逐行读入文件数据,然后将每一行文子拆分成单词;接着按照单词分组,统计每组数据的个数,就是对应单词的频次。
1、数据准备
(1)在工程根目录下新建一个data文件夹,并在下面创建文本文件words.txt
(2)在文件中输入一些单词
hello hello hello
world world
hello world
2、代码编写
(1)在com.zhm.wordcount包下新建一个Demo01_BatchProcess类
/*** @ClassName Batch* @Description 利用Flink批处理单词统计* @Author Zouhuiming* @Date 2023/9/3 9:58* @Version 1.0*/import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;/**计算的套路:(1) 计算的环境Spark:SparkContextMR:DriverFlink:ExecutionEnvironment(2) 把要计算的数据封装为计算模型Spark:RDD(Spark Core)DateFrame|DataSet(SparkSQL)DStream(SparkStream)MR:k-VFlink:DataSource(3)调用计算APIRDD.转换算子()MR:自己去编写Mapper、ReducerFlink:DataSource.算子()*/
public class Demo01_BatchProcess {public static void main(String[] args) throws Exception {//创建支持Flink计算的环境ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();//使用环境去读取数据,封装为计算模型DataSource<String> dataSource = env.readTextFile("data/words.txt");//调用计算APIdataSource.flatMap(new FlatMapFunction<String, Tuple2<String,Integer>>() {@Overridepublic void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception {String[] split = s.split(" ");for (String s1 : split) {collector.collect(new Tuple2<String,Integer>(s1,1));}}}).groupBy(0).sum(1).print();}
}运行结果:
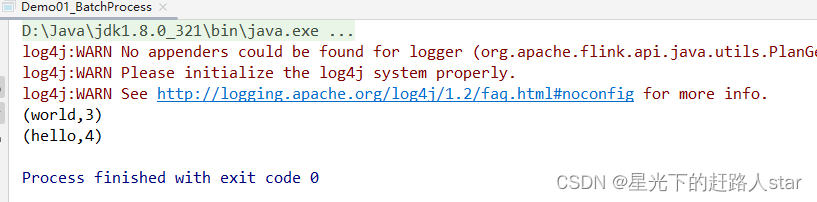
注意:这种实现是基于DataSetAPI的,也就是我们对数据的处理转换,是看作数据集来进行操作的。事实上Flink本身是流批统一的处理架构,批量的数据集本质上也是流,没有必要用两套不同的API来实现。所以从Flink1.12开始,官方推荐的做法是直接使用DataStreamAPI,在提交任务时通过将执行模式设为BATCH来进行批处理;
bin/flink run -Dexecution.runtime-mode=BATCH BatchWordCount.jar
这样,DataSetAPI就没有用了,在实际应用中我们只要维护一套DataStreamAPI就可以。这里只是为了方便大家理解,我们依然用DataSetAPI做了批处理的实现。
2.2.2 流处理
对于Flink而言,流才是整个处理逻辑的底层核心,所以流批一体之后的DataStreamAPI更加强大,可以直接处理批处理和流处理的所有场景。
下面我们就针对不同类型的的输入数据源,用具体的代码来实现流处理。
1、读取文件(有界流)
我们同样试图读取文档words.txt中的数据,并统计每个单词出现的频次。整体思路与之前的批处理非常类似,代码模式也基本一致。
在com.zhm.wordcount包下新建一个Demo02_BoundedStreamProcess类
package com.zhm.wordcount;import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.connector.file.src.FileSource;
import org.apache.flink.connector.file.src.reader.TextLineInputFormat;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;/*** @ClassName Demo02_BoundedStreamProcess* @Description 有界流* @Author Zouhuiming* @Date 2023/9/3 10:26* @Version 1.0*/public class Demo02_BoundedStreamProcess {public static void main(String[] args) throws Exception {//1、创建支持Flink计算的环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();//1.1 设置一个线程处理这个流(默认是根据你的cpu数和单词种类个数,取最小值)
// env.setParallelism(1);//2、获取数据源FileSource<String> source = FileSource.forRecordStreamFormat(new TextLineInputFormat(), new Path("data/words.txt")).build();//3、利用环境将数据源的数据封装为计算模型DataStreamSource<String> streamSource = env.fromSource(source, WatermarkStrategy.noWatermarks(), "myfile");//4、调用API对数据进行计算//4.1 将每行数据按照给定的分割符拆分为Tuple2类型的数据模型(word,1)streamSource.flatMap(new FlatMapFunction<String, Tuple2<String,Integer>>() {@Overridepublic void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception {String[] split = s.split(" ");for (String s1 : split) {collector.collect(new Tuple2<>(s1,1));}}//4.2 根据word分组}).keyBy(new KeySelector<Tuple2<String, Integer>, String>() {@Overridepublic String getKey(Tuple2<String, Integer> stringIntegerTuple2) throws Exception {return stringIntegerTuple2.f0;}//4.3 根据分组之后,按照元组中的第二列聚相加}).sum(1)// 4.4 打印结果.print();//5、提交jobenv.execute();}
}运行结果:
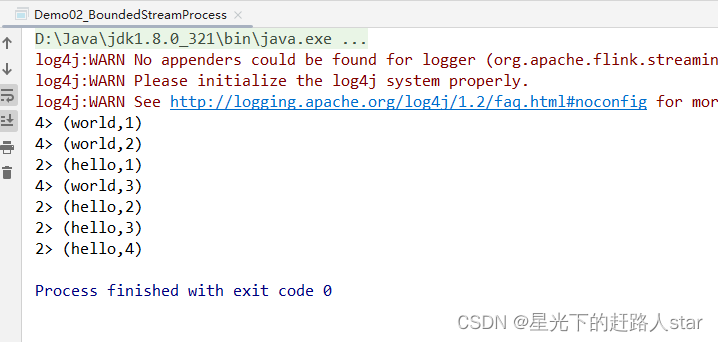
和批处理程序BatchWordCount的不同:
- 创建执行环境的不同,流处理程序使用的是StreamExecutionEnvironment。
- 转换处理之后,得到的数据对象类型不同
- 分组操作调用的方法是keyBy方法,可以传入一个匿名函数作为键选择器(KeySelector),指定当前分组的key是什么。
- 代码末尾需要调用env的execute方法,开始执行任务。
2、读取Socket文本流(无界流)
在实际的生产环境中,真正的数据流其实是无界的,有开始却没有结束,这就要求我们需要持续的处理捕获的数据。为了模拟这种场景,可以监听Socket端口,然后向该端口不断地发生数据。
(1)将StreamWordCount代码中读取文件数据的readTextFile方法,替换成读取Socket文本流的方法socketTextStream。具体代码实现如下:
package com.zhm.wordcount;import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.connector.file.src.FileSource;
import org.apache.flink.connector.file.src.reader.TextLineInputFormat;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;/*** @ClassName Demo03_UnBoundedStreamProcess* @Description 无界流* @Author Zouhuiming* @Date 2023/9/3 10:39* @Version 1.0*/
public class Demo03_UnBoundedStreamProcess {public static void main(String[] args) throws Exception {//1、创建支持Flink计算的环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();//1.1 设置一个线程处理这个流env.setParallelism(1);//2、获取数据源DataStreamSource<String> streamSource = env.socketTextStream("hadoop102", 9999);//3.1 将每行数据按照给定的分割符拆分为Tuple2类型的数据模型(word,1)streamSource.flatMap(new FlatMapFunction<String, Tuple2<String,Integer>>() {@Overridepublic void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception {String[] split = s.split(" ");for (String s1 : split) {collector.collect(new Tuple2<>(s1,1));}}//3.2 根据word分组}).keyBy(new KeySelector<Tuple2<String, Integer>, String>() {@Overridepublic String getKey(Tuple2<String, Integer> stringIntegerTuple2) throws Exception {return stringIntegerTuple2.f0;}//3.3 根据分组之后,按照元组中的第二列聚相加}).sum(1)// 3.4 打印结果.print();//4、提交jobenv.execute();}
}
(2)在Linux环境的主机hadoop102上,执行下列命令,发送数据进行测试(前提是要安装netcat)
nc -lk hadoop102 9999
(3)启动Demo03_UnBoundedStreamProcess程序
我们会发现程序启动之后没有任何输出、也不会退出。这是正常的,因为Flink的流处理是事件驱动的,当前程序会一直处于监听状态,只有接受数据才会执行任务、输出统计结果。
(4)从hadoop102发送数据

(5)观察idea控制台
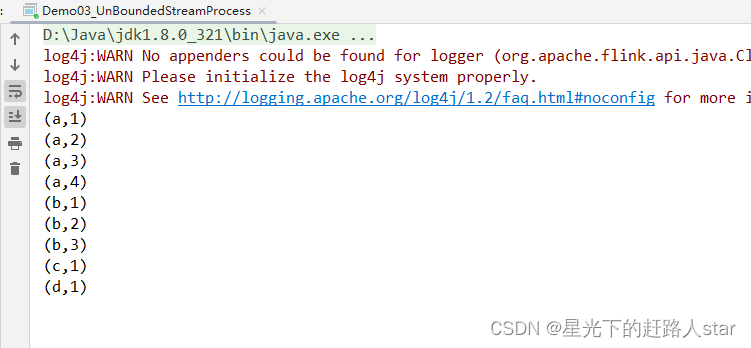
说明:Flink还具有一个类型提前系统,可以分析函数的输入和返回类型,自动获取类型信息,从而获得对应的序列化器和反序列化器。但是,由于java中泛型擦除的存在,在某些特殊情况下(比如Lambda表达式中),自动提取的信息是不够精细的–只告诉Flink当前的元素由“船头、船身、船尾”构成,根本无法重建出“大船”的模样;这时就需要显示地提供类型信息,才能使得应用程序正常工作或提高其性能。
因为对于flatMap里传入的Lambda表达式,系统只能推断出返回的是Tuple2类型,而无法得到Tuple<String,Long>。只有显示地告诉系统当前的返回类型,才能正确的解析出完整数据。
2.2.3 执行模式
从Flink 1.12开始,官方推荐的做法是直接使用DataStream API,在提交任务时通过将执行模式设为BATCH来进行批处理。不建议使用DataSet API。
// 流处理环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamAPI执行模式包括:流执行模式、批执行模式和自动模式。
- 流执行模式(Streaming)
这是DataStreamAPI最经典的模式,一边用于需要持续实时处理的无界数据流。默认情况下,程序使用的就是Streaming执行模式。 - 批执行模式(Batch)
专门用于批处理的执行模式 - 自动模式
在这种模式下,将由程序根据输入数据源是否有界来自动选择执行模式。
批执行模式的使用:主要有两种方式:
(1)通过命令行配置
bin/flink run -Dexecution.runtime-mode=BATCH ...
在提交作业时,增加execution.runtime-mode参数,指定值为BATCH。
(2)通过代码设置
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.BATCH);
在代码中,直接基于执行环境调用setRuntimeMode方法,传入BATCH模式。
实际应用中一般不会在代码中配置,而是使用命令行,这样更加灵活。
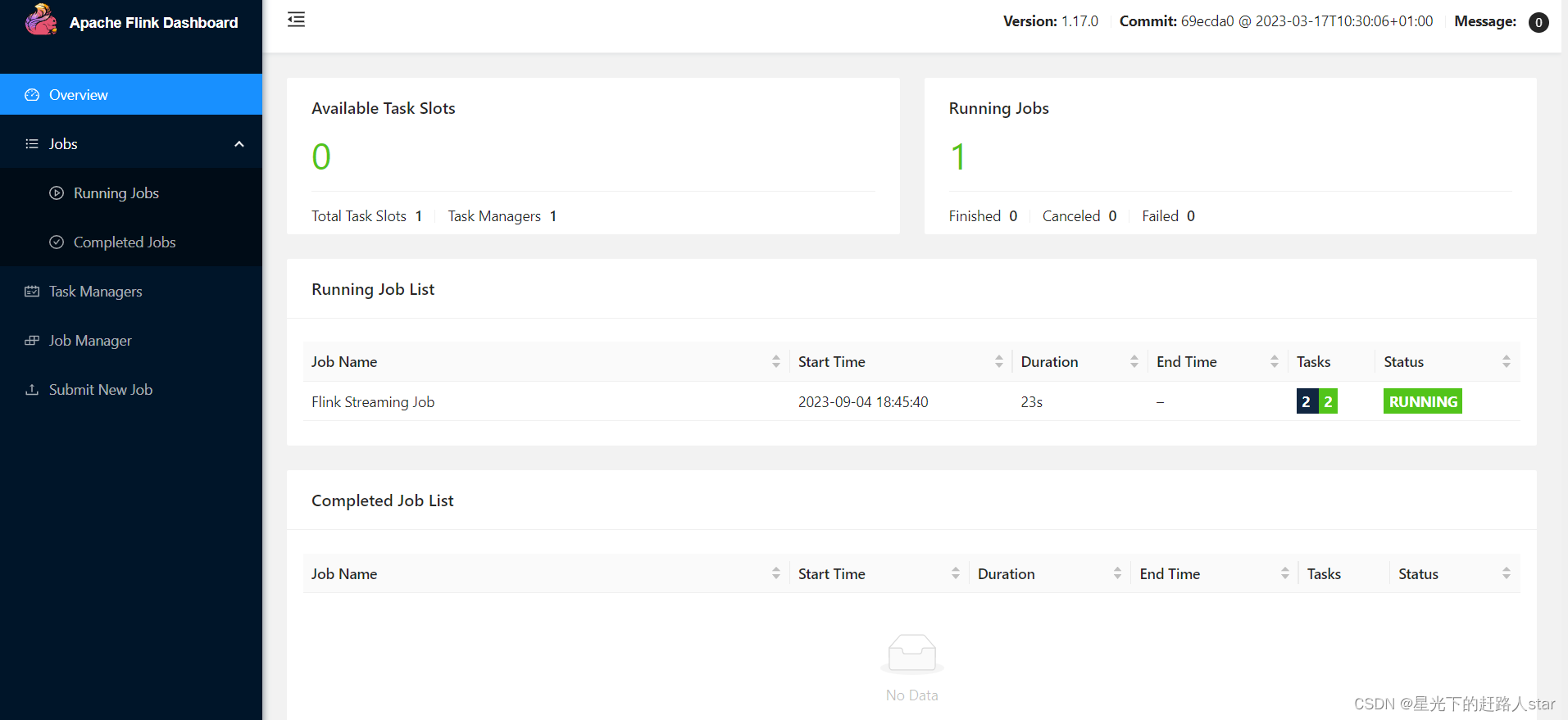
2.2.4 本地WebUI
在Idea本地运行程序时,可以通过添加本地WebUI依赖,使用WebUI界面查看Job的运行情况。
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-runtime-web</artifactId><version>${flink.version}</version><scope>provided</scope></dependency>
添加后,在代码中可以指定绑定的端口:
Configuration conf = new Configuration();conf.setInteger("rest.port", 3333);StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);
之后,在程序启动后,打开本地浏览器,访问localhost:3333即可查看job的运行情况。
相关文章:
Flink---1、概述、快速上手
1、Flink概述 1.1 Flink是什么 Flink的官网主页地址:https://flink.apache.org/ Flink的核心目标是“数据流上有状态的计算”(Stateful Computations over Data Streams)。 具体说明:Apache Flink是一个“框架和分布式处理引擎”,用于对无界…...
QT实现TCP通信(服务器与客户端搭建)
一、TCP通信框架 二、QT中的服务器操作 创建一个QTcpServer类对象,该类对象就是一个服务器调用listen函数将该对象设置为被动监听状态,监听时,可以监听指定的ip地址,也可以监听所有主机地址,可以通过指定端口号&#x…...

云备份项目
云备份项目 1. 云备份认识 自动将本地计算机上指定文件夹中需要备份的文件上传备份到服务器中。并且能够随时通过浏览器进行查看并且下载,其中下载过程支持断点续传功能,而服务器也会对上传文件进行热点管理,将非热点文件进行压缩存储&…...

基础算法(一)
目录 一.排序 快速排序: 归并排序: 二.二分法 整数二分模板: 浮点二分: 一.排序 快速排序: 从数列中挑出一个元素,称为 "基准"重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面&#…...
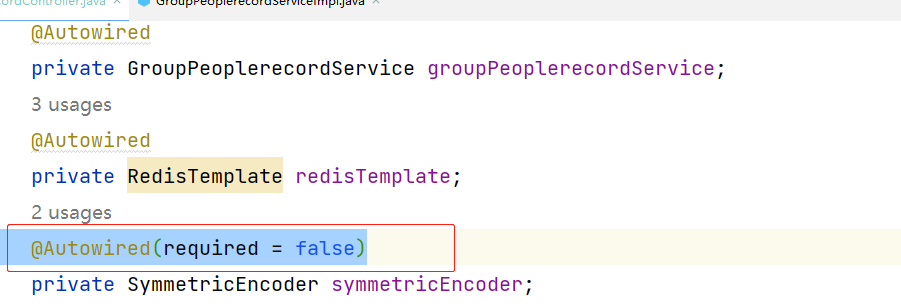
Consider defining a bean of type问题解决
Consider defining a bean of type问题解决 Consider defining a bean of type问题解决 包之后,发现项目直接报错Consider defining a bean of type。 会有一些包你明明Autowired 但是还是找不到什么bean 导致你项目启动不了 解决方法一: 这个问题主要是因为项目拆包…...

Android 1.2.1 使用Eclipse + ADT + SDK开发Android APP
1.2.1 使用Eclipse ADT SDK开发Android APP 1.前言 这里我们有两条路可以选,直接使用封装好的用于开发Android的ADT Bundle,或者自己进行配置 因为谷歌已经放弃了ADT的更新,官网上也取消的下载链接,这里提供谷歌放弃更新前最新…...
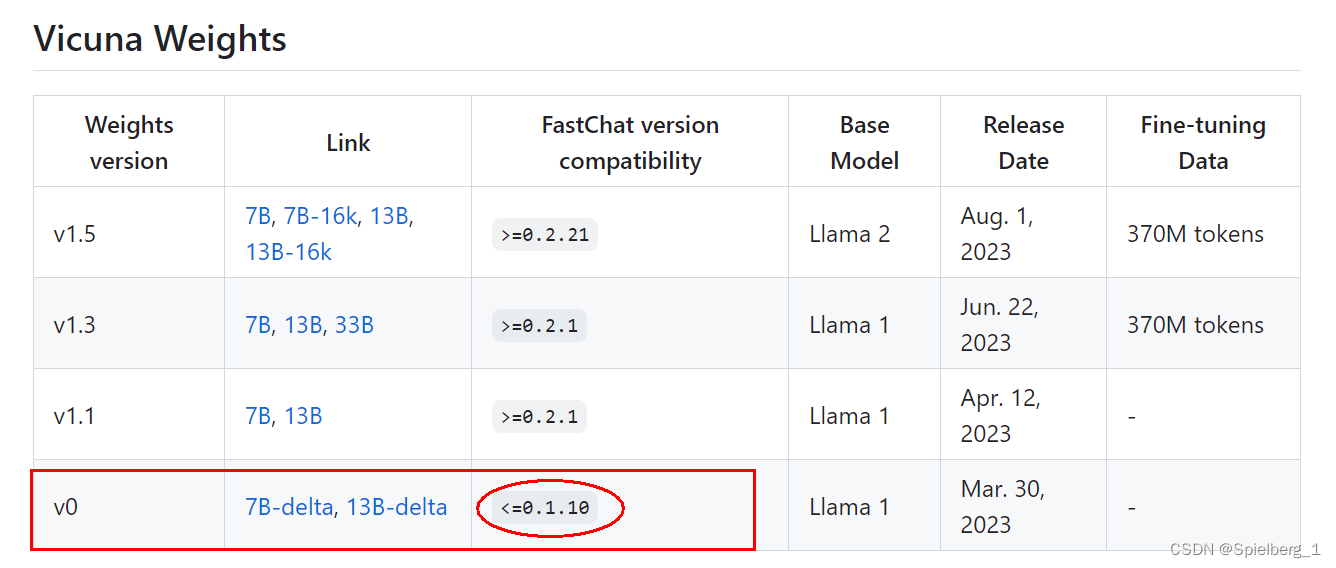
Llama-7b-hf和vicuna-7b-delta-v0合并成vicuna-7b-v0
最近使用pandagpt需要vicuna-7b-v0,重新过了一遍,前段时间部署了vicuna-7b-v3,还是有不少差别的,transforms和fastchat版本更新导致许多地方不匹配,出现很多错误,记录一下。 更多相关内容可见Fastchat实战…...

Centos、OpenEuler系统安装mysql
要在CentOS上安装MySQL并设置开机自启和root密码,请按照以下步骤进行操作: 确保您的CentOS系统已连接到Internet,并且具有管理员权限(root或sudo访问权限)。打开终端或SSH会话,使用以下命令安装MySQL&…...
如何在Win10系统上安装WSL(适用于 Linux 的 Windows 子系统)
诸神缄默不语-个人CSDN博文目录 本文介绍的方法不是唯一的安装方案,但在我的系统上可用。 文章目录 1. 视频版2. 文字版和代码3. 本文撰写过程中使用到的其他网络参考资料 1. 视频版 B站版:在Windows上安装Linux (WSL, 适用于 Linux 的 Windows 子系统…...
单片机通用学习-什么是寄存器?
什么是寄存器? 寄存器是一种特殊的存储器,主要用于存储和检查微机的状态。CPU寄存器用于存储和检查CPU的状态,具体包括计算中途数据、程序因中断或子程序分支时的返回地址、计算结果为零时的负值、计算结果为零时的信息、进位值等。 由于CP…...

【C语言】文件操作详解
文章目录 前言一、文件是什么二、文件具体介绍1.文件名2.文件类型3.文件缓冲区4.文件指针5.文件的打开和关闭 三、文件的顺序读写1.字符输入函数(fgetc)2.字符输出函数(fputc)3.文本行输入函数(fgets)4.文本…...

栈(Stack)的详解
目录 1.栈的概念 2.栈的模拟实现 1.栈的方法 2.模拟栈用(整型)数组的形式呈现 2.1栈的创建 2.2压栈 2.3栈是否为空 2.4出栈 2.5获取栈中有效元素个数 2.6获取栈顶元素 2.7完整代码实现 1.栈的概念 从上图中可以看到, Stack 继承了…...

深入了解GCC编译过程
关于Linux的编译过程,其实只需要使用gcc这个功能,gcc并非一个编译器,是一个驱动程序。其编译过程也很熟悉:预处理–编译–汇编–链接。在接触底层开发甚至操作系统开发时,我们都需要了解这么一个知识点,如何…...

leetcode 594.最长和谐子序列(滑动窗口)
⭐️ 题目描述 🌟 leetcode链接:最长和谐子序列 思路: 第一步先将数组排序,在使用滑动窗口(同向双指针),定义 left right 下标,比如这一组数 {1,3,2,2,5,2,3,7} 排序后 {1,2,2,2,3,…...

深入剖析云计算与云服务器ECS:从基础到实践
云计算已经在不断改变着我们的计算方式和业务模式,而云服务器ECS(Elastic Compute Service)作为云计算的核心组件之一,为我们提供了灵活、可扩展的计算资源。在本篇长文中,我们将从基础开始,深入探讨云计算…...
苍穹外卖技术栈
重难点详解 1、定义全局异常 2、ThreadLocal ThreadLocal 并不是一个Thread,而是Thread的一个局部变量ThreadLocal 为每一个线程提供独立的存储空间,具有线程隔离的效果,只有在线程内才能取到值,线程外则不能访问 public void …...

重新开始 杂类:C++基础
目录 1.输入输出 2 . i 与 i 3.结构体 4.二进制 1.输入输出 #include<cstdio>//cin>>,cout #include<iostream>//printf,scanf (1) cin , cout输入输出流可直接用于数字,字符 (2)scanf(&quo…...

自用的markdown与latex特殊符号
\triangleq \approx \xlongequal[y\arctan x]{x\tan y} \sum_{\substack{j1 \\ j\neq i}} \iiint\limits_\Omega \overset{\circ}{\vec{r}} \varphi \checkmark \stackrel{\cdot\cdot\cdot}{x}≜ ≈ y arctan x x tan y ∑ j 1 j ≠ i ∭ Ω r ⃗ ∘ φ ✓ x ⋅ ⋅ ⋅…...
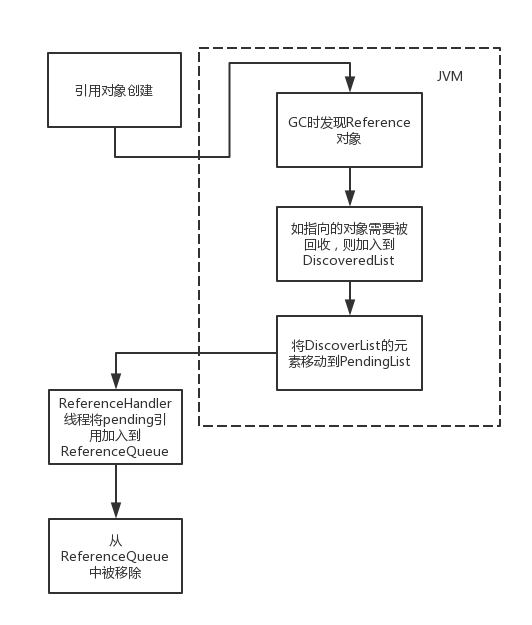
【20期】说一说Java引用类型原理
Java中一共有4种引用类型(其实还有一些其他的引用类型比如FinalReference):强引用、软引用、弱引用、虚引用。 其中强引用就是我们经常使用的Object a new Object(); 这样的形式,在Java中并没有对应的Reference类。 本篇文章主要是分析软引用、弱引用、…...

无锡布里渊——厘米级分布式光纤-锅炉安全监测解决方案
无锡布里渊——厘米级分布式光纤-锅炉安全监测解决方案 厘米级分布式光纤-锅炉安全监测解决方案 1、方案背景与产品简介: 1.1:背景简介: 锅炉作为一种把煤、石油或天燃气等化石燃料所储藏的化学能转换成水或水蒸气的热能的重要设备ÿ…...

DownKyi深度解析:重新定义B站视频内容管理的新范式
DownKyi深度解析:重新定义B站视频内容管理的新范式 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、去水印等ÿ…...

NoFences:免费开源桌面整理神器,让Windows桌面焕然一新
NoFences:免费开源桌面整理神器,让Windows桌面焕然一新 【免费下载链接】NoFences 🚧 Open Source Stardock Fences alternative 项目地址: https://gitcode.com/gh_mirrors/no/NoFences 还在为Windows桌面上杂乱无章的图标而烦恼吗&a…...

Agent 框架别急着乱学:先用 LangChain 搞懂 7 个基本模块
先说结论。 如果你想系统理解 Python Agent 框架,LangChain 仍然值得作为第一篇。它不是最轻的,也不是最“自动化”的,但它把 Agent 应用里的关键零件都摆出来了:模型、工具、状态、记忆、middleware、多 Agent 路由和 tracing。…...

从账单明细看Taotoken计费模式的透明与可追溯性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 从账单明细看Taotoken计费模式的透明与可追溯性 对于将大模型API集成到产品中的团队而言,成本控制与核算是一个核心的工…...

iOS自动化测试环境搭建:Xcode签名与WebDriverAgent配置全指南
1. 为什么iOS自动化测试环境比Android更让人头疼——从Xcode签名到WebDriverAgent的硬门槛AppiumPython实现iOS自动化测试~环境搭建,这短短十几个字背后,藏着绝大多数刚接触iOS自动化的新手在前三天反复重装系统、重启Mac、怀疑人生的真实写照。我带过六…...

UGUI三大Layout Group原理与避坑指南:Vertical、Horizontal、Grid布局本质解析
1. 为什么这三个Layout Group是UGUI里最常被误用、也最容易“看似正常实则埋雷”的组件?在Unity项目组做技术分享时,我常问新人一个问题:“你第一次用Vertical Layout Group,是不是拖进去一个空GameObject,加个组件&am…...

Tomcat Windows路径导致HTTP响应头信息泄露漏洞解析
1. 这个漏洞不是“能读文件”那么简单,而是Tomcat在特定配置下主动把敏感信息塞进HTTP响应头里CVE-2024-21733这个编号刚出来时,我第一反应是又一个常规的路径遍历或文件读取漏洞。但实际复现后才发现,它根本不是靠构造恶意URL去“偷”东西&a…...

油雾净化设备哪家技术更专业
在机械加工、五金锻造、热处理等工业生产场景中,机床切削、乳化液喷淋、高温加工会持续产生大量工业油雾。悬浮在车间内的油雾不仅会腐蚀生产设备、污染生产环境,还会刺激人体呼吸道,危害操作人员身体健康,同时超标排放还会违反环…...

你的仿真传感器数据准吗?Gazebo中激光雷达与深度相机的噪声模型配置与Rviz可视化调参实战
高保真机器人仿真:Gazebo传感器噪声模型与Rviz可视化调参全指南 在机器人算法开发中,仿真环境的真实性直接决定了算法测试的有效性。许多SLAM和导航算法在仿真环境中表现优异,一旦部署到真实机器人上却出现各种问题,这往往源于仿真…...
稀疏记忆微调:在Transformer权重中编码任务专属结构化记忆
1. 这不是又一篇“加个正则就叫持续学习”的水文——我们来拆解这篇真正动了底层参数结构的稀疏记忆微调如果你最近刷过arxiv或者NeurIPS、ICLR的预印本列表,大概率见过标题里带“Continual Learning”“Sparse”“Memory”这几个词组合出现的论文。但说实话&#x…...