整理mongodb文档:分页
个人博客
整理mongodb文档:分页
个人博客,求关注,如果文章不够清晰,麻烦指出。
文章概叙
本文主要讲下在聚合以及crud的find方法中如何使用limit还有skip进行排序。
分页的情况很经常出现,这也是这篇博客诞生的理由。
数据准备
为了方便后续的测试,这次需要准备的数据有点多,大概是一百万条。
百万级的数量能反应出skip的性能问题(毕竟用到db,必须得注意性能问题)
db.test.insertMany(new Array(1000000).fill(1).map((value, index) => ({ number: index })))
首先介绍下两位主角,一个是limit,一个是skip。
如果你需要在MongoDB中读取指定数量的数据记录,可以使用MongoDB的Limit方法,limit()方法接受一个数字参数,该参数指定从MongoDB中读取的记录条数。
我们除了可以使用limit()方法来读取指定数量的数据外,还可以使用skip()方法来跳过指定数量的数据,skip方法同样接受一个数字参数作为跳过的记录条数。
当您链接skip()和limit()时,方法链接顺序不会影响结果。服务器始终在应用限制要返回的文件数量
简单来说,我们在mysql之类的关系型数据库中使用的pagesize、pageno这些参数现在不适合了。
mongodb的分页查询,是需要两个参数,一个是跳过多少条,一个是需要查询多少条,下面举一个简单的例子:
假设我们要查询第6页的10条数据,我们需要设置我们的skip为(6-1)*10=50,设置我们的limit为10,也就是说前50条的数据被我们跳过了。
有了初步的理解,再分别介绍下如何在聚合以及find方法中使用分页。
find方法中的分页
由于在find方法中,是没有limit以及skip参数的,所以我们会直接在代码中使用skip方法以及limit方法。
db.test.find().limit(1).skip(10)
按照上面的讲述,我们查询了第11条开始的共计1条数据。

至此,你已经学会了如何在find方法中使用分页了,但请不要忽略文档中的一句话。
The skip() method requires the server to scan from the beginning of
the input results set before beginning to return results. As the
offset increases, skip() will become slower.
大体的翻译是:随着查询数据的不断增多,skip查询越后面的数据,返回越慢。
为了验证,我们需要搬出来我们的explain方法来查看更多的详情。
我们可以根据代表在该查询条件下返回文档数的"nReturned"来验证上面的说法。
首先,我们查询第11条数据,并使用explain查看查询的详情。
db.test.find().limit(1).skip(10).explain("executionStats")

接着,再查询最后一条数据。
db.test.find().limit(1).skip(999999).explain("executionStats")

而且在查询第1000000条数据的时候,也可以感觉到明显的卡顿。
根据nReturned的不同,我们就明白了当skip的值越大的时候,我们查询出来的文档数也就越多,会导致 性能下降,会出现查询缓慢的情况。
聚合通道的分页
聚合通道的分页,由于直接提供了"$limt"以及"$skip",使得我们不需要在后面拼接skip方法以及limit方法,使用的方法如下:
db.test.aggregate([{ "$limit": 3 },{ "$skip": 1 }])
上述的代码中,我们单看代码的理解是:查询从第2条开始的3条数据,也就是number分别为1,2,3的三条数据。
那么让我们打印看看查询出来的结果。

很是出乎意料,只返回了两条数据,并且返回的number还是数据库中的第二条以及第三条,说明了skip以及limit是有执行顺序的,先执行了limit的,拿出了前三条数据,再跳过这三条数据的第1条,只留下最后的两条数据。
既然如此,我们使用aggregate对skip做操作的时候,就需要考虑到执行顺序问题了。
注意点
1.上述在聚合通道的实验中,可以看到我们的顺序影响了分页的效果,所以使用分页的时候,需要注意分页所放的位置。
2.在find方法中,skip的作用是直接先将数据整理完毕,然后再查询出来,可以预测当我们要查询的数据特别后的时候,会导致我们的查询变得很慢,这也是因为一条一条数据的查询过滤。所以使用skip的时候,需要注意数据量大了就会导致性能急剧下降的问题,我们就可以尽可能的缩小查询的范围,适当的使用索引。
相关文章:
整理mongodb文档:分页
个人博客 整理mongodb文档:分页 个人博客,求关注,如果文章不够清晰,麻烦指出。 文章概叙 本文主要讲下在聚合以及crud的find方法中如何使用limit还有skip进行排序。 分页的情况很经常出现,这也是这篇博客诞生的理由。 数据准备…...
社区团购新玩法,生鲜蔬菜配货发货小程序商城
在当前的电商市场中,生鲜市场具有巨大的潜力和发展空间。为了满足消费者的需求,许多生鲜店正在寻找创新的方法来提高销售和客户满意度。其中,制作一个个性且功能强大的生鲜小程序商城是一个非常有效的策略。以下是在乔拓云平台上制作生鲜小程…...

shell bash中设置命令set
1 Preface/Foreword set命令用于shell脚本在执行命令时候,遇到异常的处理机制。 2 Usage 2.1 set -e 当执行命令过程中遇到异常,那么就退出脚本,不会往下执行其它命令。 #!/bin/bash #set -eroot GIT_TAG${CI_BUILD_TAG-NOTAG} GIT_REV…...
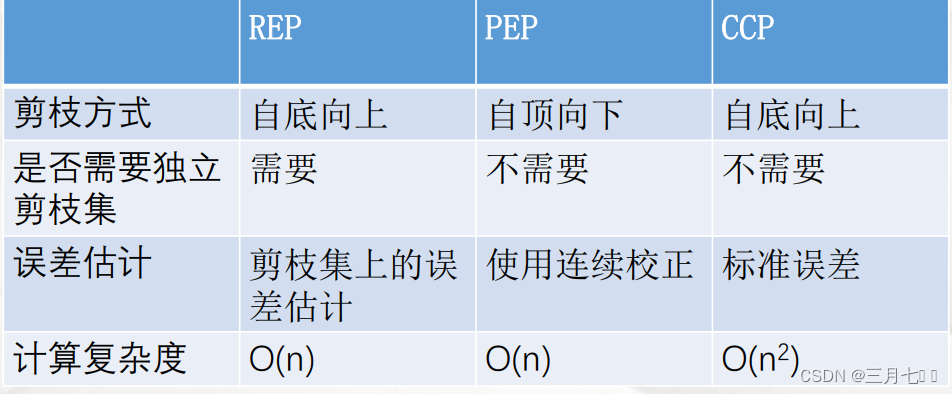
机器学习---预剪枝、后剪枝(REP、CCP、PEP、)
1. 为什么要进行剪枝 横轴表示在决策树创建过程中树的结点总数,纵轴表示决策树的预测精度。 实线显示的是决策树 在训练集上的精度,虚线显示的则是在⼀个独⽴的测试集上测量出来的精度。 随着树的增⻓,在 训练样集上的精度是单调上升的&…...

Python 爬虫—scrapy
scrapy用于从网站中提取所需数据的开源协作框架。以一种快速、简单但可扩展的方式。 该爬虫框架适合于那种静态页面, js 加载的话,如果你无法模拟它的 API 请求,可能就需要使用 selenium 这种使用无头浏览器的方式来完成你的需求了 入门 imp…...
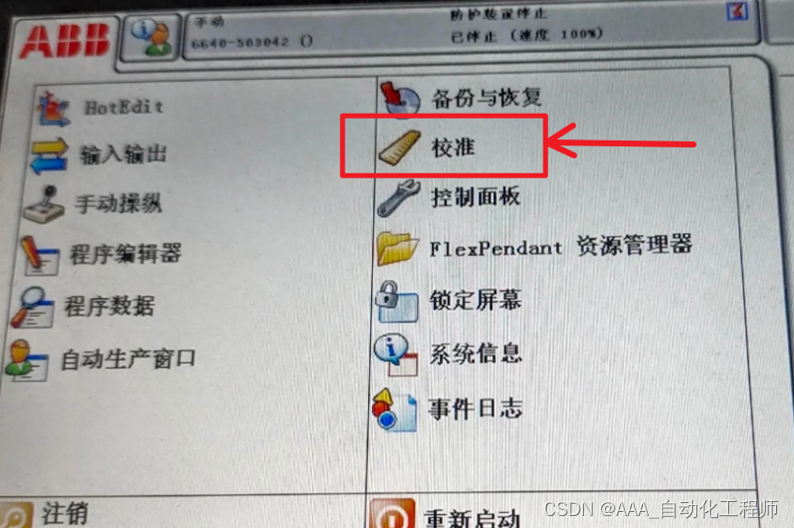
ABB机器人20032转数计数器未更新故障报警处理方法
ABB机器人20032转数计数器未更新故障报警处理方法 ABB的机器人上面安装有电池,需要定期进行更换(正常一年换一次),如果长时间不更换,电量过低,就会出现转数计数器未更新的报警,各轴编码器的位置就会丢失,在更换新电池后,需要更新转数计数器。 具体步骤如下: 先用手动…...

C# 记事本应用程序
using System; using System.Collections.Generic; using System.ComponentModel; using System.Data; using System.Drawing; using System...

模型训练:优化人工智能和机器学习,完善DevOps工具的使用
作者:JFrog大中华区总经理董任远 据说法餐的秘诀在于黄油、黄油、更多的黄油。同样,对于DevOps而言,成功的三大秘诀是自动化、自动化、更高程度的自动化,而这一切归根结底都在于构建能够更快速地不断发布新版软件的流程。 尽管人…...
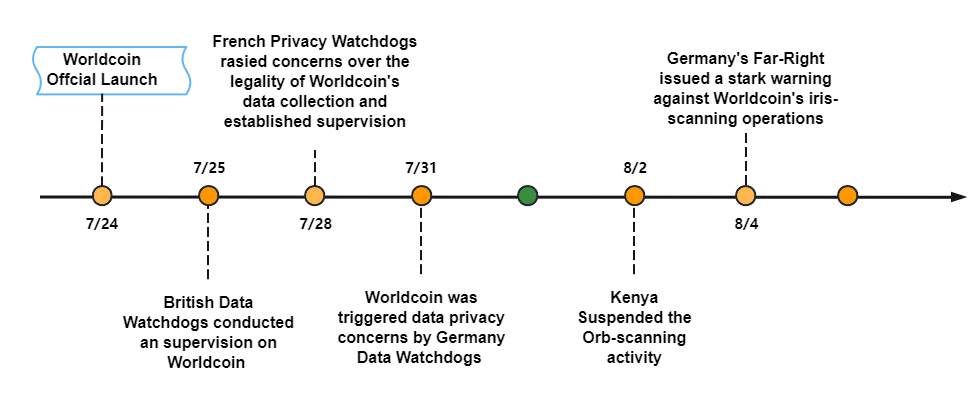
WorldCoin 运营数据,业务安全分析
WorldCoin 运营数据,业务安全分析 Worldcoin 的白皮书中声明,Worldcoin 旨在构建一个连接全球人类的新型数字经济系统,由 OpenAI 创始人 Sam Altman 于 2020 年发起。通过区块链技术在 Web3 世界中实现更加公平、开放和包容的经济体系&#…...

Java之Calender类的详细解析
Calendar类 3.1 概述 java.util.Calendar类表示一个“日历类”,可以进行日期运算。它是一个抽象类,不能创建对象,我们可以使用它的子类:java.util.GregorianCalendar类。 有两种方式可以获取GregorianCalendar对象: …...
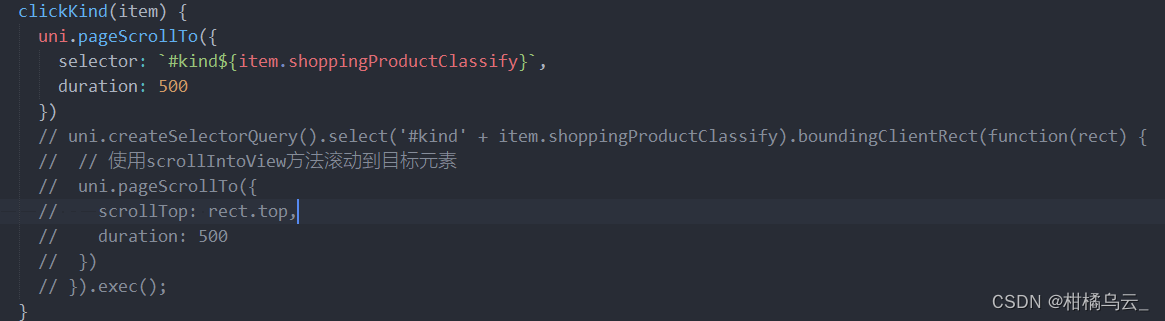
uniapp 微信小程序 锚点跳转
uniapp文档 以下是我遇到的业务场景,是点击商品分类的某一类 然后页面滚动至目标分类, 首先第一步是设置锚点跳转的目的地,在目标的dom上面添加id属性 然后给每个分类每一项添加点击事件,分类这里的item数据里面有一字段是和上…...

主成分分析笔记
主成分分析是指在尽量减少失真的前提下,将高维数据压缩成低微的方式。 减少失真是指最大化压缩后数据的方差。 记 P P P矩阵为 n m n\times m nm( n n n行 m m m列)的矩阵,表示一共有 m m m组数据,每组数据有 n n n…...
android studio 的 adb配置
首先在 Android Studio 中 打开 File -> Settings: 下载 “Google USB Driver” 这个插件 (真机调试的时候要用到), 并且记一下上面的SDK路径: 右键桌面上的 “我的电脑”, 点击 “高级系统设置”, 配置计算机的高级属性, 有两步: 添加一个新的环境变量 ANDROID_HOME, 变量…...

【HTML5高级第一篇】Web存储 - cookie、localStorage、sessionStorage
文章目录 一、数据存储1.1 cookie1.1.1 概念介绍1.1.2 存储与获取1.1.3 方法的封装1.1.4 总结 1.2 localstorage 与 sessionstorage1.2.1 概述1.2.2 操作数据的属性或方法1.2.3 案例-提交问卷1.2.4 Web Storage带来的好处 附录:1. HTML5提供的数据持久化技术&#x…...
Flink---1、概述、快速上手
1、Flink概述 1.1 Flink是什么 Flink的官网主页地址:https://flink.apache.org/ Flink的核心目标是“数据流上有状态的计算”(Stateful Computations over Data Streams)。 具体说明:Apache Flink是一个“框架和分布式处理引擎”,用于对无界…...
QT实现TCP通信(服务器与客户端搭建)
一、TCP通信框架 二、QT中的服务器操作 创建一个QTcpServer类对象,该类对象就是一个服务器调用listen函数将该对象设置为被动监听状态,监听时,可以监听指定的ip地址,也可以监听所有主机地址,可以通过指定端口号&#x…...

云备份项目
云备份项目 1. 云备份认识 自动将本地计算机上指定文件夹中需要备份的文件上传备份到服务器中。并且能够随时通过浏览器进行查看并且下载,其中下载过程支持断点续传功能,而服务器也会对上传文件进行热点管理,将非热点文件进行压缩存储&…...

基础算法(一)
目录 一.排序 快速排序: 归并排序: 二.二分法 整数二分模板: 浮点二分: 一.排序 快速排序: 从数列中挑出一个元素,称为 "基准"重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面&#…...
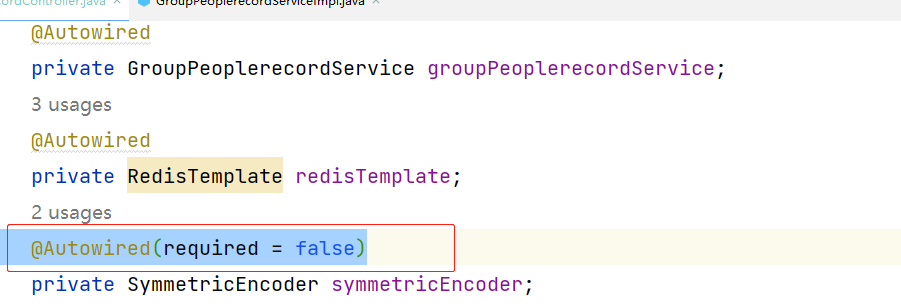
Consider defining a bean of type问题解决
Consider defining a bean of type问题解决 Consider defining a bean of type问题解决 包之后,发现项目直接报错Consider defining a bean of type。 会有一些包你明明Autowired 但是还是找不到什么bean 导致你项目启动不了 解决方法一: 这个问题主要是因为项目拆包…...

Android 1.2.1 使用Eclipse + ADT + SDK开发Android APP
1.2.1 使用Eclipse ADT SDK开发Android APP 1.前言 这里我们有两条路可以选,直接使用封装好的用于开发Android的ADT Bundle,或者自己进行配置 因为谷歌已经放弃了ADT的更新,官网上也取消的下载链接,这里提供谷歌放弃更新前最新…...

Navicat Premium试用期重置终极指南:三步恢复完整14天试用
Navicat Premium试用期重置终极指南:三步恢复完整14天试用 【免费下载链接】navicat-premium-reset-trial Reset macOS Navicat Premium 15/16/17 app remaining trial days 项目地址: https://gitcode.com/gh_mirrors/na/navicat-premium-reset-trial 你是否…...

为什么AI终于能进车间了?从聊天工具到生产力,这三件事正在发生
中石化车间里的AI 2026年5月,中石化发布了"烽火"工业智能体。 这个智能体不是用来聊天的,而是能直接操作工业软件、分析生产数据、跑仿真。它是石油化工行业第一个真正能进车间的数字专家。 在这之前,AI在工业场景里的应用,大多停留在"数据分析"层面…...

G3000,MG3660,MG3640S,TS3380,G3800,TS3480,TS3680,TS3460,TS3350,MG6380报错5B00,P07,E08,1700,5b04废墨垫清零,好用
下载:点这里下载 备用下载:https://pan.baidu.com/s/1WrPFvdV8sq-qI3_NgO2EvA?pwd0000 常见型号如下: G系列 G1000、G1100、G1200、G1400、G1500、G1800、G1900、G1010、G1110、G1120、G1410、G1420、G1411、G1510、G1520、G1810、G1820、…...

从账单明细看Taotoken计费模式的透明与可追溯性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 从账单明细看Taotoken计费模式的透明与可追溯性 对于将大模型API集成到产品中的团队而言,成本控制与核算是一个核心的工…...

书匠策AI到底有多懂毕业生?一个论文小白的“开挂“实录,看完你也想试!
嗨,各位正在为毕业论文头秃的宝子们!👋 我是你们的论文科普搭子,今天不讲枯燥的写作技巧,直接给大家安利一个我最近发现的"宝藏神器"——书匠策AI( 官网直达:www.shujiangce.com&…...

鸣潮自动化终极指南:5步实现后台智能挂机,解放你的游戏时间
鸣潮自动化终极指南:5步实现后台智能挂机,解放你的游戏时间 【免费下载链接】ok-wuthering-waves 鸣潮 后台自动战斗 自动刷声骸 一键日常 Automation for Wuthering Waves 项目地址: https://gitcode.com/GitHub_Trending/ok/ok-wuthering-waves …...

Voice-Pro 免费开源杀疯了:语音翻译、AI克隆、人声分离、YouTube下载全打包,狂省上千元
你是否也曾想过做视频,英文视频翻译成中文发到国内,或者把自己做的中文视频配上地道的英文,扬帆出海? 然而,现实往往会给你迎头痛击: 工具太碎片 :用 yt-dlp 下载了视频,要用 Demu…...

E-Hentai Downloader:三步解决漫画批量下载与打包难题的实用指南
E-Hentai Downloader:三步解决漫画批量下载与打包难题的实用指南 【免费下载链接】E-Hentai-Downloader Download E-Hentai archive as zip file 项目地址: https://gitcode.com/gh_mirrors/eh/E-Hentai-Downloader 还在为手动保存上百张漫画图片而烦恼吗&am…...

魔改frida-server实现反检测:从行为消除到可检测性归零
1. 为什么魔改frida-server比写检测绕过代码更根本?在Android逆向与安全测试一线干了十多年,我见过太多团队把精力耗在“检测逻辑对抗”上:写一堆Java层的isFridaPresent()、Native层的checkFridaPort()、甚至用ptrace自检父进程——结果呢&a…...

STM32 SysTick定时器深度配置:从原理到多场景实战应用
1. 项目概述:SysTick,一个被低估的“心脏起搏器”在STM32的世界里,SysTick定时器常常被开发者们视为一个“简单”的延时工具,或者仅仅是操作系统的心跳节拍器。但在我十多年的嵌入式开发生涯中,我越来越深刻地体会到&a…...