Hadoop依赖环境配置与安装部署
目录
- 什么是Hadoop?
- 一、Hadoop依赖环境配置
- 1.1 设置静态IP地址
- 1.2 重启网络
- 1.3 再克隆两台服务器
- 1.4 修改主机名
- 1.5 安装JDK
- 1.6 配置环境变量
- 1.7 关闭防火墙
- 1.8 服务器之间互传资料
- 1.9 做一个host印射
- 1.10 免密传输
- 二、Hadoop安装部署
- 2.1 解压hadoop的tar包
- 2.2 切换到配置文件目录
- 2.3 修改配置文件
- 2.4 分发到其他节点
- 2.5 初始化Hadoop集群
- 2.6 强制使用root启动hadoop集群
- 2.7 启动集群
- 2.8 输入命令jps,完成Hadoop的搭建
什么是Hadoop?
Hadoop是一个分布式系统基础架构, 是一个存储系统+计算框架的软件框架。主要解决海量数据存储与计算的问题,是大数据技术中的基石。Hadoop以一种可靠、高效、可伸缩的方式进行数据处理,用户可以在不了解分布式底层细节的情况下,开发分布式程序,用户可以轻松地在Hadoop上开发和运行处理海量数据的应用程序。
一、Hadoop依赖环境配置
1.1 设置静态IP地址
之所以设置静态IP是因为当我们连上不同的网络时,ip总是会发生变化,因为dhcp服务会为我们分配一个空闲的ip地址,所以静态ip解决的问题就是为了把ip地址固定下来。
- 首先查看网关,打开VMware,编辑>>虚拟网络编辑器。
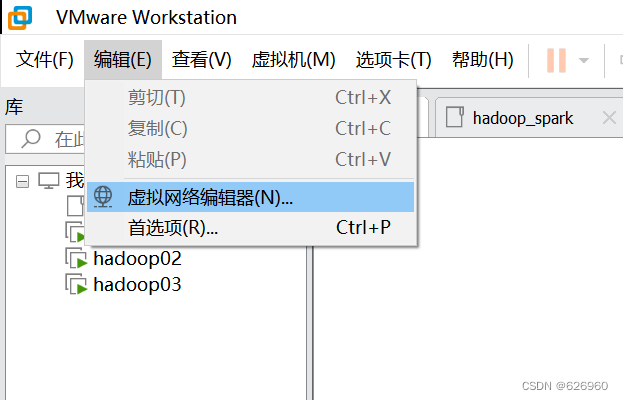
- 打开NAT设置。
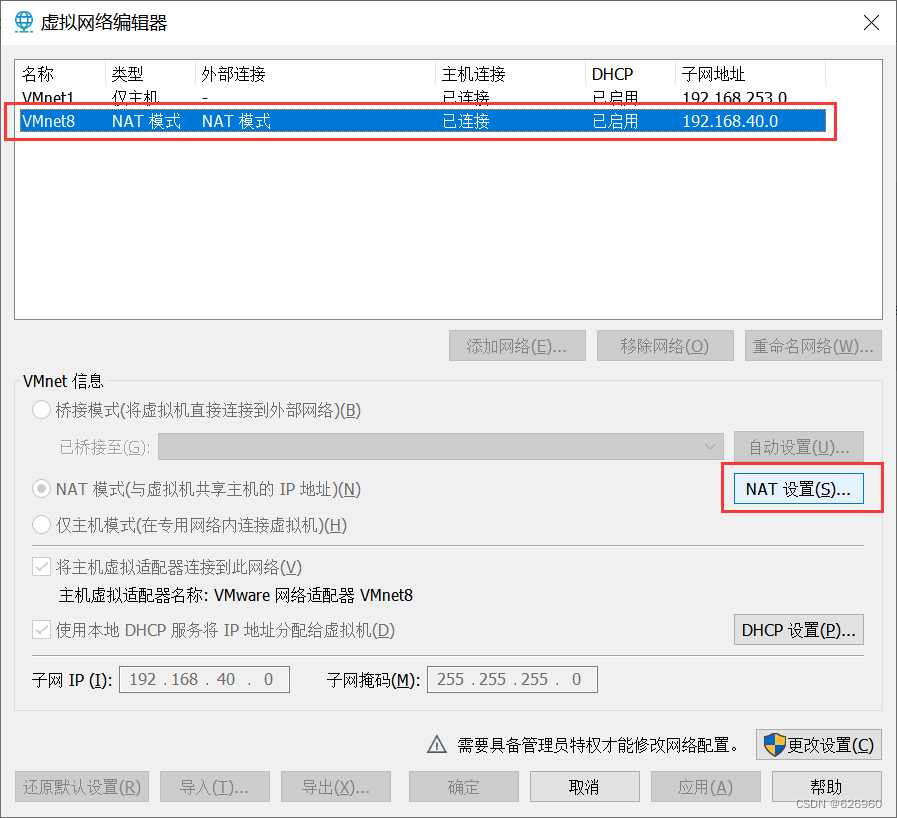
- 截图保存该页面,方便后面设置。
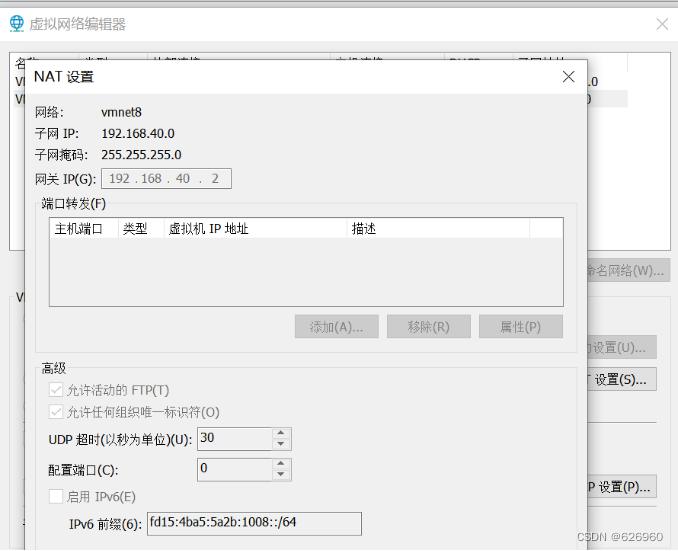
- 修改IP的配置文件
cd /etc/sysconfig/network-scripts/ //进入到如下目录
vim ifcfg-ens33 //编辑该文件
进入以后修改为如下内容:
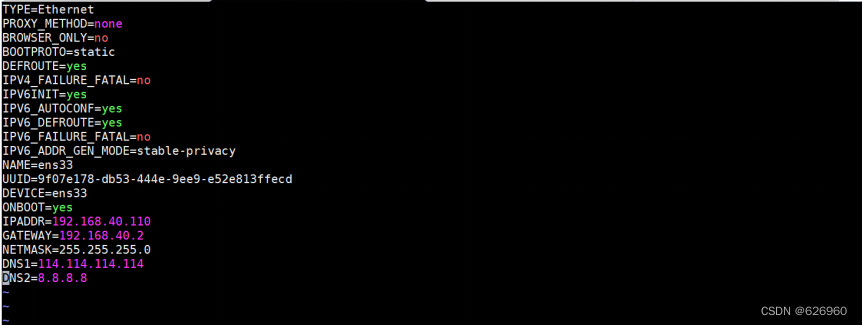
修改内容如下:
BOOTPROTO=static
ONBOOT=yes
IPADDR=192.168.xx.110 //xx查看自己之前的截图内容
GATEWAY=192.168.xx.2
NETMASK=255.255.255.0
DNS1=114.114.114.114
DNS2=8.8.8.8
1.2 重启网络
重启网络的命令:service network restart
1.3 再克隆两台服务器
-
步骤如下图
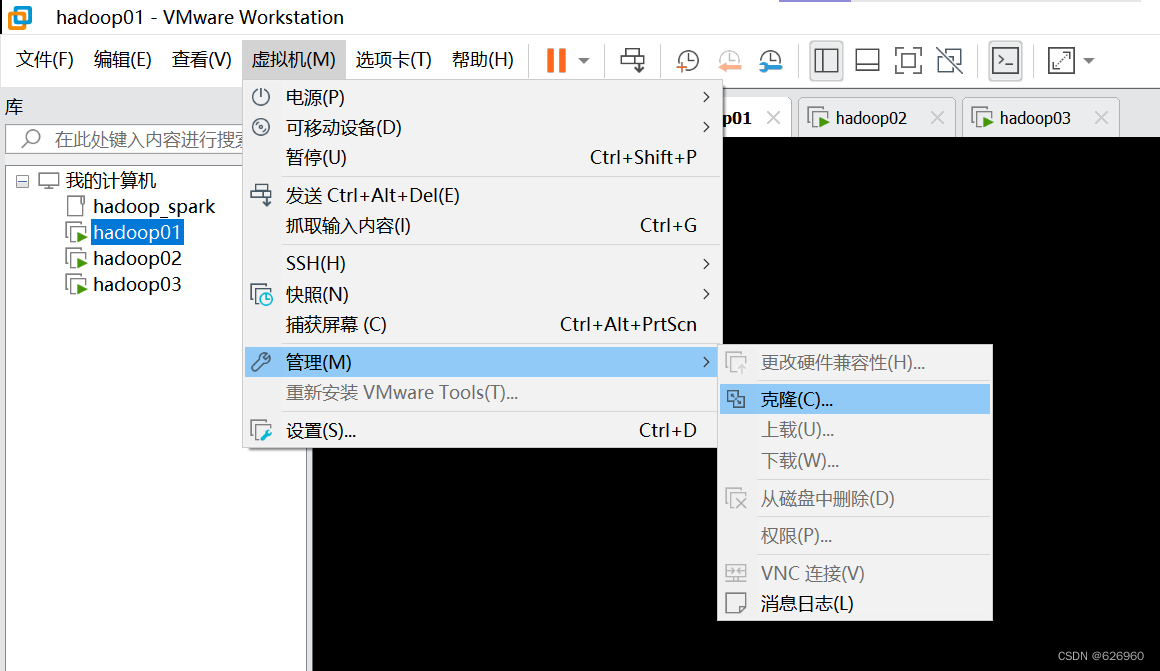
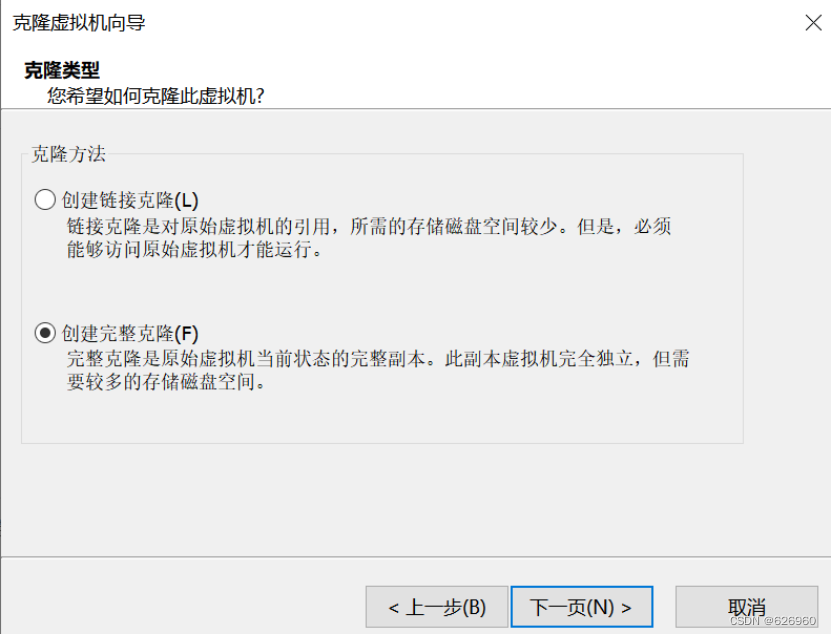
-
再克隆一台
1.4 修改主机名
克隆完虚拟机后,在MobaXterm中分布修改三台虚拟机的名称。分别输入如下命令:
hostnamectl set-hostname 'hadoop01'
hostnamectl set-hostname 'hadoop02'
hostnamectl set-hostname 'hadoop03'
1.5 安装JDK
输入命令:rpm tar.gz rpm -ivh XXX.rpm
1.6 配置环境变量
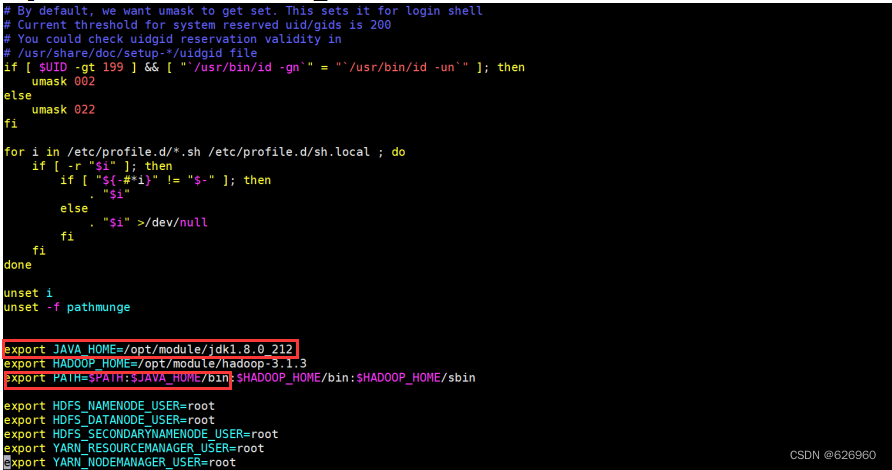
输入命令:vim /etc/profile,进入以后添加如下内容:
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
1.7 关闭防火墙
首先临时关闭防火墙,输入命令:systemctl stop firewalld
然后永久关闭防火墙( 只能先临时关闭,才能永久关闭),输入命令:systemctl disable firewalld

可以查看防火墙是否关闭:systemctl status firewalld
1.8 服务器之间互传资料
scp -r /opt/module/xxx 192.168.70.120:/opt/module
scp -r /opt/module/xxx hadoop03:/opt/module
1.9 做一个host印射
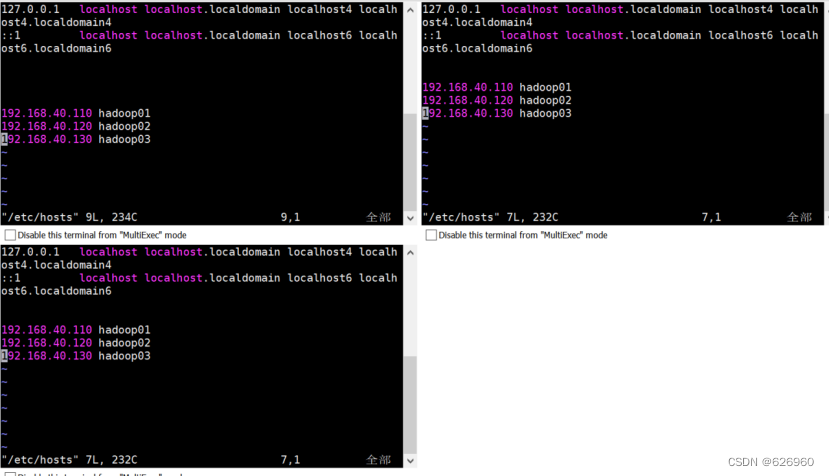
输入命令进入hosts映射文件:vim /etc/hosts
修改内容如下(三台虚拟机一样):
1.10 免密传输
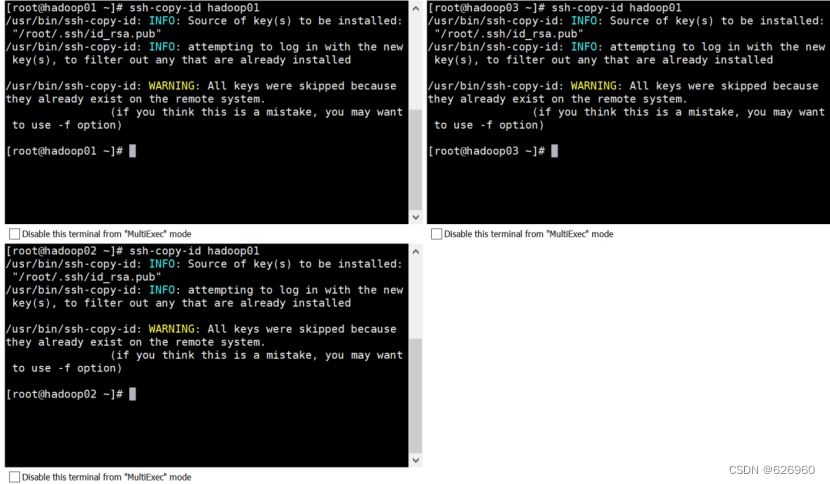
生成各自的私钥与公钥:ssh-keygen
把生成的公钥给别人:ssh-copy-id hadoop01ssh-copy-id hadoop02ssh-copy-id hadoop03
三台虚拟机同时输入:
二、Hadoop安装部署
2.1 解压hadoop的tar包
输入如下命令:tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/
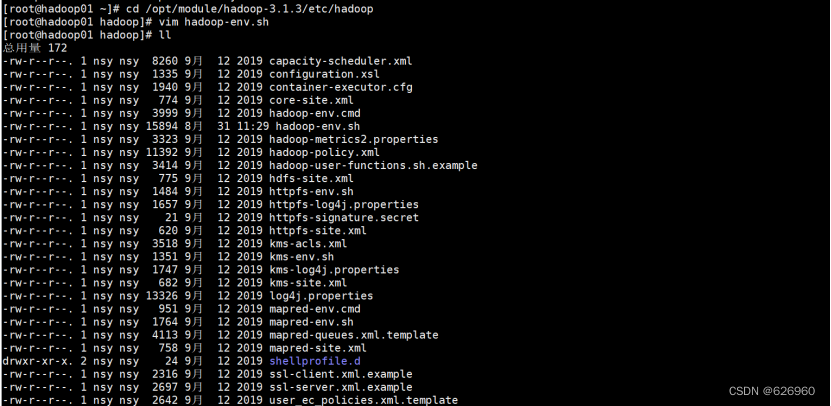
2.2 切换到配置文件目录
输入如下命令:cd /opt/module/hadoop-3.1.3/etc/hadoop
2.3 修改配置文件
-
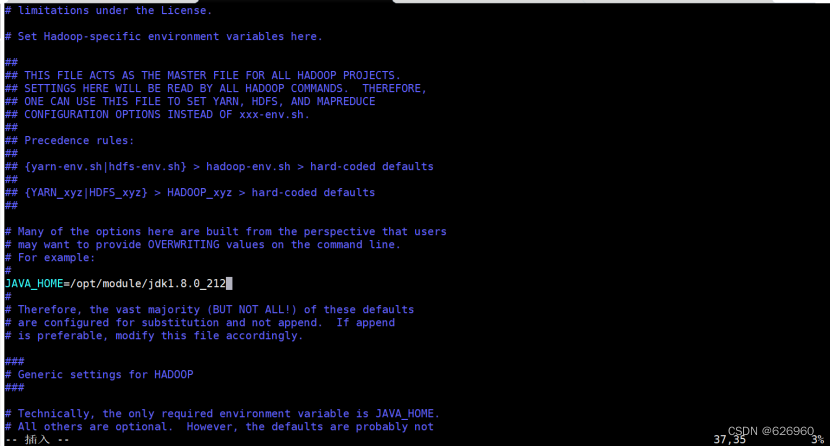
第一个配置文件,修改hadoop-env.sh,修改hadoop的环境依赖JDK:
vim hadoop-env.sh,添加jdk的环境变量。
修改内容如下:
-
第二个配置文件,输入命令:
vim core-site.xml,在<configuration></configuration>中添加如下内容:
<!-- 指定NameNode的地址 --><property><name>fs.defaultFS</name><value>hdfs://hadoop01:9000</value>
</property>
<!-- 指定hadoop数据的存储目录 --><property><name>hadoop.tmp.dir</name><value>/opt/module/hadoop-3.1.3/data</value>
</property><!-- 配置HDFS网页登录使用的静态用户为root --><property><name>hadoop.http.staticuser.user</name><value>root</value>
</property><!-- 配置该root(superUser)允许通过代理访问的主机节点 --><property><name>hadoop.proxyuser.root.hosts</name><value>*</value>
</property>
<!-- 配置该root(superUser)允许通过代理用户所属组 --><property><name>hadoop.proxyuser.root.groups</name><value>*</value>
</property>
<!-- 配置该root(superUser)允许通过代理的用户--><property><name>hadoop.proxyuser.root.groups</name><value>*</value>
</property>
- 第三个配置文件,输入命令:
vim hdfs-site.xml,在<configuration></configuration>中添加如下内容:
<!-- nn web端访问地址--><property><name>dfs.namenode.http-address</name><value>hadoop01:50070</value></property><!-- 2nn web端访问地址--><property><name>dfs.namenode.secondary.http-address</name><value>hadoop01:50090</value>
</property>
<!--副本数的配置--><property><name>dfs.replication</name><value>2</value>
</property>
- 第四个配置文件,输入命令:
vim yarn-site.xml,在<configuration></configuration>中添加如下内容:
<!-- 指定MR走shuffle --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址--><property><name>yarn.resourcemanager.hostname</name><value>hadoop01</value>
</property>
<!-- 环境变量的继承 --><property><name>yarn.nodemanager.env-whitelist</name><value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<!-- yarn容器允许分配的最大最小内存 --><property><name>yarn.scheduler.minimum-allocation-mb</name><value>512</value></property><property><name>yarn.scheduler.maximum-allocation-mb</name><value>2048</value>
</property>
<!-- yarn容器允许管理的物理内存大小 --><property><name>yarn.nodemanager.resource.memory-mb</name><value>2048</value>
</property>
<!-- 关闭yarn对物理内存和虚拟内存的限制检查 --><property><name>yarn.nodemanager.pmem-check-enabled</name><value>false</value></property><property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value></property>
- 第五个配置文件,输入命令:
vim mapred-site.xml,在<configuration></configuration>中添加如下内容:
<!-- 指定MapReduce程序运行在Yarn上 --><property><name>mapreduce.framework.name</name><value>yarn</value></property>
- 第六个配置文件,输入命令:
vim workers,添加如下内容:

2.4 分发到其他节点
scp -r /opt/module/hadoop-3.1.3 hadoop02:/opt/module/
scp -r /opt/module/hadoop-3.1.3 hadoop03:/opt/module/
2.5 初始化Hadoop集群
hadoop namenode -format
2.6 强制使用root启动hadoop集群
vim /etc/profile
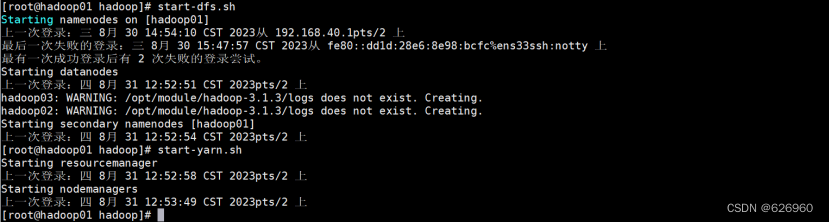
2.7 启动集群
start-dfs.sh
start-yarn.sh
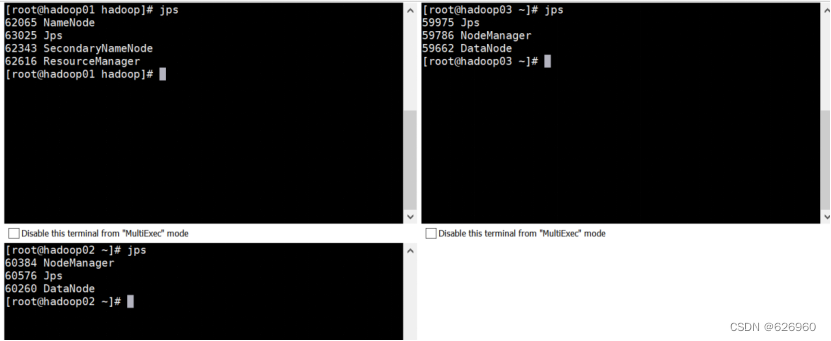
2.8 输入命令jps,完成Hadoop的搭建
相关文章:
Hadoop依赖环境配置与安装部署
目录 什么是Hadoop?一、Hadoop依赖环境配置1.1 设置静态IP地址1.2 重启网络1.3 再克隆两台服务器1.4 修改主机名1.5 安装JDK1.6 配置环境变量1.7 关闭防火墙1.8 服务器之间互传资料1.9 做一个host印射1.10 免密传输 二、Hadoop安装部署2.1 解压hadoop的tar包2.2 切换…...
[C++网络协议] I/O复用
具有代表性的并发服务器端实现模型和方法: 多进程服务器:通过创建多个进程提供服务。 多路复用服务器:通过捆绑并统一管理I/O对象提供服务。✔ 多线程服务器:通过生成与客户端等量的线程提供服务。 目录 1. I/O复用 2. select函…...
3D数据导出工具HOOPS Publish:3D数据查看、生成标准PDF或HTML文档!
HOOPS中文网http://techsoft3d.evget.com/ 一、3D导出SDK HOOPS Publish是一款功能强大的SDK,可以创作丰富的工程数据并将模型文件导出为各种行业标准格式,包括PDF、STEP、JT和3MF。HOOPS Publish核心的3D数据模型是经过ISO认证的PRC格式(ISO 14739-1:…...
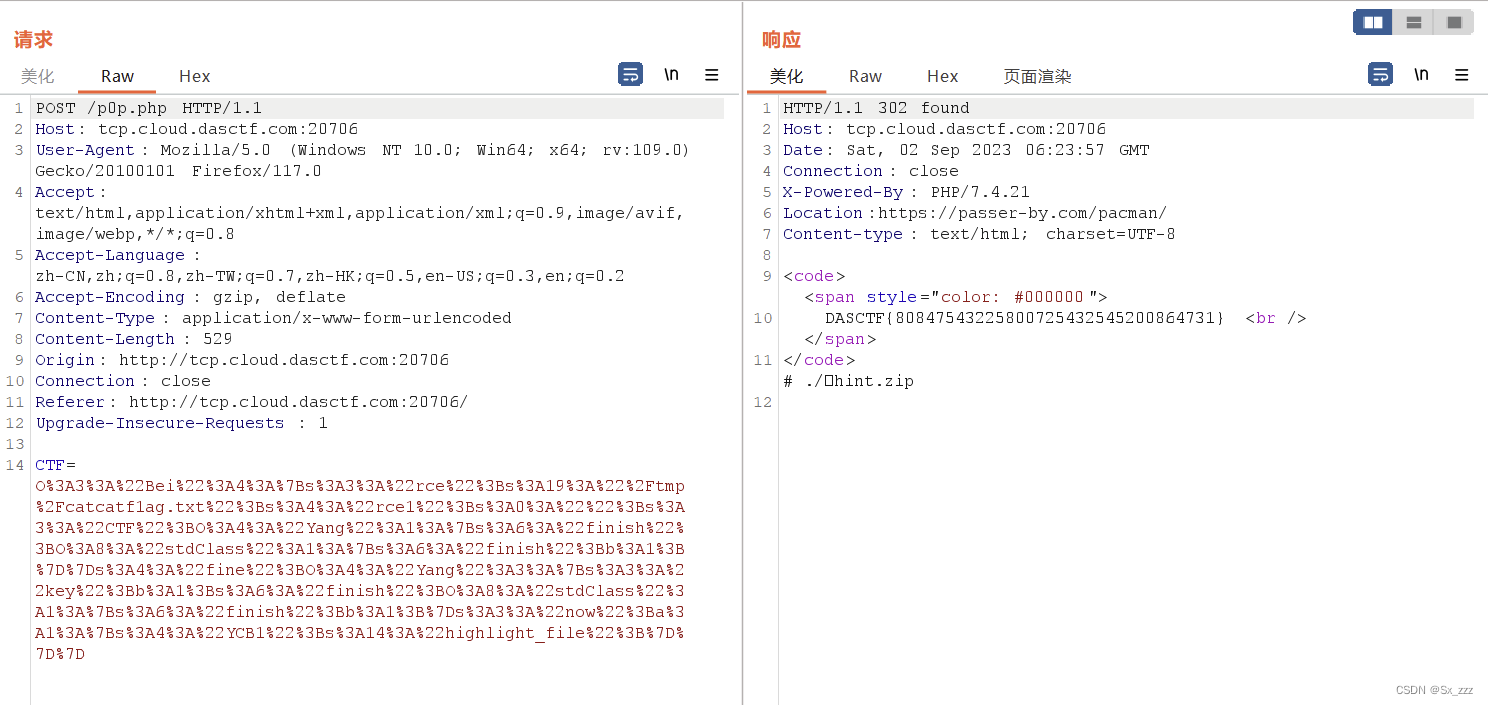
[羊城杯 2023] web
文章目录 D0nt pl4y g4m3!!! D0n’t pl4y g4m3!!! 打开题目,可以判断这里为php Development Server 启动的服务 查询得知,存在 PHP<7.4.21 Development Server源码泄露漏洞(参考文章) 抓包,构造payload 得到源码 class Pro{private $ex…...

Redisson—独立节点模式和集群管理工具
一、集群管理工具 Redisson集群管理工具提供了通过程序化的方式,像redis-trib.rb脚本一样方便地管理Redis集群的工具。 1、 创建集群 以下范例展示了如何创建三主三从的Redis集群。 ClusterNodes clusterNodes ClusterNodes.create() .master("127.0.0.1:…...
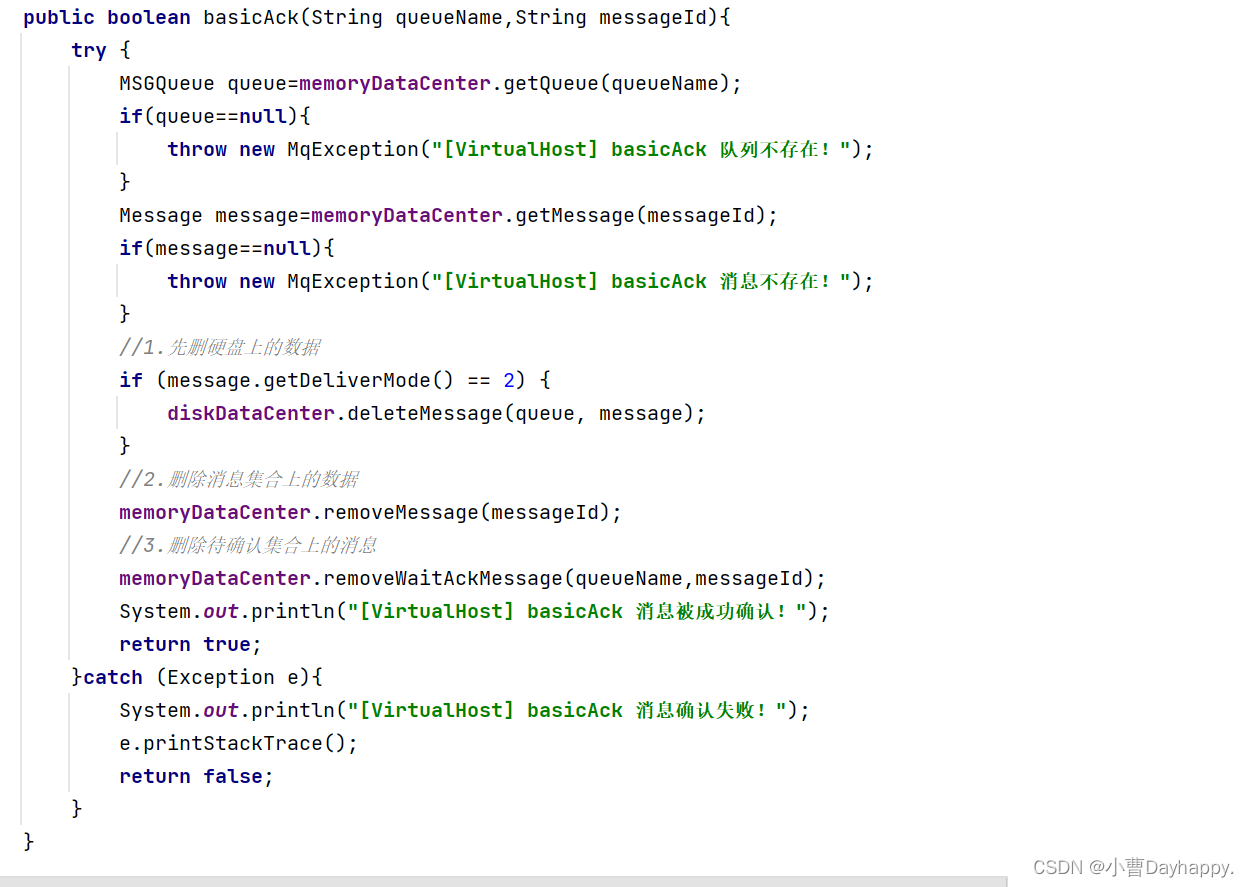
基于RabbitMQ的模拟消息队列之五——虚拟主机设计
文章目录 一、创建VirtualHost类二、初始化三、API1.创建交换机2.删除交换机3.创建队列4.删除队列5.创建绑定6.删除绑定7.发送消息转发规则 8.订阅消息1.消费者管理2.推送消息给消费者 3.添加一个消费者管理ConsumerManager9.确认消息 创建VirtualHost类。 1.串起内存和硬盘的数…...
Hadoop的概述与安装
Hadoop的概述与安装 一、Hadoop内部的三个核心组件1、HDFS:分布式文件存储系统2、YARN:分布式资源调度系统3、MapReduce:分布式离线计算框架4、Hadoop Common(了解即可) 二、Hadoop技术诞生的一个生态圈数据采集存储数…...
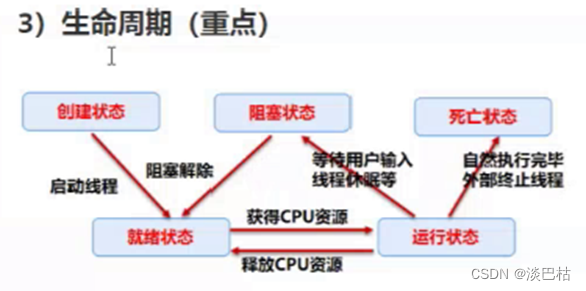
进程、线程与构造方法
进程、线程与构造方法 目录 一. 进程与线程1. 通俗解释2. 代码实现3. 线程生命周期(图解) 二. 构造方法 一. 进程与线程 1. 通俗解释 进程:就像电脑上运行的软件,例如QQ等。 线程:…...
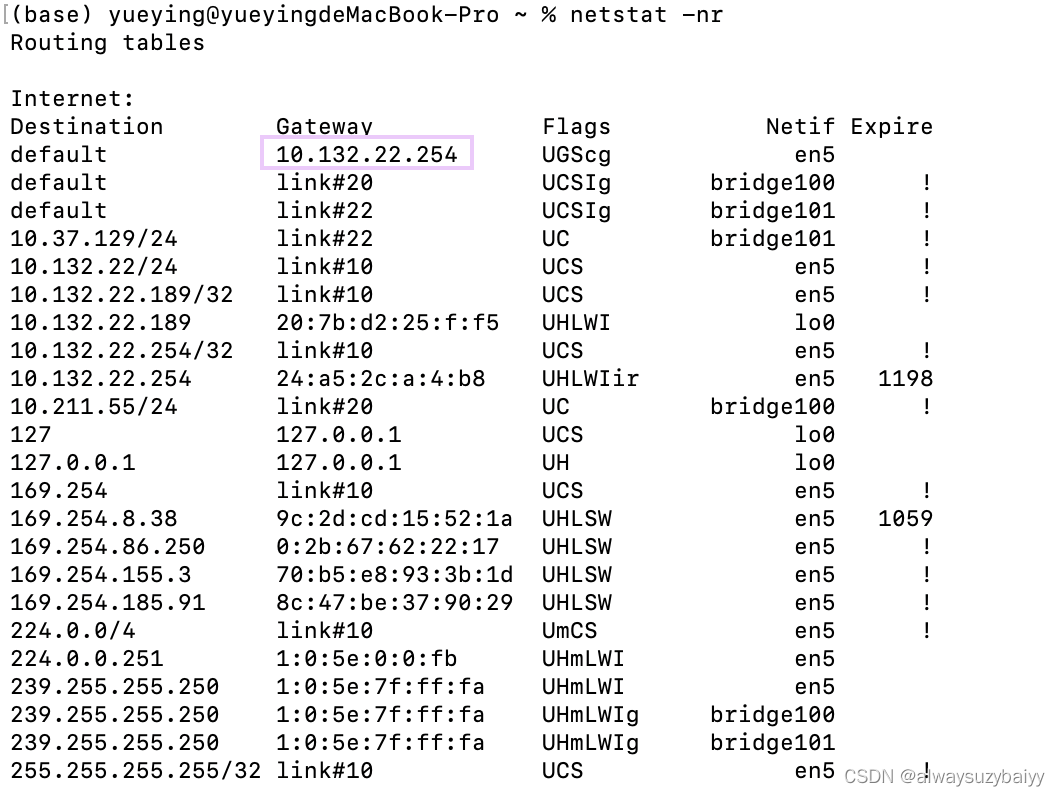
04 Linux补充|C/C++
目录 Linux补充 C语⾔ C语言中puts和printf的区别? Linux补充 (1)ubuntu安装ssh服务端openssh-server命令: ubuntu安装后默认只有ssh客户端,只能去连其它ssh服务器;其它客户端想要连接这个ubuntu系统,需要安装部署…...
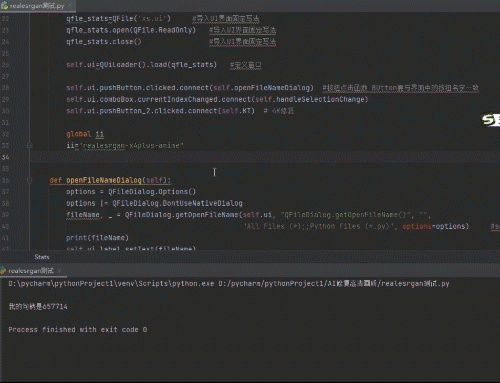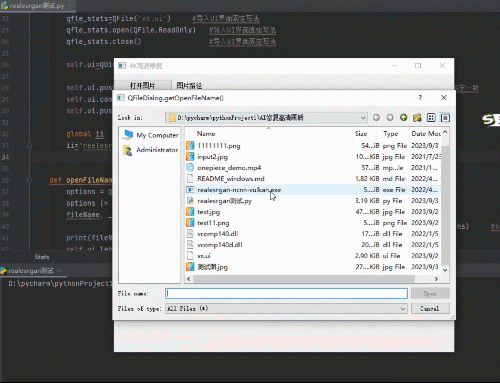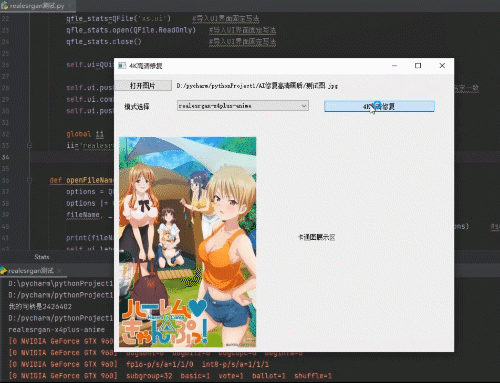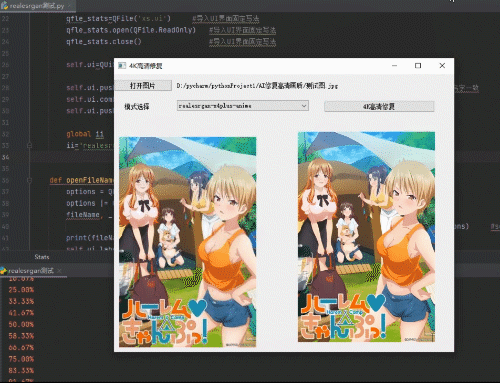
利用python制作AI图片优化工具
将模糊图片4K高清化效果如下: 优化前的图片 优化后如下图: 优化后图片变大变清晰了效果很明显 软件界面如下: 所用工具和代码: 1、所需软件包 网盘链接:https://pan.baidu.com/s/1CMvn4Y7edDTR4COfu4FviA提取码&…...

React v6(仅支持函数组件,不支持类组件)与v5版本路由使用详情和区别(详细版)
1.路由安装(默认安装最新版本6.15.0) npm i react-router-dom 2.路由模式 有常用两种路由模式可选:HashRouter 和 BrowserRouter。 ①HashRouter:URL中采用的是hash(#)部分去创建路由。 ②BrowserRouter:URL采用真实的URL资源,…...
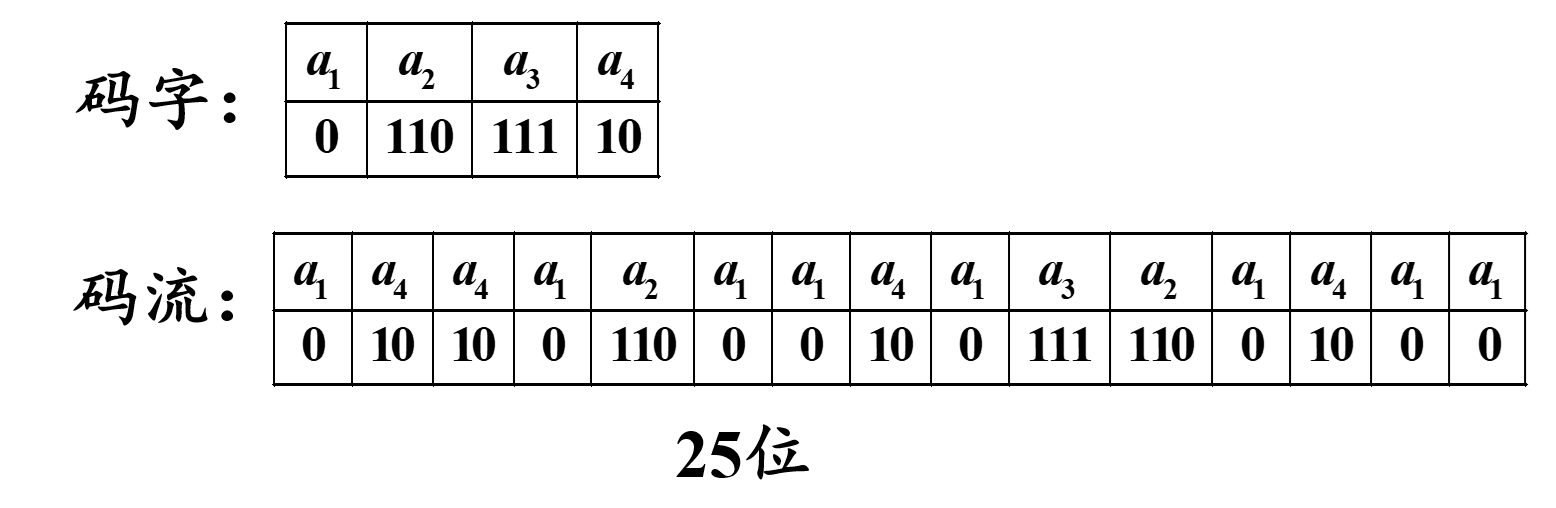
(数字图像处理MATLAB+Python)第十二章图像编码-第一、二节:图像编码基本理论和无损编码
文章目录 一:图像编码基本理论(1)图像压缩的必要性(2)图像压缩的可能性A:编码冗余B:像素间冗余C:心理视觉冗余 (3)图像压缩方法分类A:基于编码前后…...

【Unity编辑器扩展】| 顶部菜单栏扩展 MenuItem
前言【Unity编辑器扩展】 | 顶部菜单栏扩展 MenuItem一、创建多级菜单二、创建可使用快捷键的菜单项三、调节菜单显示顺序和可选择性四、创建可被勾选的菜单项五、右键菜单扩展5.1 Hierarchy 右键菜单5.2 Project 右键菜单5.3 Inspector 组件右键菜单六、AddComponentMenu 特性…...

golang读取键盘功能按键输入
golang读取键盘功能按键输入 需求 最近业务上需要做一个终端工具,能够直接连到docker容器中进行交互。 技术选型 docker官方提供了python sdk、go sdk和remote api。 https://docs.docker.com/engine/api/sdk/ 因为我们需要提供命令行工具,因此采用g…...

用sklearn实现线性回归和岭回归
此文为ai创作,今天写文章的时候发现创作助手限时免费,想测试一下,于是就有了这篇文章,看的出来,效果还可以,一行没改。 线性回归 在sklearn中,可以使用线性回归模型做多变量回归。下面是一个示…...

结构型模式-桥接模式
用于把抽象化与实现化解耦,使得二者可以独立变化。这种类型的设计模式属于结构型模式,它通过提供抽象化和实现化之间的桥接结构,来实现二者的解耦。 这种模式涉及到一个作为桥接的接口,使得实体类的功能独立于接口实现类…...

缓存的放置时间和删除时间
缓存的放置时间和删除时间是指缓存中存储的数据的生命周期。这两个时间点非常重要,因为它们决定了缓存数据的有效期和何时应该从缓存中删除。 缓存的放置时间(Cache Put Time):这是指数据首次放入缓存的时间点。当数据被放入缓存时…...
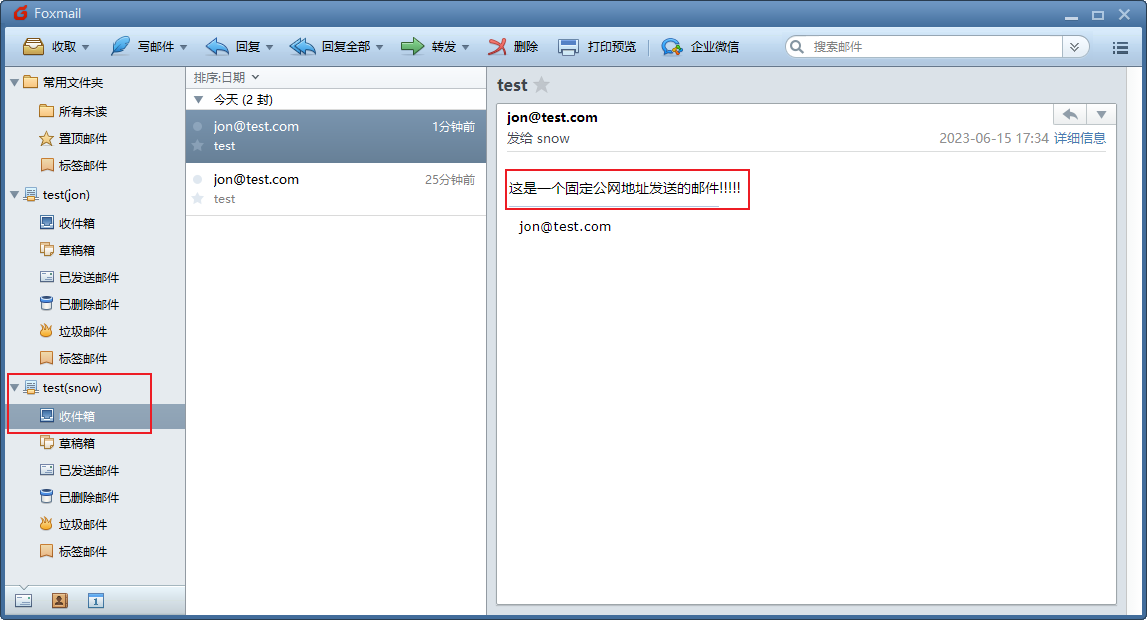
内网穿透实战应用-如何通过内网穿透实现远程发送个人本地搭建的hMailServer的邮件服务
文章目录 1. 安装hMailServer2. 设置hMailServer3. 客户端安装添加账号4. 测试发送邮件5. 安装cpolar6. 创建公网地址7. 测试远程发送邮件8. 固定连接公网地址9. 测试固定远程地址发送邮件 hMailServer 是一个邮件服务器,通过它我们可以搭建自己的邮件服务,通过cpolar内网映射工…...
)
ensp基础命令大全(华为设备命令)
路漫漫其修远兮,吾将上下而求索 今天写一些曾经学习过的网络笔记,希望对您的学习有所帮助。 OSPF,BGP,IS-IS的命令笔记没有写上来,计划单独写,敬请期待,或者您可以在这个网站查查 : 万能查询网站 …...

thinkphp6 入门(4)--数据库操作 增删改查
一、设计数据库表 比如我新建了一个数据库表,名为test 二、配置数据库连接信息 本地测试 直接在.env中修改,不用去config/database.php中修改 正式环境 三、增删改查 引入Db库 use think\facade\Db; 假设新增的控制器路径为 app\test\control…...

智慧校园软件怎么选?手把手教你看懂核心功能
✅作者简介:合肥自友科技 📌核心产品:智慧校园平台(包括教工管理、学工管理、教务管理、考务管理、后勤管理、德育管理、资产管理、公寓管理、实习管理、就业管理、离校管理、科研平台、档案管理、学生平台等26个子平台) 。公司所有人员均有多…...

RVC与So-VITS-SVC对比:轻量级vs高保真,选型决策指南
RVC与So-VITS-SVC对比:轻量级vs高保真,选型决策指南 想用AI给自己的声音换个风格,或者让喜欢的歌手“唱”一首新歌,却发现工具太多,不知道选哪个好?RVC和So-VITS-SVC是目前最火的两个开源语音转换模型&…...
》——从“像素认知”到“空间计算”,构建现实世界的智能操作体系)
《SpaceOS:空间操作系统白皮书(终极封神版)》——从“像素认知”到“空间计算”,构建现实世界的智能操作体系
🚀《SpaceOS:空间操作系统白皮书(终极封神版)》——从“像素认知”到“空间计算”,构建现实世界的智能操作体系(镜像视界(浙江)科技有限公司原创技术体系)🔴 …...

AI辅助开发:构思并实现智能交互式谷歌账号注册学习助手
AI辅助开发:构思并实现智能交互式谷歌账号注册学习助手 最近在做一个谷歌账号注册教程项目时,发现传统的图文教程存在几个痛点:用户容易迷失在步骤中、遇到错误时不知道如何解决、非英语用户理解困难。正好接触到InsCode(快马)平台的AI辅助开…...

DAMOYOLO-S模型Android端集成实战:移动端实时检测应用开发
DAMOYOLO-S模型Android端集成实战:移动端实时检测应用开发 如果你是一名Android开发者,想在自己的App里加入实时物体检测功能,比如识别摄像头里的猫猫狗狗、车辆行人,但又担心模型太大、速度太慢,那今天这个实战项目就…...

StructBERT在金融舆情监控系统中的实时分类方案
StructBERT在金融舆情监控系统中的实时分类方案 1. 引言 金融市场的波动往往源于信息的快速传播。一条突发的负面新闻可能在几分钟内引发股价大幅波动,而一个利好消息也可能在瞬间推动市场情绪高涨。传统的金融舆情监控系统往往面临响应延迟的挑战,等到…...

Vue-Touch实战案例:构建支持多点触控的图片查看器
Vue-Touch实战案例:构建支持多点触控的图片查看器 【免费下载链接】vue-touch Hammer.js wrapper for Vue.js 项目地址: https://gitcode.com/gh_mirrors/vu/vue-touch 想要为你的Vue.js应用添加流畅的多点触控交互体验吗?Vue-Touch插件正是你需要…...

猫抓扩展完整配置指南:从零开始掌握浏览器资源嗅探
猫抓扩展完整配置指南:从零开始掌握浏览器资源嗅探 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 还在为网页上的视频无法下载而烦恼吗…...

二进制逆向新选择:Binary Ninja核心功能与实战指南
二进制逆向新选择:Binary Ninja核心功能与实战指南 【免费下载链接】deprecated-binaryninja-python Deprecated Binary Ninja prototype written in Python 项目地址: https://gitcode.com/gh_mirrors/de/deprecated-binaryninja-python 一、定位解析&#…...

如何高效管理ExHentai漫画收藏:终极标签化管理解决方案
如何高效管理ExHentai漫画收藏:终极标签化管理解决方案 【免费下载链接】exhentai-manga-manager ExHentai本地漫画标签管理阅读应用, ExHentai local manga tag-manager and reader 项目地址: https://gitcode.com/gh_mirrors/ex/exhentai-manga-manager 你…...