初识c++
文章目录
- 前言
- 一、C++命名空间
- 1、命名空间
- 2、命名空间定义
- 二、第一个c++程序
- 1、c++的hello world
- 2、std命名空间的使用惯例
- 三、C++输入&输出
- 1、c++输入&输出
- 四、c++中缺省参数
- 1、缺省参数概念
- 2、缺省参数分类
- 3、缺省参数应用
- 五、c++中函数重载
- 1、函数重载概念
- 2、函数重载应用
- 六、c++中的引用
- 1、 引用概念
- 2、引用特性
- 3、常引用
- 4、指针和引用的区别
- 5、引用的应用 -- 做参数
- 6、引用的应用 -- 做返回值
前言
C语言是结构化和模块化的语言,适合处理较小规模的程序。对于复杂的问题,规模较大的程序,需要高度的抽象和建模时,C语言则不合适。为了解决软件危机, 20世纪80年代, 计算机界提出了OOP(object oriented programming:面向对象)思想,支持面向对象的程序设计语言应运而生。
1982年,Bjarne Stroustrup博士在C语言的基础上引入并扩充了面向对象的概念,发明了一种新的程序语言。为了表达该语言与C语言的渊源关系,命名为C++。因此:C++是基于C语言而产生的,它既可以进行C语言的过程化程序设计,又可以进行以抽象数据类型为特点的基于对象的程序设计,还可以进行面向对象的程序设计。
一、C++命名空间
1、命名空间
在C/C++中,变量、函数和后面要学到的类都是大量存在的,这些变量、函数和类的名称将都存在于全局作用域中,可能会导致很多冲突。使用命名空间的目的是对标识符的名称进行本地化,以避免命名冲突或名字污染,namespace关键字的出现就是针对这种问题的。
例如在如下代码中会报出rand重定义的错误,因为rand在stdlib库中为函数名。
#include<stdio.h>
#include<stdlib.h>int rand = 10;
int main()
{//因为stdlib库中定义了rand()函数,所以全局定义的rand会和库中的rand产生命名冲突//在c语言中没办法解决类似这样的命名冲突的问题,所以c++提出了namespace来解决printf("%d\n", rand);return 0;
}
c++的namespace就可以解决c语言中的命名冲突问题。
#include<stdio.h>
#include<stdlib.h>//命名空间域
namespace dong
{int rand = 0;
}int main()
{printf("%d\n", rand); //此时rand为stdlib内的函数// ::为域作用限定符printf("%d\n", dong::rand); //此时dong::rand为dong命名空间域里面的rand变量return 0;
}
2、命名空间定义
定义命名空间,需要使用到namespace关键字,后面跟命名空间的名字,然后接一对{}即可,{}中即为命名空间的成员。
#include<stdio.h>
#include<stdlib.h>//命名空间域
namespace dong
{//命名空间中定义变量int rand = 0;//命名空间还可以嵌套定义//嵌套定义命名空间namespace inside{int tmp = 5;struct Stu{char name[20];int age;};}//命名空间中定义函数void func(){printf("func()\n");}//命名空间中定义结构体struct TreeNode{struct TreeNode* left;struct TreeNode* right;int val;};
}int main()
{printf("%d\n", rand); //此时rand为stdlib内的函数// ::为域作用限定符printf("%d\n", dong::rand); //此时dong::rand为dong命名空间域里面的rand变量//此时会去全局域找func()函数,如果全局域没有定义func()就会报错//func(); //dong::指定了去命名空间域dong里面找func()的定义。dong::func(); //dong::指定了去命名空间域dong里面找struct TreeNode的定义。struct dong::TreeNode node;//访问嵌套定义的命名空间里面的变量printf("%d\n", dong::inside::tmp);struct dong::inside::Stu stu;return 0;
}
当我们在一个项目中,如果有多个模块都用到了类似栈和队列的操作,并且它们也定义了Stack和QueueNode结构等,此时我们可以直接使用一个namespace dong的命名空间将该模块的.h和.c文件都包含在namespace dong命名空间域中,此时在namespace dong里面的变量和结构体定义就不会和别的模块里面的变量和结构体产生冲突了。
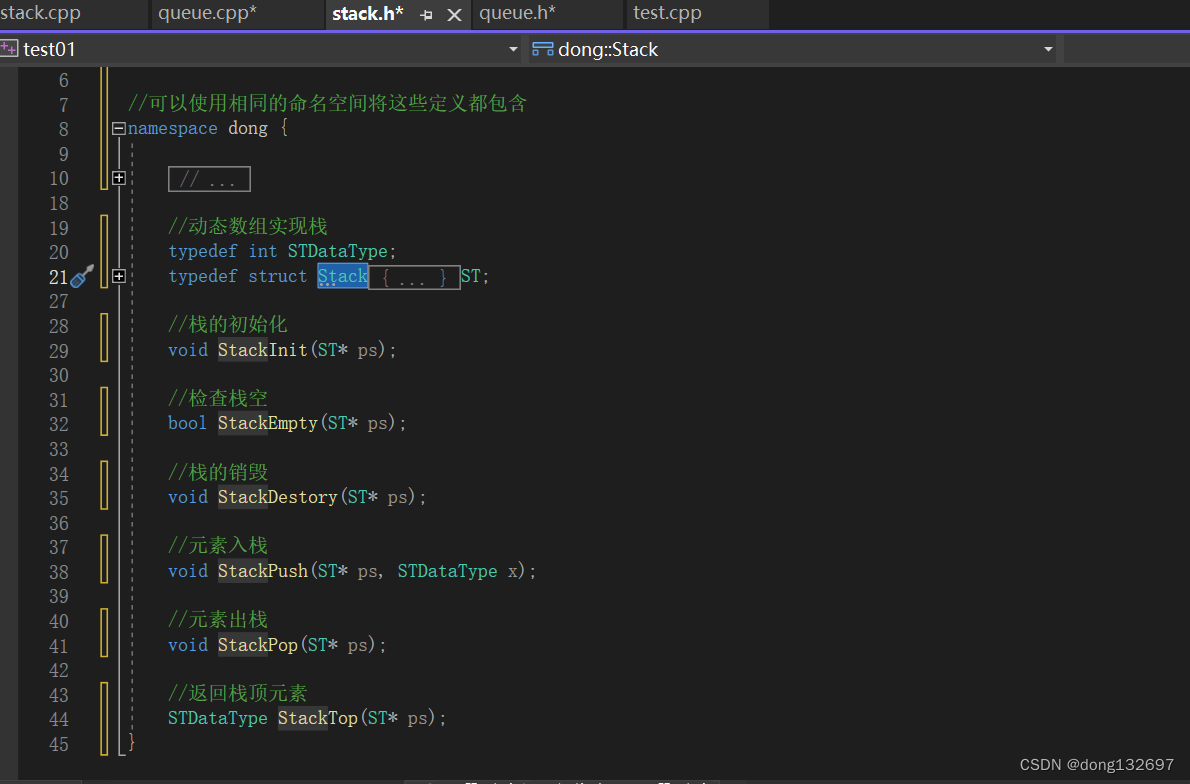
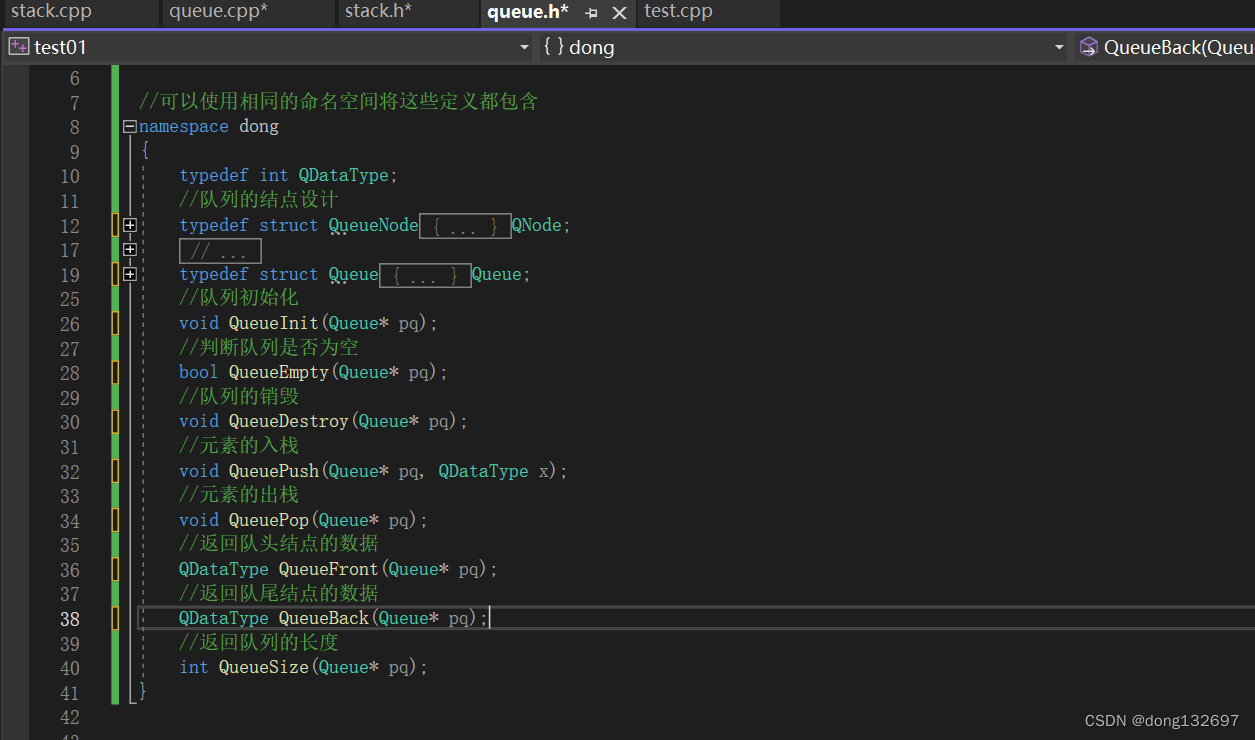

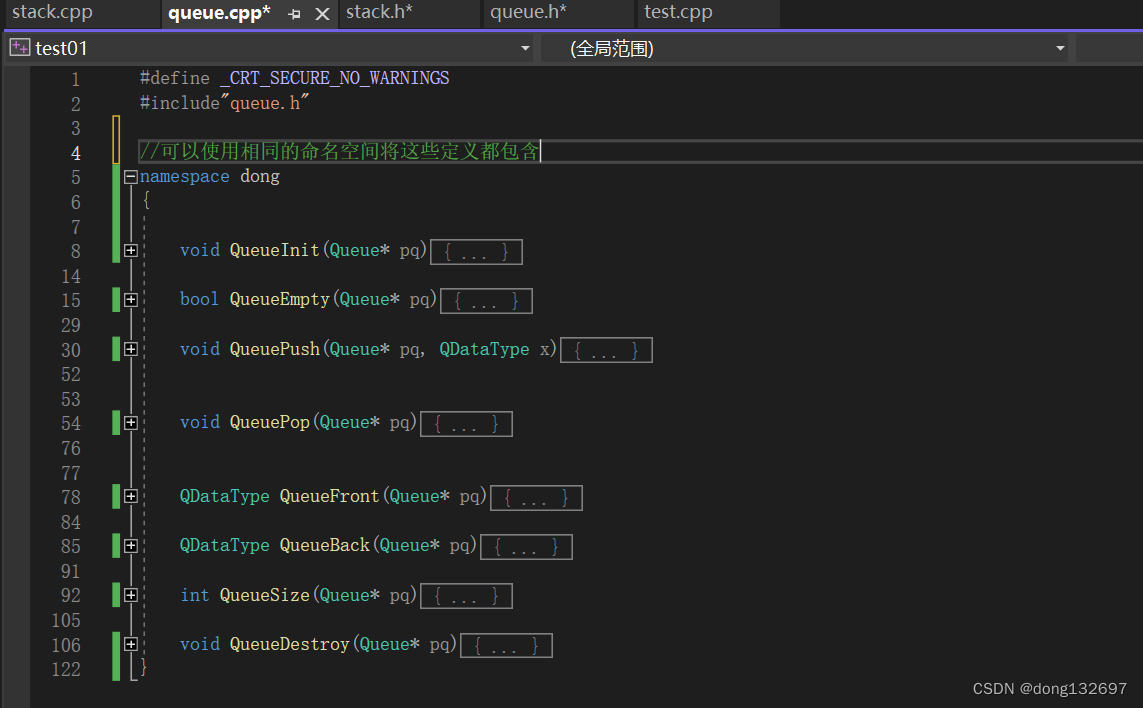
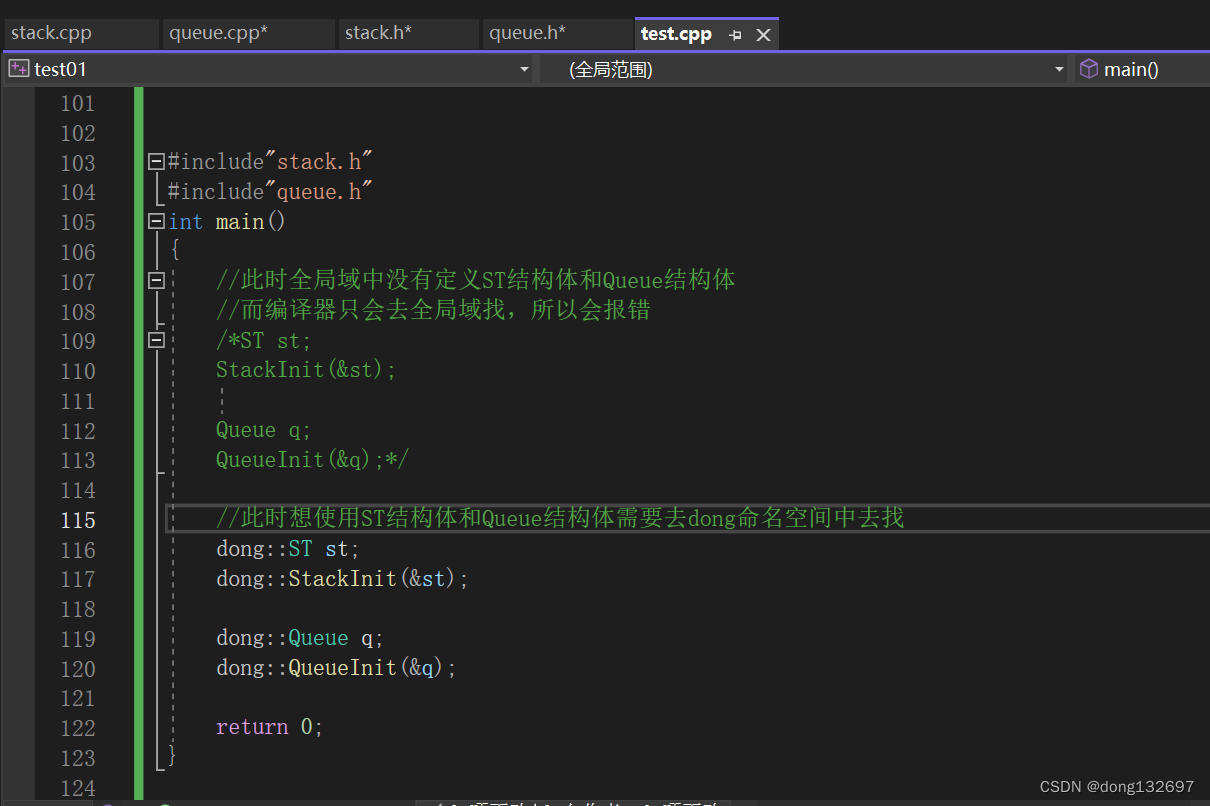
此时当我们想使用命名空间dong中定义的结构体和方法时,就不能再想下面图片中那样定义了。因为一个命名空间就定义了一个新的作用域,命名空间中的所有内容都局限于该命名空间中
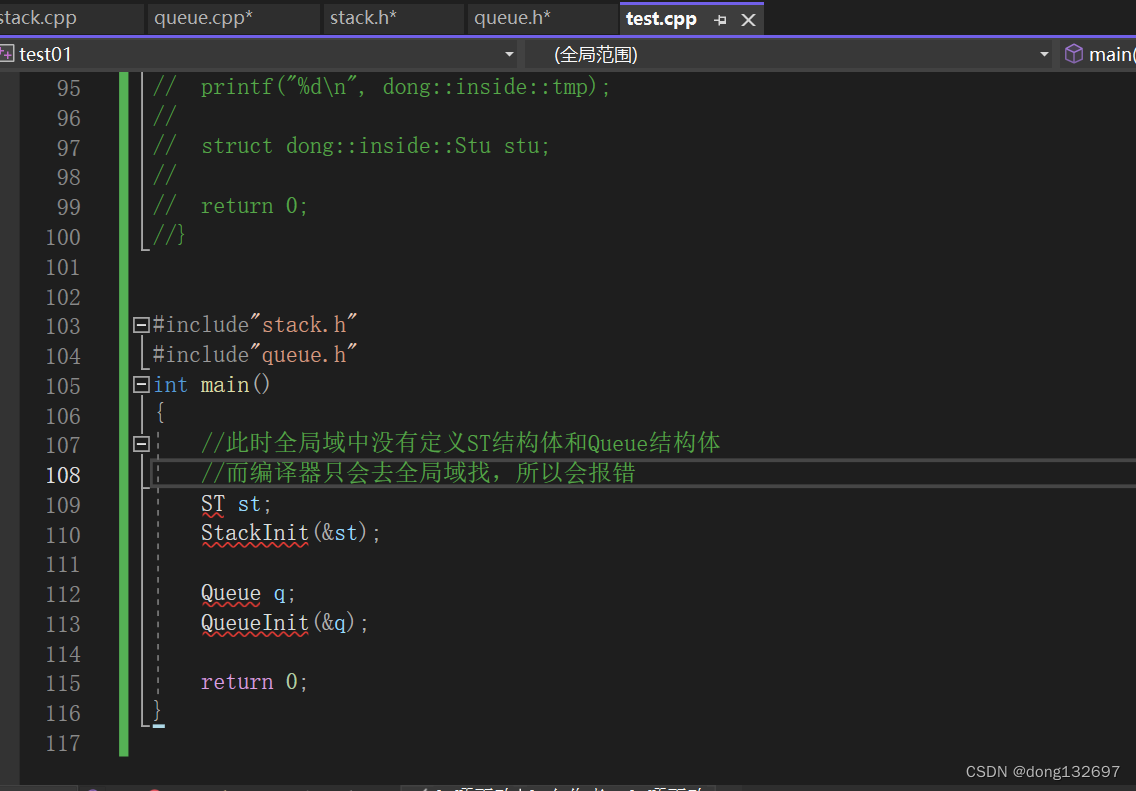
此时使用dong命名空间的结构体和函数就可以如下图一样的形式使用。这样就可以避免每个模块之间命名冲突,比如这个模块使用这些操作的话就去dong命名空间中去找这些定义,这个模块再使用其他操作的话可以去另一个命名空间中去找这些定义,这两个命名空间中可以定义相同名字的结构体或变量或函数,只要在使用时标明去哪个命名空间去找这些结构体或变量或函数的定义即可。
二、第一个c++程序
1、c++的hello world
下面为c++语言写的第一个hello world程序。
#include<iostream>
using namespace std;
int main()
{cout << "hello world" << endl;return 0;
}
其中该语句说明引入了c++里面的io流的库。
#include<iostream>
该语句说明将std命名空间里面的成员都引入,c++中标准库的东西都放到了std中,即如果有了该语句,在下面的代码中使用std里面的变量时就不需要写成std::cout,而是可以直接写成cout,省略前面的std::。因为此时std命名空间的成员已经都引入到全局域了,所以编译器可以在全局域里面找到这些成员的定义。
using namespace std;如果我们将using namespace std;注释掉的话,再使用命名空间std里面的成员时,就需要像下面这样写。
#include<iostream>
//using namespace std;
int main()
{std::cout << "hello world" << std::endl;return 0;
}
我们还可以只引入std库里面部分的变量名称。
#include<iostream>
//using namespace std;
//只引入我们需要的成员即可
using std::cout;
using std::cin;
using std::endl;
int main()
{cout << "hello world" << endl;return 0;
}
2、std命名空间的使用惯例
1.在日常练习中,建议直接using namespace std即可,这样就很方便。
2 using namespace std展开,标准库就全部暴露出来了,如果我们定义跟库重名的类型/对象/函数,就存在冲突问题。该问题在日常练习中很少出现,但是项目开发中代码较多、规模大,就很容易出现。所以建议在项目开发中使用,像std::cout这样使用时指定命名空间 或 using std::cout展开常用的库对象/类型等方式。
#include<iostream>
#include<vector>
//引入常用的库对象/类型
using std::cout;
using std::endl;
int main()
{//指定命名空间访问std::vector<int> v;v.push_back(1);v.push_back(2);v.push_back(3);v.push_back(4);cout << "hello world!" << endl;cout << "hello world!" << endl;cout << "hello world!" << endl;cout << "hello world!" << endl;return 0;
}
三、C++输入&输出
1、c++输入&输出
1.使用cout标准输出对象(控制台)和cin标准输入对象(键盘)时,必须包含< iostream >头文件以及按命名空间使用方法使用std。
2. cout和cin是全局的流对象,endl是特殊的C++符号,表示换行输出,他们都包含在包含< iostream >头文件中。
3. << 是流插入运算符,>> 是流提取运算符。
4. 使用C++输入输出更方便,不需要像printf/scanf输入输出时那样,需要手动控制格式。C++的输入输出可以自动识别变量类型。
在c语言中,当我们需要在标准输出流stdout中打印数据时,使用printf函数,当我们要读取数据时,需要使用scanf从标准输入流stdin中获取数据,并且这两个函数在打印和获取数据时,都要标明数据的类型。
但是c++中不需要像c语言那样标明数据类型。
#include<iostream>
//using namespace std;
int main()
{// << 是流插入运算符std::cout << "hello world" << std::endl;//std命名空间中的endl就类似于换行符,即 std::endl 等价于 "\n"std::cout << "hello world" << "\n";//c++中自动识别类型int i = 11;double d = 11.11;printf("%d %lf\n", i, d);//c++中可以自动识别类型std::cout << i << "," << d << std::endl;//c语言中读取数据scanf("%d %lf", &i, &d);printf("%d,%lf\n", i, d);//c++中读取数据// >> 为流提取std::cin >> i >> d;std::cout << i << "," << d << std::endl;//当需要精度控制时,因为c++实现精度控制比较麻烦,所以还可以使用c语言的printf()printf("%.2lf\n", d);return 0;
}
四、c++中缺省参数
1、缺省参数概念
缺省参数是声明或定义函数时为函数的参数指定一个缺省值。在调用该函数时,如果没有指定实参则采用该形参的缺省值,否则使用指定的实参。缺省值必须是常量或者全局变量。
//缺省参数
#include<iostream>
using namespace std;
void Func(int a = 0)
{cout << a << endl;
}
int main()
{//当调用函数Func()时,传递的有实参,则缺省参数的值不起作用Func(1);Func(2);Func(3);//当调用函数Func()时,没有传递实参,此时缺省参数的值就起作用Func();return 0;
}
2、缺省参数分类
全缺省参数:全缺省参数需要注意的就是在函数调用时,不能直接跳过前面的形参,然后传值给后面的形参。
//全缺省参数
#include<iostream>
using namespace std;
void TestFunc(int a = 10, int b = 20, int c = 30)
{cout << "a = " << a << endl;cout << "b = " << b << endl;cout << "c = " << c << endl << endl;
}
int main()
{TestFunc();//传入的实参是按照从左向右的顺序赋值的,只有一个实参就赋给形参aTestFunc(1);//有两个实参就赋给a和bTestFunc(1,2);//有三个实参就赋给a、b、cTestFunc(1,2,3);//这里需要注意的是,不能直接跳过前面的a,然后直接传值给b//TestFunc(, 1, ); //这样是错误的,语法不允许return 0;
}
半缺省参数:这里需要注意的是半缺省参数必须从右往左依次来给出,不能间隔着给。
//半缺省参数
#include<iostream>
using namespace std;//这里函数TestFunc只定义了两个缺省参数,所以在调用时必须要将形参a的值通过实参传递过来
//半缺省参数必须从右往左依次来给出,不能间隔着给
// void TestFunc(int a = 10, int b, int c = 30) //这样定义的就是错误的
void TestFunc(int a, int b = 20, int c = 30)
{cout << "a = " << a << endl;cout << "b = " << b << endl;cout << "c = " << c << endl << endl;
}
int main()
{//此时必须要将形参a的值通过实参传递过去//TestFunc(); //错误// //传入的实参是按照从左向右的顺序赋值的,只有一个实参就赋给形参aTestFunc(1);//有两个实参就赋给a和bTestFunc(1, 2);//有三个实参就赋给a、b、cTestFunc(1, 2, 3);return 0;
}
3、缺省参数应用
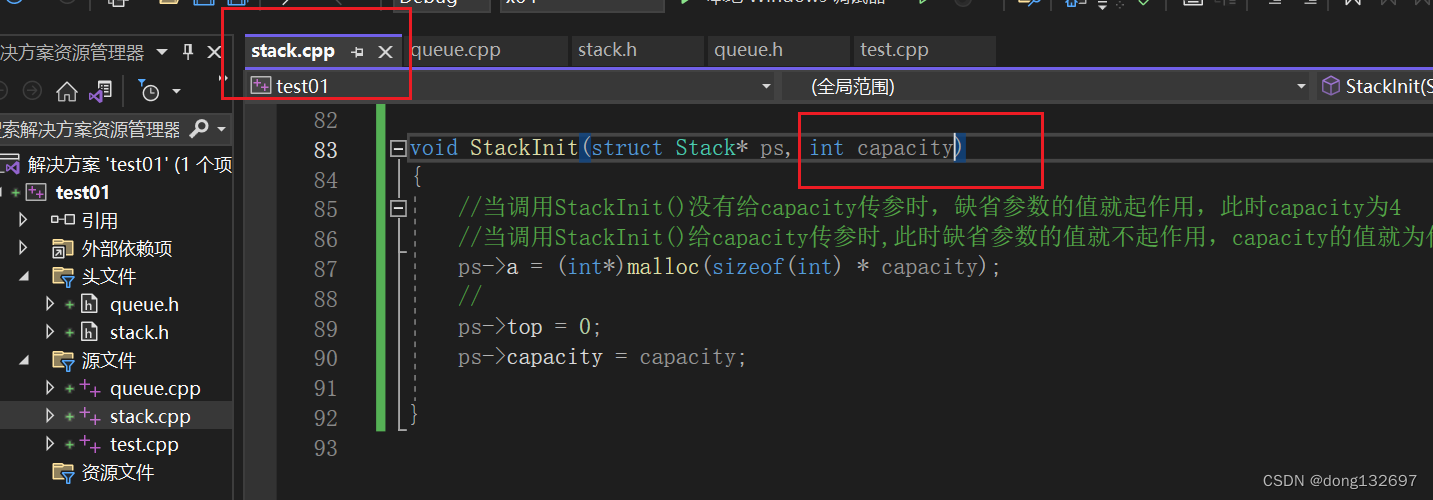
前面我们使用c语言实现了栈的创建和初始化,当我们初始化栈时会为栈的容量开辟4个空间,但是当我们知道需要向栈中插入多少数据时,此时如果还每次只开辟capacity*2的空间,然后一次一次开辟到我们需要的空间时,这样程序的开销就大了,因为每次开辟空间还有可能需要将数据转移。而此时缺省参数就可以解决上面的问题,我们将栈容量定义为缺省参数,当在初始化栈时,如果已经提前知道了需要多少空间,我们就可以给capacity传入值,而当不知道需要多少空间时,就可以不用给capacity传值,此时capacity就为4。
#include<iostream>
#include<stdlib.h>
struct Stack
{int* a;int top;int capacity;
};
//将栈的容量capacity设为缺省参数
void StackInit(struct Stack* ps, int capacity = 4)
{//当调用StackInit()没有给capacity传参时,缺省参数的值就起作用,此时capacity为4//当调用StackInit()给capacity传参时,此时缺省参数的值就不起作用,capacity的值就为传进来的值ps->a = (int*)malloc(sizeof(int) * capacity);//ps->top = 0;ps->capacity = capacity;}int main()
{//当我们在使用栈时,已经提前知道了一定会插入100个数据,所以可以直接将capacity的值当作实参传入//这样可以提前开好空间,插入数据时就避免了扩容,程序开销就会小一些struct Stack st1;StackInit(&st1, 100);//当我们不知道需要插入多少数据时,就可以不传入capacity的值。struct Stack st2;StackInit(&st2);
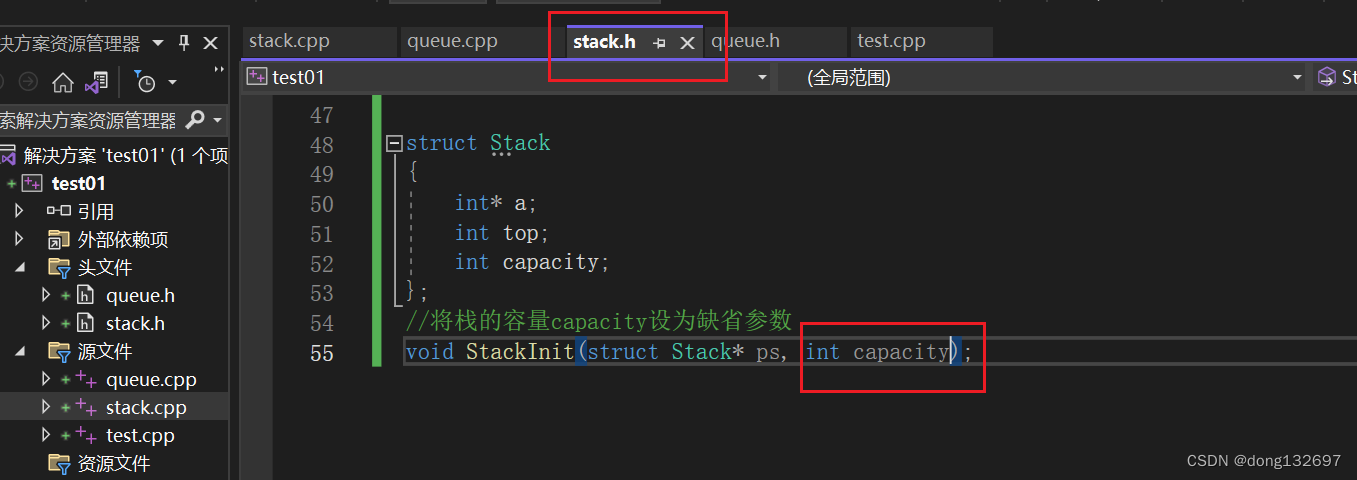
}上面的代码中我们是直接将StackInit(struct Stack* ps,int capacity=4)函数写出来了,而在项目中,我们需要在.h文件中先将StackInit(struct Stack* ps,int capacity=4)声明一下,然后在.c文件中完成StackInit(struct Stack* ps,int capacity=4)函数的定义。此时就会产生一个问题,如果StackInit()函数的声明和定义中给缺省参数capacity的值不一样时,那么编译器会以哪个为准呢?所以缺省参数不能在函数声明和定义中同时出现。
此时编译器就不知道该以哪一个为准了。
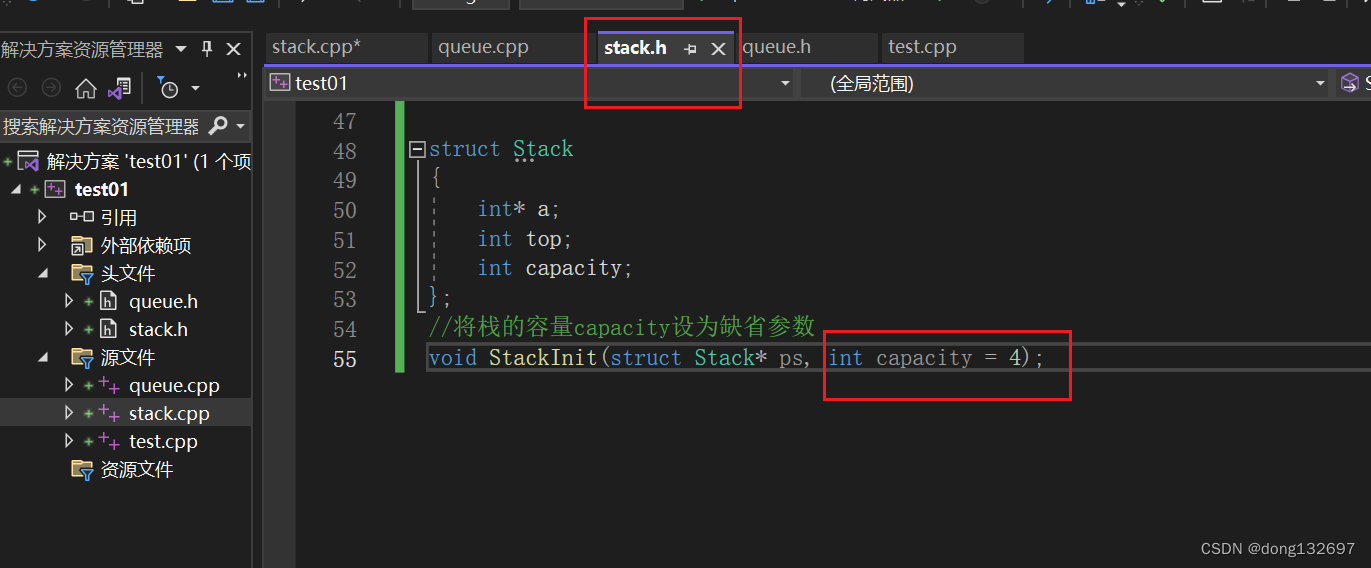
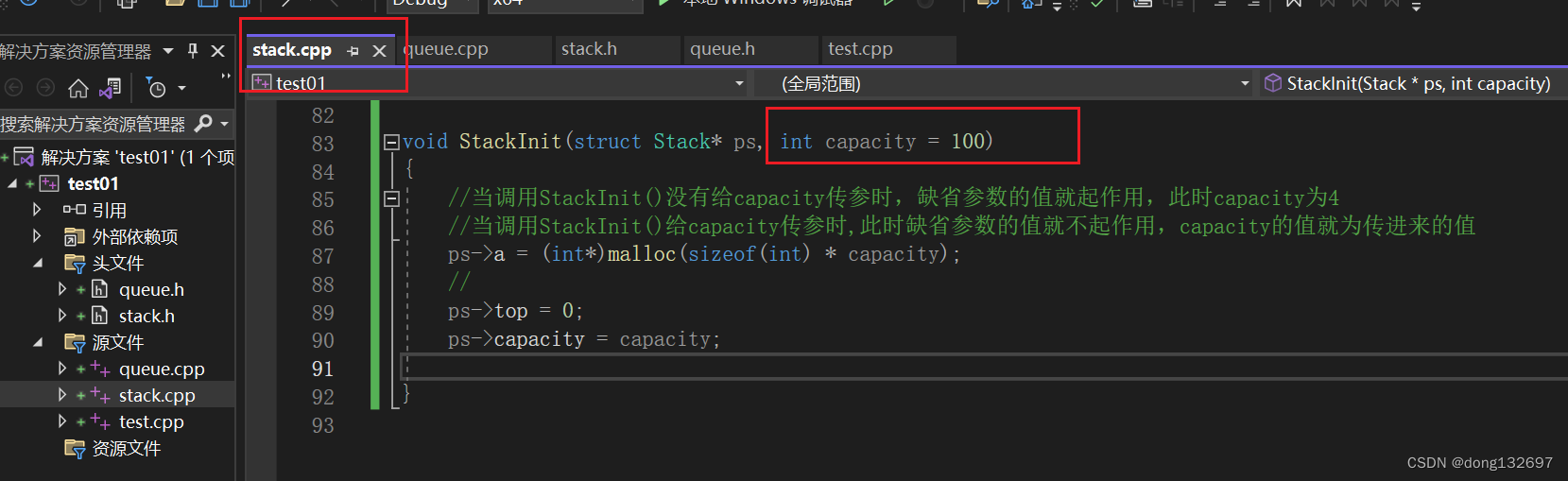
所以都是在函数声明中给缺省参数值,然后函数定义时就不需要给缺省参数值了。
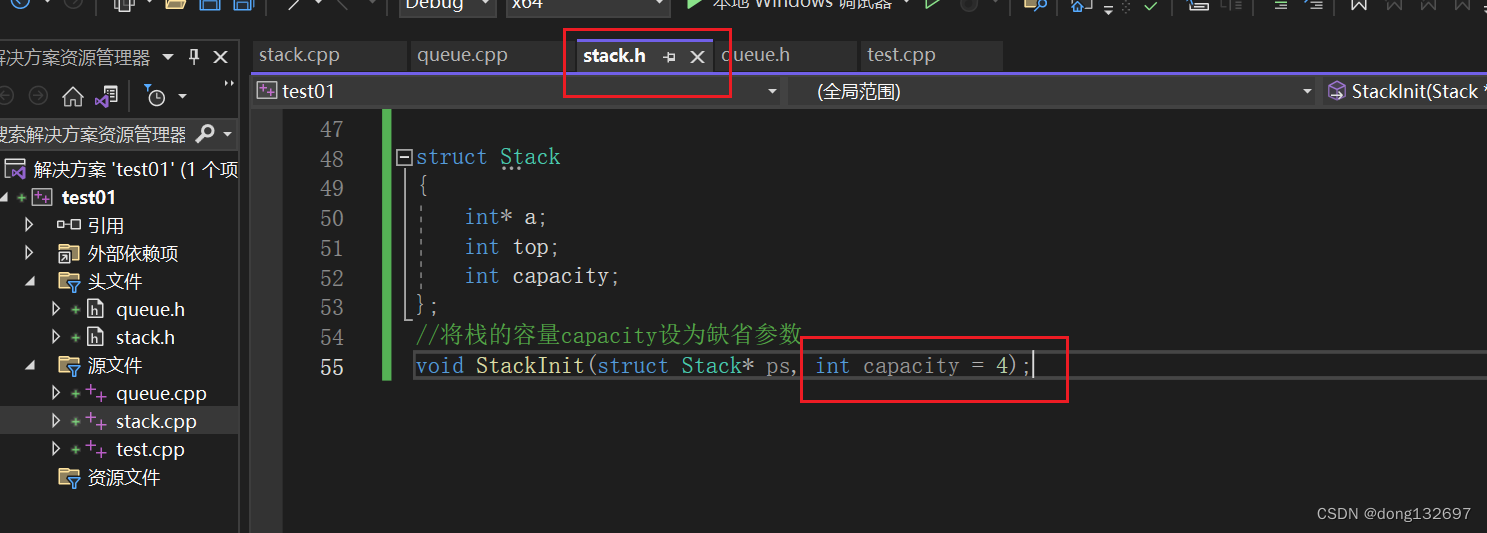
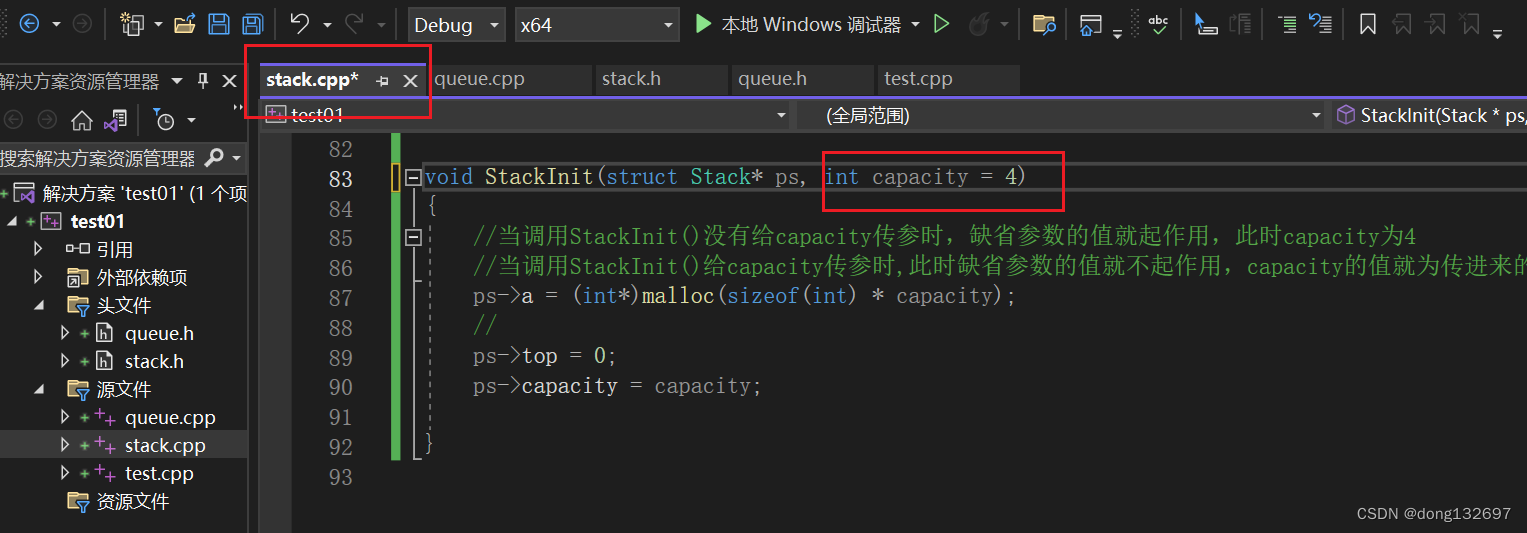
那如果在函数定义时给了缺省参数,而在函数声明时没有给缺省参数,那么此时缺省参数的值不会起作用。因为已经在函数声明时说明了该函数没有缺省参数,但是调用时按缺省参数的形式调用,就会出现错误。

五、c++中函数重载
1、函数重载概念
函数重载:是函数的一种特殊情况,C++允许在同一作用域中声明几个功能类似的同名函数,这些同名函数的形参列表(参数个数 或 类型 或 类型顺序)不同,常用来处理实现功能类似数据类型不同的问题。
函数重载 – 参数个数不同
//函数重载 参数个数不同
#include<iostream>
using namespace std;
int Add(int a, int b, int c)
{return a + b + c;
}
int Add(int a, int b)
{return a + b;
}int main()
{cout << Add(2, 2, 2) << endl;cout << Add(2, 2) << endl;return 0;
}
函数重载 – 参数类型不同
//函数重载 参数类型不同
#include<iostream>
using namespace std;
int Add(int a, int b)
{return a + b;
}
double Add(double a, double b)
{return a + b;
}int main()
{cout << Add(2, 2) << endl;cout << Add(1.1, 2.2) << endl;return 0;
}
函数重载 – 参数类型顺序不同
//函数重载 参数类型顺序不同
#include<iostream>
using namespace std;
void func(int i, char ch)
{cout << "void func(int i, char ch)" << endl;
}
void func(char ch, int i)
{cout << "void func(char ch, int i)" << endl;
}
int main()
{func(1, 'a');func('a', 1);return 0;
}
当函数返回值不同时不构成函数重载,只有参数不同才构成重载。因为函数返回值不同,函数调用时编译器无法区分去调用哪一个函数。
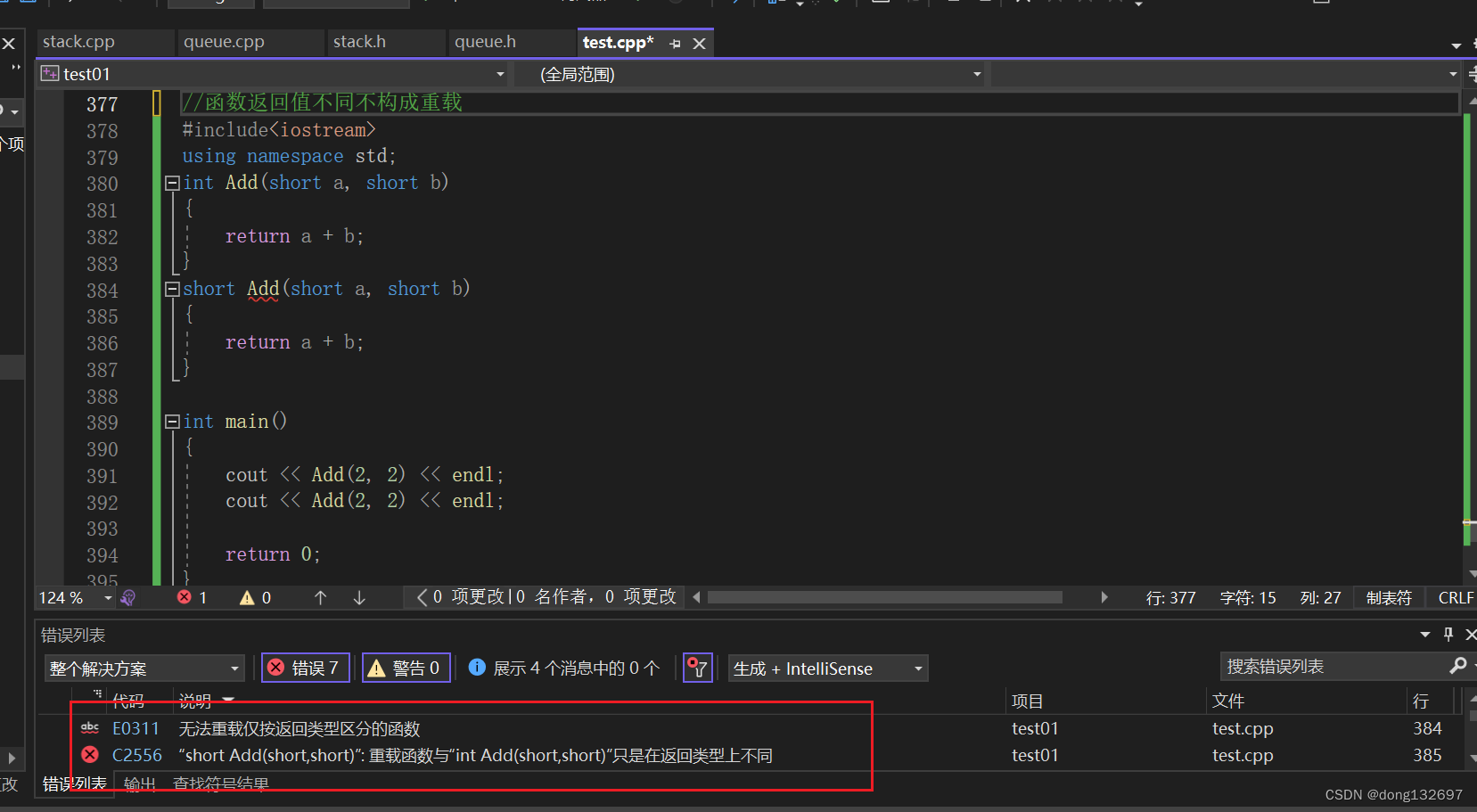
2、函数重载应用
在c语言中,当我们要交换两个int型变量的值时,需要写一个函数;当我们要交换两个double类型的值时,又要写一个函数,而且两个函数的名字还不能相同。
#include<stdio.h>
void Swapi(int* p1, int* p2)
{int tmp = *p1;*p1 = *p2;*p2 = tmp;
}void Swapd(double* p1, double* p2)
{double tmp = *p1;*p1 = *p2;*p2 = tmp;
}int main()
{int a = 1;int b = 2;double c = 1.1;double d = 2.2;Swapi(&a, &b);Swapd(&c, &d);printf("%d %d\n", a, b);printf("%lf %lf\n", c, d);return 0;
}
但是c++中的函数重载就可以解决这个问题,只要两个名称相同的函数的参数数量、类型或顺序不同,就可以构成函数重载。
#include<iostream>
using namespace std;
void Swap(int* p1, int* p2)
{int tmp = *p1;*p1 = *p2;*p2 = tmp;
}void Swap(double* p1, double* p2)
{double tmp = *p1;*p1 = *p2;*p2 = tmp;
}int main()
{int a = 1;int b = 2;double c = 1.1;double d = 2.2;Swap(&a, &b);Swap(&c, &d);cout << a << " " << b << endl;cout << c << " " << d << endl;return 0;
}
通过上述代码我们可以发现c++中的cout和cin可以自动识别类型,其实也是用到了函数重载,这样cout和cin才可以在各种类型时都可以用。
六、c++中的引用
1、 引用概念
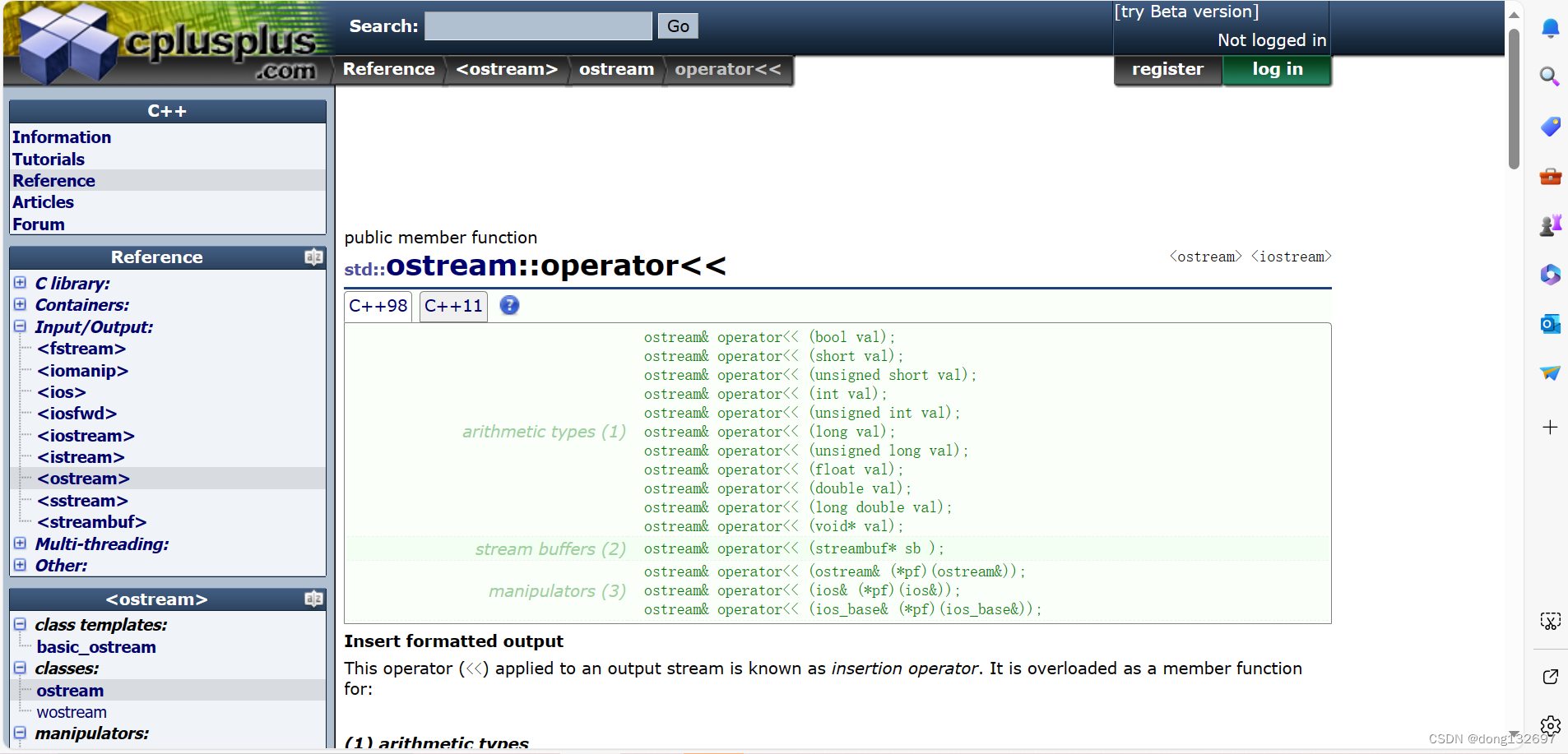
引用不是新定义一个变量,而是给已存在变量取了一个别名,编译器不会为引用变量开辟内存空间,它和它引用的变量共用同一块内存空间。
引用变量的定义: 类型& 引用变量名(对象名) = 引用实体;
//引用
#include<iostream>
using namespace std;int main()
{int a = 0;//b为a变量的别名,a和b共用一块内存空间,不管修改a或b的值,这片空间的值都会改变int& b = a;//a和b共用一块内存空间,所以a和b的地址一样cout << &b << endl;cout << &a << endl;a++;b++;cout << a << endl;cout << b << endl;return 0;
}

2、引用特性
1.引用在定义时必须初始化。
2.一个变量可以有多个引用。
3.引用一旦引用一个实体,再不能引用其他实体。
//引用特性
#include<iostream>
using namespace std;int main()
{int a = 1;//1.引用在定义时必须初始化,不然就不知道该引用是哪个变量的别名//int& b; //2.一个变量可以有多个引用,即这些变量都和a共享一片内存空间,只要其中一个引用的值改变了,该内存空间的值就改变了int& b = a;int& c = a;//还可以给a的别名c再起一个别名,此时d也和c一样,与a共享一片内存空间。int& d = c;++a;++b;++c;++d;cout << a << endl;cout << b << endl;cout << c << endl;cout << d << endl;int x = 10;//3.引用一旦引用一个实体,就不能再引用其他实体b = x; //因为此时是给b赋值为x,并不是将b变为x的别名cout << a << endl;cout << b << endl;cout << c << endl;cout << d << endl;return 0;
}
3、常引用
当定义一个const修饰的int型变量时,则说明该变量的值不可以被修改,如果此时给该变量设置一个int类型的引用,然后通过该引用将这个常变量的值修改时,这就违反了const修饰的变量的值不能被修改的规则。所以在创建引用时,也需要加上const修饰。
#include<iostream>
using namespace std;
int main()
{int a = 10;int& b = a;//typeid().name()可以显示该变量的类型cout << typeid(a).name() << endl;cout << typeid(b).name() << endl;const int c = 20;//c变量被const修饰,即为常变量,权限为只能读取,不能修改//而int& d = c;将c的权限放大为可读可修改了,所以会报错。//int& d = c; //当将d的权限也设置为只能读取,不能修改,此时const int& d = c;发生权限平移,不会报错const int& d = c;//权限可以缩小//e变量的权限为可读可修改int e = 30;//f为只能读,不能修改,所以const int& f = e;发生了权限缩小,不会报错const int& f = e;return 0;
}
所有类型转换都不是对原类型的数据进行改变,而是生成一个临时变量,将原类型的值拷贝到其中,再对该临时变量进行类型转换。因为如果将int类型强制类型转换为double类型,这是没办法操作的,int占4个字节,double占8个字节,如果改变int的值,根本没有办法存储的下8个字节,所有此时会创建一个8个字节的临时变量,然后拷贝int的值,再将该值转为double类型。
#include<iostream>
using namespace std;
int main()
{int ii = 1;double dd = ii;//将int型的ii强制类型转换为double类型,并不会再ii的地址内将ii的值改变,//而是创建一个临时变量,然后将ii的值给临时变量,将该临时变量的值转为double类型。//double dd = (double)ii;// 类型转换,并不会改变原变量类型,中间都会产生一个临时变量//发生了权限放大,会报错//double& rdd = ii;//这样就没有发生权限放大了,不会报错//此时rdd为临时变量的别名,其与临时变量共享一片空间,而不是和ii共享一片空间const double& rdd = ii;const int& x = 10; //x为常量10的别名return 0;
}

如果使用引用传参时,函数内如果不改变实参的值,那么建议尽量用const引用传参,因为该形参具有很强的接受度。
#include<iostream>
using namespace std;
void func1(int n)
{//该函数的形参为实参的拷贝,所以在函数中修改形参n的值,并不会影响到实参的值,所以常量可以当作实参传进来
}
void func2(int& n)
{//该函数的形参为实参的别名,在函数中可以通过该别名修改实参的值,所以常量不可以被当作实参传递过来
}
void func3(const int& n)
{//如果使用引用传参,函数内如果不改变实参的值,那么尽量使用const修饰引用传参//因为这样定义时,形参具有很强的接受度。
}
int main()
{int a = 10;const int b = 20;func1(a);func1(b);func1(30); //func1()函数对实参是只读,所以没有发生权限放大func2(a);//func2(b);//func2(c); //func2()函数对实参为读写,而本来b和30为常量,只有读的权限,所以发生了权限放大,会报错func3(a);func3(b);func3(30);func3(1.11); double d = 2.22;func3(d); //此时double类型也可以传过去,因为传的是类型转换时产生的临时变量return 0;
}
4、指针和引用的区别
引用和指针的不同点:
- 引用概念上定义一个变量的别名,指针存储一个变量地址。
- 引用在定义时必须初始化,指针没有要求。
- 引用在初始化时引用一个实体后,就不能再引用其他实体,而指针可以在任何时候指向任何一个同类型实体。
- 没有NULL引用,但有NULL指针。
- 在sizeof中含义不同:引用结果为引用类型的大小,但指针始终是地址空间所占字节个数(32位平台下占4个字节)。
- 引用自加即引用的实体增加1,指针自加即指针向后偏移一个类型的大小。
- 有多级指针,但是没有多级引用。
- 访问实体方式不同,指针需要显式解引用,引用编译器自己处理。
- 引用比指针使用起来相对更安全。
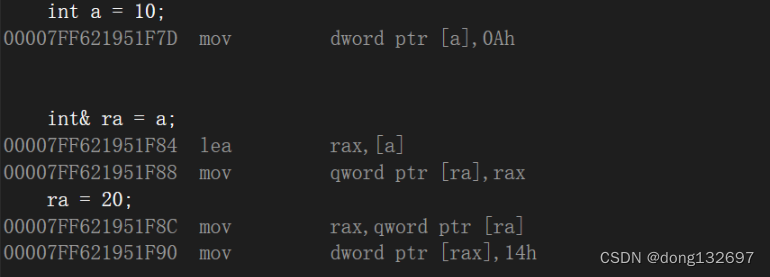
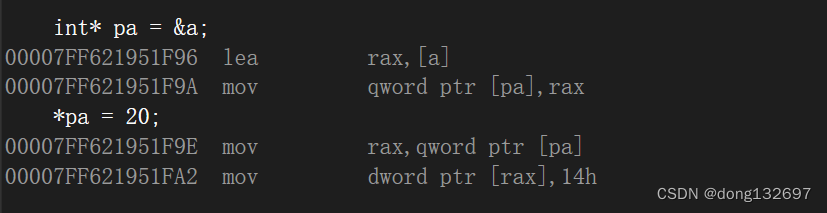
但是引用和指针在底层的实现是相同的。
可以看到引用和指针的汇编语言是一样的,即引用在底层也是使用指针来实现的。
5、引用的应用 – 做参数
(1)输出型参数
引用的一个使用场景就是作为输出型参数,即在函数定义形参时,将形参定义为实参的引用,然后就可以通过引用来改变实参的值。
//引用应用
#include<iostream>
using namespace std;
//形参是实参的别名,即引用,所以可以通过形参来改变实参的值
void Swap(int& r1, int& r2)
{int tmp = r1;r1 = r2;r2 = tmp;
}
int main()
{int a = 0;int b = 2;cout << "a = " << a << endl;cout << "b = " << b << endl;Swap(a, b);cout << "a = " << a << endl;cout << "b = " << b << endl;return 0;
}
所以我们可以使用引用来修改一下之前写的顺序表,我们还记得之前写的顺序表代码如下。
typedef int SLDataType;
typedef struct SeqList
{SLDataType* data; //指向动态开辟的数组int size; //有效数据个数int capacity; //顺序表的容量
}SL;void SLInit(SL* ps)
{assert(ps);SLDataType* tmp = (SLDataType*)calloc(4, sizeof(SLDataType)); //初始化时自动开辟4个空间if (tmp == NULL){perror("SLInit");exit(-1); //退出程序}ps->data = tmp;ps->size = 0;ps->capacity = 4;
}int main()
{//创建一个SL类型的结构体变量SL s;//需要将s地址传入函数,这样函数中才能通过s的地址来改变s结构体变量的值SLInit(&s);return 0;
}
当我们了解了引用之后,我们就可以将上面的代码改为使用引用来写,而不需要使用指针。
#include<iostream>
#include<stdlib.h>
#include<assert.h>
using namespace std;typedef int SLDataType;
typedef struct SeqList
{SLDataType* data; //指向动态开辟的数组int size; //有效数据个数int capacity; //顺序表的容量
}SL;//形参是实参的别名,即引用,所以可以通过形参来改变实参的内容。
void SLInit(SL& ps)
{assert(&ps);SLDataType* tmp = (SLDataType*)calloc(4, sizeof(SLDataType)); //初始化时自动开辟4个空间if (tmp == NULL){perror("SLInit");exit(-1); //退出程序}ps.data = tmp;ps.size = 0;ps.capacity = 4;
}int main()
{//创建一个SL类型的结构体变量SL s;//此时直接将该变量传入函数中SLInit(s);return 0;
}
那么我们前面写的单链表也可以改成使用引用的版本,我们之前写的单链表代码如下。在实现单链表的一些操作时,我们使用到了二级指针。
#include<stdlib.h>
#include<assert.h>
#include<stdio.h>typedef int SLTDataType;
typedef struct SListNode
{SLTDataType data;struct SListNode* next;
}SLTNode;void SListPushBack(SLTNode** pphead, SLTDataType x)
{assert(pphead);SLTNode* newNode = (SLTNode*)malloc(sizeof(SLTNode)); //创建一个新结点assert(newNode);newNode->data = x;newNode->next = NULL;if (*pphead == NULL) //如果单链表为空,就使新结点为单链表的首结点。{*pphead = newNode;}else{//找单链表的尾结点SLTNode* tail = *pphead;while (tail->next != NULL){tail = tail->next;}tail->next = newNode;}
}int main()
{//创建一个单链表结点指针,并将该指针赋值为NULL,代表该单链表为空SLTNode* s = NULL;//此时如果函数SListPushBack()中想要改变s的值不为NULL,就需要将s的地址传入函数中,//而s本来就为指针,所以SListPushBack()函数的形参要定义一个二级指针,用来接收指针s的地址。SListPushBack(&s, 1);SListPushBack(&s, 2);SListPushBack(&s, 3);SListPushBack(&s, 4);return 0;
}
现在我们可以使用引用来改变上面的代码,这样我们就不用使用二级指针了。
#include<stdlib.h>
#include<assert.h>
#include<stdio.h>typedef int SLTDataType;
typedef struct SListNode
{SLTDataType data;struct SListNode* next;
}SLTNode;//将函数的形参定义为一个SLTNode*类型的指针变量的引用
//此时pphead就是list的别名,phead的改变也会影响list
void SListPushBack(SLTNode*& pphead, SLTDataType x)
{assert(&pphead);SLTNode* newNode = (SLTNode*)malloc(sizeof(SLTNode)); //创建一个新结点assert(newNode);newNode->data = x;newNode->next = NULL;if (pphead == NULL) //如果单链表为空,就使新结点为单链表的首结点。{pphead = newNode;}else{//找单链表的尾结点SLTNode* tail = pphead;while (tail->next != NULL){tail = tail->next;}tail->next = newNode;}
}int main()
{//创建一个单链表结点指针,即代表该单链表为空SLTNode* list = NULL;//此时SListPushBack(SLTNode*& pphead, SLTDataType x)的形参为list指针变量的引用//所以在函数中通过该引用就可以改变list的内容SListPushBack(list, 1);SListPushBack(list, 2);SListPushBack(list, 3);SListPushBack(list, 4);return 0;
}
在一些数据结构的书上也会这样定义,即将上面的代码再次简化。
#include<stdlib.h>
#include<assert.h>
#include<stdio.h>typedef int SLTDataType;
typedef struct SListNode
{SLTDataType data;struct SListNode* next;
}SLTNode,*PSLTNode;//*PSLTNode等价于下面的语句
//typedef struct SListNode* PSLTNode;//将函数的形参定义为一个SLTNode*类型的指针变量的引用
//void SListPushBack(SLTNode*& pphead, SLTDataType x)
//上面的语句等价于下面的语句
void SListPushBack(PSLTNode& pphead, SLTDataType x)
{assert(&pphead);SLTNode* newNode = (SLTNode*)malloc(sizeof(SLTNode)); //创建一个新结点assert(newNode);newNode->data = x;newNode->next = NULL;if (pphead == NULL) //如果单链表为空,就使新结点为单链表的首结点。{pphead = newNode;}else{//找单链表的尾结点SLTNode* tail = pphead;while (tail->next != NULL){tail = tail->next;}tail->next = newNode;}
}int main()
{//等价于SLTNode* s;//通过PSLTNode创建一个单链表结点指针,该指针为空,就说明该单链表为空PSLTNode s = NULL;SListPushBack(s, 1);SListPushBack(s, 2);SListPushBack(s, 3);SListPushBack(s, 4);return 0;
}
(2)大对象传参,提高效率
#include<time.h>
#include<iostream>
using namespace std;
struct A
{int a[10000];
};void TestFunc1(A aa)
{}void TestFunc2(A& aa)
{}int main()
{A a;//以值作为函数参数int begin1 = clock();for (int i = 0; i < 10000; ++i){//每次调用TestFunc1函数都会在该函数中重新创建一个A结构体,并且该结构体的数据都拷贝实参a的值TestFunc1(a);}int end1 = clock();//以引用作为函数参数int begin2 = clock();for (int i = 0; i < 10000; ++i){//调用函数TestFunc2不会重新创建A结构体,所以该循环会效率更高TestFunc2(a);}int end2 = clock();cout << end1 - begin1 << endl;cout << end2 - begin2 << endl;return 0;
}
6、引用的应用 – 做返回值
(1)输出型返回对象
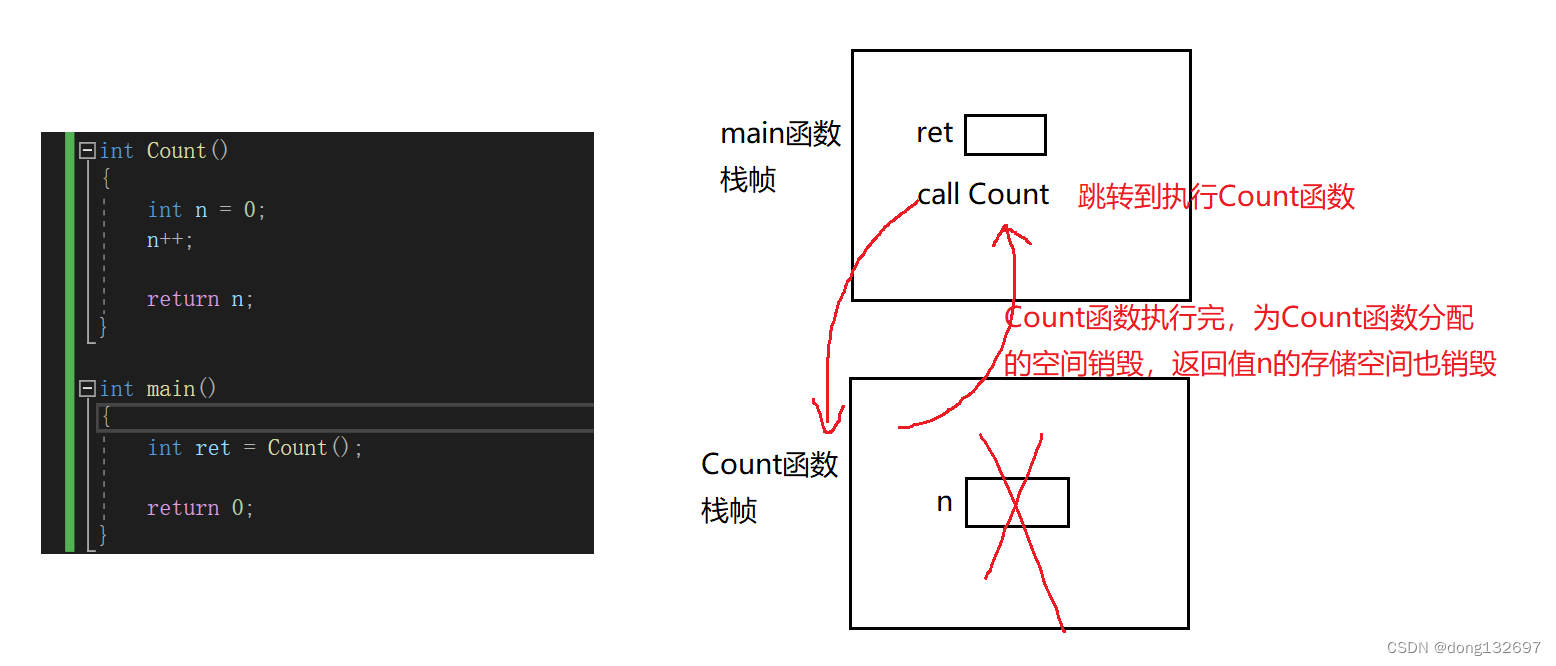
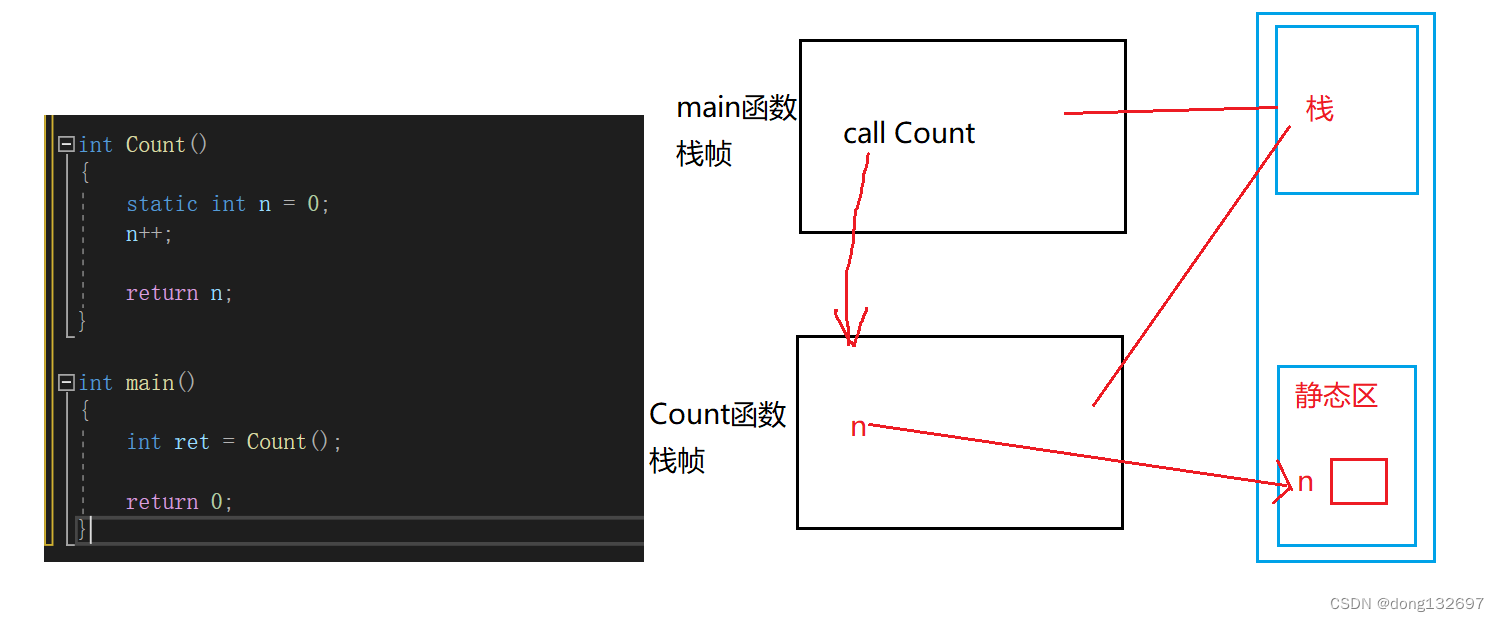
我们知道c语言中每当有一个函数调用时,编译器都会在栈区中为该次函数调用开辟一片空间,例如有如下一个程序。Count()函数的返回值为int型,那么函数调用时是如何将返回值带回到main函数内的呢?
我们先看下面两个传值返回的例子。
(1)我们可以看到当Count函数执行完后,编译器为该函数分配的空间就会回收,此时存储返回值n的空间也销毁,那么正确的n的值是怎么回到main函数中的呢?其实当Count函数返回值较小时,此时系统会直接将Count函数的返回值存在寄存器中,然后main函数去该寄存器取返回值即可。当Count函数返回值较大时,会先在main的栈帧中创建一个临时变量,然后将Count栈帧里面的n拷贝到main的临时变量中,不会直接取Count函数的栈帧中取n,因为此时Count函数的栈帧已经销毁,n的内存空间中已经存的不是原来的值了。
(2)下图中的n为static修饰的静态变量,所以此时n存储在静态区。此时虽然函数Count的空间销毁后,n还是存在静态区中没有被销毁,但是在main函数中获取Count函数的返回值时也不会去静态区去取n的值。因为编译器不知道此时静态区中有Count函数的返回值。而是还会将Count的返回值和上面例子的处理情况一样,即将Count函数的返回值拷贝一份到main函数的临时变量中。
所以不管n是在栈区还是静态区,编译器都会生成一个函数返回对象的拷贝,用来作为函数调用返回值,这样调用函数的栈帧销毁了,返回值也还有拷贝的一份,不会让函数的返回值丢失。
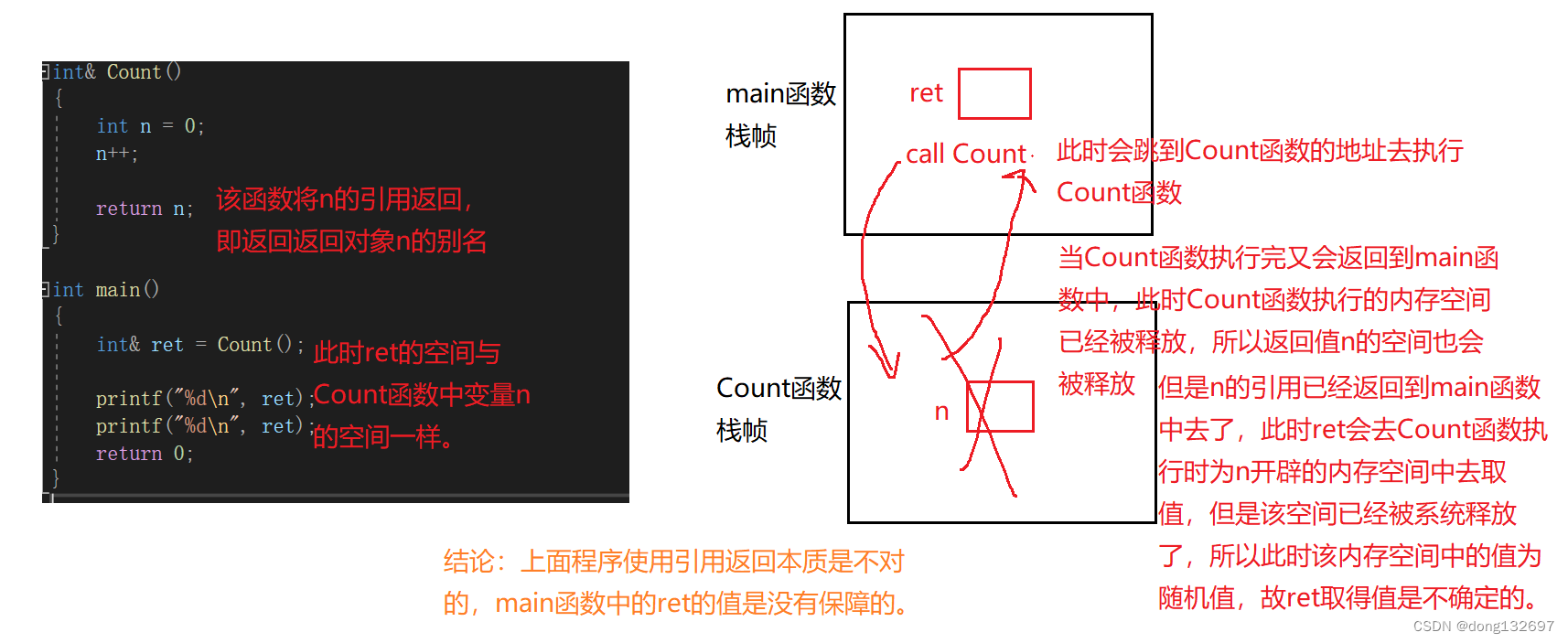
我们再看下面的两个传引用返回的例子。
下面的例子中main函数中的ret的值是不确定的,所以这种情况不能使用传引用返回。只能使用传值返回。
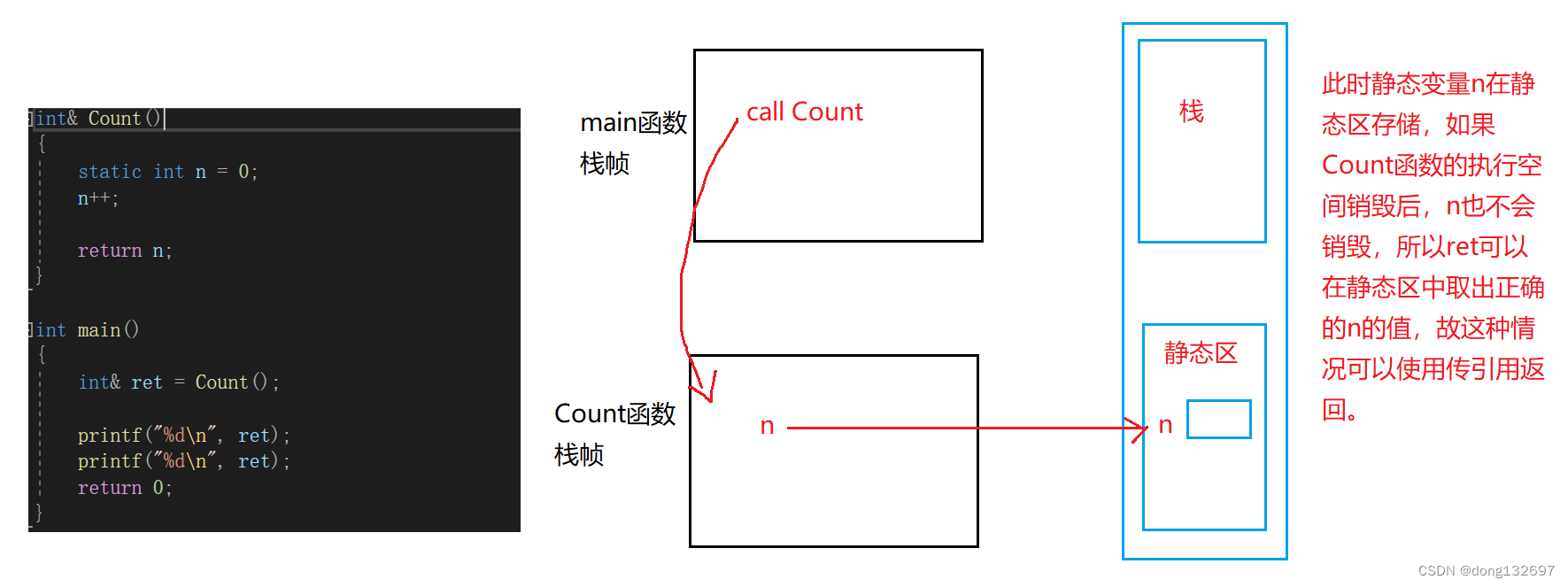
下面的例子中就可以使用传引用返回,因为返回值n在静态区中,Count函数执行时的空间被系统销毁后,n的值还在。所以当出了函数作用域,返回对象就销毁了时,那么一定不能用传引用返回,一定要用传值返回,只有在出了函数作用域后,返回对象还没有销毁的情况时才可以使用传引用返回。而传值返回不管什么情况都可以使用,因为传值返回会将返回值拷贝一份。传引用返回就是比传值返回少了一次返回值的拷贝。
知道了上面的知识后,我们又可以将以前写的关于顺序表的修改数据的函数改一下,改为传引用返回的函数。原来我们写的顺序表的修改数据的代码如下。
#include<assert.h>
#include<stdlib.h>
#include<stdio.h>
typedef int SLDataType;
typedef struct SeqList
{SLDataType* data; //指向动态开辟的数组。int size; //有效数据的个数int capacity; // 容量空间的大小
}SL;
void SLInit(SL* ps)
{assert(ps);SLDataType* tmp = (SLDataType*)calloc(4, sizeof(SLDataType)); //初始化时自动开辟4个空间if (tmp == NULL){perror("SLInit");exit(-1); //退出程序}ps->data = tmp;ps->size = 0;ps->capacity = 4;
}void SLCheckCapacity(SL* ps)
{assert(ps);if (ps->size == ps->capacity && ps->size != 0){SLDataType* tmp = (SLDataType*)realloc(ps->data, (2 * ps->capacity) * sizeof(SLDataType));if (tmp == NULL){perror("SLCheckCapacity");exit(-1);}ps->data = tmp;ps->capacity = ps->capacity * 2;}
}void SLPushBack(SL* ps, SLDataType x)
{assert(ps);SLCheckCapacity(ps); //先检查是否需要扩容ps->data[ps->size] = x; //插入数据ps->size++;
}void SLModify(SL* ps, int pos, SLDataType x)
{assert(ps && pos >= 0 && pos <= ps->size);ps->data[pos] = x;
}int main()
{SL s;SLInit(&s);SLPushBack(&s, 1);SLPushBack(&s, 2);SLPushBack(&s, 3);SLPushBack(&s, 4);SLModify(&s, 2, 6);return 0;
}
然后我们可以将SLModify函数改为一个传引用返回的函数,这样我们就可以根据返回的别名,来修改顺序表中元素的值。
#include<assert.h>
#include<stdlib.h>
#include<stdio.h>
#include<iostream>
using namespace std;
typedef int SLDataType;
typedef struct SeqList
{SLDataType* data; //指向动态开辟的数组。int size; //有效数据的个数int capacity; // 容量空间的大小
}SL;
void SLInit(SL& ps)
{assert(&ps);SLDataType* tmp = (SLDataType*)calloc(4, sizeof(SLDataType)); //初始化时自动开辟4个空间if (tmp == NULL){perror("SLInit");exit(-1); //退出程序}ps.data = tmp;ps.size = 0;ps.capacity = 4;
}void SLCheckCapacity(SL& ps)
{assert(&ps);if (ps.size == ps.capacity && ps.size != 0){SLDataType* tmp = (SLDataType*)realloc(ps.data, (2 * ps.capacity) * sizeof(SLDataType));if (tmp == NULL){perror("SLCheckCapacity");exit(-1);}ps.data = tmp;ps.capacity = ps.capacity * 2;}
}void SLPushBack(SL& ps, SLDataType x)
{assert(&ps);SLCheckCapacity(ps); //先检查是否需要扩容ps.data[ps.size] = x; //插入数据ps.size++;
}int& SLModify(SL& ps, int pos)
{assert(&ps && pos >= 0 && pos <= ps.size);return ps.data[pos];
}int main()
{SL s;SLInit(s);SLPushBack(s, 1);SLPushBack(s, 2);SLPushBack(s, 3);SLPushBack(s, 4);for (int i = 0; i < s.size; ++i){cout << SLModify(s, i) << " " ;}cout << endl;//此时返回的就是s.data[2]的别名,通过该别名就可以修改s.data[2]的值SLModify(s, 2)++;SLModify(s, 3) = 10;for (int i = 0; i < s.size; ++i){cout << SLModify(s, i) << " ";}cout << endl;//虽然也可以直接s.data[2]来修改,但是这个例子就是举例说明一下传引用返回的应用s.data[2]++;for (int i = 0; i < s.size; ++i){cout << SLModify(s, i) << " ";}cout << endl;return 0;
}
相关文章:
初识c++
文章目录 前言一、C命名空间1、命名空间2、命名空间定义 二、第一个c程序1、c的hello world2、std命名空间的使用惯例 三、C输入&输出1、c输入&输出 四、c中缺省参数1、缺省参数概念2、缺省参数分类3、缺省参数应用 五、c中函数重载1、函数重载概念2、函数重载应用 六、…...

【面试经典150题】跳跃游戏Ⅱ
题目链接 给定一个长度为 n 的 0 索引整数数组 nums。初始位置为 nums[0]。 每个元素 nums[i] 表示从索引 i 向前跳转的最大长度。换句话说,如果你在 nums[i] 处,你可以跳转到任意 nums[i j] 处: 0 < j < nums[i]i j < n 返回到达 nums[n…...

20230831-完成登录框的按钮操作,并在登录成功后进行界面跳转
登录框的按钮操作,并在登录成功后进行界面跳转 app.cpp #include "app.h" #include <cstdio> #include <QDebug> #include <QLineEdit> #include <QLabel> #include <QPainter> #include <QString> #include <Q…...

039 - sql逻辑操作符
前提: 做两个表employee和movie,用来练习使用; 表一:employee -- 创建表employee CREATE TABLE IF NOT EXISTS employee(id INT NOT NULL AUTO_INCREMENT,first_name VARCHAR(100) NOT NULL,last_name VARCHAR(100) NOT NULL,t…...

DbLInk使用
DbLInk介绍 DbLink是一种数据库连接技术,在不同的数据库之间进行数据传输和共享。它提供了一种透明的方法,让一个数据库访问另一个数据库的数据。 DbLink的优点是可以在多个数据库间实现数据共享,并且为不同数据库间的数据访问提供了便捷的…...

2.3 Vector 动态数组(迭代器)
C数据结构与算法 目录 本文前驱课程 1 C自学精简教程 目录(必读) 2 Vector<T> 动态数组(模板语法) 本文目标 1 熟悉迭代器设计模式; 2 实现数组的迭代器; 3 基于迭代器的容器遍历; 迭代器语法介绍 对迭…...
【ES6】Proxy的高级用法,实现一个生成各种 DOM 节点的通用函数dom
下面的例子则是利用get拦截,实现一个生成各种 DOM 节点的通用函数dom。 <body> </body><script>const dom new Proxy({}, {get(target, property) {return function(attrs {}, ...children) {const el document.createElement(property);for …...

气象站是什么设备?功能是什么?
气象站是一种用于测量和记录气象数据的设备。它通常是由各种传感器及其数据传输设备、固定设备和供电设备组成,可以测量风速、风向、温度、湿度、气压、降水量等气象要素,并将这些数据记录下来,以便进一步分析和研究。 气象站通常设置在广阔…...

227. 基本计算器 II Python
文章目录 一、题目描述示例 1示例 2示例 3 二、代码三、解题思路 一、题目描述 给你一个字符串表达式 s ,请你实现一个基本计算器来计算并返回它的值。 整数除法仅保留整数部分。 你可以假设给定的表达式总是有效的。所有中间结果将在 [-2^31, 2^31 - 1]的范围内…...

python中字典常用函数
字典常用函数 cmp(dict1,dict2) (已删除,直接用>,<,即可) 如果两个字典的元素相同返回0,如果字典dict1大于字典dict2返回1,如果字典dict1小于字典dict2返回-1。 先比较字典的长度,然后比较键&#x…...

leetcode88合并两个有序数组
题目: 给你两个按 非递减顺序 排列的整数数组 nums1 和 nums2,另有两个整数 m 和 n ,分别表示 nums1 和 nums2 中的元素数目。 请你 合并 nums2 到 nums1 中,使合并后的数组同样按 非递减顺序 排列。 注意:最终&…...

Ceph入门到精通-Nginx 大量请求 延迟优化
优化nginx以处理大量请求并减少延迟可以通过以下几种方法实现: 调整worker_processes和worker_connections参数:增加worker_processes值可以增加nginx的进程数量,提高并发处理能力。增加worker_connections参数的值可以增加每个worker进程可…...

Vulnstack----5、ATTCK红队评估实战靶场五
文章目录 一 环境搭建二 外网渗透三 内网信息收集3.1 本机信息收集3.2 域内信息收集 四 横向移动4.1 路由转发和代理通道4.2 抓取域用户密码4.3 使用Psexec登录域控4.4 3389远程登录 五、痕迹清理 一 环境搭建 1、项目地址 http://vulnstack.qiyuanxuetang.net/vuln/detail/7/ …...

QT 5.8
QT与Qt Creator,前者是框架,类似与MFC,而后者是QT的编译器,也可以使用Visual studio编辑,编译需要其他的 Index of /new_archive/qt/5.8/5.8.0...
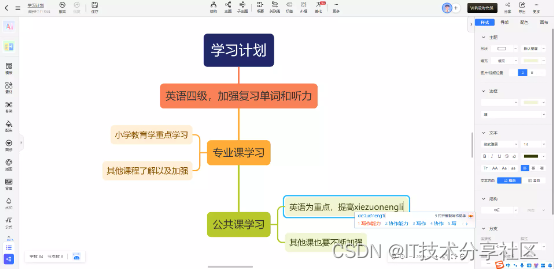
AIGC+思维导图:提升你的学习与工作效率的「神器」
目录 一、产品简介 二、功能介绍 2.1 AI一句话生成思维导图 2.2百万模版免费用 2.3分屏视图,一屏读写 2.4团队空间,多人协作 2.5 云端跨平台化 2.6 免费够用,会员功能更强大 2.7 支持多种格式的导入导出 三、使用教程 3.1 使用AI…...
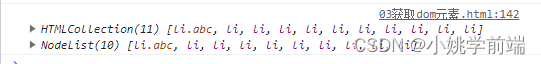
javaScript:DOM元素的获取(静态/动态获取)
目录 一.dom元素获取的意义与使用场景 使用场景(绝大多数js操作都需要dom操作) 总结/疑问解答! 二.DOM元素获取的常用方法(重点) 获取dom元素(动态) document.gerElementbyId() docume…...
数据结构前言
一、什么是数据结构? 数据结构是计算机存储、组织数据的方式。数据结构是指相互之间存在一种或多种特定关系的数据元素的集合。 上面是百度百科的定义,通俗的来讲数据结构就是数据元素集合与数据元素集合或者数据元素与数据元素之间的组成形式。 举个…...

Docker基于alpine带glibc的小型容器image
由于程序是C写的,gc编译,找了几个容器,生成比较小的是debianslim和ubuntu,生成后的大小分别为88MB,和91MB,还是太大了,于是想起一些小型容器如busybox或者alpine自己装glibc,但是试了…...
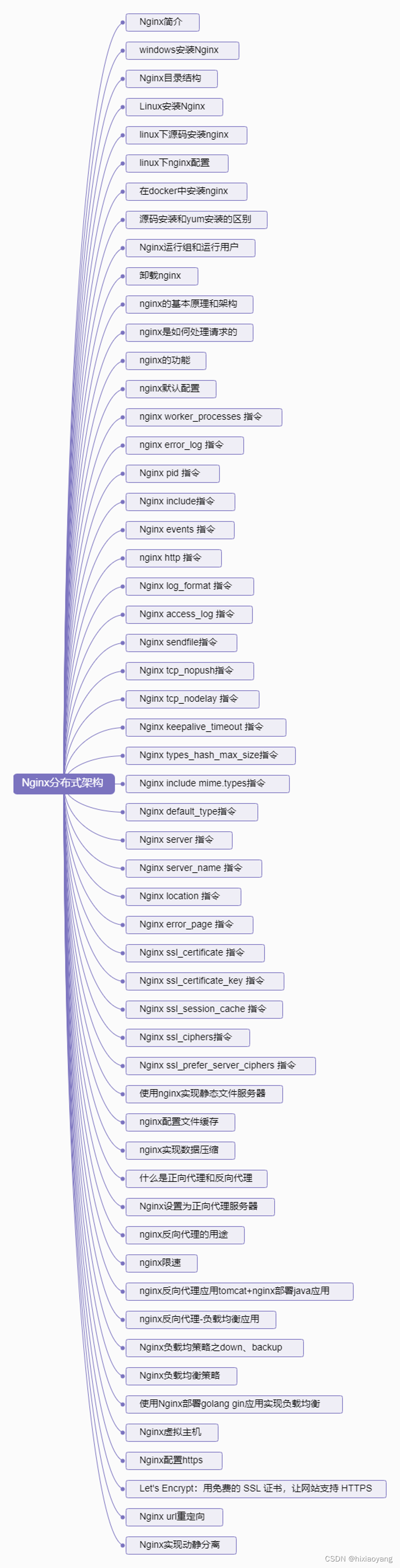
Nginx教程
Nginx教程 01-Nginx简介02-windows安装Nginx03-Nginx目录结构04-Linux安装Nginx05-linux下源码安装nginx06-linux下nginx配置07-在docker中安装nginx08-源码安装和yum安装的区别09-Nginx运行组和运行用户10-卸载nginx11-nginx的基本原理和架构12-nginx是如何处理请求的13-nginx…...

直播预约|哪吒汽车岳文强:OEM和Tier1如何有效对接网络安全需求
信息安全是一个防护市场。如果数字化程度低,数据量不够,对外接口少,攻击成本高,所获利益少,自然就没有什么攻击,车厂因此也不需要在防护上花费太多成本。所以此前尽管说得热闹,但并没有太多真实…...

解锁本科论文高效创作新思路,okbiye 赋能毕业生轻松完成学术撰稿
okbiye-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPT毕业论文 - Okbiye智能写作https://www.okbiye.com/ai/bylw 引言 步入毕业季,本科阶段最后的学术考核毕业论文,成为众多应届学子面前最大的难题。从前期选题构思、框架梳理&…...

告别Mac NTFS读写限制:免费开源的终极解决方案
告别Mac NTFS读写限制:免费开源的终极解决方案 【免费下载链接】Free-NTFS-for-Mac Nigate: An open-source NTFS utility for Mac. It supports all Mac models (Intel and Apple Silicon), providing full read-write access, mounting, and management for NTFS …...

大数据之安装zookeeper
下载 官方下载地址:https://archive.apache.org/dist/zookeeper/ 解压 tar -zxvf zookeeper-3.4.13.tar.gz 创建目录 日志目录和数据目录 cd zookeeper-3.4.13/ # 数据目录 mkdir data # 数据目录的目录 mkdir data-log # 日志目录 mkdir logs 修改配置 日志…...
)
【佛山大学主办,土木与交通学院承办 | 施普林格Springer系列出版 | EI、Scopus检索 | 另期刊论文征稿】第九届结构工程与工业建筑国际学术会议(ICSEIA 2026)
第九届结构工程与工业建筑国际学术会议(ICSEIA 2026) 2026 9th International Conference on Structural Engineering and Industrial Architecture 2026年7月3-5日 中国佛山 大会官网:www.icseia.com【论文投稿】 截稿时间:…...

FF14副本动画跳过插件终极指南:3分钟告别冗长等待
FF14副本动画跳过插件终极指南:3分钟告别冗长等待 【免费下载链接】FFXIV_ACT_CutsceneSkip 项目地址: https://gitcode.com/gh_mirrors/ff/FFXIV_ACT_CutsceneSkip 你是否曾在《最终幻想14》国服副本中,看着那些无法跳过的动画感到无比焦虑&…...

fpga开发过程中遇到的一些小问题
vivado开发过程中的一些error1、[Chipscope 16-213] The debug port u_ila_0/probe13 has 28 unconnected channels (bits). This will cause errors during implementation.2、ERROR: [Labtools 27-3312] Data read from hw_ila [hw_ila_1] is corrupted. Unable to upload wa…...

LangChain4j-examples:基于Java的AI智能体工作流编排深度解析与实践指南
LangChain4j-examples:基于Java的AI智能体工作流编排深度解析与实践指南 【免费下载链接】langchain4j-examples 项目地址: https://gitcode.com/GitHub_Trending/la/langchain4j-examples LangChain4j-examples是一个面向Java开发者的AI智能体工作流编排框…...

Vivado/DC中set_max_delay的另类用法:搞定异步FIFO等CDC路径的“半时序检查”
Vivado/DC中set_max_delay的工程艺术:异步FIFO时序约束的第三种策略 在数字电路设计中,异步时钟域(CDC)路径的处理一直是工程师们面临的棘手问题。传统做法往往陷入非黑即白的极端——要么完全忽略时序检查(set_false_…...

VSLAM与VIO技术解析:从3D建图到重定位的工程实践
1. 项目概述:从传感器融合到环境认知的跨越在机器人、自动驾驶和增强现实这些前沿领域,让机器“看见”并“理解”它所处的三维世界,是赋予其自主行动能力的基石。这背后,视觉SLAM(Simultaneous Localization and Mappi…...

燃油车的“催命符”还是环保的“里程碑”?2026年Euro 7标准下的汽车变局
如果你正打算换车,或者对汽车行业的未来走向充满好奇,那么“Euro 7”(欧7排放标准)绝对是你绕不开的一个关键词。这项被业内称为“史上最严”的排放法规,将于2026年11月29日正式对新车型实施强制认证。它不仅给内燃机戴…...