CNN详细讲解
CNN(Convolutional Neural Network)
本文主要来讲解卷积神经网络。所讲解的思路借鉴的是李宏毅老师的课程。
CNN,它是专门被用在影像上的。
Image Classification
我们从影像分类开始说起。
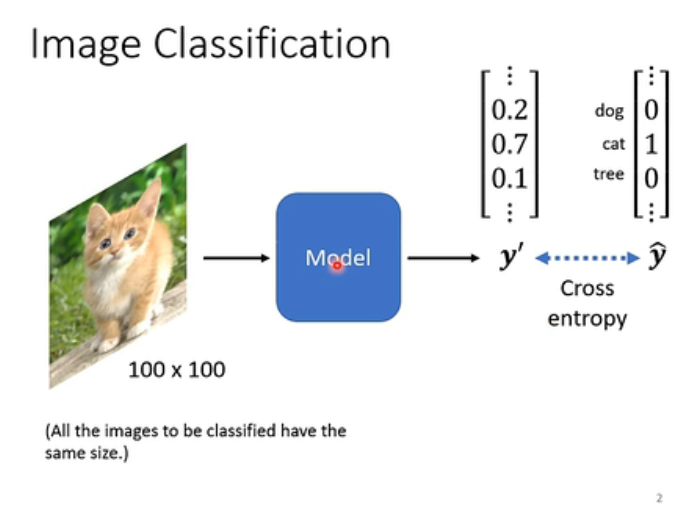
我们举例来说,它固定的输入大小是100*100的解析度(假设不会出现大小不同的照片,实际上即使大小不同,我们也可以把它变成一样大小的),然后丢到一个Model里面。我们的目标是对图像进行分类。最后输出的是一个one-hot的vector,那么这个向量的长度,就决定了你可以辨识出多少不同种类的东西(如下图)。
那么,你的Model可能会输出一个 y ′ y' y′,那我们就想要我们的 y ′ y' y′和 y ^ \hat{y} y^之间的Cross-entrpy越小越好。
那么接下来的问题就是,我们怎么样把这个图片输入到这个Model里。
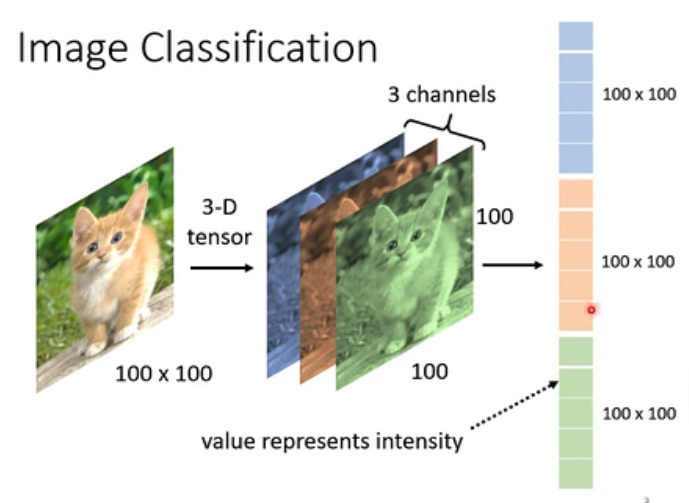
那么一张影响,对于电脑来说,就是一个三维的Tensor,分别代表图片的长、宽和通道数(即我们所说的channel),那我们把这个三位的Tensor拉直,我们就可以直接丢到我们的Network里。也就是说(我们还是假设我们图片的像素是100*100的),我们的向量是3个100 * 100向量组合起来的(如下图)。然后每一维每个颜色的数值就代表的是当前位置该颜色的强度。
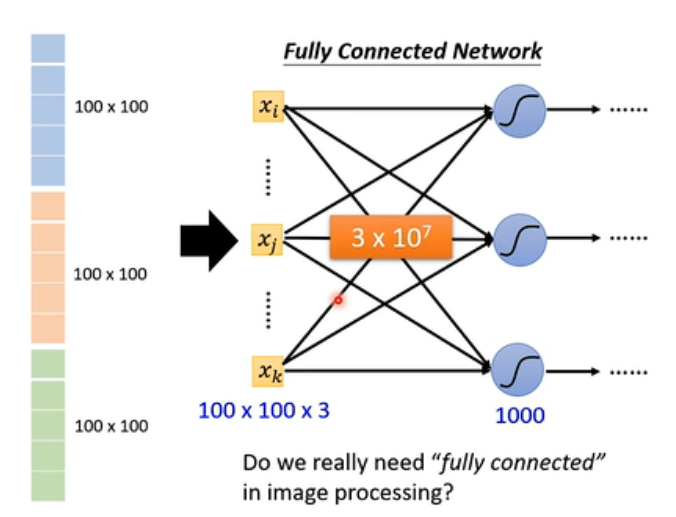
但是,问题显而易见了。如果说拉直之后,直接丢到fully connected neural里面,倘若中间第一层隐藏层有1000个神经元,那么现在在中间的这个变换矩阵中,就要有 3 ∗ 1 0 7 3*10^7 3∗107个元素。它是一个很大的数值了。我们说参数很多确实会增加模型的弹性,但是呢,它也增加了overfitting的风险。那我们有没有什么好的解决办法呢?
在影像这样特殊的问题上,我们会有特殊的方法。
我们可以先来观察:
观察点1:并不是图片的所有部分都需要一一去看

对于一个影像而言(比如说一个鸟,如上图),我们的神经网络怎么样才会知道它是一个鸟呢?也许说,某个神经元看到了一个鸟嘴,某个神经元看到了一个鸟眼,某个神经元又看到了一个鸟的爪子…那么就能够识别这是一只鸟了。你或许会觉得这样的方法好像很挫,但是,仔细想一想,似乎人类也是用这样的方法来去辨别这是一只鸟的吧。
所以,对于一张图片来说,我们不需要看到它一整个完全的部分,我们只需要能看到某些关键的部分,就能够辨识出这一个图片是什么东西。而这些关键的东西相对于一整个图像而言,通常就会小很多,那么我们Neural的复杂程度也就会小很多。
简化1:
通过这样一个观察,我们就能做这样的简化:
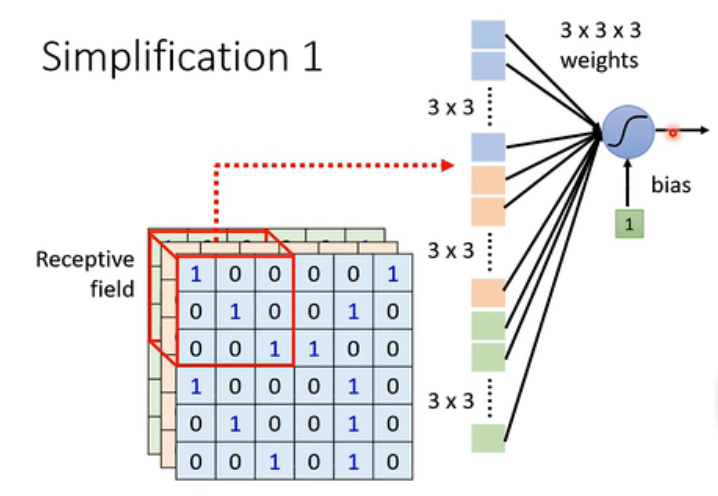
我们规定出一个Receptive field,它的大小呢可以随意(我们假设是3* 3 *3),然后,每一个neural都只关心自己的receptive field里面的东西就好了。即每一个receptive field都对应一个neural。
那这个neural怎么来考虑这个receptive field呢?我们的办法是把它拉直,就是三个3*3的向量,然后再将这3 * 3 * 3 = 27维的向量的每一个维度一个weight,然后再加上一个bias,将算出的结果输出到下一层当作输入。
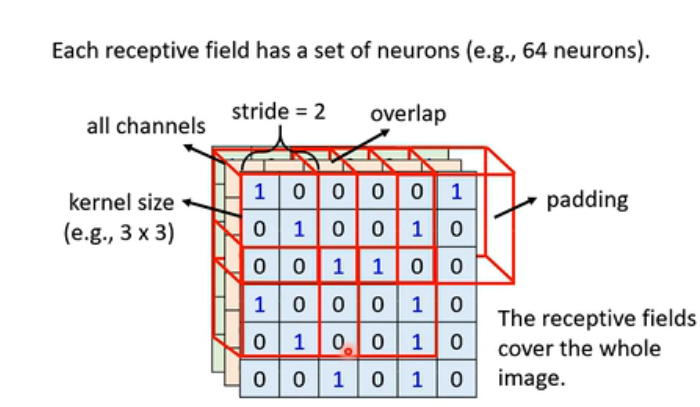
好,我们说每一个receptive field对应着一个neural,那这个receptive field是怎么定义出来的呢?答:这个是你自己来去决定的。包括它的大小,它的形状等等,并且,receptive field和receptive field之间还是可以重叠的,并且receptive field也可以仅考虑一些channel(就是不考虑三个,只考虑两个或者1个)。
不过虽然说你可以任意设计,但是还是要来说一说最经典的receptive field的设计方式(Typical Setting):
1、会看所有的channel。所以我们将receptive field的时候,就直接去讲它的高和宽就可以了。而高和宽合起来叫做kernel size(eg., 3*3)
2、每一个receptive field往往会有一组neuron(eg.,64)去和它对应。
3、stride(eg.,1,2),即你可以按照自己的意愿移动的receptive field的步长。
4、倘若receptive field超出了影像的范围,可以做padding(补值,比如补0,或者整张影像的平均值等)
5、扫过整张图片。
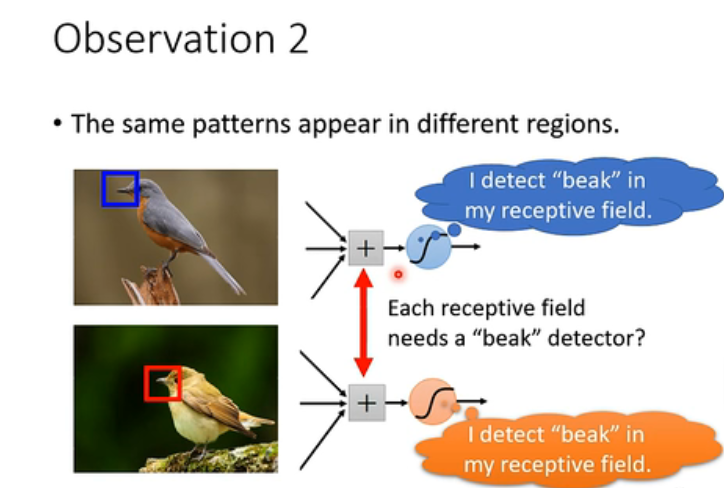
观察点2: 图片相同的样式可能出现在图片的不同的区域里
比如说我们刚刚上面说到的鸟嘴,在不同的图片里,它们都要去识别这个鸟嘴。那实际上它们做的事情是一样的,只不过它们随对应的范围是不一样的而已。但是,它们做的事情是一样的了,我们似乎就没有必要再搞两个功能相同的neural了,因为这就会造成冗余。
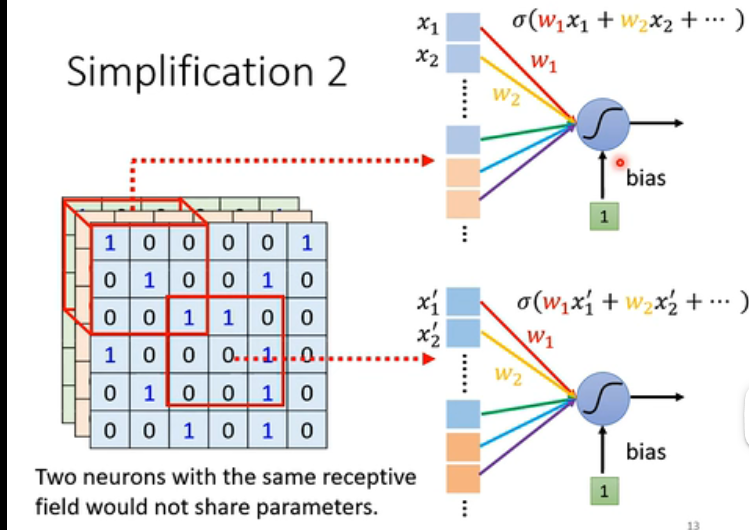
简化2:让不同的neural共享参数
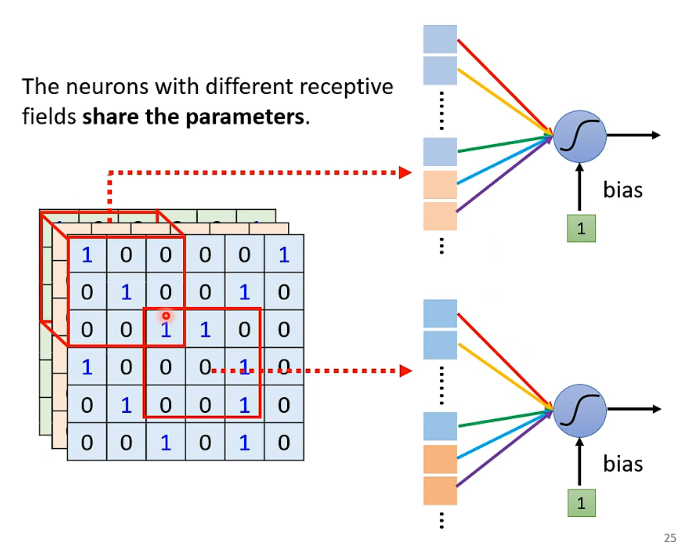
道理很简单。所谓共享参数,共享的是weight,也就是说,我们把下面的两个neural合并成一个,然后将它们的 w 1 w_1 w1、 w 2 w_2 w2…的参数共享。那么这个神经元所对应的范围就应当是下图中两部分的红色方框(即两个receptive field),怎么共享当然也可以大家自己来决定。
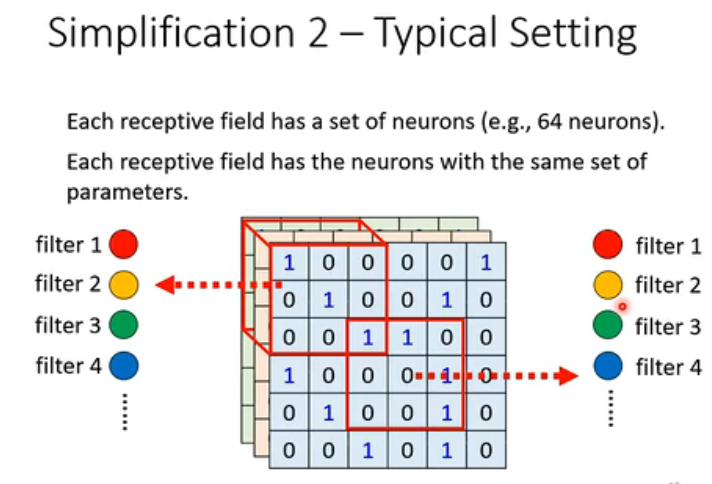
我们还是要来说一说常见的设置方法(即Typical Setting)
一个receptive field假设有64个neurons,那这些receptive field如果共享一组参数,也就是下方的两组神经元一一对应(实际上合并成了一个),红色和红色相对应合并,黄色和黄色相对应合并…
那,我们就称第一组参数为filter 1,第二组参数filter 2,第三组参数为filter 3…
我们来整理一下我们刚刚都说了些什么:
我们说,Fully-Conneected network是弹性最大的,但我们说我们只需要去看图像中重要关键的部分就可以了,所以我们就有了receptive field;然后呢,我们又说因为图片中有些特征在不同的地方实际上是相同的,所以我们又加上了Parameter Sharing,即参数共享。那receptive field加上Parameter sharing,就是Convolutional Layer(如下图)
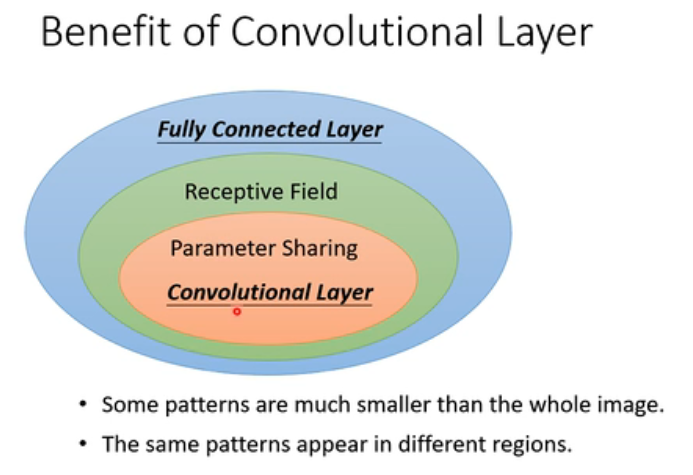
大家需要注意的是,刚刚说的这些特征都是在图像问题上才会被更好地使用,倘若所使用的范围不说图像,那就需要判断说它有没有我们刚刚所说到的这些特征。如果没有,那么它可能不适合用Convolutional Layer。
另一种介绍方式
这一种方式也是常见的介绍CNN的方式,但和刚刚我们上面所说到的意思是一样的(就是同一个东西用不同的方法介绍而已):
我们说,什么是Convolutional Layer呢?
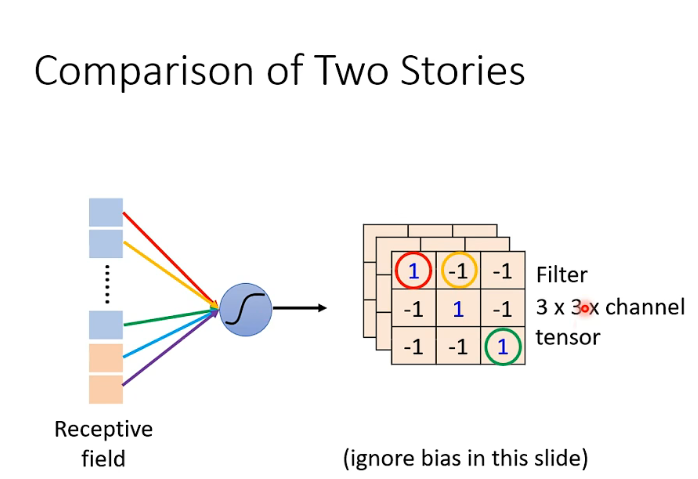
这个Layer它有数个的Filter,每一个Filter都是3* 3 * channel大小的tensor
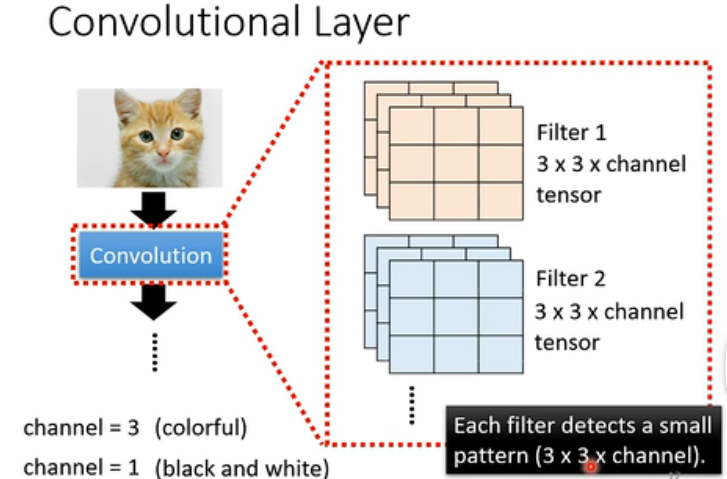
那channel数如果为3,就代表着这个图片是彩色的,如果channel数为1,就代表这个图片是黑白的。
每一个filter,就代表了它要识别的Pattern,或者说要守备的范围。
那这些filter是怎么样从图片当中抓Pattern的呢?我们来举几个例子:
我们假设现在channel = 1,然后filter里面的数值都是已知的(实际上是未知的,也就是需要通过梯度下降来去求解的,但我们为了方便观察其是怎么工作的,我们就假设它已经找出来了)
其实过程很简单,我们就让这个Filter 1和这个矩阵的左上角(3*3,和Filter一样大)相乘(将矩阵中对应的元素直接相乘,然后再相加),如下图中,经过计算得到3;然后再把这个矩形框向右移动(因为我们这里假设了Stride = 1),重复同样的操作即可。
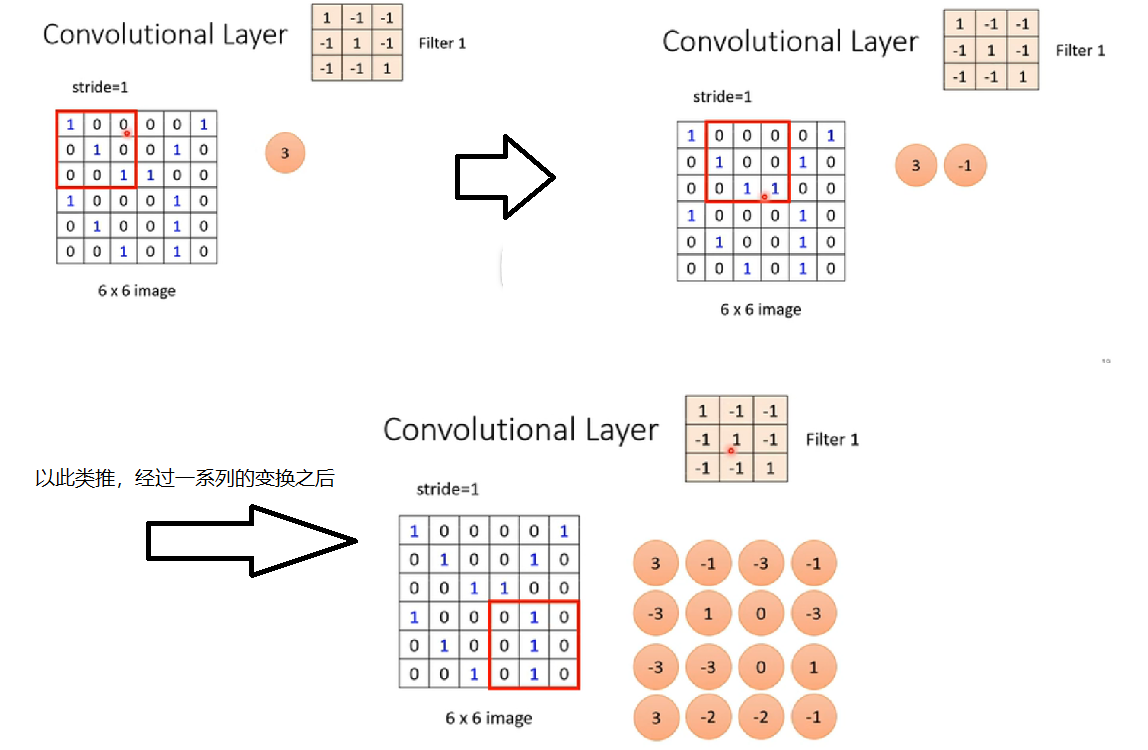
然后第二个、第三个(如果有)Filter就同理了,对每一个Filter也都进行相同的操作就可以了。
例如,我们下面也将Filter 2进行同样的操作,又得到一组数值。
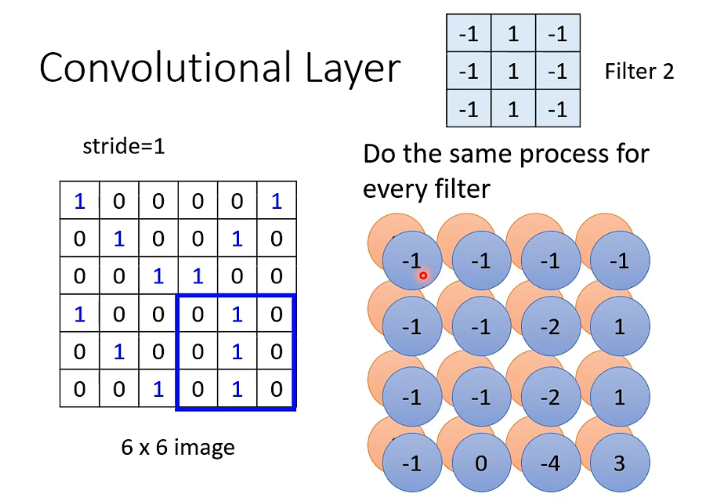
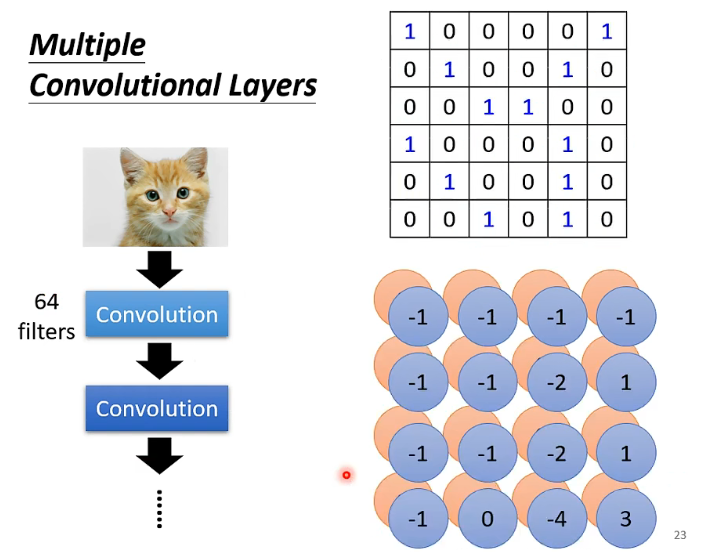
那假如说我有64个这个的Filter,那就是有64群这个的数据。那经过Filter算出来的这些数呢,它们也有自己的名字,叫做Feature Map
那如果是多层的卷积神经网络,如下图所示,如果说,我们总共有64个Filter,假设本身它的channel数是1,那结合我们上面的分析得知,经过第一层卷积层之后,它会有64张二维的图像叠在一起。所以,它的通道数就变成了64,即channel = 64。
那么,第一个卷积层它们得到的结果,我们也可以看成是一个图像。只不过,它的通道数是64。那接下来在第二层上的Filter的深度就是64
那现在有一个问题,就是如果我们一直让我们的Filter 是3*3,会不会让我们的图像难以识别较大范围的Pattern呢?其实想一想,如果按照这样一种方式下去,它的不会的。因为可以设想一下,在第二次的卷积层一个3 *3的话,对应在第一层卷积层上应该是5 * 5,对应到原图像上就会是7 * 7。那如果我们继续往下叠卷积层,就是说我如果把卷积层弄得再多一点,那最终同样是一个Filter,对应到原图像上就会更加宽广。
对比这两种方式
实际上,这两种方式是一模一样的。我们在第一种方式里讲解的共享参数,就是第二种方式里Filter的计算。只不过呢,在第二种方式里没有Bias。不过其实用第二种方式也可以是有Bias的,只不过我们刚刚没有提到,忽略掉了。
那我们说的Share the parameters,就是把一整个图片扫一遍,也就是我们在第一种方式里说的不同的receptive field。把全部图片扫一遍的这个过程,实际上就是叫做Convolution。
发现三:Pooling
我们会发现,Subsamlping并不会改变图像中的物体
举例来说,你把一个图像中偶数的Column都拿掉,奇数的Row都拿掉,那么你最后的图片是原来的 1 4 \frac{1}{4} 41,但是不会影响图片里面是什么东西。也就是把原来的图片给缩小了。

这个Pooling它没有要learn的东西的,就是说,它就只是一个Operator,它的行为都是固定好的,没有要和Data去互动的东西。
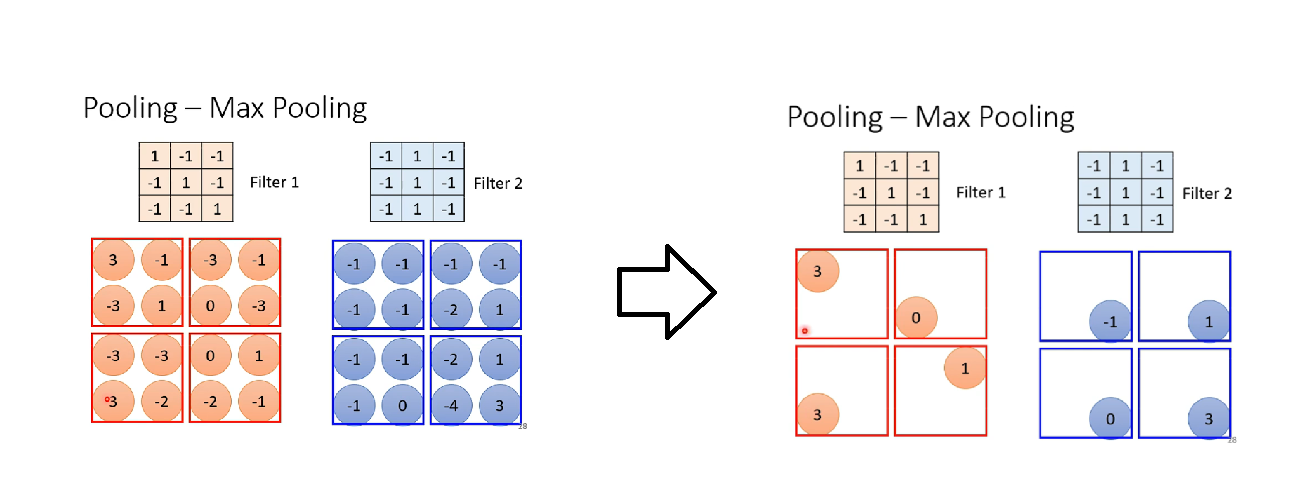
Pooling实际上也有很多不同的版本啦。比如Max Pooing。
举例来说,Max Pooling,我们把最后得到的图像,2 * 2一组且分开,然后每组留下最大的数。
留下谁是你自己决定的,因为是MaxPooling,所以你就留下最大的数,那如果是MinPooling,那就留下最小的数。也不一定是要2 * 2一组,你也可以3 * 3一组。就是说,这些都很灵活的。
然后,我们在实际的运作中,往往是先经过Convolution提取特征,然后再经过Pooling,再Pooling的过程中,Channel数是不变的。
然后,一般往往会重复Convolution和Pooling这样的一组操作。
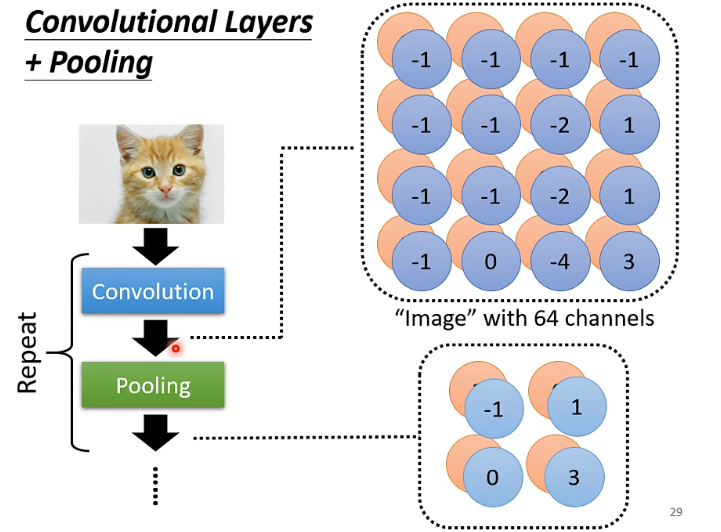
不过由于Pooling可能对你的图像还是会有比较大的损害的,所以近年来,随着算力资源的不断增强(Pooling的存在也就是为了简化计算的,本质上也是在提取特征),往往很多人都会选择Convoltion从头到底。这样,可以最大限度地保留图片的关键信息不受破坏。
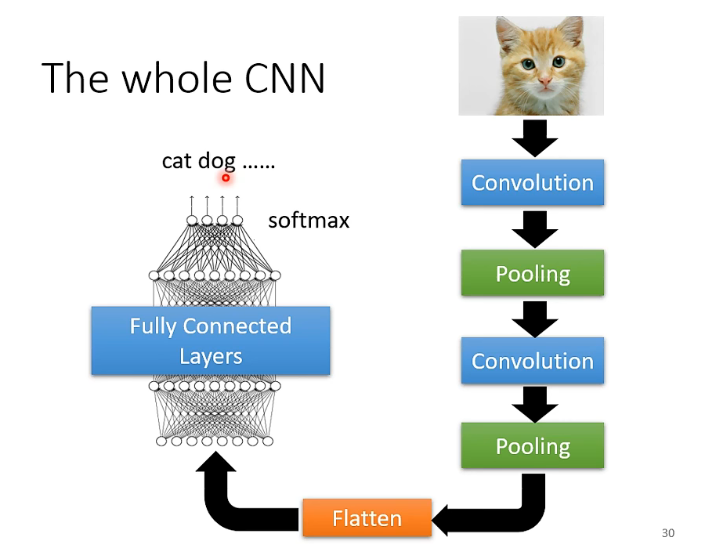
那么对于一整个CNN而言,在经过若干个Convolution和Pooling之后,会将得到的矩阵Flatten,字面意思是扁平化,就是拉直。然后把它丢到Fully connected Layers里面,最后再经过softmax的操作,就得到的分类的结果。
voltion从头到底。这样,可以最大限度地保留图片的关键信息不受破坏。
那么对于一整个CNN而言,在经过若干个Convolution和Pooling之后,会将得到的矩阵Flatten,字面意思是扁平化,就是拉直。然后把它丢到Fully connected Layers里面,最后再经过softmax的操作,就得到的分类的结果。
相关文章:
CNN详细讲解
CNN(Convolutional Neural Network) 本文主要来讲解卷积神经网络。所讲解的思路借鉴的是李宏毅老师的课程。 CNN,它是专门被用在影像上的。 Image Classification 我们从影像分类开始说起。 我们举例来说,它固定的输入大小是100*100的解析度&#x…...
pdf怎么编辑文字?了解一下这几种编辑方法
pdf怎么编辑文字?PDF文件的普及使得它成为了一个重要的文件格式。然而,由于PDF文件的特性,它们不可直接编辑,这就使得PDF文件的修改变得比较麻烦。但是,不用担心,接下来这篇文章就给大家介绍几种编辑pdf文字…...
MASM32编程状态栏显示字符动画,按钮跑马灯
一、需求分析 由于sysInfo扫描的内容比较多,打算为它增加一点动画效果,提醒用户程序正在运行,耐心等待。 二、构建测试窗口 测试窗口上放置有一个按钮,按钮上的初始文字是“开始扫描”;并使用状态栏,状态…...
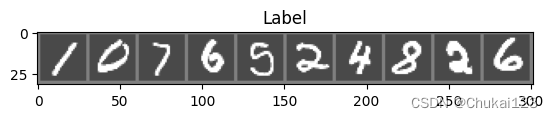
Pytorch-以数字识别更好地入门深度学习
目录 一、数据介绍 二、下载数据 三、可视化数据 四、模型构建 五、模型训练 六、模型预测 一、数据介绍 MNIST数据集是深度学习入门的经典案例,因为它具有以下优点: 1. 数据量小,计算速度快。MNIST数据集包含60000个训练样本和1000…...
微服务--服务介绍
Spring Cloud实现对比 Spring Cloud 作为一套标准,实现不一样 Spring Cloud AlibabaSpring Cloud NetflixSpring Cloud 官方Spring Cloud Zookeeper分布式配置Nacos ConficArchaiusSpring Cloud ConfigZookeeper服务注册/发现Nacos DiscoveryEureka--Zookeeper服务…...

自定义线程池-初识
自定义线程池-初步了解 创建一个固定大小的线程池 在Java中,你可以通过自定义线程池并指定线程的名称来实现你的需求。下面是一个简单的示例,展示了如何创建一个固定大小的线程池,并给每个线程指定一个名称: import java.util.…...
低代码平台:IVX 重新定义编程
目录 🍬一、写在前面 🍬二、低代码平台是什么 🍬三、为什么程序员和技术管理者不太可能接受“低代码”平台? 🍭1、不安全(锁定特性) 🍭2、不信任 🍬四、IVX低代码平台 &a…...

Android之自定义时间选择弹框
文章目录 前言一、效果图二、实现步骤1.自定义Dialog2.xml布局3.背景白色转角drawable4.取消按钮背景drawable5.确定按钮背景drawable6.NumberPicker样式和弹框样式7.弹框动画8.Activity使用 总结 前言 随着产品人员不断变态下,总是会要求我们的界面高大上…...

异地容灾系统和数据仓库系统设计和体系结构
( 1)生产系统数据同步到异地容灾系统 生产系统与异地容灾系统之间是通过百兆网连接的;生产系统的数据库是 Oracle 9i RAC,总的数据量大约为 3 TB,涉及五千多张表。对这些表进行分析归 类,发现容灾系统真正…...

【pytest】tep环境变量、fixtures、用例三者之间的关系
tep是一款测试工具,在pytest测试框架基础上集成了第三方包,提供项目脚手架,帮助以写Python代码方式,快速实现自动化项目落地。 在tep项目中,自动化测试用例都是放到tests目录下的,每个.py文件相互独立&…...
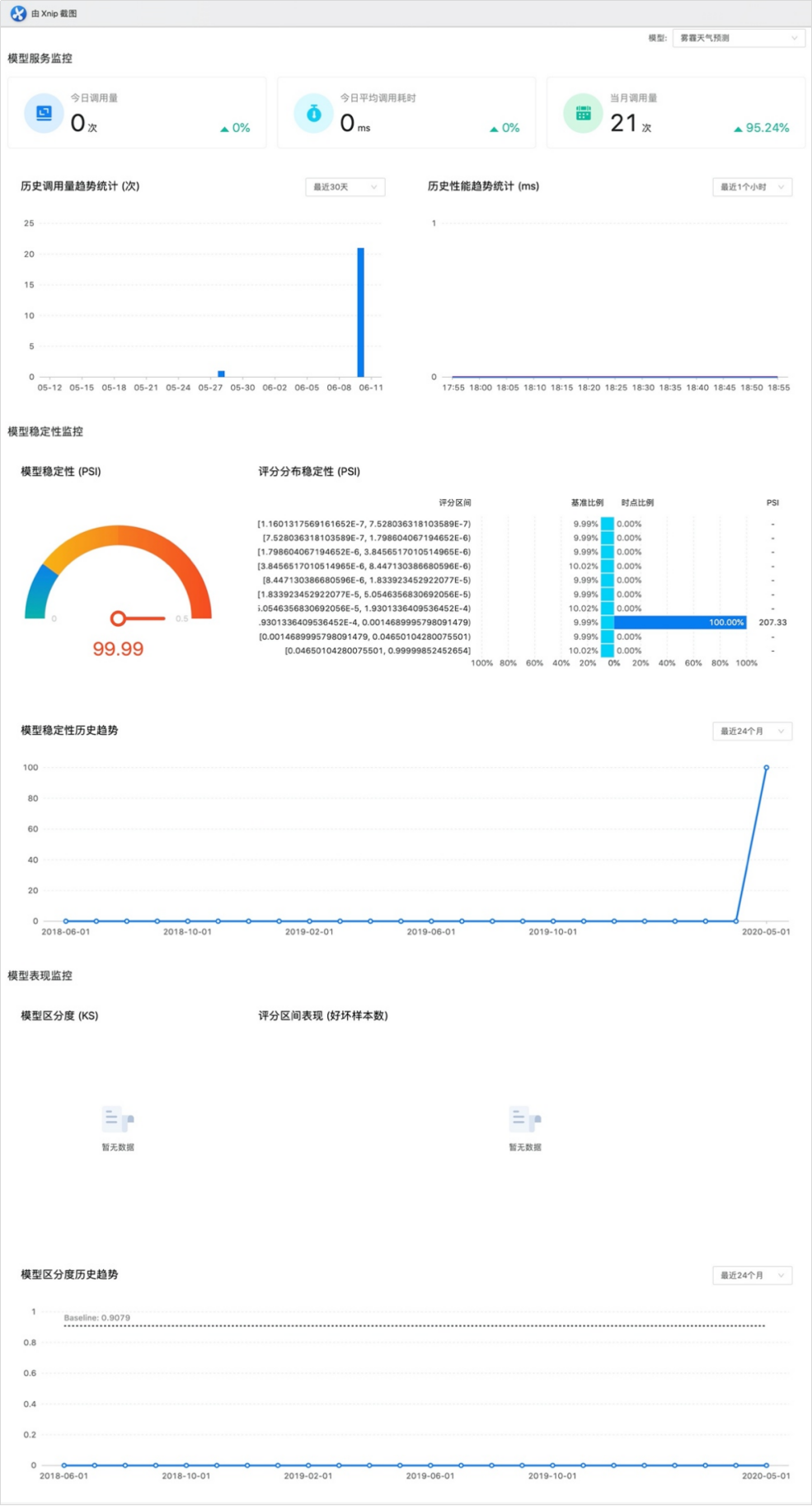
风控引擎如何快速添加模型,并实时了解运行状态?
目录 风控模型的主要类型 风控引擎如何管理模型? 模型就是基于目标群体的大规模采样数据,挖掘出某个实际问题或客观事物的现象本质及运行规律,利用抽象的概念分析存在问题或风险,计算推演出减轻、防范问题或风险的对策过程&…...

一文读懂|内核顺序锁
Linux 内核有非常多的锁机制,如:自旋锁、读写锁、信号量和 RCU 锁等。本文介绍一种和读写锁比较相似的锁机制:顺序锁(seqlock)。 顺序锁与读写锁一样,都是针对多读少写且快速处理的锁机制。而顺序锁和读写…...

openproject在docker下的安装
官方指引:https://www.openproject.org/docs/installation-and-operations/installation/docker/ 网友指引:https://blog.csdn.net/joefive/article/details/119409550 建个自己的数据文件夹: sudo mkdir -p /var/lib/openproject/{mydata…...
React【React是什么?、创建项目 、React组件化、 JSX语法、条件渲染、列表渲染、事件处理】(一)
文章目录 React是什么? 为什么要学习React React开发前准备 创建React项目 React项目结构简介 React组件化 初识JSX 渲染JSX描述的页面 JSX语法 JSX的Class与Style属性 JSX生成的React元素 条件渲染(一) 条件渲染 ࿰…...
Ubuntu系统下配置 Qt Creator 输入中文、配置软件源的服务器地址、修改Ubuntu系统时间
上篇介绍了Ubuntu系统下搭建QtCreator开发环境。我们可以发现安装好的QtCreator不能输入中文,也没有中文输入法供选择,这里需要进行设置。 文章目录 1. 配置软件源的服务器地址2. 先配置Ubuntu系统语言,设置为中文3. 安装Fcitx插件ÿ…...

Ab3d.PowerToys 11.0.8614 Crack
版本 11.0.8614 修补程序 使用 MouseCameraController 移动相机时防止旋转 FreeCamera。 版本 11.0.8585 重大更改:由于专利问题删除了 ViewCubeCameraController - 请联系支持人员以获取更多信息以及如果您想继续使用此控件。添加了 CameraNavigationCircles 控件…...
汽车3D HMI图形引擎选型指南【2023】
推荐:用 NSDT编辑器 快速搭建可编程3D场景 2002年,电影《少数派报告》让观众深入了解未来。 除了情节的核心道德困境之外,大多数人都对它的技术着迷。 我们看到了自动驾驶汽车、个性化广告和用户可以无缝交互的 3D 计算机界面。 令人惊讶的是…...
Stable Diffusion stable-diffusion-webui开发笔记
https://lexica.art/ lexica.art 该网站拥有数百万Stable Diffusion案例的文字描述和图片,可以为大家提供足够的创作灵感。可以提供promt灵感 https://civitai.com/ Civitai是一个聚集AI绘图爱好者的社区,在此网站上有许多定制化的模型,特…...
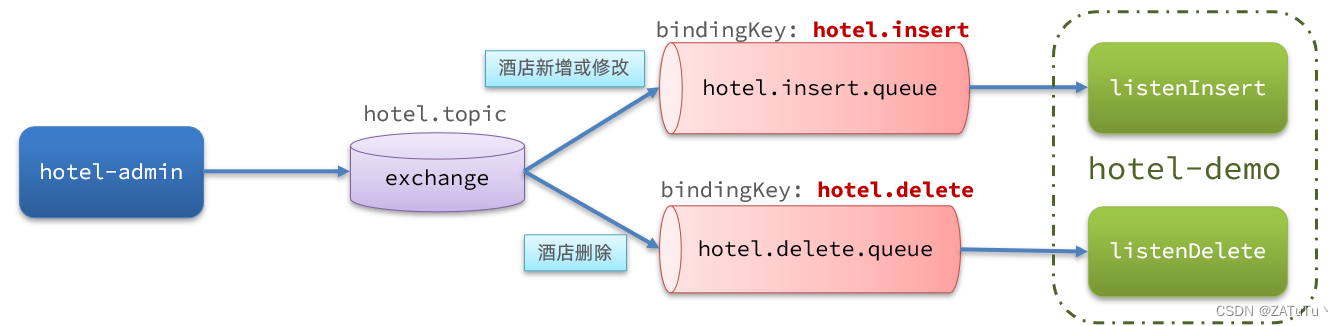
利用MQ实现mysql与elasticsearch数据同步
流程 1.声明exchange、queue、RoutingKey 2. 在hotel-admin中进行增删改(SQL),完成消息发送 3. 在hotel-demo中完成消息监听,并更新elasticsearch数据 4. 测试同步 1.引入依赖 <!--amqp--> <dependency><groupId&…...
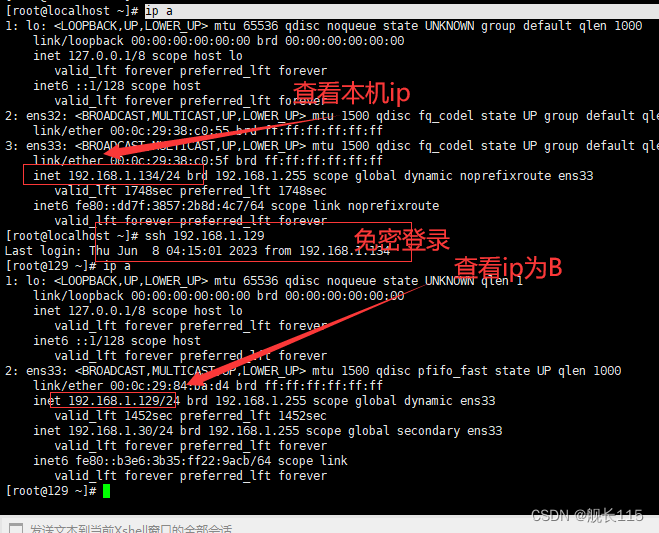
linux免密登录最简单--图文详解
最简单的免密登录 1.A电脑生成秘钥 ssh-keygen -t rsa 2.A电脑将秘钥传给B电脑 ssh-copy-id root192.168.1.129 #将秘钥直接传给B电脑 需要输入B电脑的密码,可以看到成功。 3.测试 同理:如果B->A也需要免密登录,统一的操作。 大功告…...

别再乱设Public了!Minio权限控制实战:从用户、分组到自定义策略的完整配置流程
别再乱设Public了!Minio权限控制实战:从用户、分组到自定义策略的完整配置流程 在分布式存储系统的日常运维中,权限配置不当引发的数据泄露事件屡见不鲜。最近某科技公司因对象存储桶误设为公开访问,导致数万份客户资料暴露的案例…...

N_m3u8DL-RE:终极跨平台流媒体下载工具,轻松保存加密视频内容
N_m3u8DL-RE:终极跨平台流媒体下载工具,轻松保存加密视频内容 【免费下载链接】N_m3u8DL-RE Cross-Platform, modern and powerful stream downloader for MPD/M3U8/ISM. English/简体中文/繁體中文. 项目地址: https://gitcode.com/GitHub_Trending/…...

NCMconverter终极指南:3步轻松解密NCM音频,实现全平台播放自由 [特殊字符]
NCMconverter终极指南:3步轻松解密NCM音频,实现全平台播放自由 🎵 【免费下载链接】NCMconverter NCMconverter将ncm文件转换为mp3或者flac文件 项目地址: https://gitcode.com/gh_mirrors/nc/NCMconverter 你是否遇到过从音乐平台下载…...

SAP PP实战指南:从零到一掌握BOM创建、群组BOM配置与CS01核心操作
1. BOM基础概念与核心价值 物料清单(Bill of Materials,简称BOM)是制造业的DNA图谱,它用结构化数据描述产品从原材料到成品的完整演化路径。我第一次接触SAP PP模块时,项目经理指着屏幕上的BOM结构说:"…...

OpenPnP玩家必看:深度解析松下DP102传感器与贴片机真空系统的联动原理与调优
OpenPnP系统集成实战:DP102负压传感器与真空控制回路的科学调优 在DIY贴片机的世界里,OpenPnP系统就像一位不知疲倦的指挥家,而DP102负压传感器则是这支精密乐队中的关键乐手。当吸嘴与元器件相遇的瞬间,背后是一场由气压数据驱动…...

【亲测免费】 提升数据传输效率:AccessDatabaseEngine_X64 2010 安装包推荐
提升数据传输效率:AccessDatabaseEngine_X64 2010 安装包推荐 【下载地址】AccessDatabaseEngine_X642010安装包 本仓库提供了一个名为 AccessDatabaseEngine_X64_2010.rar 的资源文件下载。该文件是 Microsoft Access 2010 数据库引擎的可再发行程序包,…...

茉莉花插件:终极Zotero中文文献管理解决方案
茉莉花插件:终极Zotero中文文献管理解决方案 【免费下载链接】jasminum A Zotero add-on to retrive CNKI meta data. 一个简单的Zotero 插件,用于识别中文元数据 项目地址: https://gitcode.com/gh_mirrors/ja/jasminum 还在为Zotero处理中文文献…...

Midscene.js:3大技术突破解决跨平台UI自动化的核心痛点
Midscene.js:3大技术突破解决跨平台UI自动化的核心痛点 【免费下载链接】midscene AI-powered, vision-driven UI automation for every platform. 项目地址: https://gitcode.com/GitHub_Trending/mid/midscene 在当今多平台应用爆发的时代,你是…...

模糊PID vs 传统PID:用Simulink仿真对比直流电机控制,结果差距有多大?
模糊PID与传统PID的直流电机控制擂台赛:Simulink仿真深度解析 在工业自动化领域,直流电机控制一直是工程师们关注的焦点。面对复杂的工况变化,传统PID控制器虽然结构简单、易于实现,但在非线性、时变系统中往往表现不佳。而模糊PI…...

NAS如何变身创作利器?基于绿联DX4600 Pro自建图床与Typora无缝协作
1. 为什么选择NAS自建图床? 作为一名长期使用Markdown写作的内容创作者,我深知图片管理的重要性。过去三年我先后尝试过七牛云、又拍云等第三方图床服务,虽然费用不高(每月约5-10元),但经常遇到两个致命问题…...