MySQL索引篇
文章目录
- 说明:
- 索引篇
- 一、索引常见面试题
- 按数据结构
- 按物理存储分类
- 按字段特性分类
- 按字段个数分类
- 索引缺点:
- 什么时候适用索引?
- 什么时候不需要创建索引?
- 常见优化索引的方法:
- 发生索引失效的情况:
- 二、从数据页角度看B+树
- 三、为什么 MySQL 采用 B+ 树作为索引?
- 四、单表不要超过2000W行,一般靠谱
- 五、索引失效有哪些?
- 六、MySQL 使用 like “%x“,索引一定会失效吗?
- 七、 count(*) 和 count(1) 有什么区别?哪个性能最好?
说明:
此类文章是为小林coding的图解MySQL,所简写,目的在于大家更快抓到小林文章的重点
本文全部由我简化,但是其中有部分引用小林的文章内容
希望大家掌握精髓,构建知识体系和知识框架
索引篇
一、索引常见面试题
- 索引底层使用了什么数据结构和算法?
- 为什么 MySQL InnoDB 选择 B+tree 作为索引的数据结构?
- 什么时候适用索引?
- 什么时候不需要创建索引?
- 什么情况下索引会失效?
- 有什么优化索引的方法?
索引分类
按数据结构
- 按「数据结构」分类:B+tree索引、Hash索引、Full-text索引。
- 按「物理存储」分类:聚簇索引(主键索引)、二级索引(辅助索引)。
- 按「字段特性」分类:主键索引、唯一索引、普通索引、前缀索引。
- 按「字段个数」分类:单列索引、联合索引。
InnoDB存储引擎,B+Tree索引类型,优势:查询效率高,查询一个数据的磁盘I/O依然维持在3-4次
1、B+Tree vs B Tree
B+Tree 的单个节点的数据量更小(只在叶子节点存储数据,而…),在相同的磁盘 I/O 次数下,就能查询更多的节点。
B+Tree 叶子节点采用的是双链表连接,适合 MySQL 中常见的基于范围的顺序查找
2、B+Tree vs 二叉树
搜索复杂度为O(logdN)(节点允许的最大子节点个数为 d 个),也就是说一次数据查询操作只需要做 3~4 次的磁盘 I/O 操作就能查询到目标数据,
所经历的磁盘I/O次数
3、B+Tree vs Hash
Hash 在做等值查询的时候效率贼快,搜索复杂度为 O(1),但不适合做范围查询
-
主键索引的 B+Tree 的叶子节点存放的是实际数据,所有完整的用户记录都存放在主键索引的 B+Tree 的叶子节点里;
-
二级索引的 B+Tree 的叶子节点存放的是主键值,而不是实际数据。
按物理存储分类
**覆盖索引:**在查询时使用了二级索引,如果查询的数据能在二级索引里查询的到,那么就不需要回表,这个过程就是覆盖索引
**回表:**如果查询的数据不在二级索引里,就会先检索二级索引,找到对应的叶子节点,获取到主键值后,然后再检索主键索引,就能查询到数据了,这个过程就是回表
按字段特性分类
PRIMARY KEY (index_column_1) USING BTREE # 主键索引
UNIQUE KEY(index_column_1,index_column_2,...) # 唯一索引
# 建表后,如果要创建唯一索引
CREATE UNIQUE INDEX index_name
ON table_name(index_column_1,index_column_2,...);
# 普通索引
INDEX(index_column_1,index_column_2,...)
# 前缀索引
column_list,
INDEX(column_name(length))
# 建表后,如果要创建前缀索引
CREATE INDEX index_name
ON table_name(column_name(length));
按字段个数分类
- 建立在单列上的索引称为单列索引,比如主键索引;
- 建立在多列上的索引称为联合索引;
使用联合索引时,存在最左匹配原则
CREATE INDEX index_product_no_name ON product(product_no, name);
索引缺点:
- 需要占用物理空间,数量越大,占用空间越大;
- 创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增大;
- 会降低表的增删改的效率,因为每次增删改索引,B+ 树为了维护索引有序性,都需要进行动态维护。
什么时候适用索引?
- 字段有唯一性限制的;
- 经常用于
WHERE查询条件的字段,这样能够提高整个表的查询速度,如果查询条件不是一个字段,可以建立联合索引。 - 经常用于
GROUP BY和ORDER BY的字段,这样在查询的时候就不需要再去做一次排序了,因为我们都已经知道了建立索引之后在 B+Tree 中的记录都是排序好的
什么时候不需要创建索引?
WHERE条件,GROUP BY,ORDER BY里用不到的字段,索引的价值是快速定位,如果起不到定位的字段通常是不需要创建索引的,因为索引是会占用物理空间的。- 字段中存在大量重复数据,比如性别字段,只有男女
- 表数据太少的时候,不需要创建索引;
- 经常更新的字段不用创建索引,比如不要对电商项目的用户余额建立索引,因为索引字段频繁修改,由于要维护 B+Tree的有序性,那么就需要频繁的重建索引,这个过程是会影响数据库性能的。
常见优化索引的方法:
- 前缀索引优化;
为了减小索引字段大小
order by 就无法使用前缀索引;
无法把前缀索引用作覆盖索引; - 覆盖索引优化;
避免回表的操作
假设我们只需要查询商品的名称、价格
建立一个联合索引,即「商品ID、名称、价格」作为一个联合索引 - 主键索引最好是自增的;
如果我们使用自增主键,每次插入一条新记录,都是追加操作,不需要重新移动数据 - 防止索引失效;
索引最好设置为 NOT NULL,否则,优化器在做索引选择的时候更加复杂,更加难以优化,比如进行索引统计时,count 会省略值为NULL 的行
没意义的值,但是它会占用物理空间
发生索引失效的情况:
- 使用左或者左右模糊匹配的时候,也就是
like %xx或者like %xx%这两种方式都会造成索引失效; - 在查询条件中对索引列做了计算、函数、类型转换操作
- 联合索引要能正确使用需要遵循最左匹配原则,否则就会导致索引失效。
- 在 WHERE 子句中, 索引列 OR 不是索引列
执行效率从低到高的顺序为:
- All(全表扫描);
- index(全索引扫描);
- range(索引范围扫描);
- ref(非唯一索引扫描);
- eq_ref(唯一索引扫描);
- const(结果只有一条的主键或唯一索引扫描)。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ujg5XLJz-1676948199446)(../my_images/索引总结.drawio.png)]](https://img-blog.csdnimg.cn/a7fa3d5a44d547699a8013790ae5ae89.png)
二、从数据页角度看B+树
B+树节点存放的是数据页
File Header 中有两个指针,双向的链表
采用链表的结构是让数据页之间不需要是物理上的连续的,而是逻辑上的连续。
User Records 是怎么组织数据的
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HrNpf9j5-1676948199447)(../my_images/243b1466779a9e107ae3ef0155604a17.png)]](https://img-blog.csdnimg.cn/0f68d61b094b4ab1ac999a69b6720917.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xbHnXC1h-1676948199447)(../my_images/fabd6dadd61a0aa342d7107213955a72.png)][外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9WNi0nlG-1676948199448)(../my_images/557d17e05ce90f18591c2305871af665.png)]](https://img-blog.csdnimg.cn/2d36e8ff089b46de858a411cd07da80c.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rG3JZRza-1676948199448)(../my_images/261011d237bec993821aa198b97ae8ce.png)]](https://img-blog.csdnimg.cn/65a4380e22ed456795899a1a9395ab37.png)

槽
- 第一个分组中的记录只能有 1 条记录;
- 最后一个分组中的记录条数范围只能在 1-8 条之间;
- 剩下的分组中记录条数范围只能在 4-8 条之间。

一张表只能有一个聚簇索引
小林总结:
nnoDB 的数据是按「数据页」为单位来读写的,默认数据页大小为 16 KB。每个数据页之间通过双向链表的形式组织起来,物理上不连续,但是逻辑上连续。
数据页内包含用户记录,每个记录之间用单向链表的方式组织起来,为了加快在数据页内高效查询记录,设计了一个页目录,页目录存储各个槽(分组),且主键值是有序的,于是可以通过二分查找法的方式进行检索从而提高效率。
为了高效查询记录所在的数据页,InnoDB 采用 b+ 树作为索引,每个节点都是一个数据页。
如果叶子节点存储的是实际数据的就是聚簇索引,一个表只能有一个聚簇索引;如果叶子节点存储的不是实际数据,而是主键值则就是二级索引,一个表中可以有多个二级索引。
在使用二级索引进行查找数据时,如果查询的数据能在二级索引找到,那么就是「索引覆盖」操作,如果查询的数据不在二级索引里,就需要先在二级索引找到主键值,需要去聚簇索引中获得数据行,这个过程就叫作「回表」。
三、为什么 MySQL 采用 B+ 树作为索引?
怎样的索引的数据结构是好的?
什么是二分查找?
什么是二分查找树?
什么是B树?
什么是B+树?
MySQL 的数据是持久化的,意味着数据(索引+记录)是保存到磁盘上的,断电,数据不丢失
内存的访问速度是纳秒级别的,磁盘访问的速度是毫秒级别的,磁盘慢上万倍
磁盘读写最小单位是扇区,52B,操作系统最小读写单位是块,linux块大小是4KB,一次磁盘I/O读写8个扇区
二叉查找树的特点是一个节点的左子树的所有节点都小于这个节点,右子树的所有节点都大于这个节点
问题1、当每次插入的元素都是二叉查找树中最大的元素,二叉查找树就会退化成了一条链表,查找数据的时间复杂度变成了 O(n)
问题2、高度是I/O次数,太高了,影响查询性能
问题3、不能范围查询
平衡二叉查找树(AVL 树)
问题1、只要是二叉树,高度都太高
B树
再限制一个节点就只能有 2 个子节点,而是允许 M 个子节点 (M>2),从而降低树的高度,简单说就是多叉树
问题1、每个节点都包含了索引+记录,数据要莫没用上,要莫就要花费更多磁盘I/O次数,
问题2、用来范围查询,需要用中序遍历,设计多个节点的磁盘I/O问题
B+ 树与 B 树差异的点,主要是以下这几点:
- 叶子节点(最底部的节点)才会存放实际数据(索引+记录),非叶子节点只会存放索引;
- 所有索引都会在叶子节点出现,叶子节点之间构成一个有序链表;
- 非叶子节点的索引也会同时存在在子节点中,并且是在子节点中所有索引的最大(或最小)。
- 非叶子节点中有多少个子节点,就有多少个索引;
下面通过三个方面,比较下 B+ 和 B 树的性能区别。
1、单点查询
节点存放索引,可以存放更多索引,可以比B树更加矮胖,查询磁盘I/O次数更少
2、插入和删除效率
删除一个节点,直接删除叶子节点,不用动非叶子节点,结构更稳定,删除更快
会自平衡,因为只涉及一条路径,不需要复杂的算法
3、范围查询
为啥不说等值查询呢,因为基本一样,而范围查询就不一样了
B+树叶子节点有双向链表连接
节点内容是数据页
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Kg8uoRmd-1676948199450)(../my_images/dd076212a7637b9032c97a615c39dcd7.png)]](https://img-blog.csdnimg.cn/bafe265eb15a4cf89de8b8127dd8c52c.png)
四、单表不要超过2000W行,一般靠谱
假设
- 非叶子节点内指向其他页的数量为 x
- 叶子节点内能容纳的数据行数为 y
- B+ 数的层数为 z
如下图中所示,Total =x^(z-1) *y 也就是说总数会等于 x 的 z-1 次方 与 Y 的乘积。
X =?
1k存标识,15k存数据,一条数据按12byte,x=15*1024/12≈1280 行
页和索引结构差不多,都会有 File Header (38 byte)、Page Header (56 Byte)、Infimum + Supermum(26 byte)、File Trailer(8byte), 再加上页目录,大概 1k 左右。
索引页中主要记录的是主键与页号,主键我们假设是 Bigint (8 byte), 而页号也是固定的(4Byte), 那么索引页中的一条数据也就是 12byte。
所以 x=15*1024/12≈1280 行。
Y=?
按一条行数据 1k 来算,那一页就能存下 15 条,Y = 15*1024/1000 ≈15。
-
假设 B+ 树是两层,那就是 z = 2, Total = (1280 ^1 )*15 = 19200
-
假设 B+ 树是三层,那就是 z = 3, Total = (1280 ^2) *15 = 24576000 (约 2.45kw)
-
我们刚刚在说 Y 的值时候假设的是 1K ,那比如我实际当行的数据占用空间不是 1K , 而是 5K, 那么单个数据页最多只能放下 3 条数据。
同样,还是按照 z = 3 的值来计算,那 Total = (1280 ^2) *3 = 4915200 (近 500w)
行数据大小不同,最大建议值不同
影响查询性能的还有很多其他因素,比如,数据库版本,服务器配置,sql 的编写等等
五、索引失效有哪些?
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-99sw1AsG-1676948199450)(../my_images/a9e6a9708a6dbbcc65906d1338d2ae70.png)]](https://img-blog.csdnimg.cn/bdfe97c345054a7bbea7092df28b2a54.png)
1、使用左模糊,|| 左右模糊
因为索引 B+ 树是按照「索引值」有序排列存储的,只能根据前缀进行比较。
2、对索引使用了函数
因为索引保存的是索引字段的原始值,而不是经过函数计算后的值,自然就没办法走索引了
从 MySQL 8.0 开始,索引特性增加了函数索引
3、对索引进行表达式计算
因为索引保存的是索引字段的原始值,而不是 id + 1 表达式计算后的值,所以无法走索引
4、对索引隐式类型转换
索引字段是字符串,但是输入的是整形
但是如果索引字段是整形,输入字段是字符串时候会用索引,因为会自动转化
MySQL 在遇到字符串和数字比较的时候,会自动把字符串转为数字,然后再进行比较。
5、联合索引非最左匹配
6、 WHERE 子句中的 OR
索引 OR 非索引字段,那么就是失效
六、MySQL 使用 like “%x“,索引一定会失效吗?
使用左模糊匹配(like “%xx”)并不一定会走全表扫描,关键还是看数据表中的字段。
数据库表中的字段只有主键+二级索引 == 全扫描二级索引树 type=index
如果数据库表中的字段都是索引的话,即使查询过程中,没有遵循最左匹配原则,也是走全扫描二级索引树(type=index)
七、 count(*) 和 count(1) 有什么区别?哪个性能最好?
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Rn3auBC5-1676948199451)(../my_images/af711033aa3423330d3a4bc6baeb9532.png)]](https://img-blog.csdnimg.cn/83f348e108c64d9b8e602b258c9e6ade.png)
count该函数作用是统计符合查询条件的记录中,函数指定的参数不为 NULL 的记录有多少个
count(1)、 count(*)、 count(主键字段)在执行的时候,如果表里存在二级索引,优化器就会选择二级索引进行扫描。尽量建立二级索引
count(字段) 来统计记录个数,效率最差,全表扫描
通常在没有任何查询条件下的 count(*),MyISAM 的查询速度要明显快于 InnoDB
MyISAM,只维护一个 row_count 变量
面对大表的记录统计,解决方法
1、近似值计算
使用 show table status 或者 explain 命令来表进行估算,像谷歌统计的
2、额外表保存计数值
当我们在数据表插入一条记录的同时,将计数表中的计数字段 + 1
新增和删除操作时,我们需要额外维护这个计数表。
相关文章:
MySQL索引篇
文章目录说明:索引篇一、索引常见面试题按数据结构按物理存储分类按字段特性分类按字段个数分类索引缺点:什么时候适用索引?什么时候不需要创建索引?常见优化索引的方法:发生索引失效的情况:二、从数据页角…...
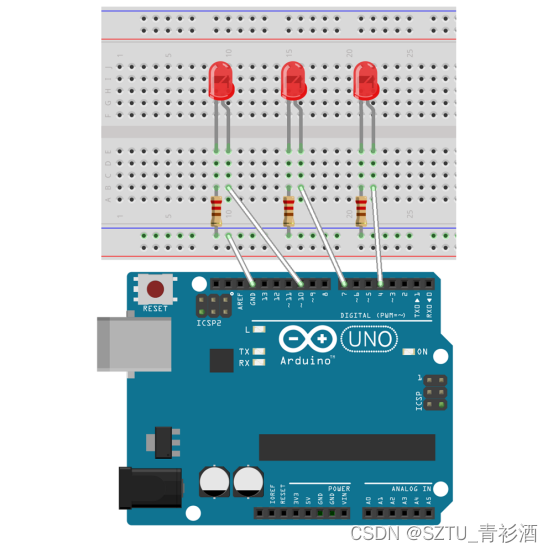
Ardiuno-交通灯
LED交通灯实验实验器件:■ 红色LED灯:1 个■ 黄色LED灯:1 个■ 绿色LED灯:1 个■ 220欧电阻:3 个■ 面包板:1 个■ 多彩杜邦线:若干实验连线1.将3个发光二极管插入面包板,2.用杜邦线…...

Leetcode.1234 替换子串得到平衡字符串
题目链接 Leetcode.1234 替换子串得到平衡字符串 Rating : 1878 题目描述 有一个只含有 Q, W, E, R四种字符,且长度为 n 的字符串。 假如在该字符串中,这四个字符都恰好出现 n/4次,那么它就是一个「平衡字符串」。 给你一个这样…...

聚类算法之K-means算法详解
文章目录 什么是聚类k-means算法简介牧师-村民模型算法步骤伪代码流程描述手动实现优缺点优点缺点算法调优与改进数据预处理合理选择 K 值手肘法Gap Statistic(间隔统计量)轮廓系数法(Silhouette Coefficient)Canopy算法拍脑袋法采用核函数K-means++ISODATA参考文献<...

电话呼入/呼出CSFB流程介绍
MO CSFB 注册的LAI跟SYS_INFO不同会触发LU流程;LU流程结束后,判断LOCATION UPDATING ACCEPT消息中的"Follow-on proceed"参数状态。(1)如果IE消息中有"Follow-on proceed",终端直接发送CM Service Request; (2)如果IE消息中没有"Follow-on procee…...

【比赛合集】9场可报名的「创新应用」、「程序设计」大奖赛,任君挑选!
CompHub 实时聚合多平台的数据类(Kaggle、天池…)和OJ类(Leetcode、牛客…)比赛。本账号同时会推送最新的比赛消息,欢迎关注!更多比赛信息见 CompHub主页 或 点击文末阅读原文以下信息仅供参考,以比赛官网为准目录创新应用赛&…...
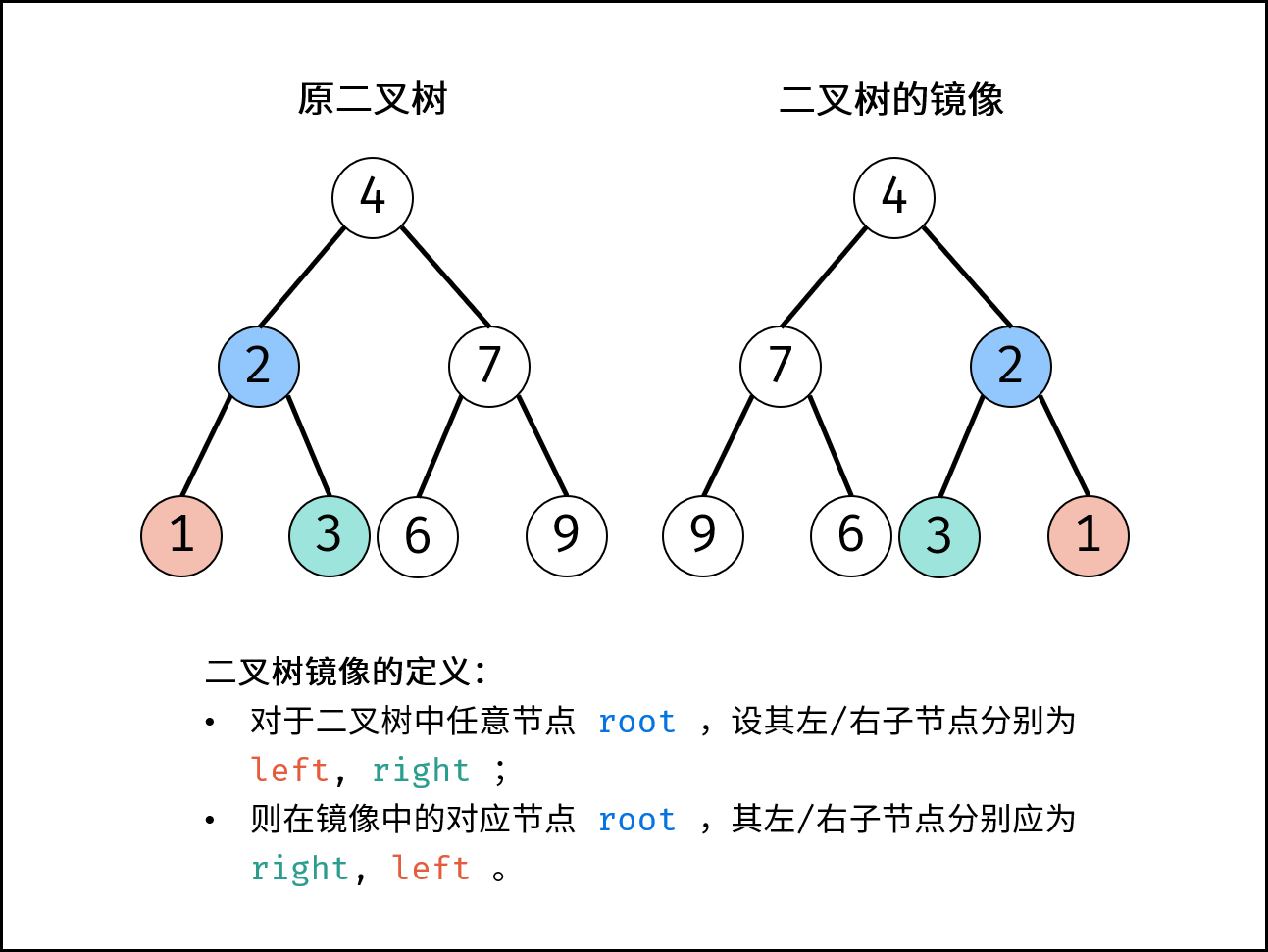
剑指 Offer 27. 二叉树的镜像
剑指 Offer 27. 二叉树的镜像 难度:easy\color{Green}{easy}easy 题目描述 请完成一个函数,输入一个二叉树,该函数输出它的镜像。 例如输入: 镜像输出: 示例 1: 输入:root [4,2,7,1,3,…...

RPC编程:RPC概述和架构演变
RPC编程系列文章第一篇一:引言1:本系列文章的目标2:RPC的概念二:架构的演变过程1:单体架构1):概念2):特点3):优缺点2:单体架构水平扩展1):水平拓展的含义2)&a…...

神经网络训练时只对指定的边更新参数
在神经网络中,通常采用反向传播算法来计算网络中各个参数的梯度,从而进行参数更新。在反向传播过程中,所有的参数都会被更新。因此,如果想要只更新指定的边,需要采用特殊的方法。 一种可能的方法是使用掩码࿰…...

Python列表list操作-遍历、查找、增加、删除、修改、排序
在使用列表的时候需要用到很多方法,例如遍历列表、查找元素、增加元素、删除元素、改变元素、插入元素、列表排序、逆序列表等操作。 1、遍历列表 遍历列表通常采用for循环的方式以及for循环和enumerate()函数搭配的方式去实现。 1ÿ…...

Python开发-学生管理系统
文章目录1、需求分析2、系统设计3、系统开发必备4、主函数设计5、 学生信息维护模块设计6、 查询/统计模块设计7、排序模块设计8、 项目打包1、需求分析 学生管理系统应具备的功能: ●添加学生及成绩信息 ●将学生信息保存到文件中 ●修改和删除学生信息 ●查询学生…...

大数据处理 - Trie树/数据库/倒排索引
Trie树Trie树的介绍和实现请参考 树 - 前缀树(Trie)适用范围: 数据量大,重复多,但是数据种类小可以放入内存基本原理及要点: 实现方式,节点孩子的表示方式扩展: 压缩实现。一些适用场景:寻找热门查询: 查询串的重复度比较高&#…...
jjava企业级开发-01
一、Spring容器演示 采用Spring配置文件管理Bean 1、创建Maven项目 修改项目的Maven配置 2、添加Spring依赖 在Maven仓库里查找Spring框架(https://mvnrepository.com) 同上添加其他依赖 <?xml version"1.0" encoding"UTF-8…...

「事务一致性」事务afterCommit
在事务还没有执行完消息就已经发出去了, 导致后续的一些数据或逻辑上的问题产生。场景如下:异步-记录日志:当事务提交后,再记录日志。发送mq消息:只有业务数据都存入表后,再发mq消息。方案1. 利用TransactionSynchroni…...
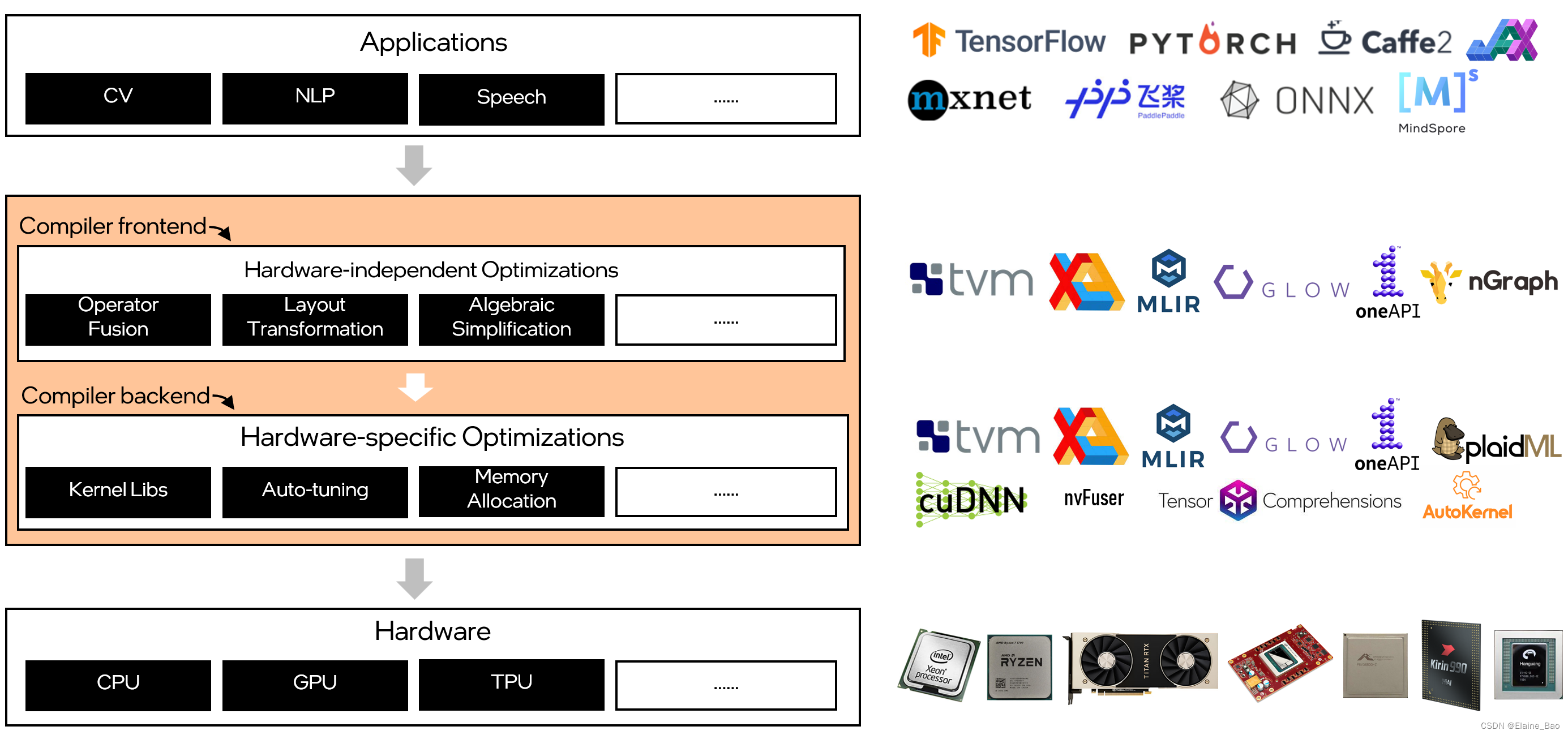
【深度学习编译器系列】2. 深度学习编译器的通用设计架构
在【深度学习编译器系列】1. 为什么需要深度学习编译器?中我们了解到了为什么需要深度学习编译器,和什么是深度学习编译器,接下来我们把深度学习编译器这个小黑盒打开,看看里面有什么东西。 1. 深度学习编译器的通用设计架构 与…...
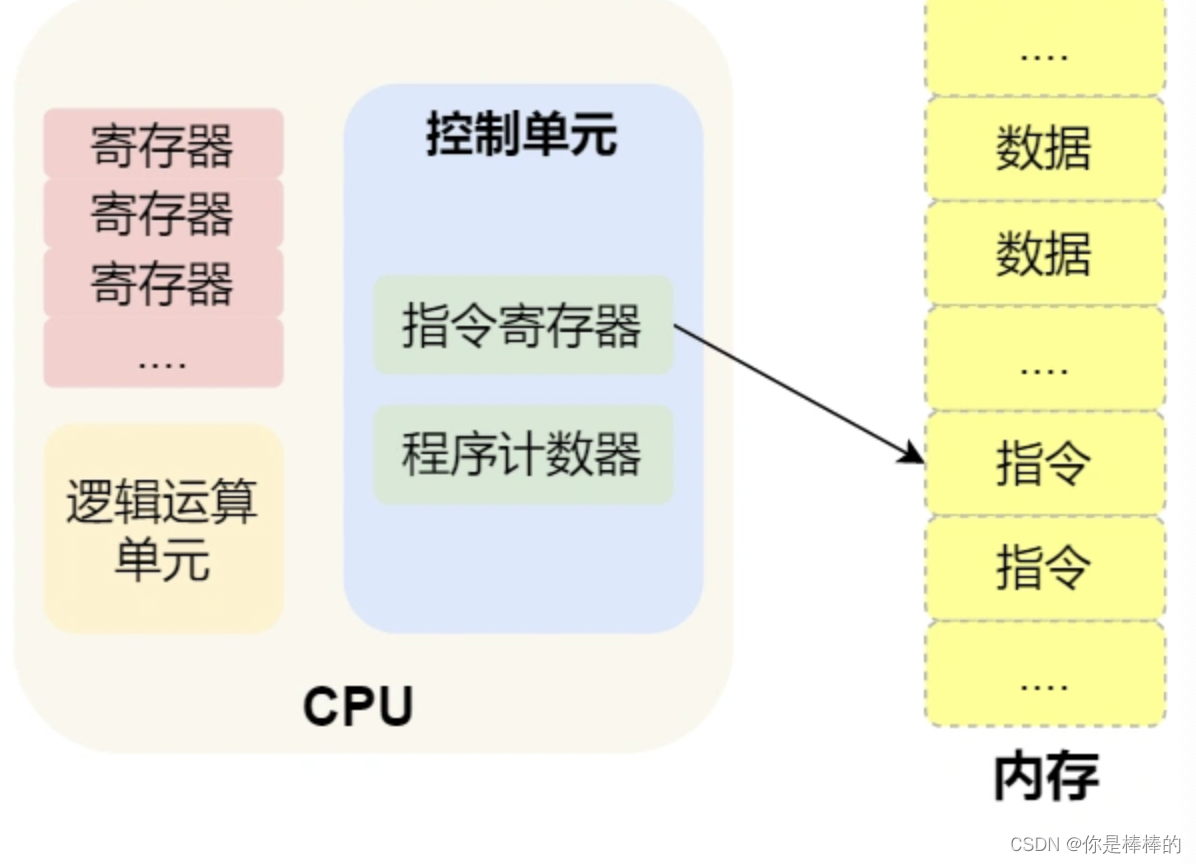
图解操作系统
硬件结构 CPU是如何执行程序的? 图灵机的工作方式 图灵机的基本思想:用机器来模拟人们用纸笔进行数学运算的过程,还定义了由计算机的那些部分组成,程序又是如何执行的。 图灵机的基本组成如下: 有一条「纸带」&am…...

【发版或上线项目保姆级心得】
第一步:先在正式环境创建数据库/新增表格或者字段 在数据库表中增加字段/表格,不会报错。 但是切记不要过早数据库字段/表格或者删除字段/表格 第二步:修改配置文件 先将正式环境需要的配置给写好,包括但不仅限于数据库配置、…...

Python数据分析-pandas库入门
pandas 库概述pandas 提供了快速便捷处理结构化数据的大量数据结构和函数。自从2010年出现以来,它助使 Python 成为强大而高效的数据分析环境。pandas使用最多的数据结构对象是 DataFrame,它是一个面向列(column-oriented)的二维表…...
MacBook Pro 恢复出厂设置
目录1.恢复出厂设置1.1 按Command-R 键1.2 macOS 实用工具1.3 从 macOS 恢复功能的实用工具窗口中选择“磁盘工具”,然后点按“继续”1.4 在“磁盘工具”边栏中选择您的设备或宗卷。1.5 点按“抹掉”按钮或标签页1.6 抹掉OS X HD - 数据 完成1.7 抹掉 OS X HD1.8 查…...

googletest 笔记
什么是一个好的测试 1 测试应该是独立的和可重复的。调试一个由于其他测试而成功或 失败的测试是一件痛苦的事情。googletest 通过在不同的对象上 运行测试来隔离测试。当测试失败时,googletest 允许您单独运 行它以快速调试。 2 测试应该很好地“组织”,…...

深圳实体门店有必要做GEO AI代运营吗
深圳实体门店有必要做GEO AI代运营吗一、开篇引言2026年深圳本地实体商业竞争进入白热化阶段,全城数百万家线下实体门店涵盖本地生活、家装工装、汽车服务、餐饮娱乐、教育培训等全品类,传统线下地推、门店自然客流、传统团购平台引流效果持续下滑&#…...

亚马逊 Rufus 关停,Alexa 正式上线:卖家必须读懂的6条新规则
2026年5月13日,亚马逊官方正式宣布,下线Rufus,推出全新AI购物助手:Alexa for Shopping。但是,这不是粗暴地直接下线 Rufus,而是一次购物AI底层架构的重组 —— 将 Rufus 的商品专长 与 Alexa的用户理解力&a…...

照着用就行:2026 最新降AIGC软件测评与推荐
2026年真正好用的AI论文降重与改写工具,核心看降重效果、去AI味、格式保留、学术适配四大指标。综合实测,千笔AI、ThouPen、豆包、DeepSeek、Grammarly 是当前最值得推荐的梯队,覆盖从免费到付费、从中文到英文、从文科到理工的全场景需求。 …...

CUDA并行计算与FSR框架优化实践
1. CUDA并行计算与FSR框架概述在GPU加速计算领域,CUDA(Compute Unified Device Architecture)作为NVIDIA推出的并行计算平台和编程模型,已经成为高性能计算的事实标准。其核心设计理念是将计算任务分解为网格(Grid&…...

3分钟告别英文恐惧:Android Studio中文界面轻松切换指南
3分钟告别英文恐惧:Android Studio中文界面轻松切换指南 【免费下载链接】AndroidStudioChineseLanguagePack AndroidStudio中文插件(官方修改版本) 项目地址: https://gitcode.com/gh_mirrors/an/AndroidStudioChineseLanguagePack 你是否曾经因…...

Facebook登录协议逆向解析:appsecret_proof与e2e加密机制
1. 这不是“爬虫教程”,而是一次对现代Web身份协议的解剖实验你有没有试过,在调试一个Facebook登录集成时,浏览器Network面板里突然冒出一串带sig、access_token、e2e、c_user的请求,参数长度动辄上千字符,加密方式五花…...

用Arduino改造TDA7010T FM收音机:数字调谐与自动搜台实战
1. 项目概述:当复古芯片遇上现代微控制器翻出抽屉角落里那个积灰的Kemo B156N套件时,我压根没想到它会变成一个如此有趣的周末项目。这个套件的核心,是一颗来自上世纪八十年代的FM收音机芯片——TDA7010T。当年,它和它的前身TDA70…...

告别手动分类!用Python+ArcPy批量处理DEM,一键生成坡度坡向等高线报告
用PythonArcPy实现DEM地形分析全自动化:从数据到报告的智能工作流 第一次接手山区风电项目的地形分析任务时,我花了整整三天时间在ArcGIS界面里反复点击同样的按钮——加载DEM、计算坡度坡向、生成等高线、调整分类阈值、导出图片。当第五个区域的报告终…...

Windows安卓子系统终极优化指南:如何通过WSABuilds实现完美Android体验
Windows安卓子系统终极优化指南:如何通过WSABuilds实现完美Android体验 【免费下载链接】WSABuilds Run Windows Subsystem For Android on your Windows 10 and Windows 11 PC using prebuilt binaries with Google Play Store (MindTheGapps) and/or Magisk or Ke…...

2026国安部重磅披露:境外间谍如何利用民用路由器构建窃密跳板?全链路技术解析与防御指南
一、引言:从"网速变慢"到国家级网络窃密 2026年5月20日,国家安全部官方微信公众号发布紧急通报,披露了一起严重的境外间谍情报机关网络窃密案件。与以往直接攻击政府或企业服务器不同,此次攻击者将目标锁定在了最容易被…...