ElasticSearch进阶
一、 search检索文档
ES支持两种基本方式检索;
- 通过REST request uri 发送搜索参数 (uri +检索参数);
- 通过REST request body 来发送它们(uri+请求体);
1、信息检索
API: https://www.elastic.co/guide/en/elasticsearch/reference/7.x/getting-started-search.html
请求参数方式检索
GET bank/_search?q=*&sort=account_number:asc
说明:
q=* # 查询所有
sort # 排序字段
asc #升序检索bank下所有信息,包括type和docs
GET bank/_search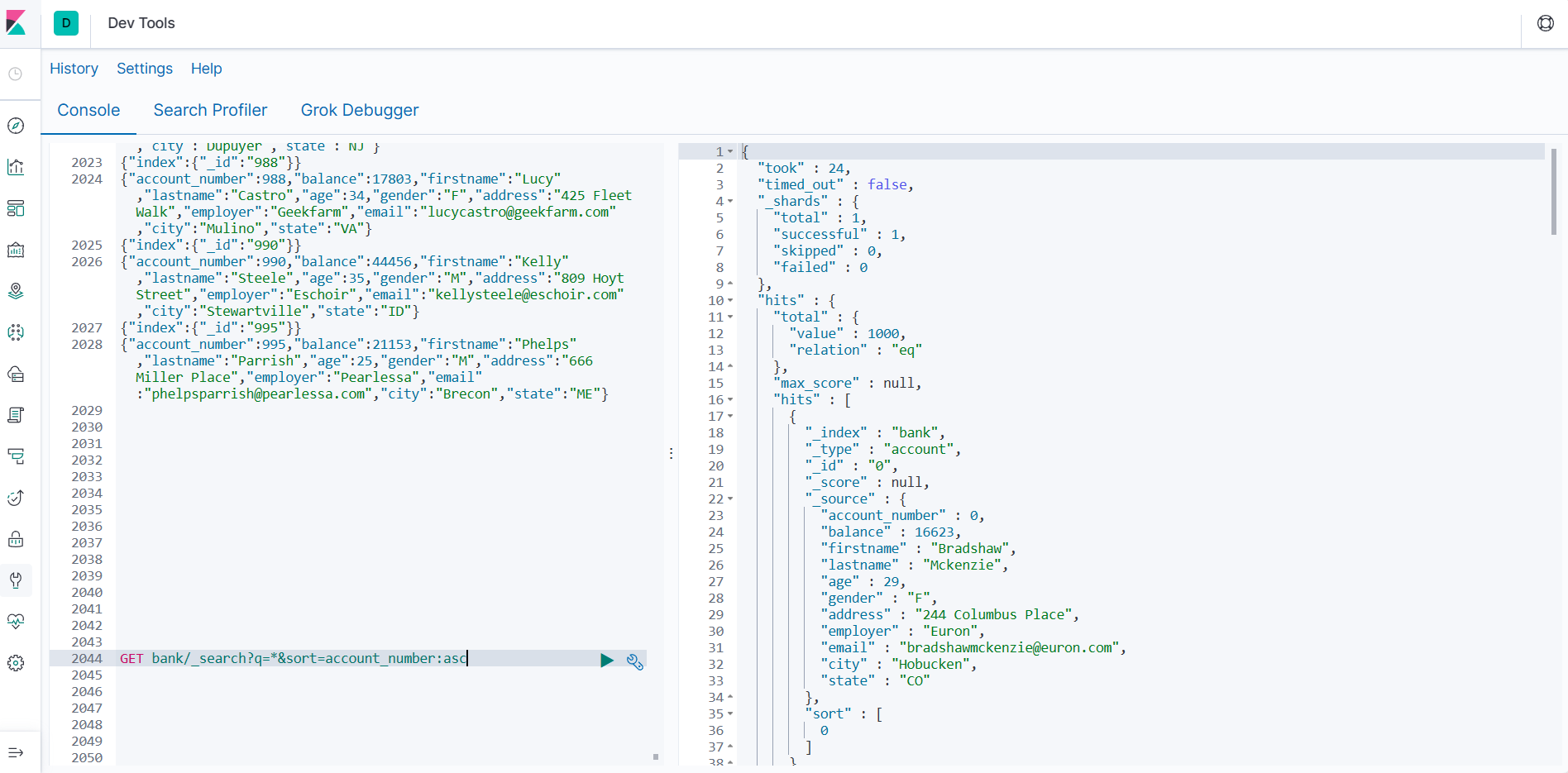
2、查询基本语法–match_all
示例 使用时不要加#注释内容
GET bank/_search
{"query": { # 查询的字段"match_all": {}},"from": 0, # 从第几条文档开始查"size": 5,"_source":["balance"],"sort": [{"account_number": { # 返回结果按哪个列排序"order": "desc" # 降序}}]
}
_source为要返回的字段
3、查询基本语法–match
如果是非字符串,会进行精确匹配。如果是字符串,会进行全文检索(模糊匹配)
- 基本类型(非字符串),精确控制
GET bank/_search
{"query": {"match": {"account_number": "20"}}
}- 字符串,全文检索(模糊匹配)
GET bank/_search
{"query": {"match": {"address": "kings"}}
}4、query/match_phrase [不拆分匹配]
GET bank/_search
{"query": {"match_phrase": {"address": "mill road" # 就是说不要匹配只有mill或只有road的,要匹配mill road一整个子串}}
}5、query/multi_math【多字段匹配,在每一个字段里面查找,相当于or,并且是分词匹配(默认都是分词)】
state或者address中包含mill,并且在查询过程中,会对于查询条件进行分词。
GET bank/_search
{"query": {"multi_match": { # 前面的match仅指定了一个字段。"query": "mill","fields": [ # state和address有mill子串 不要求都有"state","address"]}}
}6、query/bool/must复合查询(相当于and)
GET bank/_search
{"query": {"bool": {"must": [{"match": {"gender": "M"}},{"match": {"address": "mill"}}],"must_not": [{"match": {"age": "18"}}],"should": [{"match": {"lastname": "Wallace"}}]}}
}should:应该达到should列举的条件,
如果到达会增加相关文档的评分,并不会改变查询的结果。如果query中只有should且只有一种匹配规则,那么should的条件就会被作为默认匹配条件二区改变查询结果。
7、query/filter【结果过滤】
- must 贡献得分
- should 贡献得分
- must_not 不贡献得分
- filter 不贡献得分
GET bank/_search
{"query": {"bool": {"must": [{ "match": {"address": "mill" } }],"filter": { # query.bool.filter"range": {"balance": { # 哪个字段"gte": "10000","lte": "20000"}}}}}
}8、query/term
和match一样。匹配某个属性的值。
- 全文检索字段用match,
- 其他
非text字段匹配用term。
不要使用term来进行文本字段查询
es默认存储text值时用分词分析,所以要搜索text值,使用match
https://www.elastic.co/guide/en/elasticsearch/reference/7.6/query-dsl-term-query.html
- 字段.keyword:要一一匹配到
- match_phrase:子串包含即可
使用term匹配查询
GET bank/_search
{"query": {"term": {"address": "mill Road"}}
}9、aggs/agg1(聚合)
前面介绍了存储、检索,但还没介绍分析
聚合提供了从数据中分组和提取数据的能力。最简单的聚合方法大致等于SQL Group by和SQL聚合函数。
在elasticsearch中,执行搜索返回this(命中结果),并且同时返回聚合结果,把以响应中的所有hits(命中结果)分隔开的能力。这是非常强大且有效的,你可以执行查询和多个聚合,并且在一次使用中得到各自的(任何一个的)返回结果,使用一次简洁和简化的API啦避免网络往返。
例:搜索address中包含mill的所有人的年龄分布以及平均年龄,但不显示这些人的详情
# 分别为包含mill、,平均年龄、
GET bank/_search
{"query": { # 查询出包含mill的"match": {"address": "Mill"}},"aggs": { #基于查询聚合"ageAgg": { # 聚合的名字,随便起"terms": { # 看值的可能性分布"field": "age","size": 10}},"ageAvg": { "avg": { # 看age值的平均"field": "age"}},"balanceAvg": {"avg": { # 看balance的平均"field": "balance"}}},"size": 0 # 不看详情
}查询结果:
{"took" : 2,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 4, // 命中4条"relation" : "eq"},"max_score" : null,"hits" : [ ]},"aggregations" : {"ageAgg" : { // 第一个聚合的结果"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : 38, # age为38的有2条"doc_count" : 2},{"key" : 28,"doc_count" : 1},{"key" : 32,"doc_count" : 1}]},"ageAvg" : { // 第二个聚合的结果"value" : 34.0 # balance字段的平均值是34},"balanceAvg" : {"value" : 25208.0}}
}aggs/aggName/aggs/aggName子聚合
复杂:
按照年龄聚合,并且求这些年龄段的这些人的平均薪资
复杂:
按照年龄聚合,并且求这些年龄段的这些人的平均薪资
GET bank/_search
{"query": {"match_all": {}},"aggs": {"ageAgg": {"terms": { # 看分布"field": "age","size": 100},"aggs": { # 与terms并列"ageAvg": { #平均"avg": {"field": "balance"}}}}},"size": 0
}输出结果:
{"took" : 49,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 1000,"relation" : "eq"},"max_score" : null,"hits" : [ ]},"aggregations" : {"ageAgg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : 31,"doc_count" : 61,"ageAvg" : {"value" : 28312.918032786885}},{"key" : 39,"doc_count" : 60,"ageAvg" : {"value" : 25269.583333333332}},{"key" : 26,"doc_count" : 59,"ageAvg" : {"value" : 23194.813559322032}},{"key" : 32,"doc_count" : 52,"ageAvg" : {"value" : 23951.346153846152}},{"key" : 35,"doc_count" : 52,"ageAvg" : {"value" : 22136.69230769231}},{"key" : 36,"doc_count" : 52,"ageAvg" : {"value" : 22174.71153846154}},{"key" : 22,"doc_count" : 51,"ageAvg" : {"value" : 24731.07843137255}},{"key" : 28,"doc_count" : 51,"ageAvg" : {"value" : 28273.882352941175}},{"key" : 33,"doc_count" : 50,"ageAvg" : {"value" : 25093.94}},{"key" : 34,"doc_count" : 49,"ageAvg" : {"value" : 26809.95918367347}},{"key" : 30,"doc_count" : 47,"ageAvg" : {"value" : 22841.106382978724}},{"key" : 21,"doc_count" : 46,"ageAvg" : {"value" : 26981.434782608696}},{"key" : 40,"doc_count" : 45,"ageAvg" : {"value" : 27183.17777777778}},{"key" : 20,"doc_count" : 44,"ageAvg" : {"value" : 27741.227272727272}},{"key" : 23,"doc_count" : 42,"ageAvg" : {"value" : 27314.214285714286}},{"key" : 24,"doc_count" : 42,"ageAvg" : {"value" : 28519.04761904762}},{"key" : 25,"doc_count" : 42,"ageAvg" : {"value" : 27445.214285714286}},{"key" : 37,"doc_count" : 42,"ageAvg" : {"value" : 27022.261904761905}},{"key" : 27,"doc_count" : 39,"ageAvg" : {"value" : 21471.871794871793}},{"key" : 38,"doc_count" : 39,"ageAvg" : {"value" : 26187.17948717949}},{"key" : 29,"doc_count" : 35,"ageAvg" : {"value" : 29483.14285714286}}]}}
}复杂子聚合:查出所有年龄分布,并且这些年龄段中M的平均薪资和F的平均薪资以及这个年龄段的总体平均薪资
GET bank/_search
{"query": {"match_all": {}},"aggs": {"ageAgg": {"terms": { # 看age分布"field": "age","size": 100},"aggs": { # 子聚合"genderAgg": {"terms": { # 看gender分布"field": "gender.keyword" # 注意这里,文本字段应该用.keyword},"aggs": { # 子聚合"balanceAvg": {"avg": { # 男性的平均"field": "balance"}}}},"ageBalanceAvg": {"avg": { #age分布的平均(男女)"field": "balance"}}}}},"size": 0
}输出结果:
{"took" : 119,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 1000,"relation" : "eq"},"max_score" : null,"hits" : [ ]},"aggregations" : {"ageAgg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : 31,"doc_count" : 61,"genderAgg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : "M","doc_count" : 35,"balanceAvg" : {"value" : 29565.628571428573}},{"key" : "F","doc_count" : 26,"balanceAvg" : {"value" : 26626.576923076922}}]},"ageBalanceAvg" : {"value" : 28312.918032786885}}].......//省略其他}}
}二、Mapping字段映射
1、创建和查看映射
创建映射PUT /my_index
创建索引并指定映射
PUT /my_index
{"mappings": {"properties": {"age": {"type": "integer"},"email": {"type": "keyword" # 指定为keyword},"name": {"type": "text" # 全文检索。保存时候分词,检索时候进行分词匹配}}}
}查看映射GET /my_index
2、添加某个字段的映射
添加新的字段映射PUT /my_index/_mapping
PUT /my_index/_mapping
{"properties": {"employee-id": {"type": "keyword","index": false # 字段不能被检索。检索}}
}这里的 “index”: false,表明新增的字段不能被检索,只是一个冗余字段。
3、更新映射_reindex
ES不能更新映射
对于已经存在的字段映射,我们不能更新。更新必须创建新的索引,进行数据迁移。
POST _reindex
{"source": {"index": "bank","type": "account"},"dest": {"index": "newbank"}
}
🚩总结:
要更新索引那只能创建新的索引,并且将原来的数据进行转移
三、分词
1、简介_analyze
一个tokenizer(分词器)接收一个字符流,将之分割为独立的tokens(词元,通常是独立的单词),然后输出tokens流。
例如:whitespace tokenizer遇到空白字符时分割文本。它会将文本"Quick brown fox!"分割为[Quick,brown,fox!]
该tokenizer(分词器)还负责记录各个terms(词条)的顺序或position位置(用于phrase短语和word proximity词近邻查询),以及term(词条)所代表的原始word(单词)的start(起始)和end(结束)的character offsets(字符串偏移量)(用于高亮显示搜索的内容)。
elasticsearch提供了很多内置的分词器(标准分词器),可以用来构建custom analyzers(自定义分词器)。
关于分词器: https://www.elastic.co/guide/en/elasticsearch/reference/7.6/analysis.html
POST _analyze
{"analyzer": "standard","text": "The 2 Brown-Foxes bone."
}执行结果:
{"tokens" : [{"token" : "the","start_offset" : 0,"end_offset" : 3,"type" : "<ALPHANUM>","position" : 0},{"token" : "2","start_offset" : 4,"end_offset" : 5,"type" : "<NUM>","position" : 1},{"token" : "brown","start_offset" : 6,"end_offset" : 11,"type" : "<ALPHANUM>","position" : 2},{"token" : "foxes","start_offset" : 12,"end_offset" : 17,"type" : "<ALPHANUM>","position" : 3},{"token" : "bone","start_offset" : 18,"end_offset" : 22,"type" : "<ALPHANUM>","position" : 4}]
}对于中文,我们需要安装额外的分词器
2、安装ik分词器
所有的语言分词,默认使用的都是“Standard Analyzer”,但是这些分词器针对于中文的分词,并不友好。为此需要安装中文的分词器。
注意:不能用默认elasticsearch-plugin install xxx.zip 进行自动安装
https://github.com/medcl/elasticsearch-analysis-ik/releases
在前面安装的elasticsearch时,我们已经将elasticsearch容器的“/usr/share/elasticsearch/plugins”目录,映射到宿主机的“ /mydata/elasticsearch/plugins”目录下,所以比较方便的做法就是下载“/elasticsearch-analysis-ik-7.4.2.zip”文件,然后解压到该文件夹下即可。安装完毕后,需要重启elasticsearch容器。
如果不嫌麻烦,还可以采用如下的方式。
相关文章:
ElasticSearch进阶
一、 search检索文档 ES支持两种基本方式检索; 通过REST request uri 发送搜索参数 (uri 检索参数);通过REST request body 来发送它们(uri请求体); 1、信息检索 API: https://w…...

Nor flash 页写地址与数据大小的限制
厂商提供的flash手册如下 如果页写指令的地址不是256的整数倍,并且写入的数据量超过了当前地址所在页的边界,则超过的那些数据会重新写入当前页的首地址(即256的整数倍地址),所以,在进行页写的时候&#x…...

python 深度学习 解决遇到的报错问题4
目录 一、DLL load failed while importing _imaging: 找不到指定的模块 二、Cartopy安装失败 三、simplejson.errors.JSONDecodeError: Expecting value: line 1 column 1 (char 0) 四、raise IndexError("single positional indexer is out-of-bounds") 五、T…...
C到C++的升级
C和C的关系 C继承了所有C语言的特性;C在C的基础上提供了更多的语法和特性,C语言去除了一些C语言的不好的特性。C的设计目标是运行效率与开发效率的统一。 变化一:所有变量都可以在使用时定义 C中更强调语言的实用性,所有的变量…...

《热题101》动态规划篇
思路:需要一个二维数组dp来记录当前的公共子序列长度,如果当前的两个值等,则dp[i][j]dp[i-1][j-1]1,否则dp[i][j] max(dp[i-1][j],dp[i][j-1])。也就是说,当前的dp值是由左、上、左上的值决定的。获得dp数组之后,倒序…...

【综述+3D】基于NeRF的三维视觉2023年度进展报告(截止2023.06.10)
论文:2003.Representing Scenes as Neural Radiance Fields for View Synthesis 官方网站:https://www.matthewtancik.com/nerf 突破性后续改进: Instant Neural Graphics Primitives with a Multiresolution Hash Encoding | 展示官网&#…...

基于JavaScript粒子流动效果
这是一个HTML文件,主要包含了一些CSS样式和JavaScript代码,用于创建一个动画效果。 在CSS部分,定义了一些基本的样式,包括页面的背景颜色、位置、大小等。特别的,定义了两种球形元素(.ball_A 和 .ball_B&am…...
【U盘】实现U盘清空并重置恢复存储
打开电脑,将U盘插入USB端口,点按快捷键【WinR】,弹出运行对话框,输入命令 diskpart 进入命令提示符窗口 输入指令 list disk 查看现在的硬盘 这里显示的U盘编号是“1”,因此输入select disk “1”,就是选择…...
基于Hugo 搭建个人博客网站
目录 1.环境搭建 2.生成博客 3.设置主题 4.将博客部署到github上 1.环境搭建 1)安装Homebrew brew是一个在 macOS 操作系统上用于管理软件包的包管理器。类似于centos下的yum或者ubuntu下的apt,它允许用户通过命令行安装、更新和管理各种软件工具、…...
Springboot + Sqlite实战(离线部署成功)
最近有个需求,是手机软件离线使用, 用的springboot mybatis-plus mysql,无法实现,于是考虑使用内嵌式轻量级的数据库SQLlite 引入依赖 <dependency><groupId>org.xerial</groupId><artifactId>sqlite-…...
:MLWE 问题与NTT(附源码分析))
【后量子密码】CRYSTALS-KYBER 算法(一):MLWE 问题与NTT(附源码分析)
一、前言 大多数基于数论的密码学,如Diffie-Hellman协议和RSA加密系统,依赖于大整数因子分解或特定群的离散对数等困难问题。然而,Shor 在1997年给出了对所有这些问题的高效量子算法,这将使得基于数论的密码系统在未来量子计算机时代变得不安全。相比之下,目前对于格密码…...

VTK——angleWidget的3D转换
文章目录 3D空间坐标转换例程心得 3D空间坐标转换 在冠状图、矢状面、横截面等创建的角度组件的三个端点坐标,不能直接用在3D视图中。这是因为2D切片的坐标是基于像素的,而3D空间的坐标可能是基于实际物理尺寸的。 解决方案是使用2D点的坐标、切片的物理…...
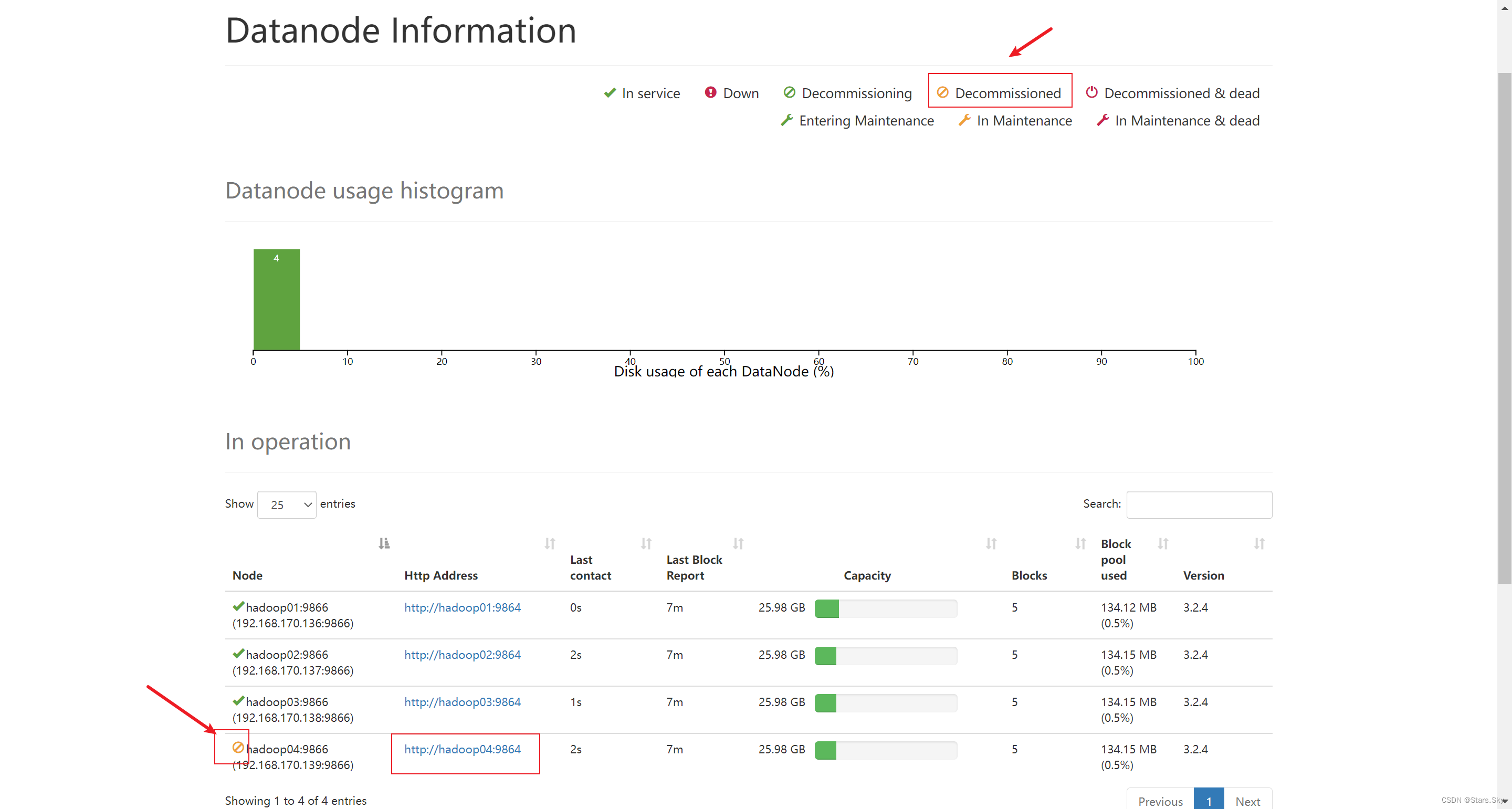
HDFS 集群动态节点管理
目录 一、动态扩容、节点上线 1.1 背景 1.2 扩容步骤 1.2.1 新机器基础环境准备 1.2.2 Hadoop 配置 1.2.3 手动启动 DataNode 进程 1.2.4 Web 页面查看情况 1.2.5 DataNode 负载均衡服务 二、动态缩容、节点下线 2.1 背景 2.2 缩容步骤 2.2.1 添加退役节点 …...
postman9.12.汉化版(附有下载链接)
想用英文版本的可以直接点击下载最新版本 这里直接付上9.12.2版本的下载链接,如果大家要下载别的版本,可以直接修改链接里面的版本号即可 ,下面是汉化包下载 链接:https://pan.baidu.com/s/1izK3HfqlfXJdq6KIYeJ2zw?pwdpetk 提…...
mysql与msql2数据驱动
mysql基本使用 数据库操作(DDL) -- 数据考操作 -- 1.查询所有数据库 SHOW DATABASES;-- 2.选择数据库 USE learn_mysql;-- 3.当前正在使用的数据库 SELECT DATABASE();-- 4.创建数据库 CREATE DATABASE IF NOT EXISTS learn_mysql;-- 5.删除数据库 DRO…...

解决微信小程序回调地狱问题
一、背景 小程序开发经常遇到根据网络请求结果,然后继续 处理下一步业务操作,代码如下: //1第一个请求 wx.request({url:"https://example.com/api/",data:data,success:function(res){//2第二个请求 wx.request({url:"http…...

cron介绍
cron表达式在线生成 在使用定时调度任务的时候,我们最常用的,就是cron表达式了。通过cron表达式来指定任务在某个时间点或者周期性的执行。 cron表达式的组成 cron表达式是一个字符串,由6到7个字段组成,用空格分隔。其中前6个字…...
mkp勒索病毒的介绍和防范,勒索病毒解密,数据恢复
mkp勒索病毒是一种新兴的电脑病毒,它会对感染的电脑进行加密,并要求用户支付一定的赎金才能解锁。这种病毒已经引起了全球范围内的关注,因为它不仅具有高危害性,而且还有很强的传播能力。本文将对mkp勒索病毒进行详细介绍…...

【面试精品】关于面试会遇到的Apache相关的面试题
1. Apache HTTP Server 基于什么协议提供网页浏览服务? 答:基于标准的http网络协议提供网页浏览服务。 2. 简述编译安装httpd软件包的基本过程? 答:解包,配置,编译,安装。 3. 编译安装httpd软…...

python对文件转md5,用于文件重复过滤
直接上代码 import hashlibdef calculate_md5(file_path):# 创建 MD5 哈希对象md5_hash hashlib.md5()# 打开文件并逐块读取,更新哈希值with open(file_path, rb) as file:while True:data file.read(8192) # 逐块读取文件,每块大小为 8192 字节if n…...

TVA动态阈值在昇腾310的适配要点
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

广告投放ROI断崖式下滑?立即排查ElevenLabs这4个语音合成致命偏差,2小时内修复
更多请点击: https://intelliparadigm.com 第一章:广告投放ROI断崖式下滑的语音归因真相 当广告主发现iOS 17设备上语音搜索转化路径中归因丢失率高达68%,却仍在依赖传统点击归因(Click-Through Attribution)模型时&a…...
:支持API密钥分级管控、审计日志追踪、GDPR合规配置)
ChatGPT与Notion深度整合实战手册(企业级私有化部署版):支持API密钥分级管控、审计日志追踪、GDPR合规配置
更多请点击: https://codechina.net 第一章:ChatGPT与Notion深度整合概述 ChatGPT 与 Notion 的深度整合正重塑个人知识管理与团队协作的工作流范式。二者分别代表当前最强大的语言理解能力与最灵活的结构化信息组织平台,其结合并非简单 API…...

代码生成器设计原理与实战:从模板引擎到自动化开发
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫xintaofei/codeg。乍一看这个名字,可能有点摸不着头脑,codeg是啥?是“代码生成器”的缩写吗?还是某种新的开发工具?点进去研究了一番&#x…...

深度解析AzurLaneAutoScript:碧蓝航线自动化脚本的技术架构与应用实践
深度解析AzurLaneAutoScript:碧蓝航线自动化脚本的技术架构与应用实践 【免费下载链接】AzurLaneAutoScript Azur Lane bot (CN/EN/JP/TW) 碧蓝航线脚本 | 无缝委托科研,全自动大世界 项目地址: https://gitcode.com/gh_mirrors/az/AzurLaneAutoScript…...
)
单卡训练mmsegmentation模型?先把这个SyncBN改成BN(附完整配置文件修改指南)
单卡训练mmsegmentation模型?先解决SyncBN这个关键配置 当你第一次在个人电脑或实验室的单一GPU设备上运行mmsegmentation训练脚本时,屏幕上突然弹出的SyncBN相关错误信息可能会让兴奋的心情瞬间跌入谷底。这个看似简单的配置问题,实际上反映…...

5分钟掌握XUnity自动翻译器:打破游戏语言障碍的终极指南 [特殊字符]
5分钟掌握XUnity自动翻译器:打破游戏语言障碍的终极指南 🎮 【免费下载链接】XUnity.AutoTranslator 项目地址: https://gitcode.com/gh_mirrors/xu/XUnity.AutoTranslator 你是否曾因语言障碍而错过心仪的游戏大作?XUnity自动翻译器…...

HOSFEM中矩阵向量乘法优化与几何因子重计算技术
1. 矩阵向量乘法在HOSFEM中的核心地位与挑战 高阶/谱有限元方法(HOSFEM)是求解偏微分方程(PDE)的重要工具,广泛应用于计算流体力学、结构力学和电磁学等领域。与传统低阶方法相比,HOSFEM能以更少的自由度达…...

HunterPie完全指南:如何在《怪物猎人世界》中获得实时数据监控优势
HunterPie完全指南:如何在《怪物猎人世界》中获得实时数据监控优势 【免费下载链接】HunterPie-legacy A complete, modern and clean overlay with Discord Rich Presence integration for Monster Hunter: World. 项目地址: https://gitcode.com/gh_mirrors/hu/…...

代码编辑器世纪大战:VS Code vs JetBrains IDE vs Zed全面对比
Visual Studio Code、IntelliJ IDEA/PhpStorm/WebStorm、Zed——这三种编辑器代表了三代程序员的生产力哲学。本文从响应速度、生态成熟度、AI赋能、协作能力四个维度进行深度横评。 一、三种编辑器的基因差异 VS Code:开放生态的胜利 VS Code的核心优势不是功能&am…...