Laravel chunk和chunkById的坑
在编写定时任务脚本的时候,经常会用到chunk和chunkById的API。
一、前言
数据库引擎为innodb。
表结构简述,只列出了本文用到的字段。
| 字段 | 类型 | 注释 |
|---|---|---|
| id | int(11) | ID |
| type | int(11) | 类型 |
| mark_time | int(10) | 标注时间(时间戳) |
索引,也只列出需要的部分。
| 索引名 | 字段 |
|---|---|
| PRIMARY | id |
| idx_sid_blogdel_marktime | type blog_del mark_time |
| Idx_marktime | mark_time |
二、需求
每天凌晨一点取出昨天标注type为99的所有数据,进行逻辑判断,然后进行其他操作。本文的重点只在于取数据的阶段。
数据按月分表,每个月表中的数据为1000w上下。
三、chunk处理数据
代码如下:
$this->dao->where('type', 99)->whereBetween('mark_time', [$date, $date+86399])->select(array('mark_time', 'id'))->chunk(1000, function ($rows){// 业务处理
});
从一个月中的数据,筛选出type为99,并且标注时间在某天的00:00:00-23:59:59的数据。可以使用到mark_time和type的索引。
type为99,一天的数据大概在15-25w上下的样子。使用->get()->toArray()内存会直接炸掉。所以使用chunk方法,每次取出1000条数据。
使用chucnk,不会出现内存不够的情况。但是性能较差。粗略估计,从一月数据中取出最后一天的数据,跑完20w数据大概需要一两分钟。
查看源码,底层的chunk方法,是为sql语句添加了限制和偏移量。
select * from
usersasc limit 500 offset 500;
在数据较多的时候,越往后的话效率会越慢,因为Mysql的limit方法底层是这样的。
limit 10000,10
是扫描满足条件的10010行,然后扔掉前面的10000行,返回最后最后20行。在数据较多的时候,性能会非常差。
查了下API,对于这种情况Laraverl提供了另一个API chunkById。
四、chunkById 原理
使用limit和偏移量在处理大量的数据会有性能的明显下降。于是chunkById使用了id进行分页处理。很好理解,代码如下:
select * from
userswhereid> :last_id order byidasc limit 500;
API会自动保存最后一个ID,然后通过id > :last_id 再加上limit就可以通过主键索引进行分页。只取出来需要的行数。性能会有明显的提升。
五、chunkById的坑
API显示chunk和chunkById的用法完全相同。于是把脚本的代码换成了chunkById。
$this->dao->where('type', 99)->whereBetween('mark_time', [$date, $date+86399])->select(array('mark_time', 'id'))->chunkById(1000, function ($rows){// 业务处理
});
在执行脚本的时候,1月2号和1月1号的数据没有任何问题。执行速度快了很多。但是在执行12月31号的数据的时候,发现脚本一直执行不完。
在定位后发现是脚本没有进入业务处理的部分,也就是sql一直没有执行完。当时很疑惑,因为刚才执行的没问题,为什么执行12月31号的就出问题了呢。
于是查看sql服务器中的执行情况。
show full processlist;
发现了问题。上节说了chunkById的底层是通过id进行order by,然后limie取出一部分一部分的数据,也就是我们预想的sql是这样的。
select * from
tabelwheretype= 99 and mark_time between :begin_date and :end_date limit 500;
explain出来的情况如下:

实际上的sql是这样的:
select * from
tabelwheretype= 99 and mark_time between :begin_date and :end_date order by id limit 500;
实际explain出来的情况是这样的:

chunkById会自动添加order by id。innodb一定会使用主键索引。那么就不会再使用mark_time的索引了。导致sql执行效率及其缓慢。
六、解决方法
再次查看chunkById的源码。
/*** Chunk the results of a query by comparing IDs.** @param int $count* @param callable $callback* @param string|null $column* @param string|null $alias* @return bool*/
public function chunkById($count, callable $callback, $column = null, $alias = null)
{$column = $column ?? $this->defaultKeyName();$alias = $alias ?? $column;$lastId = null;do {$clone = clone $this;// We'll execute the query for the given page and get the results. If there are// no results we can just break and return from here. When there are results// we will call the callback with the current chunk of these results here.$results = $clone->forPageAfterId($count, $lastId, $column)->get();$countResults = $results->count();if ($countResults == 0) {break;}// On each chunk result set, we will pass them to the callback and then let the// developer take care of everything within the callback, which allows us to// keep the memory low for spinning through large result sets for working.if ($callback($results) === false) {return false;}$lastId = $results->last()->{$alias};unset($results);} while ($countResults == $count);return true;
}
能看到这个方法有四个参数count,callback,column,alias。
默认的column为null,第一行会进行默认赋值。
/*** Get the default key name of the table.** @return string*/
protected function defaultKeyName()
{return 'id';
}
能看到默认的column为id。
进入forPageAfterId方法。
/*** Constrain the query to the next "page" of results after a given ID.** @param int $perPage* @param int|null $lastId* @param string $column* @return \Illuminate\Database\Query\Builder|static*/
public function forPageAfterId($perPage = 15, $lastId = 0, $column = 'id')
{$this->orders = $this->removeExistingOrdersFor($column);if (! is_null($lastId)) {$this->where($column, '>', $lastId);}return $this->orderBy($column, 'asc')->limit($perPage);
}
能看到如果lastId不为0则自动添加where语句,还会自动添加order by column。
看到这里就明白了。上文的chunkById没有添加column参数,所以底层自动添加了order by id。走了主键索引,没有使用上mark_time的索引。导致查询效率非常低。
chunkById的源码显示了我们可以传递一个column字段来让底层使用这个字段来order by。
代码修改如下:
$this->dao->where('type', 99)->whereBetween('mark_time', [$date, $date+86399])->select(array('mark_time', 'id'))->chunkById(1000, function ($rows){// 业务处理
}, 'mark_time');
这样最后执行的sql如下:
select * from
tabelwheretype= 99 and mark_time between :begin_date and :end_date order by mark_time limit 500;
再次执行脚本,大概执行一次也就十秒作用了,性能提升显著。
七、总结
使用 chunkById 或者 chunk 方法的时候不要添加自定义的排序,chunk和chunkById的区别就是chunk是单纯的通过偏移量来获取数据,chunkById进行了优化,不使用偏移量,使用id过滤,性能提升巨大。在数据量大的时候,性能可以差到几十倍的样子。
而且使用chunk在更新的时候,也会遇到数据会被跳过的问题。详见解决Laravel中chunk方法分块处理数据的坑
同时chunkById在你没有传递column参数时,会默认添加order by id。可能会遇到索引失效的问题。解决办法就是传递column参数即可。
本人感觉chunkById不光是根据Id分块,而是可以根据某一字段进行分块,这个字段是可以指定的。叫chunkById有一些误导性,chunkByColumn可能更容易理解。
使用chunkById时不要加排序
使用chunkById比chunk更快
原文
相关文章:
Laravel chunk和chunkById的坑
在编写定时任务脚本的时候,经常会用到chunk和chunkById的API。 一、前言 数据库引擎为innodb。 表结构简述,只列出了本文用到的字段。 字段类型注释idint(11)IDtypeint(11)类型mark_timeint(10)标注时间(时间戳) 索引&#x…...
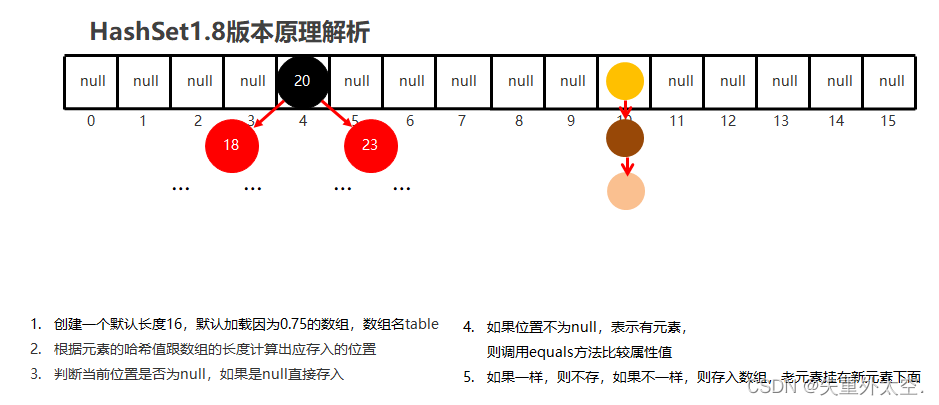
从零开始学习 Java:简单易懂的入门指南之泛型及set集合(二十二)
泛型及set集合扩展 1.泛型1.1泛型概述 2.Set集合2.1Set集合概述和特点【应用】2.2Set集合的使用【应用】 3.TreeSet集合3.1TreeSet集合概述和特点【应用】3.2TreeSet集合基本使用【应用】3.3自然排序Comparable的使用【应用】3.4比较器排序Comparator的使用【应用】3.5两种比较…...
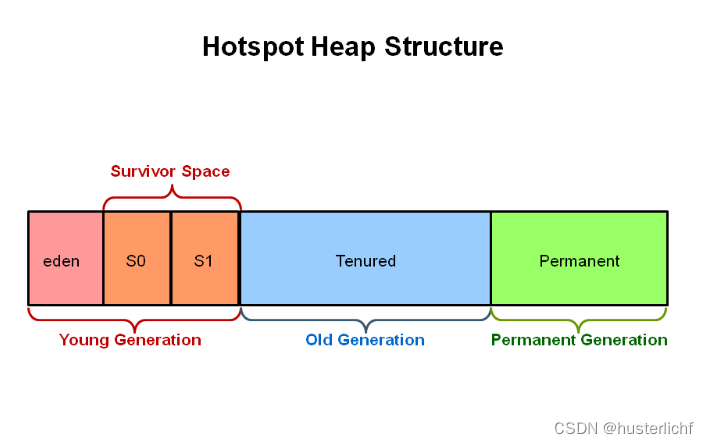
JVM----GC(垃圾回收)详解
一、Automatic Garbage Collection(垃圾回收)简介 Automatic Garbage Collection (自动垃圾回收)是JVM的一个特性,JVM会启动相关的线程,该线程会轮训检查heap memeory,并确定哪些是未被引用的(…...

数据库的三个范式
数据库的三个范式是关系数据库设计中的一组规范,用于确保数据的有效性和一致性。这三个范式分别是: 第一范式(1NF):要求数据库表中的每一列都是不可分割的原子值。换句话说,每个表中的每个字段不能包含多个…...
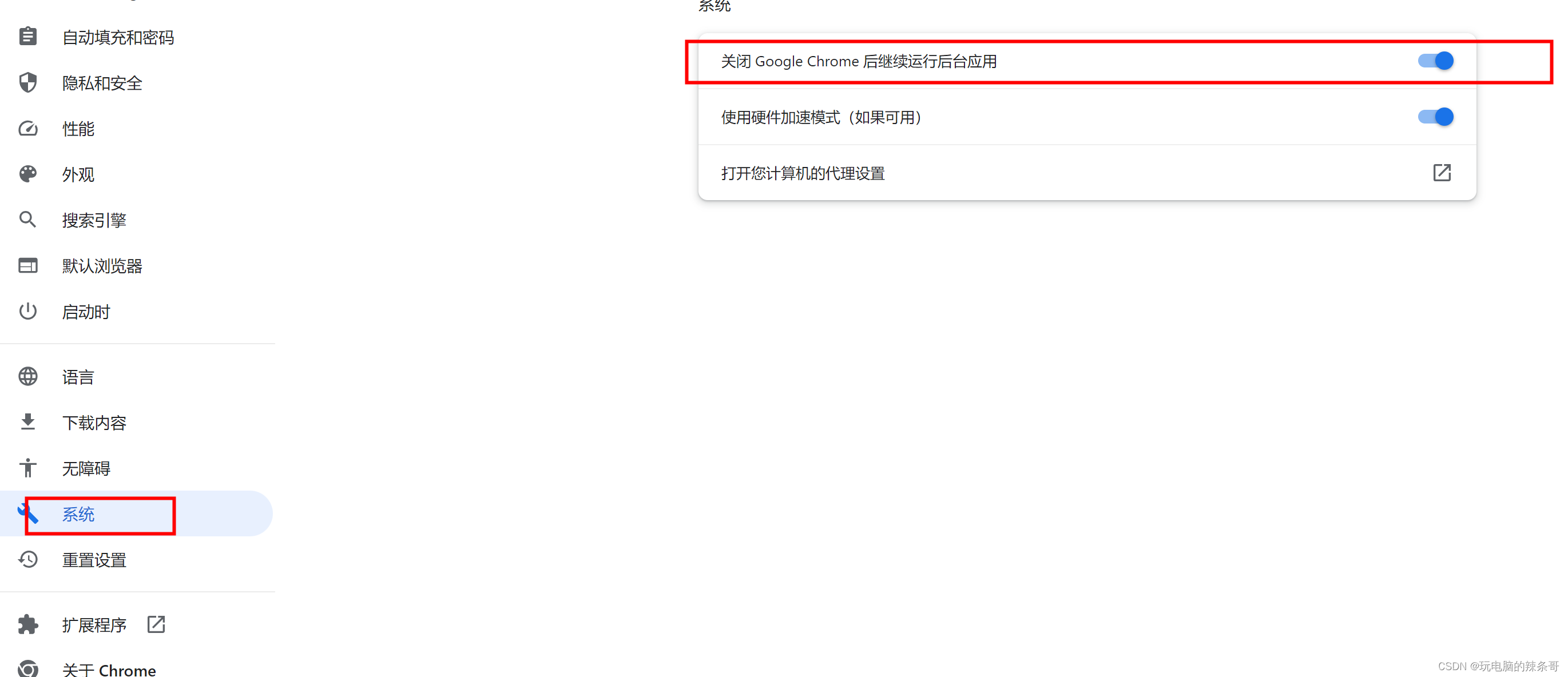
谷歌浏览器打开白屏 后台还有还有很多google chrome进程在运行
环境: Win10 专业版 谷歌浏览器 版本 116.0.5845.141(正式版本) (64 位) L盾加密终端 问题描述: 谷歌浏览器打开白屏 后台还有还有很多google chrome进程在运行,要全部结束谷歌浏览器进程&…...
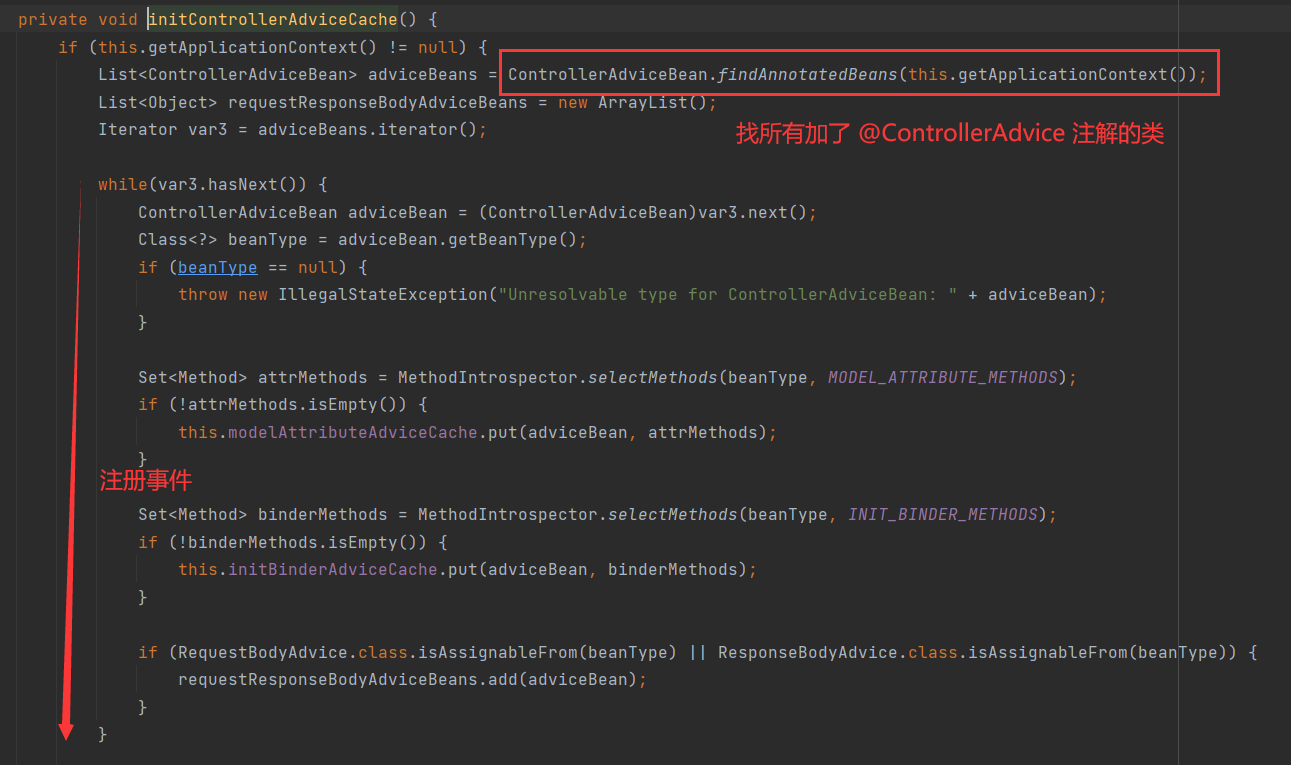
Java EE 突击 15 - Spring Boot 统一功能处理
Spring Boot 统一功能处理 一 . 统一功能的处理1.1 初级阶段 : 不断重复1.2 中级阶段 : 集成方法1.3 高级阶段 : Spring AOP1.4 超高级阶段 : Spring 拦截器准备工作实现拦截器自定义拦截器将自定义拦截器加入到系统配置 拦截器实现原理扩展 : 统一访问前缀添加 二 . 统一异常的…...
JasperReport定义变量后打印PDF变量为null以及整个pdf文件为空白
问题1: JasperReport打印出来的整个pdf文件为空白文件; 问题2:JasperReport定义变量后打印PDF变量为null; 问题1原因是因为缺少数据源JRDataSource JasperFillManager.fillReport(jasperReport, params,new JREmptyDataSource());如果你打印…...

Python 及 Pycharm 的安装 2023.8
Python 及 PyCharm 的安装 仅适用于 Windows 系统! 视频教程:【Python及Pycharm的安装 2023.8】 https://www.bilibili.com/video/BV1A34y1T7Gu 文章目录 Python 及 PyCharm 的安装安装 Python安装 PyCharmHi, PyCharmPyCharm 汉化 安装 Python 进入 …...

java中的线程中断
java中的线程中断 1、线程中断 即 线程的取消/关闭的机制2、线程对中断interrupt()的反应2.1、RUNNABLE:线程在运行或具备运行条件只是在等待操作系统调度2.2、WAITING/TIMED_WAITING:线程在等待某个条件或超时2.3、BLOCKED:线程在等待锁&…...
【跟小嘉学 Rust 编程】二十三、Cargo 使用指南
系列文章目录 【跟小嘉学 Rust 编程】一、Rust 编程基础 【跟小嘉学 Rust 编程】二、Rust 包管理工具使用 【跟小嘉学 Rust 编程】三、Rust 的基本程序概念 【跟小嘉学 Rust 编程】四、理解 Rust 的所有权概念 【跟小嘉学 Rust 编程】五、使用结构体关联结构化数据 【跟小嘉学…...
)
R Removing package报错(as ‘lib’ is unspecified)
remove.packages(ggpubr) Removing package from ‘/Library/Frameworks/R.framework/Versions/4.0/Resources/library’ (as ‘lib’ is unspecified) 解决办法: > .libPaths() [1] "/Library/Frameworks/R.framework/Versions/4.0/Resources/library&qu…...
金融信创,软件规划需关注自主安全及生态建设
软件信创化,就是信息技术软件应用创新发展的意思(简称为“信创”)。 相信在中国,企业对于“信创化”这个概念并不陌生。「国强则民强」,今年来中国经济的快速发展,受到了各大欧美强国的“卡脖子”操作的影…...

无重叠区间【贪心算法】
无重叠区间 给定一个区间的集合 intervals ,其中 intervals[i] [starti, endi] 。返回 需要移除区间的最小数量,使剩余区间互不重叠 。 class Solution {public int eraseOverlapIntervals(int[][] intervals) {//先排序,按照左边界升序,注…...
nlp系列(7)实体识别(Bert)pytorch
模型介绍 本项目是使用Bert模型来进行文本的实体识别。 Bert模型介绍可以查看这篇文章:nlp系列(2)文本分类(Bert)pytorch_bert文本分类_牧子川的博客-CSDN博客 模型结构 Bert模型的模型结构: 数据介绍 …...
Uniapp学习之从零开始写一个简单的小程序demo(新建页面,通过导航切换页面,发送请求)
先把官网文档摆在这,后面会用到的 [uniapp官网文档]: https://uniapp.dcloud.net.cn/vernacular.html# 一、开发工具准备 1-1 安装HBuilder 按照官方推荐,先装一个HBuilder 下载地址: https://www.dcloud.io/hbuilderx.html1-2 安装微信开…...
uniapp微信小程序隐私保护引导新规
1.components中新建组件PrivacyPop.vue <template><view class"privacy" v-if"showPrivacy"><view class"content"><view class"title">隐私保护指引</view><view class"des">在使用当…...
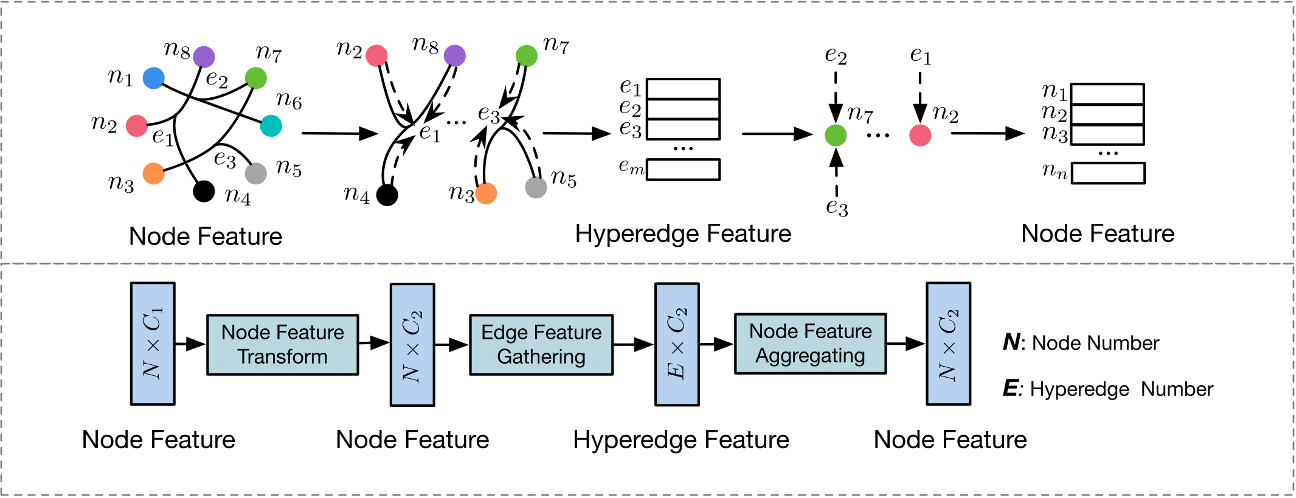
超图嵌入论文阅读2:超图神经网络
超图嵌入论文阅读2:超图神经网络 原文:Hypergraph Neural Networks ——AAAI2019(CCF-A) 源码:https://github.com/iMoonLab/HGNN 500star 概述 贡献:用于数据表示学习的超图神经网络 (HGNN) 框架…...
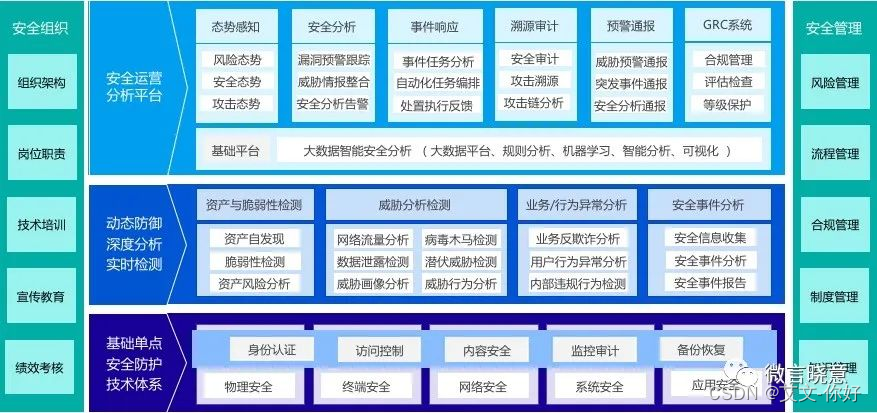
安全运营中心(SOC)技术框架
2018年曾经画过一个安全运营体系框架,基本思路是在基础单点技术防护体系基础上,围绕着动态防御、深度分析、实时检测,建立安全运营大数据分析平台,可以算作是解决方案产品的思路。 依据这个体系框架,当时写了《基于主动…...
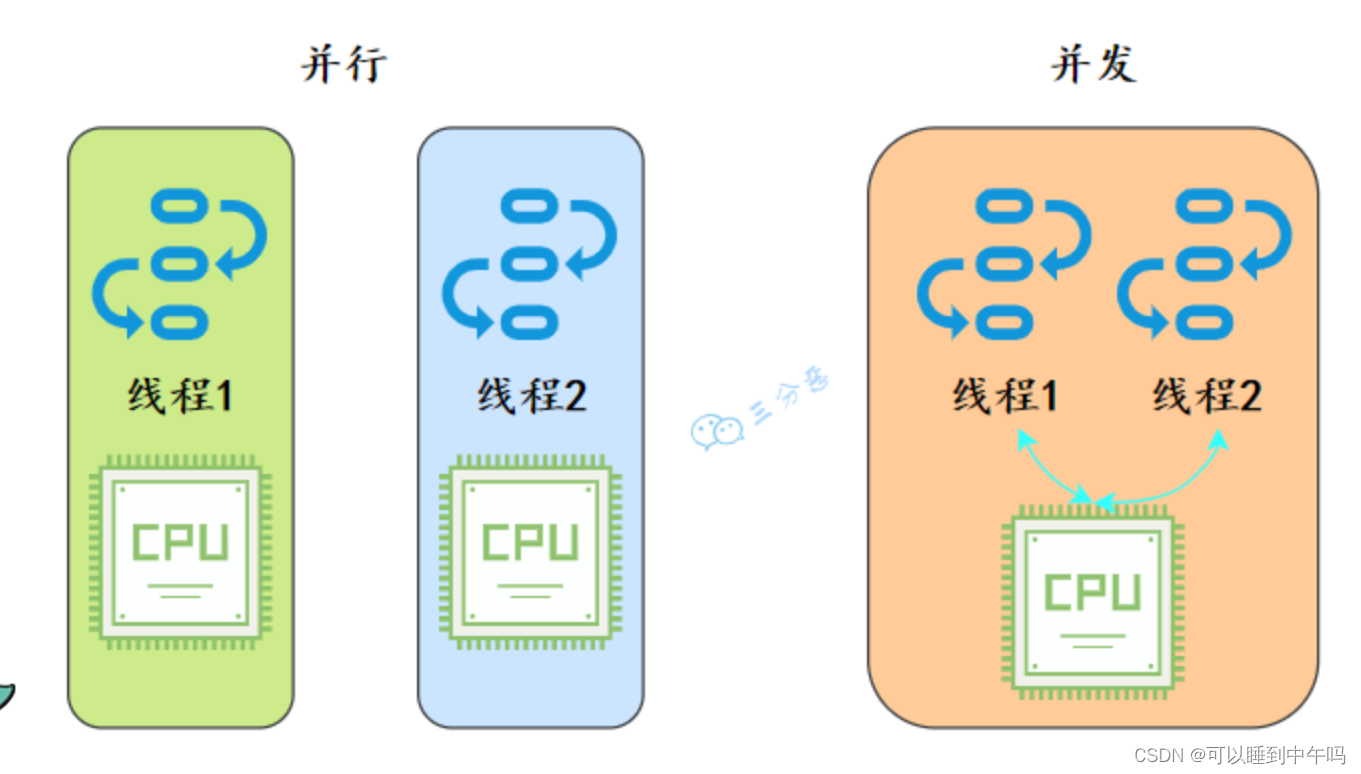
并行和并发的区别
从操作系统的角度来看,线程是CPU分配的最小单位。 并行就是同一时刻,两个线程都在执行。这就要求有两个CPU去分别执行两个线程。并发就是同一时刻,只有一个执行,但是一个时间段内,两个线程都执行了。并发的实现依赖于…...
GPT转换工具:轻松将MBR转换为GPT磁盘
为什么需要将MBR转换为GPT? 众所周知,Windows 11已经发布很长时间了。在此期间,许多老用户已经从Windows 10升级到Windows 11。但有些用户仍在运行Windows 10。对于那些想要升级到Win 11的用户来说,他们可能不确定Win 11应该使…...

多模态AI应用开发实战:GPT与图像生成的集成架构与优化
1. 项目概述与核心价值最近在折腾AI图像生成和智能对话的整合应用时,发现了一个挺有意思的仓库:bubblesslayyer-cmd/Awesome-GPT-Image-2-OpenAi。这个项目名字乍一看有点长,但拆解一下就能明白它的核心——“Awesome”系列通常代表精选资源集…...

ncmdumpGUI:3分钟掌握网易云音乐ncm格式转换的终极方案
ncmdumpGUI:3分钟掌握网易云音乐ncm格式转换的终极方案 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾经在网易云音乐下载了心爱的歌曲&a…...
)
别再死记硬背了!用MATLAB手把手教你画根轨迹图(附代码与避坑指南)
MATLAB实战:从零绘制根轨迹图的完整指南与避坑技巧 在控制系统的设计与分析中,根轨迹图是理解系统动态特性的重要工具。传统教学中,学生往往被要求死记硬背绘制规则,却难以理解其实际应用价值。本文将彻底改变这一现状——通过MAT…...

3个按键冲突场景,Hitboxer如何帮你重获游戏控制权?
3个按键冲突场景,Hitboxer如何帮你重获游戏控制权? 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd 你是否曾在激烈的游戏对战中,因为同时按下W和S键而突然卡住?或…...

Linuxbonding链路异常定位实战
Linuxbonding链路异常定位实战这是一篇面向中级 Linux 使用者的技术文章,主题聚焦在bonding链路,重点讨论链路聚合、冗余切换和接口状态。在真实生产环境中,bonding链路相关问题往往不会以单一错误形式出现,而是混杂在日志、权限、…...

如何3分钟快速上手企业级后台管理系统:终极配置秘籍
如何3分钟快速上手企业级后台管理系统:终极配置秘籍 【免费下载链接】ant-design-vue3-admin 一个基于 Vite2 Vue3 Typescript tsx Ant Design Vue 的后台管理系统模板,支持响应式布局,在 PC、平板和手机上均可使用 项目地址: https://…...

别再让某个用户占满硬盘了!手把手教你用Linux quota给CentOS 7/8的/home目录设置磁盘限额
别再让某个用户占满硬盘了!手把手教你用Linux quota给CentOS 7/8的/home目录设置磁盘限额 想象一下这样的场景:你管理的服务器上,十几个开发人员共享着同一个存储空间。某天突然收到警报——磁盘空间不足!调查后发现,一…...

火灾动力学模拟实战:如何用FDS构建精准的火灾预测系统
火灾动力学模拟实战:如何用FDS构建精准的火灾预测系统 【免费下载链接】fds Fire Dynamics Simulator 项目地址: https://gitcode.com/gh_mirrors/fd/fds 你是否曾面临这样的困境:当设计一栋大型商业建筑时,如何科学评估火灾时的人员疏…...

如何用Wedecode实现微信小程序源代码的完美还原:从加密包到可读代码的完整指南
如何用Wedecode实现微信小程序源代码的完美还原:从加密包到可读代码的完整指南 【免费下载链接】wedecode 全自动化,微信小程序 wxapkg 包 源代码还原工具, 线上代码安全审计,支持 Windows, Macos, Linux 项目地址: https://gitcode.com/gh…...

微服务架构实战:从DDD设计到K8s部署的完整指南
1. 项目概述与核心价值最近几年,微服务架构的热度一直居高不下,从互联网大厂到初创团队,几乎人人都在谈微服务。但说实话,真正能把微服务玩转、落地,并且能稳定支撑业务发展的团队,其实并不多。很多项目要么…...