nlp系列(7)实体识别(Bert)pytorch
模型介绍
本项目是使用Bert模型来进行文本的实体识别。
Bert模型介绍可以查看这篇文章:nlp系列(2)文本分类(Bert)pytorch_bert文本分类_牧子川的博客-CSDN博客
模型结构
Bert模型的模型结构:
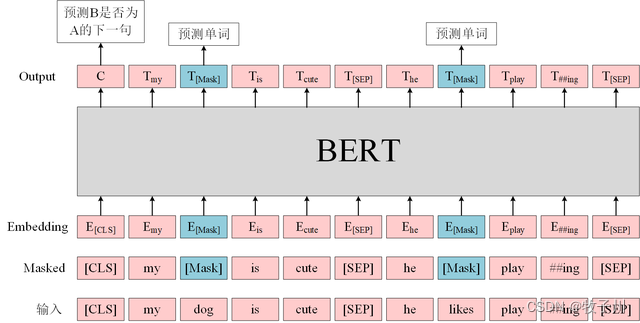
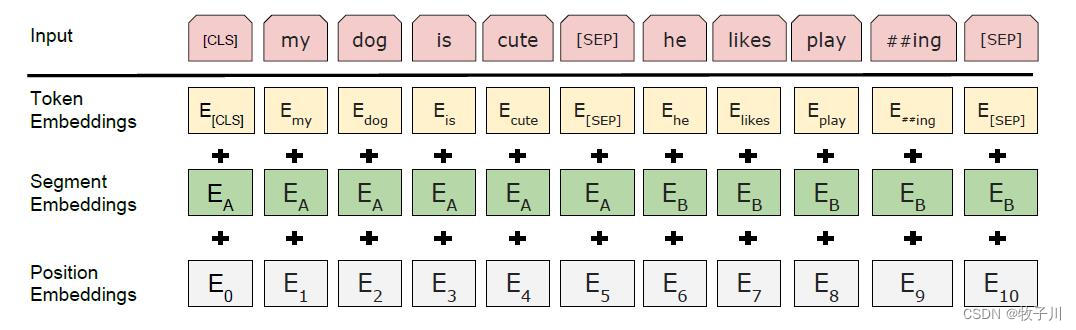
数据介绍
数据网址:https://github.com/buppt//raw/master/data/people-relation/train.txt
实体1 实体2 关系 文本

input_ids_list, token_type_ids_list, attention_mask_list, e1_masks_list, e2_masks_list, labels_list = [], [], [], [], [], []for instance in batch_data:# 按照batch中的最大数据长度,对数据进行padding填充input_ids_temp = instance["input_ids"]token_type_ids_temp = instance["token_type_ids"]attention_mask_temp = instance["attention_mask"]e1_masks_temp = instance["e1_masks"]e2_masks_temp = instance["e2_masks"]labels_temp = instance["labels"]# 添加到对应的list中input_ids_list.append(torch.tensor(input_ids_temp, dtype=torch.long))token_type_ids_list.append(torch.tensor(token_type_ids_temp, dtype=torch.long))attention_mask_list.append(torch.tensor(attention_mask_temp, dtype=torch.long))e1_masks_list.append(torch.tensor(e1_masks_temp, dtype=torch.long))e2_masks_list.append(torch.tensor(e2_masks_temp, dtype=torch.long))labels_list.append(labels_temp)# 使用pad_sequence函数,会将list中所有的tensor进行长度补全,补全到一个batch数据中的最大长度,补全元素为padding_valuereturn {"input_ids": pad_sequence(input_ids_list, batch_first=True, padding_value=0),"token_type_ids": pad_sequence(token_type_ids_list, batch_first=True, padding_value=0),"attention_mask": pad_sequence(attention_mask_list, batch_first=True, padding_value=0),"e1_masks": pad_sequence(e1_masks_list, batch_first=True, padding_value=0),"e2_masks": pad_sequence(e2_masks_list, batch_first=True, padding_value=0),"labels": torch.tensor(labels_list, dtype=torch.long)}模型准备
def forward(self, token_ids, token_type_ids, attention_mask, e1_mask, e2_mask):sequence_output, pooled_output = self.bert_model(input_ids=token_ids, token_type_ids=token_type_ids,attention_mask=attention_mask, return_dict=False)# 每个实体的所有token向量的平均值e1_h = self.entity_average(sequence_output, e1_mask)e2_h = self.entity_average(sequence_output, e2_mask)e1_h = self.activation(self.dense(e1_h))e2_h = self.activation(self.dense(e2_h))# [cls] + 实体1 + 实体2concat_h = torch.cat([pooled_output, e1_h, e2_h], dim=-1)concat_h = self.norm(concat_h)logits = self.hidden2tag(self.drop(concat_h))return logits模型预测
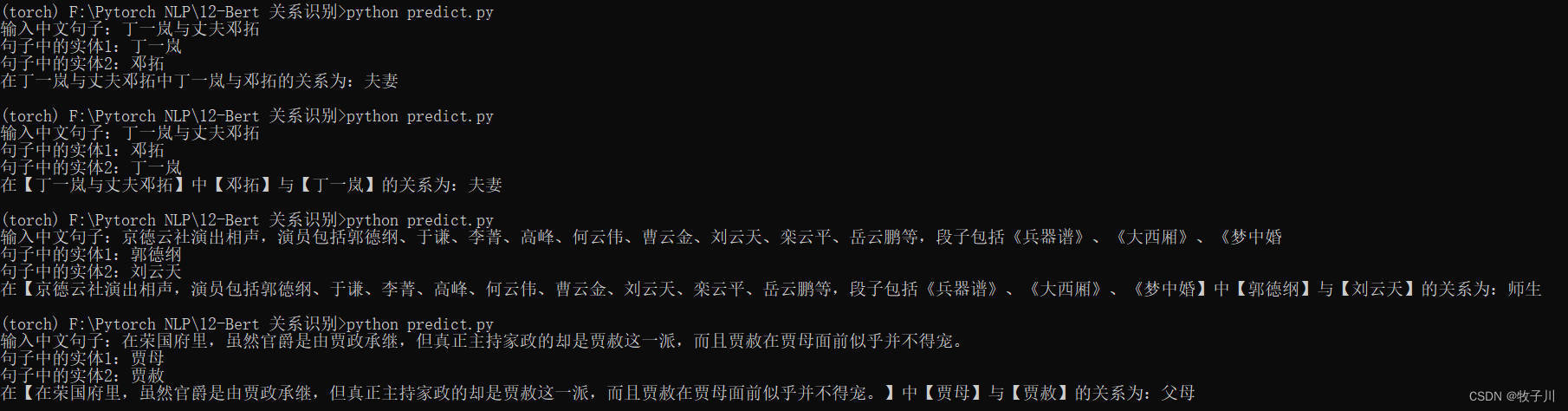
输入中文句子:丁一岚与丈夫邓拓
句子中的实体1:丁一岚
句子中的实体2:邓拓
在丁一岚与丈夫邓拓中丁一岚与邓拓的关系为:夫妻
输入中文句子:丁一岚与丈夫邓拓
句子中的实体1:邓拓
句子中的实体2:丁一岚
在【丁一岚与丈夫邓拓】中【邓拓】与【丁一岚】的关系为:夫妻
输入中文句子:京德云社演出相声,演员包括郭德纲、于谦、李菁、高峰、何云伟、曹云金、刘云天、栾云平、岳云鹏等,段子包括《兵器谱》、《大西厢》、《梦中婚
句子中的实体1:郭德纲
句子中的实体2:刘云天
在【京德云社演出相声,演员包括郭德纲、于谦、李菁、高峰、何云伟、曹云金、刘云天、栾云平、岳云鹏等,段子包括《兵器谱》、《大西厢》、《梦中婚】中【郭德纲】与【刘云天】的关系为:师生
输入中文句子:在荣国府里,虽然官爵是由贾政承继,但真正主持家政的却是贾赦这一派,而且贾赦在贾母面前似乎并不得宠。
句子中的实体1:贾母
句子中的实体2:贾赦
在【在荣国府里,虽然官爵是由贾政承继,但真正主持家政的却是贾赦这一派,而且贾赦在贾母面前似乎并不得宠。】中【贾母】与【贾赦】的关系为:父母
源码获取
Bert 关系识别![]() https://github.com/mzc421/Pytorch-NLP/tree/master/12-Bert%20%E5%85%B3%E7%B3%BB%E8%AF%86%E5%88%AB
https://github.com/mzc421/Pytorch-NLP/tree/master/12-Bert%20%E5%85%B3%E7%B3%BB%E8%AF%86%E5%88%AB
硬性的标准其实限制不了无限可能的我们,所以啊!少年们加油吧!
相关文章:
nlp系列(7)实体识别(Bert)pytorch
模型介绍 本项目是使用Bert模型来进行文本的实体识别。 Bert模型介绍可以查看这篇文章:nlp系列(2)文本分类(Bert)pytorch_bert文本分类_牧子川的博客-CSDN博客 模型结构 Bert模型的模型结构: 数据介绍 …...
Uniapp学习之从零开始写一个简单的小程序demo(新建页面,通过导航切换页面,发送请求)
先把官网文档摆在这,后面会用到的 [uniapp官网文档]: https://uniapp.dcloud.net.cn/vernacular.html# 一、开发工具准备 1-1 安装HBuilder 按照官方推荐,先装一个HBuilder 下载地址: https://www.dcloud.io/hbuilderx.html1-2 安装微信开…...
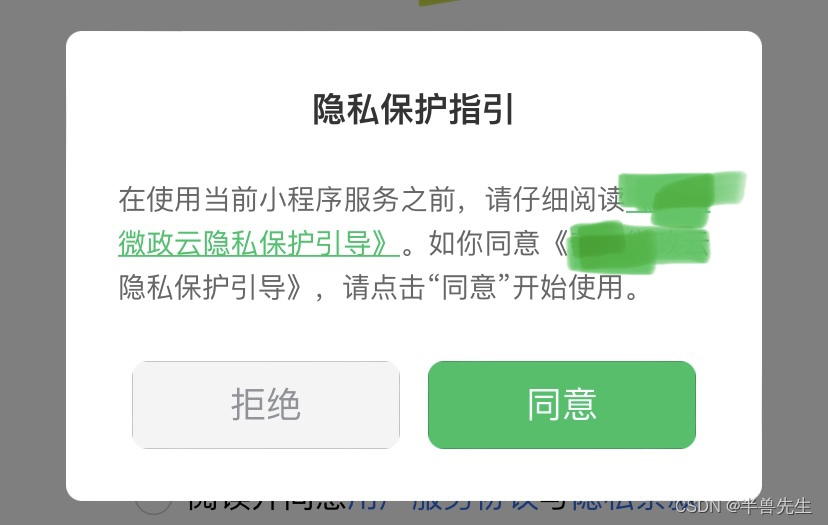
uniapp微信小程序隐私保护引导新规
1.components中新建组件PrivacyPop.vue <template><view class"privacy" v-if"showPrivacy"><view class"content"><view class"title">隐私保护指引</view><view class"des">在使用当…...
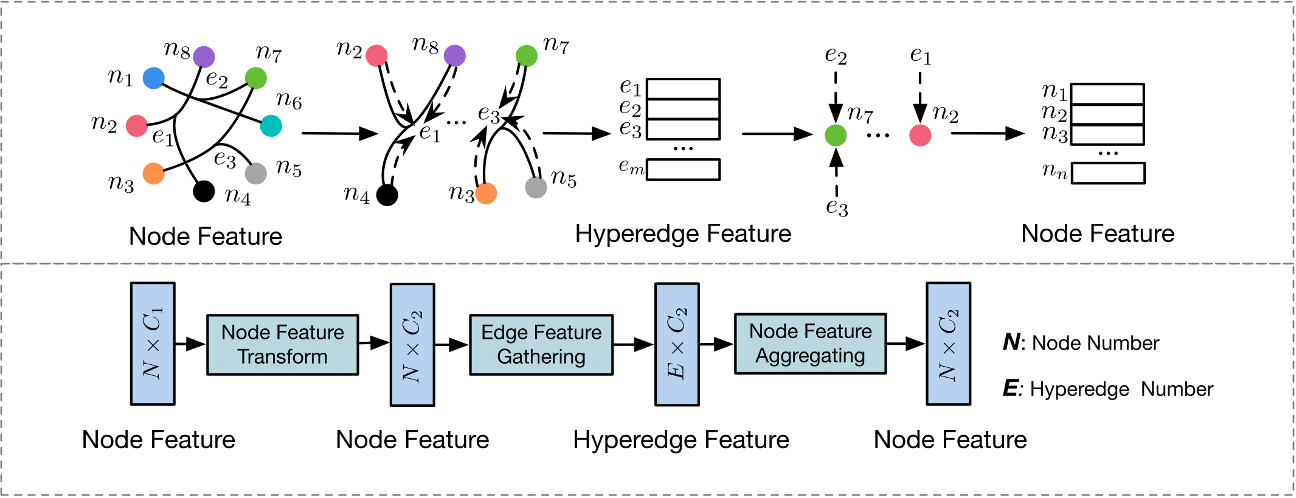
超图嵌入论文阅读2:超图神经网络
超图嵌入论文阅读2:超图神经网络 原文:Hypergraph Neural Networks ——AAAI2019(CCF-A) 源码:https://github.com/iMoonLab/HGNN 500star 概述 贡献:用于数据表示学习的超图神经网络 (HGNN) 框架…...
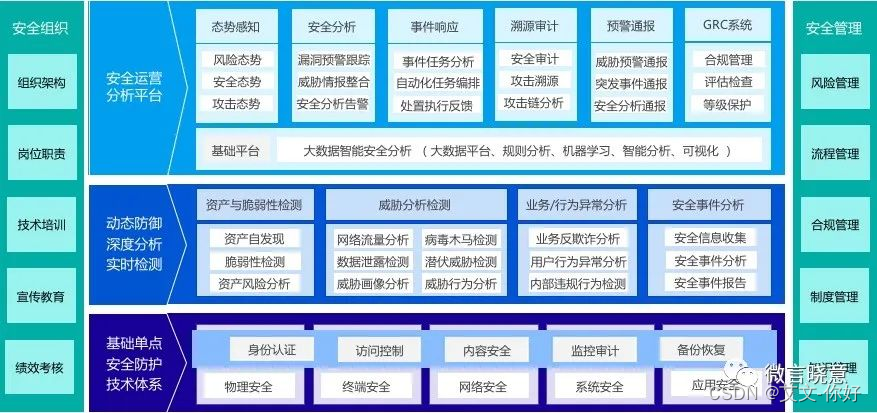
安全运营中心(SOC)技术框架
2018年曾经画过一个安全运营体系框架,基本思路是在基础单点技术防护体系基础上,围绕着动态防御、深度分析、实时检测,建立安全运营大数据分析平台,可以算作是解决方案产品的思路。 依据这个体系框架,当时写了《基于主动…...
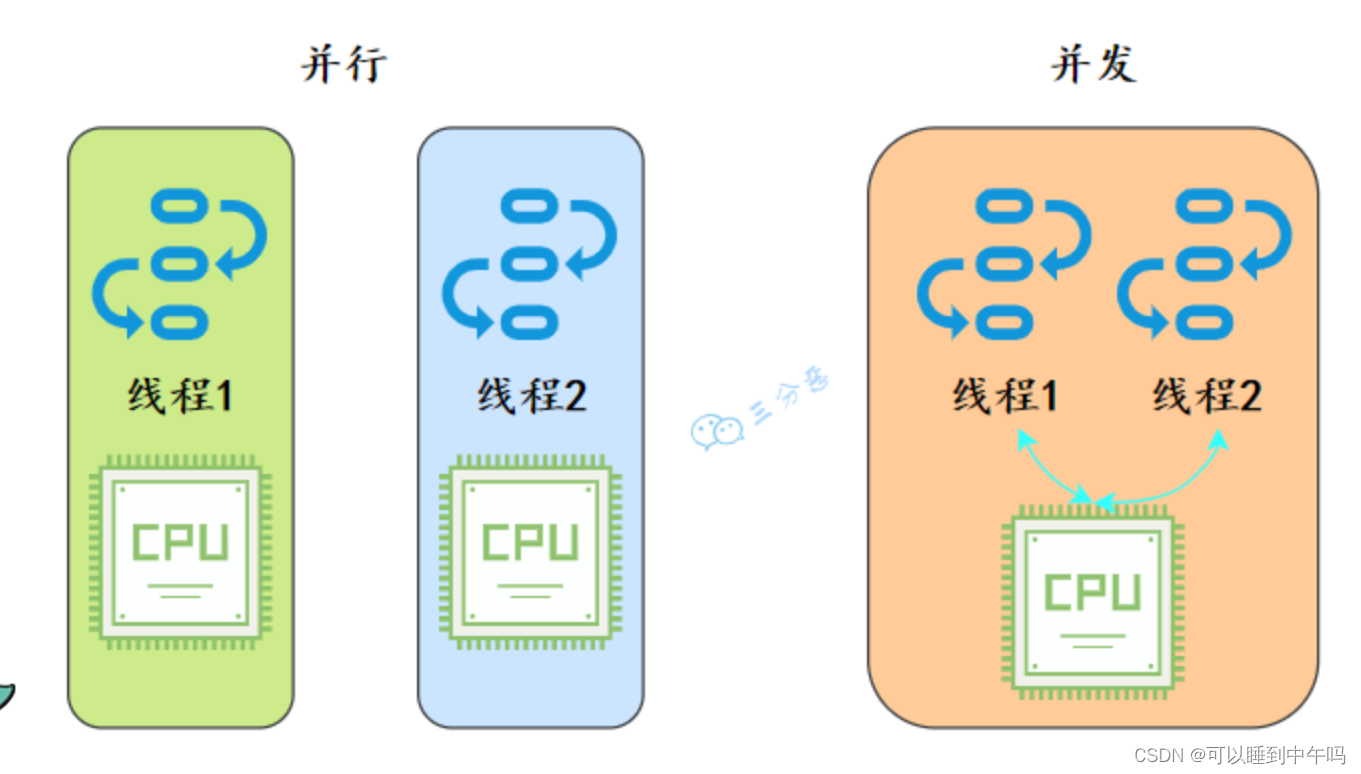
并行和并发的区别
从操作系统的角度来看,线程是CPU分配的最小单位。 并行就是同一时刻,两个线程都在执行。这就要求有两个CPU去分别执行两个线程。并发就是同一时刻,只有一个执行,但是一个时间段内,两个线程都执行了。并发的实现依赖于…...
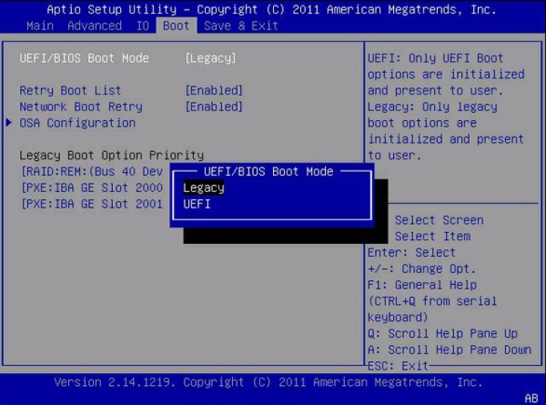
GPT转换工具:轻松将MBR转换为GPT磁盘
为什么需要将MBR转换为GPT? 众所周知,Windows 11已经发布很长时间了。在此期间,许多老用户已经从Windows 10升级到Windows 11。但有些用户仍在运行Windows 10。对于那些想要升级到Win 11的用户来说,他们可能不确定Win 11应该使…...
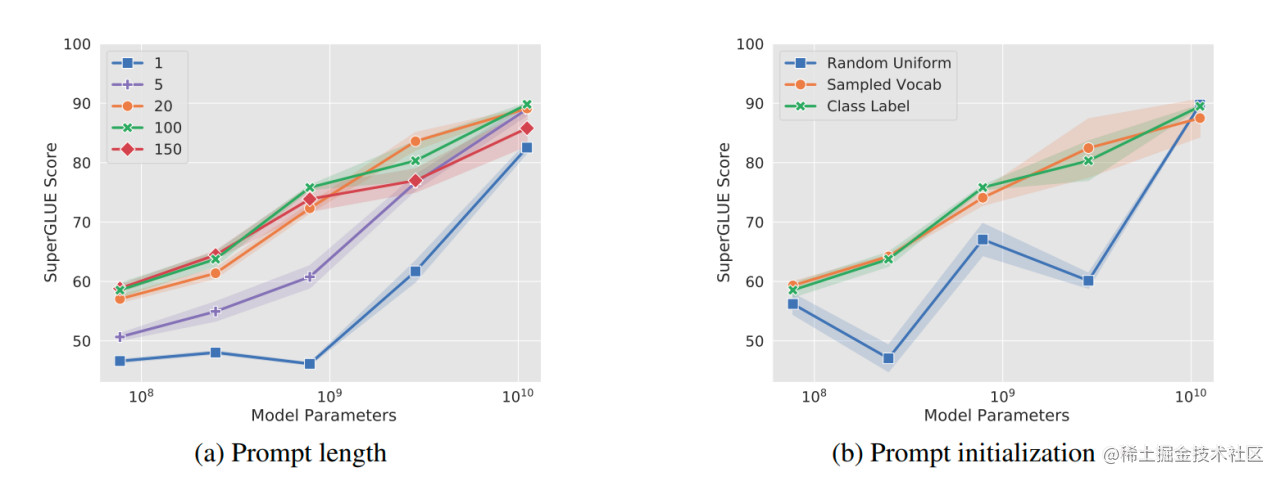
大模型参数高效微调技术原理综述(二)-BitFit、Prefix Tuning、Prompt Tuning
随着,ChatGPT 迅速爆火,引发了大模型的时代变革。然而对于普通大众来说,进行大模型的预训练或者全量微调遥不可及。由此,催生了各种参数高效微调技术,让科研人员或者普通开发者有机会尝试微调大模型。 因此,…...

将conda环境打包成docker步骤
1. 第一步,将conda环境的配置导出到environment.yml 要获取一个Conda环境的配置文件 environment.yml,你可以使用以下命令从已存在的环境中导出: conda env export --name your_env_name > environment.yml请将 your_env_name 替换为你要…...

C# 获取Json对象中指定属性的值
在C#中获取JSON对象中指定属性的值,可以使用Newtonsoft.JSON库的JObject类 using Newtonsoft.Json.Linq; using System; public class Program { public static void Main(string[] args) { string json "{ Name: John, age: 30, City: New York }"; …...
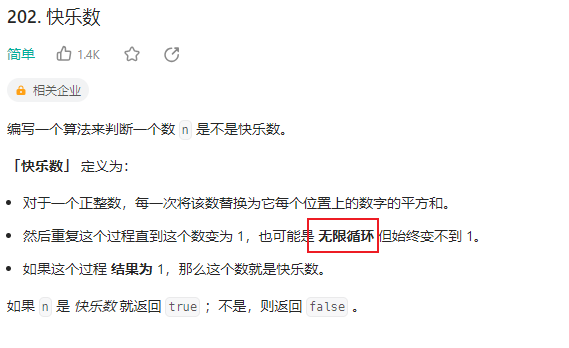
【LeetCode】202. 快乐数 - hash表 / 快慢指针
目录 2023-9-5 09:56:152023-9-6 19:40:51 202. 快乐数 2023-9-5 09:56:15 关键是怎么去判断循环: hash表: 每次生成链中的下一个数字时,我们都会检查它是否已经在哈希集合中。 如果它不在哈希集合中,我们应该添加它。如果它在…...

什么是多态性?如何在面向对象编程中实现多态性?
1、什么是多态性?如何在面向对象编程中实现多态性? 多态性(Polymorphism)是指在同一个方法调用中,由于参数类型不同,而产生不同的行为。在面向对象编程中,多态性是一种重要的特性,它…...
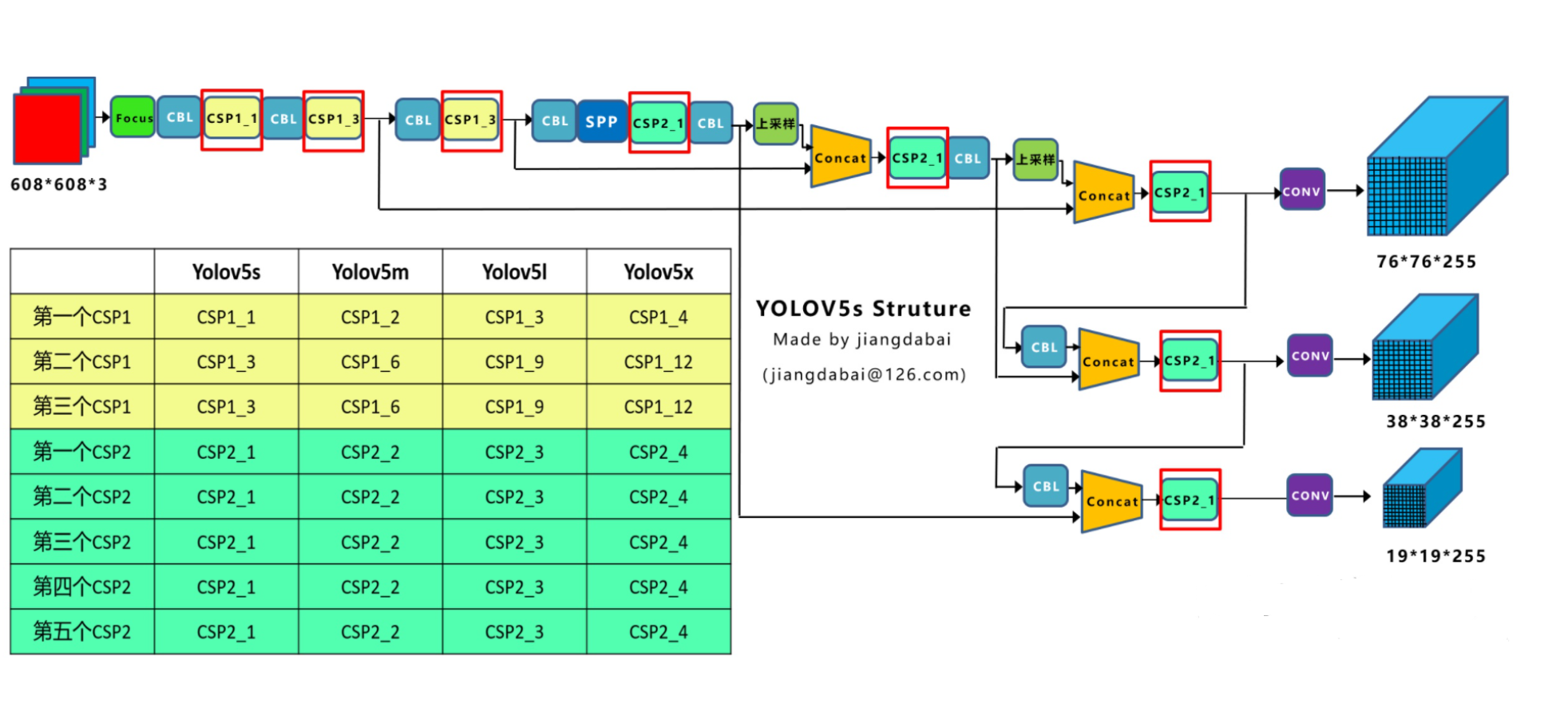
【目标检测】理论篇(3)YOLOv5实现
Yolov5网络构架实现 import torch import torch.nn as nnclass SiLU(nn.Module):staticmethoddef forward(x):return x * torch.sigmoid(x)def autopad(k, pNone):if p is None:p k // 2 if isinstance(k, int) else [x // 2 for x in k] return pclass Focus(nn.Module):def …...
IDEA爪哇操作数据库
少小离家老大回,乡音无改鬓毛衰 ⒈.IDEA2018设置使用主题颜色 IDEA2018主题颜色分为三种:idea原始颜色,高亮色,黑色 设置方法:Settings–Appearance&Behavior–Appearance ⒉.mysql中,没有my.ini,只有…...
一文速学-让神经网络不再神秘,一天速学神经网络基础(七)-基于误差的反向传播
前言 思索了很久到底要不要出深度学习内容,毕竟在数学建模专栏里边的机器学习内容还有一大半算法没有更新,很多坑都没有填满,而且现在深度学习的文章和学习课程都十分的多,我考虑了很久决定还是得出神经网络系列文章,…...

C++ 异常处理——学习记录007
1. 概念 程序中的错误分为编译时错误和运行时错误。编译时出现的错误包括关键字拼写出错、语句分号缺少、括号不匹配等,编译时的错误容易解决。运行时出现的错误包括无法打开文件、数组越界和无法实现指定的操作。运行时出现的错误称为异常,对异常的处理…...

【BIM+GIS】“BIM+”是什么? “BIM+”技术详解
对于我们日常生活影响最大的是信息化和网络化给我们的日常生活带来革命性的变化。“互联网+“在建筑行业里可以称为“BIM+”。“BIM+”"即是通过BIM与各类技术(互联网、大数据等)结合去完成不同的任务。将产品的全生命周期和全制造流程的数字化以及基于信息通信技术的模块…...

Flink算子如何限流
目录 使用方法 调用类图 内部源码 GuavaFlinkConnectorRateLimiter RateLimiter 使用方法 重写AbstractRichFunction中的open()方法,在处理数据前调用limiter.acquire(1); 调用limiter.open(getRuntimeContext())的源码,实际内部是RateLimiter,根据并行度算出subTask…...

垃圾分代收集的过程是怎样的?
垃圾分代收集是Java虚拟机(JVM)中一种常用的垃圾回收策略。该策略将堆内存分为不同的代(Generation),通常分为年轻代(Young Generation)和老年代(Old Generation)。不同代的对象具有不同的生命周期和回收频率。 下面是Java中垃圾分代收集的一般过程: 1…...
NPM 常用命令(四)
目录 1、npm diff 1.1 描述 1.2 过滤文件 1.3 配置 diff diff-name-only diff-unified diff-ignore-all-space diff-no-prefix diff-src-prefix diff-dst-prefix diff-text global tag workspace workspaces include-workspace-root 2、npm dist-tag 2.1 常…...

从myplaces.shp到专题地图:手把手教你用QGIS C++ API实现点要素分级渲染
从myplaces.shp到专题地图:QGIS C API实现点要素分级渲染实战指南 当我们需要在桌面GIS应用中直观展示气象站降雨量、城市人口密度或商业网点销售额等连续型空间数据时,分级色彩渲染是最有效的可视化手段之一。本文将深入探讨如何利用QGIS强大的C API&am…...

芯片老化座的工作温度范围?
在芯片测试领域,老化座(Burn-in Socket)是保障半导体器件长期可靠性的关键设备。它不仅要在极端温度下稳定工作,还要确保测试数据的精准度。今天,我们以HMILU(深圳市鸿怡电子有限公司)为例&…...

终极指南:如何用BabelDOC彻底解决PDF翻译格式错乱问题
终极指南:如何用BabelDOC彻底解决PDF翻译格式错乱问题 【免费下载链接】BabelDOC Yet Another Document Translator 项目地址: https://gitcode.com/GitHub_Trending/ba/BabelDOC 还在为学术论文翻译后排版全乱而烦恼吗?😫 技术文档翻…...

AI驱动代码审查:Cursor与Git工作流融合实践
1. 项目概述:当AI代码助手遇上代码审查最近在GitHub上看到一个挺有意思的项目,叫guinacio/cursor-review。光看名字,你可能会觉得这又是一个普通的代码审查工具,但点进去仔细研究,你会发现它的核心思路非常巧妙&#x…...

AI原生产品管理:多智能体协作如何重塑产品开发工作流
1. 项目概述:当AI成为你的产品经理最近在GitHub上看到一个挺有意思的项目,叫NathanJCW/ai-native-pm-cortex。光看名字,你大概能猜到它想做什么——“AI原生的产品经理大脑”。这可不是一个简单的聊天机器人插件,它试图构建一个完…...

轻量级服务器监控面板:从原理到部署实战
1. 项目概述:一个开源监控面板的诞生最近在折腾服务器和容器化应用,发现一个挺普遍的需求:当你手头有几台服务器,上面跑着几个Docker容器,或者一些自己写的服务,你总想知道它们现在“活”得怎么样。CPU是不…...

基于语义搜索的AI代码理解工具copaw-code深度解析
1. 项目概述:一个面向代码搜索与理解的AI工具 最近在GitHub上看到一个挺有意思的项目,叫 QSEEKING/copaw-code 。乍一看这个标题,可能会有点摸不着头脑,“copaw”是什么?但结合“code”和项目托管在QSEEKING这个组织…...

OpenAgentsControl:构建多智能体协同系统的开源框架解析
1. 项目概述:一个面向智能体控制的开放框架最近在折腾AI智能体(Agent)相关的项目,发现一个挺有意思的开源仓库:darrenhinde/OpenAgentsControl。这个项目名字直译过来就是“开放智能体控制”,听起来就很有搞…...

MPLAB代码配置器实战:图形化配置PIC/AVR单片机外设,提升开发效率
1. 项目概述:为什么你需要关注MPLAB代码配置器如果你正在使用Microchip的PIC或AVR单片机,并且还在手动编写外设初始化代码、一遍遍翻阅数据手册核对寄存器位,那今天聊的这个工具,可能会让你有种“相见恨晚”的感觉。我说的就是MPL…...

基于Python/Flask的洗车店业务管理系统设计与实现
1. 项目概述:从“洗车”到“洗车服务”的数字化重构最近在GitHub上看到一个挺有意思的项目,叫“washing-cars”。光看名字,你可能会觉得这只是一个关于洗车的小工具或者记录表。但当我深入进去,才发现它远不止于此。这个项目本质上…...