【跟小嘉学 Rust 编程】二十三、Cargo 使用指南
系列文章目录
【跟小嘉学 Rust 编程】一、Rust 编程基础
【跟小嘉学 Rust 编程】二、Rust 包管理工具使用
【跟小嘉学 Rust 编程】三、Rust 的基本程序概念
【跟小嘉学 Rust 编程】四、理解 Rust 的所有权概念
【跟小嘉学 Rust 编程】五、使用结构体关联结构化数据
【跟小嘉学 Rust 编程】六、枚举和模式匹配
【跟小嘉学 Rust 编程】七、使用包(Packages)、单元包(Crates)和模块(Module)来管理项目
【跟小嘉学 Rust 编程】八、常见的集合
【跟小嘉学 Rust 编程】九、错误处理(Error Handling)
【跟小嘉学 Rust 编程】十一、编写自动化测试
【跟小嘉学 Rust 编程】十二、构建一个命令行程序
【跟小嘉学 Rust 编程】十三、函数式语言特性:迭代器和闭包
【跟小嘉学 Rust 编程】十四、关于 Cargo 和 Crates.io
【跟小嘉学 Rust 编程】十五、智能指针(Smart Point)
【跟小嘉学 Rust 编程】十六、无畏并发(Fearless Concurrency)
【跟小嘉学 Rust 编程】十七、面向对象语言特性
【跟小嘉学 Rust 编程】十八、模式匹配(Patterns and Matching)
【跟小嘉学 Rust 编程】十九、高级特性
【跟小嘉学 Rust 编程】二十、进阶扩展
【跟小嘉学 Rust 编程】二十一、网络编程
【跟小嘉学 Rust 编程】二十三、Cargo 使用指南
文章目录
- 系列文章目录
- @[TOC](文章目录)
- 前言
- 一、 Cargo 介绍
- 1.1、Cargo 是什么
- 1.2、上手使用
- 1.3、为什么要有 Cargo
- 二、依赖构建和项目结构
- 2.1、添加依赖
- 2.2、更新依赖
- 2.3、Cargo 推荐的目录结构
- 三、Cargo.toml 和 Cargo.lock
- 3.1、介绍
- 3.2、是否要上传 Cargo.lock
- 四、测试和CI
- 4.1、测试
- 4.2、持续集成(Continuous Integration,CICI)
- 五、Cargo 缓存
- 5.1、CARGO_HOME
- 5.2、缓存
- 六、Cargo build 缓存
- 6.1、编译目录
- 6.2、sccache
- 七、引入依赖包方式
- 7.1、使用 cargo add 方式
- 7.2、手动方式
- 7.2.1、版本号
- 7.2.2、git 仓库作为依赖包
- 7.2.3、通过路径引入本地依赖包
- 7.2.4、根据平台引入依赖
- 八、依赖覆盖
- 九、Cargo.toml 详解
- 9.1、[package]
- 9.2、[badges]
- 9.3、[*-dependencies]
- 9.4、[profile.*]
- 十、Cargo Target
- 10.1、库对象(Library)
- 10.2、二进制对象(Binary)
- 10.3、示例对象(Examples)
- 10.4、测试对象(Tests)
- 10.5、基准性能对象(Benches)
- 10.6、 配置对象
- 10.7、对象自动发现
- 十一、工作空间
- 11.1、工作空的两种类型
- 11.1.1、root package
- 11.1.2、虚拟清单(Virtual manifest)
- 11.2、选择工作空间
- 十二、条件编译和可选依赖
- 12.1、features
- 12.2、可选依赖
- 12.2、依赖库自身的 feature
- 12.3、通过 命令行参数启用 feature
- 12.4、feature 同一化
- 12.5、彼此互斥的 feature
- 12.6、检视已解析的features
- 12.7、Feature 解析器 V2 版本
- 12.6、SemVer 兼容性
- 12.7、feature文档和发现
- 12.7.1、feature文档
- 12.7.2、如何发现 features
- 十三、构建脚本 build.rs
- 13.1、构建脚本
- 13.2、build.rs
- 13.3、构建脚本的生命周期
- 13.4、构建脚本的输入
- 13.5、构建脚本的输出
- 13.6、构建脚本的依赖
- 13.7、links
- 13.8、覆盖构建脚本
- 13.9、示例:build.rs
- 13.9.1、社区提供的功能
- 13.9.2、代码生成
- 13.9.3、构建本地库
- 13.9.3.1、使用
- 13.9.3.2、cc依赖
- 13.9.4、链接系统库
- 13.9.5、其他 sys 包
- 13.9.6、条件编译
- 总结
文章目录
- 系列文章目录
- @[TOC](文章目录)
- 前言
- 一、 Cargo 介绍
- 1.1、Cargo 是什么
- 1.2、上手使用
- 1.3、为什么要有 Cargo
- 二、依赖构建和项目结构
- 2.1、添加依赖
- 2.2、更新依赖
- 2.3、Cargo 推荐的目录结构
- 三、Cargo.toml 和 Cargo.lock
- 3.1、介绍
- 3.2、是否要上传 Cargo.lock
- 四、测试和CI
- 4.1、测试
- 4.2、持续集成(Continuous Integration,CICI)
- 五、Cargo 缓存
- 5.1、CARGO_HOME
- 5.2、缓存
- 六、Cargo build 缓存
- 6.1、编译目录
- 6.2、sccache
- 七、引入依赖包方式
- 7.1、使用 cargo add 方式
- 7.2、手动方式
- 7.2.1、版本号
- 7.2.2、git 仓库作为依赖包
- 7.2.3、通过路径引入本地依赖包
- 7.2.4、根据平台引入依赖
- 八、依赖覆盖
- 九、Cargo.toml 详解
- 9.1、[package]
- 9.2、[badges]
- 9.3、[*-dependencies]
- 9.4、[profile.*]
- 十、Cargo Target
- 10.1、库对象(Library)
- 10.2、二进制对象(Binary)
- 10.3、示例对象(Examples)
- 10.4、测试对象(Tests)
- 10.5、基准性能对象(Benches)
- 10.6、 配置对象
- 10.7、对象自动发现
- 十一、工作空间
- 11.1、工作空的两种类型
- 11.1.1、root package
- 11.1.2、虚拟清单(Virtual manifest)
- 11.2、选择工作空间
- 十二、条件编译和可选依赖
- 12.1、features
- 12.2、可选依赖
- 12.2、依赖库自身的 feature
- 12.3、通过 命令行参数启用 feature
- 12.4、feature 同一化
- 12.5、彼此互斥的 feature
- 12.6、检视已解析的features
- 12.7、Feature 解析器 V2 版本
- 12.6、SemVer 兼容性
- 12.7、feature文档和发现
- 12.7.1、feature文档
- 12.7.2、如何发现 features
- 十三、构建脚本 build.rs
- 13.1、构建脚本
- 13.2、build.rs
- 13.3、构建脚本的生命周期
- 13.4、构建脚本的输入
- 13.5、构建脚本的输出
- 13.6、构建脚本的依赖
- 13.7、links
- 13.8、覆盖构建脚本
- 13.9、示例:build.rs
- 13.9.1、社区提供的功能
- 13.9.2、代码生成
- 13.9.3、构建本地库
- 13.9.3.1、使用
- 13.9.3.2、cc依赖
- 13.9.4、链接系统库
- 13.9.5、其他 sys 包
- 13.9.6、条件编译
- 总结
前言
接下来的章节讲详细讲解 Cargo 的具体使用,对于之前 Cargo 的介绍是一种补充或者说是更加详细的介绍,已经工程上的最佳实践方案。
主要教材参考 《The Rust Programming Language》
主要教材参考 《Rust For Rustaceans》
主要教材参考 《The Rustonomicon》
主要教材参考 《Rust 高级编程》
主要教材参考 《Cargo 指南》
一、 Cargo 介绍
1.1、Cargo 是什么
Cargo 是 Rust 的包管理工具,可以用于依赖包的下载、编译、更新、分发等操作。与 Cargo 一起 还有 crate.io,它为社区提供包注册服务,用户可以将自己的包发布到 crate.io。
1.2、上手使用
我们可以使用 cargo new 来创建一个二进制项目,省略了 --bin 参数,该命令我们已经在基础章节讲解过了,这里只做简单的回顾。
cargo new hello_world --bin
cargo new hello_world
生成的 Cargo.toml, 我们称之为清单(manifest),包含了 Cargo 编译程序所需要的所有元数据。
我们可以使用 cargo build 编译我们的 Rust 程序,使用 cargo run 执行我们的二进制程序
cargo buld
cargo run
1.3、为什么要有 Cargo
Rust 有两种类型的包:库包和二进制包。包是通过 Rust 编译器(rustc)进行编译的。
rustc hello.rs
./hello
上述命令,我们使用 rustc 对二进制包进行编译,生成二进制可执行文件。但是当我们需要依赖的外部库越来越多,这种情况下我们使用 rustc 就不太方便了。
Cargo为我们解决了如下几件事
- 引入两个元数据文件,包含项目的方方面面信息: Cargo.toml 和 Cargo.lock
- 获取和构建项目的依赖,例如 Cargo.toml 中的依赖包版本描述,以及从 crates.io 下载包
- 调用 rustc (或其它编译器) 并使用的正确的参数来构建项目,例如 cargo build
- 引入一些惯例,让项目的使用更加简单
二、依赖构建和项目结构
2.1、添加依赖
我们可以在 crate.io 上寻找我们需要的包,默认就是从这里下载依赖。
添加依赖有两种方式
- 使用 cargo add 命令来进行依赖添加,此时会自动下载依赖包
cargo add time
- 手动在 cargo.toml 上添加相应的依赖文件,这种方式只有 cargo build 之后才会下载依赖,更新 Cargo.lock。
[dependencies]
time = "0.3.28"
2.2、更新依赖
cargo update
2.3、Cargo 推荐的目录结构
- Cargo.toml 和 Cargo.lock 保存在 package 根目录下
- 源代码放在 src 目录下
- 默认的 lib 包根是 src/lib.rs
- 默认的二进制包根是 src/main.rs
- 其它二进制包根放在 src/bin/ 目录下
- 基准测试 benchmark 放在 benches 目录下
- 示例代码放在 examples 目录下
- 集成测试代码放在 tests 目录下
此外 bin、tests、example等路径都可以通过配置文件进行配置,他们被称为 Carogo Target。
目录结构
.
├── Cargo.lock
├── Cargo.toml
├── src/
│ ├── lib.rs
│ ├── main.rs
│ └── bin/
│ ├── named-executable.rs
│ ├── another-executable.rs
│ └── multi-file-executable/
│ ├── main.rs
│ └── some_module.rs
├── benches/
│ ├── large-input.rs
│ └── multi-file-bench/
│ ├── main.rs
│ └── bench_module.rs
├── examples/
│ ├── simple.rs
│ └── multi-file-example/
│ ├── main.rs
│ └── ex_module.rs
└── tests/├── some-integration-tests.rs└── multi-file-test/├── main.rs└── test_module.rs三、Cargo.toml 和 Cargo.lock
3.1、介绍
Cargo.toml 和 Cargo.lock 是 Cargo 的两个元配置文件
- Cargo.toml 主要是从用户角度护发描述项目信息和依赖管理的,因此它由用户编写;
- Cargo.lock 包含了依赖的精确描述信息,由 Cargo 自行维护,因此不要去首都修改。
3.2、是否要上传 Cargo.lock
- 如果你构建的是三方类型的服务,请把 Cargo.lock 加入到 .gitignore;
- 若构建的是一个面向用户终端的产品,例如可以像命令行工具、应用程一样执行,那就把 Cargo.lock 上传到源代码目录中。
因为 Cargo.lock 会详尽描述上一次成功构建的各种信息:环境状态、依赖、版本等,Cargo 可以使用它提供确定性的构建环境和流程,无论何时何地。这种特性对于终端服务是非常重要的:能确定、稳定的在用户环境中运行起来是终端服务最重要的特性之一。
Cargo 上如果只依赖源与 git 仓库上信息,没有指定版本,那么将会自动拉去最新的版本。
四、测试和CI
4.1、测试
我们已经讲解过了 使用 cargo test 命令可以运行项目中的测试文件:
- src/库文件下单元测试
- tests/目录下的集成测试
- examples下的示例文件
- 文档中的测试
很不信,Rust 原生的性能测试还属于实验性的阶段。
4.2、持续集成(Continuous Integration,CICI)
持续集成是软件开发中异常重要的一环,大家应该都听说过 Jenkins,它就是一个拥有悠久历史的持续集成工具。简单来说,持续集成会定期拉取同一个项目中所有成员的相关代码,对其进行自动化构建。
在没有持续集成前,首先开发者需要手动编译代码并运行单元测试、集成测试等基础测试,然后启动项目相关的所有服务,接着测试人员开始介入对整个项目进行回归测试、黑盒测试等系统化的测试,当测试通过后,最后再手动发布到指定的环境中运行,这个过程是非常冗长,且所有成员都需要同时参与的。
在有了持续集成后,只要编写好相应的编译、测试、发布配置文件,那持续集成平台会自动帮助我们完成整个相关的流程,期间无需任何人介入,高效且可靠。
.travis.yml
language: rust
rust:- stable- beta- nightly
matrix:allow_failures:- rust: nightly
或使用别的工具进行 Ci 集成 可以参考对应文档
https://doc.rust-lang.org/cargo/guide/continuous-integration.html
五、Cargo 缓存
5.1、CARGO_HOME
Cargo 使用缓存的方式提升构建效率,当构建时,Cargo 会将已下载的依赖包放在 CARGO_HOME 目录下。
默认情况下,Cargo Home 所在的目录是 $HOME/.cargo/
文件
- config.toml cargo的全局配置文件
- credentials.toml 为cargo login 提供私有化登录证书,用于登录 package 注册中心
- .crates.toml 和.crates2.json 隐藏文件,包含了 cargo install 安装的包信息,不要手动修改
目录
- bin 目录包含了通过 cargo install 或 rustup 下载的包编译出的可执行文件。你可以将该目录加入到 $PATH 环境变量中,以实现对这些可执行文件的直接访问
- git 中存储了 Git 的资源文件:
- git/db,当一个包依赖某个 git 仓库时,Cargo 会将该仓库克隆到 git/db 目录下,如果未来需要还会对其进行更新
- git/checkouts,若指定了 git 源和 commit,那相应的仓库就会从 git/db 中 checkout 到该目录下,因此同一个仓库的不同 checkout 共存成为了可能性
- registry 包含了注册中心( 例如 crates.io )的元数据 和 packages
- registry/index 是一个 git 仓库,包含了注册中心中所有可用包的元数据( 版本、依赖等 )
- registry/cache 中保存了已下载的依赖,这些依赖包以 gzip 的压缩档案形式保存,后缀名为 .crate
- registry/src,若一个已下载的 .crate 档案被一个 package 所需要,该档案会被解压缩到 registry/src 文件夹下,最终 rustc 可以在其中找到所需的 .rs 文件
5.2、缓存
在 CI 构建时,出于效率的考虑,我们仅应该缓存以下目录:
- bin/
- registry/index/
- registry/cache/
- git/db/
理论上,我们可以使用手动去删除缓存
六、Cargo build 缓存
6.1、编译目录
cargo build 会把结果放入到项目根目录下的 target 目录中,这个位置可以有三种方式修改
- 设置 CARGO_TARGET_DIR 环境变量
- build.target-dir 配置项
- –target-dir 命令行参数。
target 目录结构取决于是否使用 --target 标志为特定的平台构建
| 目录 | 描述 |
|---|---|
| target/debug | 包含了 dev profile 的构建输出(cargo build 或 cargo build --debug) |
| target/release | release profile 的构建输出,cargo build --release |
处于历史原因
- dev 和 test profile 的构建结果都存放在 debug 目录
- release 和 bench profile 则存放在 release 目录
如果你使用了 --target 参数 ,则会在 target/xx/ 目录
6.2、sccache
第三方构建工具,共享缓存。
七、引入依赖包方式
7.1、使用 cargo add 方式
cargo add time
7.2、手动方式
[dependencies]
time = "0.3.28"
7.2.1、版本号
- 指定版本号
包 = 版本号,这里版本号 采用 “major.minor.patch” 形式。
- 使用版本范围
^
^1.2.3 := >=1.2.3, <2.0.0
^1.2 := >=1.2.0, <2.0.0
^1 := >=1.0.0, <2.0.0
^0.2.3 := >=0.2.3, <0.3.0
^0.2 := >=0.2.0, <0.3.0
^0.0.3 := >=0.0.3, <0.0.4
^0.0 := >=0.0.0, <0.1.0
^0 := >=0.0.0, <1.0.0
- 使用版本范围
~
制定最小化版本号
~1.2.3 := >=1.2.3, <1.3.0
~1.2 := >=1.2.0, <1.3.0
~1 := >=1.0.0, <2.0.0
*通配符
* := >=0.0.0
1.* := >=1.0.0, <2.0.0
1.2.* := >=1.2.0, <1.3.0
不过 crates.io 并不允许我们只使用 * 指定版本号。
- 比较符
可以使用比较符的方式来指定一个版本号范围或一个精确的版本号:
>= 1.2.0
> 1
< 2
= 1.2.3>= 1.2, < 1.5
7.2.2、git 仓库作为依赖包
- 默认不指定版本,从主分支拉去最新 commit
[dependencies]
regex = { git = "https://github.com/rust-lang/regex" }
- 指定分支
[dependencies]
regex = { git = "https://github.com/rust-lang/regex", branch = "next" }
任何非 tag 和 branch 的类型都可以通过 rev 来引入 例如 rev= “hash”
7.2.3、通过路径引入本地依赖包
[dependencies]
hello_utils = { path = "hello_utils" }
# 以下路径也可以
# hello_utils = { path = "./hello_utils" }
# hello_utils = { path = "../hello_world/hello_utils" }
7.2.4、根据平台引入依赖
[target.'cfg(windows)'.dependencies]
winhttp = "0.4.0"[target.'cfg(unix)'.dependencies]
openssl = "1.0.1"[target.'cfg(target_arch = "x86")'.dependencies]
native = { path = "native/i686" }[target.'cfg(target_arch = "x86_64")'.dependencies]
native = { path = "native/x86_64" }
八、依赖覆盖
如果我们依赖的包发现了 bug,不能等待官方修复发布,我们可以手动 clone 代码,本地修复后使用路径引入方式引入。
但是我们需要修改版本号,然后使用 cargo update -p uuid --precise 0.8.3 更新
修复 bug 后可以提交给依赖库官方提交 pull request。
九、Cargo.toml 详解
9.1、[package]
用于设置项目的相关信息、name必填)、version(必填)、authors、edition、rust-version、description、documentation、readme、homepage、repository、license、license-file、keywords、categories、workspace、build、links、exclude、include、publish、metadata、default-run
9.2、[badges]
该部分用于指定项目当前的状态,该状态会展示在 crates.io 的项目主页中,例如以下配置可以设置项目的维护状态:
[badges]
# `maintenance` 是项目的当前维护状态,它可能会被其它注册服务所使用,但是目前还没有被 `crates.io` 使用: https://github.com/rust-lang/crates.io/issues/2437
#
# `status` 字段时必须的,以下是可用的选项:
# - `actively-developed`: 新特性正在积极添加中,bug 在持续修复中
# - `passively-maintained`: 目前没有计划去支持新的特性,但是项目维护者可能会回答你提出的 issue
# - `as-is`: 该项目的功能已经完结,维护者不准备继续开发和提供支持了,但是它的功能已经达到了预期
# - `experimental`: 作者希望同大家分享,但是还不准备满足任何人的特殊要求
# - `looking-for-maintainer`: 当前维护者希望将项目转移给新的维护者
# - `deprecated`: 不再推荐使用该项目,需要说明原因以及推荐的替代项目
# - `none`: 不显示任何 badge ,因此维护者没有说明他们的状态,用户需要自己去调查发生了什么
maintenance = { status = "..." }
9.3、[*-dependencies]
9.4、[profile.*]
十、Cargo Target
库对象 Library 、二进制对象 Binary、示例对象 Examples、测试对象 Tests 和 基准性能对象 Benches 都是 Cargo Target
10.1、库对象(Library)
库对象用于定义一个库,该库可以被其它的库或者可执行文件所链接。该对象包含的默认文件名是 src/lib.rs,且默认情况下,库对象的名称跟项目名是一致的。
一个工程只能有一个库对象,因此也只能有一个 src/lib.rs 文件,以下是一种自定义配置:
# 一个简单的例子:在 Cargo.toml 中定制化库对象
[lib]
crate-type = ["cdylib"]
bench = false
10.2、二进制对象(Binary)
二进制对象在被编译后可以生成可执行的文件,默认的文件名是 src/main.rs,二进制对象的名称跟项目名也是相同的。
大家应该还记得,一个项目拥有多个二进制文件,因此一个项目可以拥有多个二进制对象。当拥有多个对象时,对象的文件默认会被放在 src/bin/ 目录下。
二进制对象可以使用库对象提供的公共 API,也可以通过 [dependencies] 来引入外部的依赖库。
我们可以使用 cargo run --bin <bin-name> 的方式来运行指定的二进制对象,以下是二进制对象的配置示例:
# Example of customizing binaries in Cargo.toml.
[[bin]]
name = "cool-tool"
test = false
bench = false[[bin]]
name = "frobnicator"
required-features = ["frobnicate"]
10.3、示例对象(Examples)
示例对象的文件在根目录下的 examples 目录中。既然是示例,自然是使用项目中的库对象的功能进行演示。示例对象编译后的文件会存储在 target/debug/examples 目录下。
如上所示,示例对象可以使用库对象的公共 API,也可以通过 [dependencies] 来引入外部的依赖库。
默认情况下,示例对象都是可执行的二进制文件( 带有 fn main() 函数入口),毕竟例子是用来测试和演示我们的库对象,是用来运行的。而你完全可以将示例对象改成库的类型:
[[example]]
name = "foo"
crate-type = ["staticlib"]
如果想要指定运行某个示例对象,可以使用 cargo run --example <example-name>命令。如果是库类型的示例对象,则可以使用 cargo build --example <example-name> 进行构建。
与此类似,还可以使用 cargo install --example <example-name> 来将示例对象编译出的可执行文件安装到默认的目录中,将该目录添加到 $PATH 环境变量中,就可以直接全局运行安装的可执行文件。
最后,cargo test 命令默认会对示例对象进行编译,以防止示例代码因为长久没运行,导致严重过期以至于无法运行。
10.4、测试对象(Tests)
试对象的文件位于根目录下的 tests 目录中,如果大家还有印象的话,就知道该目录是集成测试所使用的。
当运行 cargo test 时,里面的每个文件都会被编译成独立的包,然后被执行。
测试对象可以使用库对象提供的公共 API,也可以通过 [dependencies] 来引入外部的依赖库。
10.5、基准性能对象(Benches)
该对象的文件位于 benches 目录下,可以通过 cargo bench 命令来运行。很遗憾,Rust 官方的基准性能测试还属于 nightly 实验性 api。
10.6、 配置对象
我们可以通过 Cargo.toml 中的 [lib]、[[bin]]、[[example]]、[[test]] 和 [[bench]] 部分对以上对象进行配置。
库对象只有一个,所以只能使用 [lib] 形式,其余对象都是数组。
[lib]
name = "foo" # 对象名称: 库对象、`src/main.rs` 二进制对象的名称默认是项目名
path = "src/lib.rs" # 对象的源文件路径
test = true # 能否被测试,默认是 true
doctest = true # 文档测试是否开启,默认是 true
bench = true # 基准测试是否开启
doc = true # 文档功能是否开启
plugin = false # 是否可以用于编译器插件(deprecated).
proc-macro = false # 是否是过程宏类型的库
harness = true # 是否使用libtest harness : https://doc.rust-lang.org/stable/rustc/tests/index.html
edition = "2015" # 对象使用的 Rust Edition
crate-type = ["lib"] # 生成的包类型,可选的有bin、lib、rlib、dylib、cdylib、staticlib 和 proc-macro
required-features = [] # 构建对象所需的 Cargo Features (N/A for lib).
required-features 用于指定构建对象时所需要的 features 列表,对于 lib 没有任何效果。
10.7、对象自动发现
默认情况下,Cargo 会基于项目的目录文件布局自动发现和确定对象,而之前的配置规则允许我们对其进行手动的配置修改。
[package]
# ...
autobins = false
autoexamples = false
autotests = false
autobenches = false
我们只有在特定的场景下才禁用自动对象发现。
十一、工作空间
一个工作空间是由多个 package 组成的集合,他们共享同一个 cargo.lock 文件、输出目录和一些设置(例如 profiles 编译器设置和优化),组成工作空间的 packages 也被称之为工作空间的成员。
工作空间的特点
- 所有的 package 共享同一个 Cargo.lock 文件,该文件位于工作空间的根目录中
- 所有的 package 共享同一个输出目录,该目录默认的名称是 target,位于工作空间根目录下
- 只有工作空间的根目录 Cargo.toml 才能包含 [patch], [replace] 和 [profile.*],而成员的 Cargo.toml 中的相应部分将被自动忽略
11.1、工作空的两种类型
11.1.1、root package
若一个 package 的 Cargo.toml 包含了[package] 的同时又包含了 [workspace] 部分,则该 package 被称为工作空间的根 package。
换而言之,一个工作空间的根( root )是该工作空间的 Cargo.toml 文件所在的目录。
11.1.2、虚拟清单(Virtual manifest)
若一个 Cargo.toml 有 [workspace] 但是没有 [package] 部分,则它是虚拟清单类型的工作空间。
对于没有主 package 的场景或你希望将所有的 package 组织在单独的目录中时,这种方式就非常适合。
11.2、选择工作空间
选择工作空间有两种方式:Cargo 自动查找、手动指定 package.workspace 字段。
当位于工作空间的子目录中时,Cargo 会自动在该目录的父目录中寻找带有 [workspace] 定义的 Cargo.toml,然后再决定使用哪个工作空间。
我们还可以使用下面的方法来覆盖 Cargo 自动查找功能:将成员包中的 package.workspace 字段修改为工作区间根目录的位置,这样就能显式地让一个成员使用指定的工作空间。
当成员不在工作空间的子目录下时,这种手动选择工作空间的方法就非常适用。毕竟 Cargo 的自动搜索是沿着父目录往上查找,而成员并不在工作空间的子目录下,这意味着顺着成员的父目录往上找是无法找到该工作空间的 Cargo.toml 的,此时就只能手动指定了。
1、选择 package
cargo build -p
cargo build --package
cargo build --workspace
2、workspace.metadata
workspace.metadata 会被 cargo 自动忽略,就算没有使用也不会发出警告。
[workspace]
members = ["member1", "member2"][workspace.metadata.webcontents]
root = "path/to/webproject"
tool = ["npm", "run", "build"]
# ...
十二、条件编译和可选依赖
Cargo Feature 是非常强大的机制,可以为大家提供条件编译和可选依赖的高级特性。
12.1、features
Feature 可以通过 Cargo.toml 中的 [features] 部分来定义:其中每个 feature 通过列表的方式指定了它所能启用的其他 feature 或可选依赖。
[features]
webp = []
当我们定义了 webp 后,我们可以在代码里使用 cfg 表达式来进行调节编译。
#[cfg(feature = "webp")]
pub mod webp;
含义就是 只有在 webp feature 被定义后,webp 模块才会被引入进来。
在 Cargo.toml 中定义的 feature 会被 cargo 通过 --cfg 参数传递给 rustc 。如果项目中要测试 feature 是否存在 可以使用 cfg 宏 或 cfg 属性。
feature 还可以开启其他 feature,比如说 ico 包含了 bmp、png,当 ico 启用后,还得确保 bmp、png 格式
[features]
bmp = []
png = []
ico = ["bmp", "png"]
webp = []
我们可以理解为 bmp 和 png 是开启 ico 的先决条件。
默认情况下,所有的 feature 都会自动被禁用,可以通过 default 来启用他们。
[features]
default = ["ico", "webp"]
bmp = []
png = []
ico = ["bmp", "png"]
webp = []
我们也可以关闭 default
- 使用命令行参数禁用 default feature,
--no-default-features; - 可以在依赖声明中指定:
--no-default-features
12.2、可选依赖
当依赖被标记为可选时,意味着它默认不会被编译。
[dependencies]
gif = { version = "0.11.1", optional = true }
这种可选依赖的写法会自动定义一个与依赖同名的 feature,也就是 gif feature,这样一来,当我们启用 gif feature 时,该依赖也会自动被引入并启用。
目前 [feature] 不能与引入的依赖库同名,但是在 nightly 中已经提供了实验性的功能,可以查看
https://doc.rust-lang.org/stable/cargo/reference/unstable.html#namespaced-features
当然我们将可以通过显式定义 feature 的方式启用这些可选依赖。
[dependencies]
ravif = { version = "0.6.3", optional = true }
rgb = { version = "0.8.25", optional = true }[features]
avif = ["ravif", "rgb"]
12.2、依赖库自身的 feature
就像我们的项目可以定义 feature 一样,依赖库也可以定义它自己的 feature、也有需要启用的 feature 列表,当引入该依赖库时,我们可以通过以下方式为其启用相关的 features :
[dependencies]
serde = { version = "1.0.118", features = ["derive"] }
以上配置 serde 依赖开启了 derive feature,还可以通过 default-features = false 来禁用依赖库 的 default feature
[dependencies]
flate2 = { version = "1.0.3", default-features = false, features = ["zlib"] }
这种方式未必能够成功禁用 default,如果你引入的其他依赖引入了 flate2,并且没有对 default 禁用,那么 default 依然会启用
还以使用下面方式间接开启依赖库的 feature。
[dependencies]
jpeg-decoder = { version = "0.1.20", default-features = false }[features]
# Enables parallel processing support by enabling the "rayon" feature of jpeg-decoder.
parallel = ["jpeg-decoder/rayon"]
12.3、通过 命令行参数启用 feature
--features FEATURES: 启用给出的 feature 列表,可以使用逗号或空格进行分隔,若你是在终端中使用,还需要加上双引号,例如--features "foo bar"。 若在工作空间中构建多个 package,可以使用 package-name/feature-name 为特定的成员启用 features-all-features: 启用命令行上所选择的所有包的所有 features--no-default-features: 对选择的包禁用 default featue
12.4、feature 同一化
feature 只有在定义的包中才是唯一的,不同包之间的 feature 允许同名。因此,在一个包上启用 feature 不会导致另一个包的同名 feature 被误启用。
当一个依赖被多个包所使用时,这些包对该依赖所设置的 feature 将被进行合并,这样才能确保该依赖只有一个拷贝存在,这个过程就被称之为同一化。大家可以查看这里了解下解析器如何对 feature 进行解析处理。
这里,我们使用 winapi 为例来说明这个过程。首先,winapi 使用了大量的 features;然后我们有两个包 foo 和 bar 分别使用了它的两个 features,那么在合并后,最终 winapi 将同时启四个 features :
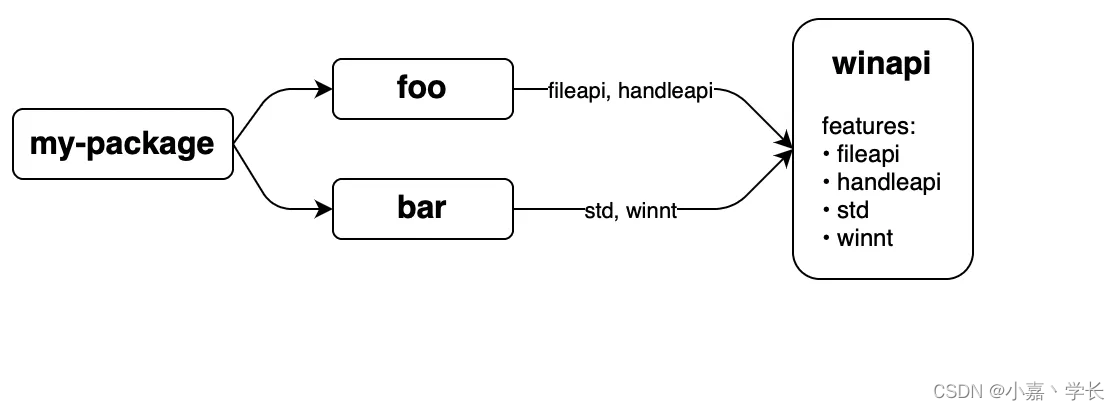
由于这种不可控性,我们需要让 启用 feature = 添加特性 这个等式成立,换言之,启用一个 feature 不应该导致某个功能被禁止。
#![no_std]
// 禁用相关标准库// 启用相关标准库
#[cfg(feature = "std")]
extern crate std;#[cfg(feature = "std")]
pub fn function_that_requires_std() {// ...
}
12.5、彼此互斥的 feature
某极少数情况下,features 之间可能会互相不兼容。我们应该避免这种设计,因为如果一旦这么设计了,那你可能需要修改依赖图的很多地方才能避免两个不兼容 feature 的同时启用。
如果实在没有办法,可以考虑增加一个编译错误来让报错更加清晰。
总之,我们应该在设计上避免这种情况的发生
- 功能分割到多个包中;
- 当冲突时,设置 feature 优先级,cfg-if 包可以帮助我们写出更加复杂的 cfg 表达时。
12.6、检视已解析的features
在复杂的依赖图中,如果想要了解不同的 features 是如何被多个包多启用的,这是相当困难的。好在 cargo tree 命令提供了几个选项可以帮组我们更好的检视哪些 features 被启用了:
cargo tree -e features ,该命令以依赖图的方式来展示已启用的 features,包含了每个依赖包所启用的特性:
cargo tree -e feature
使用cargo tree -f "{p} {f}" 命令会提供一个更加紧凑的视图:
cargo tree -f "{p} {f}"
使用 cargo tree -e features -i uuid 可以显示 featrues 如何流入指定的包中
cargo tree -e features -i uuid
12.7、Feature 解析器 V2 版本
我们可以通过下面的配置指定 V2 版本的解析器(resolver)
[package]
name = "my-package"
version = "1.0.0"
resolver = "2"
V2 版本的解析器可以在某些情况下避免 feature 同一化的发生
- 为特定的平台开启的 featrues 且此时没有被构建,会被忽略
- Build-dependencies 和 proc-macros 不再跟普通的依赖共享 features
- Dev-dependencies 的 features 不会被启用,除非正在构建的对象需要它们(例如测试对象、示例对象等)
对于部分场景而言,feature 同一化确实是需要避免的,例如,一个构建依赖开启了 std feature,而同一个依赖又被用于 no_std 环境,很明显,开启 std 将导致错误的发生。
缺点:
- 增加编译构建时间,原因是同一个依赖会被多次构建
构建脚本可以通过 CARGO_FEATURE_<name> 环境变量获取启用的 feature 列表;
我们可以用 required-features 禁用特定 Cargo Target:当某个 feature 没有启用时;
12.6、SemVer 兼容性
启用一个 feautre 不应该引入一个不兼容 SemVer 的改变。例如,启用的 feature 不应该改变现有的 API,因为这会给用户造成不兼容的破坏性变更。 如果大家想知道哪些变化是兼容的,可以参考:https://doc.rust-lang.org/stable/cargo/reference/semver.html
总而言之,在 新增/移除 feature 或可选依赖时,你需要小心,因此可能造成的向后不兼容性
- 在 发布 minor 版本时,以下通常是安全的
- 新增 feature 或可选依赖
- 修改某个依赖的 feature
- 在发布 minor 版本时,以下操作应该避免
- 移除 feature 或可选依赖
- 将现有的公有代码放在某个 featrue 之后
- 从 feature 列表中移除一个 feature
12.7、feature文档和发现
12.7.1、feature文档
你的项目支持的 feature 信息写入到文档是非常好的选择。
- 通过在 lib.rs 的顶部添加文档注释的方式来实现。
- 若项目拥有一个用户手册,那也可以在那里添加说明
- 若项目是二进制类型(可运行的应用服务,包含 fn main 入口),可以将说明放在 README 文件或其他文档中
特别是对于不稳定的或者不该再被使用的 feature 而言,它们更应该被放在文档中进行清晰的说明。
当构建发布到 docs.rs 上的文档时,会使用 Cargo.toml 中的元数据来控制哪些 features 会被启用。
12.7.2、如何发现 features
若依赖库的文档中对其使用的 features 做了详细描述,那你会更容易知道他们使用了哪些 features 以及该如何使用。
当依赖库的文档没有相关信息时,你也可以通过源码仓库的 Cargo.toml 文件来获取,但是有些时候,使用这种方式来跟踪并获取全部相关的信息是相当困难的。
十三、构建脚本 build.rs
13.1、构建脚本
一些项目希望编译第三方的非 Rust 代码,例如 C 依赖库:一些希望链接本地或基于源码构建的 C 依赖库;还有一些项目需要功能性的工具,例如在构建之间执行一些代码生成的工作等。
对于这些目标,社区已经提供了一些工具来很好的解决,Cargo 并不想替代它们,但是为了给用户带来一些便利,Cargo 提供了自定义构建脚本的方式,来帮助用户更好的解决类似的问题。
13.2、build.rs
若要创建构建脚本,我们只需在项目的根目录下添加一个 build.rs 文件即可。这样一来, Cargo 就会先编译和执行该构建脚本,然后再去构建整个项目。
fn main() {// 以下代码告诉 Cargo ,一旦指定的文件 `src/hello.c` 发生了改变,就重新运行当前的构建脚本println!("cargo:rerun-if-changed=src/hello.c");// 使用 `cc` 来构建一个 C 文件,然后进行静态链接cc::Build::new().file("src/hello.c").compile("hello");
}
关于构建脚本的一些使用场景如下
- 构建 C 依赖库;
- 在操作系统中寻找制定的 C 依赖库;
- 根据某个说明描述文件生成一个 Rust 模块
- 执行一些平台相关的配置
[package]
build = "build.rs"
13.3、构建脚本的生命周期
在项目被构建之前,Cargo 会将构建脚本编译成一个可执行文件,然后运行该文件并执行相应的任务。
在运行的过程中,脚本可以使用之前 println 的方式跟 Cargo 进行通信:通信内容是以 cargo: 开头的格式化字符串。
需要注意的是,Cargo 也不是每次都会重新编译构建脚本,只有当脚本的内容或依赖发生变化时才会。默认情况下,任何文件变化都会触发重新编译,如果你希望对其进行定制,可以使用 rerun-if命令,后文会讲。
在构建成本成功执行后,我们的项目就会开始进行编译。如果构建脚本的运行过程中发生错误,脚本应该通过返回一个非 0 码来立刻退出,在这种情况下,构建脚本的输出会被打印到终端中。
13.4、构建脚本的输入
我们可以通过环境变量的方式给构建脚本提供一些输入值,除此之外,构建脚本所在的当前目录也可以。
13.5、构建脚本的输出
构建脚本如果会产出文件,那么这些文件需要放在统一的目录中,该目录可以通过环境变量来指定,构建脚本不应该修改目录之外的任何文件
在之前提到过,构建脚本可以通过 println! 输出内容跟 Cargo 进行通信:Cargo 会将每一行带有 cargo: 前缀的输出解析为一条指令,其它的输出内容会自动被忽略。
通过 println! 输出的内容在构建过程中默认是隐藏的,如果大家想要在终端中看到这些内容,你可以使用 -vv 来调用,以下 build.rs :
fn main() {println!("hello, build.rs");
}
$ cargo run -vv
构建脚本打印到标准输出 stdout 的所有内容将保存在文件 target/debug/build/<pkg>/output中,具体位置取决于你的配置, stderr 的输出内容也将保存在同一个目录
Cargo 命令
cargo:rerun-if-changed=PATH— 当指定路径的文件发生变化时,Cargo 会重新运行脚本cargo:rerun-if-env-changed=VAR— 当指定的环境变量发生变化时,Cargo 会重新运行脚本告诉cargo:rustc-link-arg=FLAG– 将自定义的 flags 传给 linker,用于后续的基准性能测试 benchmark、 可执行文件 binary,、cdylib 包、示例 和测试。cargo:rustc-link-arg-bin=BIN=FLAG– 自定义的 flags 传给 linker,用于可执行文件 BINcargo:rustc-link-arg-bins=FLAG– 自定义的 flags 传给 linker,用于可执行文件cargo:rustc-link-arg-tests=FLAG– 自定义的 flags 传给 linker,用于测试cargo:rustc-link-arg-examples=FLAG– 自定义的 flags 传给 linker,用于示例- c
argo:rustc-link-arg-benches=FLAG– 自定义的 flags 传给 linker,用于基准性能测试 benchmark cargo:rustc-cdylib-link-arg=FLAG— 自定义的 flags 传给 linker,用于 cdylib 包cargo:rustc-link-lib=[KIND=]NAME— 告知 Cargo 通过 -l 去链接一个指定的库,往往用于链接一个本地库,通过 FFIcargo:rustc-link-search=[KIND=]PATH— 告知 Cargo 通过 -L 将一个目录添加到依赖库的搜索路径中cargo:rustc-flags=FLAGS— 将特定的 flags 传给编译器cargo:rustc-cfg=KEY[="VALUE"]— 开启编译时 cfg 设置cargo:rustc-env=VAR=VALUE— 设置一个环境变量cargo:warning=MESSAGE— 在终端打印一条 warning 信息cargo:KEY=VALUE— links 脚本使用的元数据
13.6、构建脚本的依赖
构建脚本也可以引入其它基于 Cargo 的依赖包,只需要修改在 Cargo.toml 中添加以下内容:
[build-dependencies]
cc = "1.0.46"
需要这么配置的原因在于构建脚本无法使用通过 [dependencies] 或 [dev-dependencies] 引入的依赖包,因为构建脚本的编译运行过程跟项目本身的编译过程是分离的的,且前者先于后者发生。同样的,我们项目也无法使用 [build-dependencies] 中的依赖包。
大家在引入依赖的时候,需要仔细考虑它会给编译时间、开源协议和维护性等方面带来什么样的影响。如果你在 [build-dependencies] 和 [dependencies] 引入了同样的包,这种情况下 Cargo 也许会对依赖进行复用,也许不会,例如在交叉编译时,如果不会,那编译速度自然会受到不小的影响。
13.7、links
在 Cargo.toml 中可以配置 package.links 选项,它的目的是告诉 Cargo 当前项目所链接的本地库,同时提供了一种方式可以在项目构建脚本之间传递元信息。
[package]
# ...
links = "foo"
以上配置表明项目链接到一个 libfoo 本地库,当使用 links 时,项目必须拥有一个构建脚本,并且该脚本需要使用 rustc-link-lib 指令来链接目标库。
Cargo 要求一个本地库最多只能被一个项目所链接,换而言之,你无法让两个项目链接到同一个本地库,但是有一种方法可以降低这种限制,感兴趣的同学可以看看官方文档。
假设 A 项目的构建脚本生成任意数量的 kv 形式的元数据,那这些元数据传递给将 A 用作依赖包的项目的构建脚本。例如,如果包 bar 依赖于 foo,当 foo 生成 key==value 形式的构建脚本元数据时,那么 bar 的构建脚本就可以通过环境变量的形式使用该元数据:DEP_FOO_KEY=value。
需要注意的是,该元数据只能传给直接相关者,对于间接的,例如依赖的依赖,就无能为力了。
13.8、覆盖构建脚本
当 Cargo.toml 设置了 links 时, Cargo 就允许我们使用自定义库对现有的构建脚本进行覆盖。
[target.x86_64-unknown-linux-gnu.foo]
rustc-link-lib = ["foo"]
rustc-link-search = ["/path/to/foo"]
rustc-flags = "-L /some/path"
rustc-cfg = ['key="value"']
rustc-env = {key = "value"}
rustc-cdylib-link-arg = ["…"]
metadata_key1 = "value"
metadata_key2 = "value"
增加这个配置后,在未来,一旦我们的某个项目声明了它链接到 foo ,那项目的构建脚本将不会被编译和运行,替代的是这里的配置将被使用。
warning, rerun-if-changed 和 rerun-if-env-changed 这三个 key 在这里不应该被使用,就算用了也会被忽略。
13.9、示例:build.rs
13.9.1、社区提供的功能
社区也提供了一些构建脚本的常用功能;
- bindgen:自动生成 Rust -> C 的 FFI 绑定
- cc:编译 C/C++/汇编
- pkg-config:使用 pkg-config 工具检测系统库
- cmake:运行 cmake 来构建一个本地库
- autocfg、rustc_version、version_check:基于 rustc 的档期版本来实现条件编译的方法
13.9.2、代码生成
// build.rsuse std::env;
use std::fs;
use std::path::Path;fn main() {let out_dir = env::var_os("OUT_DIR").unwrap();let dest_path = Path::new(&out_dir).join("hello.rs");fs::write(&dest_path,"pub fn message() -> &'static str {\"Hello, World!\"}").unwrap();println!("cargo:rerun-if-changed=build.rs");
}
使用代码生成
// src/main.rsinclude!(concat!(env!("OUT_DIR"), "/hello.rs"));fn main() {println!("{}", message());
}
13.9.3、构建本地库
13.9.3.1、使用
有时候,我们需要在项目中使用基于C 或 C++ 的本地库,而这种使用场景恰恰是构建脚本非常擅长的。
// build.rsuse std::process::Command;
use std::env;
use std::path::Path;fn main() {let out_dir = env::var("OUT_DIR").unwrap();Command::new("gcc").args(&["src/hello.c", "-c", "-fPIC", "-o"]).arg(&format!("{}/hello.o", out_dir)).status().unwrap();Command::new("ar").args(&["crus", "libhello.a", "hello.o"]).current_dir(&Path::new(&out_dir)).status().unwrap();println!("cargo:rustc-link-search=native={}", out_dir);println!("cargo:rustc-link-lib=static=hello");println!("cargo:rerun-if-changed=src/hello.c");
}
首先,构建脚本将我们的 C 文件通过 gcc 编译成目标文件,然后使用 ar 将该文件转换成一个静态库,最后告诉 Cargo 我们的输出内容在 out_dir 中,编译器要在这里搜索相应的静态库,最终通过 -l static-hello 标志将我们的项目跟 libhello.a 进行静态链接。
但是这种硬编码的解决方式
- gcc 命令的跨平台是受限的,例如 Windows 下难以使用它,有一些 Unix 也没有gcc 命令,同样 ar 命令也是;
- 这些命令往往不会考虑交叉编译的问题,如果我们要为 Android 平台进行交叉编译,那么 gcc 很可能无法输出一个 ARM 的可执行文件
13.9.3.2、cc依赖
社区中已经有现有的解决方案,可以让这种任务得到更容易的解决。
[build-dependencies]
cc = "1.0"
// build.rsfn main() {cc::Build::new().file("src/hello.c").compile("hello");println!("cargo:rerun-if-changed=src/hello.c");
}
不但代码简洁了很多,最重要的是可移植性、稳定性得到了解决。
- cc 会针对不同平台调用合适的编译器:windows 调用 msvc,MinGW 调用 GCC、Unix 平台调用 cc;
- 在编译时会考虑平台因素,例如合适的标志传给正在使用的编译器
- 其他环境变了
// src/main.rs// 注意,这里没有再使用 `#[link]` 属性。我们把选择使用哪个 link 的责任交给了构建脚本,而不是在这里进行硬编码
extern { fn hello(); }fn main() {unsafe { hello(); }
}
// src/hello.c#include <stdio.h>void hello() {printf("Hello, World!\n");
}
13.9.4、链接系统库
当一个 Rust 包想要链接一个本地系统库时,如何实现平台透明化,就成了一个难题。
例如:我们要实现 zlib 库,用于数据压缩。我们可以参考 libz-sys 使用。我们可以使用 pkg-config 包,该包可以帮助我们查询库的信息,会自动告诉 Cargo 该如何链接到目标库
# Cargo.toml[package]
name = "libz-sys"
version = "0.1.0"
edition = "2021"
links = "z"[build-dependencies]
pkg-config = "0.3.16
这里的 links = “z” 用于告诉 Cargo 我们想要链接到 libz 库
构建脚本:
// build.rsfn main() {pkg_config::Config::new().probe("zlib").unwrap();println!("cargo:rerun-if-changed=build.rs");
}
lib.rs
// src/lib.rsuse std::os::raw::{c_uint, c_ulong};extern "C" {pub fn crc32(crc: c_ulong, buf: *const u8, len: c_uint) -> c_ulong;
}#[test]
fn test_crc32() {let s = "hello";unsafe {assert_eq!(crc32(0, s.as_ptr(), s.len() as c_uint), 0x3610a686);}
}
我们可以使用 cargo build --vv 查看部分结果,系统中需要安装 libz 库。
cargo build --vv
13.9.5、其他 sys 包
// build.rsfn main() {let mut cfg = cc::Build::new();cfg.file("src/zuser.c");if let Some(include) = std::env::var_os("DEP_Z_INCLUDE") {cfg.include(include);}cfg.compile("zuser");println!("cargo:rerun-if-changed=src/zuser.c");
}
确保只使用了 libz库。
13.9.6、条件编译
构建脚本可以通过发出 rustc-cfg 指令来开启编译时的条件检查。
// (portion of build.rs)if let Ok(version) = env::var("DEP_OPENSSL_VERSION_NUMBER") {let version = u64::from_str_radix(&version, 16).unwrap();if version >= 0x1_00_01_00_0 {println!("cargo:rustc-cfg=ossl101");}if version >= 0x1_00_02_00_0 {println!("cargo:rustc-cfg=ossl102");}if version >= 0x1_01_00_00_0 {println!("cargo:rustc-cfg=ossl110");}if version >= 0x1_01_00_07_0 {println!("cargo:rustc-cfg=ossl110g");}if version >= 0x1_01_01_00_0 {println!("cargo:rustc-cfg=ossl111");}
}
我们通过使用版本号生成 cfg 。这些 cfg 可以跟 cfg 宏 和cfg 属性一起使用以实现条件编译。
// (portion of openssl crate)#[cfg(ossl111)]
pub fn sha3_224() -> MessageDigest {unsafe { MessageDigest(ffi::EVP_sha3_224()) }
}
这可能会导致生成的二进制文件进一步依赖档期的构建环境。如果二进制可执行文件需要在另外一个操作系统中奋发运行时,那么它依赖的信息对于该操作系统可能是不存在的。
总结
以上就是今天要讲的内容
相关文章:
【跟小嘉学 Rust 编程】二十三、Cargo 使用指南
系列文章目录 【跟小嘉学 Rust 编程】一、Rust 编程基础 【跟小嘉学 Rust 编程】二、Rust 包管理工具使用 【跟小嘉学 Rust 编程】三、Rust 的基本程序概念 【跟小嘉学 Rust 编程】四、理解 Rust 的所有权概念 【跟小嘉学 Rust 编程】五、使用结构体关联结构化数据 【跟小嘉学…...
)
R Removing package报错(as ‘lib’ is unspecified)
remove.packages(ggpubr) Removing package from ‘/Library/Frameworks/R.framework/Versions/4.0/Resources/library’ (as ‘lib’ is unspecified) 解决办法: > .libPaths() [1] "/Library/Frameworks/R.framework/Versions/4.0/Resources/library&qu…...
金融信创,软件规划需关注自主安全及生态建设
软件信创化,就是信息技术软件应用创新发展的意思(简称为“信创”)。 相信在中国,企业对于“信创化”这个概念并不陌生。「国强则民强」,今年来中国经济的快速发展,受到了各大欧美强国的“卡脖子”操作的影…...

无重叠区间【贪心算法】
无重叠区间 给定一个区间的集合 intervals ,其中 intervals[i] [starti, endi] 。返回 需要移除区间的最小数量,使剩余区间互不重叠 。 class Solution {public int eraseOverlapIntervals(int[][] intervals) {//先排序,按照左边界升序,注…...
nlp系列(7)实体识别(Bert)pytorch
模型介绍 本项目是使用Bert模型来进行文本的实体识别。 Bert模型介绍可以查看这篇文章:nlp系列(2)文本分类(Bert)pytorch_bert文本分类_牧子川的博客-CSDN博客 模型结构 Bert模型的模型结构: 数据介绍 …...
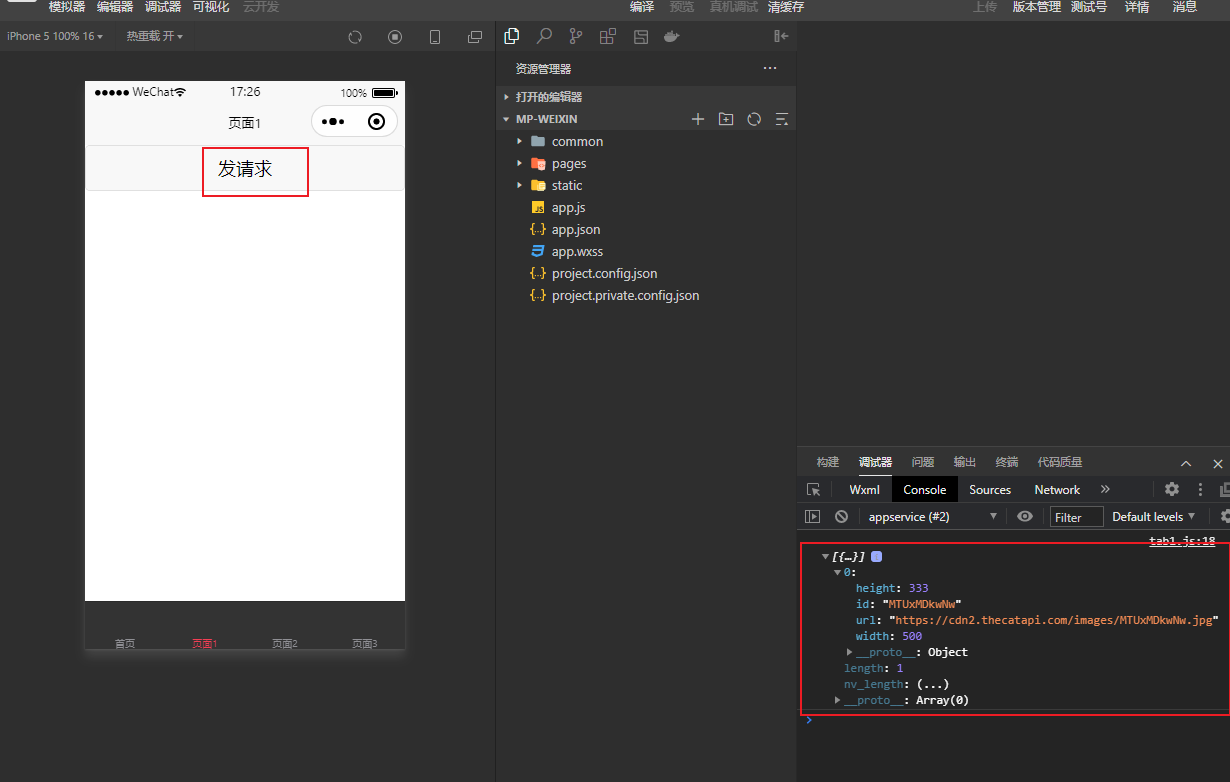
Uniapp学习之从零开始写一个简单的小程序demo(新建页面,通过导航切换页面,发送请求)
先把官网文档摆在这,后面会用到的 [uniapp官网文档]: https://uniapp.dcloud.net.cn/vernacular.html# 一、开发工具准备 1-1 安装HBuilder 按照官方推荐,先装一个HBuilder 下载地址: https://www.dcloud.io/hbuilderx.html1-2 安装微信开…...
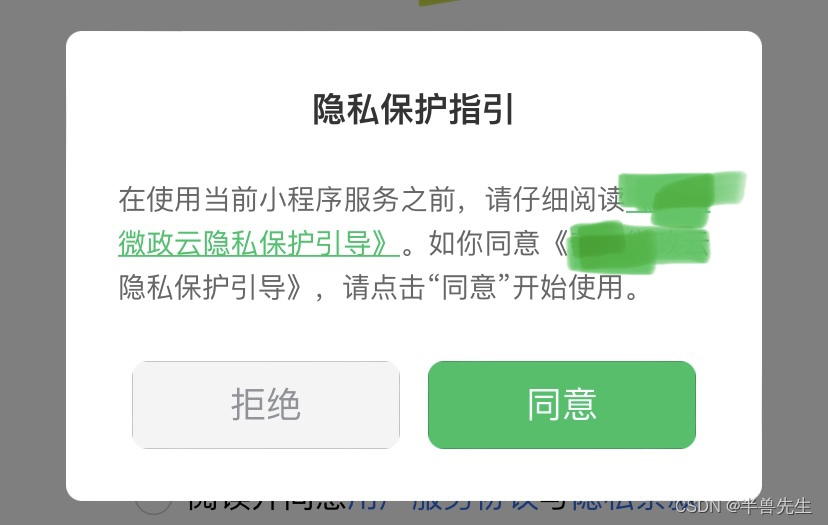
uniapp微信小程序隐私保护引导新规
1.components中新建组件PrivacyPop.vue <template><view class"privacy" v-if"showPrivacy"><view class"content"><view class"title">隐私保护指引</view><view class"des">在使用当…...
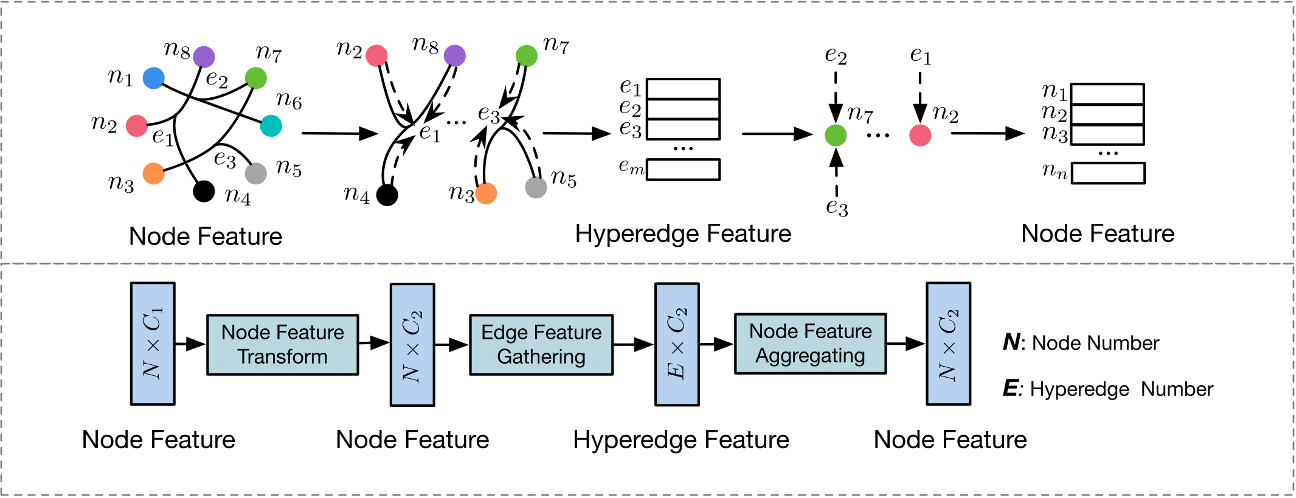
超图嵌入论文阅读2:超图神经网络
超图嵌入论文阅读2:超图神经网络 原文:Hypergraph Neural Networks ——AAAI2019(CCF-A) 源码:https://github.com/iMoonLab/HGNN 500star 概述 贡献:用于数据表示学习的超图神经网络 (HGNN) 框架…...
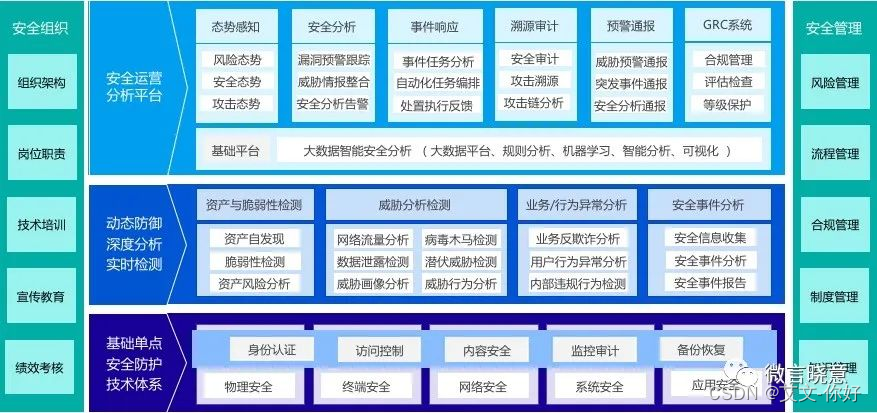
安全运营中心(SOC)技术框架
2018年曾经画过一个安全运营体系框架,基本思路是在基础单点技术防护体系基础上,围绕着动态防御、深度分析、实时检测,建立安全运营大数据分析平台,可以算作是解决方案产品的思路。 依据这个体系框架,当时写了《基于主动…...
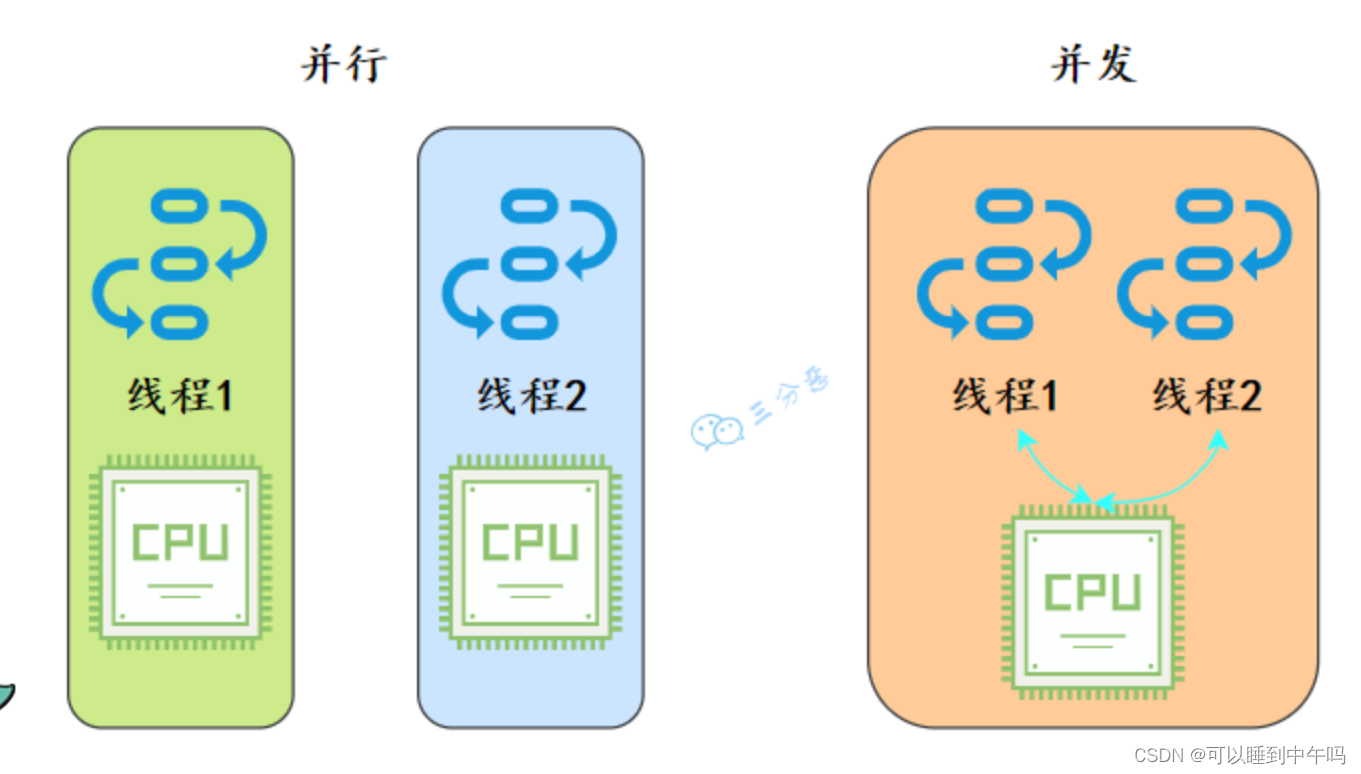
并行和并发的区别
从操作系统的角度来看,线程是CPU分配的最小单位。 并行就是同一时刻,两个线程都在执行。这就要求有两个CPU去分别执行两个线程。并发就是同一时刻,只有一个执行,但是一个时间段内,两个线程都执行了。并发的实现依赖于…...
GPT转换工具:轻松将MBR转换为GPT磁盘
为什么需要将MBR转换为GPT? 众所周知,Windows 11已经发布很长时间了。在此期间,许多老用户已经从Windows 10升级到Windows 11。但有些用户仍在运行Windows 10。对于那些想要升级到Win 11的用户来说,他们可能不确定Win 11应该使…...
大模型参数高效微调技术原理综述(二)-BitFit、Prefix Tuning、Prompt Tuning
随着,ChatGPT 迅速爆火,引发了大模型的时代变革。然而对于普通大众来说,进行大模型的预训练或者全量微调遥不可及。由此,催生了各种参数高效微调技术,让科研人员或者普通开发者有机会尝试微调大模型。 因此,…...

将conda环境打包成docker步骤
1. 第一步,将conda环境的配置导出到environment.yml 要获取一个Conda环境的配置文件 environment.yml,你可以使用以下命令从已存在的环境中导出: conda env export --name your_env_name > environment.yml请将 your_env_name 替换为你要…...

C# 获取Json对象中指定属性的值
在C#中获取JSON对象中指定属性的值,可以使用Newtonsoft.JSON库的JObject类 using Newtonsoft.Json.Linq; using System; public class Program { public static void Main(string[] args) { string json "{ Name: John, age: 30, City: New York }"; …...
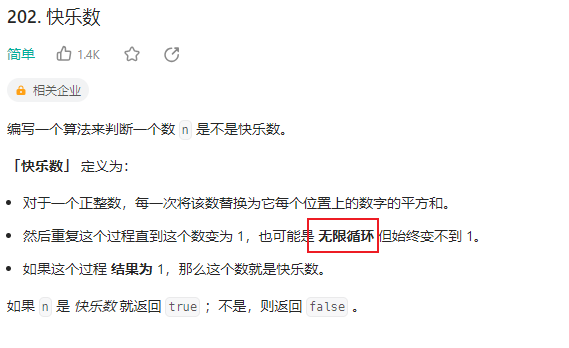
【LeetCode】202. 快乐数 - hash表 / 快慢指针
目录 2023-9-5 09:56:152023-9-6 19:40:51 202. 快乐数 2023-9-5 09:56:15 关键是怎么去判断循环: hash表: 每次生成链中的下一个数字时,我们都会检查它是否已经在哈希集合中。 如果它不在哈希集合中,我们应该添加它。如果它在…...

什么是多态性?如何在面向对象编程中实现多态性?
1、什么是多态性?如何在面向对象编程中实现多态性? 多态性(Polymorphism)是指在同一个方法调用中,由于参数类型不同,而产生不同的行为。在面向对象编程中,多态性是一种重要的特性,它…...
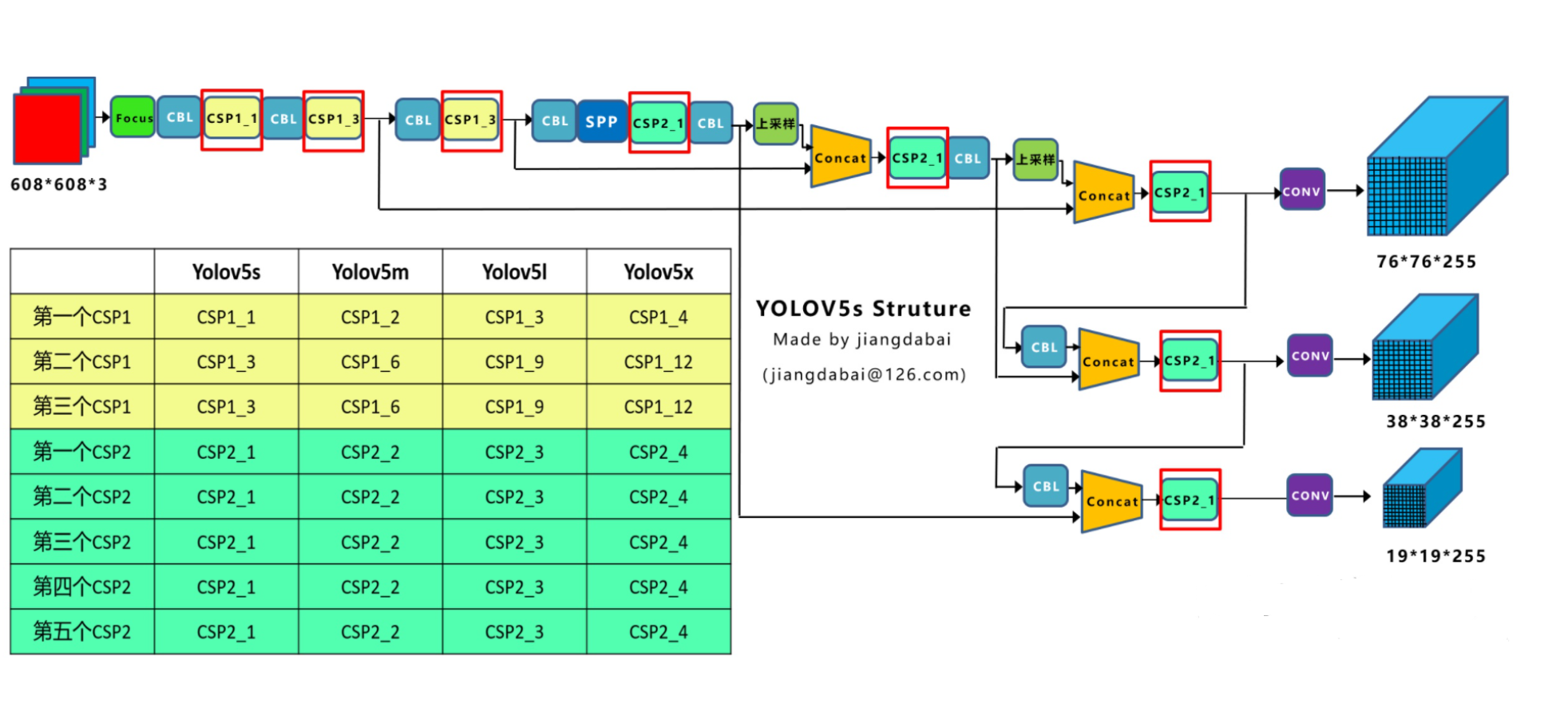
【目标检测】理论篇(3)YOLOv5实现
Yolov5网络构架实现 import torch import torch.nn as nnclass SiLU(nn.Module):staticmethoddef forward(x):return x * torch.sigmoid(x)def autopad(k, pNone):if p is None:p k // 2 if isinstance(k, int) else [x // 2 for x in k] return pclass Focus(nn.Module):def …...
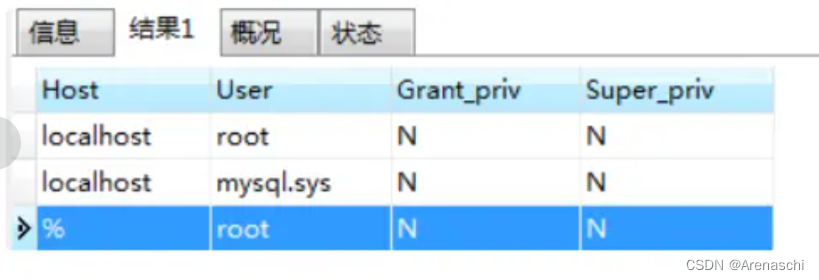
IDEA爪哇操作数据库
少小离家老大回,乡音无改鬓毛衰 ⒈.IDEA2018设置使用主题颜色 IDEA2018主题颜色分为三种:idea原始颜色,高亮色,黑色 设置方法:Settings–Appearance&Behavior–Appearance ⒉.mysql中,没有my.ini,只有…...
一文速学-让神经网络不再神秘,一天速学神经网络基础(七)-基于误差的反向传播
前言 思索了很久到底要不要出深度学习内容,毕竟在数学建模专栏里边的机器学习内容还有一大半算法没有更新,很多坑都没有填满,而且现在深度学习的文章和学习课程都十分的多,我考虑了很久决定还是得出神经网络系列文章,…...

C++ 异常处理——学习记录007
1. 概念 程序中的错误分为编译时错误和运行时错误。编译时出现的错误包括关键字拼写出错、语句分号缺少、括号不匹配等,编译时的错误容易解决。运行时出现的错误包括无法打开文件、数组越界和无法实现指定的操作。运行时出现的错误称为异常,对异常的处理…...

2026年主流抓娃娃App大对比,哪个才是你的“抓宝神器”?
在当今快节奏的生活中,年轻人面临着来自学业、工作、社交等多方面的压力。为了缓解这些压力,寻找适合的解压方式成为了大家的共同需求。抓娃娃App作为一种新兴的娱乐方式,正逐渐受到年轻人的喜爱。下面我们就从潮流趋势、科技前沿、行业洞察等…...

柔性LED灯丝DIY:从电路原理到创意饰品制作全攻略
1. 项目概述:当生日遇上柔性LED灯丝给孩子的生日派对准备一份独一无二的、会发光的惊喜,是很多家长和手工爱好者的心愿。这次,我们不买现成的塑料灯牌,而是亲手做一个能戴在头上或挂在脖子上的“生日数字灯冠”。这个项目的核心&a…...

恶劣环境下LED发光服饰的可靠系统构建:从设计到工艺的工程实践
1. 项目概述与核心挑战如果你曾经尝试过制作一件会发光的服装,无论是为了音乐节、万圣节还是水下表演,你大概都体会过那种“亮一次,修三次”的挫败感。LED灯带在工作室的桌面上测试时完美无瑕,一旦穿到身上,开始活动、…...

高效跨平台游戏模组下载:WorkshopDL完全指南
高效跨平台游戏模组下载:WorkshopDL完全指南 【免费下载链接】WorkshopDL WorkshopDL - The Best Steam Workshop Downloader 项目地址: https://gitcode.com/gh_mirrors/wo/WorkshopDL 你是否在Epic Games Store、GOG或其他非Steam平台购买了游戏࿰…...

AI模型部署实战:基于FastAPI与Tauri构建OpenClaw模型GUI应用
1. 项目概述与核心价值最近在AI应用开发圈里,一个名为“GrahamMiranda-AI/openclaw-model-gui”的项目引起了我的注意。乍一看这个标题,它融合了“openclaw-model”和“gui”两个关键部分,这让我立刻联想到一个典型的场景:一个已经…...

告别标题栏!在RK3568 Buildroot固件上,让你的Qt应用开机全屏显示的保姆级教程
RK3568嵌入式全屏实战:从Weston配置到Qt应用独占显示的完整指南 在嵌入式Linux系统开发中,GUI应用的全屏显示往往成为工程师面临的第一个"拦路虎"。当你在RK3568平台上精心开发的Qt应用启动后,却发现屏幕顶部顽固地挂着Weston窗口管…...

AssetStudio完全指南:从Unity资源提取到专业应用的全流程教程
AssetStudio完全指南:从Unity资源提取到专业应用的全流程教程 【免费下载链接】AssetStudio AssetStudio - Based on the archived Perfares AssetStudio, I continue Perfares work to keep AssetStudio up-to-date, with support for new Unity versions and addi…...

终极免费换肤方案:R3nzSkin国服版完整使用教程
终极免费换肤方案:R3nzSkin国服版完整使用教程 【免费下载链接】R3nzSkin-For-China-Server Skin changer for League of Legends (LOL) 项目地址: https://gitcode.com/gh_mirrors/r3/R3nzSkin-For-China-Server 想要在英雄联盟国服免费体验所有皮肤&#x…...

Midjourney像素艺术提示词工程:98%新手忽略的4个隐藏权重指令,实测提升风格还原度320%
更多请点击: https://intelliparadigm.com 第一章:Midjourney像素艺术提示词工程的底层逻辑重构 像素艺术在 Midjourney 中并非天然适配的生成模态,其高精度、低分辨率、强风格约束的特性与扩散模型默认的连续性渲染范式存在根本张力。要实现…...

Vibe Coding Playbook:从环境到心流,打造高效愉悦的编程系统
1. 项目概述:一个关于“氛围感编程”的实践指南最近在GitHub上看到一个挺有意思的项目,叫“Vibe Coding Playbook”。乍一看这个标题,可能会有点摸不着头脑——“Vibe Coding”是什么?是某种新的编程范式吗?还是某种神…...