电商系统架构设计系列(十一):在电商的交易类系统中,如何正确地使用 Redis 这样的缓存系统呢?需要考虑哪些问题?
上篇文章中,我给你留了一个思考题:在电商的交易类系统中,如何正确地使用 Redis 这样的缓存系统呢?需要考虑哪些问题?
这篇文章,我们来聊聊。
引言
我们知道,大部分面向公众用户的互联网系统,它的并发请求数量是和在线用户数量正相关的,而 MySQL 能承担的并发读写的量是有上限的,当系统的在线用户超过几万到几十万这个量级的时候,单台 MySQL 就很难应付了。
绝大多数互联网系统,都使用 MySQL 加上 Redis 这对儿经典的组合来解决这个问题。Redis 作为 MySQL 的前置缓存,可以替 MySQL 挡住绝大部分查询请求,很大程度上缓解了 MySQL 并发请求的压力。
Redis 之所以能这么流行,非常重要的一个原因是,它的 API 非常简单,几乎没有太多的学习成本。但是,要想在生产系统中用好 Redis 和 MySQL 这对儿经典组合,并不是一件很简单的事儿。
这篇文章,我们就来说一下,在电商的交易类系统中,如何正确地使用 Redis 这样的缓存系统,以及如何正确应对使用缓存过程中遇到的一些常见的问题。
更新缓存的最佳方式
要正确地使用好任何一个数据库,你都需要先了解它的能力和弱点,扬长避短。
Redis 是一个使用内存保存数据的高性能 KV 数据库,它的高性能主要来自于:
- 简单的数据结构
- 使用内存存储数据
像数据库是分成了执行器和存储引擎两部分,而Redis 的执行器这一层非常的薄,所以 Redis 只能支持有限的几个 API,几乎没有聚合查询的能力,也不支持 SQL。它的存储引擎也非常简单,直接在内存中用最简单的数据结构来保存数据,你从它的 API 中的数据类型基本就可以猜出存储引擎中数据结构。
比如,Redis 的 LIST 在存储引擎的内存中的数据结构就是一个双向链表。内存是一种易失性存储,所以使用内存保存数据的 Redis 不能保证数据可靠存储。从设计上来说,Redis 牺牲了大部分功能,牺牲了数据可靠性,换取了高性能。但也正是这些特性,使得 Redis 特别适合用来做 MySQL 的前置缓存。
虽然说,Redis 支持将数据持久化到磁盘中,并且还支持主从复制,但你需要知道,Redis 仍然是一个不可靠的存储,它在设计上天然就不保证数据的可靠性,所以一般我们都使用 Redis 做缓存,很少使用它作为唯一的数据存储。
即使只是把 Redis 作为缓存来使用,我们在设计 Redis 缓存的时候,也必须要考虑 Redis 的这种“数据不可靠性”,或者换句话说,我们的程序在使用 Redis 的时候,要能兼容 Redis 丢数据的情况,做到即使 Redis 发生了丢数据的情况,也不影响系统的数据准确性。
我们以电商的订单系统来作为例子说明一下,如何正确地使用 Redis 做缓存。在缓存 MySQL 的一张表的时候,通常直接选用主键来作为 Redis 中的 Key,比如缓存订单表,那就直接用订单表的主键订单号来作为 Redis 中的 key。
如果说,Redis 的实例不是给订单表专用的,还需要给订单的 Key 加一个统一的前缀,比如“orders:888888”。Value 用来保存序列化后的整条订单记录,你可以选择可读性比较好的 JSON 作为序列化方式,也可以选择性能更好并且更节省内存的二进制序列化方式,都是可以的。
然后我们来说,缓存中的数据要怎么来更新的问题。我见过很多人都是这么用缓存的:在查询订单数据的时候,先去缓存中查询,如果命中缓存那就直接返回订单数据。如果没有命中,那就去数据库中查询,得到查询结果之后把订单数据写入缓存,然后返回。在更新订单数据的时候,先去更新数据库中的订单表,如果更新成功,再去更新缓存中的数据。
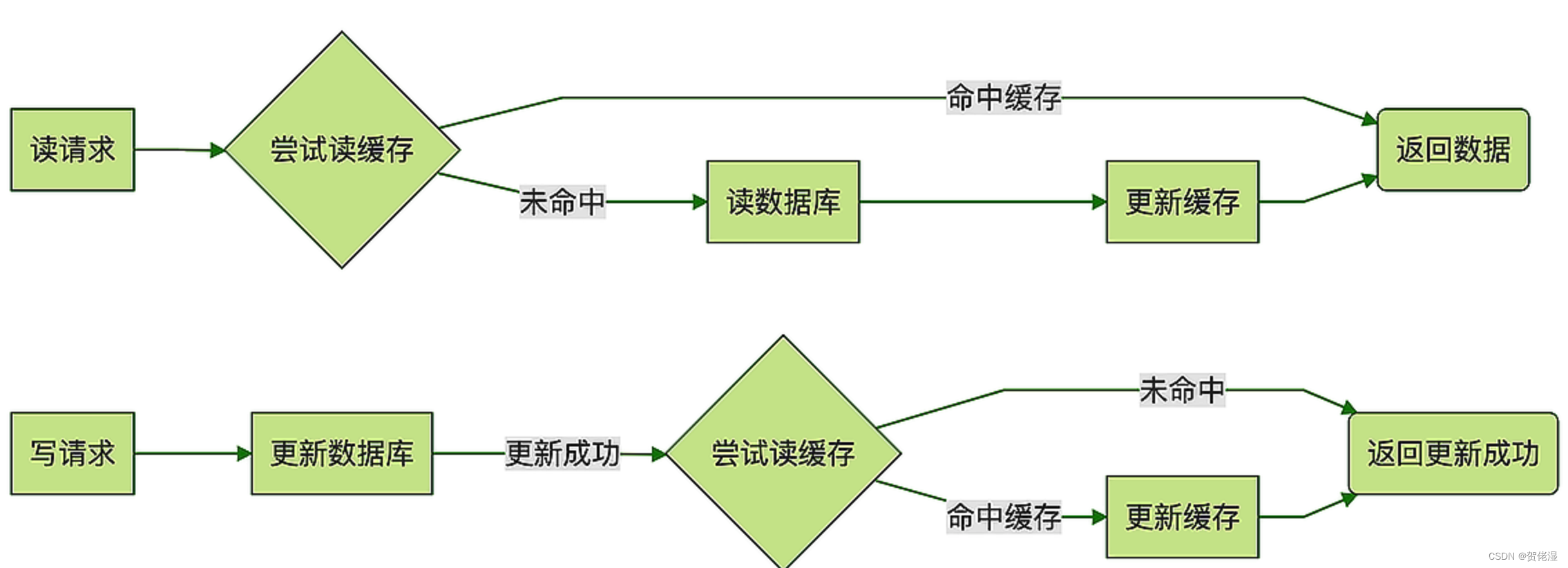
这其实是一种经典的缓存更新策略: Read/Write Through。
这样使用缓存的方式有没有问题?绝大多数情况下可能都没问题。但是,在并发的情况下,有一定的概率会出现“脏数据”问题,缓存中的数据可能会被错误地更新成了旧数据。
比如,对同一条订单记录,同时产生了一个读请求和一个写请求,这两个请求被分配到两个不同的线程并行执行,读线程尝试读缓存没命中,去数据库读到了订单数据,这时候可能另外一个读线程抢先更新了缓存,在处理写请求的线程中,先后更新了数据和缓存,然后,拿着订单旧数据的第一个读线程又把缓存更新成了旧数据。
这是一种情况,还有比如两个线程对同一个条订单数据并发写,也有可能造成缓存中的“脏数据”,具体流程类似于我们在之前“电商系统架构设计系列(三):订单系统问题有哪些”这篇文章中讲到的 ABA 问题。你不要觉得发生这种情况的概率比较小,出现“脏数据”的概率是和系统的数据量以及并发数量正相关的,当系统的数据量足够大并且并发足够多的情况下,这种脏数据几乎是必然会出现的。
另外有一个模式叫:Cache Aside,这个模式可以很好地解决这个问题,在大多数情况下是使用缓存的最佳方式。
Cache Aside 模式和上面的 Read/Write Through 模式非常像,它们处理读请求的逻辑是完全一样的,唯一的一个小差别就是,Cache Aside 模式在更新数据的时候,并不去尝试更新缓存,而是去删除缓存。

订单服务收到更新数据请求之后,先更新数据库,如果更新成功了,再尝试去删除缓存中订单,如果缓存中存在这条订单就删除它,如果不存在就什么都不做,然后返回更新成功。这条更新后的订单数据将在下次被访问的时候加载到缓存中。使用 Cache Aside 模式来更新缓存,可以非常有效地避免并发读写导致的脏数据问题。
注意缓存穿透引起雪崩
如果我们的缓存命中率比较低,就会出现大量“缓存穿透”的情况。缓存穿透指的是,在读数据的时候,没有命中缓存,请求“穿透”了缓存,直接访问后端数据库的情况。
少量的缓存穿透是正常的,我们需要预防的是,短时间内大量的请求无法命中缓存,请求穿透到数据库,导致数据库繁忙,请求超时。大量的请求超时还会引发更多的重试请求,更多的重试请求让数据库更加繁忙,这样恶性循环导致系统雪崩。
当系统初始化的时候,比如说系统升级重启或者是缓存刚上线,这个时候缓存是空的,如果大量的请求直接打过来,很容易引发大量缓存穿透导致雪崩。为了避免这种情况,可以采用灰度发布的方式,先接入少量请求,再逐步增加系统的请求数量,直到全部请求都切换完成。
如果系统不能采用灰度发布的方式,那就需要在系统启动的时候对缓存进行预热。所谓的缓存预热就是在系统初始化阶段,接收外部请求之前,先把最经常访问的数据填充到缓存里面,这样大量请求打过来的时候,就不会出现大量的缓存穿透了。
还有一种常见的缓存穿透引起雪崩的情况是,当发生缓存穿透时,如果从数据库中读取数据的时间比较长,也容易引起数据库雪崩。
比如说,我们缓存的数据是一个复杂的数据库联查结果,如果在数据库执行这个查询需要 10 秒钟,那当缓存中这条数据过期之后,最少 10 秒内,缓存中都不会有数据。
如果这 10 秒内有大量的请求都需要读取这个缓存数据,这些请求都会穿透缓存,打到数据库上,这样很容易导致数据库繁忙,当请求量比较大的时候就会引起雪崩。
所以,如果说构建缓存数据需要的查询时间太长,或者并发量特别大的时候,Cache Aside 或者是 Read/Write Through 这两种缓存模式都可能出现大量缓存穿透。
对于这种情况,并没有一种方法能应对所有的场景,你需要针对业务场景来选择合适解决方案。比如说,可以牺牲缓存的时效性和利用率,缓存所有的数据,放弃 Read Through 策略所有的请求,只读缓存不读数据库,用后台线程来定时更新缓存数据。
比如,可以通过锁来解决“Cache aside和read/write through”而带来的数据不一致问题,解决方案可以如下:
a写线程,b读线程;
b线程:读缓存->未命中->上写锁>从db读数据到缓存->释放锁;
a线程:上写锁->写db->删除缓存/改缓存->释放锁;
这样来保证a,b线程并发读写缓存带来的脏数据问题;
总结
使用 Redis 作为 MySQL 的前置缓存,可以非常有效地提升系统的并发上限,降低请求响应时延。绝大多数情况下,使用 Cache Aside 模式来更新缓存都是最佳的选择,相比 Read/Write Through 模式更简单,还能大幅降低脏数据的可能性。
使用 Redis 的时候,还需要特别注意大量缓存穿透引起雪崩的问题,在系统初始化阶段,需要使用灰度发布或者其他方式来对缓存进行预热。如果说构建缓存数据需要的查询时间过长,或者并发量特别大,这两种情况下使用 Cache Aside 模式更新缓存,会出现大量缓存穿透,有可能会引发雪崩。
顺便说一句,文章中说到的这些缓存策略,都是非常经典的理论,早在互联网大规模应用之前,这些缓存策略就已经非常成熟了,在操作系统中,CPU Cache 的缓存、磁盘文件的内存缓存,它们也都应用了我们今天说到的这些策略。
所以,无论技术发展的多快,计算机的很多基础的理论的知识都是相通的,你绞尽脑汁想出的解决工程问题的方法,很可能早都写在几十年前出版的书里。学习算法、数据结构、设计模式等等这些基础的知识,真的并不只是为了应付面试。
感谢阅读,如果你觉得这篇文章对你有一些启发,也欢迎把它分享给你的朋友。
上一篇文章
电商系统架构设计系列(十):怎么能避免写出慢SQL?
推荐阅读
- 【总结】深入剖析 Redis 性能问题及优化方案有哪些
- 【总结】互联网技术架构中常用的分库分表方案汇总
- 技术破局,业绩狂飙十倍:亿级电商平台重构大揭秘
- 当我们聊高并发时,到底是在聊什么?如何真正地掌握高并发设计能力?
- 微服务架构实战 - 我的经验分享总结2019(系统架构师)架构演进过程-从信息流架构到电商中台架构
系列分享
- Elasticsearch教程
- 微服务架构实战
- 架构思维成长系列
- 电商系统架构设计系列
------------------------------------------------------
------------------------------------------------------
我的CSDN主页
关于我(个人域名,更多我的信息)
我的开源项目集Github
期望和大家 一起学习,一起成长,共勉,O(∩_∩)O谢谢
如果你有任何建议,或想学习的知识,可与我一起讨论交流
欢迎交流问题,可加个人QQ 469580884,
或者,加我的群号 751925591,一起探讨交流问题
不讲虚的,只做实干家
Talk is cheap,show me the code
相关文章:
电商系统架构设计系列(十一):在电商的交易类系统中,如何正确地使用 Redis 这样的缓存系统呢?需要考虑哪些问题?
上篇文章中,我给你留了一个思考题:在电商的交易类系统中,如何正确地使用 Redis 这样的缓存系统呢?需要考虑哪些问题? 这篇文章,我们来聊聊。 引言 我们知道,大部分面向公众用户的互联网系统&a…...

MySQL数据库和表的操作
数据库基础 存储数据用文件就可以了,为什么还要弄个数据库? 文件保存数据有以下几个缺点: 1、文件的安全性问题 2、文件不利于数据查询和管理 3、文件不利于存储海量数据 4、文件在程序中控制不方便 数据库存储介质: 磁盘 内存 为了解决上…...
DAY-01--分布式微服务基础概念
一、项目简介 了解整体项目包含后端、前端、周边维护。整个项目的框架知识。 二、分布式基础概念 1、微服务 将应用程序 基于业务 拆分为 多个小服务,各小服务单独部署运行,采用http通信。 2、集群&分布式&节点 集群是个物理形态,…...

记:一次关于paddlenlp、python、版本之间的兼容性问题
兼容版本 Python 3.10.8 absl-py1.4.0 accelerate0.19.0 addict2.4.0 aiofiles23.1.0 aiohttp3.8.3 aiosignal1.3.1 alembic1.10.4 aliyun-python-sdk-core2.13.36 aliyun-python-sdk-kms2.16.0 altair4.2.2 altgraph0.17.3 aniso86019.0.1 antlr4-python3-runtime4.9.3 anyi…...

MyBatis配置及单表操作
文章目录 一. MyBatis概述二. MyBatis项目的创建1. 准备一个数据表2. 创建项目 三. MyBatis的使用1. 基本使用2. SpringBoot单元测试 四. 使用MyBatis实现单表操作1. 查询2. 修改3. 删除4. 新增 五. 基于注解完成SQL 一. MyBatis概述 MyBatis 是一款优秀的持久层框架ÿ…...

python基础教程:深浅copy的详细用法
前言 嗨喽,大家好呀~这里是爱看美女的茜茜呐 1.先看赋值运算 l1 [1,2,3,[barry,alex]] l2 l1l1[0] 111 print(l1) # [111, 2, 3, [barry, alex]] print(l2) # [111, 2, 3, [barry, alex]]l1[3][0] wusir print(l1) # [111, 2, 3, [wusir, alex]] print(l2)…...
【算法篇】动态规划(二)
文章目录 分割回文字符串编辑距离不同的子序列动态规划解题思路 分割回文字符串 class Solution { public:bool isPal(string& s,int begin,int end){while(begin<end){if(s[begin]!s[end]){return false;}begin;end--;}return true;}int minCut(string s) {int lens.si…...
数据库 SQL高级查询语句:聚合查询,多表查询,连接查询
目录 创建学生表聚合查询聚合函数直接查询设置别名查询设置条件查询 常用的聚合函数 分组查询单个字段Group by报错分组查询多字段分组查询 多表查询直接查询重命名查询Students表新建一列CourseID 连接(JOIN)查询INNER JOINRIGHT JOIN, LEFT JOINFULL J…...

pytorch-构建卷积神经网络
构建卷积神经网络 卷积网络中的输入和层与传统神经网络有些区别,需重新设计,训练模块基本一致 import torch import torch.nn as nn import torch.optim as optim import torch.nn.functional as F from torchvision import datasets,transforms impor…...
)
点云从入门到精通技术详解100篇-点云滤波算法及单木信息提取(续)
目录 3.3 点云滤波算法原理概述 3.3.1 坡度滤波算法 3.3.2 基于不规则三角网滤波 3.3.3 数学形态学滤波...

Gartner发布中国科技报告:数据编织和大模型技术崭露头角
近日,全球知名科技研究和咨询机构Gartner发布了关于中国数据分析与人工智能技术的最新报告。报告指出,中国正迎来数据分析与人工智能领域的蓬勃发展,预计到2026年,将有超过30%的白领工作岗位重新定义,生成式人工智能技…...

java八股文面试[数据库]——explain
使用 EXPLAIN 关键字可以模拟优化器来执行SQL查询语句,从而知道MySQL是如何处理我们的SQL语句的。分析出查询语句或是表结构的性能瓶颈。 MySQL查询过程 通过explain我们可以获得以下信息: 表的读取顺序 数据读取操作的操作类型 哪些索引可以被使用 …...

Kafka3.0.0版本——增加副本因子
目录 一、服务器信息二、启动zookeeper和kafka集群2.1、先启动zookeeper集群2.2、再启动kafka集群 三、增加副本因子3.1、增加副本因子的概述3.2、增加副本因子的示例3.2.1、创建topic(主题)3.2.2、手动增加副本存储 一、服务器信息 四台服务器 原始服务器名称原始服务器ip节点…...
升级iOS 17出现白苹果、不断重启等系统问题怎么办?
iOS 17发布后了,很多果粉都迫不及待的将iphone/ipad升级到最新iOS17系统,体验新系统功能。 但部分果粉因硬件、软件的各种情况,导致升级系统后出现故障,比如白苹果、不断重启、卡在系统升级界面等等问题。 如果遇到了这些系统问题…...

6. `Java` 并发基础之`ReentrantReadLock`
前言:随着多线程程序的普及,线程同步的问题变得越来越常见。Java中提供了多种同步机制来确保线程安全,其中之一就是ReentrantLock。ReentrantLock是Java中比较常用的一种同步机制,它提供了一系列比synchronized更加灵活和可控的操…...
float浮动布局大战position定位布局
华子目录 布局方式普通文档流布局浮动布局(浮动主要针对与black,inline元素)float属性浮动用途浮动元素父级高度塌陷 position属性定位篇相对定位(relative为属性值,配合left属性,和top属性使用)…...
算法 数据结构 递归插入排序 java插入排序 递归求解插入排序算法 如何用递归写插入排序 插入排序动图 插入排序优化 数据结构(十)
1. 插入排序(insertion-sort): 是一种简单直观的排序算法。它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入 算法稳定性: 对于两个相同的数,经过…...
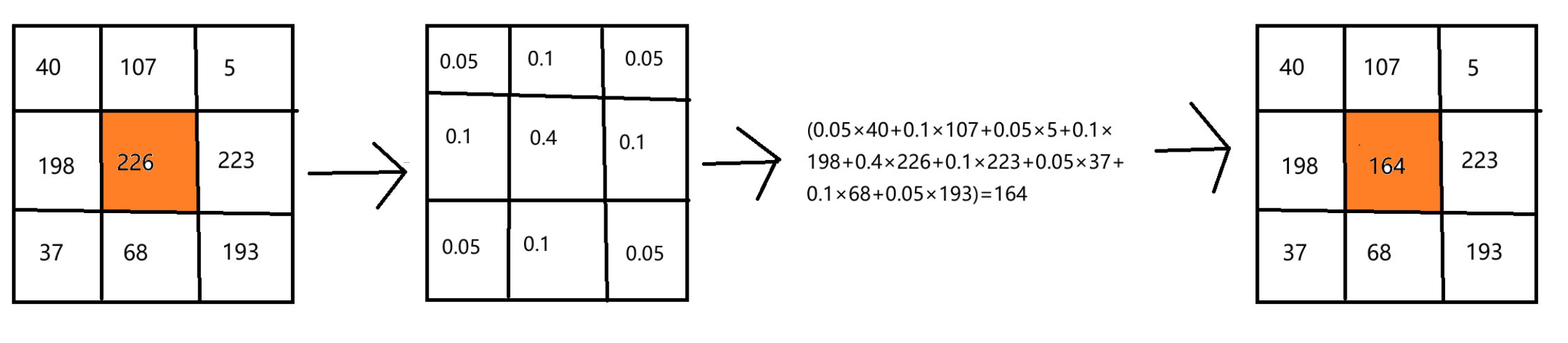
OpenCV(二十二):均值滤波、方框滤波和高斯滤波
目录 1.均值滤波 2.方框滤波 3.高斯滤波 1.均值滤波 OpenCV中的均值滤波(Mean Filter)是一种简单的滤波技术,用于平滑图像并减少噪声。它的原理非常简单:对于每个像素,将其与其周围邻域内像素的平均值作为新的像素值…...
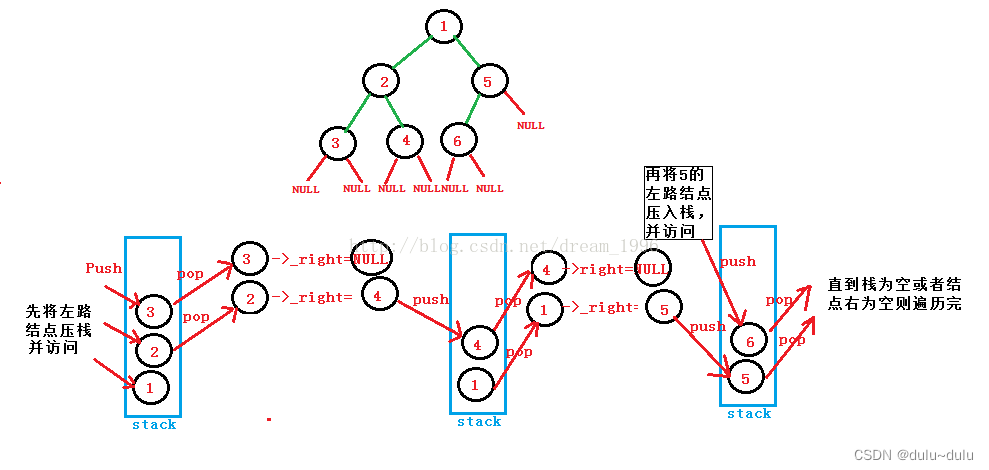
二叉树的递归遍历和非递归遍历
目录 一.二叉树的递归遍历 1.先序遍历二叉树 2.中序遍历二叉树 3.后序遍历二叉树 二.非递归遍历(栈) 1.先序遍历 2.中序遍历 3.后序遍历 一.二叉树的递归遍历 定义二叉树 #其中TElemType可以是int或者是char,根据要求自定 typedef struct BiNode{TElemType data;stru…...

JDK17:未来已来,你准备好了吗?
🌷🍁 博主猫头虎(🐅🐾)带您 Go to New World✨🍁 🦄 博客首页——🐅🐾猫头虎的博客🎐 🐳 《面试题大全专栏》 🦕 文章图文…...

3步实现AutoHotkey脚本独立运行:Ahk2Exe编译工具完全指南
3步实现AutoHotkey脚本独立运行:Ahk2Exe编译工具完全指南 【免费下载链接】Ahk2Exe Official AutoHotkey script compiler - written itself in AutoHotkey 项目地址: https://gitcode.com/gh_mirrors/ah/Ahk2Exe 你是否厌倦了每次运行AutoHotkey脚本都需要安…...

西门子PLC通信必备:手把手教你用SCL编写Modbus RTU CRC校验功能块
西门子PLC通信实战:SCL实现Modbus RTU CRC校验的工程化解决方案 在工业自动化领域,可靠的数据通信如同设备的神经系统。当两台PLC需要通过RS485接口交换温度传感器读数时,Modbus RTU协议因其简洁高效成为首选。但许多工程师在调试阶段都会遇到…...

快速免费解锁网易云音乐NCM格式:ncmdumpGUI完整使用指南
快速免费解锁网易云音乐NCM格式:ncmdumpGUI完整使用指南 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾在网易云音乐下载了心爱的歌曲&am…...

高效跨平台游戏模组下载:WorkshopDL完全指南
高效跨平台游戏模组下载:WorkshopDL完全指南 【免费下载链接】WorkshopDL WorkshopDL - The Best Steam Workshop Downloader 项目地址: https://gitcode.com/gh_mirrors/wo/WorkshopDL 你是否在Epic Games Store、GOG或其他非Steam平台购买了游戏࿰…...

Windows鼠标指针主题定制:从.cur/.ani文件到个性化交互体验
1. 项目概述:一个为Windows终端注入灵魂的鼠标指针主题如果你和我一样,每天有超过8小时的时间是与Windows操作系统相伴的,那么你对那个千篇一律的白色箭头鼠标指针,恐怕早已感到审美疲劳。它就像一个沉默的、功能性的背景板&#…...

Faderwave合成器设计:从波形塑造到数字滤波的嵌入式音频实践
1. 项目概述:从推子到声音,Faderwave合成器的设计哲学如果你玩过硬件合成器,或者对数字音频合成感兴趣,那你肯定知道,声音设计的起点往往是一个简单的波形。但如何让这个波形“活”起来,变成你脑海中那个独…...

OpenAgents开源框架:模块化AI智能体开发实战指南
1. 项目概述:一个面向未来的智能体开发框架最近在AI智能体这个圈子里,OpenAgents这个项目讨论度挺高的。简单来说,它不是一个单一的AI应用,而是一个旨在降低智能体开发门槛、加速智能体应用落地的开源框架。你可以把它想象成一个“…...

Solon框架:微内核驱动的Java全栈云原生应用开发实践
1. 项目概述:从“微内核”到“全栈”的Java框架演进如果你在Java生态里摸爬滚打有些年头,肯定经历过从SSH(StrutsSpringHibernate)到SSM(Spring MVCSpringMyBatis)的架构变迁,也一定对Spring Bo…...

长期使用后回顾,Taotoken账单明细对项目财务核算的实际帮助
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用后回顾,Taotoken账单明细对项目财务核算的实际帮助 对于一个持续数月、深度依赖大模型能力的项目组而言&#…...

AI 越火,存储越关键:一颗存储藏着设备稳定运行的秘密
很多人看芯片,第一眼喜欢看“大件”。CPU、GPU、主控、屏幕、电池、无线模组,好像这些才是产品的主角。但真正做过硬件的人都知道:一个设备能不能稳定开机,程序能不能快速读取,系统能不能在复杂环境下长期跑得住&#…...