基于神经网络结合紫外差分光谱的二氧化硫浓度定量预测
基于神经网络结合紫外差分光谱的二氧化硫浓度定量预测
- 前言
- 一、代码运行
- 1. 解压数据
- 2. 导包
- 3. 读取数据
- 4. 构建网络
- 5. 设置优化器
- 6. 模型训练
- 7. 可视化loss
- 8. 模型验证
- 二、结果展示
- 三、总结
- 作者简介
前言
二氧化硫(SO2)是一种常见的环境污染物,对大气、水体和土壤等环境有着广泛的影响。因此,准确监测和预测大气中的二氧化硫浓度对于环境管理和污染控制具有重要意义。紫外差分光谱是一种常用于二氧化硫浓度监测的方法,通过测量大气中SO2在紫外光波段的吸收特性来进行定量分析。
本项目旨在通过应用神经网络技术,结合紫外差分光谱数据,实现对二氧化硫浓度的准确定量预测。项目将采用从不同环境中收集的紫外差分光谱数据,包括大气中SO2的光谱吸收特性以及环境参数(如温度、湿度等),作为输入特征。基于这些输入特征,将建立一个神经网络模型,通过对历史数据的学习和训练,实现对二氧化硫浓度的预测。
项目计划包括以下步骤:
- 数据采集和准备:从不同环境中采集紫外差分光谱数据,包括SO2的光谱吸收特性以及环境参数。对采集到的数据进行处理和准备,包括数据清洗、特征提取和特征工程等。
- 模型选择和设计:根据项目需求,选择合适的神经网络模型,并进行模型的设计。可以考虑使用常见的神经网络模型,如多层感知器(MLP)、卷积神经网络(CNN)或循环神经网络(RNN)等。
- 模型训练和调优:使用采集到的紫外差分光谱数据,对选定的神经网络模型进行训练和调优。包括将数据集划分为训练集和验证集,进行模型参数的优化和调整,以获得最佳的预测性能。
- 模型评估和验证:通过对模型进行评估和验证,包括使用测试数据集进行性能测试,评估模型的预测准确性、稳定性和可靠性。根据评估结果进行模型的调整和优化。
- 结果解释和应用:根据训练好的神经网络模型,实现对二氧化硫的浓度预测

一、代码运行
本文的代码是基于百度的BML Codelab编写,项目地址:基于神经网络结合紫外差分光谱的二氧化硫浓度定量预测,数据在项目中被提供。
1. 解压数据
# 运行完一次记得注释掉
!unzip /home/aistudio/data/data208645/Data.zip -d ./data
2. 导包
import pandas as pd
import paddle
import numpy as np
from sklearn.model_selection import cross_val_score, train_test_split
import matplotlib.pyplot as plt
3. 读取数据
train_data = pd.read_excel("./data/Data/train.xlsx", header=None)
val_data = pd.read_excel("./data/Data/val.xlsx", header=None)
test_data = pd.read_excel("./data/Data/test.xlsx", header=None)
print("加载数据完成!")print("train_data:",train_data)
print("val_data:",val_data)
print("test_data:",test_data)
4. 构建网络
class Regressor(paddle.nn.Layer):# self代表类的实例自身def __init__(self):# 初始化父类中的一些参数super(Regressor, self).__init__()self.fc1 = paddle.nn.Linear(in_features=423, out_features=40)self.fc2 = paddle.nn.Linear(in_features=40, out_features=20)self.fc3 = paddle.nn.Linear(in_features=20, out_features=1)self.relu = paddle.nn.ReLU()# 网络的前向计算def forward(self, inputs):x = self.fc1(inputs)x = self.relu(x)x = self.fc2(x)x = self.relu(x)x = self.fc3(x)x = self.relu(x)return x
5. 设置优化器
# 声明定义好的线性回归模型
model = Regressor()# 开启模型训练模式
model.train()# 定义优化算法,使用随机梯度下降SGD
opt = paddle.optimizer.SGD(learning_rate=0.01, parameters=model.parameters())
6. 模型训练
EPOCH_NUM = 20 # 设置外层循环次数
BATCH_SIZE =32 # 设置batch大小
loss_train = []
loss_val = []
training_data = train_data.values.astype(np.float32)
val_data = val_data.values.astype(np.float32)
# 定义外层循环
for epoch_id in range(EPOCH_NUM):# 在每轮迭代开始之前,将训练数据的顺序随机的打乱np.random.shuffle(training_data)# 将训练数据进行拆分,每个batch包含10条数据mini_batches = [training_data[k:k+BATCH_SIZE] for k in range(0, len(training_data), BATCH_SIZE)]train_loss = []for iter_id, mini_batch in enumerate(mini_batches):# 清空梯度变量,以备下一轮计算opt.clear_grad()x = np.array(mini_batch[:, :-1])y = np.array(mini_batch[:, -1:])# 将numpy数据转为飞桨动态图tensor的格式features = paddle.to_tensor(x)y = paddle.to_tensor(y)# 前向计算predicts = model(features)# 计算损失loss = paddle.nn.functional.l1_loss(predicts, label=y)avg_loss = paddle.mean(loss)train_loss.append(avg_loss.numpy())# 反向传播,计算每层参数的梯度值avg_loss.backward()# 更新参数,根据设置好的学习率迭代一步opt.step()mini_batches = [val_data[k:k+BATCH_SIZE] for k in range(0, len(val_data), BATCH_SIZE)]val_loss = []for iter_id, mini_batch in enumerate(mini_batches):x = np.array(mini_batch[:, :-1])y = np.array(mini_batch[:, -1:])features = paddle.to_tensor(x)y = paddle.to_tensor(y)predicts = model(features)loss = paddle.nn.functional.l1_loss(predicts, label=y)avg_loss = paddle.mean(loss)val_loss.append(avg_loss.numpy())loss_train.append(np.mean(train_loss))loss_val.append(np.mean(val_loss))print(f'Epoch {epoch_id}, train MAE {np.mean(train_loss)}, val MAE {np.mean(val_loss)}')
7. 可视化loss
# loss
x = np.linspace(0, EPOCH_NUM+1, EPOCH_NUM)plt.figure()
plt.plot(x, loss_train, color='red', linewidth=1.0, linestyle='--', label='line')
plt.plot(x, loss_val, color='y', linewidth=1.0, label='line')
plt.savefig('loss.png', dpi=600, bbox_inches='tight', transparent=False)
plt.legend(["train MAE", "val MAE"])
plt.title("Loss")
plt.xlabel('epoch_num')
plt.ylabel('loss value')

8. 模型验证
model.eval()
test_data = paddle.to_tensor(test_data.values.astype(np.float32))
test_predict = model(test_data)
test_predict = test_predict.numpy().flatten()
test_predict = test_predict.round().astype(int)
print("test_predict:",test_predict)

二、结果展示
x = np.linspace(0, 10, 9)
Y_test = [4,9,5,6,7,14,12,13,15]
Y_test = np.array(Y_test)predicted = test_predict
plt.figure()
plt.scatter(x, predicted, color='red') # 画点
plt.scatter(x, Y_test, color='y') # 画点
plt.plot(x, predicted, color='red', linewidth=1.0, linestyle='--', label='line')
plt.plot(x, Y_test, color='y', linewidth=1.0, label='line')
plt.savefig('result.png', dpi=600, bbox_inches='tight', transparent=False)
plt.legend(["predict value", "true value"])
plt.title("SO2")
plt.xlabel('X')
plt.ylabel('Absorption intensity')


三、总结
- 从图中我们可以看出,在SO2高浓度的时候,预测的不是很准确,这大概率是因为非线性的影响。
- 在气体浓度定量分析中,如何去除非线性的影响,是一直研究的课题。
- 可以加入光谱预处理来提高模型的准确性
- 例如可以对数据进行差分拟合、小波变换、傅里叶变换等来改进
作者简介
CSDN 人工智能领域新星创作者
百度飞桨开发者技术专家
腾讯云开发初级工程师认证
我在AI Studio上获得钻石等级,点亮9个徽章,来互关呀~
相关文章:
基于神经网络结合紫外差分光谱的二氧化硫浓度定量预测
基于神经网络结合紫外差分光谱的二氧化硫浓度定量预测 前言一、代码运行1. 解压数据2. 导包3. 读取数据4. 构建网络5. 设置优化器6. 模型训练7. 可视化loss8. 模型验证 二、结果展示三、总结作者简介 前言 二氧化硫(SO2)是一种常见的环境污染物ÿ…...
一个新工具 nolyfill
名字的意思, 我自己的理解 no(po)lyfill 正如它的名字, 不要再用补丁了, 当然这里说的是过时的补丁。 polyfill 是补丁的意思 为什么要用这个插件 文档原文: 当您通过安装最新的 Node.js LTS 来接受最新的功能和安全修复时,像eslint-plugin-import、…...

vue的第2篇 开发环境vscode的安装以及创建项目空间
一 环境的搭建 1.1常见前端开发ide 1.2 安装vs.code 1.下载地址:Visual Studio Code - Code Editing. Redefined 2.进行安装 1.2.1 vscode的中文插件安装 1.在搜索框输入“chinese” 2.安装完成重启,如下变成中文 1.2.2 修改工作区的颜色 选中[浅色]…...

Java之包装类的详细解析
包装类 5.1 概述 Java提供了两个类型系统,基本类型与引用类型,使用基本类型在于效率,然而很多情况,会创建对象使用,因为对象可以做更多的功能,如果想要我们的基本类型像对象一样操作,就可以使…...
)
SpringBoot项目防止接口重复提交(简单拦截器实现方案)
基于SpringBoot框架来开发业务后台项目时,接口重复提交是一个常见的问题。为了避免这个问题,我们可以通过自定义拦截器实现一个后台拦截接口重复提交的功能,本文将介绍如何使用基于SpringBoot实现这个功能。 首先,我们需要引入一…...
C语言 数据结构与算法 I
C语言-数据结构与算法 C语言基础 因为之前写算法都是用C,也有了些C基础,变量常量数据类型就跳过去吧。 首先是环境,学C时候用Clion,C语言也用它写吧~ 新建项目,选C执行文件,语言标准。。。就先默认C99吧…...

PHP指定时间戳/日期加一天,一年,一周,一月
PHP指定时间戳加上1天,1周,1月,一年其实是不需要用上什么函数的!指定时间戳本身就是数字整型,我们只需要再计算1天,1周它的秒数相加即可! 博主搜索php指定时间戳加一天一年,结果许多…...
前端框架 vue-admin-template的搭建运行
一介绍 1.1 下载地址 vue-element-admin是基于element-ui 的一套后台管理系统集成方案。 GitHub - PanJiaChen/vue-element-admin: :tada: A magical vue admin https://panjiachen.github.io/vue-element-admin 1.2 node.js的安装 地址下载node.js 1.6版本 CNPM Binari…...
Git—版本控制系统
git版本控制系统 1、什么是版本控制2、常见的版本控制工具3、版本控制分类3.1、本地版本控制3.2、集中版本控制 SVN3.3、分布式版本控制 Git 4、Git与SVN的主要区别5、Git环境配置6、启动Git7、常用的Linux命令8、Git配置9、设置用户名与邮箱(用户标识,必…...
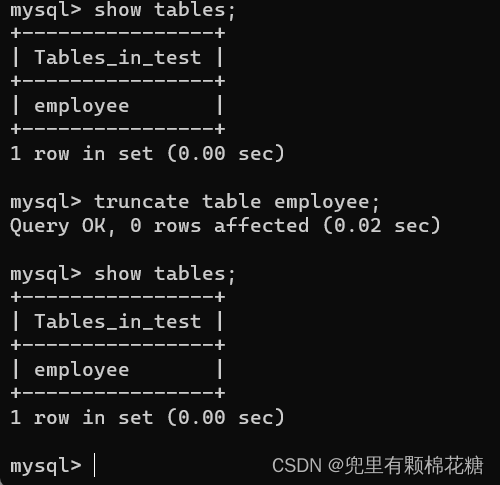
【MySQL基础|第一篇】——谈谈SQL中的DDL语句
个人主页:兜里有颗棉花糖 欢迎 点赞👍 收藏✨ 留言✉ 加关注💓本文由 兜里有颗棉花糖 原创 收录于专栏【MySQL学习专栏】🎈 本专栏旨在分享学习MySQL的一点学习心得,欢迎大家在评论区讨论💌 前言ÿ…...
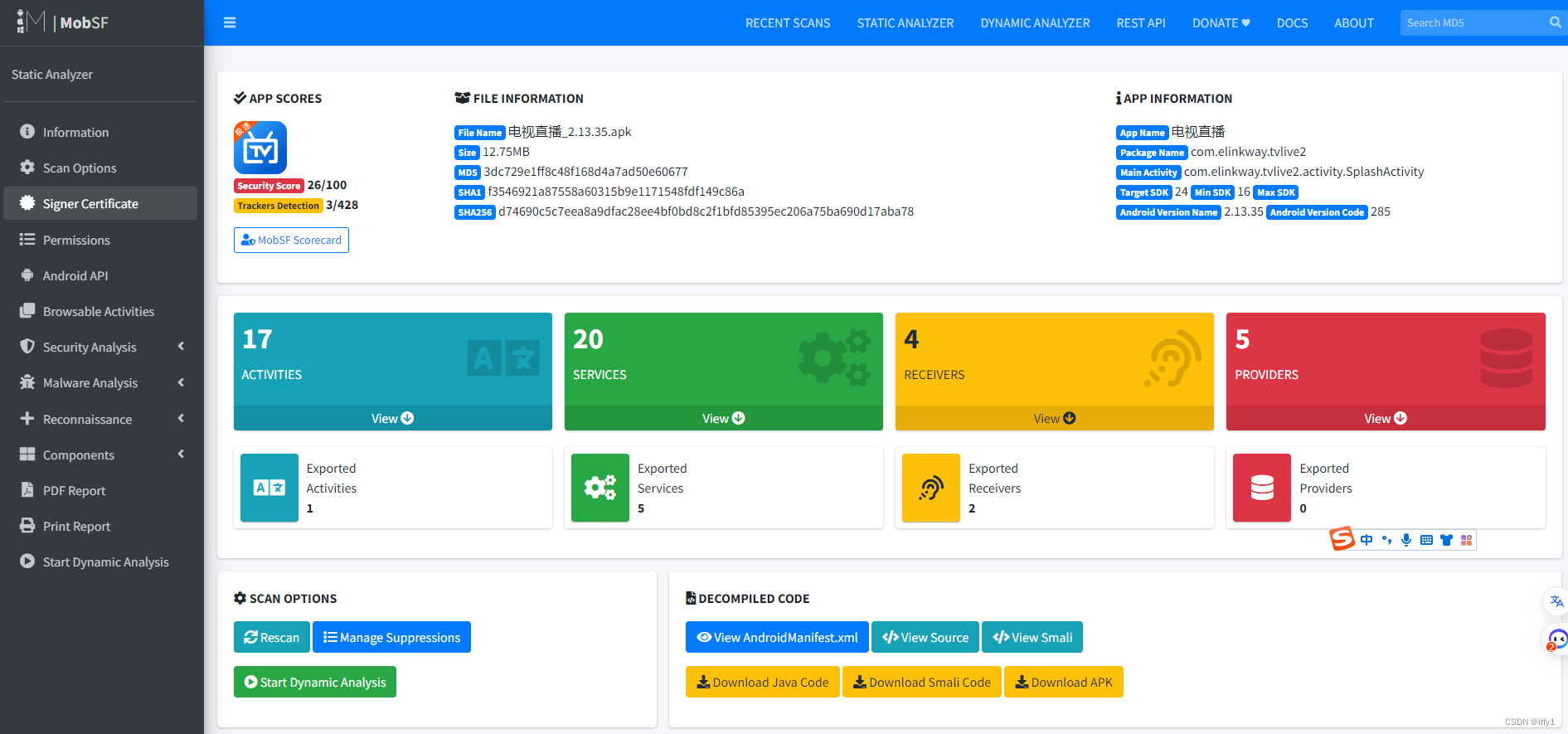
移动安全测试框架-MobSF WINDOWS 环境搭建
安装python python-3.11.5-amd64.exe 安装Win64OpenSSL-3_1_2.exe 安装VisualStudioSetup.exe github下载安装包 https://github.com/MobSF/Mobile-Security-Framework-MobSF/archive/refs/heads/master.zip GitHub - MobSF/Mobile-Security-Framework-MobSF: Mobile Secur…...
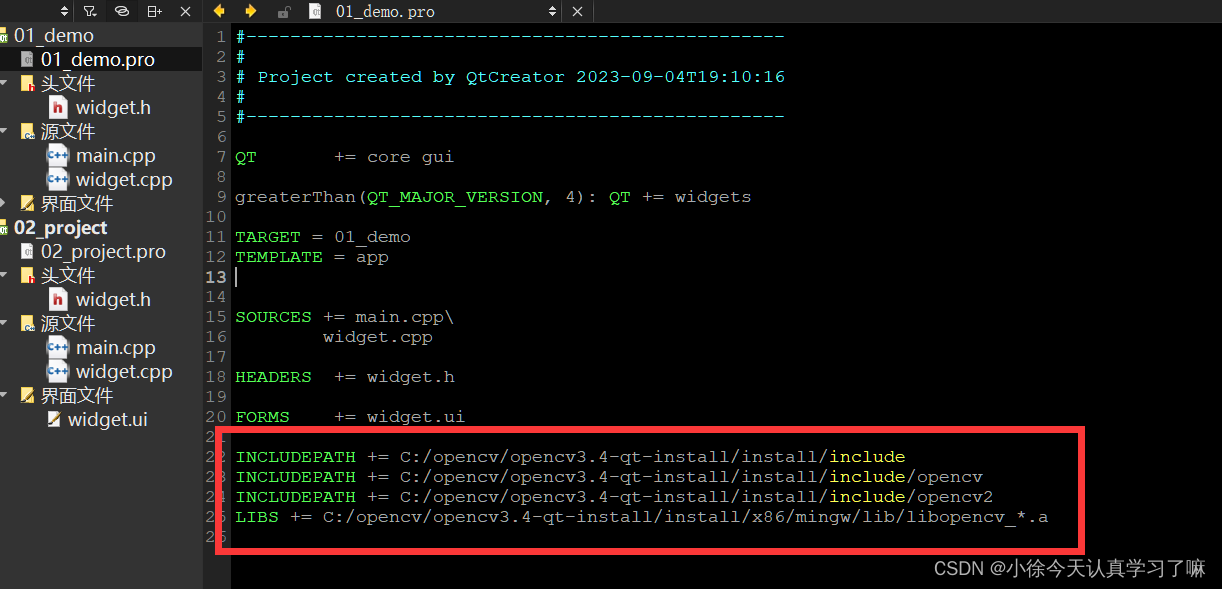
QT连接OpenCV库完成人脸识别
1.相关的配置 1> 该项目所用环境:qt-opensource-windows-x86-mingw491_opengl-5.4.0 2> 配置opencv库路径: 1、在D盘下创建一个opencv的文件夹,用于存放所需材料 2、在opencv的文件夹下创建一个名为:opencv3.4-qt-intall 文…...

使用 ElasticSearch 作为知识库,存储向量及相似性搜索
一、ElasticSearch 向量存储及相似性搜索 在当今大数据时代,快速有效地搜索和分析海量数据成为了许多企业和组织的重要需求。Elasticsearch 作为一款功能强大的分布式搜索和分析引擎,为我们提供了一种优秀的解决方案。除了传统的文本搜索,El…...

视频图像处理算法opencv在esp32及esp32s3上面的移植,也可以移植openmv
opencv在esp32及esp32s3上面的移植 Opencv简介 OpenCV是一个基于Apache2.0许可(开源)发行的跨平台计算机视觉和机器学习软件库,可以运行在Linux、Windows、Android和Mac OS操作系统上,它轻量级而且高效——由一系列 C 函数和少量…...
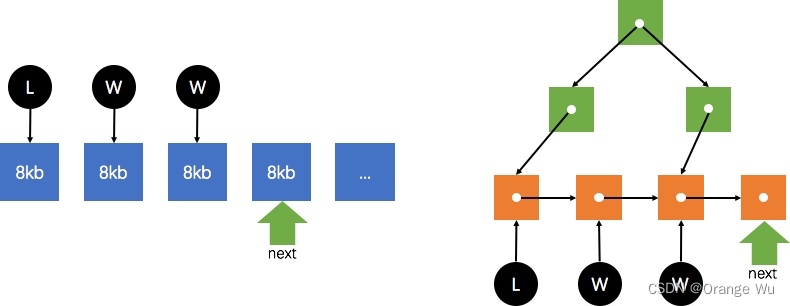
2. postgresql并行扫描(1)——pg强制走并行扫描建表及参数配置
转载自:https://developer.aliyun.com/article/700370 1. 参数设置 1.1 postgresql.conf中修改 # 1、总的可开启的WORKER足够大 max_worker_processes 128# 2、所有会话同时执行并行计算的并行度足够大 max_parallel_workers64# 3、单个QUERY中并行计算NODE开…...
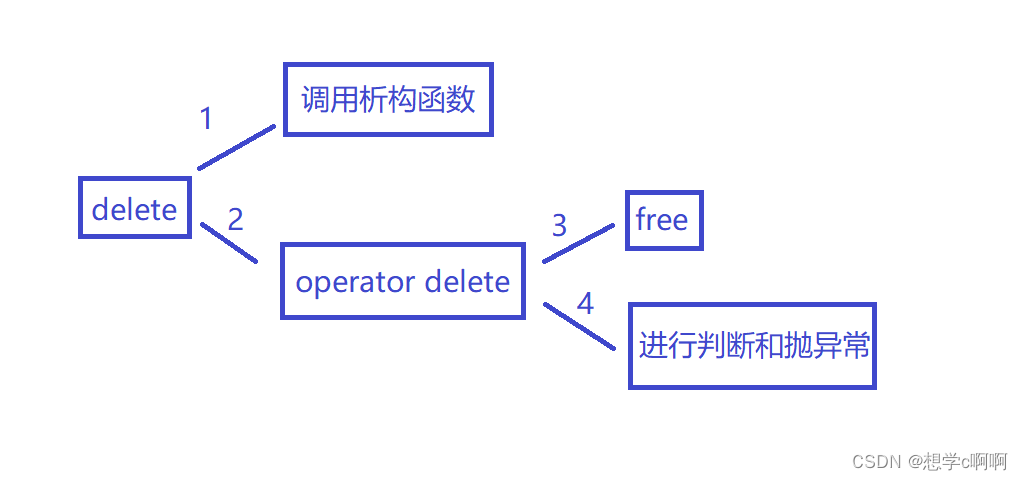
【C++】动态内存管理
【C】动态内存管理 new和delete用法内置类型自定义类型抛异常定位new 刨析new和delete的执行与实现逻辑功能执行顺序newdelete 功能实现operator new与operator delete malloc free与new delete的总结 在我们学习C之前 在C语言中常用的动态内存管理的函数为: mallo…...

MATLAB R2023a完美激活版(附激活补丁)
MATLAB R2023a是一款面向科学和工程领域的高级数学计算和数据分析软件,它为Mac用户提供了强大的工具和功能,用于解决各种复杂的数学和科学问题。以下是MATLAB R2023a Mac的一些主要特点和功能: 软件下载:MATLAB R2023a完美激活版 …...
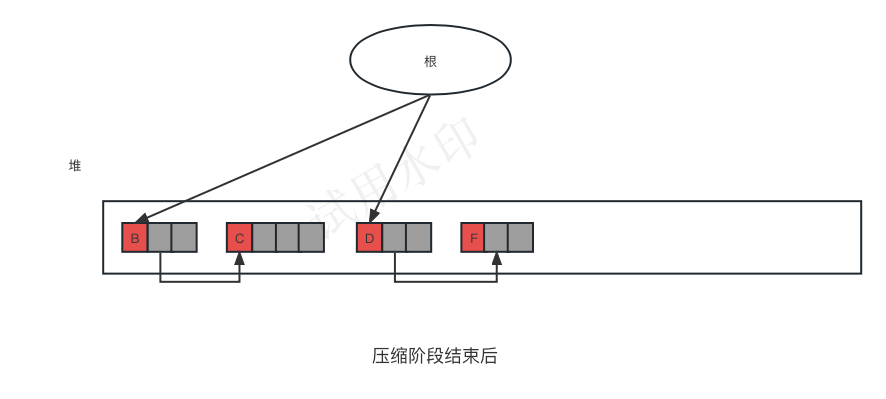
垃圾回收 - 标记压缩算法
压缩算法是将标记清除算法与复制算法相结合的产物。 1、什么是标记压缩算法 标记压缩算法是由标记阶段和压缩阶段构成。 首先,这里的标记阶段和标记清除算法时提到的标记阶段完全一样。 接下来我们要搜索数次堆来进行压缩。压缩阶段通过数次搜索堆来重新填充活动对…...

Vue中过滤器如何使用?
过滤器是对即将显示的数据做进⼀步的筛选处理,然后进⾏显示,值得注意的是过滤器并没有改变原来 的数据,只是在原数据的基础上产⽣新的数据。过滤器分全局过滤器和本地过滤器(局部过滤器)。 目录 全局过滤器 本地过滤器…...

【爬虫】7.4. 字体反爬案例分析与爬取实战
字体反爬案例分析与爬取实战 文章目录 字体反爬案例分析与爬取实战1. 案例介绍2. 案例分析3. 爬取 本节来分析一个反爬案例,该案例将真实的数据隐藏到字体文件里,即使我们获取了页面源代码,也无法直接提取数据的真实值。 1. 案例介绍 案例网…...

Umi-OCR:完全免费开源的离线OCR神器,3分钟快速上手文字识别
Umi-OCR:完全免费开源的离线OCR神器,3分钟快速上手文字识别 【免费下载链接】Umi-OCR OCR software, free and offline. 开源、免费的离线OCR软件。支持截屏/批量导入图片,PDF文档识别,排除水印/页眉页脚,扫描/生成二维…...

避开这5个坑,你的癫痫脑电AI模型准确率能翻倍:从数据标注到特征工程实战
避开这5个坑,你的癫痫脑电AI模型准确率能翻倍:从数据标注到特征工程实战 在医疗AI领域,癫痫脑电信号分析一直是个充满挑战的课题。许多开发者满怀信心地构建模型,却在验证阶段遭遇性能瓶颈——准确率停滞不前,误报率居…...

2026年主流抓娃娃App大对比,哪个才是你的“抓宝神器”?
在当今快节奏的生活中,年轻人面临着来自学业、工作、社交等多方面的压力。为了缓解这些压力,寻找适合的解压方式成为了大家的共同需求。抓娃娃App作为一种新兴的娱乐方式,正逐渐受到年轻人的喜爱。下面我们就从潮流趋势、科技前沿、行业洞察等…...

nnU-Net v2实战:从零开始配置环境与训练自定义医学影像数据集
1. 环境配置:搭建nnU-Net v2的基础舞台 第一次接触nnU-Net时,我踩过的最大坑就是环境配置。当时为了赶项目进度,直接用了现有的Python 3.8环境,结果在安装时各种报错,浪费了大半天时间。后来才发现,nnU-Net…...

AI驱动的Web可访问性审查:LLM如何成为你的自动化无障碍专家
1. 项目概述:一个为AI智能体而生,却意外照亮了所有人的可访问性审查工具 最近在折腾AI智能体(AI Agent)的开发,一个老问题又浮上水面:怎么确保我造出来的这个“数字员工”,能真正服务好所有人&…...

AI智能体记忆系统设计:从RAG到长期记忆的工程实践
1. 项目概述:从“记忆”到“智能”的跨越在AI智能体(Agent)的开发浪潮中,我们常常面临一个核心挑战:如何让智能体在复杂的、多轮次的交互中,表现得像一个真正有“记忆”和“经验”的专家?传统的…...

82.人工智能实战:大模型多环境治理怎么做?从开发、测试、预发到生产的 Prompt、模型、知识库隔离方案
人工智能实战:大模型多环境治理怎么做?从开发、测试、预发到生产的 Prompt、模型、知识库隔离方案 一、问题场景:测试环境改了 Prompt,结果生产回答变了 很多大模型项目早期只有一个环境: 一套 Prompt 一个知识库 一个模型地址 一个配置表开发、测试、运营都在同一套配置…...

我给了智能体$100去赚钱,结果...
你看过那些演示。一个自主智能体启动,获得一个目标,然后——跳到两周后的 Twitter 帖子——它不知怎么地就在运营一个 Shopify 店铺、写通讯和炒币了。未来已来。AGI 即将降临。买课吧。 我想找出实际发生了什么。 所以我给了一个智能体 100 美元和一个…...

MacOS光标增强工具:命令行驱动,实现自动化与个性化配置
1. 项目概述:当光标成为生产力工具如果你是一名长期在macOS上工作的开发者、设计师或者文字工作者,你肯定对系统自带的光标功能又爱又恨。爱的是它简洁流畅,恨的是它在某些高强度、多任务场景下显得力不从心。比如,当你需要在多个…...

MySQL高可用与扩展-主从复制读写分离分库分表
当单库压力越来越大时,常见演进路线是先做主从复制,再做读写分离;如果数据量和写入压力继续增长,就需要考虑分库分表。 这三者解决的问题不同:方案主要解决什么主从复制数据冗余、读扩展、故障切换基础读写分离缓解读请…...